深度理解 linux 系统内存分配
目录
一、用户态
1、malloc 的使用
2、glibc 内存池管理
2.1 ptmalloc的核心设计思想
2.2 架构组成
(1)Chunk (内存块)结构
(2)Bins (空闲列表容器)
(3)Arenas (分配区)
(4)Top chunk
2.3 核心算法
(1)内存分配流程
(2)内存释放流程
3、brk 与 mmap
3.1 brk
3.2 mmap
(1)核心原理
(2)优势
(3)注意事项
(4)使用场景
(5)相关 API
(6)mmap 示例
二、内核态
1、伙伴系统 Buddy
2、slab
2.1 核心思想
2.2 工作原理
2.3 基本架构
2.4 API 接口
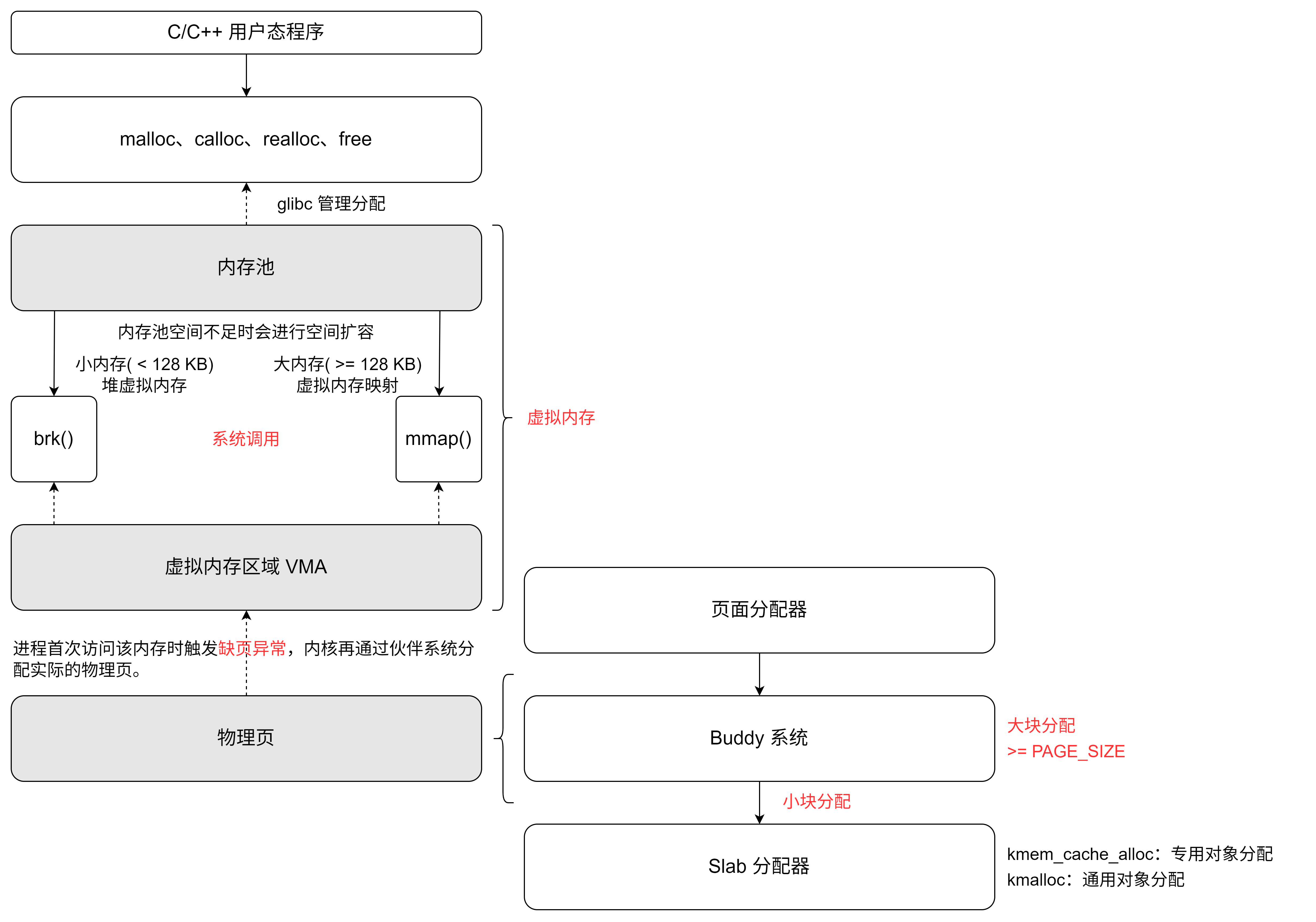
malloc 调用 brk 或 mmap 系统调用向内核申请虚拟内存。内核首先分配虚拟内存区域(VMA),当进程首次访问该内存时触发缺页异常,内核再通过伙伴系统分配实际的物理页。而 slab/slub 是内核用于管理自身小对象(如结构体实例)的内存分配器,与用户态的 malloc 没有直接关系。
| 层级 | 用户态 | 内核态 |
| 接口层 |
|
|
| 系统调用 |
|
|
| 底层支持 | 依赖内核的虚拟内存管理 | 依赖伙伴系统( |
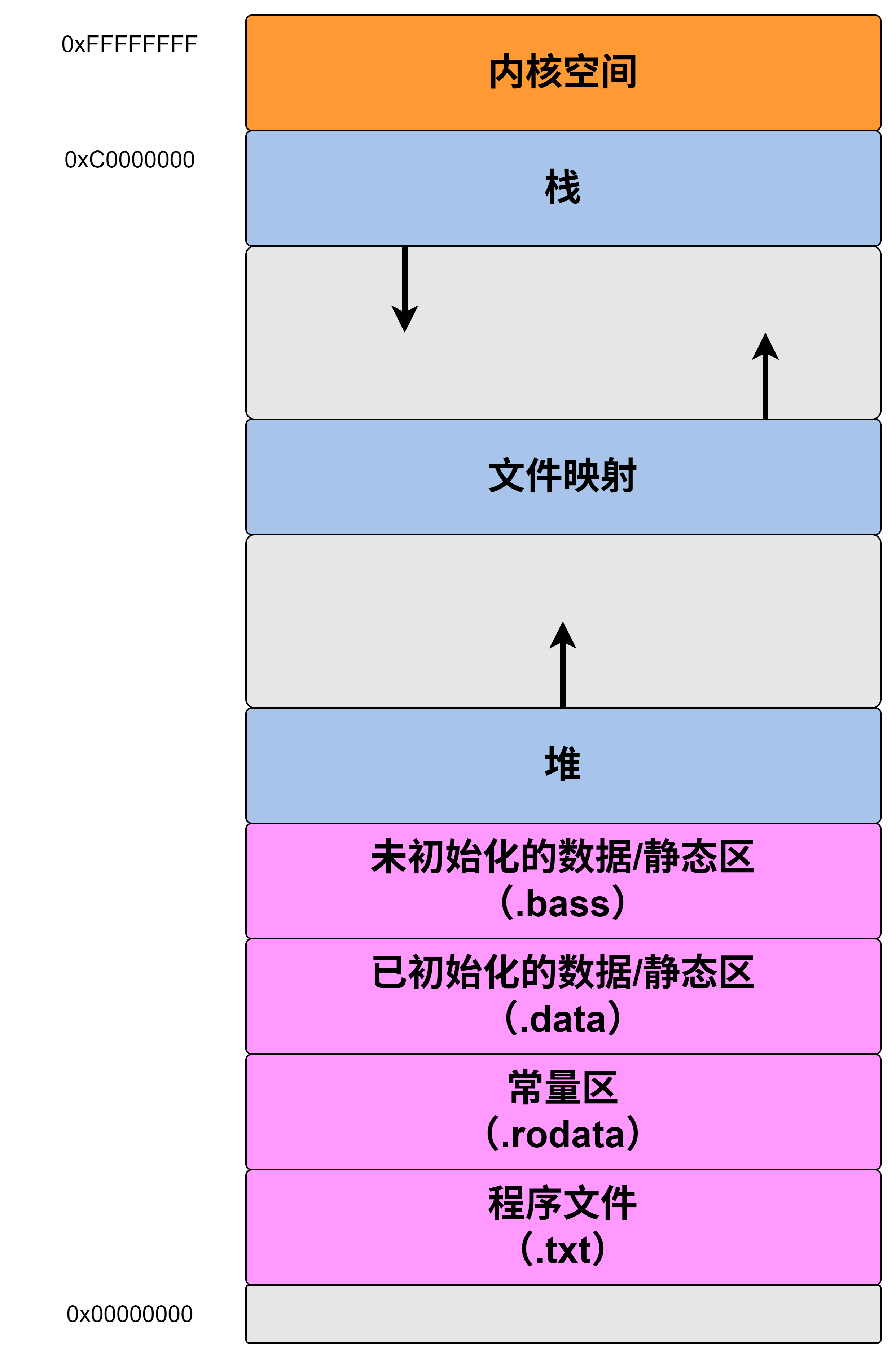
一、用户态
在C语言层面,开发者最常使用的动态内存分配接口是malloc()、calloc()、realloc()和free()。这些函数是标准 C 库提供的用户态内存分配接口。
malloc 等函数分配的内存并不是每次直接调用 brk 和mmap 分配的,而是先从 glib 管理的内存池中寻找合适的块进行分配。当内存池空间不足时则系统调用 brk和mmap扩容内存池。
1、malloc 的使用
C 内存的动态分配怎么用?有啥建议吗?内存分配中栈与堆到底有啥不同啊?_使用动态分配,使用堆而不是栈-CSDN博客文章浏览阅读716次。介绍了内存分配中栈与堆的差异,介绍了常用的动态内存分配相关函数,并对代码书写提出了一些建议_使用动态分配,使用堆而不是栈https://blog.csdn.net/qq_37437983/article/details/122720401
2、glibc 内存池管理
glibc (GNU C Library) 的内存管理主要通过其实现的 ptmalloc (pthread malloc) 来完成,这是一个成熟的内存池管理实现,特别优化了多线程环境下的内存分配性能。
2.1 ptmalloc的核心设计思想
- 减少系统调用:通过维护内存池减少频繁调用
brk/mmap - 多线程优化:采用 thread-local arenas 减少锁竞争
- 内存复用:通过bins机制实现内存块的缓存和复用
- 碎片控制:通过chunk合并减少内存碎片
2.2 架构组成
(1)Chunk (内存块)结构
内存分配的基本单位,有以下两种状态:
struct malloc_chunk {size_t prev_size; /* 前一个chunk的大小(如果前一个chunk空闲) */size_t size; /* 本chunk的大小和标志位 *//* 仅空闲 chunk 使用以下字段 */struct malloc_chunk* fd; /* 前向指针 - 指向同一bin中的下一个chunk */struct malloc_chunk* bk; /* 后向指针 - 指向同一bin中的上一个chunk */
};(2)Bins (空闲列表容器)
用于管理空闲chunk的容器,分为以下几种类型:
- Fast bins (64位系统默认有7个)
-
- 单链表结构,LIFO 策略
- 保存小尺寸(16-80字节)的 chunk
- 不合并相邻空闲 chunk (减少锁操作)
- Small bins (62个)
-
- 双链表结构,FIFO策略
- 每个 bin 保存固定大小的 chunk (等差递增)
- Large bins (63个)
-
- 双链表结构,按大小排序
- 每个 bin 保存一定范围内大小的 chunk
- Unsorted bin (1个)
-
- 双链表结构
- 暂存刚被释放的 chunk
(3)Arenas (分配区)
每个 arena 管理一个完整的内存池,包含:
struct malloc_state {/* arena参数和统计信息 */int mutex; /* 锁 */int flags;/* chunk指针 */mfastbinptr fastbinsY[NFASTBINS]; /* Fast bins */mchunkptr top; /* Top chunk */mchunkptr last_remainder;/* 常规bin */mchunkptr bins[NBINS * 2 - 2];/* arena链表 */struct malloc_state *next;struct malloc_state *next_free;
}; 主线程使用 main_arena,其他线程默认会创建自己的thread arena(最多为CPU核心数的8倍)。
(4)Top chunk
每个 arena 的顶部 chunk,用于扩展堆空间:
- 当 bins 中找不到合适 chunk 时使用
- 不足时会调用
brk/mmap扩展
2.3 核心算法
(1)内存分配流程
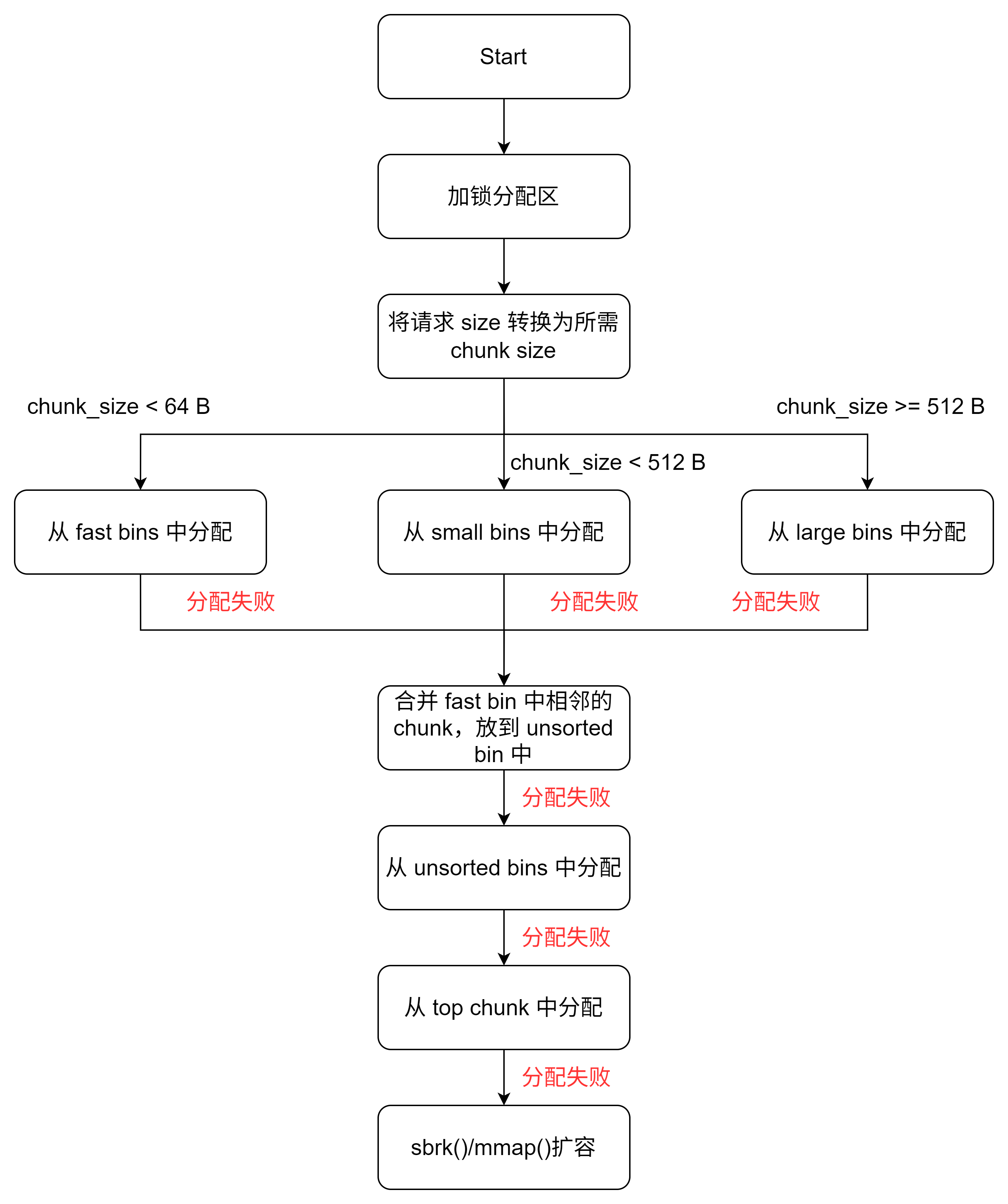
a. 根据请求大小转换为实际 chunk 大小(包括对齐和元数据)
b. 如果 size ≤ fast bin最大值(默认 64 字节):
■ 锁定 arena
■ 从对应 fast bin 中获取 chunk
■ 解锁 arena
c. 如果 size ≤ small bin 最大值(默认 512 字节):
■ 锁定 arena
■ 从对应 small bin 查找
■ 如果找不到,转到步骤 e
■ 解锁 arena
d. 如果 size > small bin最大值:
■ 锁定 arena
■ 从 large bins 查找最小满足的 chunk
■ 如果找到,切割剩余部分放入 unsorted bin
e. 检查 unsorted bin:
■ 遍历查找合适 chunk
■ 找到则返回,否则放入对应 bin
f. 仍然没找到则使用 top chunk:
■ 如果 top chunk 足够,切割并返回
■ 否则调用sbrk/mmap扩展top chunk
g. 如果所有步骤都失败,尝试合并 fast bins 并重试,这块存在疑问,有的是把这块整合在 e 步骤(体现在上述流程图中)
(2)内存释放流程
a. 检查指针有效性
b. 获取 chunk 大小和位置
c. 如果 size 属于 fast bin 范围:
■ 锁定 arena
■ 插入对应 fast bin(LIFO)
■ 解锁 arena
d. 否则:
■ 检查前一个 chunk 是否空闲,是则合并
■ 检查后一个 chunk 是否空闲,是则合并
■ 将合并后的 chunk 放入 unsorted bin
e. 如果 top chunk 变得过大,可能返还部分内存给系统
3、brk 与 mmap
3.1 brk
通过调整 program break 位置来管理堆内存;是传统 malloc 的内部实现基础。
// 堆地址是从下往上扩的
int brk(void *addr); // 绝对位置调整
void *sbrk(intptr_t increment); // 相对位置调整#include <unistd.h>void basic_brk_demo() {void *curr_brk = sbrk(0); // 获取当前break位置// 申请1MB内存,堆指针往上移动 1024 * 1024void *new_brk = sbrk(1024*1024);if (new_brk == (void*)-1) {perror("sbrk failed");return;}/*使用内存,注意申请的内存起始地址为未 curr_brk,末尾地址为 new_brk*/memset(curr_brk, 0, 1024*1024);// 释放内存(实际是缩小 break)brk(curr_brk);
}注意:
- 分配的内存是进程内连续的虚拟地址空间
- 分配粒度以页为单位(通常4KB)
- 频繁小额分配可能产生内存碎片,堆指针线性移动
- 线程不安全,需要额外同步机制
3.2 mmap
mmap(内存映射)是Linux中一种非常重要的内存管理机制,它允许将文件或其他对象直接映射到进程的地址空间,实现文件和内存之间的高效交互。
(1)核心原理
- 虚拟内存映射:mmap在进程的虚拟地址空间中创建一个映射区域,但并不立即分配物理内存
- 惰性加载:只有当进程实际访问映射区域时,才会通过缺页异常(page fault)机制加载数据
- 共享机制:多个进程可以映射同一个文件,实现内存共享
- 零拷贝:避免了数据在用户空间和内核空间之间的复制
(2)优势
- 性能高:减少数据拷贝次数,提高I/O性能
- 使用简单:映射后可以像访问普通内存一样操作文件
- 共享方便:多个进程可以共享同一映射区域
- 延迟加载:只在需要时加载数据,节省内存
(3)注意事项
- 地址对齐:映射区域应当页面对齐(通常4KB)
- 映射大小:指定的长度不能超过文件大小(匿名映射除外)
- 资源管理:务必记得munmap解除映射,避免内存泄漏
- 多线程安全:共享映射需要注意同步问题
- NFS问题:网络文件系统的mmap可能有特殊行为
(4)使用场景
文件I/O优化
- 代替传统的read/write操作,特别适合大文件处理
- 避免了用户空间和内核空间之间的数据拷贝
- 示例:数据库系统、文本编辑器处理大文件
进程间通信(IPC)
- 通过共享内存实现高性能进程间通信
- 比管道、消息队列等传统IPC方式更高效
内存分配
- 替代malloc进行大内存分配(如glibc的malloc可能使用mmap分配大块内存)
- 示例:自定义内存池实现
零拷贝网络传输
- 结合sendfile系统调用实现文件传输零拷贝
- 示例:Web服务器发送静态文件
动态库加载
- 动态链接器使用mmap将共享库映射到进程地址空间
(5)相关 API
#include <sys/mman.h>/*
参数介绍:addr:建议的映射起始地址,通常设为 NULL 让内核自动选择length:要映射的区域长度prot:保护模式,可以是以下组合:PROT_READ:可读PROT_WRITE:可写PROT_EXEC:可执行PROT_NONE:不可访问flags:映射标志,常用:MAP_SHARED:共享映射,修改会写回文件MAP_PRIVATE:私有映射,修改不会影响文件MAP_ANONYMOUS:匿名映射,不关联文件MAP_FIXED:强制使用指定地址fd:文件描述符,匿名映射设为 -1offset:文件偏移量,通常是 0返回值:成功返回映射区域指针,失败返回MAP_FAILED
*/
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);/*
解除内存映射addr 必须是 mmap 返回的地址length 应与 mmap 时相同
*/
int munmap(void *addr, size_t length);/*
将映射区域的修改同步到文件flags:MS_ASYNC:异步写MS_SYNC:同步写MS_INVALIDATE:使缓存失效
*/
int msync(void *addr, size_t length, int flags);(6)mmap 示例
下方代码只作为示例,辅助介绍 API 的相关用法。
示例 1:文件映射
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <unistd.h>
#include <string.h>int main() {const char *filename = "example.txt";const char *message = "Hello, mmap!";// 打开文件int fd = open(filename, O_RDWR | O_CREAT, 0644);if (fd == -1) {perror("open");exit(EXIT_FAILURE);}// 调整文件大小size_t len = strlen(message) + 1;if (ftruncate(fd, len) == -1) {perror("ftruncate");close(fd);exit(EXIT_FAILURE);}// 映射文件char *mapped = mmap(NULL, len, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);if (mapped == MAP_FAILED) {perror("mmap");close(fd);exit(EXIT_FAILURE);}// 写入数据strcpy(mapped, message);// 同步到文件if (msync(mapped, len, MS_SYNC) == -1) {perror("msync");}// 解除映射if (munmap(mapped, len) == -1) {perror("munmap");}close(fd);return 0;
}
示例 2:匿名内存映射示例
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <unistd.h>
#include <string.h>int main() {size_t size = getpagesize(); // 获取系统页大小(通常4KB)printf("System page size: %zu bytes\n", size);// 分配2页内存(匿名映射)size_t length = 2 * size;void *mem = mmap(NULL, length, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);if (mem == MAP_FAILED) {perror("mmap failed");return EXIT_FAILURE;}printf("Allocated memory at %p\n", mem);// 使用分配的内存strcpy((char *)mem, "Hello, mmap!");printf("Memory content: %s\n", (char *)mem);// 释放内存if (munmap(mem, length) == -1) {perror("munmap failed");return EXIT_FAILURE;}return EXIT_SUCCESS;
}示例 3:共享内存示例(进程间通讯)
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>#define SHM_NAME "/demo_shm"
#define SIZE 1024int main() {// 创建共享内存对象int fd = shm_open(SHM_NAME, O_CREAT | O_RDWR, 0666);if (fd == -1) {perror("shm_open failed");return EXIT_FAILURE;}// 设置共享内存大小if (ftruncate(fd, SIZE) == -1) {perror("ftruncate failed");close(fd);return EXIT_FAILURE;}// 内存映射void *ptr = mmap(NULL, SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);if (ptr == MAP_FAILED) {perror("mmap failed");close(fd);return EXIT_FAILURE;}// 写入数据sprintf((char *)ptr, "Hello from server! PID: %d", getpid());printf("Server wrote to shared memory\n");// 等待客户端读取printf("Press Enter to exit...\n");getchar();// 清理munmap(ptr, SIZE);close(fd);shm_unlink(SHM_NAME);return EXIT_SUCCESS;
}#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>#define SHM_NAME "/demo_shm"
#define SIZE 1024int main() {// 打开共享内存对象int fd = shm_open(SHM_NAME, O_RDONLY, 0666);if (fd == -1) {perror("shm_open failed");return EXIT_FAILURE;}// 内存映射(只读)void *ptr = mmap(NULL, SIZE, PROT_READ, MAP_SHARED, fd, 0);if (ptr == MAP_FAILED) {perror("mmap failed");close(fd);return EXIT_FAILURE;}// 读取并显示数据printf("Client received: %s\n", (char *)ptr);// 清理munmap(ptr, SIZE);close(fd);return EXIT_SUCCESS;
}示例 4:内存池实现框架
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <unistd.h>
#include <stdint.h>typedef struct MemoryBlock {struct MemoryBlock *next;// 可以添加更多管理信息
} MemoryBlock;typedef struct {size_t block_size;size_t total_blocks;size_t free_blocks;void *start;MemoryBlock *free_list;size_t pool_size; // 添加总大小用于验证
} MemoryPool;MemoryPool* create_pool(size_t block_size, size_t block_count) {// 确保块大小至少能容纳指针size_t actual_block_size = (block_size < sizeof(MemoryBlock)) ? sizeof(MemoryBlock) : block_size;size_t total_size = actual_block_size * block_count;// 使用mmap分配内存,并添加保护页void *mem = mmap(NULL, total_size + getpagesize(), PROT_READ | PROT_WRITE,MAP_PRIVATE | MAP_ANONYMOUS,-1, 0);if (mem == MAP_FAILED) {perror("mmap failed");return NULL;}// 设置最后一个页为不可访问(作为保护页)mprotect(mem + total_size, getpagesize(), PROT_NONE);// 初始化内存池结构MemoryPool *pool = malloc(sizeof(MemoryPool));if (!pool) {munmap(mem, total_size + getpagesize());return NULL;}pool->block_size = actual_block_size;pool->total_blocks = block_count;pool->free_blocks = block_count;pool->start = mem;pool->free_list = NULL;pool->pool_size = total_size;// 初始化空闲链表char *current = mem;for (size_t i = 0; i < block_count; i++) {MemoryBlock *block = (MemoryBlock *)current;block->next = pool->free_list;pool->free_list = block;current += actual_block_size;}return pool;
}void *pool_alloc(MemoryPool *pool) {if (!pool || pool->free_blocks == 0) {return NULL;}MemoryBlock *block = pool->free_list;pool->free_list = block->next;pool->free_blocks--;// 可以在这里初始化内存块return (void *)block;
}void pool_free(MemoryPool *pool, void *ptr) {if (!pool || !ptr) return;// 验证指针是否属于该池if ((uintptr_t)ptr < (uintptr_t)pool->start || (uintptr_t)ptr >= (uintptr_t)pool->start + pool->pool_size) {fprintf(stderr, "Error: Invalid pointer for this pool\n");return;}// 检查对齐if (((uintptr_t)ptr - (uintptr_t)pool->start) % pool->block_size != 0) {fprintf(stderr, "Error: Pointer is not aligned to block boundary\n");return;}MemoryBlock *block = (MemoryBlock *)ptr;block->next = pool->free_list;pool->free_list = block;pool->free_blocks++;
}void destroy_pool(MemoryPool *pool) {if (!pool) return;// 检查内存泄漏if (pool->free_blocks != pool->total_blocks) {fprintf(stderr, "Warning: Memory leak detected (%zu blocks not freed)\n",pool->total_blocks - pool->free_blocks);}// 计算总大小时要包括之前添加的保护页munmap(pool->start, pool->pool_size + getpagesize());free(pool);
}
int main() {MemoryPool *pool = create_pool(64, 100); // 64字节块,共100块if (!pool) {return EXIT_FAILURE;}void *blocks[100];for (int i = 0; i < 100; i++) {blocks[i] = pool_alloc(pool);if (!blocks[i]) {printf("Allocation failed at block %d\n", i);break;}}// 故意制造错误pool_free(pool, (void *)0x123456); // 无效指针pool_free(pool, blocks[10]); // 正确释放pool_free(pool, blocks[10]); // 双重释放destroy_pool(pool);return EXIT_SUCCESS;
}实际应用中还可以添加更多功能,如:
- 线程安全支持(加锁)
- 内存使用统计
- 调试信息记录
- 更复杂的分配策略(如首次适应、最佳适应等)
二、内核态
1、伙伴系统 Buddy
Buddy 系统是现代操作系统中用于内存管理的一种高效算法,主要用于动态分配和回收物理内存。伙伴系统(buddy system)算法以页为单位管理内存。Buddy 系统是一种内存分配算法,它的核心思想是将空闲内存块按 2 的幂次方大小组织,每个大小类别维护一个空闲链表。当需要分配内存时,系统会寻找最接近所需大小的空闲块。例如 Buddy 把所有的空闲页放到11个链表中,每个链表分别管理大小为 1,2,4,8,16,32,64,128,256,512,1024 个页的内存块。当系统需要分配内存时,就可以从 buddy 系统中获取。例如,要申请一块包含 4 个页的连续内存,就直接从buddy系统中管理 4 个页连续内存的链表中获取。同样的,如果系统需要申请 3 个页的连续内存,则只能在 4 个页的链表中获取,剩下的一个页被放到 buddy 系统中管理 1 个页的链表中。Buddy 系统解决了物理内存分配的外部碎片问题。
分配过程:
a. 系统维护一系列空闲链表,分别对应不同大小的内存块(如 4 KB, 8 KB, 16 KB...)
b. 当请求分配内存时,系统会向上取整到最近的2次幂大小
c. 在相应大小的空闲链表中查找可用块
d. 如果没有找到,则分裂更大的块为两个"伙伴"(buddies)
e. 将其中一个分配出去,另一个加入较小的空闲链表
f. 重复此过程直到找到合适大小的块
释放过程:
a. 释放内存块时,检查其"伙伴"块是否空闲
b. 如果伙伴也是空闲的,则合并这两个块为一个更大的块
c. 重复检查合并的可能性,直到无法再合并
d. 将最终合并后的块加入相应大小的空闲链表
模拟过程:
#define MAX_ORDER 10 // 最大块大小 2^10 = 1024KBstruct free_area {list_head free_list;int nr_free;
} free_area[MAX_ORDER + 1];// 分配内存
void* buddy_alloc(size_t size) {// 计算所需 orderint order = get_order(size);// 从 order 开始向上查找for (int i = order; i <= MAX_ORDER; i++) {if (!list_empty(&free_area[i].free_list)) {// 找到合适的空闲块page = list_entry(free_area[i].free_list.next, struct page, lru);list_del(&page->lru);free_area[i].nr_free--;// 如果需要分裂while (i > order) {i--;buddy = split_block(page, i);list_add(&buddy->lru, &free_area[i].free_list);free_area[i].nr_free++;}return page;}}return NULL; // 内存不足
}// 释放内存
void buddy_free(void* addr) {page = get_page(addr);order = page->order;while (order < MAX_ORDER) {buddy = get_buddy(page, order);if (!is_free(buddy) || !is_same_block(buddy, order)) {break; // 不能合并}// 合并伙伴块list_del(&buddy->lru);free_area[order].nr_free--;page = merge_blocks(page, buddy);order++;}list_add(&page->lru, &free_area[order].free_list);free_area[order].nr_free++;
}
2、slab
Slab 分配器是 Linux 内核中的一种高效内存管理机制,主要用于管理内核对象的分配与释放。其核心思想基于 Jeff Bonwick 在1994年提出的"对象缓存"概念。
2.1 核心思想
- 预分配与缓存:预先分配并缓存常用大小的内存对象,减少频繁分配释放的开销
- 对象重用:释放的对象不立即归还系统,而是保留在缓存中供后续分配
- 着色技术:通过偏移量减少缓存行冲突,提高 CPU 缓存命中率
2.2 工作原理
a. 缓存预热:为常用对象类型创建专用缓存
b. 分配流程:
■ 首先检查每CPU缓存(array_cache)
■ 如果为空,从 Slab 中批量填充
■ 如果 Slab 为空,请求伙伴系统分配新页
c. 释放流程:
■ 对象返回到每 CPU 缓存
■ 当缓存满时,批量返还给 Slab
2.3 基本架构
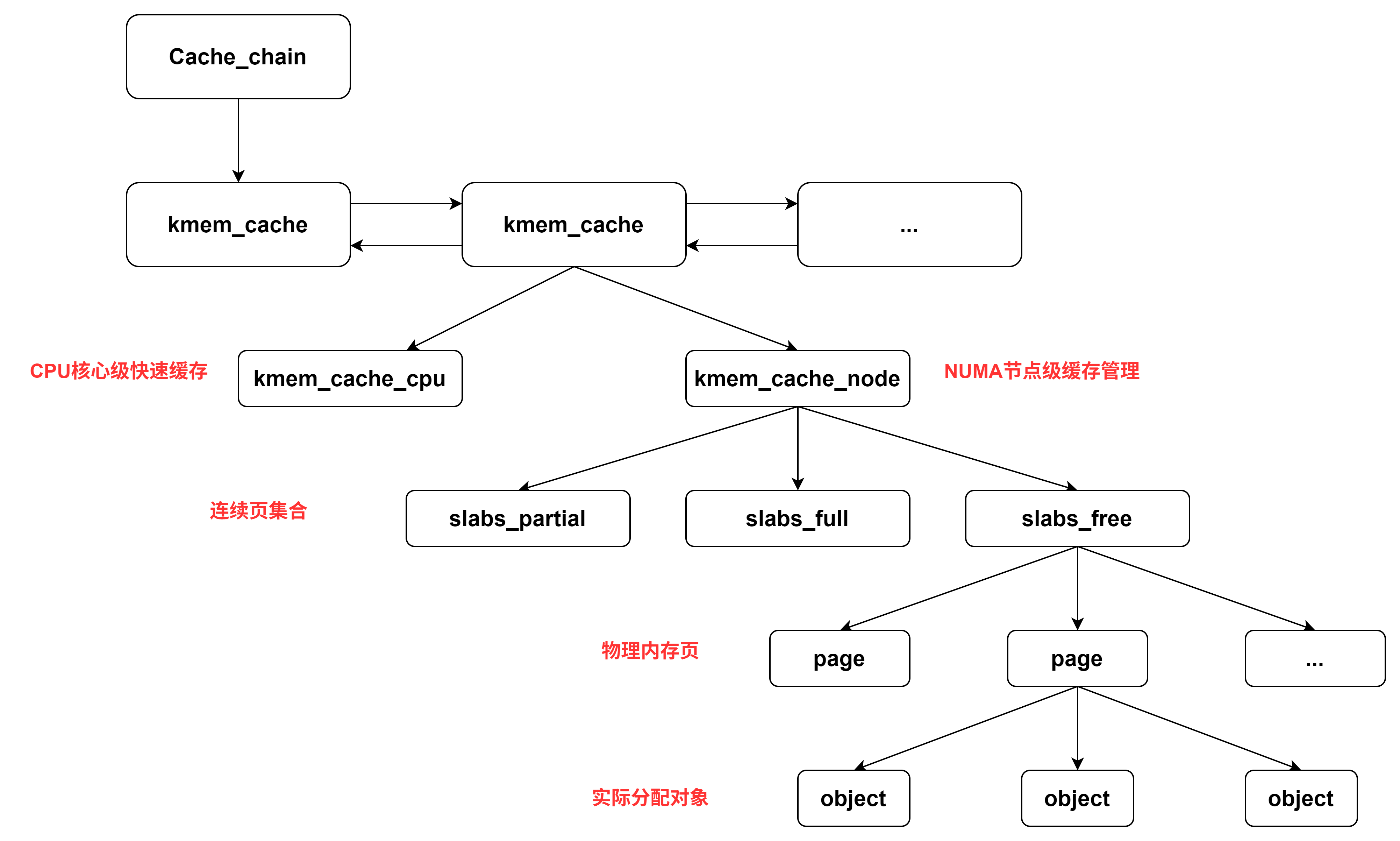
Slab分配器采用三级结构:
- kmem_cache:核心数据结构,管理特定类型的对象缓存。
struct kmem_cache {struct array_cache __percpu *cpu_cache; // 每个CPU的热缓存unsigned int size;unsigned int object_size;// NUMA节点对应的kmem_cache_node结构struct kmem_cache_node *node[MAX_NUMNODES];// ...
};/*CPU 热缓存层 (kmem_cache_cpu),每个 CPU 单独一个,减少多核竞争
*/
struct array_cache {unsigned int avail; // 可用对象数unsigned int limit; // 缓存上限void *entry[]; // 空闲对象指针数组
};-
- kmem_cache_cpu:每个 CPU 的快速缓存;
- kmem_cache_node: NUMA 节点缓存
- Slab:由一到多个连续物理页组成的内存块,包含多个对象。通过不同的偏移量减少缓存冲突。
/*每个内存节点一个
*/
struct kmem_cache_node {spinlock_t list_lock;struct list_head slabs_full;struct list_head slabs_partial;struct list_head slabs_free;unsigned long num_slabs;// ...
};cache_node 管理三类 slab:
-
slabs_partial: 该链表中的 slab 的 object 对象部分分配完了slabs_full: 该链表中每个 slab 的 object 对象都已经分配完了slabs_free: 该链表中的 object 对象全部没有分配出去(空 slab,未分配)
- Objects :Slab 中分配的实际内存单元。从slab中按需分配,释放时不立即归还系统,保留在 slab 中重用。
2.4 API 接口
// 创建缓存,仅仅是从cache_cache中分配一个 kmem_cache 实例,并不会分配实际的物理页。
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align,unsigned long flags, void (*ctor)(void *));// 销毁缓存
void kmem_cache_destroy(struct kmem_cache *);// 从缓存分配对象
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);// 释放对象到缓存
void kmem_cache_free(struct kmem_cache *cachep, void *objp);// 通用分配函数(基于Slab实现)
void *kmalloc(size_t size, gfp_t flags);
void kfree(const void *objp);#include <linux/module.h>
#include <linux/slab.h>
#include <linux/slab_def.h>#define OBJECT_SIZE 128struct my_object {char data[OBJECT_SIZE];
};static struct kmem_cache *my_cache = NULL;static int __init slab_example_init(void)
{struct my_object *obj;// 创建缓存my_cache = kmem_cache_create("my_cache", sizeof(struct my_object),0, SLAB_HWCACHE_ALIGN, NULL);if (!my_cache) {return -ENOMEM;}// 从缓存分配对象obj = kmem_cache_alloc(my_cache, GFP_KERNEL);if (!obj) {kmem_cache_destroy(my_cache);return -ENOMEM;}// 使用对象snprintf(obj->data, OBJECT_SIZE, "Slab example object");printk(KERN_INFO "Allocated object: %s\n", obj->data);// 释放对象kmem_cache_free(my_cache, obj);return 0;
}static void __exit slab_example_exit(void)
{if (my_cache) {kmem_cache_destroy(my_cache);}printk(KERN_INFO "Slab example module unloaded\n");
}module_init(slab_example_init);
module_exit(slab_example_exit);
MODULE_LICENSE("GPL");kmem_cache_alloc 与 kmalloc 的区别
| 特性 | kmem_cache_alloc | kmalloc |
| 分配粒度 | 固定大小对象 | 任意大小内存块 |
| 性能 | 更高(专用缓存) | 略低(通用缓存) |
| 适用场景 | 频繁分配的同类型对象 | 临时或不规则的内存需求 |
| 内存来源 | 专用 Slab 缓存 | 通用 Slab 缓存( kmalloc-*系列缓存) |
| 初始化支持 | 可指定构造函数 | 无初始化支持 |
// kmem_cache_alloc 典型实现路径
1. 检查每 CPU 快速缓存(kmem_cache_cpu)
2. 有可用对象则直接返回
3. 否则从 NUMA 节点缓存(kmem_cache_node)填充快速缓存
4. 再失败则从 Buddy 系统分配新 Slab// kmalloc 典型实现路径
1. 根据请求大小选择最匹配的 kmalloc 缓存(如kmalloc-8, kmalloc-16,..., kmalloc-8192)
2. 从对应 Slab 缓存分配
3. 对于超大内存请求直接从 Buddy 系统分配