机械学习--逻辑回归
进过前几天的学习,我们已经对机械学习的K近邻算法,线性回归算法有了详细的了解,并且熟悉如何用代码来实现便捷计算
接下来,我们将开始我们的第三个算法的学习----逻辑回归
1、基础概念
1.1、什么是逻辑回归
逻辑回归(Logistic Regression)是一种用于分类问题的统计模型。它通过建立一个逻辑函数模型来预测某个事件属于某一类的概率,通常用于二元分类问题。逻辑回归输出的是概率值,值域介于0到1之间。模型最终通过设定一个阈值(如0.5),将连续的概率值转换为离散的分类标签(如0或1)。
逻辑回归的核心在于使用Sigmoid函数(逻辑函数)来将线性组合的结果映射为一个概率值。其公式如下:
![]()
1.2、逻辑回归与线性回归的区别
尽管逻辑回归与线性回归都属于回归模型,但它们在用途和方法上有显著区别:
-
输出类型不同:
- 线性回归:用于连续变量预测,其输出是一个连续值(例如房价预测)。
- 逻辑回归:用于分类问题,其输出是一个概率值,通常用于二分类(例如预测邮件是否为垃圾邮件)。
-
目标函数不同:
- 线性回归:目标是最小化残差平方和(Ordinary Least Squares, OLS)。
- 逻辑回归:目标是最小化对数似然函数,通过最大化似然函数估计模型参数。
-
模型输出的范围:
- 线性回归的预测结果可以为负数或超出常规范围。
- 逻辑回归通过Sigmoid函数将结果限制在0到1之间,作为概率值。
-
适用场景:
- 线性回归适用于预测连续变量(如销量、温度等)。
- 逻辑回归适用于二分类或多分类问题(如疾病诊断、信用卡欺诈检测)。
1.3应用场景
逻辑回归广泛应用于需要分类的领域,尤其是二分类问题。以下是常见应用场景:
- 医学领域:用于预测患者是否患某种疾病(如预测心脏病发作的风险)。
- 金融领域:用于信用评分、贷款违约预测、欺诈检测等场景。
- 市场营销:用于客户分类(如预测用户是否会购买产品)、客户流失分析等。
- 社交媒体:用于垃圾邮件分类、用户行为预测等。
- 风险管理:评估企业或个人在未来发生风险事件的可能性。
逻辑回归在这些领域因其解释性强、计算效率高、且易于实现,被广泛采用。
2、逻辑回归模型
2.1、模型定义
逻辑回归是一种用于二分类问题的统计模型,旨在预测某个事件发生的概率。模型假设因变量 y yy 是二元的(即y ∈ { 0 , 1 } y \in \{0, 1\}y∈{0,1}),并通过输入变量(特征)x xx的线性组合来估计事件属于某一类别的概率。模型的形式为:
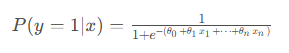
用更简洁的符号表示为:
![]()
其中:
- P ( y = 1 ∣ x ) 是事件y = 1 y=1y=1的概率。
是需要估计的模型参数。
是输入特征。
- 逻辑回归通过极大似然估计来估计模型参数。
2.2、Sigmoid函数
Sigmoid函数(也称为逻辑函数)是逻辑回归的核心,用来将线性回归模型的输出映射为一个0到1之间的概率。其数学表达式为:
其中,是输入变量的线性组合。
Sigmoid函数的输出在0到1之间,表示事件发生的概率。它具有以下特性:
- 当 z 非常大时,
接近1;
- 当z 非常小时,
- 当
时,
。
这种性质使得Sigmoid函数非常适合用于二分类问题中的概率预测。
2.3、决策边界
决策边界是逻辑回归模型用于划分类别的阈值,通常为0.5。根据Sigmoid函数的性质,逻辑回归模型通过设定一个阈值来判断输入数据属于哪一类。
h θ ( x ) h_\theta(x)hθ(x) 是逻辑回归模型的预测函数,它基于输入特征$ x $ 和模型参数$ \theta $ 来预测样本属于正类(例如,标签为1)的概率。在逻辑回归中,这个预测函数通常采用Sigmoid函数,其数学表达式如下:
这里,θ T x \boldsymbol{\theta}^T xθTx 表示参数向量 θ \boldsymbol{\theta}θ 和特征向量 x xx 的点积,即:
其中,是偏置项(bias term),
n是样本的特征值。注意:特征是x ,特征值是
。
Sigmoid函数将任意实数值映射到(0, 1)区间内,这使得h θ ( x ) h_\theta(x)hθ(x)的输出可以被解释为样本属于正类的概率。在二分类问题中,我们通常将这个概率与一个阈值(如0.5)进行比较,以决定最终的分类结果:
- 如果
,则预测样本属于正类(标签为1)。
- 如果
,则预测样本属于负类(标签为0)。
这种基于概率的预测方法不仅提供了分类结果,还给出了分类的置信度,这在许多应用场景中是非常有用的。例如,在医学诊断中,我们可能更关心测试结果的置信度,而不仅仅是一个简单的是或否的答案。
2.4、概率解释
逻辑回归的输出是事件发生的概率,而不是直接的分类标签。输出概率可以解释为某个事件属于类1的可能性。例如:
- 若
,表示在给定输入特征 x xx 的情况下,事件 y = 1发生的概率为80%。
- 若
,则表示事件 y = 1发生的概率为20%。
这一概率解释是逻辑回归的一个重要特点,它不仅给出一个分类结果,还提供了分类的置信度,从而能够在决策过程中提供更多信息。例如,在某些应用中,可以根据应用场景调整决策阈值,而不仅仅依赖默认的0.5阈值。
3、模型训练
3.1、损失函数
在逻辑回归中,模型通过最大化训练数据的似然函数来估计参数。由于直接最大化似然函数在数学上不方便处理,通常会最小化负的对数似然函数,也称为交叉熵损失。
对于逻辑回归,似然函数定义为给定输入特征x xx 和对应标签y yy,模型预测所有样本的概率的乘积。假设有n nn个样本,定义如下:
其中:是第 i 个样本的预测概率。
为了便于优化,我们通常采用负对数似然作为损失函数,公式为:
其中,是样本
属于正类的概率。
解释:
- 对于每个样本,损失函数根据预测结果与实际标签之间的差距计算“损失”。如果模型预测得越接近实际标签,损失越小,反之则损失越大。
- 优化目标是找到参数θ \thetaθ使损失函数J ( θ ) J(\theta)J(θ) 最小。
公式推导:
-
公式(1):
对于二项分布公式,可以得出:
所以:
对它求对数,得到对数似然函数:
l ( θ ) l(\theta)l(θ)可以作为逻辑回归的损失函数,但当损失函数是一个凸函数时,具备最小值。所以设定
,即
3.2、梯度下降法
梯度下降法(Gradient Descent)是逻辑回归模型中常用的优化算法之一,用于最小化损失函数,找到能够最小化损失函数的参数值β \betaβ。其基本思想是沿着损失函数的负梯度方向更新模型参数,逐步接近最优解。
梯度下降法的参数更新公式为:
其中:
是模型的第j jj 个参数。
是学习率(步长),控制每次更新的幅度。
是损失函数关于参数
每次迭代时,模型的参数根据损失函数的梯度进行调整,直到损失函数收敛到最小值。
优化过程:
-
计算梯度:
计算损失函数关于所有参数的梯度:
将其转换成向量的形式:
其中:
X XX 是包含所有样本特征的矩阵,θ \boldsymbol{\theta}θ 是参数向量,h θ ( X ) h_\theta(X)hθ(X)是所有样本的预测概率向量,Y YY是所有样本的实际标签向量
因为θ和x维度相同,所以当x 有m 维的时候,θ 同样有m维,此时的求导也变成了对θ的每一个维度求导:
-
更新参数:
接下来,我们根据梯度和学习率α \alphaα来更新每个参数。学习率是一个超参数,它控制了每次更新参数时步长的大小。参数更新的公式为:
-
重复迭代:
我们重复步骤1和2,直到满足某个停止条件。停止条件可以是:
- 梯度足够小,即
小于一个预设的阈值。
- 达到最大迭代次数。
- 损失函数的值不再显著下降。
- 梯度足够小,即
伪代码:
# 初始化参数
theta = np.array([0.0, 0.0, 0.0]) # 包括偏置项theta_0
# 设置学习率和迭代次数
alpha = 0.01
iterations = 1000
# 特征矩阵X和标签向量Y
X = np.array([[1, 1, 2], [1, 2, 3], [1, 3, 4], [1, 4, 5]]) # 添加偏置项
Y = np.array([0, 1, 1, 0])
# 梯度下降
for i in range(iterations): # 预测 predictions = 1 / (1 + np.exp(-np.dot(X, theta))) #np.dot(X, theta)计算了特征矩阵X和参数向量theta的点积,得到每个样本的线性组合。然后,对这个线性组合取负值,通过np.exp计算其指数,得到一个接近0或正无穷的值。# 计算梯度 gradient = np.dot(X.T, (predictions - y)) / len(y) #(predictions - y)计算了预测概率和实际标签之间的差异。然后,np.dot(X.T, ...)将这个差异与特征矩阵X的转置相乘,得到梯度向量# 更新参数 theta -= alpha * gradient
# 输出最终的参数
print(theta)
3.3、牛顿法
梯度下降法实现相对简单,但其收敛速度较慢。在较小值附近,梯度下降法会以一种曲折的慢速方式来逼近最小点,此时可以考虑采用牛顿法和拟牛顿法。
1. 牛顿法:
牛顿法通过使用二阶导数(即 Hessian 矩阵)来找到损失函数的最小值。更新公式为:
其中:
- H 是 Hessian 矩阵,表示损失函数的二阶导数。
是损失函数的梯度。
表示第k 次迭代时的参数向量
牛顿法通常收敛速度更快,因为它利用了二阶信息,可以更精确地找到损失函数的最优解。然而,计算 Hessian 矩阵在高维数据上代价较高,因此牛顿法更适用于中小型数据集。
公式推导:
在泰勒展开式中,对于函数f ( x ) f(x)f(x),当x xx在x 0 x_0x0附近时可以使用如下展开式来逼近f ( x ) f(x)f(x):
在牛顿法中,我们使用逐步逼近的方法来求解参数θ \thetaθ。这里我们用下标k kk标识在第k kk步的诸标量值。例如,用表示第k 步的θ 值。在第k 步,我们有当前估计
,就可以将f ( θ ) (损失函数)用在其在
处的二阶泰勒展开式来近似:
这里:
是一个标量,表示函数在
- ∇ f ( θ k ) \nabla f(\theta_k)∇f(θk) 是 f ff 在θ k \theta_kθk 处的梯度,是一个 n nn 维向量。
- 它由函数 f 在点
- 具体来说,如果
是一个 n维向量,那么梯度
的偏导数组成的向量。
- 梯度向量的每个分量定义如下:
- 它由函数 f 在点
这里,每个分量 )表示函数 f 在点
处对第 i 个变量
的偏导数。
是f在
矩阵。
- 它的构成基于函数 f 在点
- 具体来说,如果 f 是一个 n 变量的函数,那么黑塞矩阵
这意味着黑塞矩阵的主对角线上的元素是函数对每个变量的二阶偏导数,而非对角线元素则是混合偏导数。由于混合偏导数的等价性(克莱罗定理),黑塞矩阵是对称的,即
- 它的构成基于函数 f 在点
- θ是我们要求解的向量。
- 是当前的估计向量。
- θ −
在牛顿法中,我们希望找到下一个点,使得
尽可能小。所以对
进行求导,并将导数置为0:
解上述方程得到:
由于是一个方阵,我们可以将两边乘以
的逆矩阵:
因此:
将 θ \thetaθ更新为θ k + 1 \theta_{k+1}θk+1:
2. 逻辑回归的牛顿法求解
梯度:
海森矩阵:
其中:S 为对角矩阵,其第i 个对角元素为。对于一个包含m 个样本的数据集,S 的矩阵形式是:
牛顿法的迭代步骤
-
初始化参数:选择初始参数
,通常设为 0 向量。
-
计算预测概率:根据当前参数 θ ,计算预测的概率
。
-
计算梯度和 Hessian:
-
计算梯度
-
计算 Hessian 矩阵
,其中 S 为对角矩阵。
-
-
更新参数:根据牛顿法的公式更新参数:
-
检查收敛:判断参数更新后的变化量
是否小于设定的阈值
,如果是,则停止迭代,否则返回步骤 2 继续迭代。
-
输出结果:当满足收敛条件时,输出最优的参数 θ 。
在实践中,由于黑塞矩阵 H ( θ ) 是正定的,它的逆可以保证存在,并且这个更新公式可以有效地用于求解逻辑回归问题。然而,计算黑塞矩阵及其逆在计算上可能很昂贵,特别是对于大型数据集。因此,通常使用更高效的优化算法,如梯度下降法或拟牛顿法。
3.4、拟牛顿法
由于牛顿法需要计算海森矩阵的逆,因此计算量较大。随着未知数维度D DD的增大,海森矩阵(D × D D\times DD×D)也会增大,需要的存储空间增多,计算量增大,有时候甚至会大到不可计算。
拟牛顿法(Quasi-Newton Methods)是一类用于求解无约束优化问题的迭代方法,它是对经典牛顿法的改进。与牛顿法不同,**拟牛顿法不需要直接计算 Hessian 矩阵的逆,而是通过逐步构造近似 Hessian 矩阵的方式来进行优化。**这使得拟牛顿法在高维问题中更加高效,且减少了计算成本。
**BFGS(Broyden-Fletcher-Goldfarb-Shanno)**方法是拟牛顿法中的一种常用算法,用于解决无约束优化问题。它通过迭代逐步逼近目标函数的Hessian矩阵,避免了直接计算Hessian矩阵的复杂性,并保持较高的收敛效率。以下是BFGS方法的关键原理和步骤。
1.基本思想
BFGS方法的核心在于利用迭代过程中得到的梯度信息,逐步更新近似的Hessian矩阵 B k B_kBk(或它的逆矩阵),而不是显式计算目标函数的Hessian矩阵。每次迭代时,更新的近似矩阵能够反映目标函数的局部曲率,从而加速收敛。
2.BFGS算法步骤
2.1 初始条件
- 初始点 θ 0 \theta_0θ0。注:这里的θ 0 \theta_0θ0不是值,是θ \thetaθ初始化时的向量
- 初始Hessian矩阵的逆矩阵 D 0 D_0D0(通常选择为单位矩阵)
- 设定收敛容差ϵ
2.2 迭代步骤
-
计算搜索方向:
在每次迭代中,计算当前迭代点的搜索方向 $ p_k $:
其中:是近似的Hessian矩阵的逆矩阵。该搜索方向通常是下降方向。
-
线搜索:
进行线搜索的目的是寻找合适的步长
,以确保在每次迭代中沿着当前的搜索方向p k p_kpk 进行更新时,目标函数
取得充分的下降。
其中:步长
-
更新参数:
计算两个向量:- 梯度变化量 y k y_kyk:
- 位置变化量 s k s_ksk:
- 位置变化量 s k s_ksk:
- 梯度变化量 y k y_kyk:
-
更新近似的Hessian矩阵的逆矩阵
根据以下更新公式更新 $该公式能保持
的正定性和对称性,同时逐步逼近真实的Hessian矩阵。
-
判断收敛:
若梯度的范数小于设定的收敛容差 ϵ ,则迭代终止;否则继续进行下一次迭代。
3.L-BFGS:BFGS的改进版本
在处理大规模问题时,BFGS方法由于需要存储和更新完整的Hessian矩阵,可能会消耗过多内存。为此,引入了L-BFGS(Limited-memory BFGS)方法,它只存储少量的历史信息,用于更新Hessian矩阵的近似,显著减少了内存需求,适用于大规模优化问题。
3.4、正则化
正则化是一种防止模型过拟合的技术。过拟合是指模型在训练数据上表现良好,但在新数据上表现较差。通过在损失函数中加入正则项,可以对模型参数施加约束,避免过拟合。
-
L1正则化(Lasso):
L1正则化通过在损失函数中加入模型参数的绝对值之和来约束参数。L1正则化的损失函数为:其中,λ \lambdaλ是正则化系数,控制正则化的强度。
效果:L1正则化会将一些不重要的参数缩小到零,从而进行特征选择,使模型稀疏化。
-
L2正则化(Ridge):
L2正则化通过在损失函数中加入参数平方之和来约束参数。L2正则化的损失函数为:效果:L2正则化将较大的参数缩小,但不会将参数缩小到零,因此它有助于防止模型过度复杂化,而不会完全消除某些特征。
-
Elastic Net:
Elastic Net 是 L1 和 L2 正则化的组合,它结合了两者的优点,既能实现稀疏化,又能防止过拟合。其损失函数为:其中,
和
控制 L1 和 L2 正则化的强度。
3.5、总结
- 对数似然损失 是逻辑回归的核心损失函数,它通过最大化数据的似然来估计模型参数。
- 梯度下降法 是常用的优化方法,适用于大规模数据集。
- 牛顿法 和 拟牛顿法 提供了更快的收敛速度,适用于较小规模的数据集。
- 正则化 技术(L1、L2)可以防止过拟合,并帮助模型提高泛化能力。