操作系统系统面试常问(内存、快表、相关知识)
内存的覆盖是什么?有什么特点?
内存覆盖是一种动态内存管理技术,它将程序划分为固定区和覆盖区。固定区存放核心代码和常用数据,覆盖区则按需加载当前需要的非核心模块。当程序需要执行新功能时,系统会将对应模块从外存调入覆盖区,替换掉不再使用的模块。这种技术突破了程序必须全部装入内存才能运行的限制,允许运行比物理内存更大的程序。但要注意只有覆盖区的模块可以被替换,固定区的内容会常驻内存。覆盖技术通过按需加载机制有效提高了内存利用率,特别适合早期内存资源有限的系统环境。
内存交换是什么?有什么特点?
交换(对换)技术的设计思想:内存空间紧张时,系统将内存中某些进程暂时换出外存,把外存中某些已具备运⾏条
件的进程换⼊内存(进程在内存与磁盘间动态调度)
换⼊:将内存中暂时不运行的进程(如阻塞态、低优先级)整体移至磁盘交换区,腾出物理内存空间。
换出:当需要运行被换出的进程时,再将其从磁盘完整载回内存,恢复执行。
内存交换中,被换出的进程保存在哪里?
内存交换技术利用磁盘对换区暂存被换出的进程数据,采用连续分配方式提升I/O速度。与追求空间利用率的文件区不同,对换区通过牺牲部分存储效率来换取更快的进程切换性能,当内存不足时将不活跃进程换出到对换区,需要时快速换入,从而扩展可用内存空间。
在发生内存交换时,有些进程是被优先考虑的?你可以说⼀说吗?
1、可优先换出阻塞进程
2、可换出优先级低的进程
3、为了防⽌优先级低的进程在被调⼊内存后很快⼜被换出,有的系统还会考虑进程在内存的驻留时间… (注意: PCB 会常驻内存,不会被换出外存)
内存交换你知道有哪些需要注意的关键点吗?
1、交换需要备份存储,通常是快速磁盘,它必须⾜够⼤,并且提供对这些内存映像的直接访问。
2、为了有效使⽤CPU,需要每个进程的执⾏时间⽐交换时间⻓,⽽影响交换时间的主要是转移时间,转移时间与所交换的空间内存成正⽐。
3、如果换出进程,⽐如确保该进程的内存空间成正⽐。
4、交换空间通常作为磁盘的⼀整块,且独⽴于⽂件系统,因此使⽤就可能很快。
5、交换通常在有许多进程运⾏且内存空间吃紧时开始启动,⽽系统负荷降低就暂停。
6、普通交换使⽤不多,但交换的策略的某些变种在许多系统中(如UNIX系统)仍然发挥作⽤。
说⼀下你理解中的内存?他有什么作用呢?
内存是用于存放数据的硬件。程序执行前需要先放到内存中才能被CPU处理。
问题:如果多个程序数据需要同时放入到内存中,那么如何区分各个程序的数据放在哪个地方?
方法:给内存的存储单元编地址,内存地址是从0开始,每个地址对应一个存储单元(如果计算机按字节编址,则每个存储单元大小为1字节,即1B,及8个二进制位,如果字长位16位的计算机按字编址,则一个存储单元为1个字;每个字为16个二进制位)
操作系统在对内存进行管理的时候需要做些什么?
1、操作系统负责内存空间的分配与回收。
2、操作系统需要提供某种技术从逻辑上对内存空间进⾏扩充。
3、操作系统需要提供地址转换功能,负责程序的逻辑地址与物理地址的转换。
4、操作系统需要提供内存保护功能。保证各进程在各⾃存储空间内运⾏,互不⼲扰
Windows和Linux环境下内存分布情况
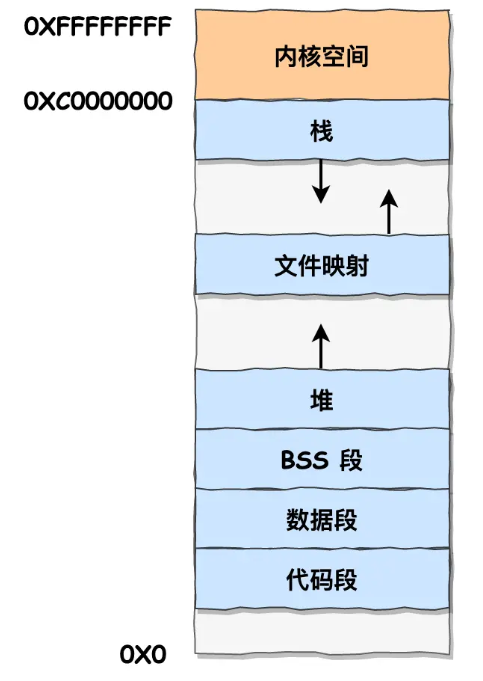
1、程序⽂件段,包括⼆进制可执⾏代码;
2、已初始化数据段,包括静态常量;
3、未初始化数据段,包括未初始化的静态变量;
4、堆段,包括动态分配的内存,从低地址开始向上增⻓;
5、⽂件映射段,包括动态库、共享内存等,从低地址开始向上增⻓(跟硬件和内核版本有关)
6、栈段,包括局部变量和函数调⽤的上下⽂等。栈的⼤⼩是固定的,⼀般是 便我们⾃定义⼤⼩;
⼀个由C/C++编译的程序占用的内存分为哪几个部分?
1、栈区(stack)— 地址向下增⻓,由编译器⾃动分配释放,存放函数的参数值,局部变量的值等。其操作⽅式类似于数据结构中的队列,先进后出。
2、堆区(heap)— 地址向上增⻓,⼀般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆是两回事,分配⽅式倒是类似于链表。
3、全局区(静态区)(static)—全局变量和静态变量的存储是放在⼀块的,初始化的全局变量和静态变量在⼀块区域,未初始化的全局变量和未初始化的静态变量在相邻的另⼀块区域。 - 程序结束后有系统释放
4、⽂字常量区 —常量字符串就是放在这⾥的。程序结束后由系统释放
5、程序代码区(text)—存放函数体的⼆进制代码。
常见内存分配方式有哪些?
1、从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运⾏期间都存在。例如全局变量,static变量。
2、在栈上创建。在执⾏函数时,函数内局部变量的存储单元都可以在栈上创建,函数执⾏结束时这些存储单元⾃动被释放。栈内存分配运算内置于处理器的指令集中,效率很⾼,但是分配的内存容量有限。
3、从堆上分配,亦称动态内存分配。程序在运⾏的时候⽤malloc或new申请任意多少的内存,程序员⾃⼰负责在何时⽤free或delete释放内存。动态内存的⽣存期由我们决定,使⽤⾮常灵活,但问题也最多。
常见的内存分配内存错误
1、内存分配未成功,却使⽤了它(编程新⼿常犯这种错误,因为他们没有意识到内存分配会不成功。常⽤解决办法是,在使⽤内存之前检查指针是否为NULL)
2、内存分配虽然成功,但是尚未初始化就引⽤它(以⽆论⽤何种⽅式创建数组,都别忘了赋初值,即便是赋零值也不可省略,不要嫌麻烦)
3、内存分配成功并且已经初始化,但操作越过了内存的边界(例如在使⽤数组时经常发⽣下标“多1”或者“少1”的操作。特别是在for循环语句中,循环次数很容易搞错,导致数组操作越界)
4、忘记了释放内存,造成内存泄露(动态内存的申请与释放必须配对,程序中malloc与free的使⽤次数⼀定要相同,刚开始时系统的内存充⾜,你看不到错误。终有⼀次程序突然挂掉,系统出现提示:内存耗尽)
5、释放了内存却继续使⽤它(函数的return语句写错了,注意不要返回指向“栈内存”的“指针”或者“引⽤”,因为该内存在函数体结束时被自动销毁。使⽤free或delete释放了内存后,没有将指针设置为NUL。)
从堆和栈上建立对象哪个快?(考察堆和栈的分配效率比较)
从两⽅⾯来考虑:
1、分配和释放,堆在分配和释放时都要调⽤函数(malloc,free),⽐如分配时会到堆空间去寻找⾜够⼤⼩的空间(因为多次分配释放后会造成内存碎⽚),这些都会花费⼀定的时间,具体可以看看malloc和free的源代码,函数做了很多额外的⼯作,而栈却不需要这些。
2、访问时间,访问堆的⼀个具体单元,需要两次访问内存,第⼀次得取得指针,第⼆次才是真正的数据,而栈只需访问⼀次。另外,堆的内容被操作系统交换到外存的概率⽐栈⼤,栈⼀般是不会被交换出去的。
⼀个程序从开始运行到结束的完整过程,你能说出来多少?
预编译
主要处理源代码⽂件中的以“#”开头的预编译指令。处理规则⻅下:
1、宏替换:所有 #define 定义的宏会被直接替换成对应的值或代码,不会保留宏名。
2、条件编译处理:#if、#ifdef、#elif、#else、#endif 等指令会被解析,仅保留符合条件的代码块,其余部分移除。
3、头文件展开:#include 指定的文件内容会被递归插入到当前文件,形成完整的待编译代码。
4、删除注释:所有 // 单行注释和 /* */ 多行注释都会被移除。
5、保留 #pragma 指令:如 #pragma once 等编译器特殊指令会被保留,它们可能影响编译行为(如防止重复包含)。
6、添加行号标记:编译器会插入行号和文件名信息,便于调试和错误定位。
编译
把预编译之后⽣成的xxx.i或xxx.ii⽂件,进⾏⼀系列词法分析、语法分析、语义分析及优化后,⽣成相应的汇编代
码⽂件。
1、词法分析:将代码拆解成记号(如标识符、关键字、运算符等),类似于“分词”过程。
2、语法分析:根据语法规则,将记号组合成语法树,检查代码结构是否正确(如括号匹配、语句格式)
3、语义分析:检查变量类型、作用域等静态语义,确保表达式合法(如 int a = “hello”; 会报错)。
4、优化:对代码进行简化(如删除无用计算、常量折叠),提升运行效率。
5、生成汇编代码:将优化后的中间代码转换为目标机器的汇编指令。
6、汇编代码优化:调整寻址方式、简化指令等,进一步提高性能。
汇编
汇编器(如 as)将汇编代码(.s)逐行翻译成机器码,生成目标文件(Linux 下 .o,Windows 下 .obj)。这一过程是直接对照汇编指令与机器码的映射表转换,不涉及语法分析或优化。生成的文件已经是二进制格式,可直接用于后续链接。
链接
将不同的源⽂件产⽣的⽬标⽂件进⾏链接,从⽽形成⼀个可以执⾏的程序。链接分为静态链接和动态链接:
1、静态链接:
静态链接在编译时将库函数和数据直接复制到最终的可执行文件中。这种方式会导致每个程序都包含所需库的完整副本,造成存储空间浪费,特别是多个程序使用相同库时会在内存中存在重复副本。另一个缺点是库更新时需要重新编译整个程序。不过静态链接的优势在于运行时无需加载外部库,因此执行速度更快。
2、动态链接:
动态链接采用运行时加载的方式,将程序模块在运行时才进行链接。多个程序可以共享同一个库文件的内存副本,避免了静态链接的空间浪费问题。当库需要更新时,只需替换库文件即可,无需重新编译程序,大大简化了维护工作。不过由于需要在程序运行时进行链接,会带来一定的性能开销。这种机制在节省内存和方便更新方面具有明显优势,但以轻微的性能损失为代价。
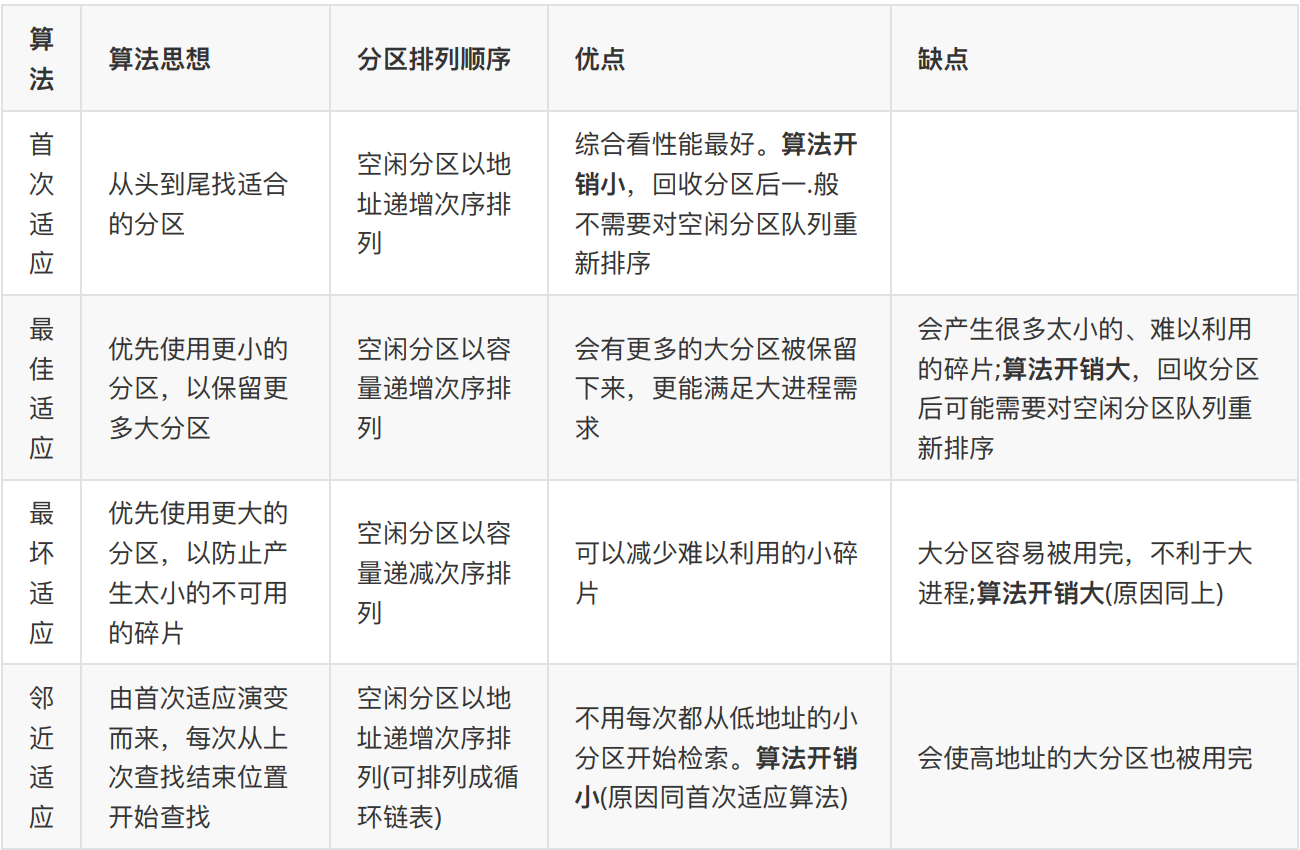
动态分区分配算法有哪⼏种?可以分别说说吗?
1、⾸次适应不仅最简单,通常也是最好最快,不过⾸次适应算法会使得内存低地址部分出现很多⼩的空闲分区,⽽每次查找都要经过这些分区,因此也增加了查找的开销。2、邻近算法试图解决这个问题,但实际上,它常常会导致在内存的末尾分配空间分裂成⼩的碎⽚,它通常⽐⾸次适应算法结果要差。3、最佳导致⼤量碎⽚。4、最坏导致没有⼤的空间。进过实验,⾸次适应⽐最佳适应要好,他们都⽐最坏好。
逻辑地址VS物理地址
编译时只需确定变量x存放的相对地址是100 ( 也就是说相对于进程在内存中的起始地址⽽⾔的地址)。 CPU想要找到x在内存中的实际存放位置,只需要⽤进程的起始地址+100即可。相对地址⼜称逻辑地址,绝对地址⼜称物理地址。