如何在生成式引擎优化(GEO)中取得成功
如果你希望您的内容出现在 AI Overviews、ChatGPT 和 Gemini 中?以下是设置 GEO 广告系列的方法。
任何好的 GEO 活动的第一步是创造一些东西实际上想要链接到或引用。
GEO 策略组件
想象一些你合理预期不会直接在 ChatGPT 或类似系统中找到的体验:
- 例如卢浮宫的 3D 导览或虚拟现实音乐会。
- 实时数据如价格、航班延误、可用酒店房间等。虽然大型语言模型(LLMs)可通过 API 集成此类数据,但我认为目前存在机会捕获部分此类流量。
- 需要 EEAT(经验、专业知识、权威性、可信度)的主题。
LLMs 无法拥有第一手经验。但用户希望获得。LLMs 有动力引用提供第一手经验的来源。这是需要记住的一点,但还有其他什么呢?
我们需要区分两种方法:影响基础模型与通过锚定影响LLM答案。前者对大多数创作者而言难以实现,而后者则提供了切实可行的机会。
影响基础模型
基础模型是在固定数据集上训练的,训练完成后无法学习新信息。对于当前的模型如GPT-4而言,已经为时已晚——它们已经完成训练。
但这对于未来至关重要:想象一台智能冰箱使用 2025 年的 o4-mini 系统,它可能——假设性地——更倾向于可口可乐而非百事可乐。这种偏见可能在未来数年内影响购买决策!
优化RAG/地面校准
当大型语言模型(LLMs)仅凭训练数据无法回答问题时,它们会使用检索增强生成(RAG)技术——从当前信息中提取内容以辅助生成答案。AI Overviews 和 ChatGPT 的网页搜索功能便是通过这种方式实现的。
作为 SEO 专业人士,我们希望实现以下三点:
- 我们的内容被选为信息来源。
- 我们的内容在这些来源中被引用最多。
- 其他被选中的来源支持我们的预期结果。
成功运用 GEO 的具体步骤
别担心,优化内容和品牌提及以适应大型语言模型(LLMs)并不需要高深的知识。实际上,许多传统的 SEO 方法仍然适用,其中一些可以融入你的工作流程。
步骤1:确保可爬取
听起来简单,但实际上这是非常重要的一步。如果你希望 LLMs 能够爬取你的网站,就必须允许它们这样做。OpenAI、Anthropic 等公司提供了多种 LLM 爬虫工具。
其中部分爬虫行为异常,可能触发反爬虫和 DDoS 防护机制。若您自动拦截了攻击性机器人,请与IT团队沟通,确保不会误拦截您关注的 LLM 爬虫。
若使用 CDN 服务(如:Fastly 或 Cloudflare),请确认LLM爬虫未被默认设置拦截。
步骤 2:继续提升传统排名
最关键的 GEO 策略其实非常简单。做好传统 SEO。在 Google(针对 Gemini 和 AI Overviews)、Bing(针对 ChatGPT 和 Copilot)、Brave(针对 Claude)以及百度(针对 DeepSeek)上获得良好的排名。
步骤 3:目标查询分支
当前一代的语言模型实际上比简单的 RAG 做了更多事情。它们会生成多个查询。这被称为查询分支。
例如,当我最近询问 ChatGPT “SEO 们讨论的最新 Google 专利是什么?”时,它进行了两次网络搜索,分别是 “SEO 们讨论的最新 Google 专利 2025 SEO 论坛” 和 “SEO 们讨论的最新 Google 专利 2025”。
建议:检查提示词的典型查询分支,并尝试为这些关键词进行排名。
我在 ChatGPT 中看到的典型扇出模式包括:当询问人们在讨论什么时,会附加“论坛”一词;当询问与某人相关的问题时,会附加“采访”一词。当前年份(2025)也常被添加。
注意:不同 LLM 的扇出模式存在差异,且随时间变化。我们今天看到的模式可能在12个月后不再适用。
步骤 4:确保品牌提及的一致性
这是每个人都应做到的简单事情——无论是作为个人还是企业。确保您在网上被一致地描述。在 X、LinkedIn、您自己的网站、Crunchbase、Github 等平台上,始终以相同的方式描述自己。
如果你在 X 和 LinkedIn 上的个人资料中称自己为“中小企业地理信息系统(GIS)顾问”,就不要在 Github 上改成“人工智能(AI)专家”,也不要在新闻稿中称自己为“机器学习(ML)自由职业者”。
我曾看到有人仅通过在网上保持一致的自我描述,就在 ChatGPT 和 Google AI Overviews 上取得了积极成果。这一点也适用于公关报道——你为品牌获得的报道越多且质量越高,LLMs 就越有可能将这些内容原封不动地反馈给用户。
步骤 5:避免使用 JavaScript
作为 SEO,我总是要求尽可能少地使用 JavaScript。作为 GEO,我坚决要求!
大多数 LLM 爬虫无法渲染 JavaScript。如果您的主要内容隐藏在 JavaScript 之后,您就出局了。
步骤 6:拥抱社交媒体与用户生成内容(UGC)
毫不意外,大型语言模型(LLMs)似乎非常依赖 Reddit 和维基百科。这两个平台几乎涵盖了所有主题的用户生成内容。得益于多层社区驱动的审核机制,大量垃圾信息和垃圾邮件已被过滤掉。
尽管两者均可被滥用,但其内容的平均可靠性仍远高于互联网整体水平。两者均会定期更新。
Reddit 还为 LLM 实验室提供了关于人们如何在线讨论话题、使用何种语言描述不同概念以及对冷门小众话题的知识等数据。
我们可以合理假设,在 Reddit、维基百科、Quora 和 Stack Overflow 等平台上经过审核的用户生成内容(UGC)将对 LLM 保持相关性。
我并不主张在这些平台上进行垃圾信息轰炸。然而,如果你能影响自己和竞争对手在这些平台上的展示方式,你可能希望这样做。
步骤 7:为机器可读性和可引用性创建内容
编写 LLMs 能理解并愿意引用的内容。目前还没有人完美地解决这个问题,但以下方法似乎有效:
- 使用陈述性和事实性语言。例如,不要写“我们觉得这双鞋对顾客来说不错”,而是写“96% 的买家表示对这双鞋感到满意”。
- 添加结构化数据标记(Schema)。这一话题曾多次被讨论。最近,必应(Bing)首席产品经理 Fabrice Canel 确认,结构化数据标记有助于 LLM 理解您的内容。
- 如果您希望内容被现有 AI Overviews 引用,请确保内容长度与现有内容相当。虽然不应直接复制现有 AI Overviews,但高余弦相似度有助于提升引用概率。对于技术控:是的,考虑到归一化,当然可以使用点积代替余弦相似度。
- 如果你在内容中使用了专业术语,请进行解释。最好用一句简单的话说明。
- 为长段落文本、评论列表、表格、视频及其他难以引用的内容格式添加摘要。
步骤8:优化你的内容

如果我们参考《GEO: Generative Engine Optimization》(arXiv:2311.09735)、《What Evidence Do Language Models Find Convincing? 》(arXiv:2402.11782v1)以及类似的科学研究,答案是明确的。这取决于具体情况!
要在某些 LLM 中被引用,以下几点有助于提升效果:
- 添加独特词汇
- 包含利弊分析
- 收集用户评价
- 引用专家观点
- 包含定量数据并注明来源
- 使用通俗易懂的语言
- 以积极的语气撰写
- 添加低困惑度(可预测且结构清晰)的产品文本
- 包含更多列表(如本段所示!)
然而,对于其他主题与LLM的组合,这些措施可能适得其反。
在广泛认可的最佳实践形成之前,我能给出的唯一建议是:以用户利益为先并进行实验。
步骤 9:坚持事实
十多年来,算法一直从文本中提取知识,将其表示为三元组(主体、谓词、对象)——例如,(自由女神像,位置,纽约)。与已知事实相矛盾的文本可能显得不可信。与共识一致但添加独特事实的文本是大型语言模型(LLMs)和知识图谱的理想选择。
因此,请坚持已确立的事实,并添加独特信息。
步骤 10:投资于数字公关
这里讨论的所有内容不仅适用于您自己的网站,也适用于其他网站上的内容。影响它的最佳方式是什么?数字公关!
您为品牌获得的覆盖范围越广、质量越高,大型语言模型(LLMs)就越有可能将这些内容原封不动地反馈给用户。
我甚至见过广告软文被用作信息来源的案例!
要尝试的具体 GEO 工作流程
在加入Peec AI之前,我曾是该平台的用户。以下是我使用该工具的方式,以及我建议我们的客户如何使用它。
了解您的竞争对手是谁
与传统 SEO 类似,使用一个好的地理定位工具(GEO 工具)往往能揭示出意想不到的竞争对手。定期查看自动识别出的竞争对手列表。对于那些让你感到意外的竞争对手,查看他们在哪些提示中被提及。然后检查导致他们被纳入的来源。你在这些来源中是否得到了恰当的呈现?如果没有,立即采取行动!
如果竞争对手是因为他们的 PeerSpot 个人资料而被提及,但你在那里没有评论,那就请客户留下评论。
你的竞争对手的 CEO 是否被一位 Youtuber 采访过?尝试也上那个节目。或者发布你自己的视频,针对类似的关键词。
你的竞争对手是否经常出现在前十名列表中,而你从未进入前五名?向创建该列表的发布者提供一个他们无法拒绝的联盟协议。在下一次内容更新时,你几乎可以肯定会成为新的第一名。
了解来源
在执行搜索基础时,LLM 依赖于来源。
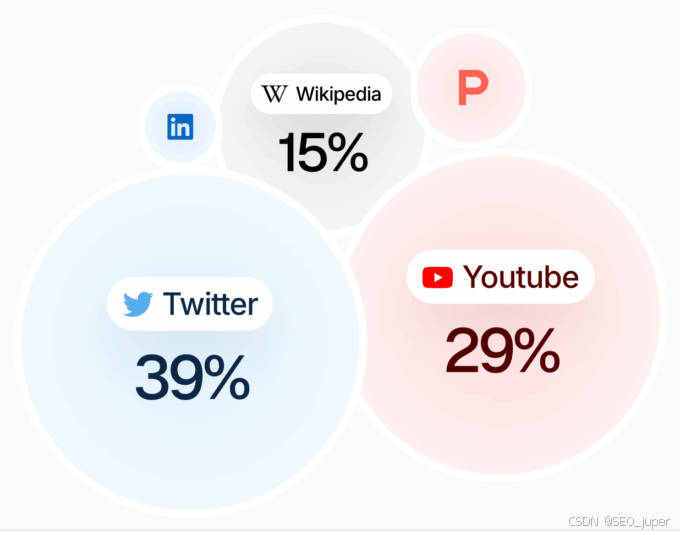
查看大量相关提示的顶级来源。暂时忽略你的网站和竞争对手。你可能会发现以下内容:
- 一个像 Reddit 或 X 这样的社区。加入社区并参与讨论。X 是你在 Grok 上影响结果的最佳选择。
- 一个由影响者驱动的网站,如:YouTube 或 TikTok。雇佣影响者制作视频。确保指导他们针对正确的关键词。
- 联盟发布商。通过支付更高佣金来提升排名。
- 新闻与媒体发布商。购买广告软文并/或通过公关活动针对他们。在某些情况下,你可能需要联系他们的商业内容部门。
你还可以查看这个。
目标查询扇出
一旦您观察到哪些搜索是由查询扇出触发的,针对这些搜索创建内容。
在您自己的网站上。通过在 Medium 和 LinkedIn 上发布文章。通过新闻稿。或者通过付费文章投放。如果它在搜索引擎中排名靠前,就有机会被基于 LLM 的回答引擎引用。
最后
生成式引擎优化已不再是可选项——它是自然增长的新前沿。在 Peec AI,我们正在构建工具,以追踪、影响并在这片新生态系统中取得胜利。
生成式引擎优化已不再是可选项——它是有机增长的新前沿。目前,我们看到客户的 LLM 流量每 2 到 3 个月就能增长 100%。有时,其转化率甚至能达到传统SEO流量的20倍!
无论您是正在塑造 AI 答案、监控品牌提及,还是推动内容可见性,现在正是采取行动的时机。