chukonu阅读笔记(2)
3. DAG分裂概述
在本节中,我们将介绍DAG分割的思想,并阐述它如何以低开销将原生计算引擎集成到Spark中。一个大数据分析程序可以用有向无环图在逻辑上表示,其中顶点是算子,边是两个算子之间的依赖关系,我们称之为DAG程序。
肯定是有向无环图的,不然结束不了
我们的方法将DAG程序分割成运行时部分和编译时部分。
编译时部分是DAG程序的一个子图,它将在编译时被原生编译和优化。
运行时部分是DAG程序的一个子图,它将由Spark直接执行。在§3.1和§3.2中,我们将分别讨论如何将DAG程序分割成两个部分,以及如何优化编译时部分。
有一部分可能是需要预编译的,另一部分直接外包,考虑之前所讨论过的程序执行方案,这是一种较低开发成本的提升性能的方法,开发成本,以及相对旧有方案的效率提升,应该是主要来自编译时部分的。
3.1 DAG程序分割策略
Chukonu根据算子的类别分割DAG程序。每个算子可能属于编译时部分或运行时部分。图2展示了Chukonu如何分割DAG程序的一个简单例子。
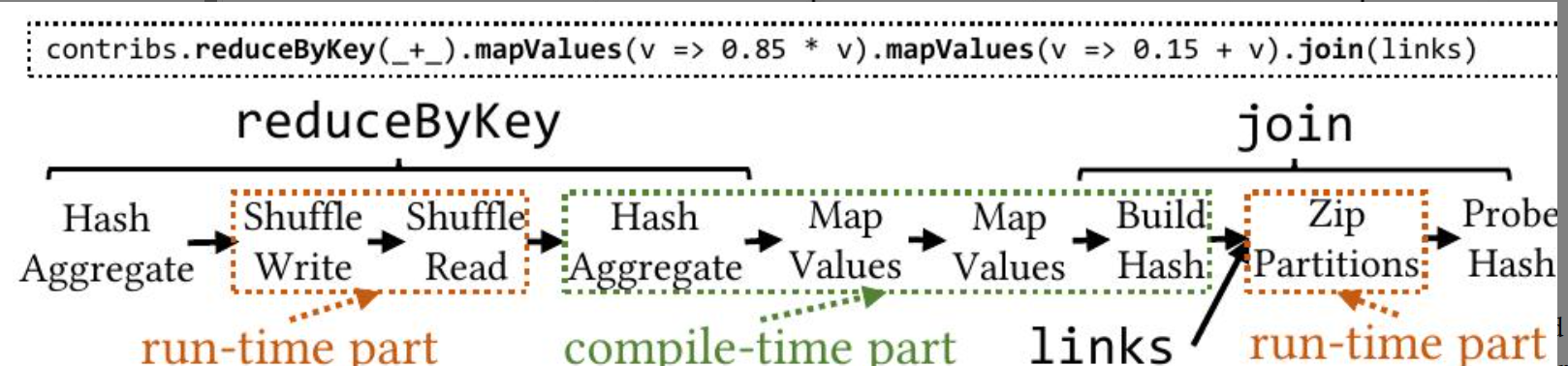
该代码摘自PageRank应用程序,它对应于下面的DAG程序。在这个例子中,shuffle和zip算子位于运行时部分,而其他算子位于编译时部分。
这张图展示了一个数据处理流程,可能是在一个大数据处理框架(如Spark)中执行的操作。图中分为三个主要部分:reduceByKey、links 和 join。每个部分都有编译时和运行时的组件。
-
reduceByKey:
- 运行时部分:
- Hash Aggregate:对数据进行哈希聚合。
- Shuffle Write/Read:数据在不同节点之间进行洗牌,写入和读取。
- 编译时部分:
- Hash Aggregate:再次进行哈希聚合。
- Map Values:对值进行映射操作。
- 运行时部分:
-
links:
- 编译时部分:
- Map Values:对值进行映射。
- Build Hash:构建哈希表。
- 编译时部分:
-
join:
- 运行时部分:
- Zip Partitions:对分区进行压缩。
- Probe Hash:进行哈希探测。
- 运行时部分:
图中展示了数据处理的各个阶段,包括数据的聚合、洗牌、映射和连接等操作。这些操作在编译时和运行时分别执行,以优化性能和资源利用。
值得讨论的是将算子分配到这两个类别的策略。如果一个算子被分配到运行时部分,它会被委托给 Spark,并且只需要很少的人工来实现,但可能会受到 Spark 集成开销的影响。我们遵循的原则是,难以实现的算子应该优先考虑运行时部分,除非它们被证明是性能瓶颈。
外包就是省心,但是慢,如果一个东西没有那么慢,还很难自己搞,那就还是外包吧
在这种方法下,我们尽量避免不必要的人工,只要 Spark 集成开销保持在较小水平。
Chukonu 将以下算子分配到运行时部分:
首先,分区剪枝算子和具有多个依赖关系的算子,例如 union、zip 和 cartesian,都位于运行时部分。这为 Spark 提供了与血缘相关的信息,并重用了 Spark 基于血缘的容错机制。
其次,shuffle 算子位于运行时部分。这重用了 Spark 的容错数据混洗机制,该机制不仅难以实现,而且部署起来也具有侵入性:它需要重新配置集群资源管理器,以便在集群的每个节点中部署一个专用的 shuffle 服务
第三,cache 算子位于运行时部分。这重用了 Spark 的中间数据管理机制。
第四,数据源算子位于运行时部分。这为 Spark 提供了位置信息,并重用了 Spark 的位置感知任务调度。其他算子,例如 map、filter 和 flatMap,被分配到编译时部分,以便可以在编译时对其进行优化。
以下为一些必要的解释,由gpt生成,补充一些spark和大数据算子的必要知识。
一、什么是“编译时”和“运行时”?
编译时: 就是在你写完代码、还没有真正去“跑”它的时候,对代码进行分析、优化、转换的过程。
运行时: 是代码真正“跑起来”以后,系统根据实际数据和资源进行计算、调度、处理的过程。
这个划分很重要,因为:
编译时做的事情越多,运行时就越轻松,同时也可能更高效。
但有些操作不适合在编译时做,必须等到“真正运行时”才知道怎么处理。
🚀 二、为什么这些 Spark 算子被划分到运行时或编译时?
我们逐个来看:
✅ 适合放在运行时的算子
算子 为什么放在运行时? 通俗解释
分区剪枝(Partition Pruning) 依赖运行时才能知道哪些分区的数据是“真正需要”的 比如你想读取2023年的数据,只有在运行时知道你到底查的是哪一年
Union / Zip / Cartesian 这些操作涉及多个数据源,Spark 需要在运行时构建血缘图(数据从哪来的) 就像你要合并两个表,只有在运行时才知道这两个表具体长啥样
Shuffle Shuffle 是数据重新分区排序的过程,需要复杂的容错、网络通信机制 非常复杂,Spark 内置了高性能机制,自己实现太麻烦
Cache Spark 的缓存机制做得很好,能自动管理内存和磁盘 自己实现缓存系统太费劲,不如复用 Spark 的
数据源(Data Source) Spark 能根据数据存在哪台机器上,优化任务调度 比如数据在机器A上,Spark 会把任务尽量安排在机器A上计算,减少网络传输
✅ 适合放在编译时的算子
算子 为什么放在编译时? 通俗解释
map / filter / flatMap 这些是函数式编程的基础操作,非常容易优化和合并 比如连续的 map 可以合并成一个 map,提高效率
其他逻辑变换算子 可以通过编译器提前转换、融合操作,减少运行时开销 比如先乘2再加3,可以合并为“乘2再加3”,只做一次遍历
🎯 总结:为什么这样分?
Chukonu 这样设计,是为了在不牺牲 Spark 已有成熟机制的前提下,尽可能提升性能:
运行时部分:保留 Spark 的强项,比如分布式调度、容错、shuffle、数据位置感知等复杂机制。
编译时部分:优化能够提前处理的逻辑,比如函数链、操作融合、避免不必要的中间结果。
这样既能复用 Spark 的强大能力,又能通过编译优化某些容易处理的逻辑,实现“低侵入、高性能”的目标。
必要的解释结束
3.2 优化编译时部分
对编译时部分的优化对于减轻 Spark 集成开销是必要的。为了说明这一点,图 3 (a) 显示了从编译时部分到 Spark 的一种简单映射。
解释一下这个命令
好的,让我们用一个简单的例子来解释这个命令。
假设我们有一个DataFrame contribs,它记录了不同项目(键)的贡献值(值)。我们还有一个DataFrame links,它记录了项目之间的链接关系。
示例数据
DataFrame contribs:
project | value
--------|------
A | 10
B | 20
A | 30
C | 40
DataFrame links:
project | link
--------|-----
A | X
B | Y
C | Z
目标
我们的目标是计算每个项目的贡献值的85%,然后加上15,最后将结果与links DataFrame合并。
步骤
-
reduceByKey(_ + _):- 这个操作会将
contribsDataFrame中相同项目的值相加。 - 结果:
project | value --------|------ A | 40 B | 20 C | 40
- 这个操作会将
-
mapValues(v => 0.85 * v):- 这个操作会将每个项目的值乘以0.85。
- 结果:
project | value --------|------ A | 34 B | 17 C | 34
-
mapValues(v => 0.15 + v):- 这个操作会将每个项目的值加上0.15。
- 结果:
project | value --------|------ A | 34.15 B | 17.15 C | 34.15
-
join(links):- 这个操作会将上述结果与
linksDataFrame合并,只保留项目名称相同的行。 - 结果:
project | value | link --------|-------|----- A | 34.15 | X B | 17.15 | Y C | 34.15 | Z
- 这个操作会将上述结果与
最终结果
最终,我们得到了一个新的DataFrame,其中包含了每个项目的贡献值(经过计算后),以及它们对应的链接关系。
这个命令的目的是先对contribs DataFrame中的数据进行一些计算处理,然后将处理后的结果与links DataFrame合并,以便进行进一步的分析或操作。
解释完毕
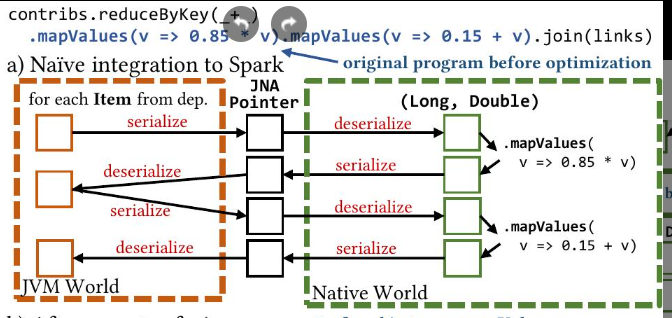
JNA Pointer是Java Native Access (JNA) 库中的一个概念,用于在Java程序中表示和操作C或C++等原生代码中的指针。它允许Java代码与本地库交互,访问和操作内存中的数据,以及调用原生函数。简而言之,JNA Pointer是一个桥梁,连接Java世界和原生世界,使得Java程序能够直接与底层系统交互。
序列化和反序列化的含义之前已经给出,具体来说,就是同一个数据,要进行格式转换。
每个 mapValues 转换都直接映射到一个 Spark RDD,并且每个值都映射到一个 Java 对象。尽管它很简单,但这种简单的集成方式存在很大的开销:处理像 long double 对这样简单的值需要在 JVM 世界中序列化/反序列化一次,在原生世界中序列化/反序列化一次,并且需要创建一个 Java 对象。这抵消了原生效率的性能优势。Chukonu 对编译时部分执行以下三个优化:首先,Chukonu 执行算子融合,这意味着 DAG 的每个编译时部分都被融合,以消除不必要的原生/JVM 交互。
只跑一趟就搞定。
图 3 (b) 说明了它的效果:
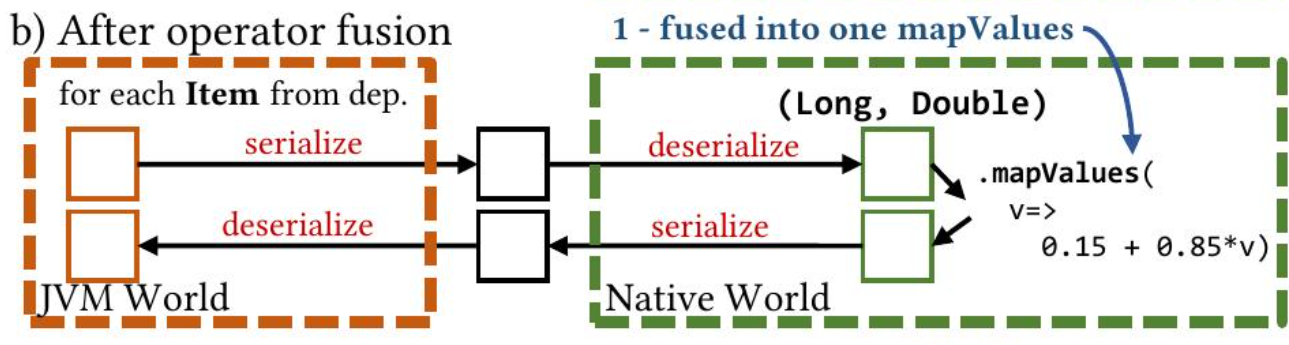
两个连续的 mapValues 被融合为一个 mapValues。然后,Chukonu 执行向量化,这会将每个元素的 JNA 调用转换为运行时部分和编译时部分边界上的每个批次的 JNA 调用,并且还向量化编译时部分中的融合算子。图 3 © 说明了它的主要效果:
这个就是为了并行,和ai里的vectorization是一个事情,就是要把for循环尽量变成矩阵运算
不过这里好像也不是为了并行,每次JNA调用,比如序列化和反序列化是有上下文切换,内存管理,同步等一系列开销的,减少一点开销是一点。
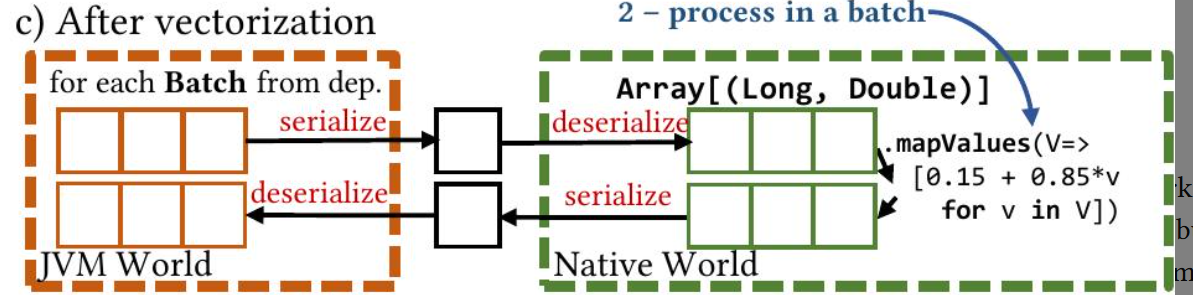
JNA 调用的数量减少了,因为 JNA 一次传递一个对数组。
最后,Chukonu 执行压缩,其中使用一些连续的内存缓冲区(称为紧凑数据布局)来表示一批元素。图 3 (d) 说明了它的影响: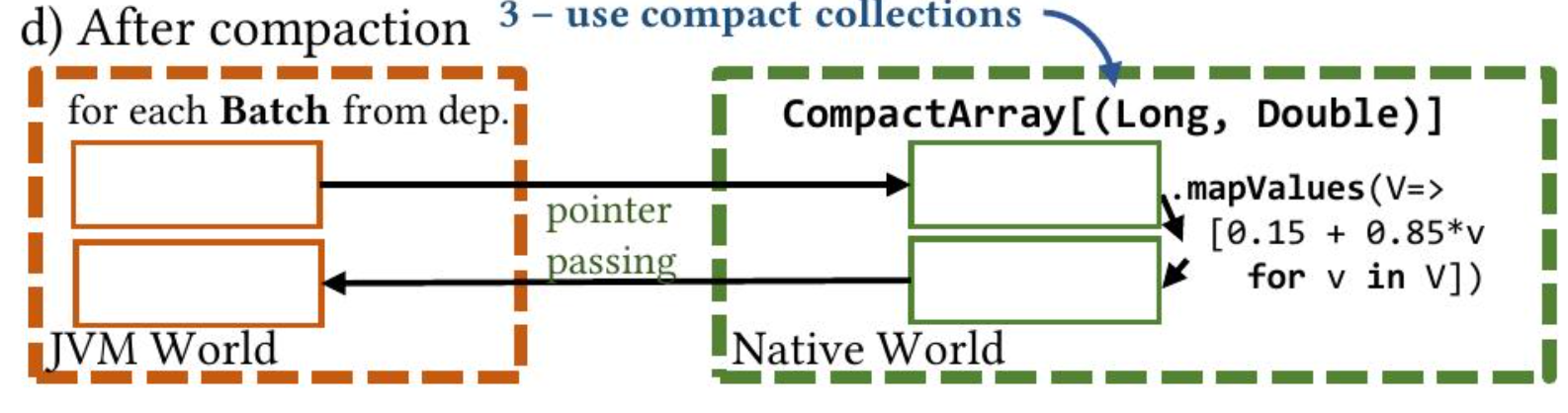
由缓冲区支持的紧凑的对数组通过指针显式传递,而无需数据序列化。这些优化由代码转换提供支持。图 4 从代码转换的角度说明了 Chukonu 的优化,其中包含页面排序 Chukonu 程序的一个片段。这些优化将在 §4.1 和 §4.2 中进一步讨论。
4 CHUKONU编程框架
在本节中,我们将介绍Chukonu编程框架的详细设计。Chukonu的架构如图5所示。
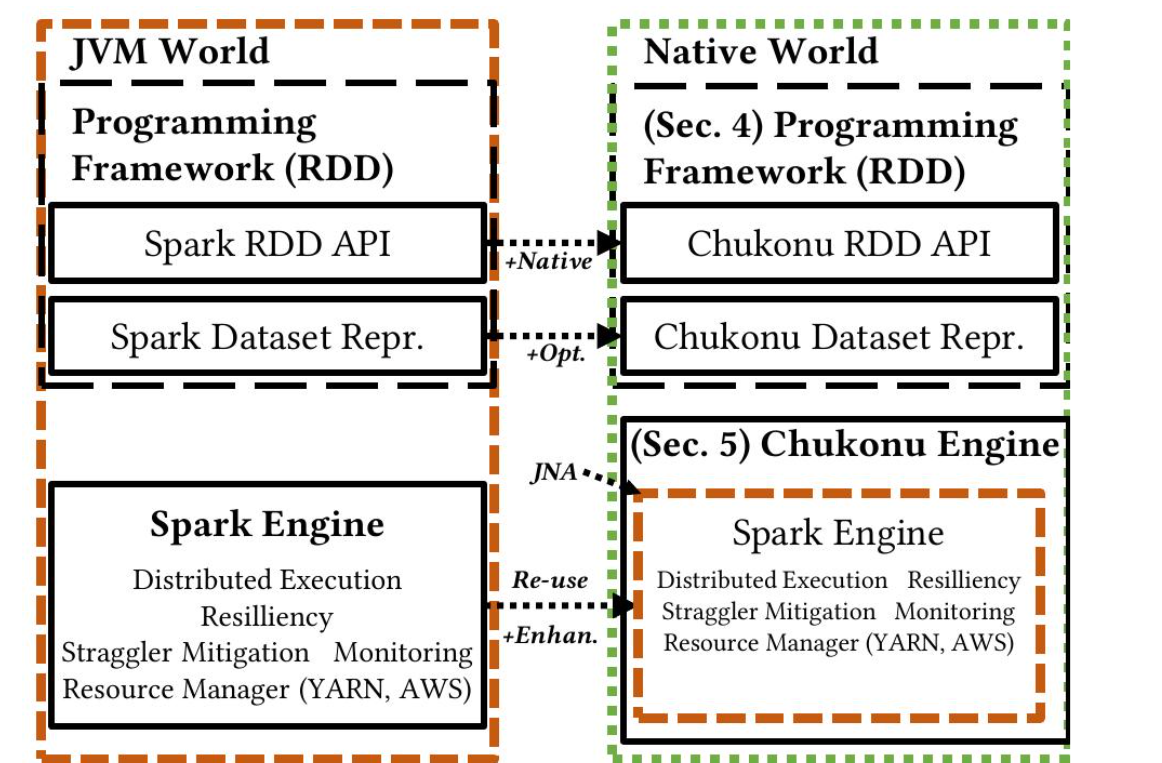
Chukonu为用户提供了一个原生的类似RDD的API来构建DAG程序。Chukonu(数据集)表示实现了DAG分割和优化,用于编译时部分。Chukonu在Spark之上实现了一个薄封装,称为Chukonu引擎,用于执行运行时部分。§4.1介绍了Chukonu表示,并讨论了DAG分割和优化是如何实现的。§4.2介绍了典型的紧凑数据布局。§4.3介绍了Chukonu的API。
有两个东西会比较重要, chukonu presentation和 chukonu engine