【MySQL】MySQL索引—B树/B+树
目录
1. 数据库索引
1.1 索引的概念
1.2 索引的特点
1.3 索引查询对比普通的查询
1.4 索引的操作
1.5 索引的原理
1.6 B树
1.7 B+树
1.8 B+树的优点
1. 数据库索引
1.1 索引的概念
数据库的索引是一种特殊的数据结构,里面包含着数据表中所有记录的引用,可以对表中一列或者多列创建索引并指定类型
可以将数据库的索引想象为书的目录,可以帮助数据库系统快速定位和访问表中的特定数据,而不必扫描整个表。
1.2 索引的特点
- 通过索引可以直接定位数据,不需要逐个扫描数据表中的记录,可以提高数据库的查询性能
- 数据表在进行插入/更新/删除操作时,因为要更新索引,导致效率降低
- 由于索引需要单独存储,需要引入额外的存储开销
- 一般建议高频的查询建立索引(如:根据用户名—密码)
- 在实际的工作中,查询使用的频率远远高于数据的增加/删除/修改
1.3 索引查询对比普通的查询
普通select查询
- 需要遍历整个表
- 将遍历的当前行带入条件中,看条件是否成立
- 如果条件成立,则将这一行保留,不成立则会跳过
索引查询
- 不需要遍历整个表
- 只需要读取索引页和少量的数据页
- 并通过索引数据结构(B+树)快速定位数据
索引属于针对查询操作进行的优化手段,可以通过索引来加快查询的速度,由于数据存储在硬盘中,如果每次插叙都访问硬盘,数据从硬盘中加载进入内存,进行对比,这一系列操作开销虽然不大,但是数据量如果非常多的话,则会导致开销很大,所以引入索引是很有必要的
1.4 索引的操作
(1)查看索引
show index from 表名;
(2)创建索引
create index 索引名 on 表名(字段名);
(3)删除索引
drop index 索引名 on 表名;
注意:
- 一个索引是针对一个列来指定的,只有这一列进行查询的时候,查询速度才会被优化
- 一个表中可以存在多个索引
- 创建索引一般在创建表的时候就需要规定好索引
- 如果现有的数据很多,整个时候如果增加一个索引,很有可能会造成数据库的崩溃
1.5 索引的原理
- 索引的实现肯定是依靠数据结构,但是我们平常使用的数据结构,并不适合
- 顺序表:适合通过下表访问和尾插
- 链表:适合中间插入和删除,不适合查询
- 栈/队列/堆:这些更不适合
- 二叉搜索树: 由于平衡性问题,查询效率会降低(不稳定),硬盘数据的存储效率低,查询效率低
- 哈希表:只适合点到点的精准查询,不能进行范围查询和模糊查询
- 红黑树:虽然可以精准查询和模糊查询,但是由于树的高度较高,查询访问的IO访问次数会变多
由于常见的这些数据结构,都不适合数据库操作,故引入了新的数据结构—B+树(N叉搜索树)
1.6 B树
在了解B+树之前,先了解B树
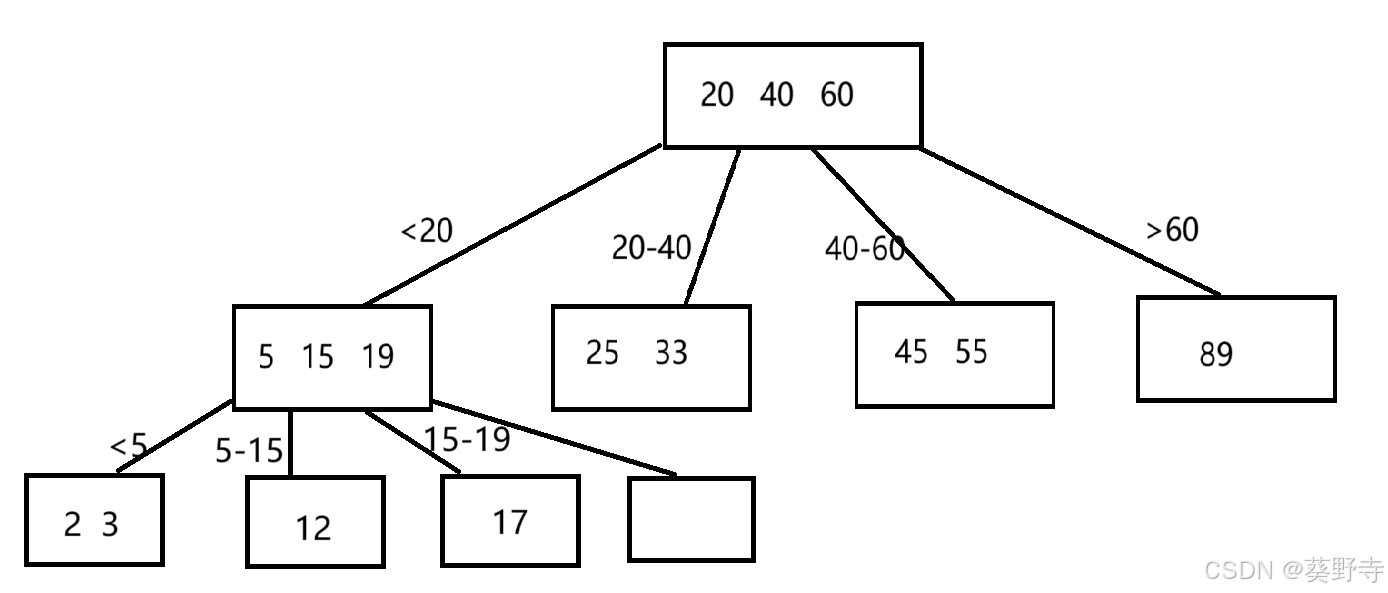
类似于这样的结构,就是B树
- 节点内部Key按顺序排列,自动保持树的高度平衡,所有叶子节点位于同一层,每个节点可以有多个子节点
- 每一个节点可以存在多个Key ,但是也不是无限存储,到达一定的规模会触发节点的分裂,删除元素到达一定的数据也会触发合并
- 一个节点上保存N个key值就可以划分出N+1个区间,每个区间都可以衍生出一系列的子树
- 像这些节点,都存储在硬盘的一块区域中,一次读取节点,意味着读取出多个Key,再进行几次比较,就可以快速找到自己想要的数值
1.7 B+树
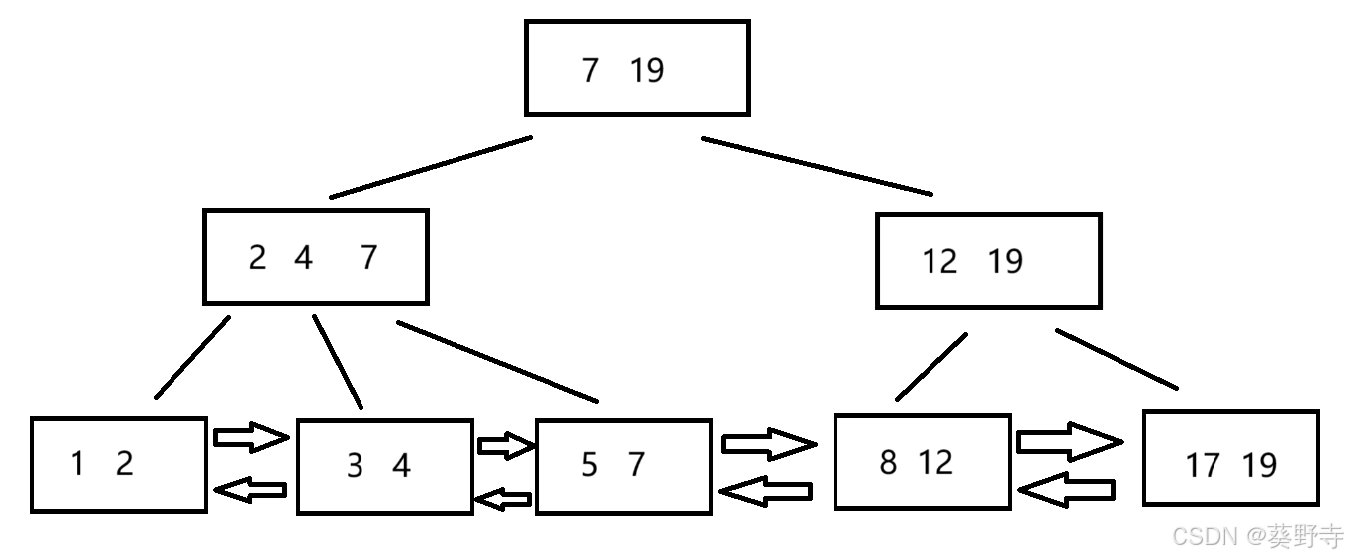
- 所有的数据都保存在叶子节点中,除叶子结点外的节点,不保存数据,只是用来索引
- 节点中,最右边为最大值(根节点中,最右边为整个元素中的最大值)
- 无论增加或删除什么元素,都需要保证根节点的最右边是最大元素
- 每一个父节点元素都出现在子节点中,是子节点最大(或最小)元素。
在进行查询的时候,从根节点触发,判定要查询的数据,在节点的那个区间,决定往哪里走,叶子节点之间,通过双链表进行连接,方便数据集合之间按照范围进行查询,也可以快速进行删除和增加等操作
1.8 B+树的优点
相比于B树,红黑树来说
- N叉搜索树,树的高度有限,降低了IO访问次数
- 由于叶子节点之间的链表结构,方便增加和删除操作
- 所有叶子节点之间属于有序链表,方便范围查询。
- 由于叶子节点存放数据,查询开销非常的稳定(稳定性好)