OPCap:Object-aware Prompting Captioning
研究方向:Image Captioning
1. 论文介绍
本文提出了一种目标感知的提示策略(OPCap)来有效缓解对象幻觉现象。具体方法是使用预训练的对象检测器来识别图像中的关键对象标签及其空间信息。然后根据这些空间信息提取相应的图像区域,并将它们输入到属性预测器中以获取对象的属性。这些对象标签和属性与由图像编码器提取的特征结合后传递给解码器,增强了模型对图像上下文的理解。

2. 方法介绍
该方法主要包括四个步骤:图像编码、对象检测、属性预测和解码。通过将检测到的对象及其属性整合到字幕生成过程中,OPCap增强了模型对图像上下文的理解,而不依赖外部语言模型。
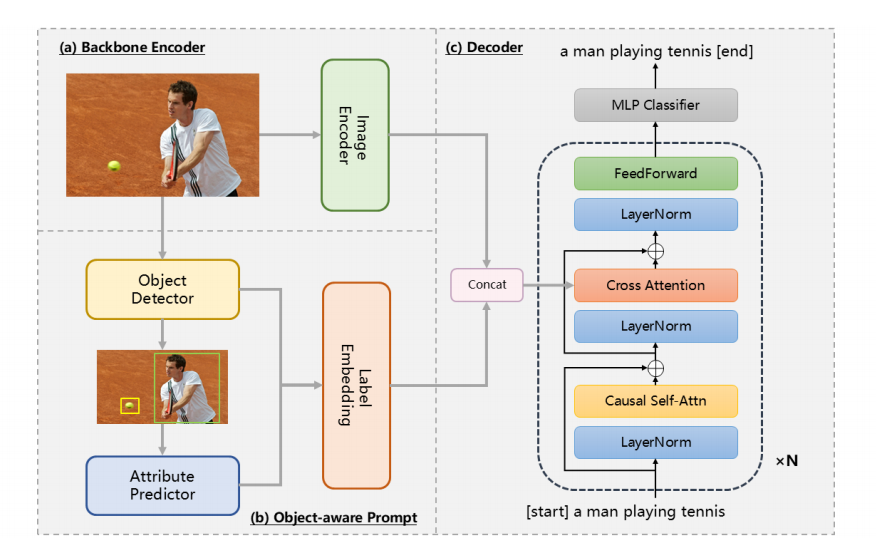
2.1 对象感知的提示
图像通过目标检测器后,我们获得图像内物体的标签和位置。然后裁剪这些物体区域,用作属性预测器的输入,预测详细的属性,如颜色、形状和状态。
属性预测是一个多标签分类任务。采用了CLIP作为图像编码器,并将其与多层感知器(MLP)分类器集成在一起。
在预测过程中,我们在应用sigmoid激活函数后选择前k个属性。生成的标签随后连接成一个自定义的标记序列。例如,当k=2时,相应的标记序列为:
[OBJ] person [ATTR] gray [ATTR] swinging
[OBJ] sports ball [ATTR] small[ATTR] rounded
嵌入后,标记序列与图像特征结合,作为输入传递给解码器。
2.2 caption生成与训练
图像分别输入到图像编码器和目标检测器。图像编码器输出 个特征向量,而目标检测器生成一个包含
个物体的列表。然后属性预测器为每个物体预测
个属性。为了区分这些信息片段,我们使用自定义的特殊标记来分隔与对象相关的信息。最后,通过嵌入层,这些信息被映射到
个特征向量中。

表示第
个样本,而
和
分别指代对象标签及其对应的边界框。
代表与每个对象相关联的属性。
和
都映射到相同的特征维度
,确保它们共享相同的嵌入空间。随后,这两个特征被连接起来,形成:
为了防止模型过度依赖语言先验并提高其鲁棒性,我们首先对文本中的标记应用随机丢弃,然后再将嵌入的文本输入到因果注意力层。表示处理过的输入字幕,
为Transformer的关键值对,
为查询。然后将Transformer的输出通过一个多层感知器分类器来完成解码过程:
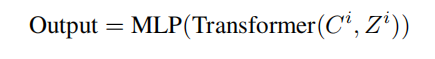
损失函数如下:
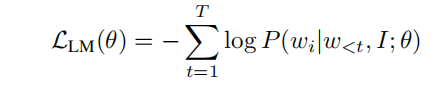
是在给定图像
、前面的词
和模型参数
的条件下生成词
的概率。
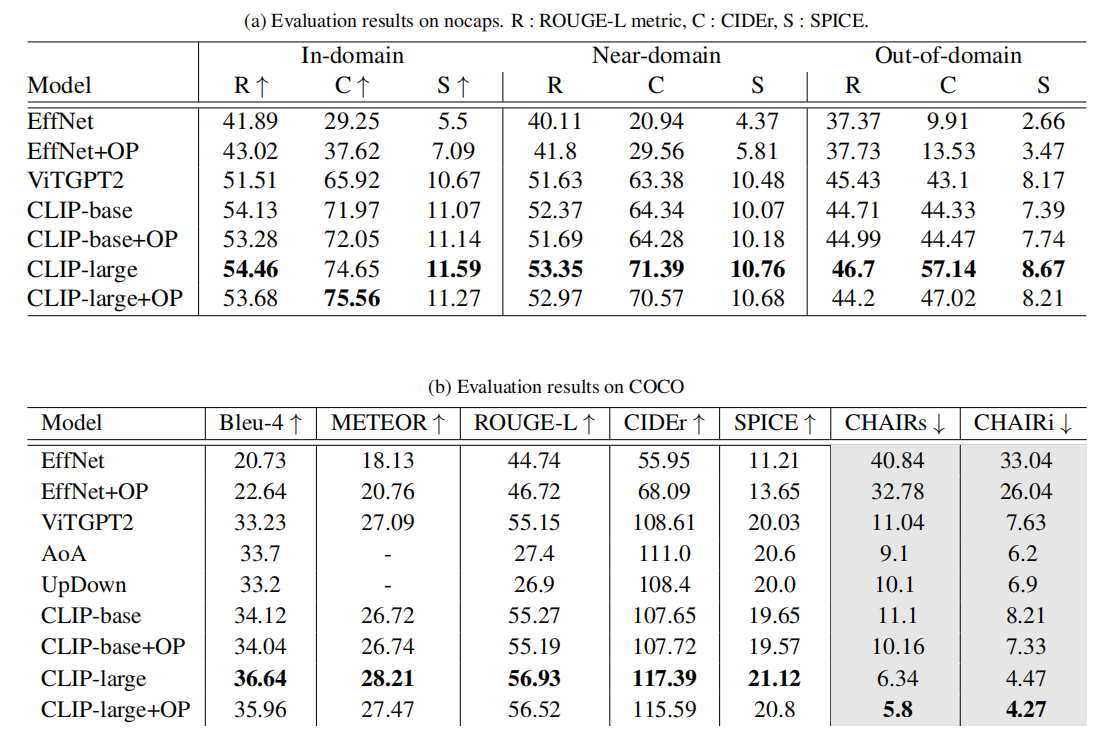
3. 实验
数据集: MSCOCO2017(最新的版本)
评估指标:常见有参指标CIDEr、BLEU、METEOR 和 SPICE;幻觉指标 CHAIRs 和 CHAIRi,分别评估句子级别和对象级别的幻觉。
定性分析:不同模型输出的比较,“+OP”表示采用了我们提出的对象感知提示方法的模型。