LLM Prompt与开源模型资源(1)提示词工程介绍
- 学习材料:https://www.hiascend.com/developer/courses/detail/1935520434893606913
- 学习时长: 预计 30 分钟
- 学习目的:
-
- 了解提示工程的定义与作用
-
- 熟悉提示工程的关键技术相关概念
-
- 掌握基于昇腾适配的大模型提示工程的入门及进阶指南
提示词工程介绍
NLP发展的四大范式
NLP(自然语言处理)发展的四大范式通常被概括为:
非神经网络时代的完全监督学习(特征工程):这一范式主要依赖于人工设计的规则或统计模型,需要大量的人工特征工程来完成特定的NLP任务 。
基于神经网络的完全监督学习(架构工程):随着深度学习的发展,开始使用如RNN、CNN等神经网络模型进行NLP任务,这一阶段侧重于模型架构的设计 。
预训练+精调范式(目标工程):利用大规模语料进行预训练,然后针对具体任务对模型进行微调(Fine-tuning)。
预训练+提示+预测范式(Prompting):这是近期兴起的一种范式,通过设计特定的提示(Prompt)来引导预训练模型生成所需的结果,减少了对大量标注数据微调的依赖。
这些范式的演进体现了NLP技术从依赖人工规则和特征,到利用深度神经网络,再到利用大规模预训练模型的发展历程。
什么是 Prompt
在大规模语言模型(LLM, Large Language Models)领域,Prompt 是一种结构化的输入序列,用于引导预训练的语言模型生成预期的输出。它通常包括明确的任务要求、背景信息、格式规定以及示例,以充分利用模型的能力,在特定任务中生成高质量的响应。
Prompt 的核心作用
- 指导模型行为:通过提供清晰的任务描述和上下文,Prompt 告诉模型需要完成什么任务。
- 控制输出质量:通过包含格式规范和示例,Prompt 可以帮助模型生成符合期望的输出。
- 提高模型表现:Prompt 设计得当可以显著提升模型在特定任务中的表现,尤其是在零样本学习(Zero-Shot Learning)或少样本学习(Few-Shot Learning)场景中。
Prompt 的组成要素
- 任务要求:明确告诉模型需要完成的任务,例如“翻译这段文字”、“回答这个问题”等。
- 背景信息:提供与任务相关的上下文或背景知识,帮助模型更好地理解问题。
格式规定:指定输出的格式要求,例如“请用简短的句子回答”、“按照时间顺序排列”等。 - 示例:提供一个或多个示例,展示期望的输入和输出格式,帮助模型理解任务的具体要求。
Prompt 的工作原理
Prompt 被输入到大语言模型中,模型根据 Prompt 中的信息生成相应的输出。以下是其工作流程:
- 输入 Prompt:用户向模型提供一个结构化的输入序列(Prompt),其中包含任务描述、背景信息、格式要求和示例。
- 模型处理:大语言模型根据 Prompt 的内容,结合其预训练的知识和能力,生成符合任务要求的输出。
- 生成文本:模型输出一段文本,作为对 Prompt 的响应。
举例说明:
帮助小学四年级的学生写一篇600字的人工智能介绍

Prompt 怎样发挥作用
Prompt 的作用机制可以分为多个步骤,从输入到最终输出的生成过程。
- 接受输入
- 用户输入 Prompt:用户向大语言模型提供一个结构化的输入序列(Prompt),其中包含任务描述、背景信息、格式要求和示例等。
Prompt 的内容: - 任务要求:明确告诉模型需要完成的任务,例如翻译、问答、摘要等。
- 背景信息:提供与任务相关的上下文或背景知识,帮助模型更好地理解问题。
- 格式规定:指定输出的格式要求,例如“请用简短的句子回答”、“按照时间顺序排列”等。
示例:提供一个或多个示例,展示期望的输入和输出格式,帮助模型理解任务的具体要求。
- 文本处理与编码
- 分词(Tokenization):将 Prompt 中的文本分解为基本单元(tokens)。这些 tokens 可能是单词、子词(subword)、字符或其他单位,具体取决于模型的设计。
- 编码(Encoding):将分词后的 tokens 转换为模型能够理解的数值表示(通常是向量形式)。这个过程通常使用预训练的语言模型中的嵌入层(Embedding Layer)完成。
- 上下文窗口限制:由于大多数大语言模型具有上下文窗口限制(例如 GPT-3 的 2048 tokens 或 GPT-4 的更长上下文窗口),Prompt 的长度需要控制在模型支持的范围内。
- 模型计算
- 输入到模型:经过编码的 Prompt 被输入到大语言模型中。模型是一个深度神经网络,通常基于 Transformer 架构。
自回归生成:大语言模型通常是自回归式的,这意味着它会逐个生成输出 token。模型根据当前已生成的部分输出和输入的 Prompt,预测下一个最可能的 token。 - 注意力机制:Transformer 模型的核心是注意力机制(Attention Mechanism),它允许模型关注输入序列中的不同部分,从而更好地理解和生成输出。
概率分布:在每个时间步,模型会输出一个概率分布,表示每个可能的 token 出现的概率。模型会选择概率最高的 token 作为当前的输出。
- 生成输出
- 逐步生成:模型根据概率分布逐步生成输出 token,直到满足停止条件(例如达到最大长度、生成特殊结束标记等)。
- 输出解码:生成的 token 序列被解码回原始文本形式,形成最终的输出。
- 格式调整与后处理
- 格式调整:根据 Prompt 中的格式要求,对生成的输出进行调整。例如,如果 Prompt 要求输出为列表形式,但模型生成的是连续文本,可能需要手动分割或调整格式。
- 后处理:对输出进行进一步的优化,例如去除重复内容、修正语法错误、调整语气等。
- 质量检查:验证输出是否符合任务要求,必要时可以重新调整 Prompt 或使用其他方法改进结果。
为什么需要提示词工程
Prompt 工程(Prompt Engineering)是通过精心设计和优化 Prompt,以引导大语言模型(LLM)生成高质量、符合预期的输出的过程
1. LLM 的黑盒特性
- LLM 是一个黑盒:尽管大语言模型经过大量数据预训练,具有强大的语言理解和生成能力,但其内部工作机制对于用户来说是不透明的。模型的推理过程是一个复杂的神经网络计算过程,用户无法直接控制或干预。
- 结果依赖于输入:LLM 的输出高度依赖于输入的 Prompt。即使是同一模型,在面对不同的 Prompt 时,可能会生成截然不同的结果。
2. 提高任务完成质量
- 明确任务需求:通过精心设计 Prompt,可以更清晰地传达任务要求,帮助模型更好地理解用户的意图。
- 提供上下文信息:Prompt 可以包含背景知识、示例等上下文信息,为模型提供更多的线索,从而生成更准确、更符合预期的输出。
- 控制输出格式:通过在 Prompt 中指定格式要求(如列表、段落、表格等),可以引导模型生成符合特定格式的输出。
3. 实现零样本学习与少样本学习
- 零样本学习(Zero-Shot Learning):在没有额外训练数据的情况下,通过设计合适的 Prompt,可以让模型直接完成新任务。例如,让模型完成从未见过的任务类型(如翻译、问答、摘要等)。
- 少样本学习(Few-Shot Learning):通过在 Prompt 中提供少量示例,可以显著提升模型在新任务上的表现。这种方法避免了重新训练模型的高昂成本,同时能够快速适应新的应用场景。
4. 不更新模型参数即可调整行为
- 无需重新训练:Prompt 工程的核心优势在于,它可以在不更新模型参数的前提下,通过调整 Prompt 来改变模型的行为。这对于大规模语言模型尤为重要,因为重新训练这些模型的成本极高(计算资源、时间、资金等)。
- 灵活性强:通过调整 Prompt,可以快速适应不同的任务需求,而无需对模型本身进行修改。
5. 改善用户体验
- 定制化输出:通过优化 Prompt,可以生成更加个性化、符合用户需求的输出。例如,根据用户的偏好调整语气、风格、内容深度等。
- 减少试错成本:精心设计的 Prompt 可以显著提高模型的首次响应质量,减少用户反复尝试的次数,提升整体使用体验。
以下是一个具体的例子,说明 Prompt 工程的重要性:
场景:生成旅行攻略
- 原始 Prompt:
我想去杭州玩,请帮我做一份攻略。

-
问题:输出较为笼统,缺乏具体细节(如行程安排、预算、推荐景点的价格等)。
-
优化后的 Prompt:
我想去杭州玩,请综合考虑为我做一份旅行攻略。请注意,我们从北京出发,行程5天,旅行人数3人,有一名2岁小孩,我不太喜欢行程太紧凑,希望包含吃穿住行四个方面内容,预算1万元。推荐的景点请附上价格以及最佳订票时间。

改进:输出更加详细、个性化,充分考虑了用户的行程安排、预算限制、家庭成员情况等,提供了更具实用价值的信息。
完整回答:chat.qwen.ai/s/d13f90f2-2443-4b10-9420-33ae40e895ac?fev=0.0.166
Prompt 典型应用场景
Prompt 的典型应用场景
Prompt 是一种强大的工具,广泛应用于自然语言处理(NLP)和图像生成等领域。通过精心设计的 Prompt,可以引导模型完成各种复杂任务,并生成高质量的输出
1. 自然语言处理领域
在自然语言处理领域,Prompt 主要用于指导大语言模型完成特定的语言相关任务。以下是一些典型应用场景:
(1) 文本生成
- 任务描述:根据给定的提示词或上下文,生成符合要求的文本内容。
- 应用场景:
- 故事创作:例如,“请续写一个关于未来世界的科幻故事,主角是一名年轻的科学家。”
- 新闻撰写:例如,“根据以下事件摘要,撰写一篇新闻报道:某城市发生地震,造成多人伤亡。”
- 邮件撰写:例如,“请帮我写一封感谢信,感谢客户对我们的支持。”
(2) 翻译
- 任务描述:将一种语言的文本翻译成另一种语言。
- 应用场景:
- 多语言支持:例如,“请将这段英文翻译成中文:The quick brown fox jumps over the lazy dog.”
- 实时翻译:例如,在跨语言交流中,使用 Prompt 实现即时翻译。
(3) 问答系统
- 任务描述:根据问题生成准确的答案。
- 应用场景:
- 知识检索:例如,“请问巴黎圣母院的历史背景是什么?”
- 客服机器人:例如,“如何更换手机号码?”
(4) 摘要生成
- 任务描述:从长文本中提取关键信息,生成简洁的摘要。
- 应用场景:
- 新闻摘要:例如,“请为以下新闻文章生成一段50字的摘要。”
- 学术论文摘要:例如,“请为这篇研究论文生成一份简短的摘要。”
(5) 文本分类
- 任务描述:根据文本内容将其归类到特定的类别。
- 应用场景:
- 情感分析:例如,“请判断以下评论的情感倾向:正面、负面或中性。”
- 主题分类:例如,“请将这篇文章归类为科技、娱乐或体育。”
(6) 代码改写与解释
- 任务描述:根据代码片段生成解释或改写代码。
- 应用场景:
- 代码解释:例如,“请解释以下代码的功能:
for i in range(len(arr)): arr[i] += 1” - 代码优化:例如,“请将这段代码改写为更高效的版本。”
- 代码解释:例如,“请解释以下代码的功能:
(7) 对话系统
- 任务描述:模拟人类对话,生成连贯的回复。
- 应用场景:
- 虚拟助手:例如,“你好,我想预订一张明天去北京的机票。”
- 聊天机器人:例如,“今天天气怎么样?”
(8) 创意写作
- 任务描述:根据提示生成创意性的文本内容。
- 应用场景:
- 诗歌创作:例如,“请写一首关于秋天的五言绝句。”
- 剧本创作:例如,“请为一部电影编写一个开头场景。”
2. 图像领域
在图像生成和处理领域,Prompt 也被广泛应用于指导模型完成特定任务。以下是一些典型应用场景:
(1) 图像生成
- 任务描述:根据文本描述生成相应的图像。
- 应用场景:
- 艺术创作:例如,“生成一幅描绘森林中的精灵跳舞的图像。”
- 广告设计:例如,“生成一张展示现代办公室环境的图片。”
(2) 风格转换
- 任务描述:将图像转换为特定的艺术风格。
- 应用场景:
- 艺术效果:例如,“将这张照片转换为梵高的《星夜》风格。”
- 复古效果:例如,“将这张照片添加复古滤镜,使其看起来像老照片。”
(3) 图像编辑
- 任务描述:根据提示修改图像中的某些元素。
- 应用场景:
- 背景替换:例如,“将这张照片中的背景替换为海滩。”
- 人物修饰:例如,“将照片中的人物头发颜色改为金色。”
(4) 自动标注
- 任务描述:根据图像内容生成标签或描述。
- 应用场景:
- 图像分类:例如,“这张图片的内容是什么?”
- 目标检测:例如,“请标记出图像中的所有行人。”
(5) 视频生成
- 任务描述:根据文本描述生成视频内容。
- 应用场景:
- 动画制作:例如,“生成一段描述太空探险的动画视频。”
- 虚拟现实:例如,“根据用户输入的场景描述生成虚拟现实内容。”
3. 其他领域
除了 NLP 和图像领域,Prompt 还可以应用于其他领域,例如:
(1) 数据分析
- 任务描述:根据数据生成报告或分析结果。
- 应用场景:
- 财务分析:例如,“根据这份财报,生成一份年度财务总结。”
- 市场调研:例如,“根据调查数据,生成一份市场趋势分析报告。”
(2) 游戏开发
- 任务描述:生成游戏脚本、情节或角色对话。
- 应用场景:
- 剧情生成:例如,“生成一个冒险游戏的开场情节。”
- NPC 对话:例如,“为游戏角色设计一段对话。”
(3) 教育
- 任务描述:生成教学材料或练习题。
- 应用场景:
- 课程设计:例如,“根据这个主题,生成一份适合初中生的学习计划。”
- 习题生成:例如,“生成10道关于代数的练习题。”
(4) 医疗
- 任务描述:根据医学数据生成诊断报告或治疗建议。
- 应用场景:
- 病例分析:例如,“根据患者的病历,生成一份初步诊断报告。”
- 药物推荐:例如,“根据患者症状,推荐合适的药物。”
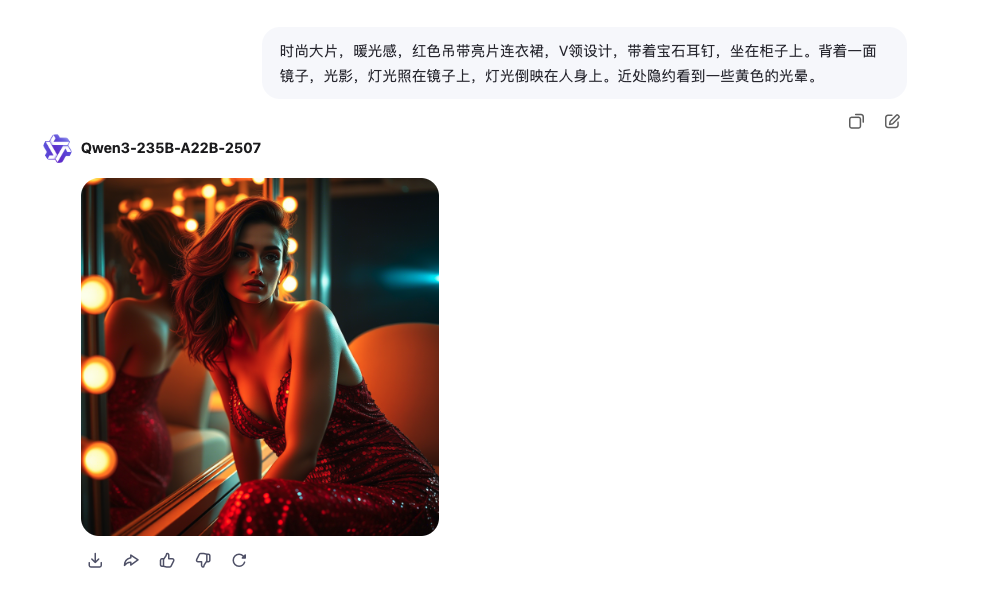
最后以一个文生图结束今天的学习:
时尚大片,暖光感,红色吊带亮片连衣裙,V领设计,带着宝石耳钉,坐在柜子上。背着一面镜子,光影,灯光照在镜子上,灯光倒映在人身上。近处隐约看到一些黄色的光晕。