蚂蚁开源团队发布的2025大模型开源开发生态发展情况速览
蚂蚁开源团队发布的2025大模型开源开发生态发展情况速览
- 1. 2025大模型开源生态OpenRank Top 20项目
- 2. 大模型开源生态变化趋势分析
- 2.1 模型能力带来的应用重塑、生态位之间的动态博弈
- 2.2 未来七大趋势浮出水面
- 2.2.1 Agent 框架来到下半场
- 2.2.2 AI Coding
- 2.2.3 AI基础设施层
- 2.2.4 大模型训练和推理
- 2.2.5 多模态数据治理技术的演化
- 内容来源:机器之心
5 月 27 日,蚂蚁集团的开源团队发布了一张《2025大模型开源开发生态全景图》这是一张由开源社区数据驱动的技术演进路线图——
- 135 个社区核心项目、19 个技术领域,全面覆盖从智能体应用到模型基建,系统性梳理了开源力量在大模型浪潮下的集结与演化路径。
- 其中,模型训练框架、高效推理引擎、低代码应用开发框架成为当前最具主导力的三条技术赛道。

访问地址:https://antoss-landscape.my.canva.site
完整项目列表和相关数据:https://docs.google.com/spreadsheets/d/1av9kitgnRGtsmDp6AbW96m2cCR4jXZFQmUVG2di8Bjw/edit?gid=0#gid=0
1. 2025大模型开源生态OpenRank Top 20项目
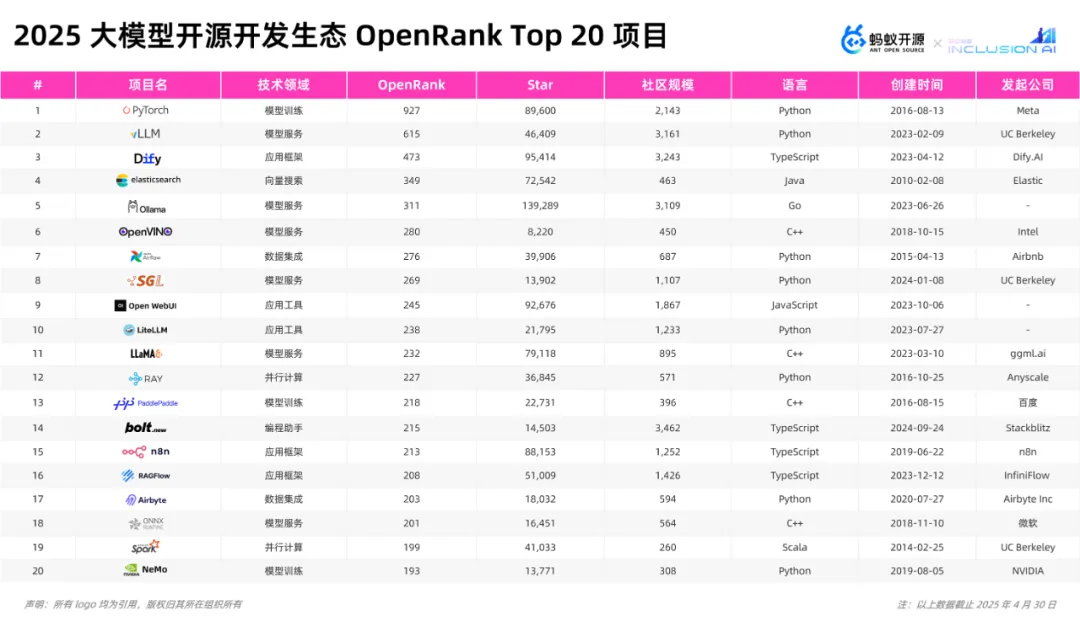
135个项目中位于2025 年 OpenRank 排名Top 20的项目。这里用到了华东师范大学X-lab实验室OpenRank影响力评价指标。
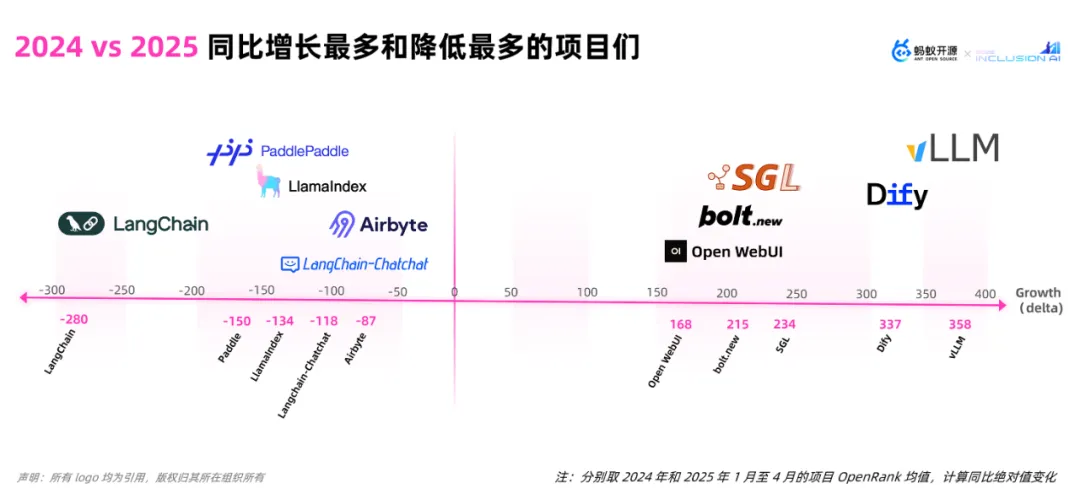
结合前一张图,将 OpenRank 指标与 2024 年数据对比,三大主导技术赛道的同比上升幅度尤为明显。
2. 大模型开源生态变化趋势分析
2.1 模型能力带来的应用重塑、生态位之间的动态博弈
以 AI 搜索为例,开源项目集体式微,并非「做得不够好」,而是 GPT-4、Gemini 们已经将联网检索、答案生成「内嵌进模型」,直接抹平了原有的工具价值。
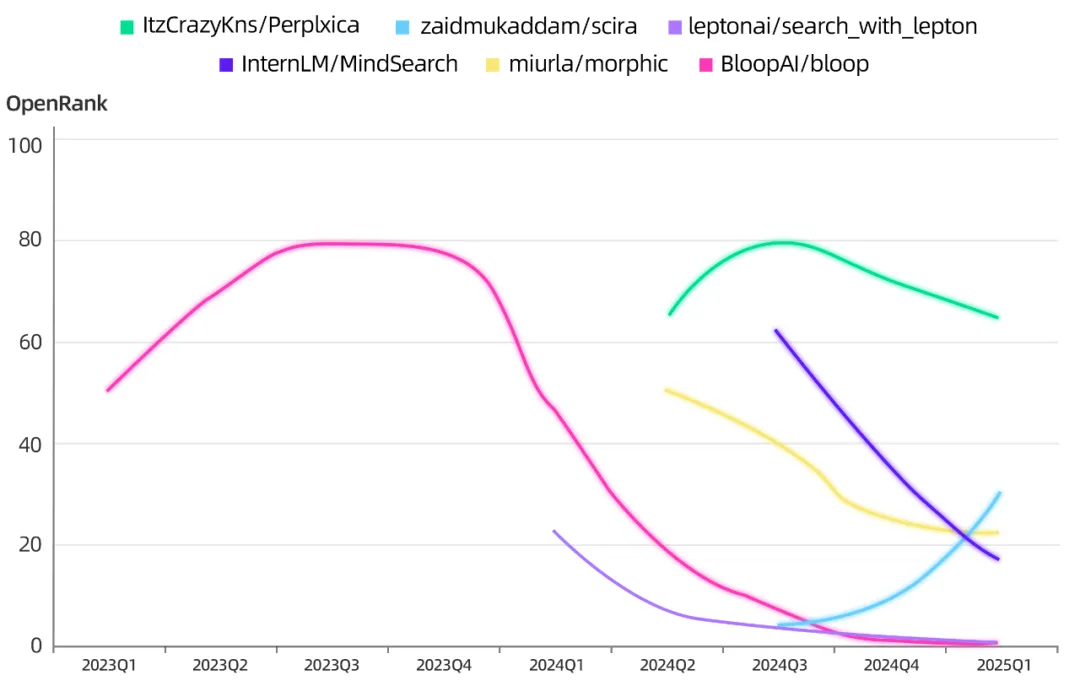
AI Search 开源项目们的 OpenRank 趋势,犹如日落西山
相反,AI Coding 类开源项目则一派繁荣,OpenRank 走势「嘴角上扬」几乎成标配。这一轮热潮的背后,是 Claude 3.7 Sonnet 等大模型在代码生成与代码理解能力上的集体飞跃,直接重构了「人机协作」方式。
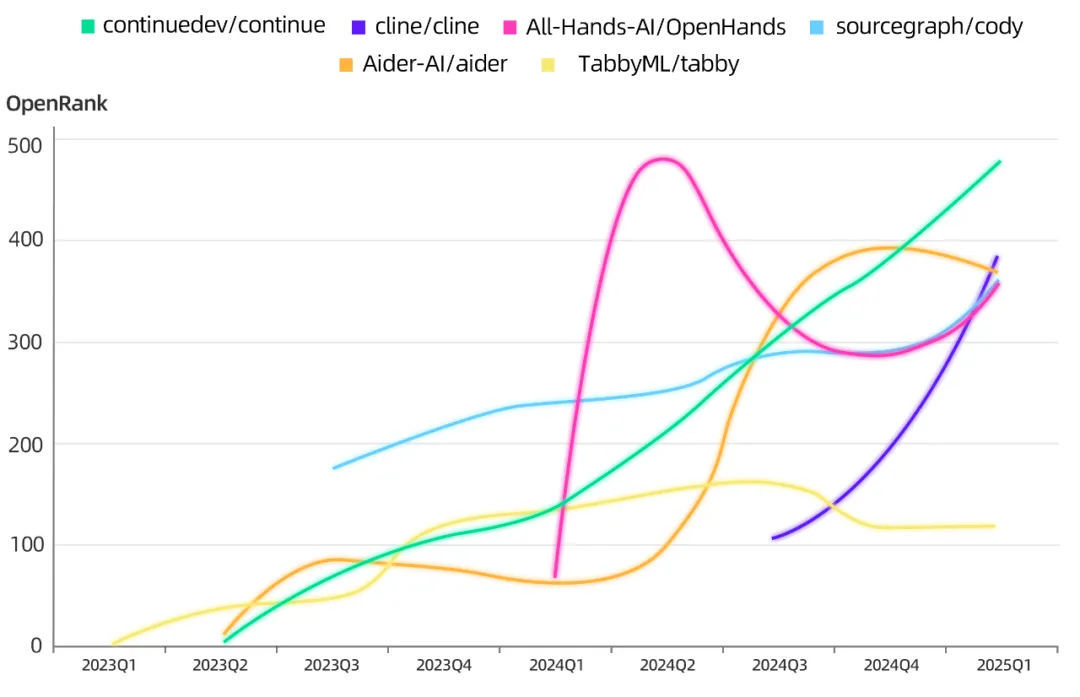
AI Coding开源项目 OpenRank 趋势,几乎个个「嘴角上扬」,蒸蒸日上。
与此同时,生态位之间也在激烈博弈中,变化最剧烈当属 Agent Framework 领域——Dify、n8n、RAGFlow 等低代码平台工具涨幅显著,高达 72.22%;而与此同时,LangChain、LlamaIndex、AutoGen等曾经红极一时的SDK范式整体下滑了 35.90%,跌幅居首。这可能意味着一个转向——从服务开发者「写代码拼接智能体」,转向更注重用户的「可视化、可定制、业务级可落地」的平台产品。
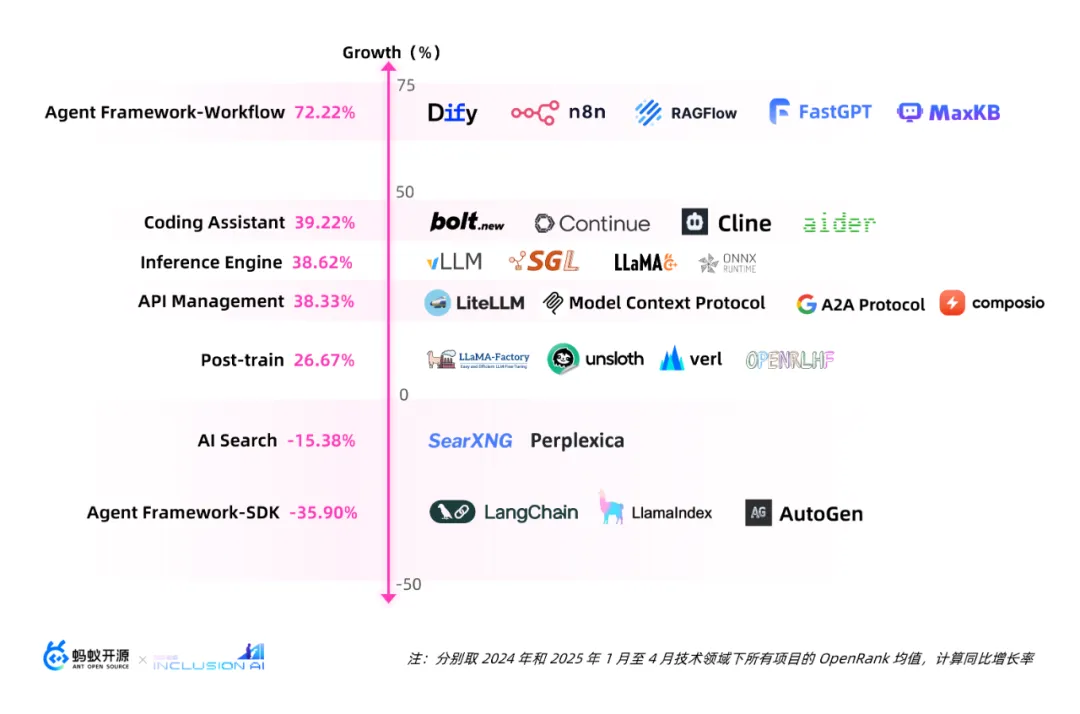
低代码平台跃升至最顶端,而 SDK 范式则集体「下滑到底」。
2.2 未来七大趋势浮出水面
 前三个聚焦智能体应用层,后四个围绕模型基础设施层
前三个聚焦智能体应用层,后四个围绕模型基础设施层
最具体感的趋势都集中在了智能体应用,而且两个都与 Manus 爆火有关。2025年,Agent 框架热潮褪去。从 2024 年下半年开始,LangChain 等早期 SDK 型框架的热度开始「下台阶」式回落,新框架鲜有涌现,开发者重心悄然转移。而到了 2025 年,Dify、RAGFlow 等低代码工作流平台因契合企业需求迅速崛起(也是从中国开发者社区中生长出来的强势项目)。
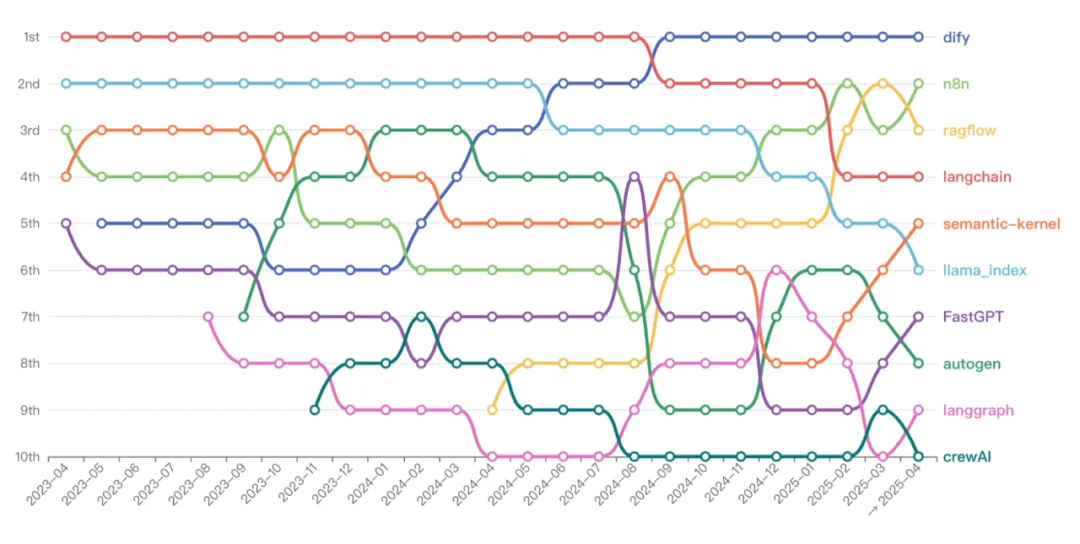
Agent框架OpenRank排名前十的变化
2.2.1 Agent 框架来到下半场
过去两年,「上半场」的主旋律是开发者工具:大模型刚崭露头角,各类框架如 LangChain、AutoGen、LlamaIndex 等纷纷涌现,争相为开发者搭建「脚手架」。随着 Agent 流程逐渐标准化,开发者不再需要五花八门的新框架,在「下半场」,Agent 框架更注重应用场景落地,帮助普通用户完成更复杂任务。当然,解决真实场景的任务时需要强化学习,还面临不少挑战(如奖励设计)。
2025 年低代码平台强势崛起,表明 Agent 框架的竞争从比拼技术范式,走向比拼「谁能更快成为企业的生产力工具」。那些技术节奏稳、商业理解深的开源平台,正乘势成为「 AI 新基建」的领跑者,Dify 就是代表之一。
除了框架圈,Manus 更撬动了「大厂觉醒」,连夜启动配套建设,尤其是标准协议层。
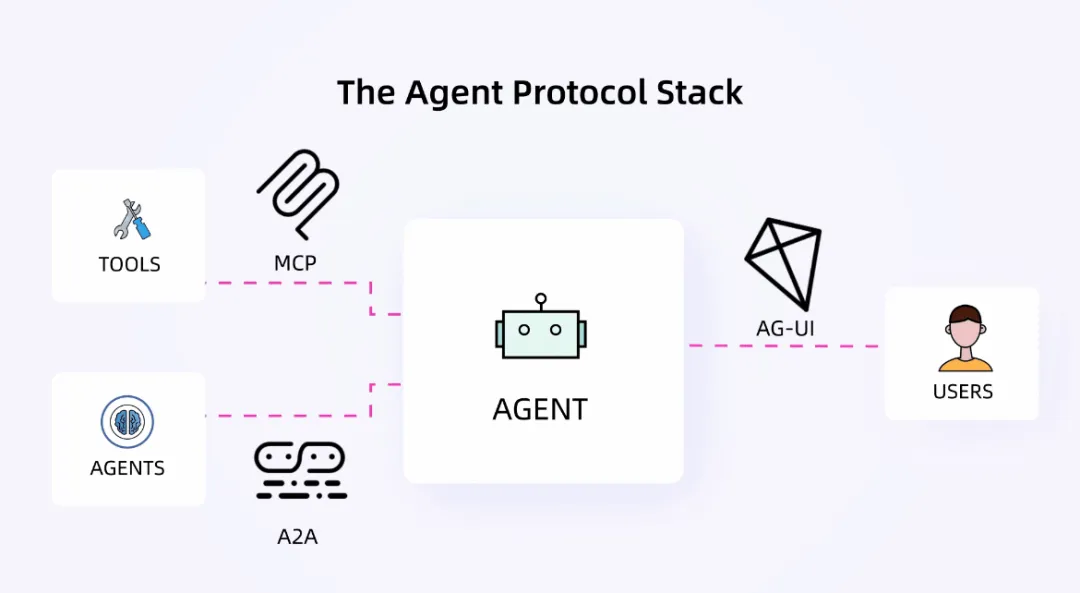
MCP一出,标准协议层正式登场,一键接入,就能组成一个能办事、能协作的 Agent,触达生活的每一个角落。紧接着,Google 在 2025 年开源 A2A( Agent2Agent ) 协议,解决 Agent 之间互操作的问题;CopilotKit 又推出的 AG-UI 协议 进一步打通了智能体后端与前端用户。
开发者们也指出 Agent 间的协作与传统工具调用很不同——它往往是一个持续十几分钟乃至更长的「长程任务」,在执行过程中需要频繁与提供方交互。因此,协议不仅要能传递信息,更要支持任务状态的维护、过程控制和动态交互能力。而目前的 MCP 协议没有涵盖这些能力,A2A 解决的还是「连得上」的问题,「协作」仍是未解之题。这一领域仍有广阔优化空间,也为开源社区留下了巨大的创新机会。
未来需要原生为大模型场景设计的新协议,而在这场技术升级中,开源生态将成为关键阵地。谁能率先定义这些新协议,并将其与工具链(如 SDK、框架)打通,谁就有机会建立自己的技术闭环,抢占「模型即服务( MaaS )」时代的生态制高点。可以预见,未来一到两年,标准协议层将迎来激烈的生态博弈期。
2.2.2 AI Coding
写代码是大模型与生俱来的优势,AI 编程项目确实红火,几乎个个「嘴角上扬」。
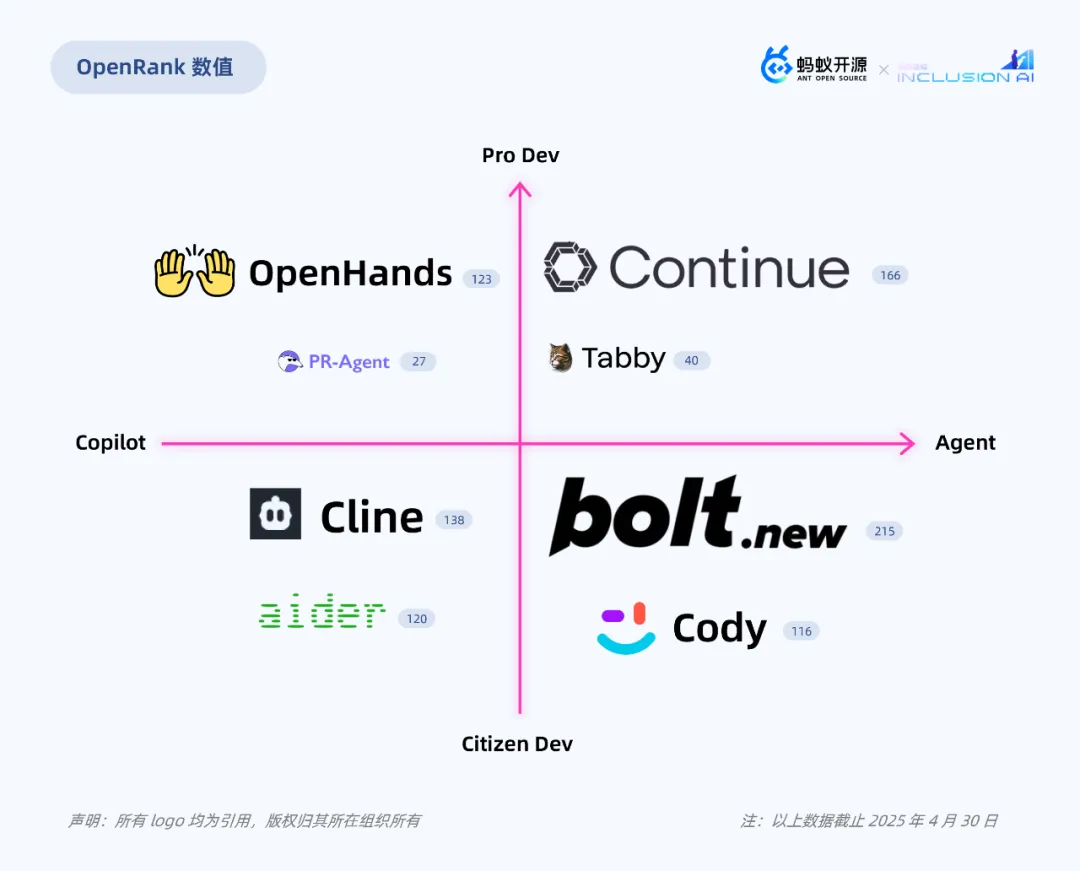
根据项目的智能化程度(辅助还是完全替代?)以及目标受众群体(专业人士还是普通用户?)的专业化程度,将这些 GitHub 上热门的 AI Coding 类开源项目划分为四个象限。
国内百度、阿里、腾讯、蚂蚁、字节等陆续推出 AI 代码助手,率先跑马圈地。AI Coding 也成为开源生态中少数几个不依赖独占数据、也不被私有场景锁死的活跃赛道。
如今,AI 代码助手已深度介入整个软件开发流程:从需求理解、系统设计,到前后端开发、测试调试,再到上线与运维。有意思的是,真正「带它上路」的,是程序员自己。但要说全面替代程序员?还远得很。目前的 AI 编程助手,大致处于「智能辅助驾驶」阶段,能在特定任务上独立作业,比如自动生成前端页面、小程序骨架、测试脚本、代码检查等。
技术演进的关键瓶颈,预测明确指出有两个:一是上下文感知能力( Context-Awareness ),二是领域知识融合( Domain Knowledge Integration )。在未来 24 个月里,AI 助手的「接单能力」会不断增强,但在人机共创的长期范式中,关键决策权,仍牢牢掌握在人类程序员手中。
2.2.3 AI基础设施层
与应用层的「生死时速」不同,一旦「下沉」到基础设施,趋势变化更像是静水深流。有关「向量数据库是不是伪需求」,一直争议不断。从当前的稳定趋势来看,它可能确实是一项真需求。
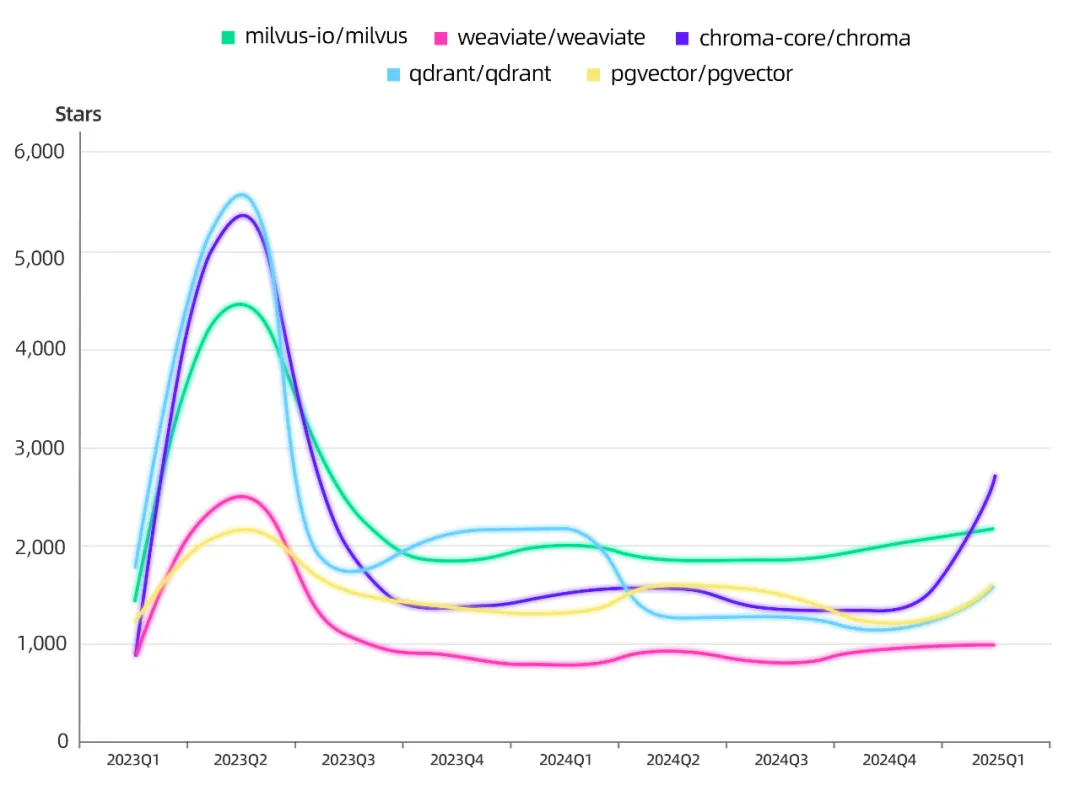
向量数据库的每月 Star 增量变化
对向量数据库来说,短期看是稳定期,但中长期是否能迎来「第二曲线」,还要看 AI 生态新场景的开拓速度。向量数据库不仅是模型应用阶段的「召回引擎」,也正在成为训练流程中的「数据发现器」。 如在自动驾驶场景中,如果模型在「红灯前突然窜出一只狗」这类边缘案例中表现不佳,就需要通过数据回溯找到类似样本,进一步强化训练。但这类数据往往来自非结构化源,如网页爬虫、文本、视频等,难以通过传统标签化方式精准搜集。此时,向量数据库的价值就体现出来了——它能帮助我们高效从海量异构数据中,按语义相似性快速定位相关样本,从而实现更精准的「问题驱动式数据提取」,支持面向真实任务场景的精细化训练。
2.2.4 大模型训练和推理
2023 年以来,出现了一大波面向于模型部署和高效推理的大模型服务工具,在性能和生态上彼此追赶,混战一直持续到今天。眼下,vLLM 与 SGLang 已是当之无愧的「推理顶流」,社区影响力持续扩张。
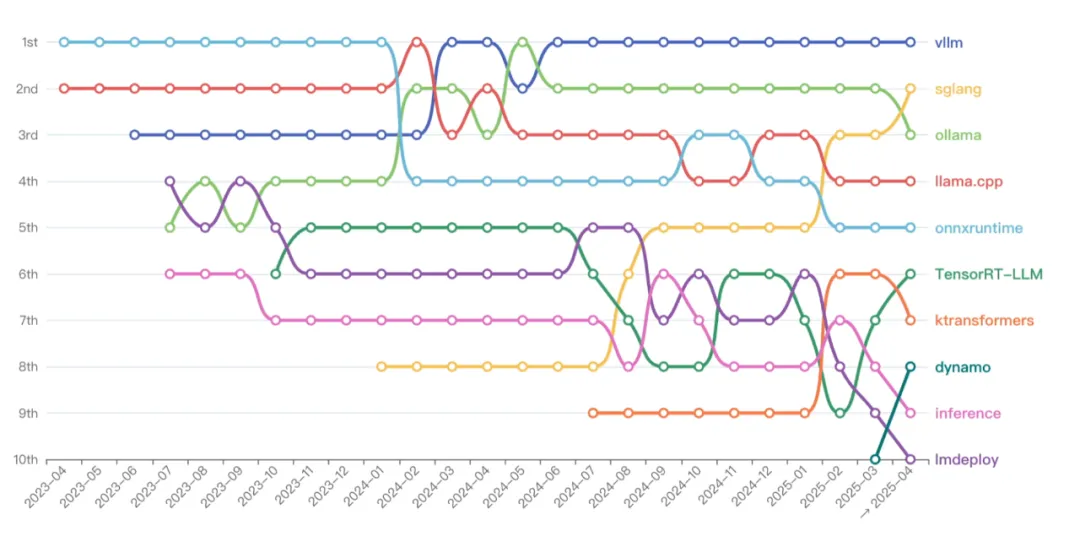
从 Top 10 的模型服务项目的排名变化上来看,仍有新的项目不断冒出来,并吸引开发者参与到其中去。例如去年 7 月清华推出的 KTransformers 和今年 3 月 NVIDIA 推出的 Dynamo。
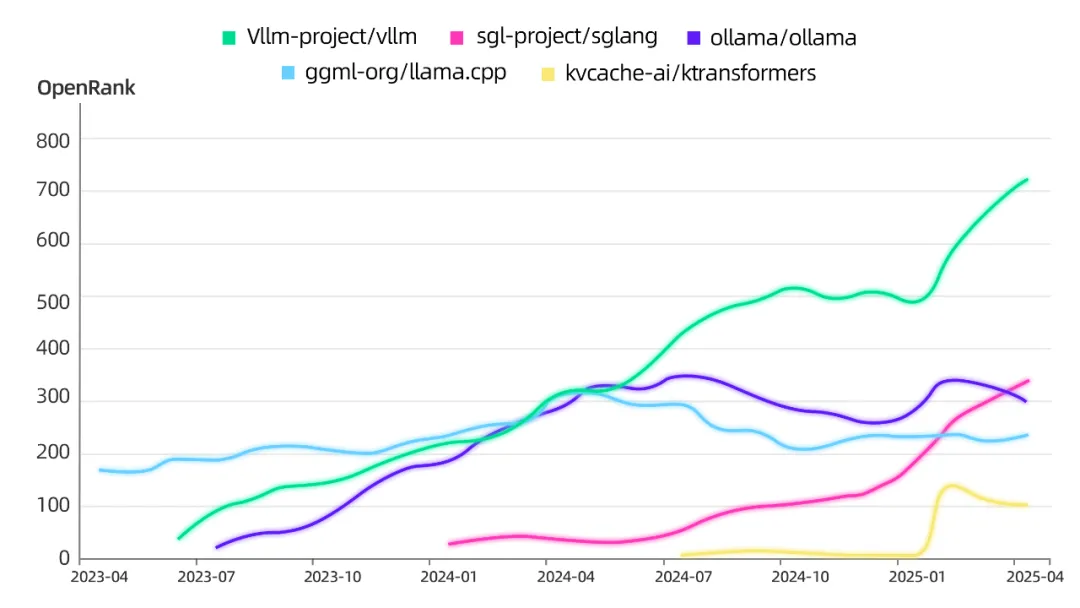
几大模型服务项目的 OpenRank 曲线变化
- 2023 年 6 月,vLLM 首次发布,被视为大语言模型推理的分水岭:在不改动模型结构的前提下,它显著压缩显存占用、提升并发能力,是首个对 LLM 推理进行系统级重构的开源引擎。2025年,vLLM 发布 v1,完成核心架构升级后重回增长通道,依旧是主流部署场景中的首选框架,并具备更强的商业集成度。
- SGLang 属于后者居上—— 2024 年 1 月发布,定位更贴近真实 Agent 应用场景,不仅具备更强的 GPU 并发调度能力,还支持多步推理优化。2025 年一季度,其 OpenRank 增长达 31%,远超同期 vLLM 的 17%。SGLang 也被用于重写 Grok 2 推理技术栈,极大改善了产品体验,甚至获得马斯克的公开点赞。
- 2025 年 2 月,清华大学 KVCache.AI 团队推出的
KTransformers破解千亿级大模型本地部署难题,4090 单卡实现 DeepSeek-R1 满血运行。该项目 OpenRank 飙升 34 倍,吸引 736 名开发者参与协作,GitHub Star 数突破 1 万。看来在大模型时代,哪怕是底层细节的优化,也可能带来「超级红利」
2.2.5 多模态数据治理技术的演化
在多模态数据治理技术的演化上,湖仓「四足鼎立」, 为大模型所依赖的非结构化海量数据提供更强的存储与管理能力。元数据治理也开始拥抱非结构化数据和 AI 资产管理。
不过,Data Infra 发展了二十年,发展得非常完善,有自己的方法论。而多模态原生数据 Infra 才刚刚开始,用新的方式再做一遍时,Data Infra 遭遇过的痛点可能会再度出现。
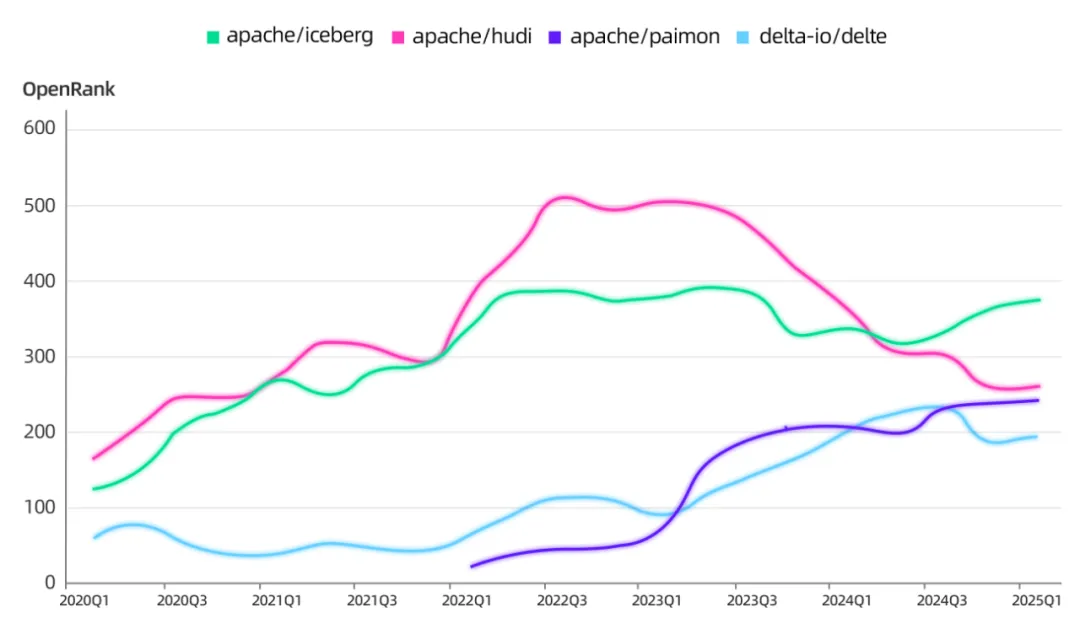
数据湖表格式项目 OpenRank 曲线变化
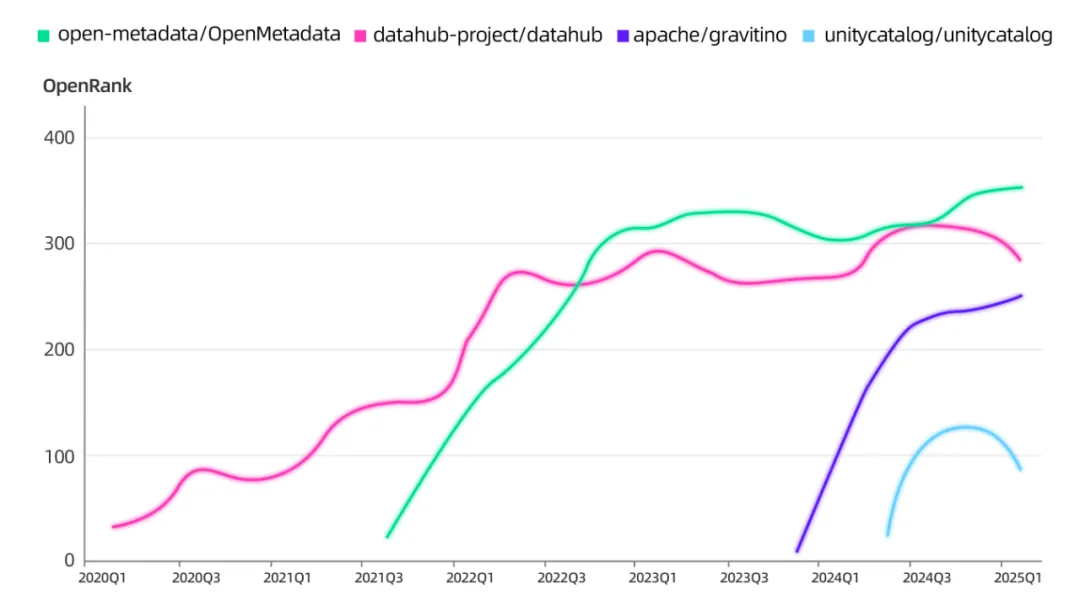
元数据治理项目 OpenRank 曲线变化
OpenRank——由华东师范大学 X-lab 开发的开源影响力指标
内容来源:机器之心
135 个项目、七大趋势、三大赛道:撕开大模型开源生态真相,你会怎么卷?