Linux文件系统:从内核到缓冲区的奥秘
目录
一:理解一切皆文件
二:缓冲区
2.1什么是缓冲区
2.2为什么要引入缓冲区机制
2.3缓冲类型
2.4文件内核级缓冲区
2.5FILE
一:理解一切皆文件
首先,在windows中是文件的东西,它们在linux中也是文件;其次⼀些在windows中不是文件的东 西,比如进程、磁盘、显示器、键盘这样硬件设备也被抽象成了文件,你可以使用访问文件的方法访问它们获得信息;甚止是管道,也是文件。 这样做最明显的好处是,开发者仅需要使一套API和开发工具,即可调取Linux系统中绝大部分的资源。
举个简单的例子,Linux中几乎所有读(读文件,读系统状态,读PIPE)的操作都可以用read函数来进行;几乎所有更改(更改文件,更改系统参数,写PIPE)的操作都可以用write函数来进行。 之前我们讲过,当打开⼀个文件时,操作系统为了管理所打开的文件,都会为这个文件创建⼀个file结 构体,该结构体定义在 /usr/src/kernels/3.10.0- 1160.71.1.el7.x86_64/include/linux/fs.h 下,以下展示了该结构部分我们关系的内容:
struct file
{...struct inode *f_inode; /* cached value */const struct file_operations *f_op;...atomic_long_t f_count; // 表⽰打开⽂件的引⽤计数,如果有多个⽂件指针指向它,就会增加f_count的值。unsigned int f_flags; // 表⽰打开⽂件的权限fmode_t f_mode; // 设置对⽂件的访问模式,例如:只读,只写等。所有的标志在头⽂件<fcntl.h> 中定义loff_t f_pos; // 表⽰当前读写⽂件的位置...} __attribute__((aligned(4)));
/* lest something weird decides that 2 is OK*/值得关注的是 struct file 中的 f_op 指针指向了⼀个 file_operations 结构体,这个结构 体中的成员除了struct module* owner 其余都是函数指针。该结构和 struct file 都在fs.h下。
一张图总结:
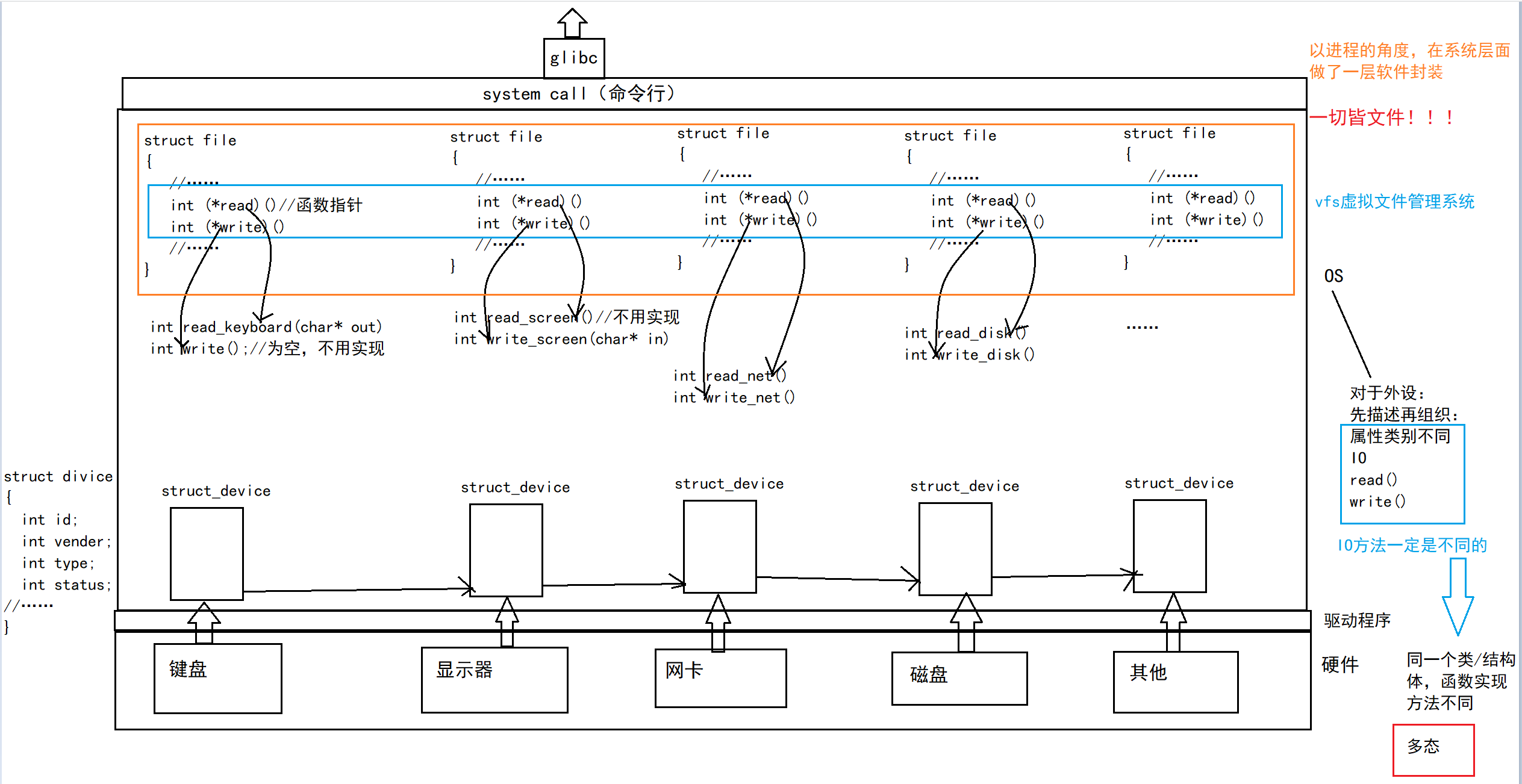
上图中的外设,每个设备都可以有自己的read、write,但一定是对应着不同的操作方法!!但通过 struct file 下 file_operation 中的各种函数回调,让我们开发者只用file便可调取 Linux系统中绝大部分的资源!!这便是“linux下⼀切皆文件”的核心理解。
为什么语言喜欢做封装?(文本写入 VS 二进制写入 )例如C++/C语言
好处:1.方便用户操作
2.提高用户的可移植性
二:缓冲区
2.1什么是缓冲区
缓冲区是内存空间的⼀部分。也就是说,在内存空间中预留了⼀定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区
2.2为什么要引入缓冲区机制
读写文件时,如果不会开辟对文件操作的缓冲区,直接通过系统调用对磁盘进行操作(读、写等),那么每次对文件进行一次读写操作时,都需要使⽤读写系统调用来处理此操作,即需要执行一次系统调用,执行一次系统调用将涉及到CPU状态的切换,即从用户空间切换到内核空间,实现进程上下文的切换,这将损耗一定的CPU时间,频繁的磁盘访问对程序的执行效率造成很大的影响。
为了减少使用系统调用的次数,提高效率,我们就可以采用缓冲机制。比如我们从磁盘里取信息,可以在磁盘文件进行操作时,可以⼀次从文件中读出大量的数据到缓冲区中,以后对这部分的访问就不 需要再使用系统调用了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数, 再加上计算机对缓冲区的操作快于对磁盘的操作,故应用缓冲区可大大提高计算机的运行速度。
又比如,我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和高速的CPU能够协调⼯作,避免低速的输⼊输出设备占用CPU,解放出CPU,使其能够高效率工作。
2.3缓冲类型
标准I/O提供了3种类型的缓冲区。
1.全缓冲区:这种缓冲方式要求填满整个缓冲区后才进行I/O系统调用操作。对于磁盘文件的操作通常使用全缓冲的方式访问。
2.行缓冲区:在行缓冲情况下,当输入和输出中遇到换行符时,标准I/O库函数将会执行系统调用操作。当所操作的流涉及⼀个终端时(例如标准输入和标准输出),使用行缓方式。因为标准 I/O库每行的缓冲区长度是固定的,所以只要填满了缓冲区,即使还没有遇到换行符,也会执行 I/O系统调用操作,默认行缓冲区的大小为1024。
3.无缓冲区:无缓冲区是指标准I/O库不对字符进行缓存,直接调用系统调用。标准出错流stderr通 常是不带缓冲区的,这使得出错信息能够尽快地显示出来。
除了上述列举的默认刷新方式,下列特殊情况也会引发缓冲区的刷新:
1. 缓冲区满时; 2. 执行flush语句; 3. 进程结束
int main()
{close(1);int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);if(fd < 0){perror("open");return 1;}printf("hello fd : %d\n",fd);close(fd);return 0;
}
我们本来想使用重定向思维,让本应该打印在显示器上的内容写到“log.txt”文件中,但我们发现, 程序运行结束后,文件中并没有被写入内容:
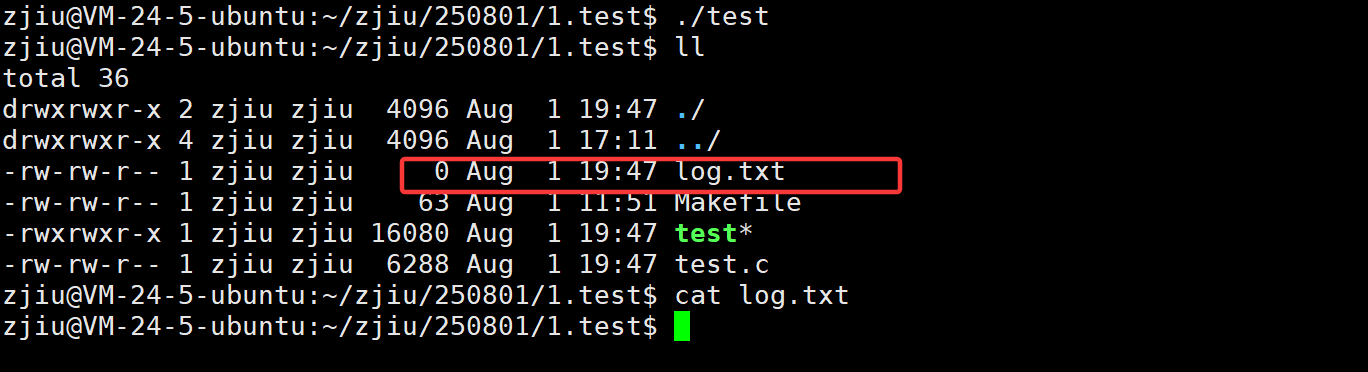
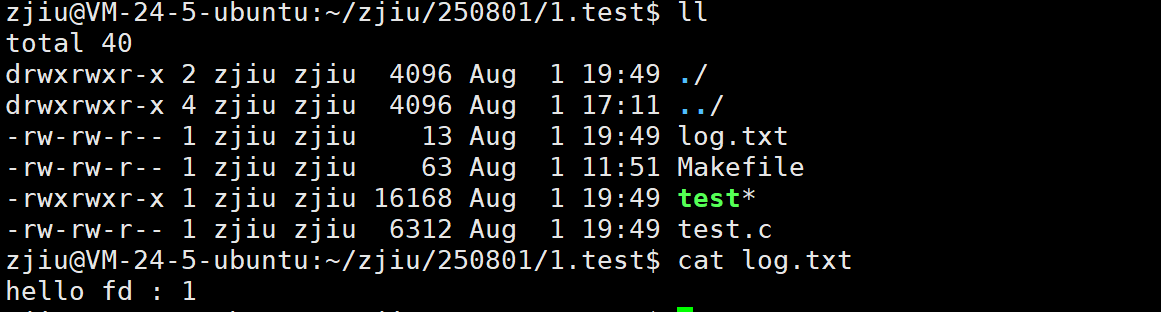
这是由于我们将1号描述符重定向到磁盘文件后,缓冲区的刷新方式成为了全缓冲。而我们写入的内容并没有填满整个缓冲区,导致并不会将缓冲区的内容刷新到磁盘文件中。怎么办呢?可以使用fflush强 制刷新下缓冲区。
int main()
{close(1);int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);if(fd < 0){perror("open");return 1;}printf("hello fd : %d\n",fd);fflush(stdout);close(fd);return 0;
}
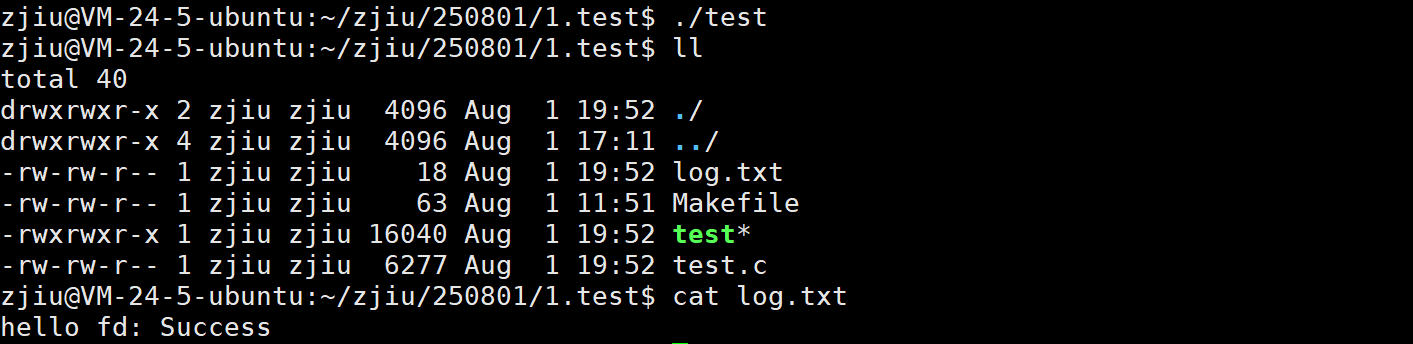
还有⼀种解决方法,刚好可以验证一下stderr是不带缓冲区的,代码如下 :
int main()
{close(1);int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);if(fd < 0){perror("open");return 1;}perror("hello fd");close(fd);return 0;
}
2.4文件内核级缓冲区
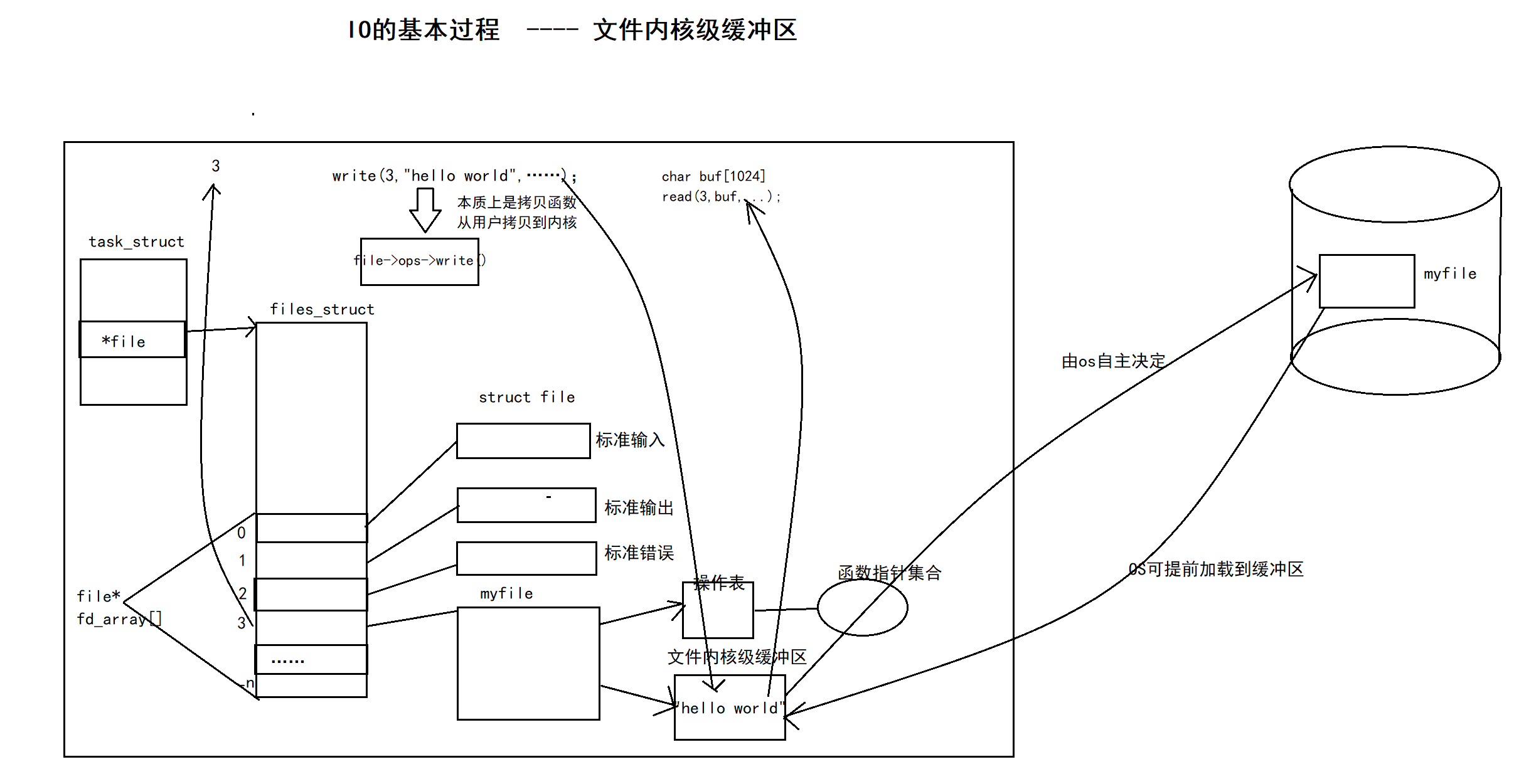
1.写入:通过fd = 3,在task_struct中file*指向的数组中,找到下标为3的对应文件,根据write函数,把内容从用户拷贝到文件缓冲区,什么时候加载到磁盘由OS自主决定
2.读取:OS可提前将磁盘中的文件内容加载到对应文件的缓冲区中,根据fd找到对应的文件,根据read函数,把缓冲区中对应的内容写入对应位置
3.修改:先读取,再修改,再写入修改后的内容
为什么要存在缓冲区?
将内容加载到外设,过程十分缓慢,消耗时间,利用缓冲区将一段内容加载到外设,可以提高效率
2.5FILE
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通 过fd访问的。上面已经通过代码验证了,C库当中的FILE结构体内部,封装了fd。
int main()
{const char *msage0 = "hello printf\n";const char *msage1 = "hello fwrite\n";const char *msage2 = "hello write\n";printf("%s",msage0);fwrite(msage1,strlen(msage1),1,stdout);write(1,msage2,strlen(msage2));fork();return 0;
}

但如果对进程实现输出重定向呢? ./test > file ,我们发现结果变成了:
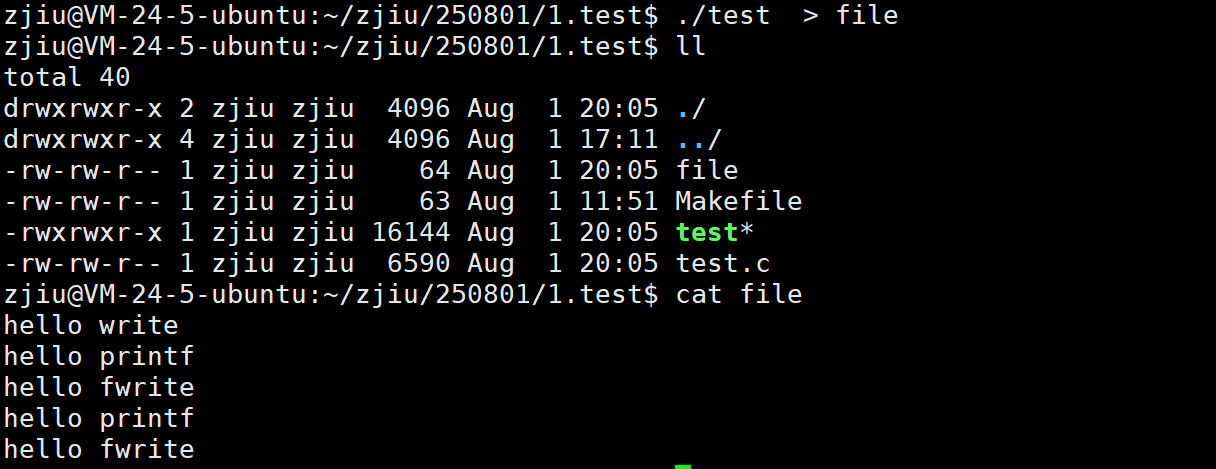
我们发现 printf 和 fwrite (库函数)都输出了2次,而write 只输出了⼀次(系统调用)。为什么呢?肯定和fork有关!
⼀般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
printf fwrite 库函数会自带缓冲区(前面制作进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。
而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后
但是进程退出之后,会统⼀刷新,写入文件当中。
但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的⼀份数据,随即产生两份数据。
write 没有变化,说明没有所谓的缓冲。
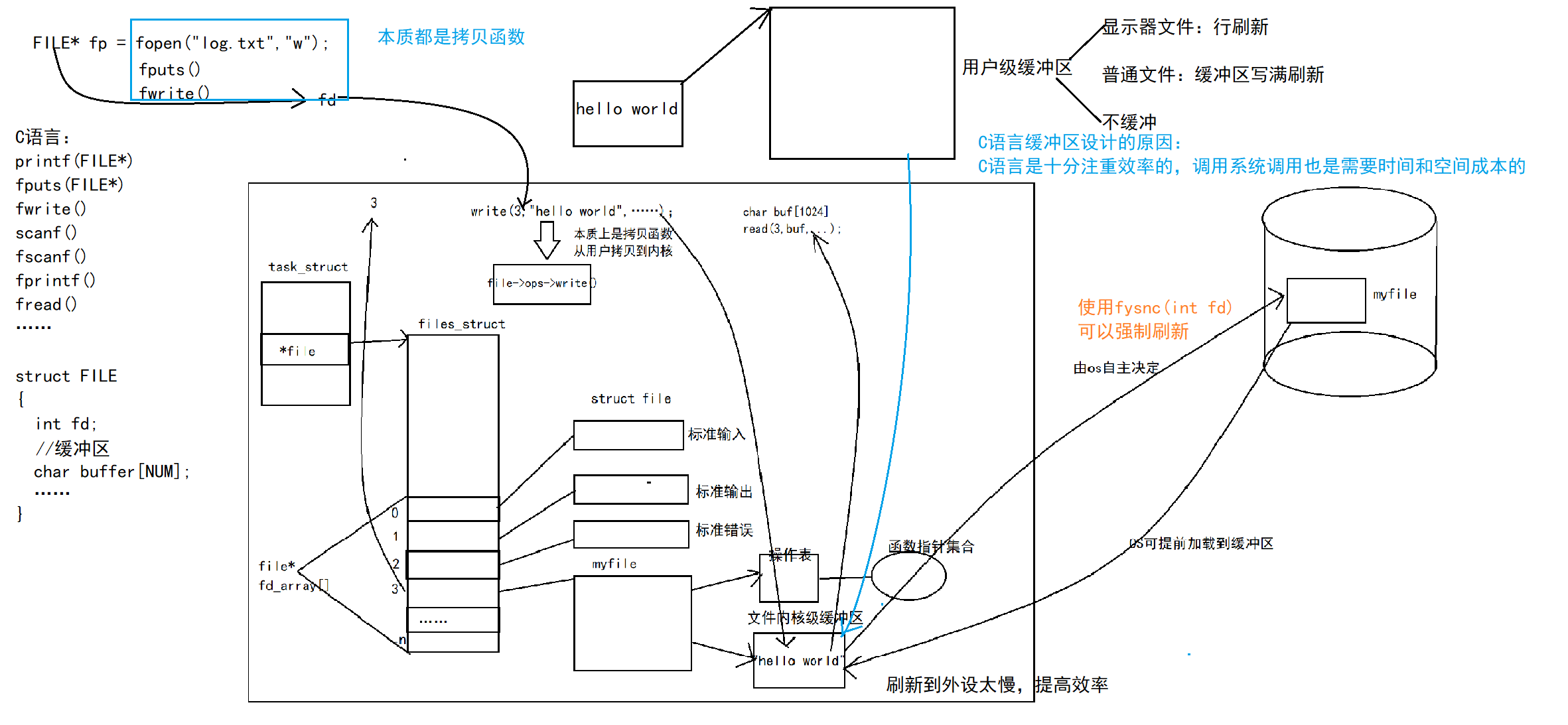
综上: printf fwrite 库函数会自带缓冲区,而write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区,都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不再我们讨论范围之内。
那这个缓冲区谁提供呢? printf fwrite 是库函数, write 是系统调用,库函数在系统调用的“上层”,是对系统调用的“封装”,但是 write 没有缓冲区,而printf fwrite 有,足以 说明,该缓冲区是二次加上的,又因为是C,所以由C标准库提供。