第4章唯一ID生成器——4.5 美团点评开源方案Leaf
Leaf是美团点评公司基础研发平台推出的一个唯一ID生成器服务,其具备高可靠性、低延迟、全局唯一等特点,目前已经被广泛应用于美团金融、美团外卖、美团酒旅等多个部门。Leaf根据不同业务的需求分别实现了Leaf-segment和Leaf-snowflake两种方案,前者基于数据库的自增主键,后者基于Snowflake算法。接下来介绍这两种方案的技术原理。 需要注意的是,Leaf和前几节介绍的几种技术方案非常相似,只是多了一些思考和优化,这也是我们在本节中重点着墨的部分。
4.5.1 Leaf-segment 方案
Leaf-segment方案与4.4.2节介绍的批量缓存架构方案类似,只不过它没有依赖数据库的自增主键,而是在数据库中为每个业务场景都记录目前可用的唯一ID号段。具体的数据表设计如表4-1所示。

不同业务方的唯一ID需求用biz_tag字段区分,每个biz_tag的ID相互隔离。当某业务请求携带biz_tag访问Leaf服务时,数据库会通过执行如下语句生成唯一ID:
BEGIN
UPDATE table SET max_id = max_id + step WHERE biz_tag = xxx
SELECT tag, max_id, step FROM table WHERE biz_tag = xxx
COMMIT
比如在数据表中外卖业务方的biz tag为waimai_ordertag,此时max_id为10000, step 为2000,那么外卖业务方下次得到的唯一ID号段是10001-12000, max_id的值被更新为12000。
通过修改step字段值,可以方便地控制一个业务访问数据库的频率:
-
如果step为1,则说明每次生成唯一ID时业务方都要访问数据库;
-
如果step为1000,则说明每用 完1000个唯一ID时,业务方才再次访问数据库。
美团技术团队官网给出了Leaf-segment方案的大致架构图,如图4-14所示。
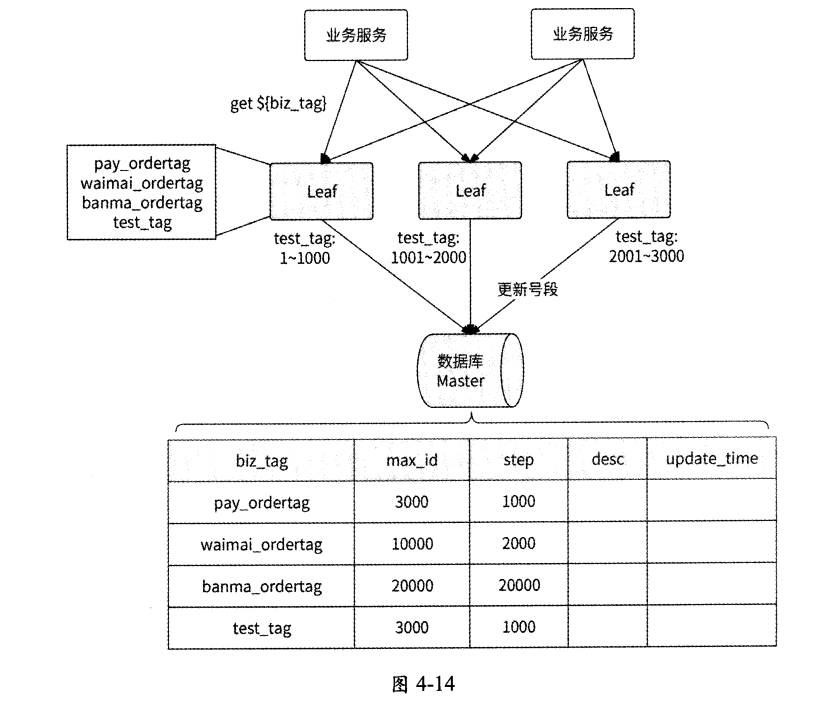
从架构图中可以看到,Leaf-segment方案与4.4.2节介绍的批量缓存架构方案确实大同小异,服务实例在本地缓存一批可用的唯一ID号段供业务请求使用,当某业务请求发现唯一ID号段用完时,再从数据库中批量获取新的唯一ID号段。如果此时数据库发生网络抖动或慢查询,则会导致访问数据库的业务请求被阻塞,整个服务的响应变慢。
Leaf-segment方案针对这个问题做了优化:当使用可用的唯一ID号段到达某个检查点时,Leaf服务实例就异步地从数据库中获取下一个可用的唯一ID号段,而不需要等到唯一ID号段用完才访问数据库,这样可以防止唯一ID号段用完时阻塞业务请求。
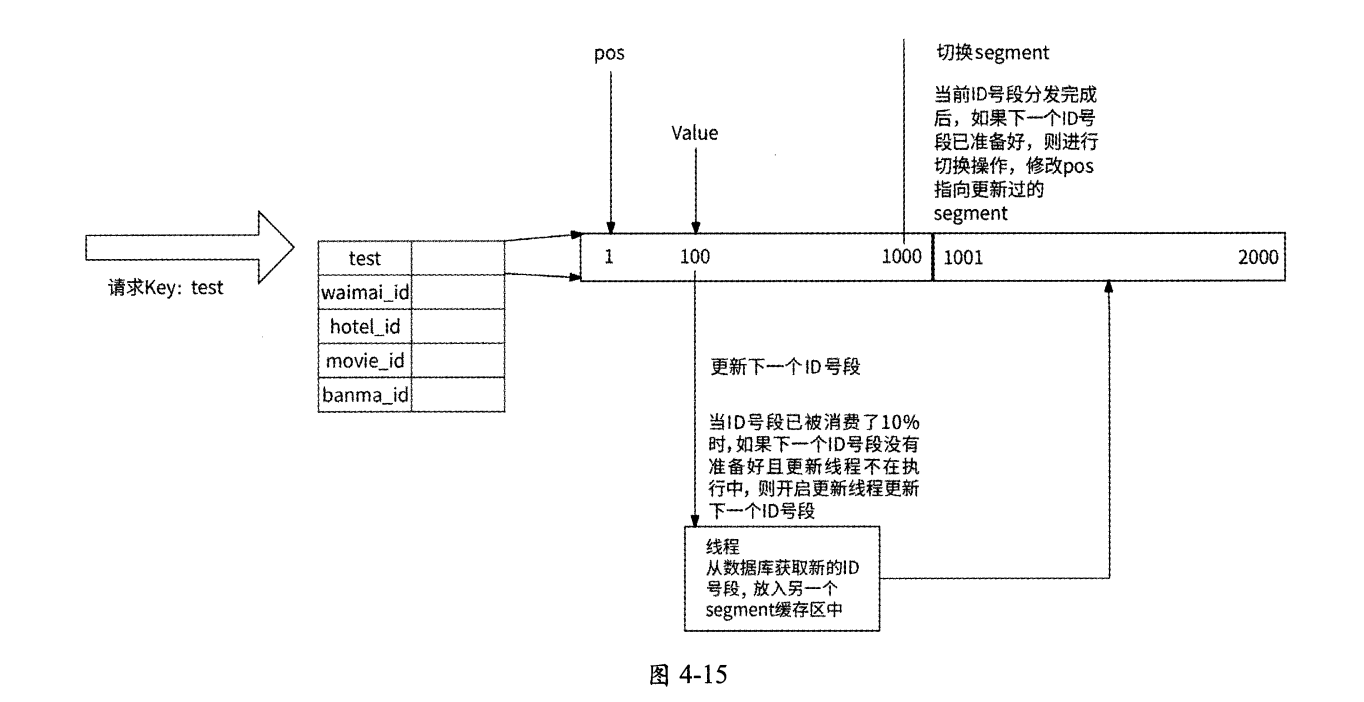
具体来说,Leaf服务实例内部有两个唯一ID号段缓存区:
-
第一个缓存区用于对外提供服务,业务请求从这里获取唯一ID;
-
第二个缓存区用于提前向数据库加载下一个 可用的唯一 id号段。
当第一个缓存区已经下发10%可用的唯一ID时,Leaf服务实例将启动一个线程异步访问数据库,并将获取到的下一个可用的唯一ID号段保存到第二个缓存区。这样一来,当某业务请求发现第一个缓存区中已无可用的唯一ID时,Leaf服务实例就直接切换到第二个缓存区继续下发可用的唯一ID,如此循环往复,业务请求不会被阻塞在访问数据库的过程中。
这个技术优化的示意图如图4-15所示(参考自美团技术团队官网)。
4.5.2 Leaf-snowflake方案
使用Leaf-segment方案可以生成趋势递增的唯一ID,但是ID值会反映实际的数据量,并不适用于订单ID生成的场景。如果将此方案应用在订单ID生成的场景中,则很容易被竞品公司计算出订单的总量,这等于把业务的数据表现直接实时暴露给其他公司。为了解决这个问题,美团点评公司提供了Leaf-snowflake方案,这个方案和4.3节介绍的基于时间戳的方案类似。
Leaf-snowflake方案在唯一ID的设计上完全沿用Snowflake算法,即使用1+41+10+12的方式组装ID;至于worker ID的分配问题,Leaf snowflake方案借助了ZooKeeper持久顺序节点的特性,每个Leaf服务实例都会在ZooKeeper的leaf_forever节点下注册一个持久顺序节点,将对应的顺序数字作为worker ID。假设现在有4个服务实例注册了持久顺序节点,leaf_forever节点的结构可能如图4-16所示。
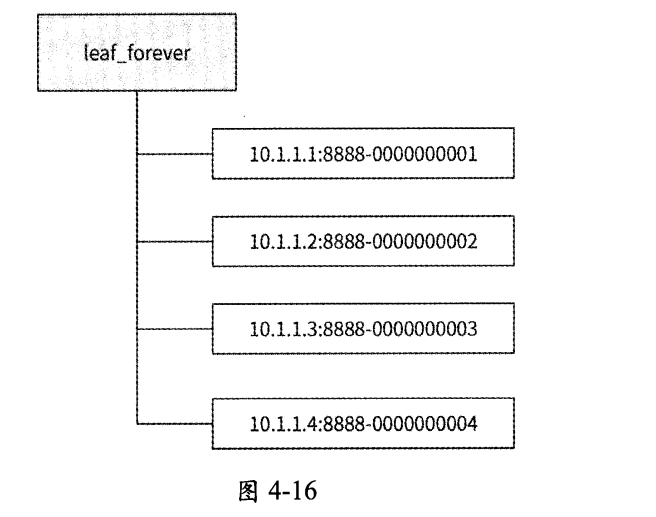
每个服务实例都携带IP地址和端口号在leaf_forever节点下注册持久顺序节点(格式为IP:port),然后ZooKeeper会自动生成一个自增序号作为每个顺序节点的后缀,这个序号就可被分配作为实例的worker ID。Leaf-snowflake方案分配worker ID的流程如下。
- Leaf服务实例启动时,连接ZooKeeper。
- 服务实例查询leaf_forever节点是否存在。如果不存在,则跳至第4步,否则继续。
- 服务实例读取leaf_forever节点下的子节点列表,然后根据自身的IP地址和端口号遍历子节点列表,查询自己是否注册过子节点。
- 如果未找到子节点,则实例在leaf_forever节点下创建子节点,将所得到的节点后缀序号作为worker ID。
- 如果找到子节点,则将此子节点的后缀序号取出作为worker ID。
- 获取到worker ID后,Leaf服务实例就启动成功了;否则,启动失败。
Leaf服务实例在获取到worker ID后会将其保存到本地文件中,这样可以做到对ZooKeeper的弱依赖。将来,如果ZooKeeper出现故障,而此时Leaf服务实例恰好重启,那么就可以从本地文件中得到worker ID,避免了无法正常启动的问题。
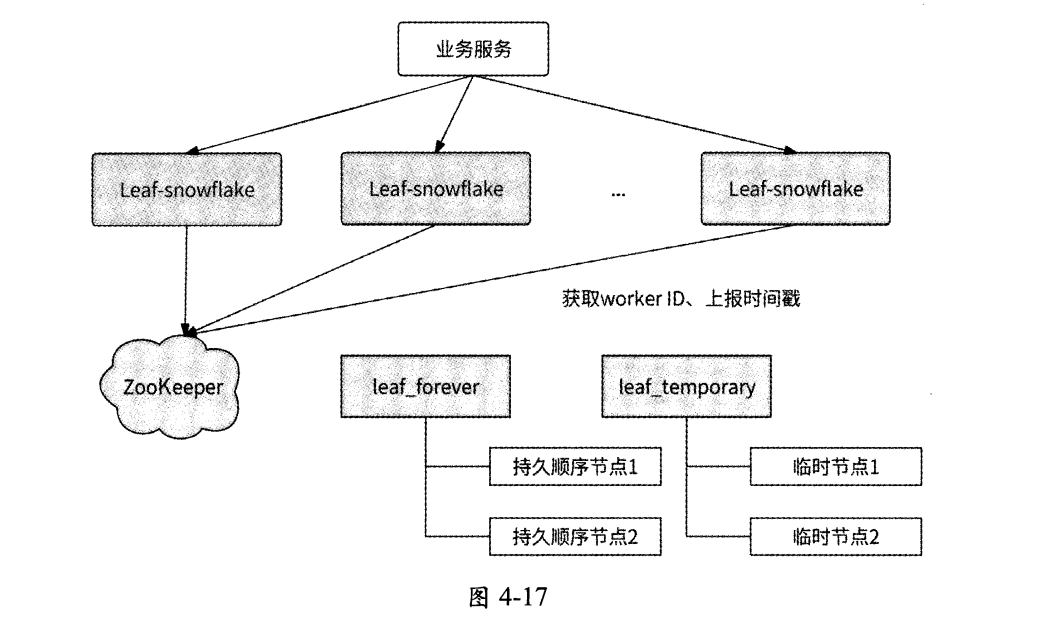
每个Leaf服务实例都会每隔3s将自身的系统时间上报到其在leaf_forever节点下注册的子节点,并且还会在另一个ZooKeeper节点leaf_temporary下创建一个临时节点,leaf_temporary下的临时节点列表代表了此时正在运行的Leaf服务实例集合。也就是说, Leaf服务实际上与两个ZooKeeper父节点交互:
- leaf_forever节点
- leaf_temporary节点
如图4-17所示:
Leaf-snowflake方案使用这两个节点来解决时钟回拨问题,具体的工作流程如下。
- 如果Leaf服务实例在leaf_forever节点下未注册持久顺序节点,那么在注册节点 时将顺便写入自身的系统时间。
- 如果Leaf服务实例已在leaf_forever节点下注册持久顺序节点,则对比持久顺序节点记录的时间与自身的系统时间。如果自身的系统时间更小,则认为发生了时钟回拨,服务实例启动失败。
- 否则,获取leaf_temporary节点下的所有临时节点信息,然后向这些临时节点代表的Leaf服务实例发送RPC请求查询它们的系统时间,并计算出平均时间,用于表示Leaf服务集群的系统时间。
- 如果平均时间与Leaf服务实例自身的系统时间的差值小于某个阈值,则认为本服务实例的系统时间是准确的,服务实例可以正常启动。
- 否则,说明本服务实例的系统时间相较于Leaf集群中的其他服务实例发生了大幅度的时钟漂移,服务实例启动失败。
- 启动成功的Leaf服务实例每隔3s将自身的系统时间上报到在leaf_forever节点下注册的持久顺序节点。
Leaf-snowflake方案通过检查服务实例上报的自身系统时间和其他Leaf服务实例的平均时间来解决时钟回拨问题,按照美团点评公司技术博客中的说法,这个策略有效地避免了时钟回拨对业务造成的影响。另外,此方案也建议关闭NTP时钟同步功能。
本章小结
分布式唯一ID应该具备占用空间小、可用作数据库主键的能力,所以一般用递增的long类型整数来表示。
递增可以分为单调递增和趋势递增。
单调递增的唯一ID生成器可以基于Redis INCRBY命令实现,或者基于数据库的自增主键实现。采用批量生成ID的方式可以提高唯一ID生成器的性能,ID生成器服务实例将一批唯一ID缓存到本地对外提供服务,当可用的唯一ID消耗完时再生成下一批唯一ID。不过,为了保证唯一ID单调递增,此时只能有一个服务实例对外工作。由于单调递增的唯一ID生成器服务无法兼顾高可用性和高性能,所以应用相对具有局限性。
如果把单调递增改为趋势递增,那么唯一ID生成器服务将打破局限性。一种方案是使用数据库分库分表架构生成自增主键,同时利用数据库自带的自增主键调整自增步长和设置初始值来防止各分表生成的自增主键冲突。这种方案可以提高数据库的高可用性与性能,但是可扩展性较差。另一种方案是使用批量缓存架构,即在批量获取单调递增的唯一ID的基础上采用多服务实例生成趋势递增的唯一ID。这两种方案都是基于数据库的自增主键生成唯一ID的,数值的可读性过强,在某些场景中有泄露业务数据的风险。基于时间戳生成唯一ID可以解决这个问题。
如何基于时间戳设计唯一ID生成器呢? Snowflake算法为我们提供了很好的思路:将分布式环境下的各变量体现到唯一ID的二进制位上,比如不同的机房、不同的服务实例、不同的时间、相同时间不同的请求。每个ID生成器服务实例都需要有唯一表示自己的worker ID,可以使用数据库的自增主键、分布式协调服务ZooKeeper或etcd来实现;同时,服务实例维护从系统上线时间开始经过的总毫秒数、当前毫秒内已生成的ID数量,以便区分时间和并发请求。最后,一定要防止时钟漂移问题影响ID的唯一性。
美团点评公司的唯一ID生成器服务Leaf实现了两种生成唯一ID的方案:Leaf-segment和Leaf-snowflake。前者采用了批量缓存ID的思想,后者是对Snowflake算法的应用。