【AI论文】具备测试时扩散能力的深度研究者
摘要:基于大语言模型(Large Language Models, LLMs)的深度研究智能体正迅速发展;然而,当使用通用测试时扩展算法生成复杂的长篇研究报告时,其性能往往趋于平稳。受人类研究迭代特性的启发——人类研究包含搜索、推理和修订的循环过程,我们提出了测试时扩散深度研究者(Test-Time Diffusion Deep Researcher, TTD-DR)框架。这一新颖框架将研究报告的生成概念化为一个扩散过程。TTD-DR以初步草稿开启该过程,这份可更新的草稿框架作为一个不断演变的基础,为研究方向提供指引。随后,草稿通过“去噪”过程进行迭代优化,该过程由检索机制动态提供信息,检索机制在每一步都融入外部信息。通过将自进化算法应用于智能体工作流程的每个组件,核心过程得到进一步增强,确保为扩散过程生成高质量的上下文信息。这种以草稿为中心的设计使报告撰写过程更加及时、连贯,同时减少了迭代搜索过程中的信息丢失。我们在一系列需要密集搜索和多跳推理的基准测试中证明,我们的TTD-DR取得了最优成果,显著优于现有的深度研究智能体。Huggingface链接:2507.16075,论文链接:2507.16075
研究背景和目的、研究方法、研究结果、研究局限及未来研究方向总结
一、研究背景和目的
研究背景
随着大型语言模型(LLMs)的快速发展,深度研究智能体(Deep Research Agents, DR Agents)在科研和工业界得到了广泛关注。这些智能体能够自动生成新想法、有效搜集信息并执行分析或实验,从而辅助撰写研究报告或论文。然而,现有的DR智能体在生成复杂且长篇的研究报告时,性能往往会遇到瓶颈,尤其是在需要密集搜索和多跳推理的任务中,表现不尽如人意。
当前大多数DR智能体采用通用的测试时扩展算法,如Chain-of-Thought(CoT)、best-of-n采样、蒙特卡洛树搜索(MCTS)等,但这些方法往往缺乏人类认知行为的系统性设计,特别是在处理复杂研究任务时,缺乏一个结构化的草稿、搜索和反馈机制。因此,如何设计一个能够有效模拟人类研究过程的DR智能体,成为了一个亟待解决的问题。
研究目的
本研究旨在提出一个名为测试时扩散深度研究者(Test-Time Diffusion Deep Researcher, TTD-DR)的新颖框架,以解决现有DR智能体在生成复杂长篇研究报告时的性能瓶颈问题。具体目标包括:
- 模拟人类研究过程:通过引入草稿生成、迭代优化和自进化算法,模拟人类研究的迭代特性,包括搜索、推理和修订。
- 提高报告生成质量:通过“去噪”过程和动态信息检索机制,提高生成报告的准确性和全面性。
- 减少信息丢失:在迭代搜索过程中保持上下文连贯性,减少信息丢失。
- 超越现有基准:在多个基准测试中证明TTD-DR的性能优于现有DR智能体。
二、研究方法
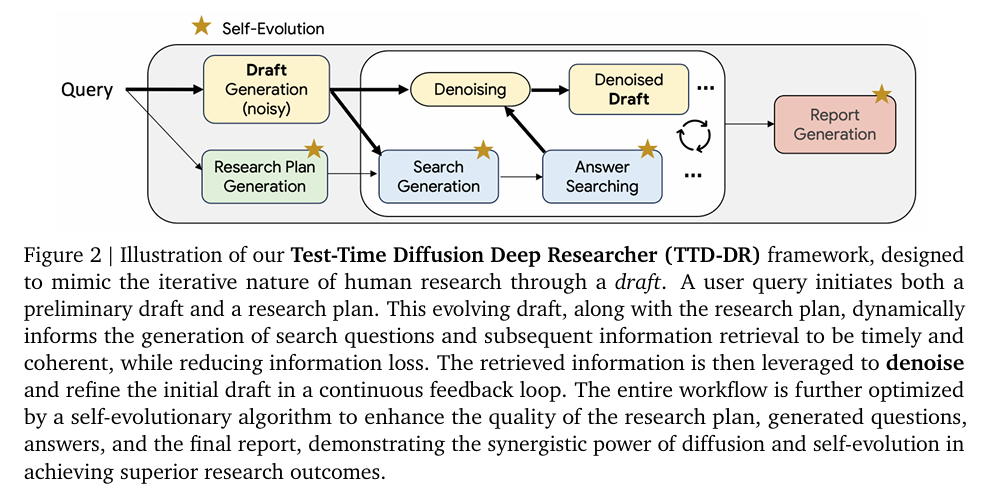
1. 框架设计
TTD-DR框架的核心在于将研究报告的生成视为一个扩散过程,并引入以下关键机制:
- 初步草稿生成:基于用户查询生成一个初步草稿,作为后续研究和修订的基础。
- 迭代优化(去噪):通过“去噪”过程迭代优化草稿,每一步都融入外部信息,由检索机制动态提供。
- 自进化算法:应用于智能体工作流程的每个组件,确保为扩散过程生成高质量的上下文信息。
2. 具体实现
2.1 骨干DR智能体
TTD-DR的骨干DR智能体由三个主要阶段组成:
- 研究计划生成:生成一个详细的研究计划,概述最终报告的结构,指导信息搜索过程。
- 迭代搜索与综合:通过循环工作流程生成搜索问题,并使用RAG系统从检索到的文档中综合精确答案。
- 最终报告生成:综合所有收集到的信息,生成全面且连贯的最终报告。
2.2 组件级自进化
自进化算法受近期自进化工作启发,通过生成多个初始状态的变体,并让每个变体与环境交互获得适应度分数和反馈,然后进行修订。这一过程重复多次,直到达到最大迭代次数,最后将多个修订后的变体合并,生成最终的高质量输出。
2.3 报告级去噪与检索
受扩散模型采样过程启发,TTD-DR引入了一个去噪与检索机制。初步草稿作为“噪声”起点,通过动态融入外部信息的检索机制进行迭代优化。每一步生成的搜索问题都基于当前草稿和研究计划,检索到的信息用于修订草稿,从而逐步“去噪”。
三、研究结果
1. 性能比较
在多个基准测试中,TTD-DR显著优于现有DR智能体:
- LongForm Research和DeepConsult:在需要生成长篇综合报告的任务中,TTD-DR的获胜率分别达到69.1%和74.5%,显著优于OpenAI Deep Research。
- HLE-Search和GAIA:在需要多跳搜索和推理的任务中,TTD-DR的准确率分别提高了4.8%、7.7%和1.7%。
2. 消融研究
通过消融研究,验证了TTD-DR各组件的贡献:
- 骨干DR智能体:相较于仅使用LLM和搜索工具的基线,性能显著提升。
- 自进化算法:进一步提高了搜索问题和答案的复杂性,丰富了收集到的信息,从而提高了最终报告的质量。
- 去噪与检索:相较于自进化算法,去噪与检索在早期搜索阶段更有效地利用了信息,从而在较少的搜索步骤内达到了更高的性能。
3. 评估指标
使用Helpfulness、Comprehensiveness和Correctness等评估指标,结合人类评估和LLM-as-a-judge自动评估,全面评估了TTD-DR的性能。实验结果表明,TTD-DR在这些指标上均优于现有DR智能体。
四、研究局限
尽管TTD-DR在多个基准测试中取得了显著成果,但仍存在以下局限:
- 工具集成有限:当前工作主要关注搜索工具的使用,未集成其他工具如浏览和编码,未来需探索这些工具的集成以进一步增强DR智能体的性能。
- 智能体调优未探索:本研究聚焦于测试时计算扩展,未涉及智能体调优,未来工作可探索通过训练来改进DR智能体。
- 特定领域适应性:尽管TTD-DR在多个领域表现出色,但在某些特定领域或复杂任务中的适应性仍需进一步验证。
五、未来研究方向
1. 工具集成与扩展
未来工作应探索集成更多工具,如网页浏览、代码执行等,以进一步增强DR智能体的信息搜集和分析能力。这将有助于处理更复杂的研究任务,提高报告的全面性和准确性。
2. 智能体调优与训练
尽管测试时计算扩展在提高DR智能体性能方面表现出色,但通过训练来进一步优化智能体仍是一个值得探索的方向。未来工作可探索使用强化学习、多任务学习等方法来训练DR智能体,以提高其自主学习和适应能力。
3. 特定领域定制化
针对不同领域和任务需求,定制化开发TTD-DR框架的变体,以提高其在特定场景下的性能和适应性。例如,在生物医学、金融等领域开发专门的DR智能体,以满足这些领域对高精度和全面性的要求。
4. 交互性与用户反馈
增强DR智能体的交互性,允许用户在研究过程中提供反馈和指导,从而进一步优化研究路径和报告生成质量。通过结合人类专家的知识和经验,DR智能体可以生成更加符合需求的研究报告。
5. 可解释性与透明度
提高DR智能体的可解释性和透明度,使其生成的研究报告更加可信和可靠。通过可视化工具和技术,展示DR智能体在研究过程中的决策依据和推理路径,有助于用户更好地理解和评估报告的质量。
结论
本研究提出了测试时扩散深度研究者(TTD-DR)框架,通过模拟人类研究的迭代特性,有效解决了现有DR智能体在生成复杂长篇研究报告时的性能瓶颈问题。实验结果表明,TTD-DR在多个基准测试中显著优于现有DR智能体,展示了其卓越的性能和潜力。未来工作将进一步探索工具集成、智能体调优、特定领域定制化等方向,以推动DR智能体技术的不断发展和应用。