当文档包含图文混排表格时,如何结合大模型(如DeepSeek-VL)和OCR提取数据
从金融研报、市场分析材料到学术论文,柱状图、折线图、散点图等图表经常被运用于记录和直观表现数据。有时候我们需要将表格中的部分数据提取出来,进行专门的分析和使用。
但是,当我们试图从图文混排表格中逆向拆解PDF或JPG、PNG格式的图表,将其重新转化为Excel等可编辑数据形式,就会遇到难点。要么速度慢,需要人工操作一个一个数据的提取,要么利用ocr工具,但没有接入AI能力的OCR工具只能提取文本信息,难以理解用户真正所需的数据。
以金融行业为例,机构常需解析上市公司的年报、各类研报中的数据,其中包括大量图表数据。这些文件以PDF和图片格式为主体,也不乏批量处理更困难的加密PDF。相比纯文本,表格、图表中包含了更多重要数据,如何准确地提取这些数据对进一步的研究分析工作至关重要。
针对这一问题,【TextIn】文档解析工具作为大模型加速器,为解决这一难点量身定制。TextIn文档解析上架新功能——图表解析,通过线上参数配置即可调用,完成全文解析,无需对样本进行预先分割或其他预处理。让我们来看几个例子。
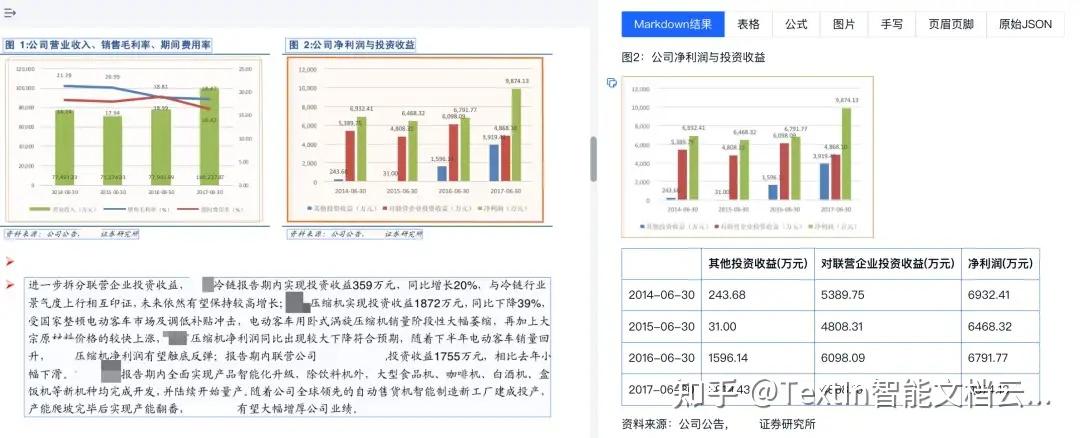
图1
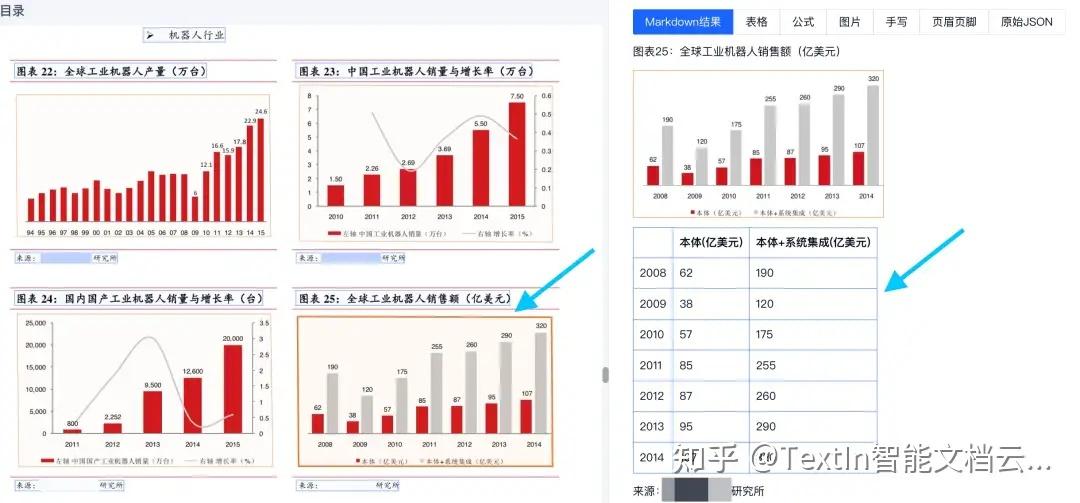
图2
对于有数值标注的图表,TextIn文档解析可以直接输出准确表格,将其转化为结构化数据,方便后续的数据入库、分析或输入大模型进行处理。
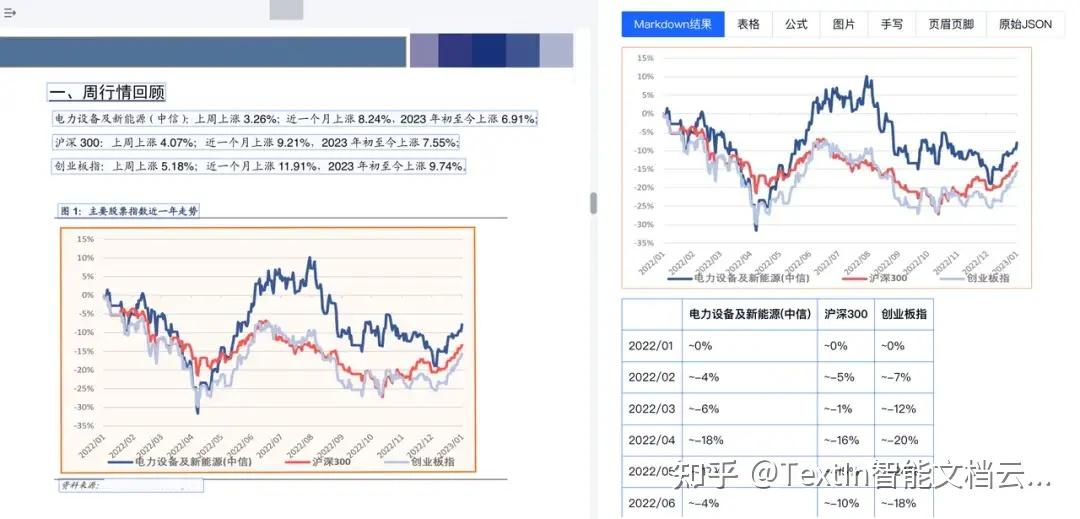
图3
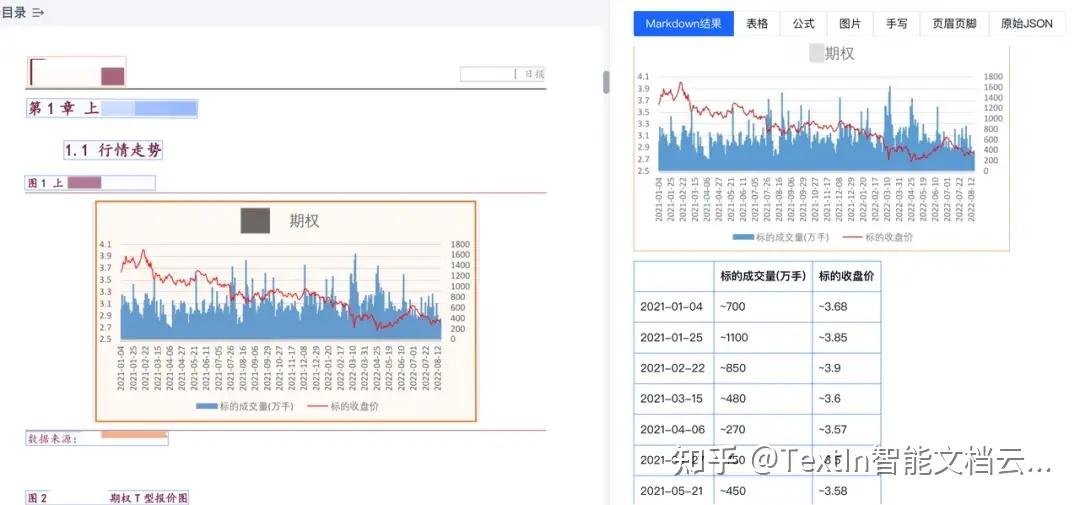
图4
对于没有明确数值的复杂图表,TextIn也会通过精确测量给出预估数值,在仅有扫描件、图片文件的情况下,帮助挖掘更多有效数据信息,完成分析及预测工作。
以图2中的图表为例。图表展示了全球工业机器人销售额,我们向大模型上传文件,并提出问题。下方图5为直接上传PDF的回答,图6为上传TextIn解析后的Markdown文件获得的答复。
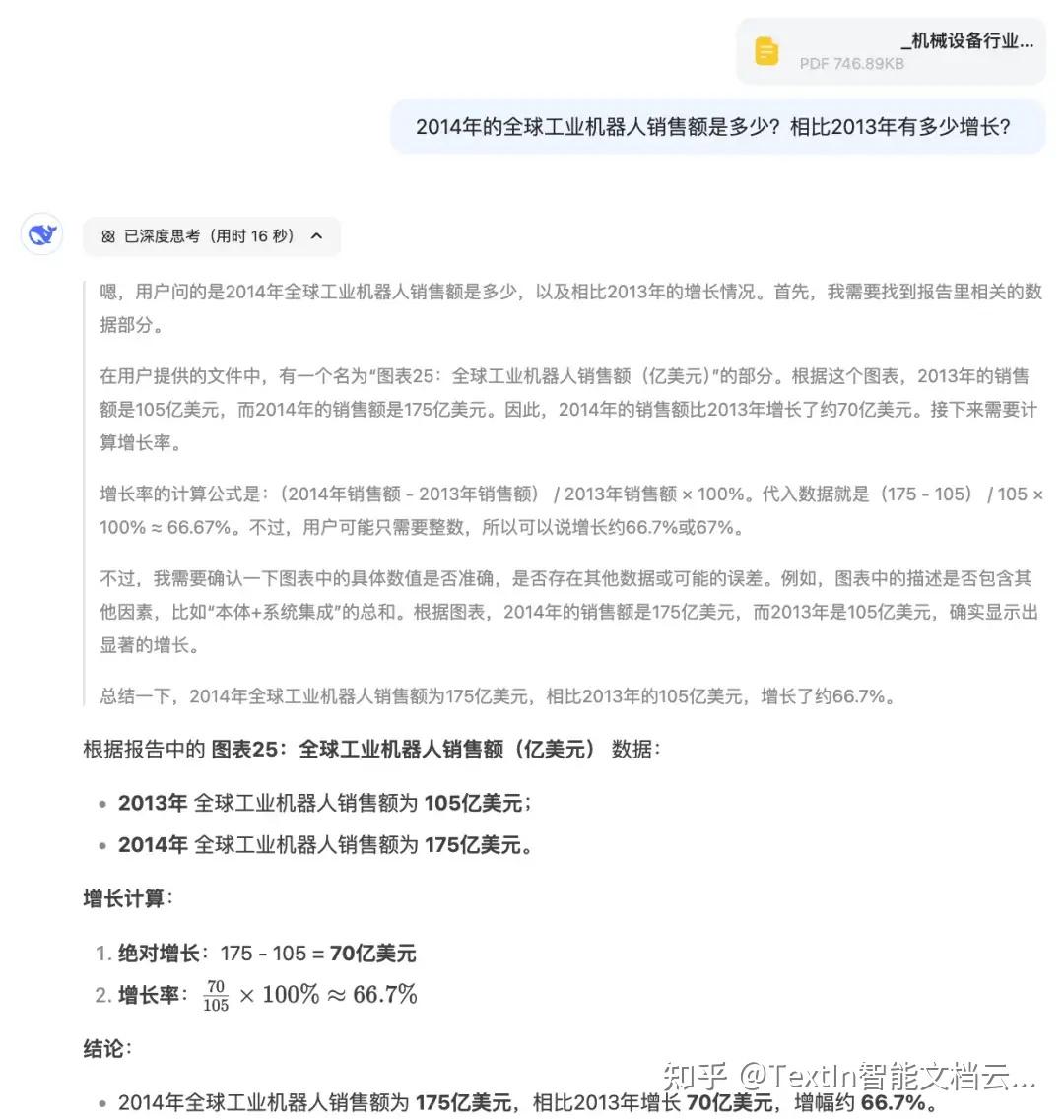
图5

图6
可以看到,未经过解析的柱状图对大模型的理解造成了干扰,经过图表转化后,模型给出了准确、优质的答案。
因此,接入AI能力的文档解析工具已不仅仅是一款OCR工具,反而可以成为提炼文本内容并将文档中非结构化数据转换成结构化数据的利器,方便用户的同时,也能赋能计算机读取理解文档信息。