逻辑回归参数调优实战指南
逻辑回归的参数调节
参数展示
LogisticRegression(penalty='l2',dual=False,tol=1e4,C=1.0,fit_intercept=True,intercept_scaling=1,class_weight=None,random_state=None,solver='liblinear',max_iter=100,multi_class='ovr',verbose=0,warm_start=False, n_jobs=1)
在前面的学习中,我们参数使用的都是默认参数。所有在面对特殊问题的时候,准确率会高,召回率也不高。所以我们要对某些数据进行微调。
正则化惩罚项
在我们处理数据的时候,有时候会出现各种各样的数据,然后根据数据我们也有各种各样的权重参数,例如下面有两种权重参数
data:1,1,1,1
w1:1,0,0,0
w2:0.25,0.25,0.25,0.25
在两组参数中,我们得到的最终结果都是一样的,那我们知道,第一种肯定不行,过拟合了,不能运用所有数据,但是我们该如何让机器也知道,什么样的权重参数好,什么坏呢?
这里在均方差中引入了正则化惩罚项

正则化惩罚项
λR(W)- λ: 正则化强度系数(超参数)也就是参数中的C
- R(W): 权重的惩罚函数,包含两种形式:
- L1 正则化:
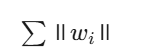
- 产生稀疏权重,自动特征选择
- L2 正则化:
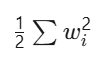
- 为求导便利设计的系数(梯度计算时抵消平方项导数产生的2)
- 控制权重幅度,防止过拟合
- L1 正则化:
其实正则化最重要的功能也就是防止过拟合
交叉验证
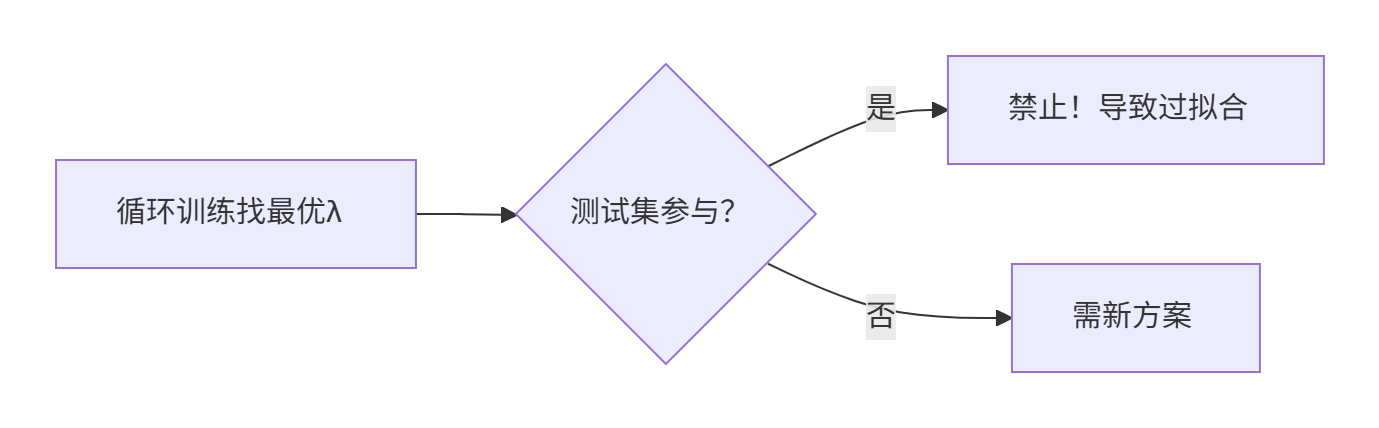
对于上面的正则化惩罚项系数,我们该怎么知道哪个阐述最好呢?我们会想到让机器循环找到那个最好的参数。
于是我们想到循环训练,让测试集来测试,选择出一个最好的参数,但是我们注意到,如果我们让测试集参与到了训练中,这样结果会不会也会有过拟合的现象,所有我们无论如何也不能把测试集参与到训练中。
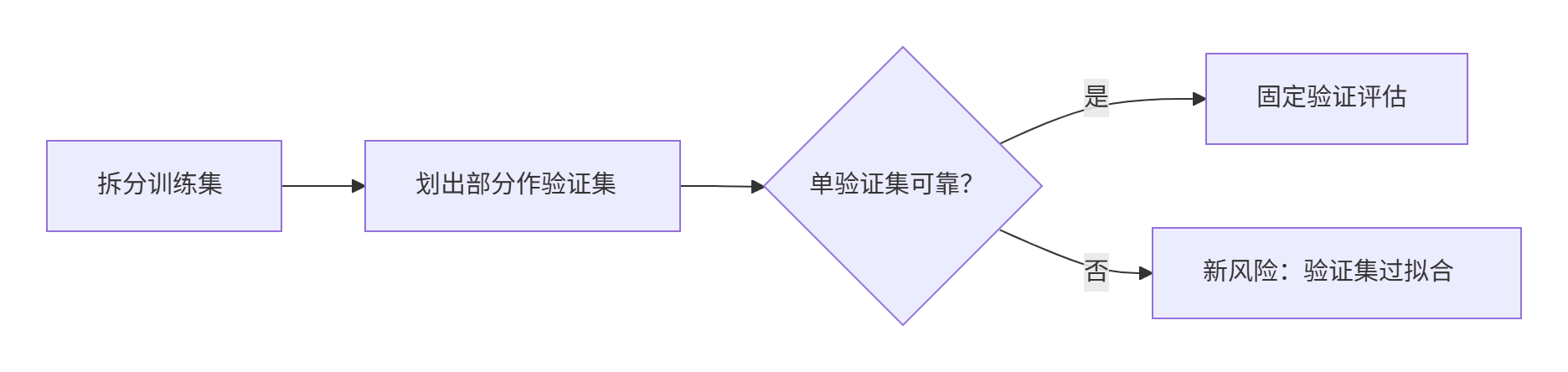
 下面我们又想到,可以把训练集中划出一部分来进行验证,是不是也可以。但是我们又想着一直用这一个验证集会不会也会过拟合。
下面我们又想到,可以把训练集中划出一部分来进行验证,是不是也可以。但是我们又想着一直用这一个验证集会不会也会过拟合。
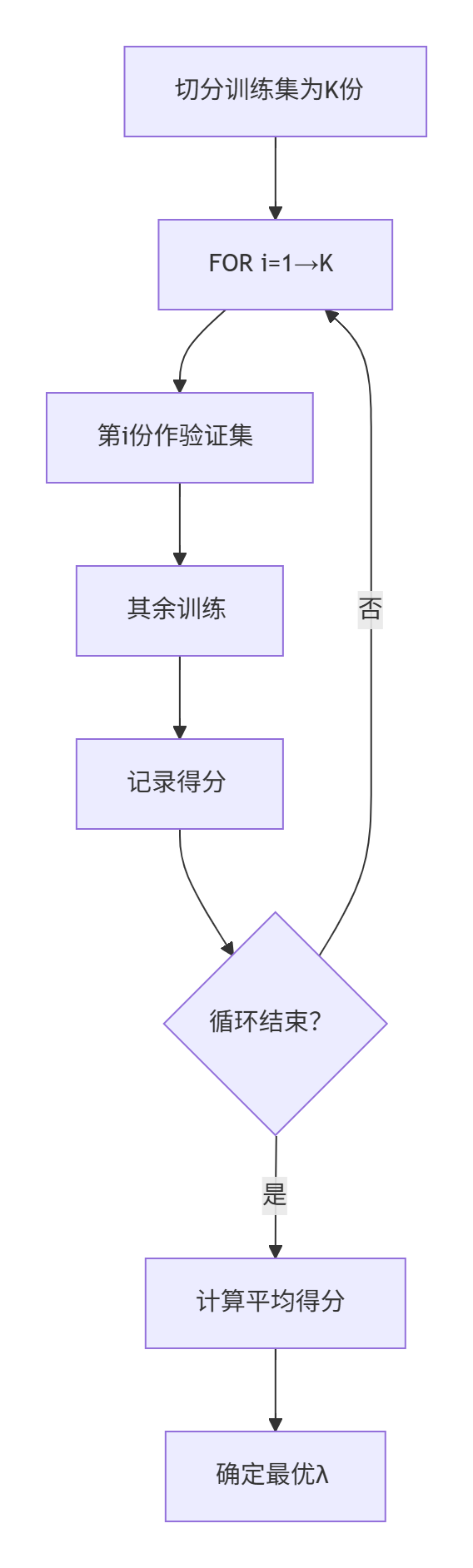
 接下来,我们想到,我们可以把训练集切成几份,循环到一个参数时,依次把几份中的一个当作验证集,其余训练。然后去他们的平均值作为我们的最终结果。这样就是我们的交叉验证了!
接下来,我们想到,我们可以把训练集切成几份,循环到一个参数时,依次把几份中的一个当作验证集,其余训练。然后去他们的平均值作为我们的最终结果。这样就是我们的交叉验证了!
代码实例
import pandas as pd
from numpy.ma.core import count
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
data=pd.read_csv(r'D:\培训\机器学习\逻辑回归\银行贷款\creditcard.csv')
print(len(data[data['Class'] == 1]))
mod=StandardScaler()
data["Amount"]=mod.fit_transform(data[['Amount']])
X=data.drop(["Time","Class"],axis=1)
y=data["Class"]
train_X,test_X,train_y,test_y=train_test_split(X,y,test_size=0.2,random_state=42)from sklearn.model_selection import cross_val_score
import numpy as np
scores=[]
pe=[0.01,0.1,1,10,100]
for p in pe:lr=LogisticRegression(C=p,penalty ='l2',random_state=42,max_iter=1000)score=cross_val_score(lr,train_X,train_y,cv=8,scoring='recall')scores_mean=sum(score)/len(score)scores.append(scores_mean)print(scores_mean)best_c=pe[np.argmax(scores)]
print('最优系数:',best_c)
model=LogisticRegression(C=best_c,penalty ='l2',random_state=42,max_iter=1000)
model.fit(train_X,train_y)
print(model.score(test_X,test_y))
from sklearn import metrics
print(metrics.classification_report(test_y,model.predict(test_X)))上面我们取了[0.01,0.1,1,10,100]这几个值来进行测试,然后找出最优的值。下面我们对代码核心部分for循环中的部分进行解读
先建立模型
lr=LogisticRegression(C=p,penalty ='l2',random_state=42,max_iter=1000)计算召回率的得分值
score=cross_val_score(lr,train_X,train_y,cv=8,scoring='recall')求均值,并把值添加到列表中。
scores_mean=sum(score)/len(score)scores.append(scores_mean)找出最大值
best_c=pe[np.argmax(scores)]根据最优参数进行训练
model=LogisticRegression(C=best_c,penalty ='l2',random_state=42,max_iter=1000)
model.fit(train_X,train_y)
print(model.score(test_X,test_y))
from sklearn import metrics
print(metrics.classification_report(test_y,model.predict(test_X)))得出结果
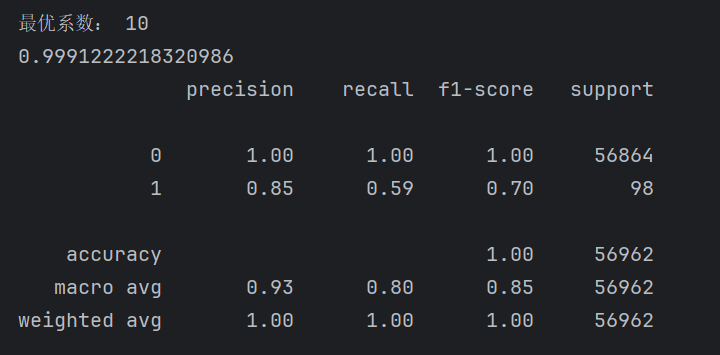
下面这个是没有进行交叉验证时候的结果
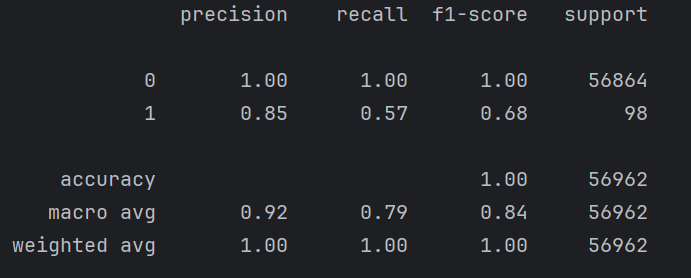
召回率仅仅增加了百分之二,但是如果对于后期增加百分之二也很重要,这里主要是数据类别的极度不均衡。下面我们对数据进行处理
数据处理
我们数据中的,类别为1的和为0的数据差了几千倍,并且我们比较关注为1的结果,所以我们要对数据进行处理,也就是两条路,一个是增加1的数据量,或者减少0的数据量。
下采样
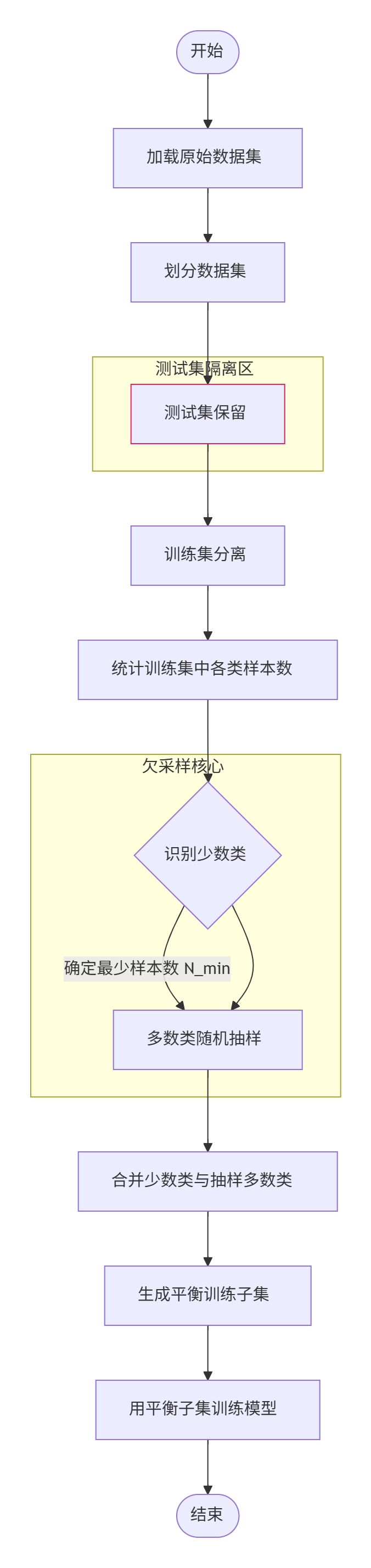
这个是训练集中0的数据量。我们想先对数据集进行划分,测试集不处理,训练集进行处理,先找出少的那一类的数据条数,然后对数据多的那一类进行抽样,抽出相同数量的数据,然后针对这些进行训练。
代码部分
train_data,test_data=train_test_split(data,test_size=0.2,random_state=42)pe=train_data[train_data['Class'] == 1]
ne=train_data[train_data['Class'] == 0]d1 = ne.sample(len(pe))train_data = pd.concat([d1,pe])train_X=train_data.drop(["Time","Class"],axis=1)
train_y=train_data["Class"]
test_X=test_data.drop(["Time","Class"],axis=1)
test_y=test_data["Class"]其余没修改,就这一部分修改了
上面代码中,我们先对训练集和测试集进行分开,然后对训练集中标签为0的标签中取样出标签0数量的数据,然后进行连接,下面就正常训练了,不够这样可能会让数据量减少许多
过采样
这个是让数据量少的那一类增加,不够也不是随便增加,其中采用了SMOTE算法,如下:
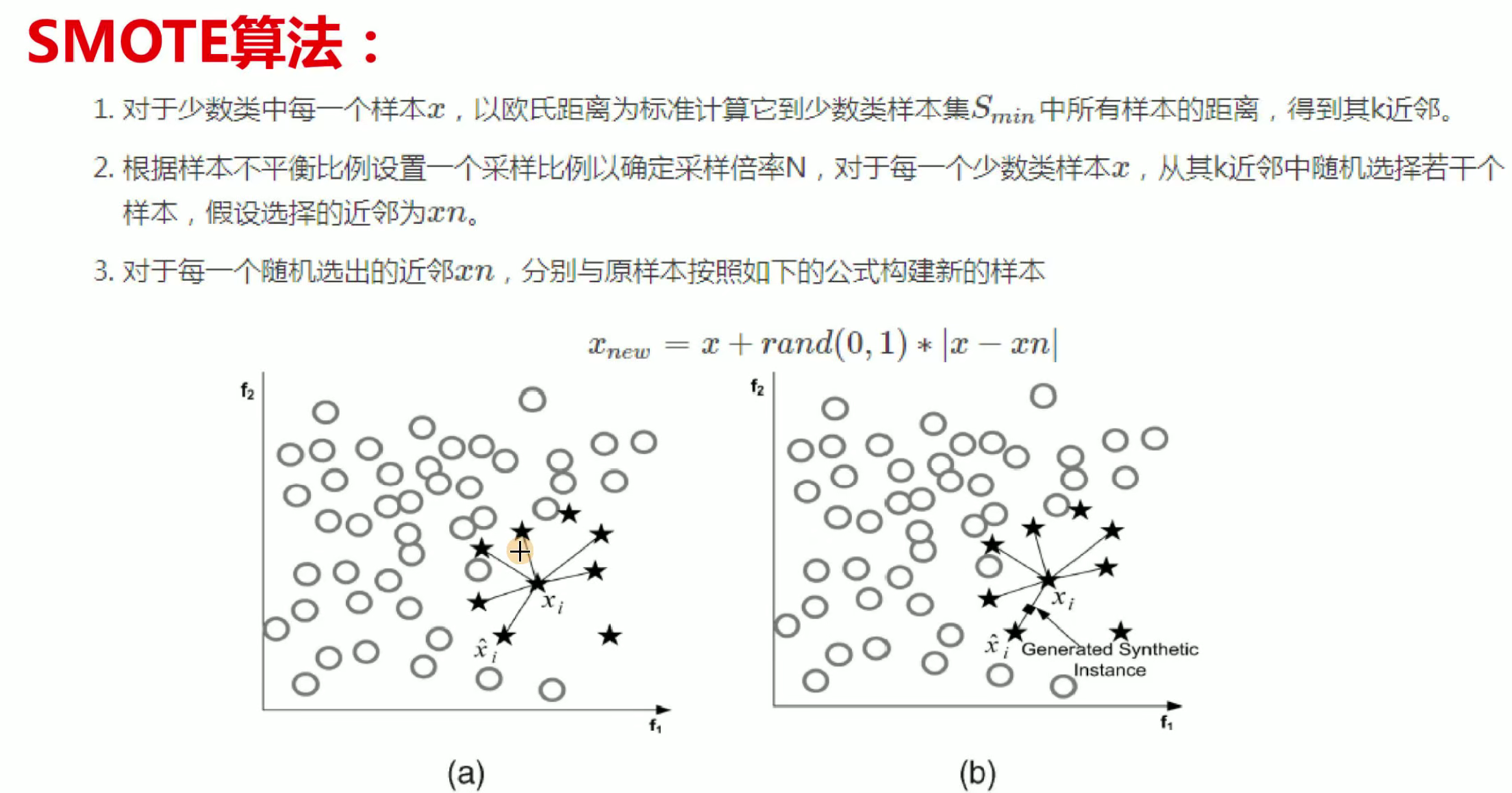
代码部分
from imblearn.over_sampling import SMOTE#imblearn这个库里面调用,
oversampler =SMOTE(random_state=0)#保证数据拟合效果,随机种子
train_X, train_y = oversampler.fit_resample(train_X,train_y)#人工拟合数据主要就是导入库,这个库直接pip下载就行,然后直接fit就行,这里直接导入数据,会自动识别那个多哪个少,然后进行处理。
评价方法
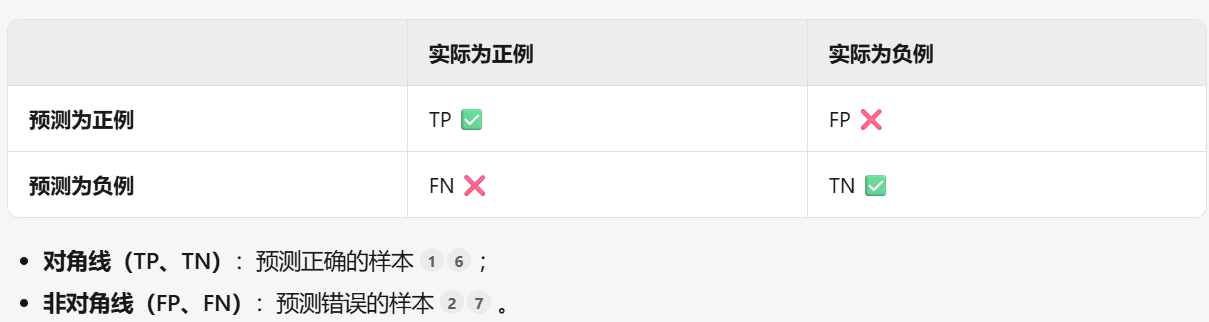
| 指标 | 公式 | 适用场景 | 特点 |
|---|---|---|---|
| 准确率 | 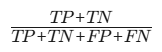 | 类别平衡数据 | 简单直观,但类别不平衡时失效 |
| 精确率 | 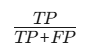 | 关注假阳性成本(如垃圾邮件检测) | 强调预测正例的准确性 |
| 召回率 | 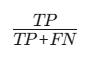 | 关注漏检成本(如疾病诊断) | 强调捕捉正例的能力 |
| F1分数 | 平衡精确率与召回率 | 综合性能指标,适合一般场景 | |
| ROC-AUC | ROC曲线下面积 | 类别不平衡或需调整阈值时 | 反映模型整体排序能力,与阈值无关 |
| 混淆矩阵 | 四格表(TP, FP, FN, TN) | 分析错误类型分布 | 可视化分类细节,衍生多指标 |