MySQL 9 Group Replication维护
MySQL 9 Group Replication维护
本文讲述Mysql 9 MGR的维护。
1. MGR在线配置
1.1 MGR在线配置注意事项
在配置整个组时,操作的分布式特性意味着它们与组复制插件的许多进程交互,应该遵守以下几点:
- 可以在任何地方发出配置操作。如果你想让成员A成为新的主成员,你不需要对成员A调用操作。所有操作都是以协调的方式在所有组成员上发送和执行的。
- 所有会员必须在线。组中当前不得包含分布式恢复过程中的任何成员。
- 在配置更改期间,任何成员都不能加入组。
- 一次只有一个配置。正在执行配置更改的组不能接受任何其他组配置更改。
1.2 改变主节点
使用group_replication_set_as_primary()函数更改单个主组的哪个成员是主节点,该函数可以在组的任何成员上运行。完成此操作后,当前主服务器将成为只读次服务器,指定的组成员将成为读/写主服务器;
SELECT group_replication_set_as_primary(member_uuid); #通传入要成为组新主成员的成员的server_uuid:
先查询组的当前状态
mysql> select * from performance_schema.replication_group_members;

SELECT group_replication_set_as_primary('3c50fdaf-6b49-11f0-8ed7-000c29f5cd1e', 300);
-- 300是可选项,为超时的时间, 当超时到期时,对于尚未达到提交阶段的任何事务,客户端会话将断开连接,因此事务不会继续进行。已达到提交阶段的事务可以完成。如果显式定义的事务(使用START TRANSACTION或BEGIN语句,事务将回滚)会受到超时、断开连接和传入事务阻止的影响,即使它们没有修改任何数据。

再次查询组状态
mysql> select * from performance_schema.replication_group_members;

dbserver02 成为主节点
要检查超时状态,请使用性能模式线程表中的PROCESSIST_INFO列,如下所示:
mysql> SELECT NAME, PROCESSLIST_INFO FROM performance_schema.threads
WHERE NAME="thread/group_rpl/THD_transaction_monitor";

当操作运行时,通过下面显示的语句来检查其进度:
mysql> SELECT event_name, work_completed, work_estimated FROM performance_schema.events_stages_current
WHERE event_name LIKE "%stage/group_rpl%";

2. 更改组运行模式
2.1 更改组运行模式为单主模式
SELECT group_replication_switch_to_single_primary_mode();
当更改为单主模式时,所有组成员也会按照单主模式的要求禁用严格的一致性检查:group_replication_enforce_update_everywhere_checks=OFF
如果没有传入字符串member_uuid,则在生成的单一初选组中选举新的初选将遵选举政策。
要覆盖选举过程并将多主组的特定成员配置为该过程中的新主,请获取该成员的server_uuid并将其传递给group_replication_switch_To_sonline_primary_mode()
SELECT group_replication_switch_to_single_primary_mode(member_uuid);
先查询组状态:
mysql> select * from performance_schema.replication_group_members;

进行切换
mysql> SELECT group_replication_switch_to_single_primary_mode('6c440f84-6c92-11f0-8cc4-000c29dfd734');

再次查询组状态:
mysql> select * from performance_schema.replication_group_members;

组变成单组模式,dbserver01变成主节点。
2.2 改组运行模式为多主模式
使用group_replication_switch_to_multi_primary_mode()函数通过发出以下命令将以单主模式运行的组更改为多主模式:
SELECT group_replication_switch_to_multi_primary_mode();
先查询组状态:
mysql> select * from performance_schema.replication_group_members;

执行切换
mysql> SELECT group_replication_switch_to_multi_primary_mode();
 再次查询组状态:
再次查询组状态:
mysql> select * from performance_schema.replication_group_members;

- 经过一些协调的组操作以确保数据的安全性和一致性后,属于该组的所有成员都将成为主要成员。
- 当您将组从单主模式更改为多主模式时,如果成员运行的MySQL服务器版本高于组中存在的最低版本,则会自动将其置于只读模式。
检查其进度:
SELECT event_name, work_completed, work_estimated FROM performance_schema.events_stages_current WHERE event_name LIKE "%stage/group_rpl%";

3. 使用组复制组写入共识实例数
组复制组写入最大共识实例数被称为组的事件范围,是组可以并行执行的共识实例的最大数量。这使您能够微调组复制部署的性能。例如,默认值10适用于在局域网(LAN)上运行的组,但对于在广域网(WAN)等较慢网络上运行的各组,请增加此值以提高性能。
3.1 检查组的写入并发性
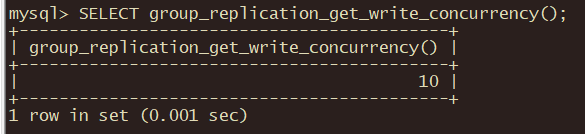
使用group_replication_get_write_concurrency()函数在运行时通过发出以下命令来检查组的事件范围值:
mysql> SELECT group_replication_get_write_concurrency();
3.2 配置组的写入并发性
使用group_replication_set_write_concurrency()函数通过发出以下命令来设置系统可以并行执行的共识实例的最大数量:
mysql>SELECT group_replication_set_write_concurrency(20);

4. 集群通信协议版本设置
从MySQL 8.0.16开始,MGR就有了组通信协议的概念。可以显式地管理组复制通信协议的版本,并将其设置为希望组支持的最老的MySQL Server版本号。这使得集群允许由运行在不同MySQL Server版本的节点组成,同时确保向后兼容性。
检查组使用的通信协议:
mysql> SELECT group_replication_get_communication_protocol();
设置组的通讯协议
SELECT group_replication_set_communication_protocol("5.7.25");
- 如果将组中所有成员都升级到新的MySQL Server版本,则组不会自动将该组的通信协议版本升级到匹配最新的版本。必须使用group_replication_set_communication_protocol() UDF将通信协议版本设置为最新MySQL Server版本。
- group_replication_set_communication_protocol() UDF作为一个MGR操作实现,因此它同时在MGR集群的所有节点上执行。执行该函数过程中,集群操作会缓冲消息并等待通讯协议版本修改完成之后再将缓冲的消息发送出去。如果某个Server在更改通信协议版本后尝试加入集群,则集群中的节点将使用最新的通讯协议版本来决定是否允许该Server加入集群。
5. 配置成员操作
- performance_schema.replication_group_member_actions列出了配置中可用的成员操作、触发这些操作的事件以及它们当前是否已启用。成员操作的优先级为1到100,较低的值将首先执行。如果在执行成员操作时发生错误,可以记录成员操作的失败,但可以忽略。如果成员操作的失败被认为是严重的,则可以根据group_replication_exit_state_action系统变量指定的策略进行处理。
mysql> select * from performance_schema.replication_group_member_actions;

- mysql.replication_group_configuration_version表记录了成员操作配置的当前版本,可以使用性能架构表replication_group_conguration_version查看该表。每当使用函数启用或禁用成员操作时,版本号都会递增。
- group_replication_reset_member_actions函数只能在不属于组的服务器上使用。它将成员操作配置重置为默认设置,并将其版本号重置为1。服务器必须是可写的(只读系统变量设置为OFF),并且安装了组复制插件。如果您打算将服务器用作没有成员操作或不同成员操作的独立服务器,则可以使用此功能删除服务器在作为组的一部分时使用的成员操作配置。
- mysql_disable_super_read_only_if_primary 在选择新的主模式时,处于单主模式的组保持在super_read_only模式.
默认情况下,当主服务器选择超级只读模式时,它会被禁用,这样主服务器就会变成读/写模式,并接受来自复制源服务器和客户端的更新。
如果使用group_replication_disable_member_action()函数将操作设置为禁用,则主服务器在选举后仍将保持超级只读模式。
6. 重启组服务
组复制旨在确保数据库服务持续可用,即使组成组的某些服务器目前由于计划内维护或计划外问题而无法参与其中。只要剩下的成员是该团体的大多数,他们就可以选举一个新的初选,并继续作为一个组运作。但是,如果复制组的每个成员都离开该组,并且通过STOP group_replication语句或系统关闭在每个成员上停止组复制,则该组现在仅在理论上作为成员上的配置存在。在这种情况下,要重新创建组,必须像第一次启动一样通过引导来启动。
第一次引导组与第二次或后续引导组之间的区别在于,在后一种情况下,被关闭的组的成员可能具有彼此不同的事务集,具体取决于它们被停止或失败的顺序。如果一个成员有其他组成员没有的事务,则该成员无法加入组。对于组复制,这包括已提交和应用的事务(位于gtid_executed gtid集中)以及已认证但尚未应用的事务,位于Group_Replication_applier通道中。提交事务的确切时间取决于为组设置的事务一致性级别。但是,组复制组成员从不删除已认证的事务,这是该成员提交事务意图的声明。
因此,必须从最新的成员开始重新启动复制组,即执行和认证事务最多的成员。然后,事务较少的成员可以通过分布式恢复加入并赶上他们丢失的事务。假设组中最后一个已知的主要成员是组中最新的成员是不正确的,因为比主要成员晚关闭的成员可能有更多的事务。因此,您必须重新启动每个成员以检查事务,比较所有事务集,并确定最新的成员。然后,此成员可用于引导组。
按照下面步骤安全启动复制组:
(1) mysql> stop group_replication;
(2) 确保my.cnf中group_replication_start_on_boot=OFF,防止MySQL服务器启动时启动组复制,这是默认设置。
(3) 如果您无法在系统上更改该设置,则可以允许服务器尝试启动组复制,但由于组已完全关闭且尚未启动,因此将失败。如果你采取这种方法,在这个阶段不要在任何服务器上设置group_replication_boottrap_group=ON。
(4) 启动MySQL Server实例,并验证组复制是否尚未启动(或启动失败)。在此阶段不要启动组复制。
(5)从组成员那里收集以下信息:
mysql> SELECT @@GLOBAL.GTID_EXECUTED;
从group_replication_applier渠道上经过认证的事务集。
mysql> SELECT received_transaction_set FROM performance_schema.replication_connection_status WHERE channel_name="group_replication_applier";
(6) 从所有组成员收集事务集后,比较它们以找出哪个成员拥有最大的事务集,包括已执行的事务(gtid_executed)和已认证的事务(在group_replication_applier通道上)。使用具有最大事务集的成员引导组。
mysql> SET GLOBAL group_replication_bootstrap_group=ON;
mysql> START GROUP_REPLICATION;
mysql> SET GLOBAL group_replication_bootstrap_group=OFF;
(7) 验证组中是否存在此创始成员
mysql> SELECT * FROM performance_schema.replication_group_members;
(8) 通过对每个成员执行START group_REPLICATION语句,将每个其他成员重新添加到组中。
mysql> START GROUP_REPLICATION;
(9) 验证每个成员是否已加入组
mysql> SELECT * FROM performance_schema.replication_group_members;
7. 配置事务一致性保证
Group_Replication_consistance变量配置的可能一致性级别,按事务一致性保证的顺序排列:
- EVENTUAL
只读或读/写事务在执行之前都不会等待前面的事务被应用。在主故障转移的情况下,新的主可以在应用之前的所有主事务之前接受新的只读和读/写事务。只读事务可能会导致值过时,读/写事务可能会因冲突而导致回滚。
- BEFORE_ON_PRIMARY_FAILOVER
在应用了任何积压之前,不会应用与新选定的主服务器的新只读或读/写事务,该主服务器正在应用旧主服务器的积压。这确保了当主故障转移发生时,无论是否有意,客户端始终能看到主故障转移的最新值。这保证了一致性,但意味着客户端必须能够在应用积压的情况下处理延迟。通常这种延迟应该是最小的,但它确实取决于积压的大小。
- BEFORE
读/写事务在应用之前等待所有前面的事务完成。只读事务在执行之前等待所有前面的事务完成。这确保了此事务仅通过影响事务的延迟来读取最新值。通过确保同步仅用于只读事务,这减少了每个读/写事务的同步开销。此一致性级别还包括BEFORE_ON_PRIMARY_FAILOVER提供的一致性保证。
- AFTER
读/写事务会等待,直到其更改已应用于所有其他成员。此值对只读事务没有影响。此模式可确保在本地成员上提交事务时,任何后续事务都会读取任何组成员上的写入值或最新值。将此模式与主要用于只读操作的组一起使用,以确保应用的读/写事务在提交后应用于所有地方。这可以由您的应用程序使用,以确保后续读取获取包括最新写入的最新数据。通过确保同步仅用于读/写事务,这减少了每个只读事务的同步开销。此一致性级别还包括BEFORE_ON_PRIMARY_FAILOVER提供的一致性保证。
- BEFORE_AND_AFTER
读/写事务在应用之前等待1)所有前面的事务完成,2)直到其更改已应用于其他成员。只读事务在执行之前等待所有前面的事务完成。此一致性级别还包括BEFORE_ON_PRIMARY_FAILOVER提供的一致性保证。
BEFORE_and_AFTER一致性级别可用于只读和读/写事务。AFTER一致性级别对只读事务没有影响,因为它们不会生成更改。
以下场景显示了如何根据您使用组的方式选择一致性保证级别:
场景1:您希望在不担心过时读取的情况下平衡读取,并且组写入操作比组读取操作少得多。在这种情况下,您应该选择AFTER。
场景2:对于应用多次写入的数据集,您希望偶尔执行读取,而不必担心读取过时的数据。在这种情况下,你应该选择之前。
场景3:您希望特定事务只从组中读取最新数据,这样每当更新文件凭据等敏感数据时,读取总是使用最新值。在这种情况下,你应该选择之前。
场景4:对于一个主要具有只读数据的组,您希望读/写事务在提交后应用于所有地方,以便后续读取是在包括您最新写入的数据上完成的,并且您不会为每个只读事务承担同步成本,而只对读/写交易承担同步成本。在这种情况下,您应该选择AFTER。
场景5:对于主要使用只读数据的组,您希望读/写事务从组中读取最新数据,并在提交后应用于任何地方,以便对包括最新写入的数据执行后续读取,并且您不会为每个只读事务承担同步成本,而只对读/写交易承担同步成本。在这种情况下,您应该选择BEFORE_AND_AFTER。
要强制当前会话的一致性级别,请使用会话范围,如下所示:
SET @@SESSION.group_replication_consistency= 'BEFORE';
要强制所有会话的一致性级别,请使用全局作用域,如下所示:
SET @@GLOBAL.group_replication_consistency= 'BEFORE';
场景6:一个给定的系统处理多个不需要强一致性级别的指令,但有一种指令确实要求强一致性:管理文档的访问权限;在这种情况下,系统会更改访问权限,并希望确保所有客户端都看到正确的权限。您只需在这些指令上设置@@SESSION.group_replication_consistance='AFTER',并让其他指令在全局范围内设置EVENTUAL的情况下运行。
场景7:在场景6中描述的同一系统上,需要使用最新数据每天执行一个执行分析的命令。要实现这一点,您只需在执行命令之前运行SQL语句SET@@SESSION.group_replication_consistance='BEFORE'。
BEFORE一致性级别除了在事务流上排序外,只影响本地成员。也就是说,它不需要与其他成员协调,也不会对他们的交易产生影响。换句话说,BEFORE只会影响使用它的事务。
AFTER和BEFORE_and_AFTER一致性级别确实对在其他成员上执行的并发事务有副作用。如果具有EVENTUAL一致性级别的事务在执行AFTER或BEFORE_AND_AFTER事务时启动,这些一致性级别会使其他成员事务等待。即使其他成员的事务具有EVENTUAL一致性级别,其他成员也会等待该成员提交AFTER事务。换句话说,AFTER和BEFORE_and_AFTER会影响所有在线组成员。
持久化到其配置中
SET PERSIST group_replication_consistency='BEFORE_ON_PRIMARY_FAILOVER';
这确保了所有成员的行为都是相同的,并且配置在成员重新启动后得以持久。
尽管在使用BEFORE_ON_PRIMARY_FAILOVER一致性级别时,所有写入都被保留,但并非所有读取都被阻止,以确保在升级后应用积压时,您仍然可以检查服务器。这对于调试、监控、可观察性和故障排除非常有用。允许进行一些不修改数据的查询,例如:
show语句, set语句,不使用表或可加载函数的DO语句,空声明,USE声明,
在performance_schema 和 sys 数据库使用select, 对infoschema数据库中的PROCESSIST表使用SELECT语句,不使用表或可加载函数的SELECT语句, STOP GROUP_REPLICATION, SHUTDOWN statements, RESET PERSIST 语句。
8. 组复制分布式恢复
组复制在分布式恢复期间使用以下方法的组合进行状态传输:
使用克隆插件的功能进行远程克隆操作。要启用此状态传输方法,您必须在组成员和加入成员上安装克隆插件。组复制会自动配置所需的克隆插件设置并管理远程克隆操作。
从捐赠者的二进制日志中复制并将事务应用于加入的成员。此方法使用名为group_replication_recovery的标准异步复制通道,该通道在供体和加入成员之间建立。
连接尝试次数
如果2个组成员是合适的捐赠者,并且连接重试限制设置为4,则加入成员在达到限制之前会尝试2次连接到每个捐赠者。
默认连接重试限制为10。以下命令将连接到捐赠者的最大尝试次数设置为5:
mysql> SET GLOBAL group_replication_recovery_retry_count= 5;
连接尝试的睡眠间隔
如果2个组成员是合适的捐赠者,并且连接重试限制设置为4,则加入成员会尝试连接到每个捐赠者,然后在连接重试间隔内休眠,然后在达到限制之前再次尝试连接到每一个捐赠者。
默认连接重试间隔为60秒,您可以动态更改此值。以下命令将分布式恢复供体连接重试间隔设置为120秒:
mysql> SET GLOBAL group_replication_recovery_reconnect_interval= 120;