python案例分析:基于抖音评论的文本分析,使用svm算法进行情感分析以及LDA主题分析,准确率接近90%
思路步骤:
本文实现了从相关文本评论数据中提取有用信息,分析其情感分布、主题分布,并通过可视化展示。以下是具体步骤和思路:
1、数据准备与预处理
加载数据:通过 pandas 读取抖音一二级的评论数据,并进行合并处理。
文本清洗与分词:使用正则表达式提取中文字符,并调用 jieba 对文本进行分词,同时去除停用词,保留有意义的词语。
文本筛选:筛选剔除重复内容,以确保分析的效率和数据质量。
2、情感分析与可视化
情感分析:利用svm模型对评论数据进行训练,分类为“正面”“中性”或“负面”。
可视化展示:统计情感分布并绘制饼图,用不同颜色表示情感类别,直观反映用户反馈。
3、主题分析:
进行一致性和困惑度计算,通过改变主题数量范围,计算不同主题数量下的一致性和困惑度,并绘制折线图展示结果。
进行主题建模和关键词提取,使用LDA模型对分词结果进行主题建模,并提取每个主题的关键词。对主题建模结果进行可视化,使用pyLDAvis库生成LDA主题模型的可视化结果,并保存为HTML文件。根据LDA模型计算主题之间的相关性和关键词之间的权重。
数据处理实现:
数据准备与预处理在文本分析中至关重要,是后续建模与分析的基础。本文中的数据准备与预处理主要包括以下步骤:
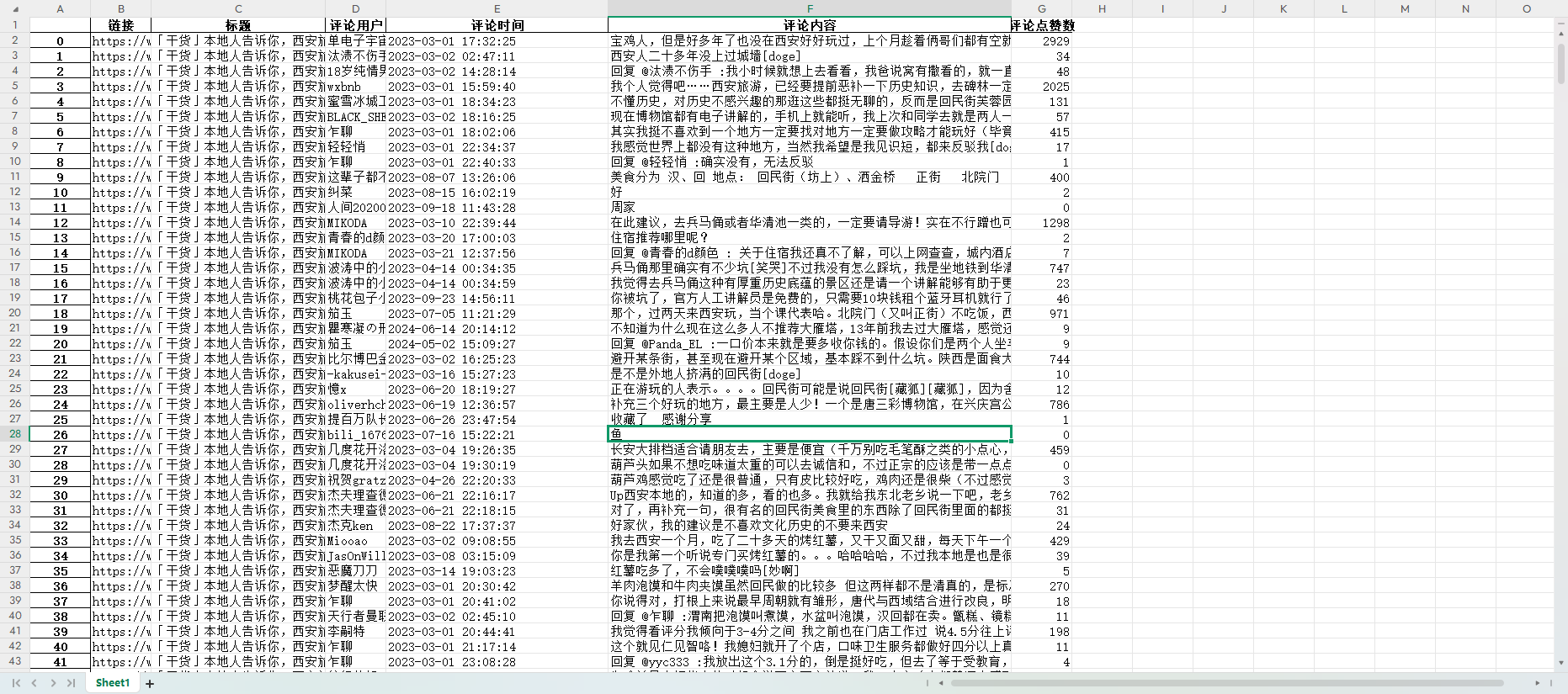
1、数据加载:通过 pandas 读取评论数据 DataFrame 格式。

- 数据清洗与筛选:通过 drop_duplicates 去重,避免因重复数据影响分析结果。
去重前:

去重后:

- 文本预处理:对评论内容进行分词和清洗。利用正则表达式提取中文字符后,通过 jieba 进行分词,并加载停用词表过滤掉无意义的高频词和单字。最后将处理后的分词结果重新拼接成文本,便于后续特征提取。
清洗完成后:
停用词:

词频分析:
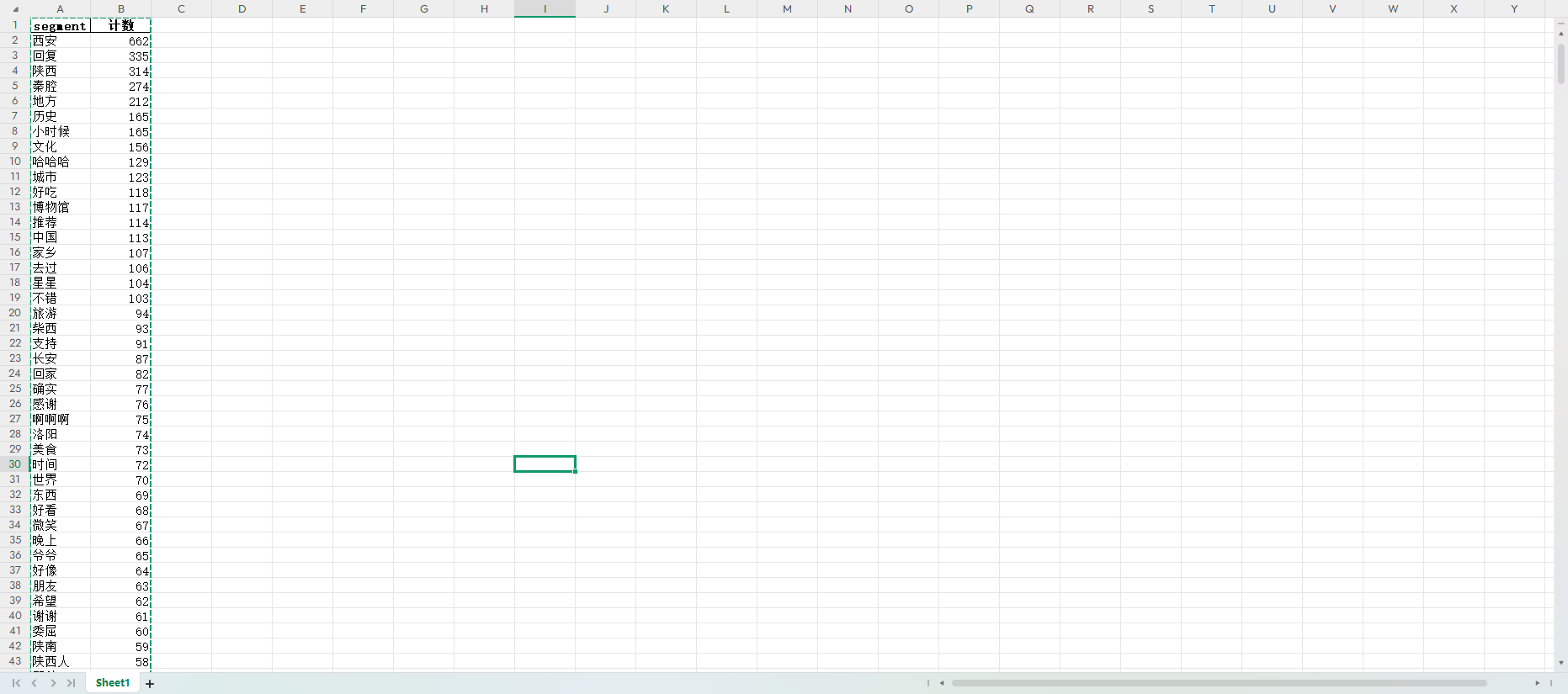
在词频分析中,核心目标是统计文本中每个词出现的频率,以发现高频词和潜在的关键词。实现过程中,首先需要对文本进行预处理,包括去除停用词、标点符号等无效信息,并通过分词工具(如 jieba)将句子拆分为词语。然后,利用数据结构(如字典或 Counter)统计每个词的出现次数。将结果按频率从高到低排序,提取高频词以生成词云或柱状图进行可视化。此外,结合 TfidfVectorizer 提取权重更高的关键词,与简单词频分析的结果进行对比分析,从而提升分析的精准性和有效性。这种方法广泛应用于文本挖掘、舆情监控等领域。积极词频结果如下:
词频表:
词云图:

西安及陕西相关词汇频率较高,显示出该地区在话题讨论中的主导地位。其中,“西安”出现最大,表明该城市是讨论的核心,紧随其后的“陕西”和“长安”也进一步强化了地域的关注度。此外,“历史”和“文化”等词汇的高频出现,表明与西安及陕西相关的传统文化和历史遗产是讨论的重点。
从情感和日常体验角度看,“小时候”和“家乡”反映出对地方记忆和归属感的讨论,而“美食”和“旅游”则突出与该地区的体验相关的主题。
此外,诸如“感谢”、“支持”等词汇反映出积极的情感和对西安及陕西的肯定,表明该地在用户心中占有正面形象。数据体现了对陕西及西安历史文化、家乡记忆以及旅游体验的浓厚兴趣。
消极词频结果如下:
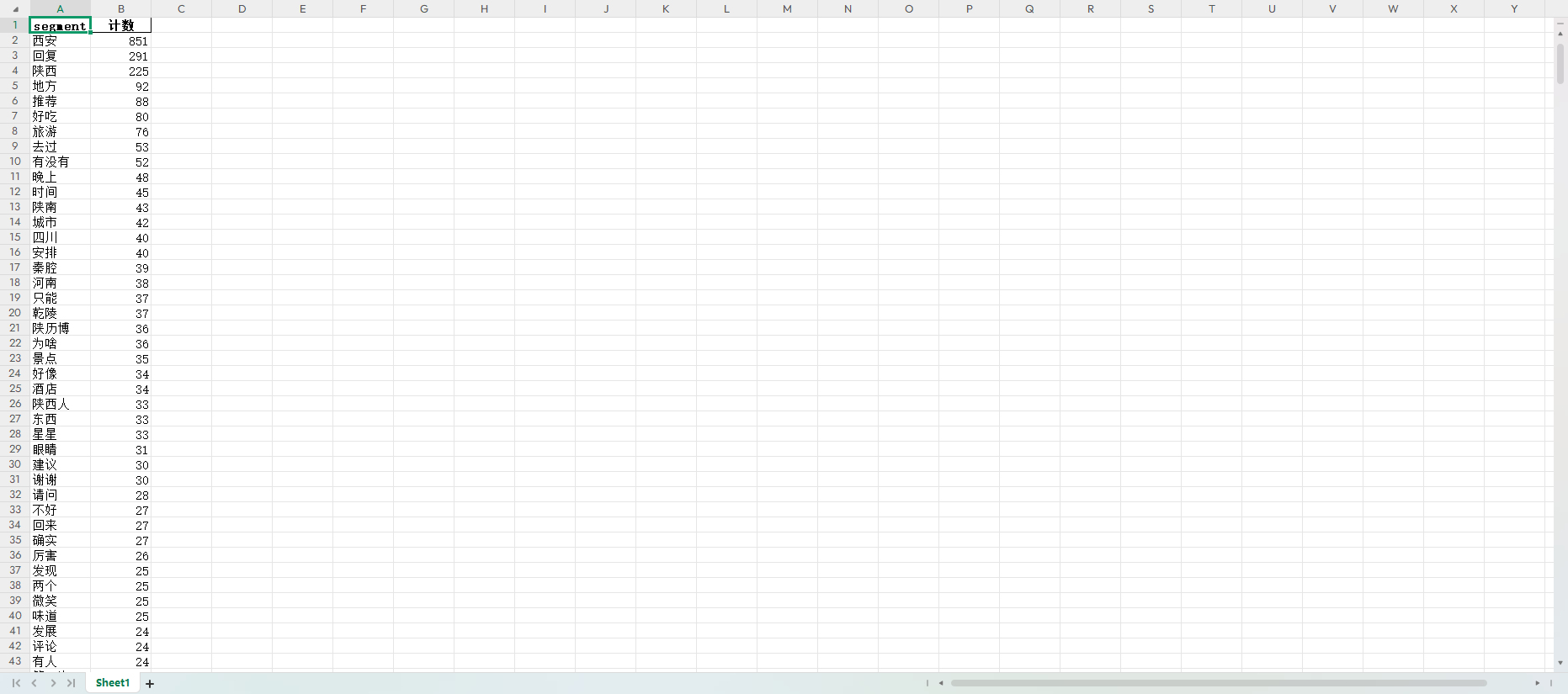
词云图:

消极情绪和负面反应的词汇相对较少,但仍有一定的反映。例如,“不行”、“不好”和“可惜”表明在讨论中有一些不满或遗憾的情绪。这些词汇的出现可能与某些地方的体验或服务不尽如人意有关。此外,“疫情”和“天气”也暗示着用户在讨论过程中提到的环境因素或不便情况。
不过,相较于积极词汇,这些消极情感的频次较低,显示出用户对西安及陕西的整体印象仍然是积极的。负面情绪的出现通常与特定的情况或体验相关,如“门票”)和“导游”(18次)等与旅行体验相关的词汇,可能反映了一些关于旅行安排或服务的意见。尽管有一些负面反馈,但这些反映的情绪并不占主导,说明对西安及陕西的讨论中仍以正面评价为主。
情感分析实现与结果可视化
支持向量机(SVM)是一种常用的监督学习算法,广泛应用于分类和回归任务。在情感分析中,SVM被用于根据文本数据预测情感类别(如正面、负面、中性)。其基本思想是通过找到一个最优超平面,将不同类别的数据点分开,以最大化类别间的间隔(Margin)。SVM的目标是使得样本点到超平面的距离尽可能远,从而提高模型的泛化能力。
SVM首先通过核函数将低维数据映射到高维空间,以便更容易地找到一个分隔不同类别的超平面。常见的核函数有线性核、RBF(径向基函数)核等。通过优化算法,SVM找到使分类间隔最大的超平面,并且能够处理复杂的非线性分类问题。
在SVM建模与预测实现中,首先通过词向量模型将文本转换为数值特征。步骤如下:
特征工程:使用改进的Word2Vec模型生成300维词向量,通过TF-IDF加权计算文本向量,并对特征进行标准化处理(StandardScaler)。

处理类别不平衡:采用SMOTE对训练数据过采样,均衡各类样本分布。

模型调优:配置SVC基础模型(RBF核、类别加权),通过网格搜索(GridSearchCV)在参数空间(C、gamma)中交叉验证,以AUC为指标选择最优参数组合。

模型训练:使用最优参数重新训练SVM模型,支持多分类概率预测。
预测与评估:对标准化后的测试数据调用predict()获取类别标签,用predict_proba()输出概率。通过分类报告、混淆矩阵和ROC曲线评估性能,计算宏观AUC值。
模型保存:将训练好的SVM模型、标准化器及词向量模型持久化,便于后续部署。整个过程强调特征优化、参数调校及不平衡数据处理,以提升分类效果,并应用于测试集中积极:中性:消极=1:2:1进行预测。模型的性能通过分类报告、混淆矩阵和ROC曲线等指标进行评估,确保其在情感分析任务中的准确性和可靠性。随后,利用 Pandas 的 groupby 方法对情感分析结果进行分组统计,得到各情感类别下评论数量的统计结果。最后,利用 Matplotlib 库绘制了饼图,展示了不同情感类别在内容中的占比情况。
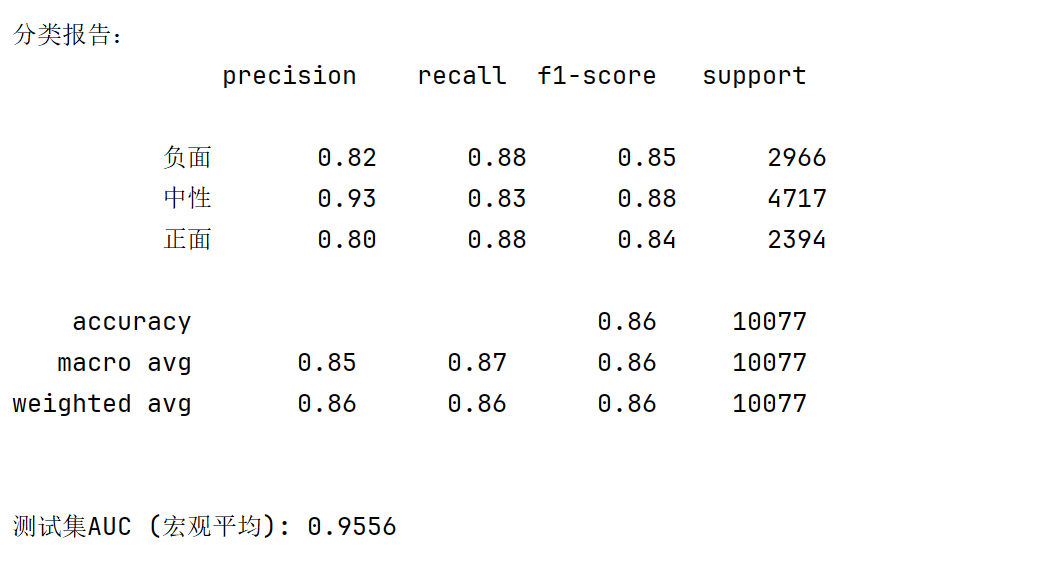
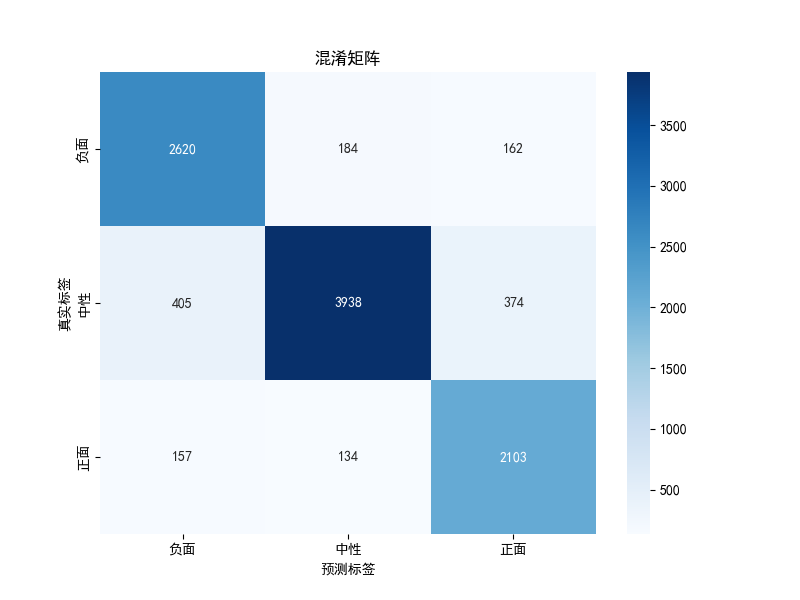
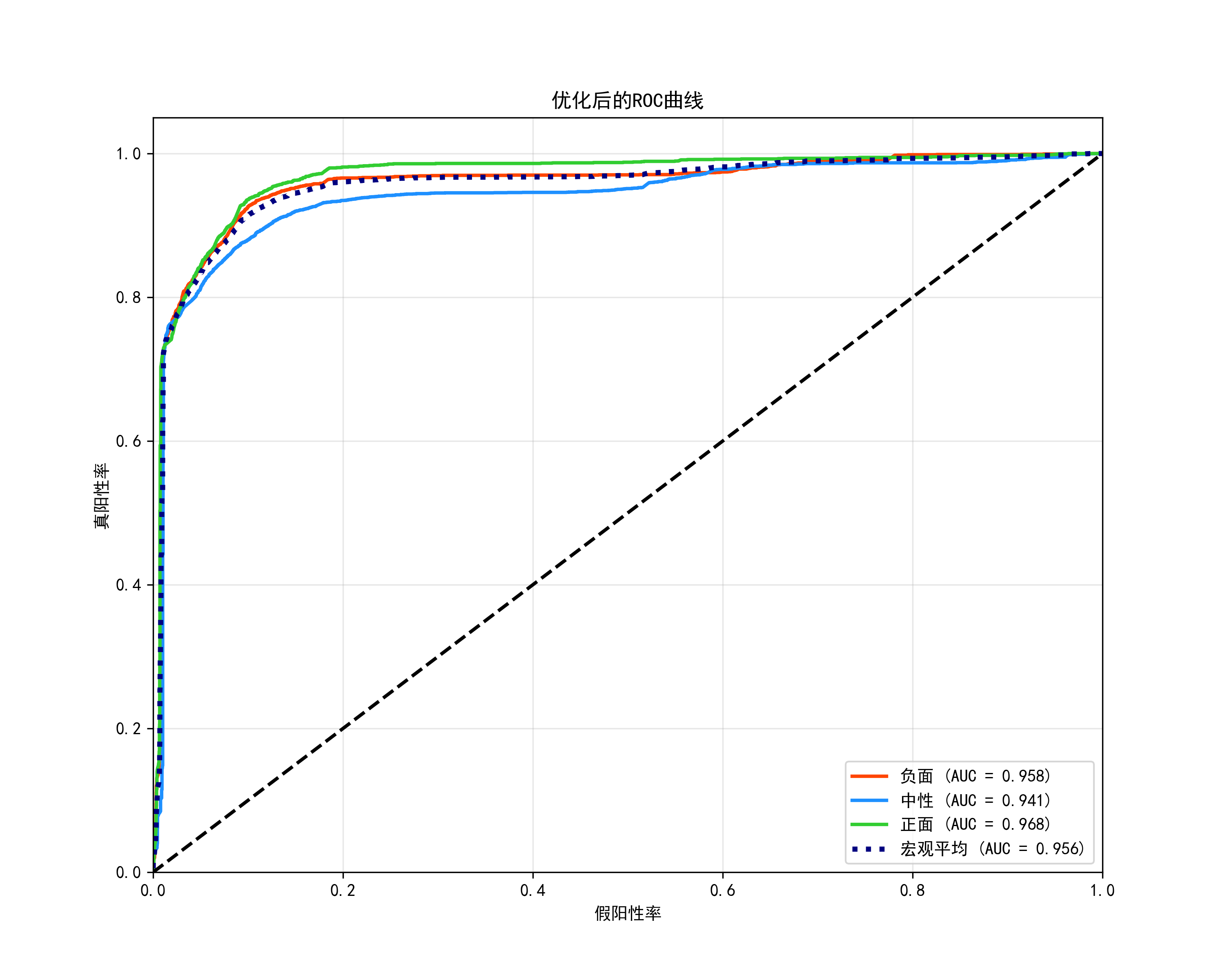
通过混淆矩阵和roc图可以发现,三个类别的准确率都在90%左右。
通过这一系列操作,实现了对评论内容进行情感分析并可视化呈现不同情感类别的占比情况,为进一步分析用户情感倾向提供了重要参考。这样的分析和可视化有助于了解用户对产品的情感态度,为满意度分析提供了有益的信息支持。
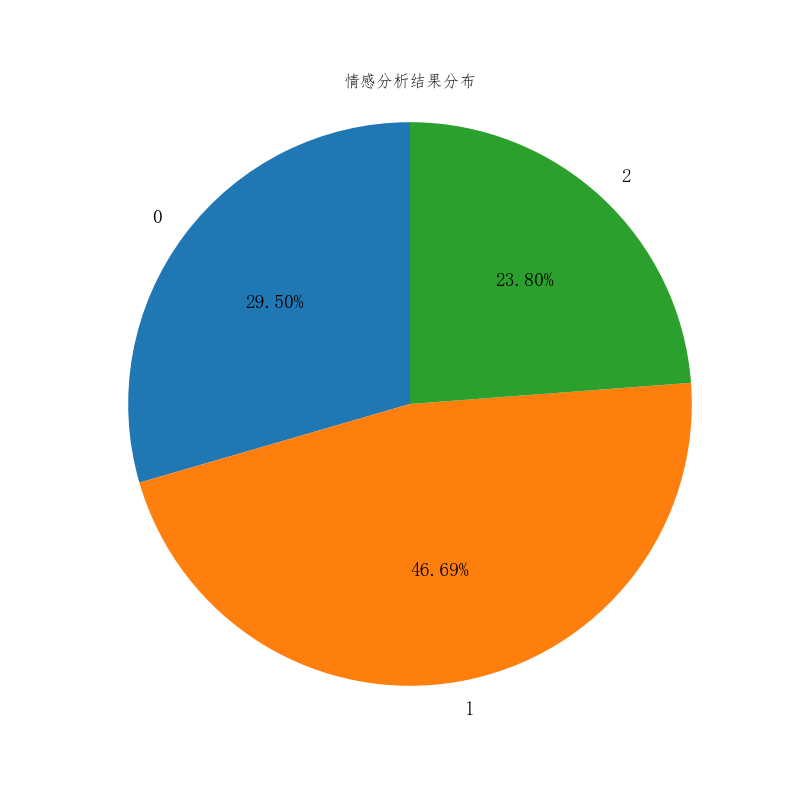
从情感分析结果来看,积极占比最大,消极和积极占比接近,反映出用户情感的总体趋势。这一分析结果表明,用户在讨论中的情感倾向较为积极,积消极情绪虽然存在,但并未占据主导地位。
Lda主题分析
LDA主题分析的实现过程如下,模型参数:

准备好经过数据清洗和预处理的文本数据。
使用gensim库构建语料库和词袋模型,将文本数据转换为可用于LDA模型的格式。
设置LDA模型的参数,包括主题数量、迭代次数、词频阈值等。
使用LDA模型训练语料库,并得到主题-词语分布和文档-主题分布。
根据需求,选择合适的方法获取每个主题的关键词,可以是按照权重排序或者设定阈值筛选。
可以使用pyLDAvis库对LDA模型进行可视化,生成交互式的主题模型可视化图表,并保存为HTML文件。
分析LDA主题分析结果,根据关键词和文档-主题分布了解每个主题的含义和特点,理解文本数据中不同主题的分布情况。
可以进一步对文本数据进行主题分析,根据文档-主题分布确定每个文档最可能的主题,并将主题信息添加到原始数据中。
通过LDA主题分析,可以发现文本数据中的主题结构和主要内容。主题分析可以帮助我们了解文本数据的内在关联性和分布情况,从而更好地理解文本数据的内容和意义。此外,LDA主题分析还可以用于文本分类、信息检索和推荐系统等领域,提供有关文本数据的深入洞察和应用价值。结果如下:
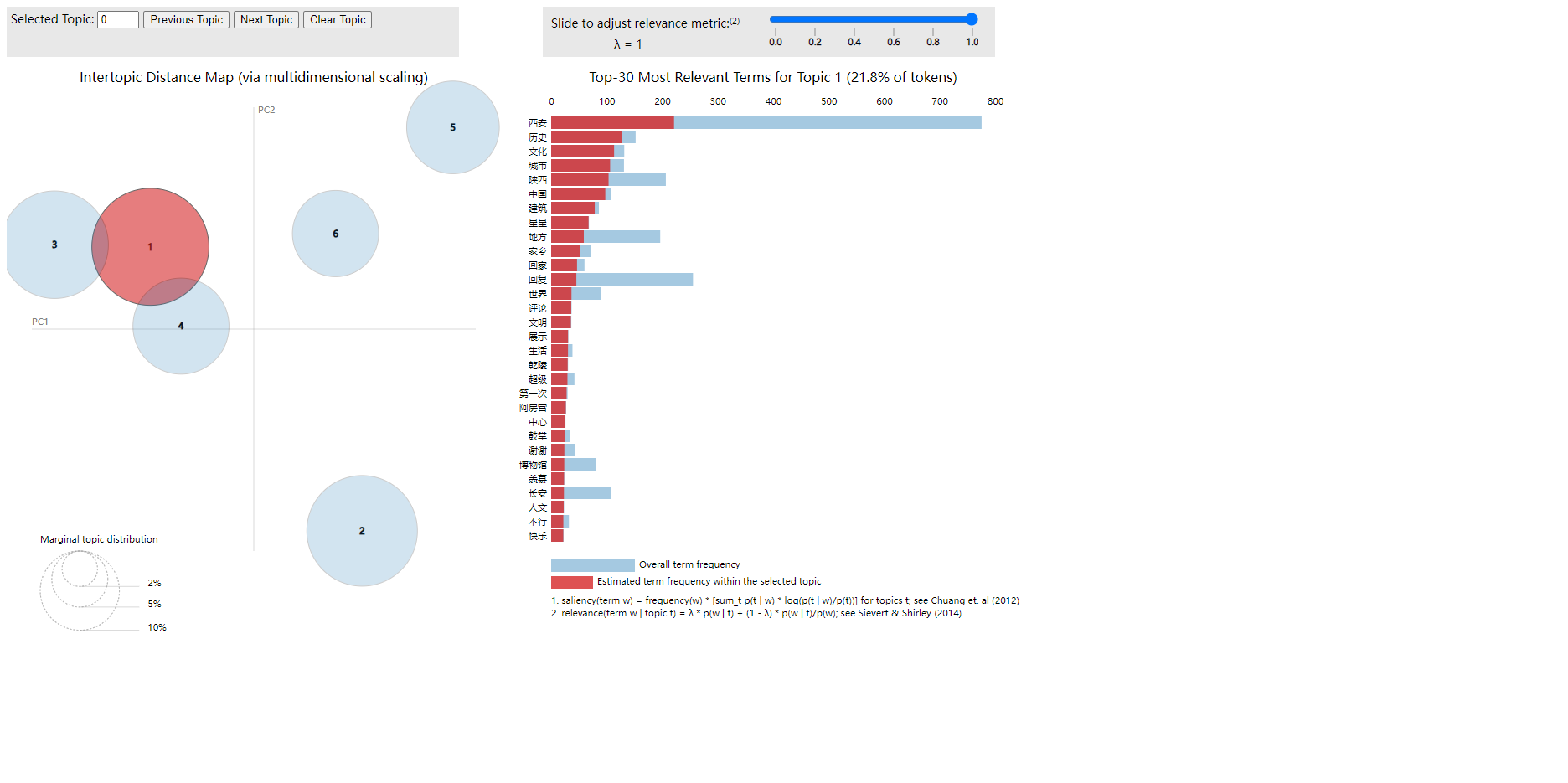
根据积极主题分析结果,西安积极评论呈现三大核心亮点:
历史文化深度认可(主题1、4、5,合计占比49.3%):高频词"历史""建筑""秦腔"彰显古都文化吸引力,17.4%的评论聚焦城墙、博物馆等文化地标,14.1%提及华清池等景点推荐。主题5中"秦腔""小时候"体现非遗文化唤醒集体记忆,形成差异化旅游吸引力。
现代文旅创新突破(主题0、2,占比40.1%):主题0以24.9%占比居首,"支持""感谢"反映服务优化成效,结合"剪辑""收藏"等新媒体热词,显示短视频传播对城市形象提升作用显著。主题2中"音乐""非凡"等词,暗示文旅产品创新获得年轻群体青睐。
体验细节好评突出(主题3,占比10.7%):"好吃""惊喜"直指餐饮体验超出预期,"金箍""金桥"等特色地标关联"值得"关键词,体现文旅消费场景精细化运营成效。但"时间""可惜"提示部分体验存在时间规划痛点。
建议:巩固"历史文化+现代创意"双轮驱动模式,开发秦腔数字化体验项目;针对占比24.9%的服务认可类评论,建立游客情感激励体系;优化"美食+景点"动线设计,减少"可惜"类时间损耗。需关注主题2中"柴西"(可能为网红标签)等新兴传播符号,加强UGC内容生态建设。。
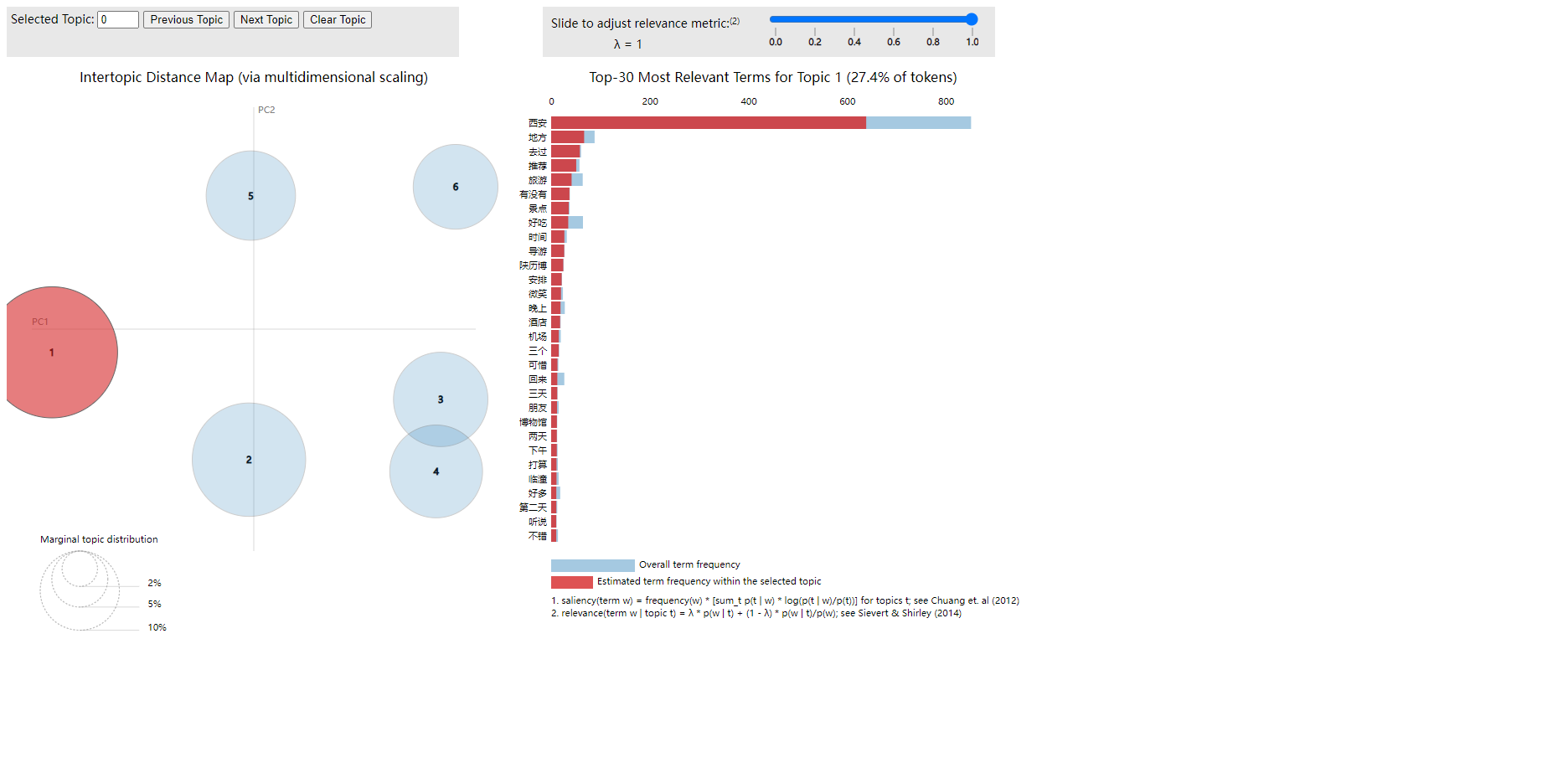
根据消极LDA主题分析结果,西安相关消极评论可归纳为三大核心问题:
旅游体验落差(主题0、1、5,合计占比64.7%):高频词"生气""建议""不好"显示游客对景点管理、服务质量存在强烈不满。主题1虽含"推荐"等中性词,但结合"有没有""时间"等疑问词,暗示旅游信息不透明、行程安排不合理等问题。主题5中"城市发展"与"河南"对比,折射出对西安建设滞后的批评。
服务与沟通缺陷(主题3、4,占比25.4%):"回复"高频出现暴露官方沟通渠道低效,"垃圾""不用"等词直指基础设施维护不足。主题4中"希望"与"大部分不用"的对比,凸显用户期待与现实落差形成的负面情绪累积。
节假日管理痛点(主题2,占比9.9%):"五一""假期"与"游客""确实"的关联,反映高峰期接待能力不足。特殊词"啊啊啊"等语气词强化了游客的焦虑情绪,提示应急管理机制缺失。
建议优先改善旅游服务质量体系,建立实时反馈处理机制,重点整治节假日拥堵问题。针对"垃圾""不好"等具象化投诉,需加强城市精细化管理和跨区域形象对标(如河南),通过提升服务细节扭转负面认知。舆情监测应特别关注占比26.3%的高热度主题1和主题5,防范负面口碑扩散。