【Linux系统】库的制作与原理
1. 什么是库
库(Library)是一组预编译的可复用代码集合,以二进制形式存在,用于封装常用功能(如数学计算、字符串操作),避免重复开发。程序通过链接库来调用这些功能,无需从零编写代码。库的本质是目标文件(.o文件)的压缩打包,由操作系统加载执行 。
- 核心特点:
- 提高代码复用性和开发效率。
- 分为静态库和动态库两类,主要区别在链接时机和内存占用 。
- 示例:标准C库提供基础输入输出功能,被多个程序依赖 。
2. 静态库
静态库(Static Library)在编译时将库代码完全复制到可执行文件中,生成独立的程序。运行时不再依赖原库文件,但会导致可执行文件体积较大 。
- 文件格式:Linux下以
.a结尾(如libmylib.a),Windows下为.lib。 - 适用场景:嵌入式系统、需独立运行的环境,或对库改动较少的程序 。
2.1 静态库的生成
生成步骤分为编译源文件和打包:
编译目标文件:使用
gcc -c生成位置无关的.o文件。gcc -c mylib.c -o mylib.o # 编译mylib.c为目标文件打包为静态库:使用
ar命令归档.o文件。ar rcs libmylib.a mylib.o # rcs选项表示替换/创建/索引,生成libmylib.aar是归档工具,rcs确保库更新和索引优化 ,r(替换文件)、c(创建库)、s(生成索引)。- 静态库本质是.o文件的集合,无链接过程 。
2.2 静态库的使用
在编译可执行文件时链接静态库:
命令示例:
gcc main.c -o main -L. -lmylib # -L指定库路径,-l指定库名(省略lib前缀和.a后缀)-L.:指定库搜索路径(.表示当前目录)。-lmylib:链接libmylib.a(-l后跟库名,省略lib和.a)。
特点:
可执行文件独立运行,无需外部依赖。
文件体积较大(库代码被完整复制到可执行文件中)。
库更新需重新编译整个程序。
关键点:
- 静态库需在编译命令末尾指定,链接器会复制所需代码到可执行文件 。
- 搜索路径优先级:手动指定(
-L) > 环境变量LIBRARY_PATH> 系统默认路径(如/lib,/usr/lib) 。
优点:运行时无需额外依赖;缺点:增大程序体积,无法共享更新 。
3. 动态库
动态库(Dynamic Library,也称共享库)在程序运行时才加载到内存,多个程序可共享同一库副本,减少内存占用和磁盘空间。但运行时需确保库文件可用 。
- 文件格式:Linux下以
.so结尾(如libmylib.so),Windows下为.dll。 - 适用场景:库频繁更新、多进程共享(如服务器程序),或需节省资源的场景 。
3.1 动态库的生成
生成需位置无关代码(PIC),确保加载时地址灵活:
编译PIC目标文件:使用
-fPIC选项。gcc -c -fPIC mylib.c -o mylib.o # -fPIC生成位置无关代码打包为动态库:使用
gcc -shared链接.o文件。gcc -shared -o libmylib.so mylib.o # -shared选项生成动态库- 可选步骤:创建软链接简化版本管理(如
ln -s libmylib.so .1.0 libmylib.so) 。
- 可选步骤:创建软链接简化版本管理(如
3.2 动态库的使用
编译时指定库,但运行时加载:
命令示例:
gcc main.c -o main -L. -lmylib # 编译时链接,与静态库语法相同关键点:
- 编译后,可执行文件仅记录库名而非完整代码,体积较小 。
- 运行时若找不到库,会报错(如
error while loading shared libraries) 。
优点:节省内存、支持热更新;缺点:依赖运行时环境 。
3.3 库运行搜索路径
动态库运行时搜索路径按优先级确定,需配置以确保可执行文件正常加载:
默认系统路径:如
/lib、/usr/lib,存放标准库 。/etc/ld.so .conf配置的路径:可添加自定义目录,后运行ldconfig更新缓存 。环境变量
LD_LIBRARY_PATH:临时指定路径,适用于开发测试。export LD_LIBRARY_PATH=/path/to/lib:$LD_LIBRARY_PATH # 添加当前目录编译时
-rpath选项:嵌入绝对路径到可执行文件。gcc main.c -o main -L. -lmylib -Wl,-rpath=/absolute/path # -Wl传递参数给链接器其他方法:
- 复制.so文件到系统库目录(如
/usr/lib) 。 - 创建符号链接指向库文件 。
- 复制.so文件到系统库目录(如
- 优先级总结:
-rpath>LD_LIBRARY_PATH>/etc/ld.so .conf> 默认路径 。 - 验证工具:
ldd main:检查程序依赖的库及路径 。nm libmylib.so:查看库中的符号 。
关键区别总结
| 特性 | 静态库(.a/.lib) | 动态库(.so/.dll) |
|---|---|---|
| 链接时机 | 编译时 | 运行时 |
| 文件体积 | 较大(库代码被复制) | 较小(仅记录引用) |
| 部署难度 | 简单(单文件) | 需确保库存在于运行环境 |
| 更新灵活性 | 需重新编译程序 | 替换库文件即可生效 |
| 内存占用 | 每个程序独立占用内存 | 多个程序共享同一库实例 |
4. 目标文件
在Windows系统中,IDE将这些编译和链接步骤完美地封装起来,用户只需一键操作即可完成构建,操作非常便捷。然而,一旦出现错误,特别是链接相关的错误时,很多人往往不知所措。此前我们已在Linux环境下学习过如何使用gcc编译器来完成这些操作。
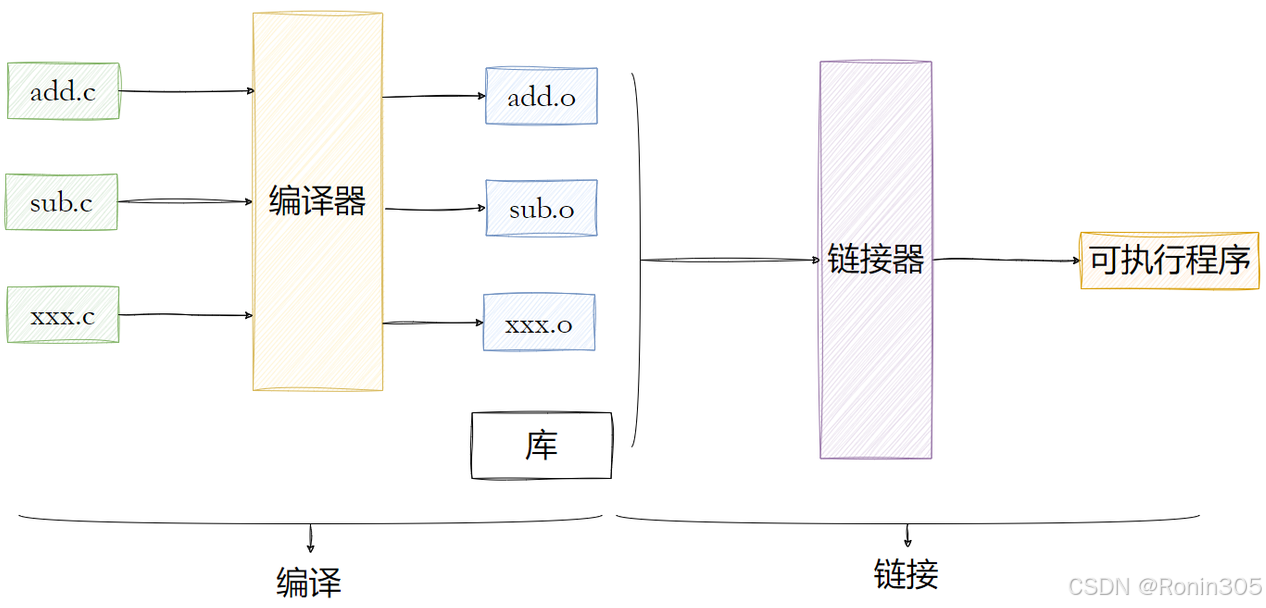
让我们深入探讨编译和链接的完整流程,以更好地理解动静态库的使用原理。
让我们先来回顾一下什么是编译。编译是指将高级编程语言(如C、Java、Python等)编写的源代码,通过特定的编译程序(编译器)转换成计算机CPU能够直接识别和执行的机器代码的过程。
这个翻译过程通常包括以下几个主要步骤:
- 预处理阶段:处理源代码中的宏定义、头文件包含等预处理指令
- 词法分析:将源代码分解为一系列有意义的标记(tokens)
- 语法分析:检查语法结构是否符合语言规范,生成抽象语法树
- 语义分析:进行类型检查等语义验证
- 中间代码生成:生成与平台无关的中间表示
- 代码优化:对中间代码进行各种优化
- 目标代码生成:最终生成特定CPU架构的机器指令
例如,当我们用C语言编写一个简单的"Hello World"程序并编译时:
#include <stdio.h>
int main() {printf("Hello World");return 0;
}
编译器会将其转换为x86或ARM等架构的机器指令,这些指令可以直接被CPU执行。编译后的程序执行效率通常比解释型语言更高,因为代码已经针对目标平台进行了优化。
比如:在一个名为hello.c的C语言源文件中,我们编写了一个简单的程序,包含一个main()函数用于输出"hello world!"字符串,同时调用了另一个名为run()的函数。这个run()函数的具体实现被定义在另一个独立的源文件code.c中。
// hello.c
#include<stdio.h>
void run();int main() {printf("hello world!\n");run();return 0;
}// code.c
#include<stdio.h>
void run() {printf("running...\n");
}
为了编译这个由多个源文件组成的项目,我们可以使用GCC编译器的-c选项来分别编译这两个源文件
// 编译两个源⽂件
$ gcc -c hello.c
$ gcc -c code.c
$ ls
code.c code.o hello.c hello.o首先编译hello.c文件,这会生成hello.o目标文件,其中包含main()函数的机器码,但run()函数调用会被标记为未解析的外部引用。接着编译code.c文件,这会生成code.o目标文件,其中包含run()函数的实现代码。
此时生成的两个目标文件是独立且不完整的:
hello.o知道要调用run()但不知其位置code.o包含run()实现但不知被谁调用
需要注意的是,如果只修改了某个源文件,只需单独重新编译该文件即可,无需耗时重新编译整个项目。目标文件采用ELF格式的二进制文件,这种格式对二进制代码进行了封装。
说了这么多,也许你会有这样的疑问:
为什么要把.c编译为.o文件,最后再链接呢?为什么不直接将.c文件进行链接呢?
模块化开发
独立编译:在大型项目中,通常会将代码分成多个
.c文件,每个文件实现特定的功能模块。将每个.c文件单独编译为.o文件,可以实现模块的独立编译,每个模块的修改和编译不会相互影响。例如,一个项目包含math.c、string.c和main.c三个文件,开发人员可以在修改math.c后单独重新编译它为math.o,而无需重新编译其他未修改的文件。便于维护和更新:独立的
.o文件便于对项目进行维护和更新。当需要修改某个功能模块时,只需重新编译对应的.c文件生成新的.o文件,然后再进行链接即可,无需对整个项目进行重新编译。这大大提高了开发效率,尤其是在项目规模较大时。
提高编译效率
避免重复编译:如果直接将
.c文件进行链接,编译器需要在每次链接时对所有相关的.c文件进行重新编译,这会浪费大量的时间和计算资源。而将.c文件预先编译为.o文件后,只要.c文件没有发生变化,其对应的.o文件就可以直接用于链接,避免了重复编译的过程,显著提高了编译效率。增量编译:在软件开发过程中,通常只需要修改部分代码,而不需要对整个项目进行修改。通过将
.c文件编译为.o文件,可以实现增量编译,即只重新编译那些被修改的.c文件,其他未修改的.o文件可以继续使用,从而加快了整个项目的编译速度。
链接阶段的优势
链接多个目标文件:链接器的主要任务是将多个目标文件(
.o文件)链接在一起,解析各个文件之间的外部引用,生成最终的可执行文件。如果直接对.c文件进行链接,链接器需要先将.c文件编译为目标代码,然后再进行链接,这增加了链接器的复杂性和工作量。而将编译和链接分开,链接器可以直接处理.o文件,更高效地完成链接任务。使用预编译库:在实际开发中,经常会使用一些预编译的库文件(如静态库
.a文件或动态库.so文件)。这些库文件本身也是由多个.o文件组成的。通过将项目中的.c文件编译为.o文件,可以方便地将这些.o文件与预编译库文件一起链接,生成最终的可执行程序。
举个例子,假设有一个项目包含两个 .c 文件:file1.c 和 file2.c,以及一个预编译的静态库 libmylib.a。如果直接对 .c 文件进行链接,需要在链接命令中指定所有的 .c 文件和库文件,并且编译器需要先编译 .c 文件为目标代码,然后再与库文件链接,命令如下:
gcc file1.c file2.c libmylib.a -o myprogram
而将 .c 文件预先编译为 .o 文件后,链接命令可以简化为:
gcc file1.o file2.o libmylib.a -o myprogram
这样,链接器可以直接处理 .o 文件和库文件,提高了链接的效率。
综上所述,将 .c 文件编译为 .o 文件然后再链接,是为了实现模块化开发、提高编译效率以及更好地利用链接阶段的优势。这种编译和链接的分离方式是软件开发过程中的重要实践,有助于提高开发效率和软件的质量。
引入ELF:
我们的.o文件和可执行文件都是ELF格式的
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ file hello.o
hello.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ file code.o
code.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped## file命令⽤于辨识⽂件类型。关键特征解析:
| 属性 | 说明 |
|---|---|
relocatable | 可重定位文件(未完成链接) |
not stripped | 包含调试符号信息 |
LSB | 小端字节序 |
x86-64 | AMD64架构 |
目标文件是编译过程的中间产物,包含:
机器指令:源代码编译后的二进制代码
数据:程序中定义的全局/静态变量
符号表:函数/变量名称及其位置信息
重定位信息:标记需要链接器处理的地址引用
目标文件如何变成可执行文件
通过链接器解决:
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ gcc hello.o code.o -o hello
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ ./hello
hello world!
running...
链接过程详解:
- 符号解析:
hello.o引用run(),在code.o中找到其定义。- 若符号未定义,链接器报错(如
undefined reference to 'run')。
- 地址重定位:
- 合并
.text段(代码)和.data段(全局变量)。(后文原理部分会介绍) - 将
run()在code.o中的地址写入hello.o的调用位置。
- 合并
- 生成可执行文件:
- 输出可执行文件 hello,格式为
ELF executable。
- 输出可执行文件 hello,格式为
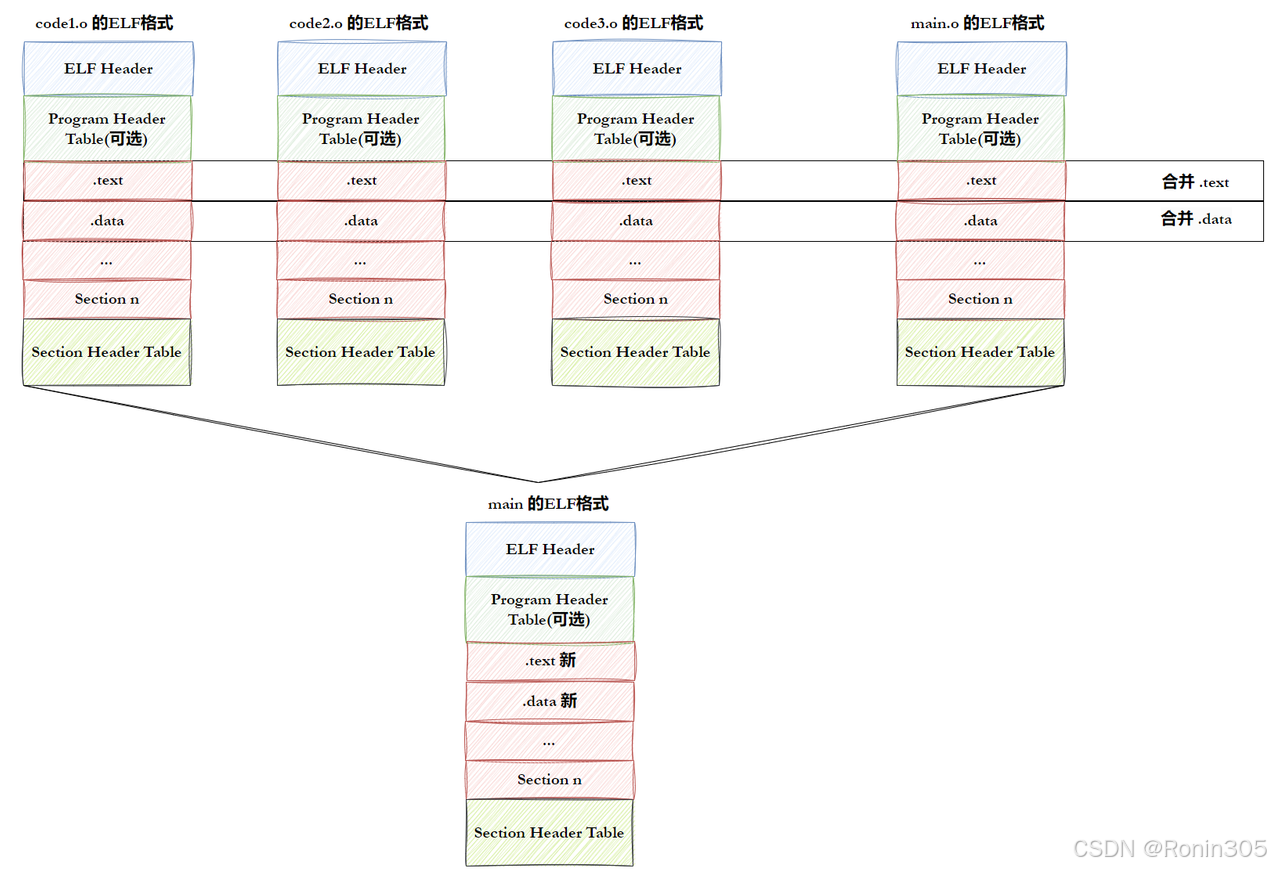
目标文件与库的关系
库本质上就是目标文件的集合:
静态库 = 多个
.o文件打包成.a文件ar rcs libmylib.a file1.o file2.o动态库 = 特殊处理的目标文件集合(位置无关代码)
gcc -shared -fPIC -o libmylib.so file1.o file2.o
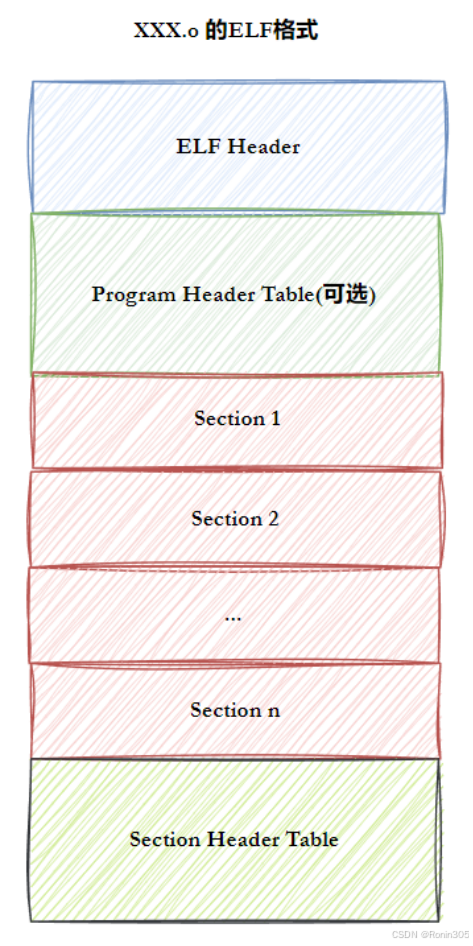
5. ELF文件
要深入理解编译链接的细节,我们需要先了解ELF文件。实际上,以下四种文件都属于ELF文件类型:
ELF文件类型详解
| 类型 | 文件扩展名 | 特点 | 工具查看命令 |
|---|---|---|---|
| 可重定位文件 | .o (Linux) | 包含代码/数据,但地址未确定,需链接器处理 | readelf -h hello.o |
| 可执行文件 | 无扩展名 | 包含可直接执行的程序,有入口地址 | readelf -h a.out |
| 共享目标文件 | .so (Linux) | 可被动态加载的库文件 | readelf -h libmylib.so |
| 内核转储文件 | core | 进程崩溃时的内存快照,用于调试 | gdb -c core |
• 可重定位文件(Relocatable File): 即扩展名为.o的中间目标文件,由编译器生成但尚未经过链接处理。这类文件包含机器代码和数据,但其中的符号引用尚未解析,地址也是相对的(可重定位的),需要链接器(ld)将其与其他目标文件或库合并才能生成可执行文件或共享库。例如,在Linux下使用gcc编译但不链接时就会生成此类文件(gcc -c file.c)。
• 可执行文件(Executable File): 这是可以直接在操作系统上运行的完整程序文件。它们已经过完整的编译和链接过程,所有符号引用都已解析,具有固定的入口地址(如main函数)。在Linux中,这类文件通常没有扩展名,但可以通过chmod +x赋予可执行权限。例如,gcc编译链接后生成的a.out就是典型的可执行文件。
• 共享目标文件(Shared Object File): 即动态链接库文件,扩展名为.so(Windows下对应.dll文件)。这类文件包含可被多个程序共享的代码和数据,在程序运行时由动态链接器加载。与静态库不同,它们支持运行时加载,能有效减少内存占用。例如Linux系统的标准C库就是/lib/x86_64-linux-gnu/libc.so.6。
• 内核转储(Core Dumps): 这是当程序异常终止时(如段错误、非法指令等),由操作系统内核生成的进程内存快照文件(通常名为core或core.pid)。它完整记录了进程崩溃时的执行上下文,包括寄存器值、堆栈状态、内存映射等信息,配合调试器(如gdb)可以分析崩溃原因。在Linux中可通过ulimit -c设置core文件大小限制,默认可能被禁用。
ELF 文件的核心结构
ELF 文件由四个关键部分组成,通过 readelf 命令可查看详细信息:
readelf -h hello # 查看 ELF 头
readelf -l hello # 查看程序头表(段信息)
readelf -S hello # 查看节头表(节信息)
ELF 头 (ELF Header)
- 位置:文件起始处
- 作用:描述文件基本信息
- 文件类型(可执行/共享库等)
- 目标机器架构(x86-64/ARM)
- 入口地址(程序起始执行点)
- 节头表/程序头表的位置和大小
• ELF头(ELF header) :描述文件的主要特性。其位于文件的开始位置,通常占用前52或64个字节(32位/64位系统),包含了ELF文件的魔数(0x7F+ELF)、字长(32/64位)、字节序等基本信息。它的主要目的是定位文件的其他部分,如程序头表和节头表的位置和大小。例如,通过e_phoff字段可以找到程序头表的起始偏移量。
程序头表 (Program Header Table)
作用:指导操作系统加载文件到内存
关键段 (Segments):
段名 作用 内存权限 LOAD可加载的代码/数据段 R-X (代码) 或 RW (数据) DYNAMIC动态链接信息 RW INTERP指定动态链接器路径 R
• 程序头表(Program header table) :列举了所有有效的段(segments)和他们的属性。每个表项通常包含以下关键信息:
- p_type:段类型(如PT_LOAD表示可加载段)
- p_offset:段在文件中的偏移量
- p_vaddr:段在内存中的虚拟地址
- p_filesz:段在文件中的大小
- p_memsz:段在内存中的大小
- p_flags:访问权限(读/写/执行) 这些段紧密地排列在二进制文件中,需要通过程序头表的描述信息才能正确加载和执行。
节头表 (Section Header Table)
- 作用:描述文件中的 节 (Sections) 信息
- 节 vs 段:
- 节 (Sections) :链接阶段使用(如合并代码)
- 段 (Segments) :执行阶段使用(内存加载)
• 节头表(Section header table) :包含对节(sections)的描述,通常位于文件末尾。每个表项包含:
- sh_name:节名称在字符串表中的索引
- sh_type:节类型(如SHT_PROGBITS表示程序数据)
- sh_flags:节属性(可写/可分配/可执行等)
- sh_addr:节在内存中的地址
- sh_offset:节在文件中的偏移
- sh_size:节的大小
节 (Sections)
文件中的实际数据区域,常见节如下:
节名 作用 是否加载到内存 .text可执行机器指令(程序代码) 是 (R-X) .data已初始化的全局/静态变量 是 (RW) .rodata只读数据(如字符串常量) 是 (R) .bss未初始化的全局/静态变量(不占磁盘空间) 是 (RW) .symtab符号表(函数/变量名地址) 否 .strtab字符串表(符号名称字符串) 否
• 节(Section) :ELF⽂件中的基本组成单位,包含了特定类型的数据。这些节在链接时会被组合成段(Segment),在加载时按段为单位映射到内存。
最常见的节:
• 代码节(.text):⽤于保存机器指令,是程序的主要执⾏部分。通常具有只读和可执行属性,包含函数的具体实现代码。
• 数据节(.data):保存已初始化的全局变量和局部静态变量,具有读写属性。例如:
int global_var = 42; // 存储在.data节
static int static_var = 100; // 也存储在.data节• 未初始化数据节(.bss):存储未初始化的全局和静态变量,不占用文件空间,但在加载时会分配内存空间并初始化为0。例如:
int uninit_var; // 存储在.bss节示例:
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ size hellotext data bss dec hex filename1462 600 8 2070 816 hello
| 字段 | 含义 | 对应节 | 本例值 |
|---|---|---|---|
text | 代码段大小(机器指令占用的字节数) | .text | 1462 字节 |
data | 已初始化数据大小(全局变量/静态变量初始值) | .data | 600 字节 |
bss | 未初始化数据大小(运行时分配零值内存,磁盘不占空间) | .bss | 8 字节 |
dec | 总内存占用量(十进制:text + data + bss) | - | 2070 字节 |
hex | 总内存占用量(十六进制) | - | 0x816 |
filename | 文件名 | - | hello |
关键说明:
bss的特殊性:虽然输出显示 8 字节,但磁盘文件中.bss不占用空间,仅在程序加载到内存时分配空间并初始化为 0。- 内存对齐:实际加载时各段会按页(通常 4KB)对齐,因此内存占用可能大于
dec值。
6. ELF从形成到加载轮廓
6.1 ELF形成可执行
ELF(Executable and Linkable Format)可执行文件形成过程
编译阶段(step-1):
- 源代码转换:编译器(如gcc/g++)将每个独立的C/C++源代码文件(.c/.cpp)分别编译
- 生成目标文件:输出与源文件对应的.o文件(如main.c → main.o)
- 库文件处理:
- 静态库(.a文件):直接被链接进最终可执行文件
- 动态库(.so文件):仅记录引用信息,运行时加载
链接阶段(step-2):
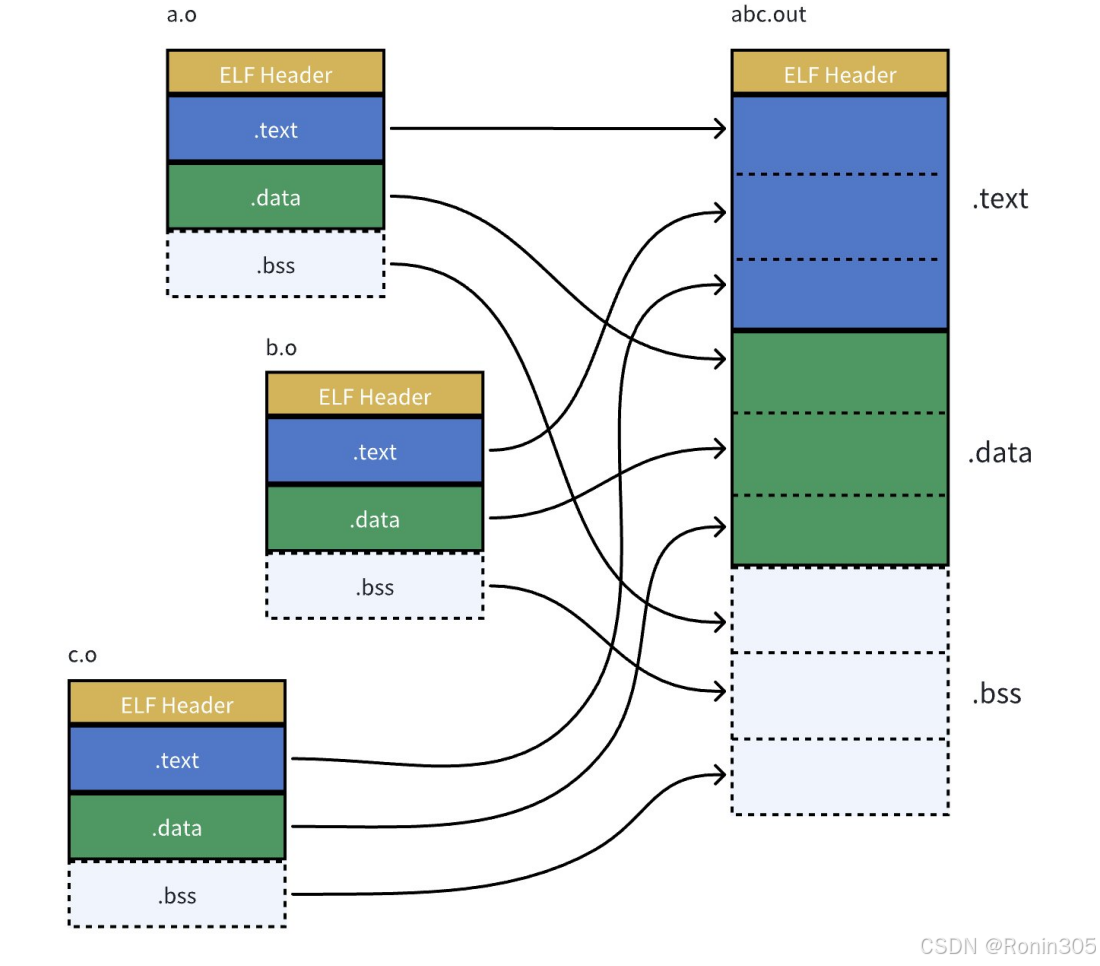
- Section合并处理:
- 代码段(.text)合并:将所有.o文件的代码段合并
- 数据段(.data/.bss)合并:初始化/未初始化数据的整合
- 符号解析:处理跨文件的函数/变量引用
- 重定位:修正代码中的地址引用
📌 重要说明:
链接优化:
- 实际链接过程会执行去除未使用代码(--gc-sections)
- 进行符号消解(解决多重定义等问题)
- 处理库依赖关系(递归处理依赖的静态库)
特殊处理:
- 动态库的延迟绑定(PLT/GOT机制)
- 地址空间布局随机化(ASLR)准备
- 调试信息(.debug_*)的保留或剥离
6.2 ELF可执行文件加载
1. Section与Segment的本质区别
| 特性 | Section(节) | Segment(段) |
|---|---|---|
| 作用阶段 | 链接阶段(Linking View) | 执行阶段(Execution View) |
| 描述表 | 节头表(Section Header Table) | 程序头表(Program Header Table) |
| 目的 | 指导链接器合并代码/数据 | 指导操作系统加载内存 |
| 数量关系 | 一个Segment包含多个属性相同的Section | 一个Section仅属于一个Segment |
| 下文示例 | readelf -S 显示31个Section(如.text, .data) | readelf -l 显示13个Program Headers(后文详解) |
核心结论:
Section是编译链接的逻辑单元,Segment是内存加载的物理单元。合并行为在链接时确定,通过程序头表描述 。
2. Section合并为Segment的原则
(1) 合并条件
- 权限相同:可读(R)、可写(W)、可执行(X)
- 加载要求:需在运行时申请内存空间(如
.text需加载,.debug不加载) - 内存对齐:按页对齐(通常4KB),避免内存碎片
(2) 典型合并案例
| Segment类型 | 包含的典型Section | 权限 | 下文示例中的地址范围 |
|---|---|---|---|
| 代码段 | .text, .rodata, .interp | R-X | 0x0000318-0x0001556 |
| 数据段 | .data, .dynamic, .got | RW | 0x0003db0-0x0003dc8 |
| 只读数据段 | .eh_frame, .gcc_except_table | R | 未显式展示,通常与代码段合并 |
注:示例中
readelf -S输出的.interp(解释器路径)与.text权限均为R-X,合并到同一代码段。
在 ELF 文件加载到内存时,系统会根据 Program Header Table 中的信息将多个 Section 合并为 Segment。这个合并过程主要依据以下特征:
内存属性一致性:
- 可读性(R)
- 可写性(W)
- 可执行性(X)
- 加载需求(LOAD)
典型合并模式示例:
- 所有只读的代码段(如
.text,.rodata)会被合并到 TEXT Segment - 可写的数据段(如
.data,.bss)会被合并到 DATA Segment - 动态链接相关段(如
.dynamic,.got)会被合并到 DYNAMIC Segment
- 所有只读的代码段(如
显然,合并操作在生成 ELF 文件时就已经确定,具体的合并规则被记录在 ELF 的程序头表(Program header table)中。
# 查看 ELF 头
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ readelf -h hello
ELF Header:Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64Data: 2's complement, little endianVersion: 1 (current)OS/ABI: UNIX - System VABI Version: 0Type: DYN (Position-Independent Executable file)Machine: Advanced Micro Devices X86-64Version: 0x1Entry point address: 0x1060Start of program headers: 64 (bytes into file)Start of section headers: 14032 (bytes into file)Flags: 0x0Size of this header: 64 (bytes)Size of program headers: 56 (bytes)Number of program headers: 13Size of section headers: 64 (bytes)Number of section headers: 31Section header string table index: 30# 查看可执⾏程序的section
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ readelf -S hello
There are 31 section headers, starting at offset 0x36d0:Section Headers:[Nr] Name Type Address OffsetSize EntSize Flags Link Info Align[ 0] NULL 0000000000000000 000000000000000000000000 0000000000000000 0 0 0[ 1] .interp PROGBITS 0000000000000318 00000318000000000000001c 0000000000000000 A 0 0 1[ 2] .note.gnu.pr[...] NOTE 0000000000000338 000003380000000000000030 0000000000000000 A 0 0 8[ 3] .note.gnu.bu[...] NOTE 0000000000000368 000003680000000000000024 0000000000000000 A 0 0 4[ 4] .note.ABI-tag NOTE 000000000000038c 0000038c0000000000000020 0000000000000000 A 0 0 4[ 5] .gnu.hash GNU_HASH 00000000000003b0 000003b00000000000000024 0000000000000000 A 6 0 8[ 6] .dynsym DYNSYM 00000000000003d8 000003d800000000000000a8 0000000000000018 A 7 1 8[ 7] .dynstr STRTAB 0000000000000480 00000480000000000000008d 0000000000000000 A 0 0 1[ 8] .gnu.version VERSYM 000000000000050e 0000050e000000000000000e 0000000000000002 A 6 0 2[ 9] .gnu.version_r VERNEED 0000000000000520 000005200000000000000030 0000000000000000 A 7 1 8[10] .rela.dyn RELA 0000000000000550 0000055000000000000000c0 0000000000000018 A 6 0 8[11] .rela.plt RELA 0000000000000610 000006100000000000000018 0000000000000018 AI 6 24 8[12] .init PROGBITS 0000000000001000 00001000000000000000001b 0000000000000000 AX 0 0 4[13] .plt PROGBITS 0000000000001020 000010200000000000000020 0000000000000010 AX 0 0 16[14] .plt.got PROGBITS 0000000000001040 000010400000000000000010 0000000000000010 AX 0 0 16[15] .plt.sec PROGBITS 0000000000001050 000010500000000000000010 0000000000000010 AX 0 0 16[16] .text PROGBITS 0000000000001060 00001060000000000000012b 0000000000000000 AX 0 0 16[17] .fini PROGBITS 000000000000118c 0000118c000000000000000d 0000000000000000 AX 0 0 4[18] .rodata PROGBITS 0000000000002000 00002000000000000000001c 0000000000000000 A 0 0 4[19] .eh_frame_hdr PROGBITS 000000000000201c 0000201c000000000000003c 0000000000000000 A 0 0 4[20] .eh_frame PROGBITS 0000000000002058 0000205800000000000000cc 0000000000000000 A 0 0 8[21] .init_array INIT_ARRAY 0000000000003db8 00002db80000000000000008 0000000000000008 WA 0 0 8[22] .fini_array FINI_ARRAY 0000000000003dc0 00002dc00000000000000008 0000000000000008 WA 0 0 8[23] .dynamic DYNAMIC 0000000000003dc8 00002dc800000000000001f0 0000000000000010 WA 7 0 8[24] .got PROGBITS 0000000000003fb8 00002fb80000000000000048 0000000000000008 WA 0 0 8[25] .data PROGBITS 0000000000004000 000030000000000000000010 0000000000000000 WA 0 0 8[26] .bss NOBITS 0000000000004010 000030100000000000000008 0000000000000000 WA 0 0 1[27] .comment PROGBITS 0000000000000000 00003010000000000000002b 0000000000000001 MS 0 0 1[28] .symtab SYMTAB 0000000000000000 000030400000000000000390 0000000000000018 29 19 8[29] .strtab STRTAB 0000000000000000 000033d000000000000001e6 0000000000000000 0 0 1[30] .shstrtab STRTAB 0000000000000000 000035b6000000000000011a 0000000000000000 0 0 1
Key to Flags:W (write), A (alloc), X (execute), M (merge), S (strings), I (info),L (link order), O (extra OS processing required), G (group), T (TLS),C (compressed), x (unknown), o (OS specific), E (exclude),D (mbind), l (large), p (processor specific)# 查看section合并的segment
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ readelf -l helloElf file type is DYN (Position-Independent Executable file)
Entry point 0x1060
There are 13 program headers, starting at offset 64Program Headers:Type Offset VirtAddr PhysAddrFileSiz MemSiz Flags AlignPHDR 0x0000000000000040 0x0000000000000040 0x00000000000000400x00000000000002d8 0x00000000000002d8 R 0x8INTERP 0x0000000000000318 0x0000000000000318 0x00000000000003180x000000000000001c 0x000000000000001c R 0x1[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]LOAD 0x0000000000000000 0x0000000000000000 0x00000000000000000x0000000000000628 0x0000000000000628 R 0x1000LOAD 0x0000000000001000 0x0000000000001000 0x00000000000010000x0000000000000199 0x0000000000000199 R E 0x1000LOAD 0x0000000000002000 0x0000000000002000 0x00000000000020000x0000000000000124 0x0000000000000124 R 0x1000LOAD 0x0000000000002db8 0x0000000000003db8 0x0000000000003db80x0000000000000258 0x0000000000000260 RW 0x1000DYNAMIC 0x0000000000002dc8 0x0000000000003dc8 0x0000000000003dc80x00000000000001f0 0x00000000000001f0 RW 0x8NOTE 0x0000000000000338 0x0000000000000338 0x00000000000003380x0000000000000030 0x0000000000000030 R 0x8NOTE 0x0000000000000368 0x0000000000000368 0x00000000000003680x0000000000000044 0x0000000000000044 R 0x4GNU_PROPERTY 0x0000000000000338 0x0000000000000338 0x00000000000003380x0000000000000030 0x0000000000000030 R 0x8GNU_EH_FRAME 0x000000000000201c 0x000000000000201c 0x000000000000201c0x000000000000003c 0x000000000000003c R 0x4GNU_STACK 0x0000000000000000 0x0000000000000000 0x00000000000000000x0000000000000000 0x0000000000000000 RW 0x10GNU_RELRO 0x0000000000002db8 0x0000000000003db8 0x0000000000003db80x0000000000000248 0x0000000000000248 R 0x1Section to Segment mapping:Segment Sections...00 01 .interp 02 .interp .note.gnu.property .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt 03 .init .plt .plt.got .plt.sec .text .fini 04 .rodata .eh_frame_hdr .eh_frame 05 .init_array .fini_array .dynamic .got .data .bss 06 .dynamic 07 .note.gnu.property 08 .note.gnu.build-id .note.ABI-tag 09 .note.gnu.property 10 .eh_frame_hdr 11 12 .init_array .fini_array .dynamic .got 📌 为什么要将section合并成为segment
• 减少内存碎片:Section合并的主要目的是为了减少页面碎片,提升内存使用效率。现代操作系统通常以4KB(4096字节)为单位进行内存分配和管理。当多个小的section独立分配时,会造成大量内存浪费。例如:
- 假设.text段占用4097字节(超过1个页面)
- .init段仅占用512字节
- 如果不合并,将浪费7679字节(4095 + 4096 - 512)的空间
- 合并后,.text和.init可以共享一个页面,只需2个页面而非3个
• 权限管理优化:合并后的segment可以统一设置内存访问权限,提高安全性: - 操作系统加载程序时,会将具有相同属性(如可读/可写/可执行)的section合并 - 例如:将所有可执行代码段(如.text、.init)合并为代码segment - 将所有数据段(如.data、.bss)合并为数据segment - 每个segment可设置独立的权限标志(如代码段只读可执行)
• 性能提升:合并带来额外好处: - 减少TLB(转译后备缓冲器)条目数量 - 降低内存管理单元(MMU)的地址转换开销 - 提高程序加载速度(减少页面映射操作)
• 实际应用场景: - 在Linux系统中,ELF文件通过程序头表(Program Header)描述segment - 典型的segment包括: 1. LOAD(可加载段) 2. DYNAMIC(动态链接信息) 3. INTERP(解释器路径) - 通过readelf命令可查看ELF文件的segment布局
程序头表和节头表作为ELF文件的两个核心部分,提供了不同维度的视角:
ELF文件双视图:程序头表与节头表深度解析
一、双视图设计原理
链接视图(Linking View)
- 对应结构:节头表(Section Header Table)
- 核心作用:为链接器提供细粒度文件结构,支持符号解析与节合并优化。
- 设计逻辑:
将ELF文件按功能划分为独立节(Section),如代码(
.text)、数据(.data)、符号表(.symtab)等。链接器通过节头表定位各节属性(类型、地址、权限),合并相同权限的节为段(Segment),提升空间利用率。
优化意义:避免内存碎片(物理页通常4KB),若多个小节(如
.data中的小变量)独立加载,将浪费大量内存。
📊 示例:100个8字节全局变量独立加载需100×4KB=400KB;合并后仅需1页(4KB)。
执行视图(Execution View)
- 对应结构:程序头表(Program Header Table)
- 核心作用:指导操作系统加载进程内存映像,初始化执行环境。
- 设计逻辑:
- 将链接阶段合并的段(如可执行段、数据段)映射到内存,定义权限(R/W/X)和加载地址。
- 加载器按程序头表条目加载段,动态链接器解析依赖库(如
.interp指定/lib64/ld-linux-x86-64.so.2)。 - 强制存在性:可执行文件必须有程序头表;可重定位文件(
.o)通常无此表。
二、节头表:链接视图的基石
核心节的功能与属性
节名 内容 权限 链接阶段作用 .text机器指令(代码) R-X合并为可执行段,入口地址由ELF头指定 .data已初始化全局/静态变量 RW合并为可读写数据段 .rodata只读数据(字符串常量等) R合并到代码段(因权限匹配 R-X).bss未初始化变量(磁盘不占空间) RW统计大小,运行时分配零填充内存 .symtab符号表(函数/变量地址映射) - 解析跨文件符号引用(如 main调用run()).got.plt全局偏移表(动态链接跳转入口) RW运行时由动态链接器修改,绑定共享库函数 .interp动态链接器路径 R独立为 PT_INTERP段,供加载器使用节合并的工程价值
- 空间优化:链接器将多个
.text节(如main.o和util.o的代码)合并为单一可执行段,减少内存页分配次数。 - IO效率:连续节合并后,加载器批量读取文件内容。
- 安全隔离:只读节(
.rodata)并入代码段(R-X),防止篡改。
- 空间优化:链接器将多个
三、程序头表:执行视图的蓝图
关键段类型与功能
段类型 作用 对应节 内存权限 PT_LOAD可加载段(代码/数据) .text+.rodata(合并)R-X.data+.bss(合并)RWPT_INTERP动态链接器路径 .interpRPT_DYNAMIC动态链接信息(依赖库列表) .dynamicRWPT_GNU_STACK控制栈权限(如禁止执行) 无直接对应节 标记栈属性 加载流程详解
操作系统加载器按程序头表初始化进程:定位程序头表:通过ELF头中的
e_phoff偏移读取表位置(示例中偏移64字节)。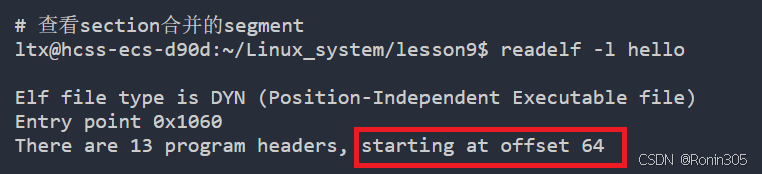
加载
PT_LOAD段:- 代码段:文件偏移→虚拟地址(如
0x0000318),权限设为R-X。 - 数据段:
.bss区分配零填充内存(p_memsz > p_filesz时)。
- 代码段:文件偏移→虚拟地址(如
处理动态依赖:
- 加载
PT_INTERP指定的动态链接器。 - 解析
PT_DYNAMIC中的依赖库(如libc.so)。
- 加载
跳转执行:从入口地址(如
0x1060)启动。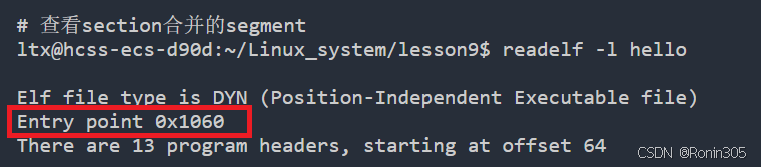
🔍 示例验证:
size hello输出中bss=8,对应数据段的p_memsz - p_filesz = 8。
四、双视图协作:从节到段的转换
链接器生成程序头表的逻辑
- 步骤:
- 收集相同权限的节(如所有
R-X节→代码段)。 - 计算段内存布局:代码段基址(如
0x400000),数据段紧随其后并按页对齐。 - 填充程序头表条目(
p_type,p_flags,p_offset等)。
- 收集相同权限的节(如所有
- 设计价值:
- 空间效率:示例中8字节
.bss独立加载浪费99.8%内存页;合并后仅占0.2%。 - 安全性:
PT_GNU_STACK段标记栈不可执行(RW),防御缓冲区溢出攻击。
- 空间效率:示例中8字节
- 步骤:
视图转换示意图
链接视图(节头表) → 链接器合并 → 执行视图(程序头表) +----------------+ +----------------+ | .text (R-X) | | LOAD Segment1 | +----------------+ 合并为代码段(R-X) | (R-X) | | .rodata (R) | | | +----------------+ +----------------+ | .data (RW) | | LOAD Segment2 | +----------------+ 合并为数据段(RW) | (RW) | | .bss (RW) | +----------------+ +----------------+
五、实践验证:readelf命令分析
节头表分析(链接视图)
$ readelf -S hello Section Headers:[Nr] Name Type Address Offset Size Flags[ 16] .text PROGBITS 0000000000001060 00001060 0000015f AX # 代码节(R-X)[ 18] .rodata PROGBITS 0000000000002000 00002000 0000000d A # 只读数据(R)[ 25] .data PROGBITS 0000000000004000 00003000 00000200 WA # 数据节(RW)- 关键点:
.rodata地址(0x2000)介于.text和.data之间,但因权限为R,实际被合并到代码段(权限R-X)。
- 关键点:
程序头表分析(执行视图)
$ readelf -l hello Program Headers:Type Offset VirtAddr MemSiz Flags AlignLOAD 0x000000 0x0000000000000000 0x5e8 R E 0x1000 # 代码段(含.rodata)LOAD 0x002000 0x0000000000002000 0x210 RW 0x1000 # 数据段(含.bss)- 验证:第一
LOAD段包含.text(0x1060)和.rodata(0x2000),因权限均为只读。
- 验证:第一
我们可以在 ELF头 中找到文件的基本信息,以及可以看到ELF头是如何定位程序头表和节头表的。
ELF头:文件的核心导航
ELF头包含关键定位信息:
ELF Header:Entry point address: 0x1060 # 程序入口地址Start of program headers: 64 (bytes into file) # 程序头表位置Start of section headers: 14032 (bytes into file) # 节头表位置Size of program headers: 56 (bytes) # 每个程序头大小Number of program headers: 13 # 程序头数量Size of section headers: 64 (bytes) # 每个节头大小Number of section headers: 31 # 节头数量加载器工作流程:
读取ELF头前64字节
根据
Start of program headers找到程序头表遍历13个程序头(每个56字节)
按程序头指示将段加载到内存
跳转到
Entry point address(0x1060)执行
小tips:
魔数(Magic Number)是文件开头的一组特定字节序列,用于标识文件的格式。魔数通常位于文件的开头,不同的文件格式都有其特定的魔数。通过检查文件的魔数,系统可以快速判断文件的类型。
魔数工作原理
文件格式标识 :每个文件格式都有其固定的魔数。例如,ELF文件的魔数是以
0x7F开头,接着是E、L、F三个字符对应的ASCII码值,也就是0x45、0x4C、0x46。当系统读取到文件开头的字节序列符合这个魔数时,就能判定这是一个ELF文件。
示例解释
例如我们上文中的ELF头中魔数的十六进制表示为:
7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
前四个字节 :
7f 45 4c 46表示这是一个ELF文件。其中,7f是ELF文件的起始标志,45、4c、46分别对应ASCII字符E、L、F。第五个字节 :
02表示ELF文件的版本号,这里是2,表明这是一个遵循ELF版本2规范的文件。第六个字节 :
01表示文件的字节序,这里是小端字节序(little-endian)。这意味着在存储多字节数据时,最低有效字节存储在最低地址处。第七个字节 :
01表示操作系统的架构类型,这里表示这是一个用于64位架构的操作系统。
魔数在文件识别中的应用
系统文件识别 :操作系统在处理文件时,会读取文件的魔数来快速确定文件的类型。例如,当用户双击一个文件时,系统根据魔数判断文件类型,然后调用相应的程序打开该文件。
文件类型检查工具 :许多工具(如
file命令)也利用魔数来识别文件类型。file命令会读取文件的魔数,并与已知的魔数列表进行比对,从而输出文件的类型信息
对于 ELF HEADER 这部分来说,我们只用知道其作用即可,它的主要目的是定位文件的其他部分。
拓展:ELF 文件区域与偏移量关系
ELF文件中的各个区域(segments)和节(sections)在文件中的位置和大小都通过文件偏移量来描述,这些信息存储在程序头表(Program Header Table)和节头表(Section Header Table)中。
一、ELF 文件区域与偏移量基础
ELF 文件由四大结构化区域构成,各区域的偏移量关系如下:
| 区域 | 定位方式 | 大小/偏移量依赖 | 作用 |
|---|---|---|---|
| ELF 头 | 固定偏移 0 | 独立存在 | 定义文件类型、入口点、程序头表/节头表位置 |
| 程序头表 | ELF 头的 e_phoff 字段指定 | 表项数由 e_phnum 定义 | 描述段(Segment)的加载信息 |
| 节头表 | ELF 头的 e_shoff 字段指定 | 表项数由 e_shnum 定义 | 描述节(Section)的链接信息 |
| 节/段内容区 | 程序头表的 p_offset 或节头表的 sh_offset | 由 p_filesz 或 sh_size 定义 | 存储实际代码/数据 |
📌 关键验证:示例中
readelf -h hello显示:
- 程序头表偏移:
64字节- 节头表偏移:
14032字节
二、偏移量关系的三层映射体系
1. 物理文件层(磁盘存储)
文件按连续字节流存储,各区域通过偏移量精确锚定:
文件偏移示例:
0x0000 ┌──────────────┐ ELF 头 (64字节)│Magic/类型/入口点│
0x0040 ├──────────────┤ 程序头表 (56字节×13=728字节)│PT_LOAD/INTERP│
0x0368 ├──────────────┤ .text 节 (代码)│ 机器指令 │
0x2000 ├──────────────┤ .data 节 (初始化数据)│ 全局变量值 │
0x36D0 └──────────────┘ 节头表 (描述31个节)
🔍 设计逻辑:
- ELF 头固定起始位置(偏移0),作为根导航器
- 程序头表紧接 ELF 头(如偏移64),避免碎片化访问
- 节内容区按功能分组存储(代码→数据→调试信息)
- 节头表置于文件末尾,因其在运行时不需要加载
2. 链接视图(节头表管理)
节头表(Section Header Table)通过 sh_offset 定位各节:
| 节名 | sh_offset 作用 | 示例值 | 权限 |
|---|---|---|---|
.text | 代码起始偏移(如 0x1060) | 0x0318 → 0x1556 | R-X |
.data | 初始化数据偏移(如 0x2000) | 0x3DB0 → 0x3DC8 | RW |
.rodata | 只读数据偏移 | 未显示 | R |
.bss | 无文件偏移(内存中分配) | 大小 8 字节 | RW |
⚠️ 特殊案例:
.bss节:文件无存储空间(sh_size=0),但需在内存分配空间- 重叠节:多个节可能共享相同文件偏移(如
.text包含.rodata)
3. 执行视图(程序头表管理)
程序头表(Program Header Table)通过 p_offset 定位段:
| 段类型 | p_offset 作用 | 内存映射 | 包含的节 |
|---|---|---|---|
PT_LOAD | 可加载段起始偏移 | VirtAddr → VirtAddr+MemSiz | .text + .rodata (代码段) / .data + .bss (数据段) |
PT_INTERP | 动态链接器路径偏移 | 不直接加载 | .interp |
PT_DYNAMIC | 动态链接信息偏移 | 加载到数据段 | .dynamic |
🔧 映射示例(
readelf -l hello隐含逻辑):程序头表项: Type: PT_LOAD (代码段)Offset: 0x00000000 VirtAddr: 0x400000FileSiz: 0x1556MemSiz: 0x1556Flags: R-E → 包含 .text (0x1060-0x1556)Type: PT_LOAD (数据段)Offset: 0x00002000 VirtAddr: 0x402000FileSiz: 0x018 → .data 文件内容MemSiz: 0x020 → 含 .bss 扩展内存
验证:
MemSiz - FileSiz = 8与size命令的bss=8一致 。
三、偏移量设计的工程价值
1. 空间效率最大化
- 节合并优化:链接器将相同权限的节(如
.text和.rodata)合并为段,减少内存碎片📏 例:100 个 8 字节变量独立加载需 400KB 内存;合并后仅 4KB
.bss零存储:未初始化数据不占文件空间,仅运行时分配内存
2. 加载性能优化
- 连续 IO:程序头表描述连续段(如
Offset=0x2000, FileSiz=0x1000),触发操作系统批量读取 - 按需加载:动态链接库仅加载被引用的段(通过
.got.plt偏移定位)
3. 安全与隔离
- 权限隔离:通过
p_flags将可执行段(R-X)与数据段(RW)物理分离,阻止代码注入 - 地址随机化:加载时
VirtAddr可偏移,但文件内Offset固定不变
结论:偏移量关系的本质
ELF 文件的偏移量体系是物理存储(文件)与逻辑执行(内存)的桥梁:
- 文件层:通过 链式偏移(ELF头→程序头→节内容→节头)实现紧凑存储
- 链接层:节头表的
sh_offset实现精准符号定位(如.symtab记录函数偏移) - 执行层:程序头表的
p_offset指导按段加载,映射到虚拟地址 - 优化核心:偏移量设计平衡了 空间效率(合并节)、加载性能(连续IO)、安全隔离(权限分离)三大需求
7. 理解链接与加载
7.1 静态链接
静态链接是将多个目标文件(.o)及静态库(本质是.o的归档)合并为单一可执行文件的过程。其核心任务是 符号解析 和 重定位:
- 符号解析:链接器建立符号引用(如函数调用)与符号定义(如函数实现)的关联 。
- 重定位:修正代码中符号的地址引用,使其指向正确的内存位置 。
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ ll
total 24
drwxrwxr-x 2 ltx ltx 4096 Jul 30 17:46 ./
drwxrwxr-x 11 ltx ltx 4096 Jul 29 16:35 ../
-rw-rw-r-- 1 ltx ltx 62 Jul 29 16:37 code.c
-rw-rw-r-- 1 ltx ltx 1496 Jul 29 16:38 code.o
-rw-rw-r-- 1 ltx ltx 102 Jul 29 16:36 hello.c
-rw-rw-r-- 1 ltx ltx 1560 Jul 29 16:38 hello.o
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ gcc *.o -o main.exe
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ ll
total 40
drwxrwxr-x 2 ltx ltx 4096 Jul 30 17:47 ./
drwxrwxr-x 11 ltx ltx 4096 Jul 29 16:35 ../
-rw-rw-r-- 1 ltx ltx 62 Jul 29 16:37 code.c
-rw-rw-r-- 1 ltx ltx 1496 Jul 29 16:38 code.o
-rw-rw-r-- 1 ltx ltx 102 Jul 29 16:36 hello.c
-rw-rw-r-- 1 ltx ltx 1560 Jul 29 16:38 hello.o
-rwxrwxr-x 1 ltx ltx 16016 Jul 30 17:47 main.exe*
查看编译后的.o目标文件
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ objdump -d code.ocode.o: file format elf64-x86-64Disassembly of section .text:0000000000000000 <run>:0: f3 0f 1e fa endbr64 4: 55 push %rbp5: 48 89 e5 mov %rsp,%rbp8: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # f <run+0xf>f: 48 89 c7 mov %rax,%rdi12: e8 00 00 00 00 call 17 <run+0x17>17: 90 nop18: 5d pop %rbp19: c3 ret
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ objdump -d hello.ohello.o: file format elf64-x86-64Disassembly of section .text:0000000000000000 <main>:0: f3 0f 1e fa endbr64 4: 55 push %rbp5: 48 89 e5 mov %rsp,%rbp8: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # f <main+0xf>f: 48 89 c7 mov %rax,%rdi12: e8 00 00 00 00 call 17 <main+0x17>17: b8 00 00 00 00 mov $0x0,%eax1c: e8 00 00 00 00 call 21 <main+0x21>21: b8 00 00 00 00 mov $0x0,%eax26: 5d pop %rbp27: c3 ret
objdump -d 命令:将代码段(.text)进行反汇编查看
hello.o 中的 main 函数不认识 printf和run 函数, code.o 不认识 printf 函数
// hello.c
#include<stdio.h>
void run();int main() {printf("hello world!\n");run();return 0;
}// code.c
#include<stdio.h>
void run() {printf("running...\n");
}
在反汇编的输出中可以看到:
- 对于
hello.o中的main函数,调用printf和run的地址都是0 - 对于
code.o中的run函数,调用printf的地址也是0
# hello.o 中的调用
12: e8 00 00 00 00 call 17 <main+0x17> # 调用printf
1c: e8 00 00 00 00 call 21 <main+0x21> # 调用run# code.o 中的调用
12: e8 00 00 00 00 call 17 <run+0x17> # 调用printf这是因为编译器在编译单个源文件时:
不知道外部函数的具体地址
不知道数据段/代码段的最终布局
需要保留位置供链接器填充
目标文件中的未解析符号:重定位的起点
1. 编译时的占位符机制
- 当编译器遇到外部符号(如
printf或run)时,因无法确定其地址,生成指令时使用 0 占位 。
2. 重定位表:链接器的修正指南
每个目标文件包含 重定位表(如 .rel.text),记录需要修正的位置及其类型 :
- 重定位项结构:
r_offset:需修正的指令在文件中的偏移量(如call指令的操作数位置)。r_info:符号索引 + 重定位类型(绝对地址/相对地址修正)。r_addend:附加常数(通常为0)。
- 修正类型:
- 绝对寻址(
R_X86_64_32) :用于全局变量,直接替换为符号的绝对地址。 - 相对寻址(
R_X86_64_PC32) :用于函数调用,替换为符号与下条指令的地址差 。
- 绝对寻址(
📌 关键点:
示例中的call指令需进行 相对地址修正(R_X86_64_PC32),因为函数调用依赖与当前指令指针(PC)的偏移 。
链接器的重定位过程:分步拆解
1. 符号解析:构建全局符号表
链接器扫描所有目标文件,提取符号定义(如 run 在 code.o 中)和引用(如 main 调用 run),构建全局符号表:
- 若符号未定义(如未链接
libc.a),链接报错undefined reference。 - 示例中,
main和run均在合并的.o文件中,故符号可解析。
2. 地址分配:合并同类型段
链接器将所有目标文件的段按类型合并:
.text段合并为代码段,.data段合并为数据段 。- 为每个符号分配运行时地址(如
run()的入口地址)。
3. 重定位修正:覆盖占位符
遍历重定位表,根据符号地址修正指令:
绝对寻址修正:
// 修正前(假设符号地址为0x400500) movl $0x0, 0x4(%esp) // 占位符0// 修正后 movl $0x400500, 0x4(%esp) // 替换为符号绝对地址相对寻址修正(示例中的函数调用):
// 修正前(call指令的操作数占位0) 1c: e8 00 00 00 00 call 21 <main+0x21> // 修正后(假设run在0x401250 1c: e8 2f 01 00 00 call 401250 <run>计算:
0x401250 - (0x40101c + 5) = 0x12F→ 小端存储为2F 01 00 00注:实际计算时需考虑指令长度和地址对齐 。
静态库的链接:本质相同
静态库(如 libc.a)是多个目标文件的归档(ar 打包)。链接时:
- 链接器从库中提取被引用的目标文件(如包含
printf的.o)。 - 重定位过程与普通目标文件完全一致 。
设计意义:为何需要重定位?
- 分离编译的必然性
大型项目分模块编译,编译器无法预知其他模块的符号地址 。 - 地址空间隔离
每个目标文件的代码段默认从地址0开始,链接后需按全局布局调整地址 。 - 静态库的按需加载
避免将整个库链接进可执行文件,仅提取必要目标文件 。
在链接过程中,地址重定位是一个关键步骤,主要涉及对目标文件(.o文件)中的外部符号进行地址解析和修正。具体来说:
符号解析阶段:
- 链接器会扫描所有输入的目标文件,建立全局符号表
- 对于每个未定义的符号引用,查找对应的符号定义
- 例如,当main.o中调用了printf()函数时,链接器会在其他目标文件或库中查找printf的定义
重定位处理:
- 确定每个符号在最终输出文件中的绝对地址
- 修改目标代码中的相对地址引用为绝对地址
- 包括对函数调用、全局变量引用等地址的修正
具体实现方式:
- 对于函数调用:修正call指令的操作数
- 对于数据访问:修正mov等指令的内存地址操作数
- 处理重定位表(relocation table)中的各项记录
典型应用场景:
- 静态链接时多个目标文件的合并
- 动态链接时PLT(过程链接表)的建立
- 可执行文件加载时的地址空间布局随机化(ASLR)
这个过程确保了程序中的各个模块能够正确引用彼此的函数和数据,最终形成一个可以正确执行的完整程序映像。
7.2 ELF加载与进程地址空间
虚拟地址/逻辑地址
下面是objdump -S main.exe之后的反汇编代码
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ objdump -S main.exemain.exe: file format elf64-x86-64Disassembly of section .init:0000000000001000 <_init>:1000: f3 0f 1e fa endbr64 1004: 48 83 ec 08 sub $0x8,%rsp1008: 48 8b 05 d9 2f 00 00 mov 0x2fd9(%rip),%rax # 3fe8 <__gmon_start__@Base>100f: 48 85 c0 test %rax,%rax1012: 74 02 je 1016 <_init+0x16>1014: ff d0 call *%rax1016: 48 83 c4 08 add $0x8,%rsp101a: c3 ret Disassembly of section .plt:0000000000001020 <.plt>:1020: ff 35 9a 2f 00 00 push 0x2f9a(%rip) # 3fc0 <_GLOBAL_OFFSET_TABLE_+0x8>1026: f2 ff 25 9b 2f 00 00 bnd jmp *0x2f9b(%rip) # 3fc8 <_GLOBAL_OFFSET_TABLE_+0x10>102d: 0f 1f 00 nopl (%rax)1030: f3 0f 1e fa endbr64 1034: 68 00 00 00 00 push $0x01039: f2 e9 e1 ff ff ff bnd jmp 1020 <_init+0x20>103f: 90 nopDisassembly of section .plt.got:0000000000001040 <__cxa_finalize@plt>:1040: f3 0f 1e fa endbr64 1044: f2 ff 25 ad 2f 00 00 bnd jmp *0x2fad(%rip) # 3ff8 <__cxa_finalize@GLIBC_2.2.5>104b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)Disassembly of section .plt.sec:0000000000001050 <puts@plt>:1050: f3 0f 1e fa endbr64 1054: f2 ff 25 75 2f 00 00 bnd jmp *0x2f75(%rip) # 3fd0 <puts@GLIBC_2.2.5>105b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)Disassembly of section .text:0000000000001060 <_start>:1060: f3 0f 1e fa endbr64 1064: 31 ed xor %ebp,%ebp1066: 49 89 d1 mov %rdx,%r91069: 5e pop %rsi106a: 48 89 e2 mov %rsp,%rdx106d: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp1071: 50 push %rax1072: 54 push %rsp1073: 45 31 c0 xor %r8d,%r8d1076: 31 c9 xor %ecx,%ecx1078: 48 8d 3d e4 00 00 00 lea 0xe4(%rip),%rdi # 1163 <main>107f: ff 15 53 2f 00 00 call *0x2f53(%rip) # 3fd8 <__libc_start_main@GLIBC_2.34>1085: f4 hlt 1086: 66 2e 0f 1f 84 00 00 cs nopw 0x0(%rax,%rax,1)108d: 00 00 00 0000000000001090 <deregister_tm_clones>:1090: 48 8d 3d 79 2f 00 00 lea 0x2f79(%rip),%rdi # 4010 <__TMC_END__>1097: 48 8d 05 72 2f 00 00 lea 0x2f72(%rip),%rax # 4010 <__TMC_END__>109e: 48 39 f8 cmp %rdi,%rax10a1: 74 15 je 10b8 <deregister_tm_clones+0x28>10a3: 48 8b 05 36 2f 00 00 mov 0x2f36(%rip),%rax # 3fe0 <_ITM_deregisterTMCloneTable@Base>10aa: 48 85 c0 test %rax,%rax10ad: 74 09 je 10b8 <deregister_tm_clones+0x28>10af: ff e0 jmp *%rax10b1: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)10b8: c3 ret 10b9: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)00000000000010c0 <register_tm_clones>:10c0: 48 8d 3d 49 2f 00 00 lea 0x2f49(%rip),%rdi # 4010 <__TMC_END__>10c7: 48 8d 35 42 2f 00 00 lea 0x2f42(%rip),%rsi # 4010 <__TMC_END__>10ce: 48 29 fe sub %rdi,%rsi10d1: 48 89 f0 mov %rsi,%rax10d4: 48 c1 ee 3f shr $0x3f,%rsi10d8: 48 c1 f8 03 sar $0x3,%rax10dc: 48 01 c6 add %rax,%rsi10df: 48 d1 fe sar %rsi10e2: 74 14 je 10f8 <register_tm_clones+0x38>10e4: 48 8b 05 05 2f 00 00 mov 0x2f05(%rip),%rax # 3ff0 <_ITM_registerTMCloneTable@Base>10eb: 48 85 c0 test %rax,%rax10ee: 74 08 je 10f8 <register_tm_clones+0x38>10f0: ff e0 jmp *%rax10f2: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)10f8: c3 ret 10f9: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)0000000000001100 <__do_global_dtors_aux>:1100: f3 0f 1e fa endbr64 1104: 80 3d 05 2f 00 00 00 cmpb $0x0,0x2f05(%rip) # 4010 <__TMC_END__>110b: 75 2b jne 1138 <__do_global_dtors_aux+0x38>110d: 55 push %rbp110e: 48 83 3d e2 2e 00 00 cmpq $0x0,0x2ee2(%rip) # 3ff8 <__cxa_finalize@GLIBC_2.2.5>1115: 00 1116: 48 89 e5 mov %rsp,%rbp1119: 74 0c je 1127 <__do_global_dtors_aux+0x27>111b: 48 8b 3d e6 2e 00 00 mov 0x2ee6(%rip),%rdi # 4008 <__dso_handle>1122: e8 19 ff ff ff call 1040 <__cxa_finalize@plt>1127: e8 64 ff ff ff call 1090 <deregister_tm_clones>112c: c6 05 dd 2e 00 00 01 movb $0x1,0x2edd(%rip) # 4010 <__TMC_END__>1133: 5d pop %rbp1134: c3 ret 1135: 0f 1f 00 nopl (%rax)1138: c3 ret 1139: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)0000000000001140 <frame_dummy>:1140: f3 0f 1e fa endbr64 1144: e9 77 ff ff ff jmp 10c0 <register_tm_clones>0000000000001149 <run>:1149: f3 0f 1e fa endbr64 114d: 55 push %rbp114e: 48 89 e5 mov %rsp,%rbp1151: 48 8d 05 ac 0e 00 00 lea 0xeac(%rip),%rax # 2004 <_IO_stdin_used+0x4>1158: 48 89 c7 mov %rax,%rdi115b: e8 f0 fe ff ff call 1050 <puts@plt>1160: 90 nop1161: 5d pop %rbp1162: c3 ret 0000000000001163 <main>:1163: f3 0f 1e fa endbr64 1167: 55 push %rbp1168: 48 89 e5 mov %rsp,%rbp116b: 48 8d 05 9d 0e 00 00 lea 0xe9d(%rip),%rax # 200f <_IO_stdin_used+0xf>1172: 48 89 c7 mov %rax,%rdi1175: e8 d6 fe ff ff call 1050 <puts@plt>117a: b8 00 00 00 00 mov $0x0,%eax117f: e8 c5 ff ff ff call 1149 <run>1184: b8 00 00 00 00 mov $0x0,%eax1189: 5d pop %rbp118a: c3 ret Disassembly of section .fini:000000000000118c <_fini>:118c: f3 0f 1e fa endbr64 1190: 48 83 ec 08 sub $0x8,%rsp1194: 48 83 c4 08 add $0x8,%rsp1198: c3 ret
问题 1:ELF 程序未加载时是否存在地址?
答案:存在逻辑地址(虚拟地址)
ELF 程序在磁盘上时已具备完整的逻辑地址布局,这是现代计算机采用 平坦模式(Flat Mode) 的必然要求。编译器在生成可执行文件时,会从 地址 0 开始对代码、数据等所有元素进行统一编址,形成连续的虚拟地址空间。
关键机制解析
编址原理
- 逻辑地址 = 起始地址(0) + 偏移量:如
objdump -S main.exe输出中左侧的地址列(各段都有明确的起始地址(如.init段从0000000000001000开始),各函数都有固定的偏移地址(如_start函数位于0000000000001060)),这些地址在程序加载前已确定。 - 作用:确保函数、变量等符号的地址在编译后固定,为链接器和加载器提供统一的寻址基准。
- 逻辑地址 = 起始地址(0) + 偏移量:如
平坦模式的核心价值
- 线性编址:CPU 通过 段基址寄存器置 0 实现逻辑地址到线性地址的直接映射。
- 兼容性:支持现代操作系统的虚拟内存机制,简化地址转换流程。
验证示例
反汇编输出片段:0000000000001060 <_start>:1060: f3 0f 1e fa endbr64 1064: 31 ed xor %ebp,%ebp1060是_start函数的逻辑地址,在磁盘文件中已固化。
问题 2:进程内存结构初始化数据来源
答案:数据源于 ELF 文件的程序头表(Program Header Table)
进程创建时,内核通过解析 ELF 的程序头表,提取 Segment 信息 初始化 mm_struct 和 vm_area_struct。
初始化流程详解
数据结构作用
结构体 功能 初始化来源 mm_struct管理进程的整个虚拟地址空间 ELF 的 PT_LOAD段信息vm_area_struct描述虚拟内存区域(代码段/数据段等)的属性(起始地址、长度、权限) ELF Segment 的 p_vaddr,p_memsz,p_flags具体步骤
- Step 1:读取程序头表
内核定位 ELF 头的e_phoff字段,获取程序头表位置(示例中偏移64字节)。 - Step 2:映射 PT_LOAD 段
// 伪代码:基于 Segment 初始化 vma for (每个 PT_LOAD 段) {vma = kmalloc(sizeof(vm_area_struct));vma->vm_start = segment.p_vaddr; // 如 0x1060(代码段)vma->vm_end = segment.p_vaddr + segment.p_memsz;vma->vm_flags = segment.p_flags; // 如 R-X(代码段)、RW(数据段)insert_vma(mm, vma); // 插入 mm_struct }
- Step 1:读取程序头表
注意:
- 代码段(.text)通常从固定虚拟地址开始(如0x400000)
- 数据段(.data)、BSS段等有预定的布局规则
- Step 3:特殊段处理
- 堆空间初始化:
set_brk()函数设置堆的起止地址(mm->start_brk = mm->brk),初始为空。 - 动态链接器加载:
若存在PT_INTERP段(如/lib64/ld-linux-x86-64.so.2),将其映射到内存映射区域。
- 堆空间初始化:
示例验证
ELF 头信息(readelf -h main.exe):Entry point address: 0x1060 // 进程从 _start 开始执行 Start of program headers: 64 // 程序头表位置 Number of program headers: 13 // 含多个 PT_LOAD 段- 内核用
PT_LOAD段的p_vaddr=0x1060(代码段)、p_memsz=文件大小初始化vm_area_struct。
- 内核用
设计意义:从磁盘到内存的协同
编译器与操作系统的协作
- 编译器:生成逻辑地址,确保符号位置固定。
- 操作系统:将逻辑地址平移至进程虚拟地址空间(如
0x1060→ 实际虚拟地址0x400000+1060)。
零页优化
.bss段在文件中无实体(p_filesz=0),但内核根据p_memsz分配归零内存,节省磁盘空间。安全隔离
- 权限分离:代码段(R-X)与数据段(RW)的
vm_flags不同,阻止代码注入。 - 地址随机化(ASLR) :加载时基址随机偏移,但段内逻辑地址关系不变。
- 权限分离:代码段(R-X)与数据段(RW)的
再谈进程虚拟地址空间
ELF(Executable and Linkable Format)文件在被编译完成后,会在其头部结构中记录程序的关键信息。具体来说,ELF header 中专门设置了一个 Entry 字段,用于存储程序执行时的入口地址。这个地址指向程序代码段(.text section)中 main 函数的起始位置,或者更准确地说,是程序启动后执行的第一条指令所在的内存地址(通常是 _start 而非直接是 main)。
入口地址的实际指向
不是直接指向 main() :而是指向
_start函数(由 C 运行时库提供)_start 的作用:
_start:xor %ebp, %ebp ; 清除帧指针mov (%rsp), %edi ; 获取 argclea 8(%rsp), %rsi ; 获取 argvlea 16(%rsp,%rdi,8), %rdx ; 获取 envpcall __libc_start_main ; 调用初始化函数__libc_start_main 的工作:
- 初始化线程环境
- 调用
main()函数 - 处理
main()的返回值 - 调用
exit()结束进程
下文会详细说明_start的工作机制
当操作系统加载并运行 ELF 可执行文件时,会首先解析 ELF header,读取其中的 Entry 字段值,然后将程序计数器(PC)设置为该地址值,从而开始执行程序。这个机制确保了程序能够从正确的起始位置开始运行。
在典型的 32 位 ELF 格式中,Entry 字段位于 ELF header 的第 24 字节处,占用 4 个字节;而在 64 位 ELF 格式中,它位于第 24 字节处,占用 8 个字节。开发者可以使用 readelf 或 objdump 等工具查看这个入口地址的具体数值。
例如,使用命令:
readelf -h [文件名]
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ readelf -h main.exe
ELF Header:Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64Data: 2's complement, little endianVersion: 1 (current)OS/ABI: UNIX - System VABI Version: 0Type: DYN (Position-Independent Executable file)Machine: Advanced Micro Devices X86-64Version: 0x1Entry point address: 0x1060 #Entry字段Start of program headers: 64 (bytes into file)Start of section headers: 14032 (bytes into file)Flags: 0x0Size of this header: 64 (bytes)Size of program headers: 56 (bytes)Number of program headers: 13Size of section headers: 64 (bytes)Number of section headers: 31Section header string table index: 30
可以在输出结果中看到类似"Entry point address: 0x1060"这样的信息,这就是程序的实际入口地址。这个地址的具体值由链接器(ld)在链接阶段确定,并受到链接脚本、代码布局等多种因素的影响。
从磁盘到内存的地址转换:
一、ELF 文件的预编址机制与虚拟地址空间基础
ELF 的逻辑地址预定义
- 未加载时的地址存在性:ELF 文件在磁盘中已通过逻辑地址(或称虚拟偏移地址)进行统一编址,编译器采用 平坦模式(Flat Mode) 从地址
0开始布局所有代码和数据。 - 入口地址固化:ELF 头中的
e_entry字段(32 位占 4 字节,64 位占 8 字节)存储程序入口地址(如上面示例中的0x1060),该地址指向_start而非直接指向main。 - 验证工具:
readelf -h main.exe | grep "Entry point" # 输出:0x1060 objdump -d --start-address=0x1060 main.exe # 反汇编入口代码
- 未加载时的地址存在性:ELF 文件在磁盘中已通过逻辑地址(或称虚拟偏移地址)进行统一编址,编译器采用 平坦模式(Flat Mode) 从地址
虚拟地址空间的构成要素
区域 作用 ELF 来源 权限 典型地址 (x86-64) 代码段 存储可执行指令 .text节R-X 0x400000-0x401000数据段 已初始化全局变量 .data节RW- 0x601000-0x602000BSS 段 未初始化全局变量(零填充) .bss节(磁盘无内容)RW- 紧邻数据段 堆 动态分配内存(malloc) 无直接对应,运行时扩展 RW- 0x700000-0x800000栈 局部变量/函数调用 无直接对应 RW- 0x7ffffffff000内存映射区 动态库/文件映射 PT_INTERP(如 ld.so)R-X/RW 0x7f0000000000📌 注:权限分离(R/W/X)是安全隔离的核心机制。
二、从磁盘到虚拟地址空间的转换过程
1. 内核加载流程(基于程序头表)
解析程序头表:
内核读取 ELF 头的e_phoff定位程序头表(示例中偏移64字节),遍历PT_LOAD段:// 内核源码伪代码 (fs/binfmt_elf.c) for (i = 0; i < elf_ex->e_phnum; i++) {if (phdr[i].p_type == PT_LOAD) {// 计算虚拟地址:Vaddr = phdr[i].p_vaddr + 加载基址// 映射内存:mmap(Vaddr, phdr[i].p_memsz, PROT_READ | PROT_EXEC, ...)} }虚拟地址空间初始化:
- 固定基址 + 逻辑偏移:
逻辑地址0x1060→ 虚拟地址0x400000 + 0x1060 = 0x401060。 - ASLR(地址随机化):
若启用 ASLR,加载基址随机偏移(如0x555555550000),但段内逻辑关系不变:// 实际虚拟地址 = 随机基址 + p_vaddr vaddr = random_base + phdr[i].p_vaddr; // 如 0x555555551060
- 固定基址 + 逻辑偏移:
- 特殊段处理:
.bss段优化:磁盘中不占用空间(p_filesz=0),内存分配零填充页。- 动态链接器加载:
PT_INTERP指定的ld.so被映射到内存映射区。
2. 进程内存结构初始化
mm_struct与vm_area_struct:
内核为每个PT_LOAD段创建vm_area_struct,记录虚拟地址范围、权限和文件映射关系:struct vm_area_struct {unsigned long vm_start; // 如 0x400000unsigned long vm_end; // 如 0x401000pgprot_t vm_page_prot; // 如 PROT_READ | PROT_EXECstruct file *vm_file; // 指向 ELF 文件 };入口地址激活:
通过start_thread(regs, elf_entry)设置RIP=0x401060,启动程序执行。
三、从虚拟地址到物理地址的转换机制
1. MMU 与页表的核心作用
转换流程:

页表层级结构(x86-64 四级页表):
| 层级 | 字段位范围 | 作用 |
|---|---|---|
| PML4 | 47-39 | 顶级页目录 |
| PDP | 38-30 | 页目录指针 |
| PD | 29-21 | 页目录 |
| PT | 20-12 | 页表 |
| Offset | 11-0 | 页内偏移(4KB 页) |
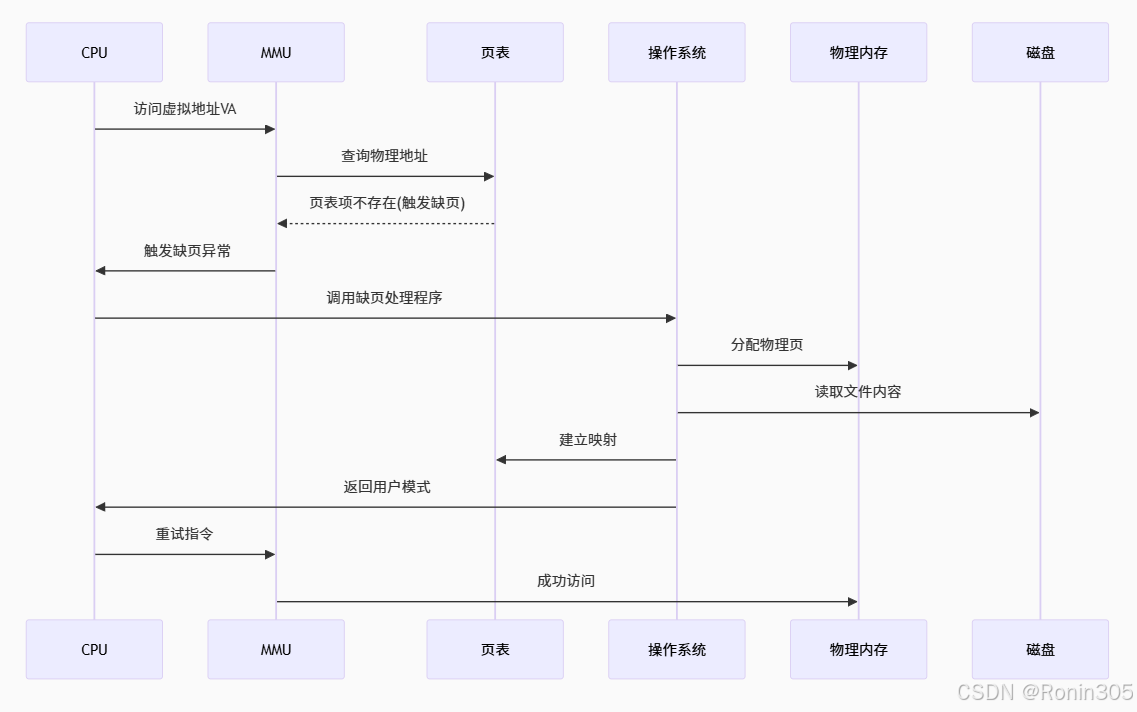
2. 缺页中断的详细处理
中断触发条件:
- 访问未映射的虚拟地址(如首次访问
.bss段)。 - 权限违规(如写只读页)。
- 访问未映射的虚拟地址(如首次访问
内核响应流程:
do_page_fault(vaddr) {if (vaddr 在 vm_area 范围内) {分配物理页;若为文件映射(如代码段),从磁盘读取内容;若为匿名映射(如堆),填充零;更新页表项;} else {发送 SIGSEGV 信号; // 段错误} }
流程图示例:
四、全流程实例验证
| 阶段 | 地址类型 | 值 | 工具验证 |
|---|---|---|---|
| 磁盘文件 | 逻辑地址 | 0x1060 (_start) | objdump -d main.exe |
| 加载后 | 虚拟地址 | 0x401060 (ASLR 关闭) | gdb -p $pid : info proc mappings |
| 首次执行指令 | CPU 访问虚拟地址 | 0x401060 | gdb : info reg rip |
| MMU 转换 | 物理地址 | 0x89ab000 | sudo cat /proc/$pid/pagemap |
从磁盘到内存的完整旅程
磁盘阶段:
ELF文件包含预设的虚拟地址
程序头表定义加载布局
加载阶段:
创建进程虚拟地址空间
建立VMA映射关系
初始化页表(无物理映射)
执行阶段:
CPU访问虚拟地址
MMU触发缺页异常
内核分配物理页
从磁盘读取内容
建立页表映射
恢复程序执行
优化阶段:
COW减少内存复制
页面缓存加速访问
交换机制释放内存
一张图总结:
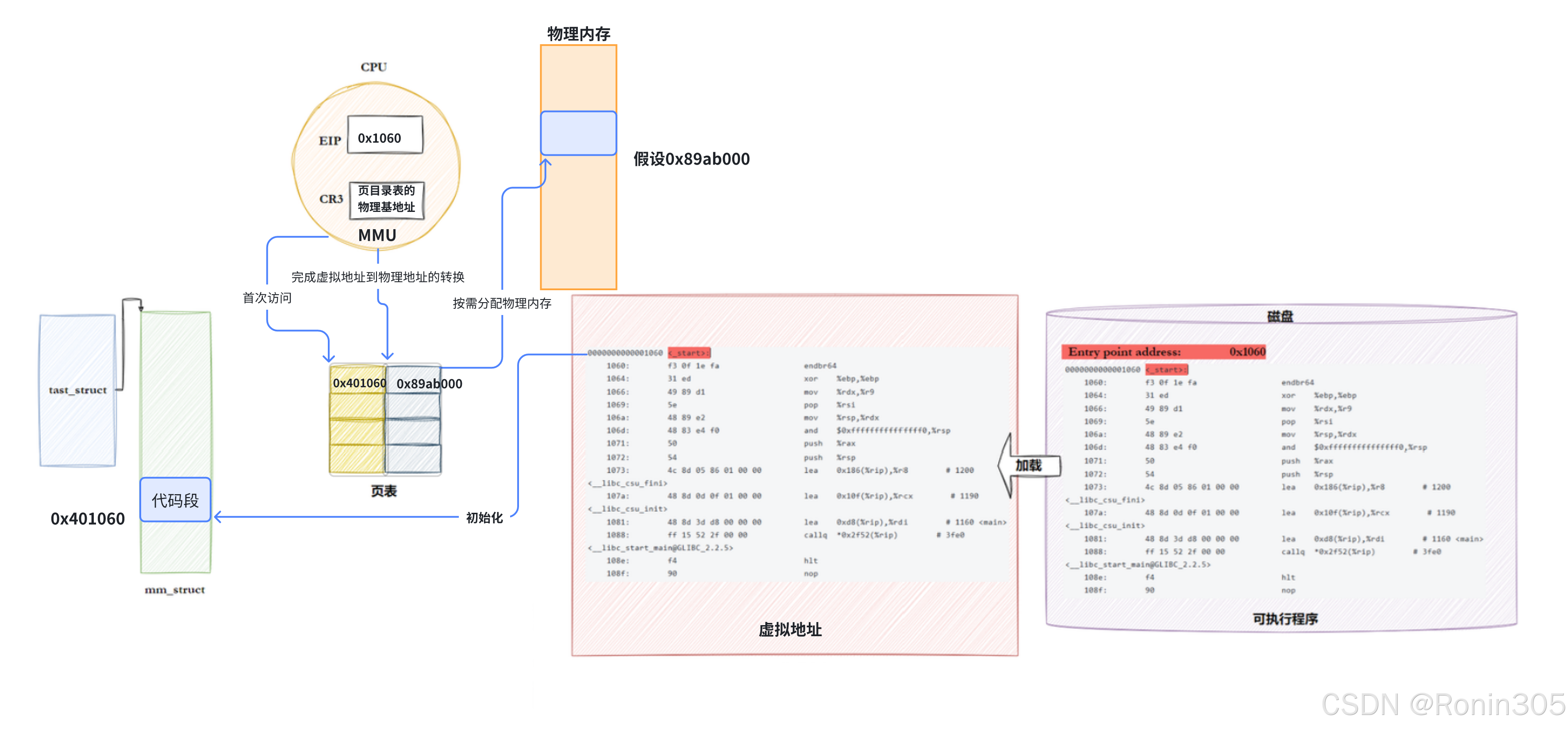
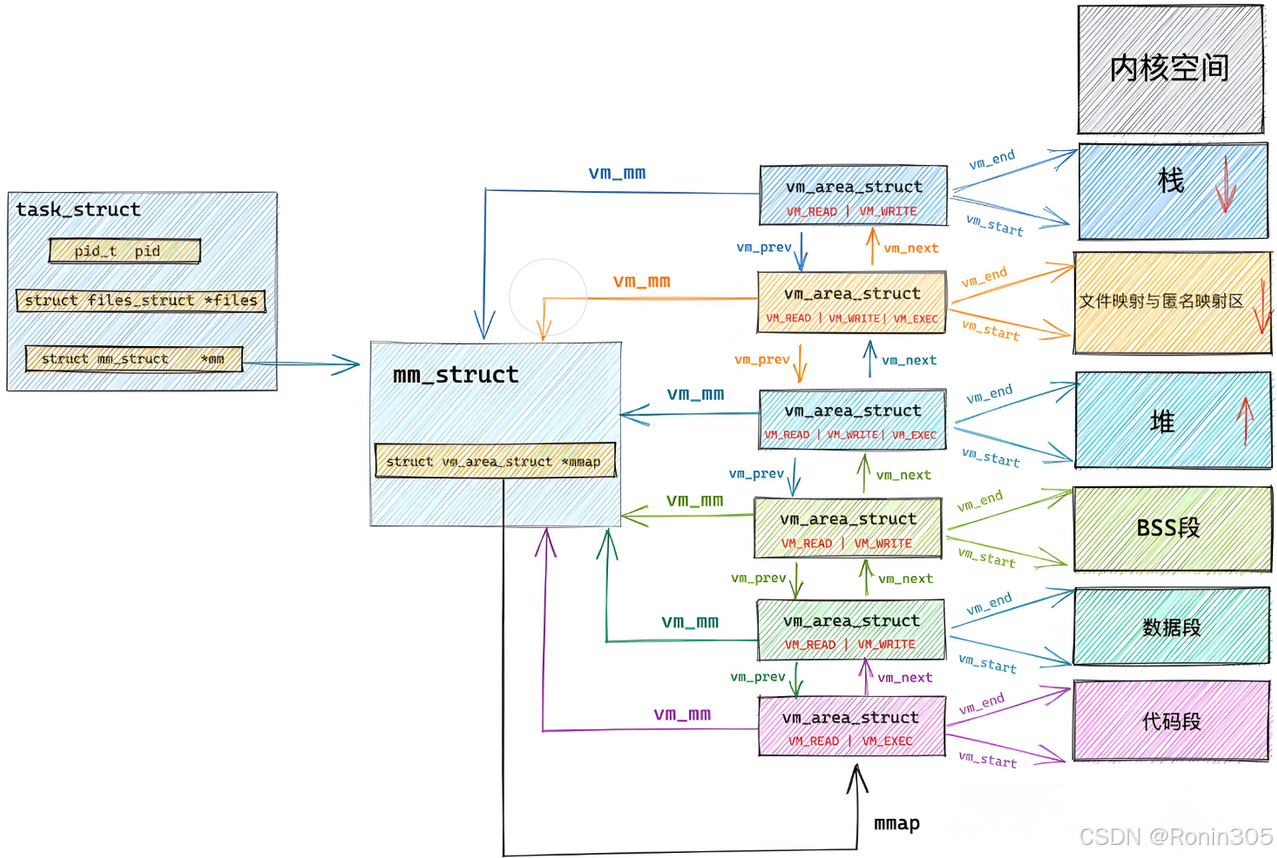
核心结论:
从磁盘到内存的地址转换是逻辑地址→虚拟地址→物理地址的三级映射过程:
- 编译时:平坦模式固化逻辑地址。
- 加载时:程序头表驱动虚拟地址空间构建。
- 运行时:MMU 通过页表动态转换物理地址。
这一机制在保证效率的同时,通过权限隔离、随机化、零页优化实现了安全与性能的平衡。
7.3 动态链接与动态库加载
进程如何看到动态库
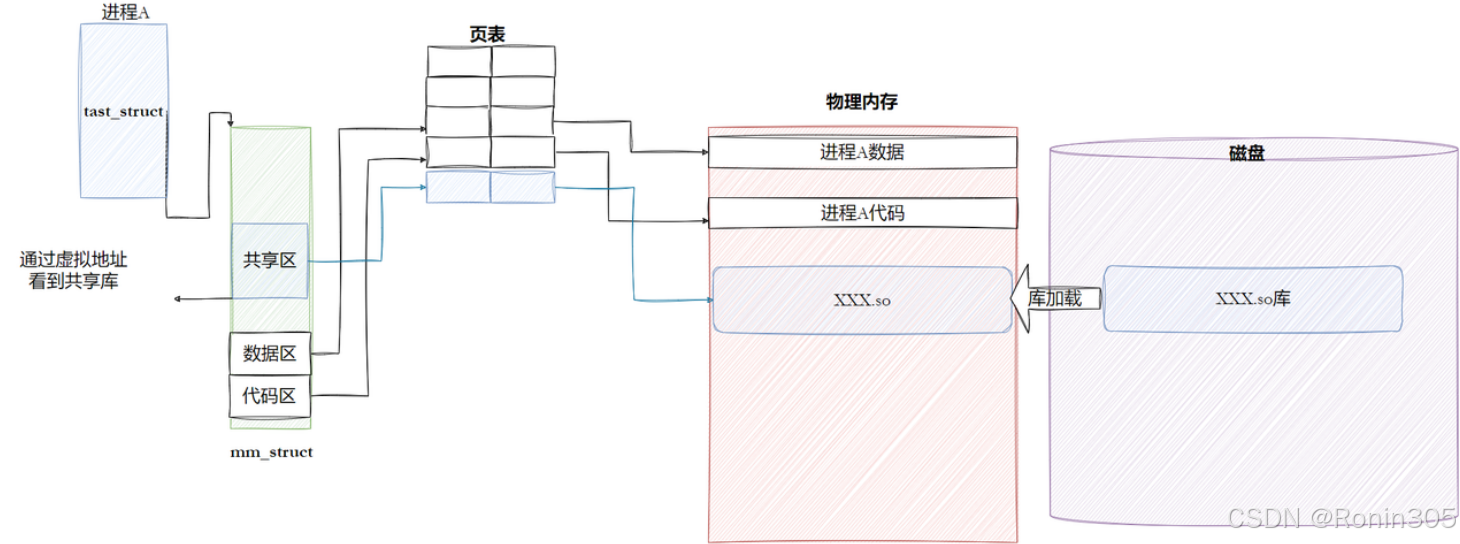
注意:磁盘上的内容不会直接加载到物理内存上,而是通过操作系统的虚拟内存管理机制间接完成,详细过程如上文再谈进程虚拟地址空间。上图和下图中简化了中间的过程,但我们要知道,心里有数。
进程间如何共享库的
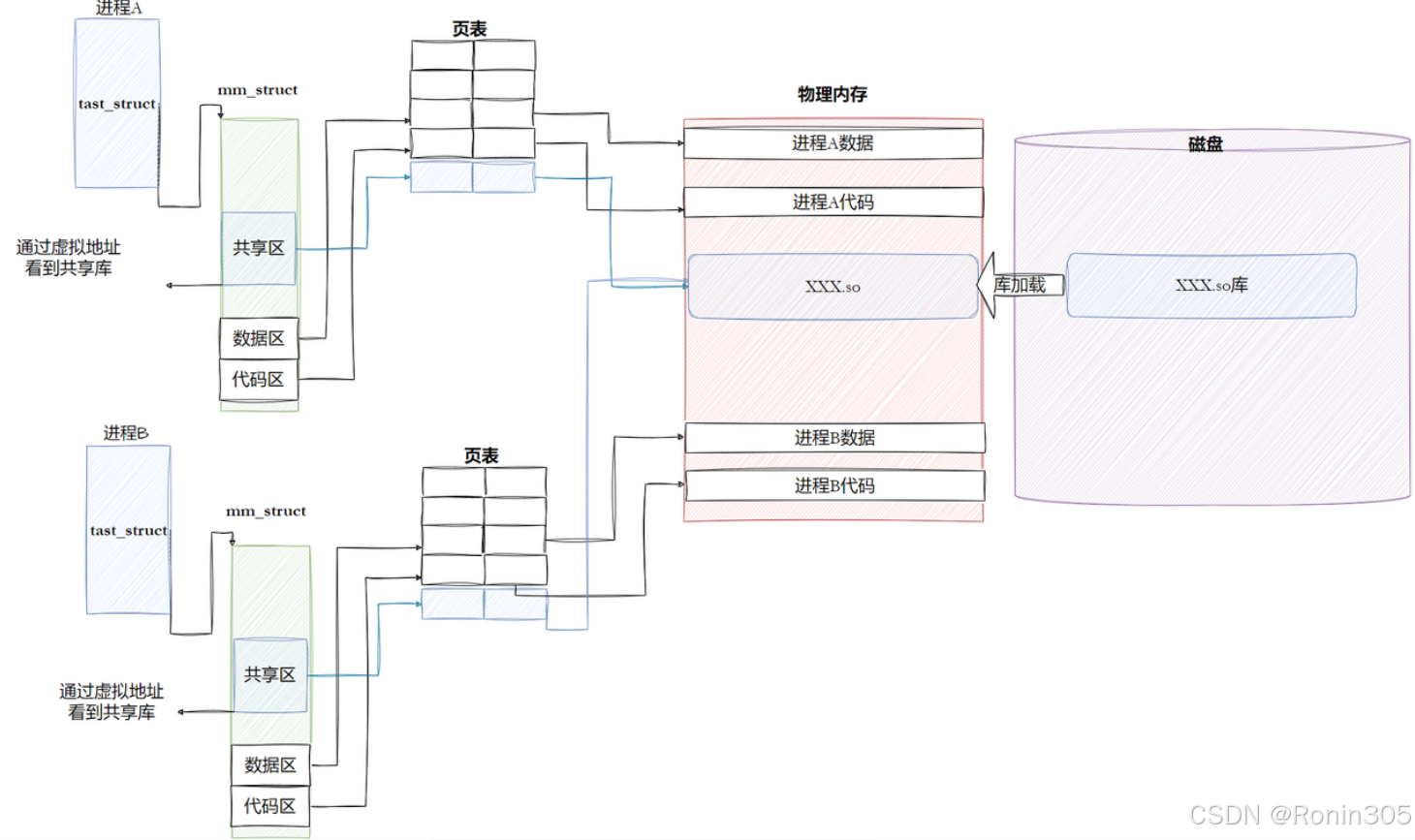
动态链接
动态链接在现代操作系统中远比静态链接要常用得多,这已经成为软件开发中的标准实践。让我们通过一个具体的例子来深入了解:当我们查看main.exe这个可执行程序的依赖关系时,会发现它依赖几个关键的动态库:
ltx@hcss-ecs-d90d:~/Linux_system/lesson9$ ldd main.exelinux-vdso.so.1 (0x00007ffe12ff9000)libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ff61129d000)/lib64/ld-linux-x86-64.so.2 (0x00007ff6114d3000)
这里,ldd命令是一个非常有用的工具,它能够打印出程序或库文件所依赖的共享库列表。在上面的输出中:
linux-vdso.so.1是内核提供的一个虚拟动态共享对象,用于加速系统调用libc.so.6是C语言的标准运行时库,提供了诸如printf、malloc、strcpy等常用函数ld-linux-x86-64.so.2是动态链接器/加载器本身
那么为什么现代编译器通常默认使用动态链接而不是静态链接呢?静态链接确实有一个明显的优势:它会将所有目标文件和所需的库合并成一个独立的可执行文件,不需要额外的依赖就能运行,这在某些特定场景下(如嵌入式系统)很有用。
然而,静态链接存在几个严重的问题:
文件体积问题:静态链接生成的可执行文件通常比动态链接版本大很多。例如,一个简单的Hello World程序,静态链接版本可能达到几MB,而动态链接版本可能只有几十KB。
内存浪费:当多个程序都静态链接了相同的库(如libc)时,这些相同的代码会在内存中存在多个副本。例如,如果同时运行10个静态链接的程序,libc的代码会在内存中存在10份。
更新维护困难:当需要更新某个库时(比如修复安全漏洞),静态链接的程序需要全部重新编译,而动态链接的程序只需要更新共享库即可。
动态链接的工作原理可以总结为"延迟绑定"——它将链接的整个过程推迟到了程序加载的时候。具体工作流程如下:
- 程序启动时,操作系统首先加载程序的可执行文件到内存
- 动态链接器(
ld-linux.so)读取程序的动态段(.dynamic section),获取需要加载的共享库列表 - 操作系统为每个共享库分配地址空间,采用地址空间布局随机化(ASLR)技术确保安全性
- 动态链接器执行重定位操作,修正所有需要引用的外部符号地址
- 对延迟绑定的函数(PLT条目),会在第一次调用时才进行实际绑定
这个过程的关键创新在于:
- 共享库可以被多个进程共享,节省内存
- 库的更新不需要重新编译主程序
- 通过延迟绑定技术提高程序启动速度
- 地址随机化提高了系统安全性
现代操作系统如Linux、Windows和macOS都广泛采用这种动态链接机制,它是支撑现代软件生态的基础技术之一。
关键机制:
C/C++程序启动机制详解
程序启动流程
在C/C++程序中,当程序开始执行时,它首先并不会直接跳转到main函数。实际上,程序的入口点是_start,这是由C运行时库(通常是glibc)或链接器(如ld)提供的特殊函数。这个过程是操作系统和C运行时环境密切配合的结果。
_start函数执行流程
在_start函数中,会执行一系列关键的初始化操作:
设置堆栈
- 操作系统(如Linux内核)在加载可执行文件时,会为程序分配虚拟地址空间
_start函数负责建立初始的栈指针(ESP/RSP),设置栈帧- 示例:在x86_64架构上,栈指针会被初始化为进程栈空间的最高地址
初始化数据段
- 处理
.data段(已初始化的全局变量和静态变量) - 处理
.bss段(未初始化的全局变量和静态变量),将其内存区域清零 - 处理
.rodata段(只读数据)的映射 - 这些段的位置信息来自ELF文件头中的程序头表(Program Header Table)
- 处理
动态链接
- 这是最复杂的关键步骤,
_start函数会调用动态链接器的代码 - 动态链接器会解析和加载程序所依赖的所有共享库(shared libraries)
- 具体流程包括:
- 解析
.dynamic段中的DT_NEEDED条目,获取依赖库列表 - 加载这些库到内存中(可能涉及延迟加载机制)
- 执行符号解析和重定位操作
- 处理全局偏移表(GOT)和过程链接表(PLT)
- 解析
- 示例:当程序调用
printf()时,动态链接器会确保调用能正确跳转到libc中的实现
- 这是最复杂的关键步骤,
调用__libc_start_main
- 这个glibc函数负责完成C运行时环境的最终设置
- 执行的操作包括:
- 初始化线程局部存储(TLS)
- 设置线程栈保护(Stack Guard)
- 初始化atexit()处理程序
- 设置locale环境
- 注册信号处理函数
- 在多线程程序中,还会初始化线程支持库
调用main函数
__libc_start_main最终调用用户编写的main函数- 将命令行参数(argc, argv)和环境变量(envp)传递给main
- 此时程序的控制权才正式交给开发者代码
处理main函数的返回值
- 当main返回时,返回值被传递给
__libc_start_main - 执行所有注册的atexit()处理程序
- 调用
_exit系统调用终止程序 - 将main的返回值作为进程退出状态返回给操作系统
- 当main返回时,返回值被传递给
动态链接器详解
主要功能
动态链接器(如Linux上的ld-linux.so)是程序运行时加载的核心组件,负责:
- 解析程序中的动态库依赖(DT_NEEDED)
- 加载共享对象到内存地址空间
- 执行符号解析和重定位
- 处理延迟绑定(Lazy Binding)
- 维护全局符号表
加载机制
搜索路径:
- 默认路径:
/lib,/usr/lib - 由
LD_LIBRARY_PATH环境变量指定的路径 /etc/ld.so.conf中配置的路径(通常包含/etc/ld.so.conf.d/目录下的文件)- 二进制文件中嵌入的
RPATH或RUNPATH
- 默认路径:
缓存系统:
/etc/ld.so.cache是ldconfig工具生成的二进制缓存- 包含系统中所有已知共享库的优化索引
- 通过
ldconfig -p可以查看缓存内容
符号解析:
- 使用广度优先搜索算法解析符号
- 处理符号版本控制(Versioning)
- 解决符号冲突和多重定义问题
性能优化
- 预链接(Pre-linking):通过
prelink工具预先计算库的加载地址,减少运行时重定位开销 - 延迟加载(Lazy Binding):通过PLT/GOT机制推迟符号解析,直到第一次调用
- 共享库缓存:避免重复加载相同库的不同实例
环境配置
重要环境变量
LD_LIBRARY_PATH:- 冒号分隔的目录列表,动态链接器会优先在这些路径中查找共享库
- 示例:
export LD_LIBRARY_PATH=/opt/mylibs:$LD_LIBRARY_PATH
LD_PRELOAD:- 指定要优先加载的共享库,可用于函数拦截
- 常用于调试或修改程序行为
LD_DEBUG:- 控制动态链接器的调试输出
- 常用值:
files(显示库加载)、symbols(显示符号解析)、bindings(显示绑定信息)
配置文件
/etc/ld.so.conf:- 主配置文件,包含动态库搜索路径
- 通常通过
include /etc/ld.so.conf.d/*.conf包含其他配置
/etc/ld.so.preload:- 系统级的预加载库配置
- 每行列出一个库的全路径
开发者视角
虽然这些底层细节对大多数开发者是透明的,但了解它们有助于:
调试问题:
- 诊断库加载失败(如
error while loading shared libraries) - 解决符号冲突问题
- 分析程序启动性能瓶颈
- 诊断库加载失败(如
性能优化:
- 减少不必要的库依赖
- 优化库搜索路径
- 使用适当的链接选项(如
-Wl,-rpath)
安全考虑:
- 防止库劫持攻击
- 确保使用正确版本的库
- 控制动态链接器的行为
跨平台开发:
- 不同系统(Linux/Windows/macOS)有不同的动态链接机制
- 了解这些差异有助于编写可移植代码
理解这些底层机制可以让开发者更好地掌控程序的整个生命周期,从启动到终止的每个环节。
动态库中的相对地址机制
动态库(Dynamic Link Library, DLL)为了实现灵活的加载和内存映射功能,采用了相对地址的编址方案。这种设计使得动态库能够在不同的进程地址空间中正确运行,无论被加载到内存的哪个位置。
工作原理:
相对编址:
- 动态库中的所有函数和变量地址都是相对于库基地址的偏移量
- 例如,一个函数在库中的偏移量为0x1000,当库被加载到0x400000时,其实际地址为0x401000
加载时重定位:
- 操作系统加载器负责将动态库映射到进程地址空间
- 加载时根据实际加载地址调整所有相对地址
- 在Windows中称为"重定位",在Linux中称为"位置无关代码"(PIC)
平坦内存模型:
- 现代操作系统都采用平坦内存模型(Flat Memory Model)
- 所有进程共享同一个连续的虚拟地址空间
- 可执行程序(exe)也遵循这个规则,但它通常被加载到固定地址
实际应用示例:
- 当多个进程加载同一个动态库时:
- 进程A可能将库加载到0x10000000
- 进程B可能将库加载到0x20000000
- 但库内部的所有函数调用都使用相同的相对偏移
技术实现细节:
- ELF格式(Unix/Linux)使用.got(全局偏移表)和.plt(过程链接表)
- PE格式(Windows)使用导入地址表(IAT)和重定位节区
- 编译器通过-fPIC(Position Independent Code)选项生成位置无关代码
这种设计使得:
- 动态库可以被多个进程共享
- 避免了地址冲突问题
- 提高了内存使用效率
- 支持动态加载和卸载
程序与动态库的映射机制及函数调用
文件加载与内存映射
- 操作系统通过open()系统调用打开库文件
- 使用mmap()系统调用将库文件映射到进程的虚拟地址空间
- 映射时会建立从文件偏移到虚拟地址的对应关系
文件操作底层:
- 动态库作为磁盘文件,需通过
open()打开 → 获取文件描述符(fd)。 - 使用
mmap()将文件映射到虚拟地址空间:// 伪代码:动态链接器映射库文件 void* addr = mmap(NULL, // 由内核选择映射地址lib_size, // 库文件大小PROT_READ|PROT_EXEC, // 代码段权限MAP_SHARED, // 多进程共享fd, // 库文件描述符0 // 文件偏移 );
虚拟地址空间映射机制
1. 共享区(Shared Region)的核心地位
| 区域 | 起始地址(x86-64) | 内容 | 权限 | 物理内存共享 |
|---|---|---|---|---|
| 栈区 | ~0x7FFFFFFFFFFF | 局部变量/调用栈 | RW- | 否 |
| 共享区 | 0x7F0000000000 | 动态库映射 | R-X/RW | 是 |
| 堆区 | 0x00600000 | malloc内存 | RW- | 否 |
| 数据段 | 0x00601000 | 全局变量 | RW- | 否 |
| 代码段 | 0x00400000 | 程序指令 | R-X | 否 |
- 验证工具:
cat /proc/1234/maps # 查看进程内存映射 7f3a5a200000-7f3a5a3e0000 r-xp 00000000 08:01 /lib/libc.so.6 # 代码段(共享) 7f3a5a5e0000-7f3a5a5e4000 r--p 001e0000 08:01 /lib/libc.so.6 # 只读数据(共享) 7f3a5a5e4000-7f3a5a5e6000 rw-p 001e4000 08:01 /lib/libc.so.6 # 可写数据(COW)
符号表合并
动态链接器构建全局符号表:
struct Symbol {const char *name;Elf64_Addr value;Elf64_Addr size;
};符号解析优先级:
可执行文件符号
先加载库的符号
后加载库的符号
函数调用机制
- 当程序调用库函数时:
- CPU通过PLT(Procedure Linkage Table)跳转
- 第一次调用会触发延迟绑定,由动态链接器解析实际地址
- 后续调用直接通过GOT中的地址跳转
结合图示:
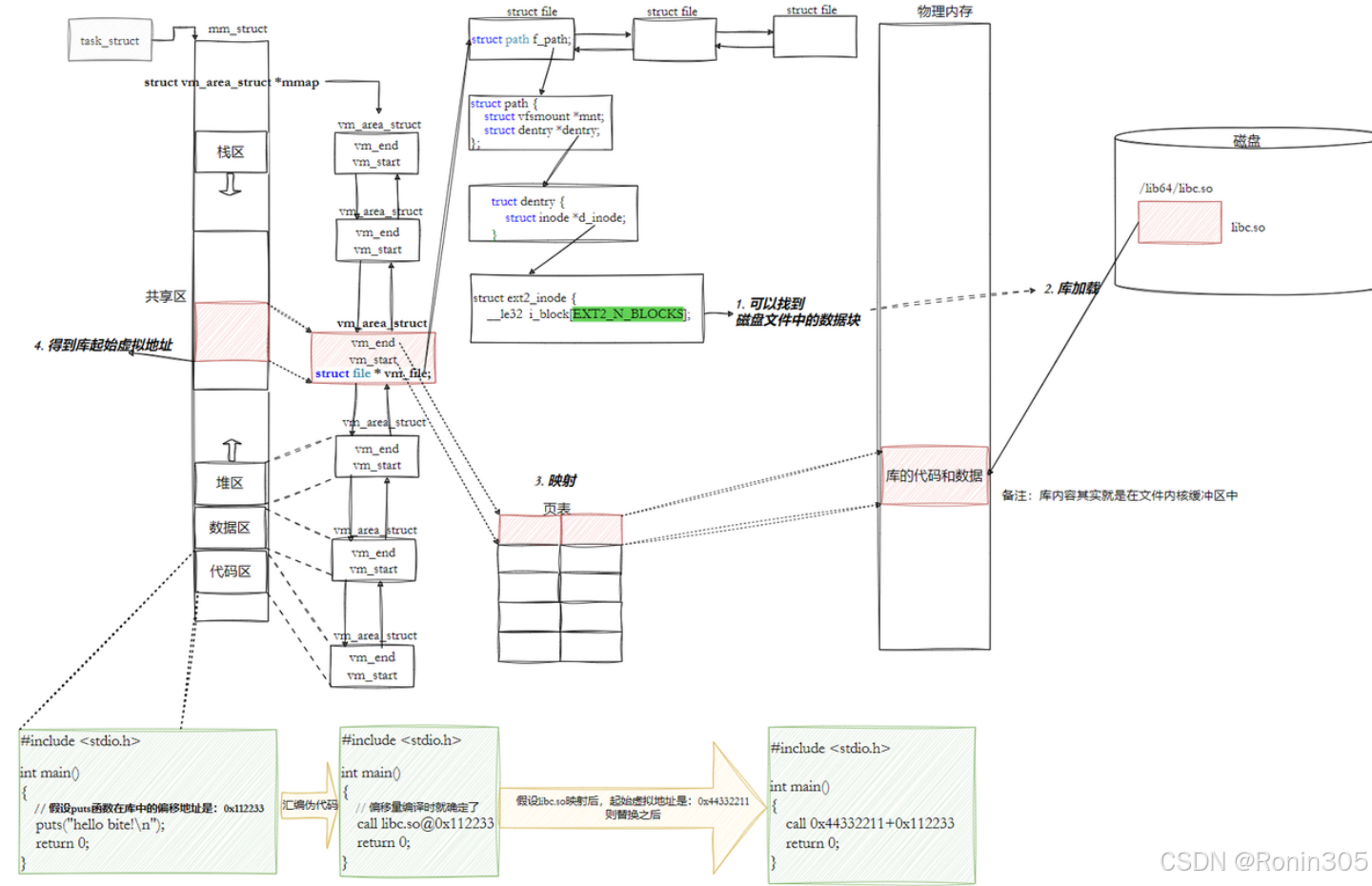
全局偏移量表GOT(global offset table)
📌 核心要点:
• 在程序运行之前,需要先把所有依赖的动态链接库加载并映射到内存中。此时,所有库的起始虚拟地址都应该被确定下来。
• 然后对已加载到内存中的程序进行库函数调用的地址修正,这个过程称为"加载地址重定位"(load-time relocation)。
• 这里存在一个关键问题:代码区(.text)在进程中是只读的,我们无法直接修改其中的跳转地址。那么如何实现这种地址修正呢?
解决方案:动态链接采用在.data段(可执行程序或库自身)中专门预留一块区域来存放函数的跳转地址,这块区域被称为全局偏移表GOT(Global Offset Table)。表中的每一项都记录着本运行模块需要引用的全局变量或函数的真实地址。
一、GOT 的设计背景与核心问题
代码段只读的约束
- 代码段(
.text)在进程内存中为只读(R-X),禁止运行时修改(安全机制防御代码注入)。 - 矛盾点:动态链接需根据库加载地址修改函数调用地址,但直接修改代码段会违反内存保护。
- 代码段(
解决方案:数据段动态重定位
动态链接将地址修正转移到 可读写的数据段(.data) ,通过 GOT 表间接跳转:// 伪代码:函数调用流程 call puts@PLT // 1. 跳转到PLT条目 → PLT: jmp *GOT[n] // 2. 间接跳转到GOT存储的地址 → GOT[n] = 0x7f8a3b251100 // 3. 动态库函数真实地址
GOT 表本质:位于 .data 段的函数指针数组,存储外部函数/变量的绝对地址。
二、GOT 表的工作机制
1. 地址生成与修正流程
| 步骤 | 操作 | 关键参与者 |
|---|---|---|
| 1. 库加载 | 动态链接器(ld.so)映射库到共享区 | 内核mmap |
| 2. 地址计算 | 真实地址 = 共享区基址 + 库内偏移 | 动态链接器 |
| 3. GOT更新 | 将真实地址写入进程的GOT表项 | ld.so |
| 4. 函数调用 | 通过PLT→GOT跳转到真实地址 | CPU/MMU |
寻址机制:
- 在单个.so动态库内部,GOT表与.text段的相对位置是固定的
- 可以利用CPU的相对寻址(PC-relative addressing)来定位GOT表
- 示例:
# libc.so 加载基址 (ASLR随机化) 0x7f8a3b200000 # printf 库内偏移 (编译固定) 0x51100 # GOT 存储的最终地址 0x7f8a3b200000 + 0x51100 = 0x7f8a3b251100
2. PIC(地址无关代码)的实现
这种通过GOT表实现的动态链接机制被称为PIC(Position Independent Code,地址无关代码)。它具有以下特点:
- 动态库不需要做任何修改就能被加载到任意内存地址
- 能够被所有进程共享使用同一份物理内存副本
- 这就是为什么在编译动态库时需要指定
-fPIC参数的原因
- 编译要求:
gcc -fPIC -shared - 技术核心:
- 代码段:仅包含相对跳转指令(不依赖绝对地址)。
- 数据段:GOT 表存储绝对地址,通过 固定偏移 访问:
; 访问GOT表示例(x86) lea GOT(%rip), %rax // 加载GOT地址 mov (%rax+index), %rbx // 读取函数指针 jmp *%rbx // 跳转
PIC的实现机制 = 相对编址(PC-relative addressing) + GOT表
应用场景:
- 动态链接库(.so/.dll)的编译
- 地址空间布局随机化(ASLR)的实现基础
- 提高内存使用效率(多个进程共享同一份代码)
三、GOT 表的进程隔离与共享机制
1. 为何进程不能共享 GOT 表?
| 内存区域 | 共享性 | 原因 |
|---|---|---|
代码段(.text) | 多进程共享 | 只读属性+相同物理页 |
GOT 表(.data) | 进程私有 | 1. 不同进程库加载基址不同(ASLR) 2. 需存储进程专属的绝对地址 |
2. 物理内存优化
- 代码段共享:所有进程映射到同一物理页(只读属性)。
- 数据段隔离:GOT 表及库数据段使用 写时复制(COW):
// 伪代码:写时复制触发 if (进程修改GOT表) {复制物理页;更新页表指向新物理页; }
关键结论:GOT 表的核心价值
解决只读约束
通过将地址修正转移到可写的.data段,绕过代码段不可修改的限制。实现地址无关性(PIC)
- 代码段:相对跳转(位置无关)。
- 数据段:GOT 存储绝对地址 + 固定偏移访问。
平衡效率与安全
- 效率:延迟绑定减少启动开销。
- 安全:ASLR + RELRO 防御内存攻击。
进程间资源共享
- 代码段:多进程共享物理页。
- 数据段:COW 隔离修改,GOT 表进程私有。
PLT延迟绑定(Lazy Binding)技术
动态链接在程序加载时需要对大量外部函数进行重定位,这一过程会显著增加程序的启动时间。为了优化这一性能问题,现代操作系统采用了延迟绑定(Lazy Binding)技术,也称为PLT(Procedure Linkage Table)机制。
延迟绑定的核心思想是:与其在程序启动时就解析和绑定所有可能用到的动态库函数,不如将这个绑定过程推迟到函数第一次被实际调用时。这种设计基于一个重要的观察:在典型的程序运行过程中,动态库中的许多函数可能永远不会被调用到。例如,一个图像处理程序可能加载了数学库,但只使用了其中的部分数学函数;或者一个程序可能加载了错误处理函数库,但在正常运行时根本不会触发错误处理流程。
具体实现上,延迟绑定通过以下机制工作:
- 在程序启动时,全局偏移表(GOT)中的函数跳转地址会被初始化为指向一段特殊的桩代码(stub code),这段代码位于PLT中
- 当程序第一次调用某个动态库函数时,控制流会先进入这段桩代码
- 桩代码会触发动态链接器的解析过程,通过符号表查找真正的函数地址
- 找到实际函数地址后,动态链接器会更新GOT表中对应的条目
- 后续对该函数的调用将直接通过GOT跳转到实际函数实现,不再需要重复解析
这种机制带来了显著的性能优势:
- 减少了程序启动时的重定位开销
- 避免了为从不使用的函数进行不必要的解析
- 保持了"按需加载"的原则,与动态链接的设计哲学一致
以Linux系统为例,当调用一个动态库函数printf()时:
- 第一次调用会经过PLT桩代码,触发
_dl_runtime_resolve进行符号解析 - 解析完成后,GOT表中
printf的条目会被更新为libc中的实际地址 - 后续调用将直接跳转到libc中的
printf实现
这种优化技术在现代操作系统中被广泛采用,如Linux的glibc、macOS的dyld等都实现了类似的延迟绑定机制,大幅提升了包含大量动态库的程序的启动速度。
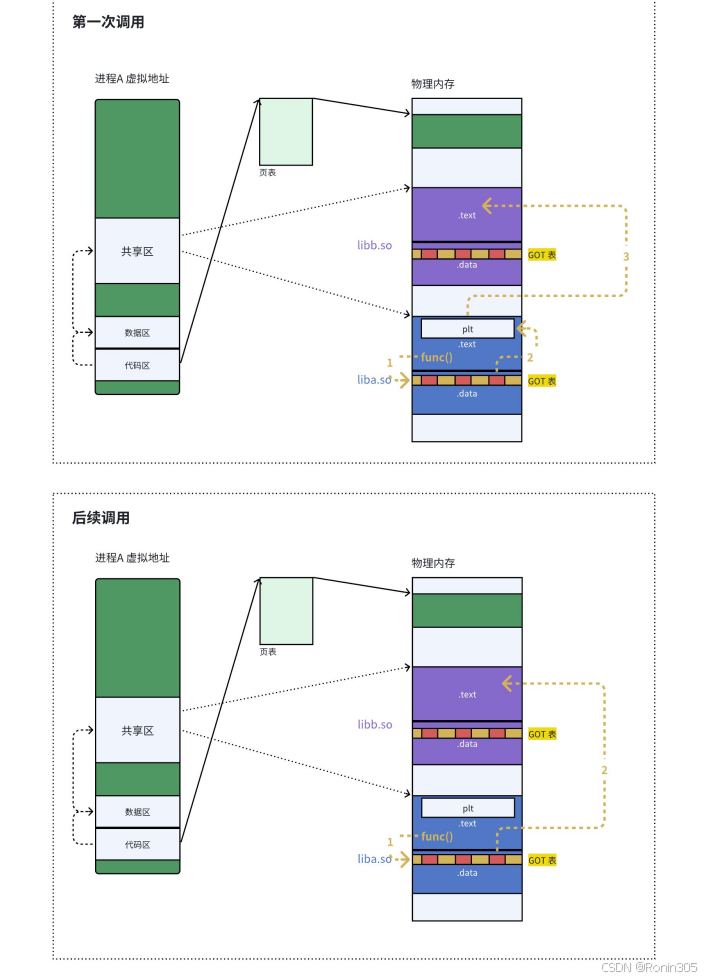
总而言之,动态链接实际上将链接的整个过程从传统的编译时推迟到了程序的运行时。具体来说,这个过程包括:
- 符号查询:程序在运行时通过动态链接器(如Linux的ld.so)查找所需符号
- 地址重定位:将相对地址转换为实际的内存地址
- 库加载:将共享库映射到进程地址空间
这种机制虽然会带来一定的性能开销(大约增加10-15%的函数调用时间)和程序启动延迟(首次加载需要解析符号),但其优势非常显著:
资源利用方面:
- 磁盘空间节省:多个程序可以共享同一个库文件(如glibc.so)
- 内存节省:相同的库代码只需加载一次,被所有使用该库的进程共享
维护便利性:
- 更新库时只需替换.so文件,无需重新编译整个程序
- 可以方便地通过LD_PRELOAD进行库的调试或替换
代码复用:
- 实现了二进制级别的ABI兼容
- 允许不同语言编写的程序复用相同的库
- 支持插件架构(如Nginx模块)
在Linux系统中,典型的动态链接过程是:当执行一个动态链接的可执行文件时,内核首先加载程序解释器(如/lib64/ld-linux-x86-64.so.2),然后由解释器负责加载所有依赖的共享库,解析未定义符号,最后才将控制权转交给程序入口点。