YOLO V11 + BotSort行人追踪定位项目
本文可以让你一个小时内从0搭建一个成熟的追踪项目,并且会附上很多参考资料,以及可运行的项目demo,如果你是一个计科或者软工毕业生,准备搞毕业设计,不妨看一看,可以让你在短时间内完成一个惊艳同学和导师的毕业设计(文章后面也有对YOLO V11以及BotSort原理详细讲解)。
项目准备部分:
环境搭建:
1,首先你要下载一个python+conda环境,这种简单的我就不赘述了。看以下的文章,有环境的跳过
Anaconda创建Pytorch虚拟环境(排坑详细)_anaconda创建pytorch环境-CSDN博客
2,你要在Ultralytics团队下载对应的项目框架代码地址如下
主页 -Ultralytics YOLO 文档
详细教程:YOLOV8全环境配置教程(图文教程,30分钟可配置完成!!)_yolov8环境配置-CSDN博客
3,准备工作做完你应该有一个这样的目录
具体实现demo植入
1.创建一个新的py文件在内部,然后把下面具体运行的代码copy进去,然后根据报错提示去把缺少的库补充。
import cv2
import torch
from ultralytics import YOLO
from ultralytics.trackers import BOTSORT, BYTETracker
from ultralytics.trackers.basetrack import BaseTrack
from pathlib import Path
import time
import os
import numpy as np
from collections import defaultdictdef load_mode(MODEL_PATH):"""加载YOLOv11模型参数:MODEL_PATH: 模型文件路径返回:model: 加载好的YOLO模型"""model = YOLO(MODEL_PATH)# 使用GPU加速(如果可用)if torch.cuda.is_available():model = model.cuda()return modeldef print_imformation(VIDEO_PATH):"""打印视频基本信息并返回宽高和FPS参数:VIDEO_PATH: 视频文件路径返回:width: 视频宽度height: 视频高度fps: 视频帧率"""cap = cv2.VideoCapture(VIDEO_PATH)# 获取视频属性width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))fps = cap.get(cv2.CAP_PROP_FPS)frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))print(f"视频宽度: {width}")print(f"视频高度: {height}")print(f"视频帧率: {fps}")print(f"视频总帧数: {frame_count}")cap.release()return width, height, fpsdef Preproces_frames(frame, w, h):"""预处理帧 - 按比例缩放参数:frame: 原始帧w: 目标宽度h: 目标高度返回:frame_resized: 缩放后的帧"""scale = 1.2new_w, new_h = int(w * scale), int(h * scale)frame_resized = cv2.resize(frame, (new_w, new_h))return frame_resizeddef video_track(VIDEO_PATH, model, w, h, video_fps):"""视频追踪主函数,实时显示追踪结果并保存输出视频参数:VIDEO_PATH: 视频文件路径model: YOLO模型w: 视频原始宽度h: 视频原始高度video_fps: 视频帧率"""# 跟踪参数conf_threshold = 0.3iou_threshold = 0.5person_class_id = 0scale = 1.2# 计算缩放后的尺寸new_w, new_h = int(w * scale), int(h * scale)# 创建视频写入对象fourcc = cv2.VideoWriter_fourcc(*'mp4v')out = cv2.VideoWriter(OUTPUT_PATH, fourcc, video_fps, (new_w, new_h))# 打开视频文件cap = cv2.VideoCapture(VIDEO_PATH)if not cap.isOpened():print("无法打开视频文件")return# 用于存储每个人的停留时间和位置历史track_history = defaultdict(lambda: {'first_seen': None,'positions': [],'duration': 0.0,'last_position': None})# 用于帧率计算prev_time = 0frame_count = 0while cap.isOpened():success, frame = cap.read()if not success:break# 预处理帧frame_resized = Preproces_frames(frame, w, h)# 使用模型进行跟踪results = model.track(frame_resized,persist=True,conf=conf_threshold,iou=iou_threshold,classes=[person_class_id],tracker="botsort.yaml",verbose=False # 禁用详细输出以提高效率)# 获取检测结果boxes = results[0].boxes.xyxy.cpu().numpy()confidences = results[0].boxes.conf.cpu().numpy()class_ids = results[0].boxes.cls.cpu().numpy().astype(int)# 获取追踪ID(如果可用)track_ids = []if results[0].boxes.id is not None:track_ids = results[0].boxes.id.cpu().numpy().astype(int)# 在帧上绘制结果for idx, box in enumerate(boxes):x1, y1, x2, y2 = map(int, box)conf = confidences[idx]class_id = class_ids[idx]# 只绘制人的检测结果if class_id == person_class_id:# 计算中心点位置center_x = int((x1 + x2) / 2)center_y = int((y1 + y2) / 2)# 获取或初始化追踪信息track_id = track_ids[idx] if idx < len(track_ids) else -1track_info = track_history[track_id]# 更新位置历史(保留最近5个位置)track_info['positions'].append((center_x, center_y))if len(track_info['positions']) > 5:track_info['positions'].pop(0)# 更新停留时间current_time = frame_count / video_fps # 当前视频时间(秒)if track_info['first_seen'] is None:track_info['first_seen'] = current_timetrack_info['duration'] = current_time - track_info['first_seen']track_info['last_position'] = (center_x, center_y)# 绘制边界框color = (0, 255, 0) # 绿色cv2.rectangle(frame_resized, (x1, y1), (x2, y2), color, 2)# 绘制中心点cv2.circle(frame_resized, (center_x, center_y), 5, (0, 0, 255), -1)# 准备显示信息id_text = f"ID: {track_id}" if track_id != -1 else "ID: N/A"conf_text = f"Conf: {conf:.2f}"pos_text = f"Pos: ({center_x}, {center_y})"dur_text = f"Dur_time: {track_info['duration']:.1f}s"# 绘制文本信息(四行)y_offset = y1 - 10for i, text in enumerate([id_text, conf_text, pos_text, dur_text]):cv2.putText(frame_resized, text, (x1, y_offset - i * 25),cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 1)# 计算并显示帧率curr_time = time.time()fps = 1 / (curr_time - prev_time) if prev_time > 0 else 0prev_time = curr_time# 显示全局统计信息stats_text = f"FPS: {fps:.1f} | Tracked: {len(track_ids)}"cv2.putText(frame_resized, stats_text, (10, 30),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)# 显示处理后的帧cv2.imshow("Person Tracking", frame_resized)# 写入输出视频out.write(frame_resized)# 按'q'退出if cv2.waitKey(1) & 0xFF == ord('q'):breakframe_count += 1if frame_count % 50 == 0:print(f"已处理 {frame_count} 帧 | 追踪人数: {len(track_ids)}")# 释放资源cap.release()out.release()cv2.destroyAllWindows()# 打印最终统计信息print("\n追踪统计:")print(f"总帧数: {frame_count}")print(f"总追踪人数: {len(track_history)}")if track_history:avg_duration = sum(info['duration'] for info in track_history.values()) / len(track_history)print(f"平均停留时间: {avg_duration:.1f}秒")print(f"结果保存至: {OUTPUT_PATH}")if __name__ == "__main__":# ===== 配置参数 =====VIDEO_PATH = r"D:\DataSet\video\people_walk.mp4" # 视频路径OUTPUT_PATH = r"D:\DataSet\video\results\mot20_tracked.mp4" # 输出视频路径MODEL_PATH = r".\yolo11n.pt" # YOLOv11模型路径# 1.加载模型decte_mode = load_mode(MODEL_PATH)# 2.视频参数打印video_w, video_h, video_fps = print_imformation(VIDEO_PATH)# 3.视频追踪video_track(VIDEO_PATH, decte_mode, video_w, video_h, video_fps)代码简略分析:
tip:由于你是基于ultralytics这个团队做的yolo11的检测基础上去完成追踪所以代码量很少。
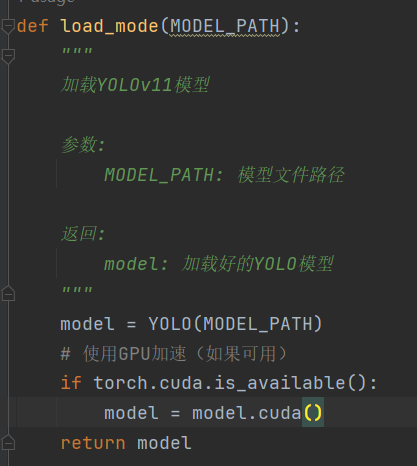
1.模型加载模块,可以更换其他版本的模型
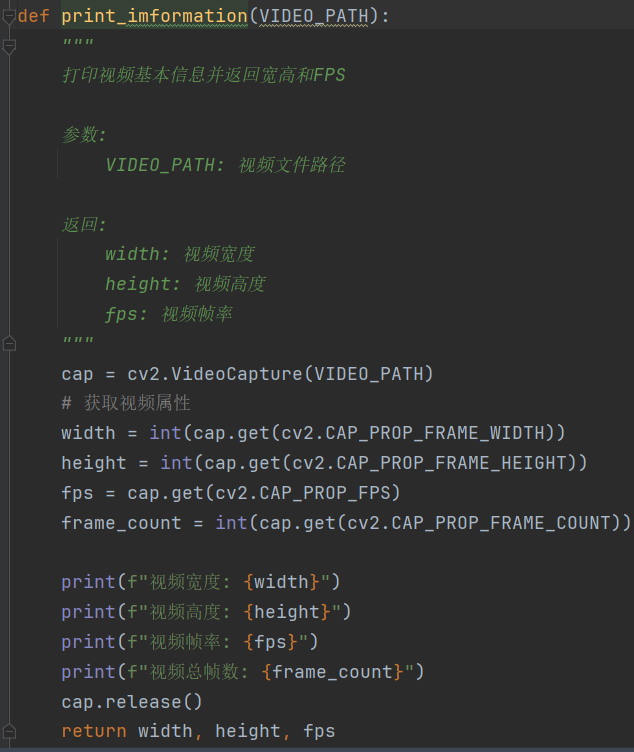
2.获取你测试视频信息模块
3.具体实现检测和追踪并且画在原图中部分的代码
def video_track(VIDEO_PATH, model, w, h, video_fps):"""视频追踪主函数,实时显示追踪结果并保存输出视频参数:VIDEO_PATH: 视频文件路径model: YOLO模型w: 视频原始宽度h: 视频原始高度video_fps: 视频帧率"""# 跟踪参数conf_threshold = 0.3iou_threshold = 0.5person_class_id = 0scale = 1.2# 计算缩放后的尺寸new_w, new_h = int(w * scale), int(h * scale)# 创建视频写入对象fourcc = cv2.VideoWriter_fourcc(*'mp4v')out = cv2.VideoWriter(OUTPUT_PATH, fourcc, video_fps, (new_w, new_h))# 打开视频文件cap = cv2.VideoCapture(VIDEO_PATH)if not cap.isOpened():print("无法打开视频文件")return# 用于存储每个人的停留时间和位置历史track_history = defaultdict(lambda: {'first_seen': None,'positions': [],'duration': 0.0,'last_position': None})# 用于帧率计算prev_time = 0frame_count = 0while cap.isOpened():success, frame = cap.read()if not success:break# 预处理帧frame_resized = Preproces_frames(frame, w, h)# 使用模型进行跟踪results = model.track(frame_resized,persist=True,conf=conf_threshold,iou=iou_threshold,classes=[person_class_id],tracker="botsort.yaml",verbose=False # 禁用详细输出以提高效率)# 获取检测结果boxes = results[0].boxes.xyxy.cpu().numpy()confidences = results[0].boxes.conf.cpu().numpy()class_ids = results[0].boxes.cls.cpu().numpy().astype(int)# 获取追踪ID(如果可用)track_ids = []if results[0].boxes.id is not None:track_ids = results[0].boxes.id.cpu().numpy().astype(int)# 在帧上绘制结果for idx, box in enumerate(boxes):x1, y1, x2, y2 = map(int, box)conf = confidences[idx]class_id = class_ids[idx]# 只绘制人的检测结果if class_id == person_class_id:# 计算中心点位置center_x = int((x1 + x2) / 2)center_y = int((y1 + y2) / 2)# 获取或初始化追踪信息track_id = track_ids[idx] if idx < len(track_ids) else -1track_info = track_history[track_id]# 更新位置历史(保留最近5个位置)track_info['positions'].append((center_x, center_y))if len(track_info['positions']) > 5:track_info['positions'].pop(0)# 更新停留时间current_time = frame_count / video_fps # 当前视频时间(秒)if track_info['first_seen'] is None:track_info['first_seen'] = current_timetrack_info['duration'] = current_time - track_info['first_seen']track_info['last_position'] = (center_x, center_y)# 绘制边界框color = (0, 255, 0) # 绿色cv2.rectangle(frame_resized, (x1, y1), (x2, y2), color, 2)# 绘制中心点cv2.circle(frame_resized, (center_x, center_y), 5, (0, 0, 255), -1)# 准备显示信息id_text = f"ID: {track_id}" if track_id != -1 else "ID: N/A"conf_text = f"Conf: {conf:.2f}"pos_text = f"Pos: ({center_x}, {center_y})"dur_text = f"Dur_time: {track_info['duration']:.1f}s"# 绘制文本信息(四行)y_offset = y1 - 10for i, text in enumerate([id_text, conf_text, pos_text, dur_text]):cv2.putText(frame_resized, text, (x1, y_offset - i * 25),cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 1)# 计算并显示帧率curr_time = time.time()fps = 1 / (curr_time - prev_time) if prev_time > 0 else 0prev_time = curr_time# 显示全局统计信息stats_text = f"FPS: {fps:.1f} | Tracked: {len(track_ids)}"cv2.putText(frame_resized, stats_text, (10, 30),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)# 显示处理后的帧cv2.imshow("Person Tracking", frame_resized)# 写入输出视频out.write(frame_resized)# 按'q'退出if cv2.waitKey(1) & 0xFF == ord('q'):breakframe_count += 1if frame_count % 50 == 0:print(f"已处理 {frame_count} 帧 | 追踪人数: {len(track_ids)}")# 释放资源cap.release()out.release()cv2.destroyAllWindows()# 打印最终统计信息print("\n追踪统计:")print(f"总帧数: {frame_count}")print(f"总追踪人数: {len(track_history)}")if track_history:avg_duration = sum(info['duration'] for info in track_history.values()) / len(track_history)print(f"平均停留时间: {avg_duration:.1f}秒")print(f"结果保存至: {OUTPUT_PATH}")4,运行效果展示与分析
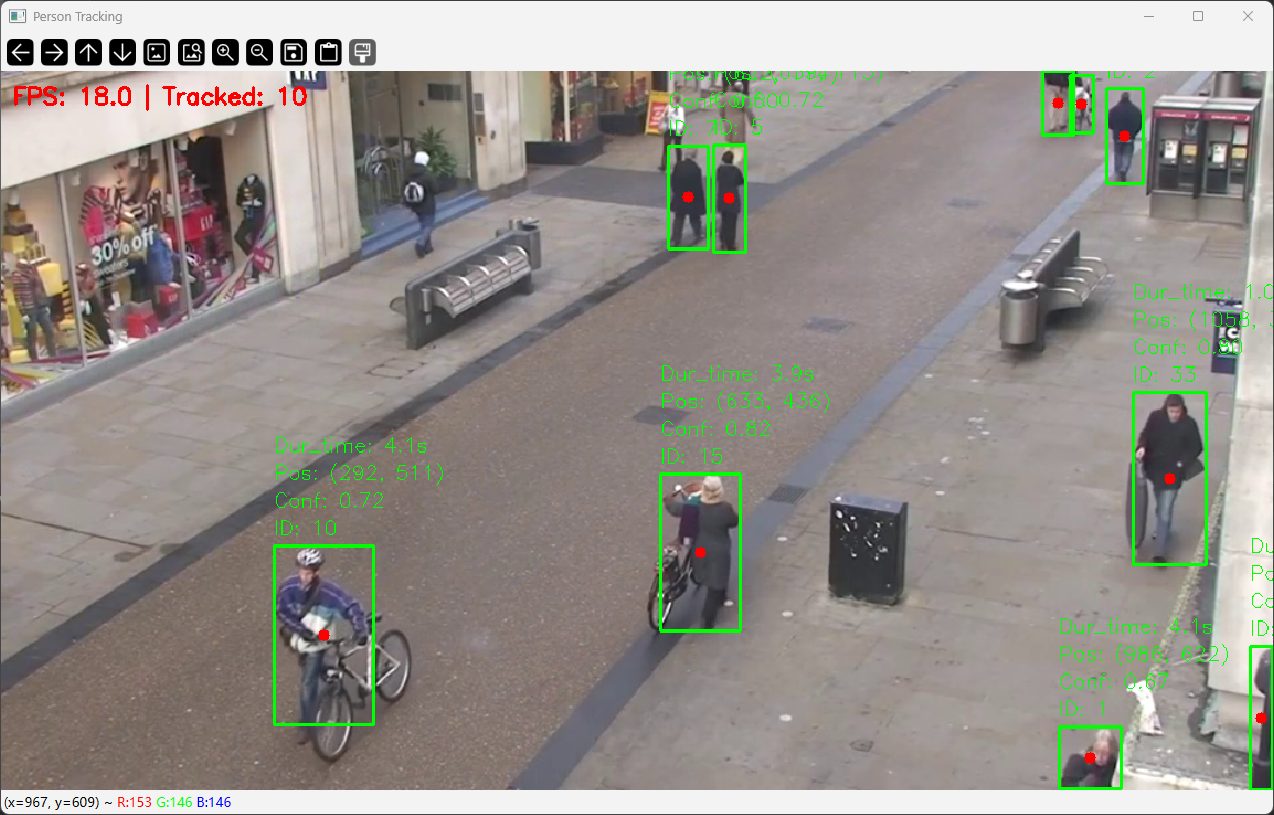
1.左上角是你追踪时候的帧率,和当前被锁定追踪的目标数量。
2.每个人头上的ID是追踪的时候对这个人的标记(用于确定是那个人)。
3.conf:0.72是置信度,既为检测这个是人的概率为多大。
4.pos:是这个人在图中当前绝对位置。
5.Dur_time是这个人在画面停留的时间。
tip:这些都是基础数据根据这些,你可以去衍生很多具体统计与任务处理。
原理:
YOLO11
tips建议不懂yolo的可以去看下我之前写的yolov8的文章,不然肯定看不懂11
具体链接:Yolo v8详解(文字版)_yolov8算法详解-CSDN博客
网络结构:
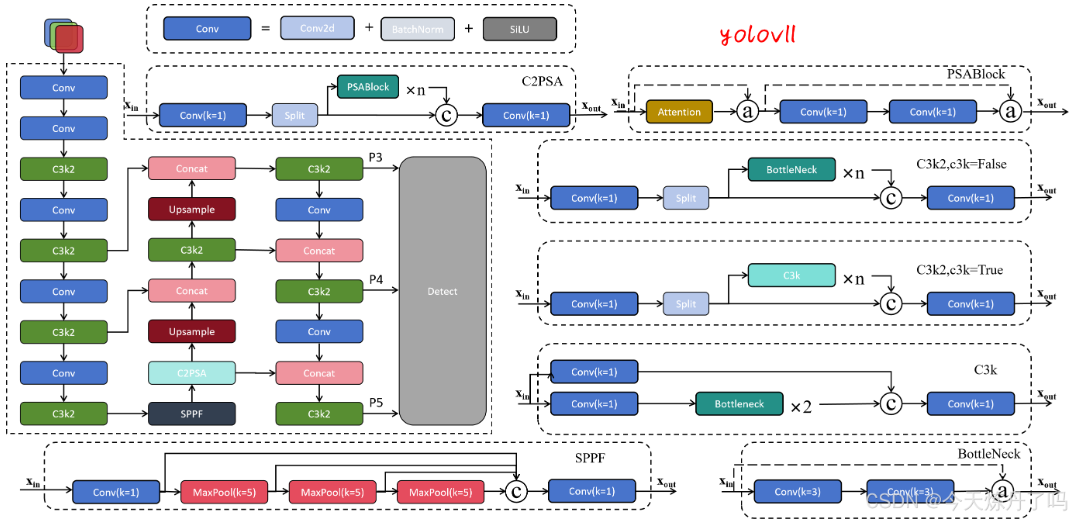
网络模块分析:
1Backbone(主干网络提取特征):
①Conv 模块:通常包含卷积Conv2d、批量归一化(BN)和激活函数(如 SiLU)
作用:通过 3×3 卷积(步长 2)对输入图像进行下采样,分别得到分辨率为原图 1/2(P1/2)和 1/4(P2/4)的特征图。
②C3K2模块:类似 YOLOv5 中的 C3 模块,是一种轻量级残差模块,包含瓶颈结构和跨层连接。
作用:分通道,残差链接,融合后的特征进一步提取。也是为了更好,更快的提取特征。
2NecK(PAN-FPN特征融合):
①SPPF模块:Spatial Pyramid Pooling Fast(快速空间金字塔池化)和以往的没啥区别
作用:通过多尺度最大池化(如 5×5)融合不同感受野的特征,增强模型对目标尺度变化的适应性。
②C2PSA模块:结合通道注意力(Channel Attention)和空间注意力(Spatial Attention)的增强模块。
作用:通过注意力机制聚焦关键区域特征,抑制背景噪声,提升特征表达能力。
PAN-FPN:上采样特征融合concat,下采样特征融合,这个过程,就是为了在高层语义信息,注入高分辨率特征图,解决小目标在深层特征中消失的问题。缓解深层网络梯度消失问题。并且分不同尺度的头输出多尺度特征提取检测。
3Head(检测头):
p3:检测小目标(1/8分辨率):reg_p3 回归头 [1, 16*4, 80, 80] (4*16=64) cls_p3类别头[1, 80, 80, 80] obj_p3有无目标[1, 1, 80, 80] = [1,145,80,80]
p4:检测中目标(1/16分辨率):reg_p3 回归头 [1, 16*4, 40, 40] (4*16=64) cls_p3类别头[1, 80, 40, 40] obj_p3有无目标[1, 1, 40, 40] = [1,145,40,40]
p5:检测大目标(1/32分辨率):reg_p3 回归头 [1, 16*4, 20, 20] (4*16=64) cls_p3类别头[1, 80, 20, 20] obj_p3有无目标[1, 1, 20, 20] =[1,145,20,20]
tip:检测头部分唯一和yolo v8的区别就是v11在cls分支上使用深度可分离卷积,以减少冗余计算,提高效率。
4其他部分:
训练过程,正样本选择,loss构建反向传播都和之前的yolo8没有什么区别就不赘述了。
BotSort:
tip对于botsort的详细分析看下面这两篇文章:
BOT-SORT算法整体解析-CSDN博客
BOT-SORT完整跟踪代码详解(bot_sort.py)-CSDN博客
核心思路:
基于 排序增强的匹配策略,通过融合多个特征(位置、外观、运动)提高目标匹配的精度。
(1) 目标检测
BOT-SORT 依赖高性能目标检测器,确保每一帧中的目标检测结果(Bounding Box)足够准确。检测结果通常包含:
①检测框位置 [x,y,w,h]
②检测置信度 c
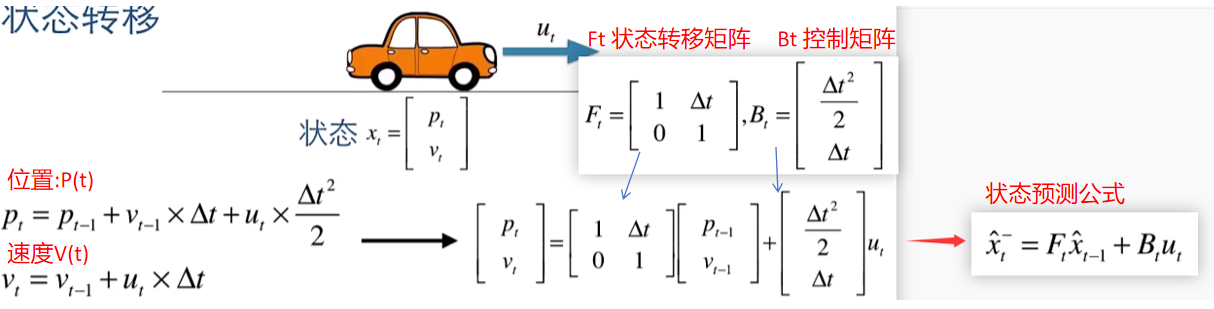
(2) 状态预测
①通过 Kalman 滤波预测目标在当前帧的位置和运动状态。状态包括:
②位置和速度
③状态更新利用上一帧的匹配结果和检测结果。
(3) 外观特征提取
BOT-SORT 使用预训练的深度学习模型(如 ReID 网络)提取目标的外观特征。特征向量用于衡量目标之间的相似性,解决遮挡和快速移动导致的跟踪丢失问题。
(4) 匹配策略
采用 级联排序匹配 (Cascade Matching):优先匹配高置信度目标和状态一致的目标。距离计算融合了多种度量方法,包括:
①位置距离(IoU):衡量两个检测框重叠的程度。
②外观相似性(Cosine Similarity):衡量两目标外观特征的相似性。
③运动一致性:利用 Kalman 滤波预测目标运动趋势。
(5) 身份维护
对未匹配的目标进行新身份分配或丢失目标回收。
采用轨迹管理策略防止短暂丢失目标被误删除。
目标追踪原理:
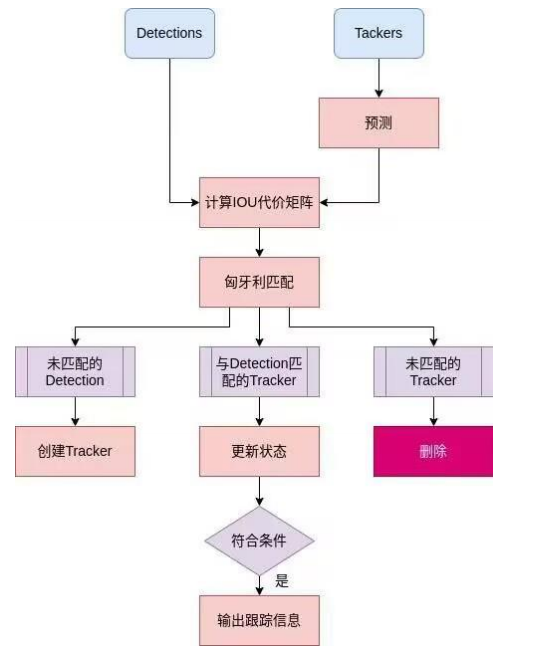
算法核心工作流程:
- 预测 (Prediction): 使用轨迹的运动模型(如卡尔曼滤波器)预测下一帧的位置。
- 丢失计数器 (Miss Counter): 增加该轨迹的丢失计数器。如果丢失计数器超过预设阈值(如 max_age),则认为目标已离开视野或跟踪失败,终止该轨迹。
- 重新检测 (Re-detection): 在后续帧中,尝试在预测位置附近或全局搜索(结合外观特征)重新关联该轨迹。
- 状态管理: 区分“确认的”(Confirmed)和“未确认的”(Tentative)轨迹。只有确认的轨迹在丢失超过 max_age 后才终止;未确认的轨迹(通常是刚初始化的)可能只允许丢失 1 帧就被终止。
目标检测:
卡尔曼滤波:
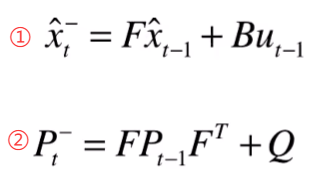
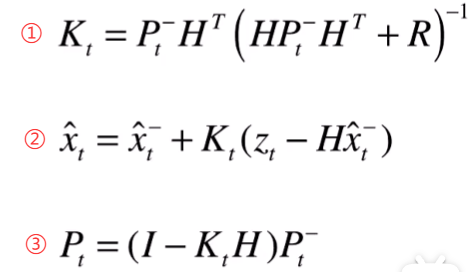
匈牙利算法:
- 行规约(Row Reduction):对每行 ii,减去该行最小值:cij←cij−mink{cik}∀j.cij←cij−kmin{cik}∀j.
- 列规约(Column Reduction):对每列 jj,减去该列最小值:cij←cij−mink{ckj}∀i.cij←cij−kmin{ckj}∀i.
- 覆盖所有零元素:用最少的水平线(覆盖行)和垂直线(覆盖列)覆盖矩阵中的所有零元素。设最少线数为 kk。
- 若 k=nk=n:找到最优匹配(每行每列恰有一个零)。
- 若 kk<n:进入步骤 4。
- 矩阵调整(Adjustment):
- 找到未被覆盖元素的最小值 δδ。
- 所有未被覆盖的行减去 δδ。
- 所有被覆盖的列加上 δδ。返回步骤 3。
总结:
以上就是简单的完成一个机器视觉追踪任务的代码实际项目到他的原理。希望能帮到有需要的人。