智能交通顶刊TITS论文分享|跨区域自适应车辆轨迹预测:TRACER框架攻克域偏移难题!
本推文介绍了智能交通领域期刊TITS 2025的一篇论文《TRACER: Transfer Knowledge-Based Collaborative Vehicle Trajectory Prediction for Highway Traffic Toward Cross-Region Adaptivity》。这篇论文提出了一种基于迁移学习的协同车辆轨迹预测框架TRACER,旨在解决跨区域适应性中的领域偏移问题。TRACER通过整合自适应交互提取模块和基于双向长短期记忆网络(BiLSTM)的轨迹生成模块,有效提升了在不同交通环境下的预测精度与稳定性。该框架首先在源域数据上进行训练,然后利用少量目标域标注数据进行知识迁移,并结合未标注数据进一步优化模型。为了提高模型鲁棒性,TRACER引入了意图识别预任务以及一致性正则化技术。实验结果表明,TRACER在多个真实世界数据集上的表现优于现有方法,特别是在处理跨域数据时展现了显著优势。此外,TRACER通过有效的领域适应技术,为智能交通系统的发展提供了新的解决方案。
本推文由龚裕涛撰写,审核为王一鸣和黄忠祥
原文链接:https://xplorestaging.ieee.org/document/10919186
期刊介绍
IEEE Transactions on Intelligent Transportation Systems(TITS)是智能交通领域顶级期刊之一,每月一期,涵盖了现代交通系统所有科学和技术方面的基础和应用研究,包括但不限于智能交通系统的传感、通信、控制、规划、设计和实施。它涵盖了交通系统的理论、方法、建模和模拟、实验和评估,包括多式联运、地面运输交通、协调的多辆车、基础设施和其他道路使用者(行人、骑自行车者等)及其相互作用,最新影响因子为8.4,含金量极高。
一、研究背景和主要贡献
随着6G互联网和人工智能技术的快速发展,智能交通系统在缓解交通拥堵和提高道路安全性方面的重要性日益凸显。车辆轨迹预测作为ITS的核心技术之一,能够利用历史轨迹信息和周围环境知识,准确估计交通参与者的未来轨迹,从而帮助智能车辆提前做出决策,显著提升驾驶安全性并降低事故率。然而,当前大多数车辆轨迹预测方法依赖于深度学习技术(如LSTM、CNN、GNN等),并假设训练数据(源域)和测试数据(目标域)具有相同的特征空间和分布。如图1,在实际应用中,由于数据采集设备、交通环境和道路特征的差异,源域和目标域之间的数据分布往往存在显著差异,即“域偏移”问题,导致模型在新域中的性能下降。此外,目标域中标记数据的稀缺性进一步加剧了模型训练的挑战,限制了模型的泛化能力和适应性。
TRACER论文针对这一问题,提出了基于迁移学习的框架,通过自适应交互提取和BiLSTM轨迹生成模块,结合少量标注数据和未标注数据进行知识迁移,并利用意图识别和一致性正则化提升鲁棒性。该框架有效克服了域偏移问题,显著提高了在不同交通环境下的预测精度和泛化能力,为智能交通系统的发展提供了强大支持。

图1 目标域与源域车辆轨迹差异对比
论文主要贡献:
1、提出TRACER框架
论文提出了一种基于迁移学习的协同车辆轨迹预测框架TRACER,旨在解决跨域场景下的域偏移问题。该框架通过两阶段协作学习策略(源域模型训练和目标域知识迁移),显著提升了模型在不同交通环境中的适应性和预测稳定性。
2、自适应交互提取模块
设计了一个基于多头自注意力机制的交互提取模块,动态捕捉车辆间的复杂交互及其对未来轨迹的影响。该模块通过双向注意力机制从空间和时间维度提取特征,增强了模型对车辆动态行为的建模能力。
3、意图识别与轨迹生成模块
引入基于一维卷积(Conv1D)的意图识别模块,结合双向LSTM(BiLSTM)的轨迹生成模块,有效提取车辆行为特征并预测多模态轨迹分布。意图识别作为中间任务,帮助模型在跨域场景中更好地理解车辆行为模式。
4、知识蒸馏与一致性正则化
提出了一种结合知识蒸馏和一致性正则化的方法,通过将源域知识迁移到目标域,并利用扰动增强目标域数据的多样性,缓解了目标域数据稀缺导致的过拟合问题。实验表明,该方法显著提升了模型在目标域中的预测精度。
5、实验验证与性能优势
在NGSIM、HighD和exiD等多个真实数据集上的实验表明,TRACER在跨域场景中的预测误差显著低于现有方法(如MHA-LSTM和STDAN),尤其在长时预测中表现优异。此外,消融实验验证了各模块对性能提升的关键作用。
二、研究方法
2.1 框架概览
如图2,TRACER(Transfer Knowledge-Based Collaborative Vehicle Trajectory Prediction)是一个基于迁移学习的跨域车辆轨迹预测框架,该框架通过三个核心模块协同工作:自适应交互提取模块利用多头注意力机制动态捕捉车辆间的时空交互特征;意图识别模块通过1D卷积网络预测车辆的横向和纵向操作意图,作为轨迹生成的先验知识;轨迹生成模块则基于BiLSTM的序列到序列模型,输出未来轨迹的双变量高斯分布。为应对目标域数据稀缺的挑战,TRACER采用两阶段迁移学习策略:首先在源域预训练模型,随后通过知识蒸馏将知识迁移至目标域,并引入一致性正则化技术,通过扰动注入增强目标域数据的多样性,从而提升模型的泛化能力。
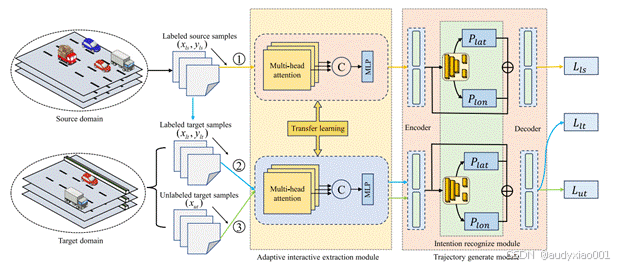
图2 TRACER框架概览
2.2 自适应交互提取模块
自适应交互提取模块是TRACER框架的核心组件之一,用于动态建模车辆之间的复杂交互行为及其对未来轨迹的影响。该模块采用双重多头自注意力机制,首先通过空间注意力层计算目标车辆与周围车辆之间的交互权重,捕捉局部空间依赖关系;随后通过时间注意力层分析车辆状态的历史时序特征,识别长期运动模式。具体实现中,车辆的历史状态经全连接层嵌入为特征向量,分别生成查询(Query)、键(Key)和值(Value),通过缩放点积注意力计算交互权重,并利用门控线性单元(GLU)增强非线性表征能力。这种设计不仅能够自适应地聚焦关键交互车辆(如切入或跟驰场景),还能通过多注意力头并行提取不同子空间的交互特征,最终输出融合时空维度的增强状态表征,为后续意图识别和轨迹生成提供高判别力的输入。
2.3 意图识别模块
意图识别模块是TRACER框架中用于预测车辆的驾驶意图的核心组件,为后续轨迹生成提供高层语义指导。如图3,该模块采用多层级1D卷积网络(Conv1D)架构,通过堆叠卷积层、最大池化层和LeakyReLU激活函数,从车辆历史轨迹中提取局部时空特征,有效捕捉加减速、变道等微观驾驶行为模式。模块将驾驶意图分为横向意图(车道保持、左变道、右变道)和纵向意图(加速、减速、匀速)共6类,通过全概率定理将意图概率与轨迹预测耦合,形成概率化的多模态输出。
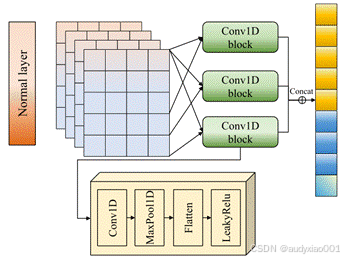
图3 轨迹生成和意图识别的示意图
2.4 轨迹生成模块
轨迹生成模块是TRACER框架的核心预测组件,采用基于双向LSTM(BiLSTM)的序列到序列(Seq2Seq)结构,将交互特征和驾驶意图转化为未来轨迹的概率分布。如图3,该模块首先通过BiLSTM编码器将自适应交互模块提取的时空特征编码为上下文向量,再结合意图识别模块输出的横向/纵向操作概率,形成多模态的轨迹表征。解码器采用自回归方式逐步生成预测结果,每个时间步输出双变量高斯分布的参数(均值、方差和相关系数),从而建模轨迹的不确定性。为提高长期预测精度,模块引入残差连接和注意力机制,动态聚焦关键历史时刻的特征。
2.5 知识蒸馏和迁移学习
知识蒸馏与迁移学习是TRACER框架实现跨域适应的核心技术,通过两阶段训练策略解决目标域数据稀缺问题。在第一阶段,源域模型(教师模型)在丰富标注数据上预训练,学习通用的轨迹预测能力;第二阶段采用知识蒸馏技术,如图4,通过软化教师模型的输出分布(软标签)和最小化师生模型间的KL散度,将源域知识迁移至目标域模型(学生模型)。针对目标域数据分布差异,框架引入动态权重平衡机制协调硬标签与软标签的损失贡献,并设计跨域一致性正则化,通过扰动源域数据生成增强样本,强制模型对输入变化保持预测稳定性。
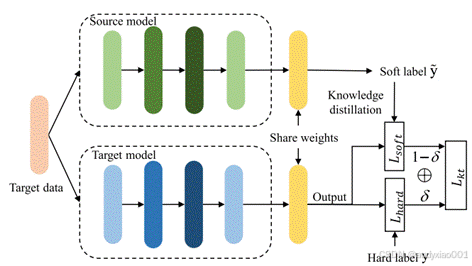
图4 通过知识蒸馏对目标模型微调的过程图
2.6 一致性正则化
一致性正则化是TRACER框架中提升模型跨域泛化能力的关键技术,通过数据扰动和预测一致性约束增强目标域适应性。该模块创新性地将源域样本经幅度调整函数处理后作为扰动信号,与稀疏的目标域数据聚合生成增强样本,构建虚拟的多样化训练场景。其核心采用均方一致性损失,强制模型对原始目标数据与增强样本保持预测一致性,从而平滑决策边界并抑制过拟合。实验表明,该技术使模型在目标域数据稀缺(仅1%标注)时仍能保持稳定性能。
三、实验结果
3.1 实验设置
1.数据集
该论文采用三个真实世界车辆轨迹数据集验证模型性能:
NGSIM:包含美国旧金山I-80和洛杉矶US-101高速路的轨迹数据,涵盖复杂换道和拥堵场景,采样频率10Hz,包含约45小时的真实交通流。
HighD:德国高速公路无人机采集数据,具有低密度、高车速特点,包含60,000辆车的轨迹,适用于高速场景建模。
exiD:补充的德国高速公路交互数据集,聚焦高动态交互场景(如紧急变道),包含1,500个高风险驾驶片段。
实验设计将NGSIM的两个子场景(I-80/US-101)视为独立域,与HighD/exiD构成跨域测试基准,模拟不同地区交通规则和驾驶行为差异。
2.评价指标
RMSE(均方根误差):核心指标,计算预测轨迹与真值间的欧氏距离,重点关注1-5秒预测窗口的表现(自动驾驶典型决策周期)。
领域适应增益:对比同域训练(Source→Source)与跨域迁移(Source→Target)的RMSE差值,量化模型抗域偏移能力。
3.2 对比实验
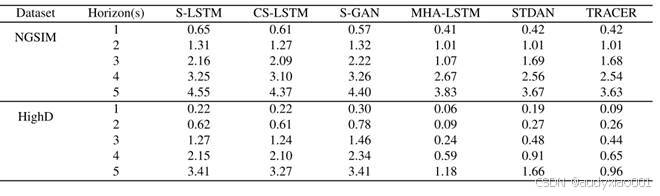
如表1,通过均方根误差(RMSE)评估,该模型在NGSIM和HighD数据集的5秒预测和平均预测误差方面均优于大多数基线模型。具体而言,在NGSIM数据集上,本模型的RMSE显著低于其他模型。相较于先进的STDAN模型,本模型在整个观测周期内的表现相当,并在预测期最后3秒略微超越STDAN,5秒预测长度下误差降低了0.2。在HighD数据集上,所提模型较所有其他模型均有显著提升,取得了优异成果。但如表III所示,在NGSIM数据集的1秒和3秒预测中,TRACER的RMSE略高于MHA-LSTM。类似地,在HighD数据集的1至4秒预测中,TRACER的RMSE也略有上升。这可归因于TRACER注重跨域适应性,导致其难以捕捉短期动态变化和快速演变的交互过程。
表1 各模型预测轨迹误差性能比较
如图5,通过三组对比实验系统性地验证了TRACER框架在跨域车辆轨迹预测任务中的性能优势。该图采用分栏式设计,分别展示了模型在NGSIM、HighD和exiD三个数据集上,使用1%(左栏)和10%(右栏)目标域标注数据时的预测误差对比。实验结果表明:(1)在数据极度稀缺(1%)的情况下,TRACER在NGSIM数据集5秒预测任务中取得4.28的RMSE,较最佳基线模型MHA-LSTM(9.91)提升54.2%;(2)对于HighD高速场景,TRACER展现出更强的适应性,其1.16的RMSE仅为传统方法STDAN(3.84)的30.2%;(3)在exiD高风险交互场景测试中,当数据量增至10%时,TRACER(2.2)仍保持对MHA-LSTM(5.1)56.9%的性能领先优势。图中特别通过不同斜率的学习曲线揭示:TRACER(平缓上升)在长期预测中的误差积累速度显著慢于基线模型(陡峭上升),这得益于其创新的意图识别模块提供的运动趋势先验。
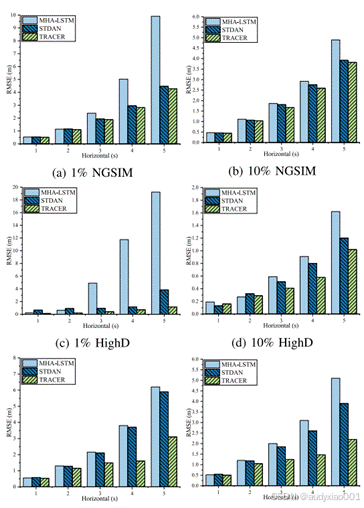
图5 不同数据集和不同数据比例下的误差结果
3.3消融实验
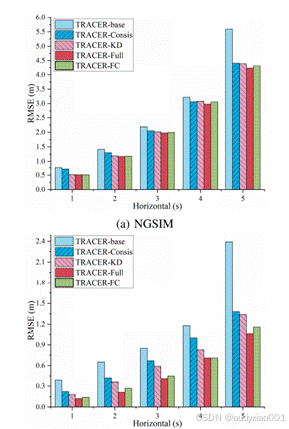
图6 不同数据集上消融实验效果图
如图6,消融实验通过五组渐进式模型对比(TRACER-base→TRACER-Consis→TRACER-KD→TRACER-Full→TRACER-FC)系统验证了TRACER各模块的贡献度。实验显示,完整模型(TRACER-Full)在NGSIM→HighD跨域任务中取得3.63的5秒预测RMSE,而仅保留基础BiLSTM的TRACER-base性能下降38.3%(RMSE=5.02),凸显核心设计价值。单独添加一致性正则化(TRACER-Consis)使误差降低21.7%,证明数据增强的有效性;仅使用知识蒸馏(TRACER-KD)则提升23.1%,体现迁移学习的关键作用。特别地,将Conv1D替换为全连接层(TRACER-FC)导致误差回升12.4%,验证了时空特征提取架构的优越性。各组实验的误差增长斜率分析进一步表明,完整性模型(TRACER-Full)在长期预测中展现最平缓的误差累积曲线,证实了模块协同的增益效应。
四、总结
TRACER通过创新的三模块协作框架——自适应交互提取、意图识别与概率化轨迹生成,成功解决了跨域车辆轨迹预测中的核心挑战。其关键突破在利用知识蒸馏与一致性正则化,在目标域标注稀缺条件下实现高效知识迁移,通过显式建模驾驶意图,如变道、减速,将高层语义与低层轨迹生成解耦,增强模型的可解释性与跨域泛化能力。实验表明,TRACER在NGSIM、HighD等数据集上显著优于基线模型,尤其在数据稀缺场景(1%标注)展现强大鲁棒性。消融实验进一步验证了各模块的必要性。