PostgreSQL锁机制详解:从并发控制到死锁检测
PostgreSQL锁详解
————向逍xiangxiao@highgo.com
首先要讲锁的话,必须得先了解并发控制。数据库中的对象都是共享的,如果同时间不同的用户对同一个对象进行修改,就会出现数据不一致的情况。所以如果要实现并发访问,就需要对这个过程加以控制。
PostgreSQL针对并发访问控制有两种方法,一是基于锁的机制,也就是两阶段锁机制(Two phase lock,2PL),二是基于时间戳的机制,即MVCC机制。而本文要提到的就是基于锁的机制,两阶段锁机制简单来说就是把对锁的操作分为两阶段:加锁阶段(增长阶段)和解锁阶段(收缩阶段),并且强制要求加锁阶段不能释放锁,在解锁阶段不能加锁。
同时,在PostgreSQL中锁分为一下3中层次。
-
自旋锁(Spin Lock):是一种和硬件结合的互斥锁。它借用了硬件提供的原子操作来对一些共享变量进行加锁,通常适用于临界资源比较小的情况。
-
轻量锁(Lightweight Lock):负责保存PostgreSQL中的大量共享内存和数据结构。是一种读写锁,具有共享和排他两种模式。
-
常规锁(Regular Lock):给数据库对象进行加锁,针对不同的数据库对象,锁的粒度也不一样,例如分为表、页面、元组和事务ID等等。常规锁分为八个等级,不同的操作需要不同级别的锁。
1、PostgreSQL自旋锁
1.1、什么是自旋锁
自旋锁,顾名思义,就是不断旋转的锁。如果一个进程需要访问临界区,则必须先获取锁资源,如果不能获得锁资源,就会一直在原地忙等,即旋转,直到获取锁资源。
自旋锁的这种忙等,也就是自旋非常浪费CPU资源,所以一般用于临界资源非常小的情况,持有这个锁的进程能够很快的释放锁,在这个时候自旋对CPU资源的浪费小于释放CPU资源带来的上下文切换的资源消耗,那就是适合自旋锁的情况。
但是需要注意的是这里的自旋锁的实现必须依赖原子操作,也就是说这个操作可能在c语言是一条语句,但是转换为汇编指令则可能是多条指令才能达到的效果,当进程在访问的时候可能出现同时获取资源的情况。比如*lock != 0这条语句转换为汇编指令为movq -0x8(%rbq), %rax和cmpl $0x0, (%rax)这就不是原子操作。
PG采用了两种方式去实现自旋锁,一种是硬件提供的原子操作去实现,另一种是如果机器没有TAS指令集,则通过自己定义的信号量PGSemaphore来仿真SpinLock,但是后者的效率不如前者,本文这里暂时只介绍通过硬件提供的原子操作实现。
1.2、自旋锁的申请
打开spin.h文件可以发现,PG是通过宏定义HAVE_SPINLOCKS判断机器是否由TAS指令集。
自旋锁的申请使用的是SpinLockAcquire,但是这是一个宏定义,它最终调用的是tas函数,函数的定义如下:
static inline int
tas(volatile slock_t *lock)
{register slock_t _res = 1;asm _volatile_(" lock \n"" xchgb %0,%1 \n"
: "+q"(_res), "+m"(*lock)
: /* no inputs */
: "memory", "cc");return (int) _res;
}这里举的例子是x86架构下的TAS实现方法,对于不同的架构,PostgreSQL提供不同的方法实现,具体可以查看src/include/storage/s_lock.h这个文件下的内容。
1.3、自旋锁的释放
自旋锁的释放就是将这里的*lock的值置为1,具体代码实现如下:
#define S_UNLOCK(lock) \do { asm _volatile_("" : : : "memory"); *(lock) = 0; } while (0)2、PostgreSQL轻量锁
2.1、什么是轻量锁
自旋锁是一个互斥锁,对于临界资源比较小的情况,能保证多个进程对临界区的访问是互斥的,但是在数据库的实际使用过程中,会出现多个进程同时读取共享内存,在这种情况下大量的读操作是不冲突的,因为他们并不会修改数据,所以就需要轻量锁来解决这个问题。
轻量级锁有两种模式,共享和排他,在读操作的时候就加上共享锁,这样保证在其他进程读的时候不冲突,而又杜绝了其他写操作。在写操作的时候就加上排他锁,这样保证在写操作执行的过程中,其他进程既不可以读也不可以写。
轻量级锁的相容性矩阵如下:
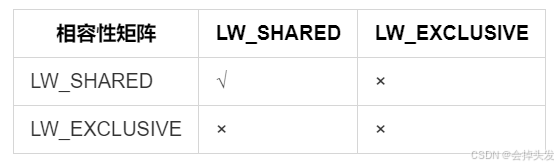
轻量级锁类型定义在lwlocknames.h中,这个文件是在编译的时候由lwlocknames.txt生成的,在这里面定义了PG的轻量级锁的类型。
#define ShmemIndexLock (&MainLWLockArray[1].lock)
#define OidGenLock (&MainLWLockArray[2].lock)
#define XidGenLock (&MainLWLockArray[3].lock)
...
#define NotifyQueueTailLock (&MainLWLockArray[47].lock)#define NUM_INDIVIDUAL_LWLOCKS 48从这个宏定义可以看出,在这个文件中所有的轻量级锁的类型都存储在MainLWLockArray里面。在上面这种为individual lwlock,每个individual lwlock都有自己固定要保护的对象。individual lwlock的使用方法如下:
LWLockAcquire(ShmemIndexLock, LW_EXCLUSIVE);
//这里对需要保护的变量进行写操作
LWLockRelease(ShmemIndexLock);在individual lwlock中,每个lwlock都对应一个tranche id,它具有全局唯一性,在MainLWLockArray中前NUM_INDIVIDUAL_LWLOCKS - 1都是individual lwlock。
除了individual lwlock之外,还有Builtin tranche,每一个builtin tranche可能对应多个lwlock,他代表的是一组lwlocks,这组lwlocks虽然各自封锁各自的内容,但是他们的功能相同。builtin tranche包含如下类型,类型定义在lwlock.h文件的BuiltinTrancheIds枚举类型中。
typedef enum BuiltinTrancheIds
{LWTRANCHE_XACT_BUFFER = NUM_INDIVIDUAL_LWLOCKS,LWTRANCHE_COMMITTS_BUFFER,LWTRANCHE_SUBTRANS_BUFFER,LWTRANCHE_MULTIXACTOFFSET_BUFFER,
...
}从这里可以看出来,对于Builtin tranche,他的计数是从NUM_INDIVIDUAL_LWLOCKS开始的,也就是individual lwlock的最后。
这些Builtin Tranche对应的锁一部分保存在MainLWLockArray中,另一半部分被保存在使用他们的结构体中,如下所示:
//存储在MainLWLockArray中
/* Register named extension LWLock tranches in the current process. */
for (int i = 0; i < NamedLWLockTrancheRequests; i++)LWLockRegisterTranche(NamedLWLockTrancheArray[i].trancheId,NamedLWLockTrancheArray[i].trancheName);
//存储在自己的结构体中 xlog.c:4465 (pg15.8)
//这里初始化了NUM_XLOGINSERT_LOCKS个轻量锁
//这些轻量锁的tranche id都是lwtranche_wal_insert
//这些轻量锁没有保存在MainLWLockArray里面
for (i = 0; i < NUM_XLOGINSERT_LOCKS; i++)
{LWLockInitialize(&WALInsertLocks[i].l.lock, LWTRANCHE_WAL_INSERT);WALInsertLocks[i].l.insertingAt = InvalidXLogRecPtr;WALInsertLocks[i].l.lastImportantAt = InvalidXLogRecPtr;
}但是无论是individual lwlocks还是builtin tranches,他们都被保存在共享内存中,只是保存的方式不相同而已。
这里先给出轻量级锁的结构体定义:
typedef struct LWLock{uint16 tranche; /* tranche ID *///这是一个原子变量,用于保存轻量级锁的状态pg_atomic_uint32 state; /* state of exclusive/nonexclusive lockers *///轻量级锁的等待队列proclist_head waiters; /* list of waiting PGPROCs */#ifdef LOCK_DEBUG pg_atomic_uint32 nwaiters; /* number of waiters 等待者的数量 *///最后一次获取排他锁的进程struct PGPROC *owner; /* last exclusive owner of the lock */#endif} LWLock;在早期轻量级锁是通过自旋锁实现的,但是随着性能的提升,轻量级锁的实现开始借助原子操作来实现,pg_atomic_uint32 state;关注这个状态的变量,这是一个32位的无符号整型,其中他的低24位作为存储共享锁的计数器,因此一个轻量级锁最多拥有2^24个共享锁持有者。有1位作为排他锁的标记,因为同一时刻最多只能拥有一个持锁者。

2.2、轻量锁的申请
接下来介绍轻量锁的申请,主要分为两种,一是申请共享锁,二是申请排他锁。
(1)当申请一个共享锁的时候:
a如果里面是共享锁或者无锁 —-> 直接获取
b如果里面排他锁 —-> 进入等待队列
(2)当申请一个排他锁的时候:
a如果里面是共享锁或者排他锁 —-> 进入等待队列
b如果里面没有锁 —-> 直接获取
在比较极端的情况下,如果申请一个排他锁,然后目前持有的是共享锁,则进入等待队列,在这个过程中不断的申请共享锁,那么这个排他锁将持续等待,出现排他锁饥饿的情况。
具体申请轻量锁的详细细节如下:
获取锁的调用LWLockAcquire方法,释放调用LWLockRelease方法。 获取的步骤大致为:
-
判断锁的持有数量是否超出能记录的持有列表大小。
if (num_held_lwlocks >= MAX_SIMUL_LWLOCKS)elog(ERROR, "too many LWLocks taken");-
尝试获取,成功则返回。
mustwait = LWLockAttemptLock(lock, mode);if (!mustwait){LOG_LWDEBUG("LWLockAcquire", lock, "immediately acquired lock");break; /* got the lock 获取成功则返回 */}-
失败则进入等待队列。
/* add to the queue */
LWLockQueueSelf(lock, mode);-
再次尝试获取,成功则出队列,并返回。
mustwait = LWLockAttemptLock(lock, mode);/* ok, grabbed the lock the second time round, need to undoqueueing */
if (!mustwait){LOG_LWDEBUG("LWLockAcquire", lock, "acquired, undoing queue");LWLockDequeueSelf(lock);//从队列中出来,获取成功,直接返回break;}-
失败则报告等待事件开始,并持续等待被唤醒,然后报告等待事件结束。
LWLockReportWaitStart(lock);if (TRACE_POSTGRESQL_LWLOCK_WAIT_START_ENABLED())TRACE_POSTGRESQL_LWLOCK_WAIT_START(T_NAME(lock), mode);for (;;){PGSemaphoreLock(proc->sem);if (proc->lwWaiting == LW_WS_NOT_WAITING)break;extraWaits++;}/* Retrying, allow LWLockRelease to release waiters again. 使用原子操作获取更新锁的状态 */pg_atomic_fetch_or_u32(&lock->state, LW_FLAG_RELEASE_OK);if (TRACE_POSTGRESQL_LWLOCK_WAIT_DONE_ENABLED())TRACE_POSTGRESQL_LWLOCK_WAIT_DONE(T_NAME(lock), mode);LWLockReportWaitEnd();-
然后持续再次尝试获取锁,回到1,直到获取成功。
-
获取成功之后将这个锁增加到held_lwlocks中去。
held_lwlocks[num_held_lwlocks].lock = lock;
held_lwlocks[num_held_lwlocks++].mode = mode;2.3、轻量锁的释放
释放轻量级锁的步骤大致如下:
-
将这个锁在held_lwlocks中定位,并将数组该位置之后的锁前移。
for (i = num_held_lwlocks; --i >= 0;)if (lock == held_lwlocks[i].lock)break;if (i < 0)elog(ERROR, "lock %s is not held", T_NAME(lock));mode = held_lwlocks[i].mode;num_held_lwlocks--;//释放之后数组前移for (; i < num_held_lwlocks; i++)held_lwlocks[i] = held_lwlocks[i + 1];PRINT_LWDEBUG("LWLockRelease", lock, mode);-
释放锁。
if (mode == LW_EXCLUSIVE)oldstate = pg_atomic_sub_fetch_u32(&lock->state, LW_VAL_EXCLUSIVE);
elseoldstate = pg_atomic_sub_fetch_u32(&lock->state, LW_VAL_SHARED);-
获取修改前的状态,判断是否需要唤醒等待队列的进程。
//如果锁未被持有并且等待队列为空则不需要唤醒
if ((oldstate & (LW_FLAG_HAS_WAITERS | LW_FLAG_RELEASE_OK)) ==(LW_FLAG_HAS_WAITERS | LW_FLAG_RELEASE_OK) &&(oldstate & LW_LOCK_MASK) == 0)check_waiters = true;
elsecheck_waiters = false;-
如果需要唤醒,则唤醒。
if (check_waiters){/* XXX: remove before commit? */LOG_LWDEBUG("LWLockRelease", lock, "releasing waiters");LWLockWakeup(lock);}2.4、Extension拓展轻量级锁
在插件中拓展轻量级锁有两种方法。
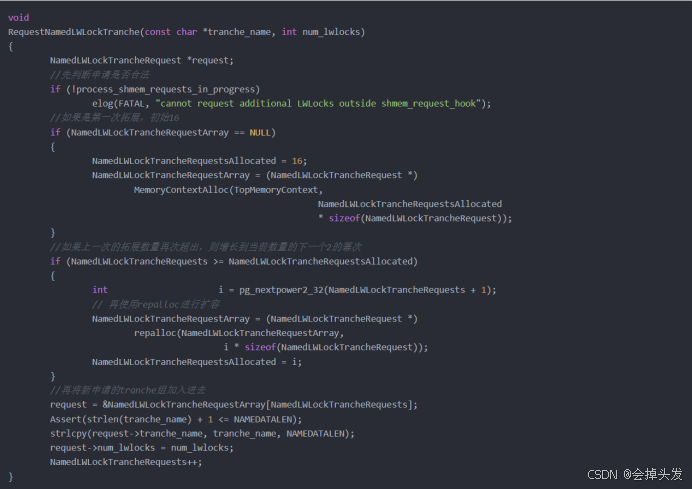
方法一、通过RequestNamedLWLockTranche函数和GetNamedLWLockTranche函数来实现。其中RequestNamedLWLockTranche函数负责注册Tranche的名字以及自己所需要的轻量级锁的数量,GetNamedLWLockTranche负责根据Tranche Name来获得对应的锁。每个tranche都有自己唯一的id,全局唯一,tranche id和tranche name一一对应。
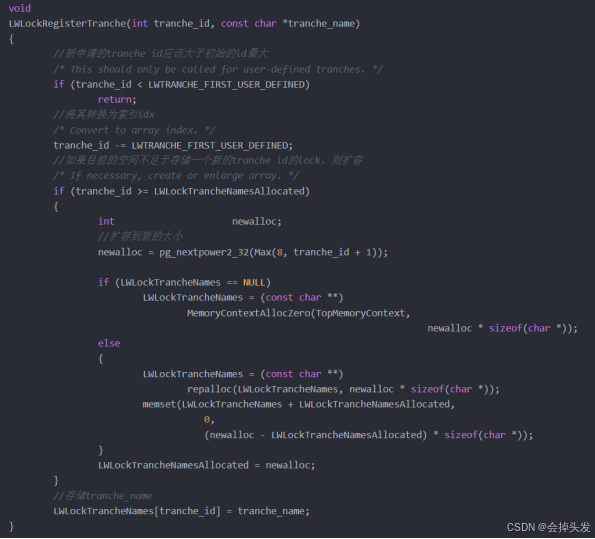
方法二、通过LWLockNewTrancheId函数获取新的Tranche ID,然后将Tranche ID和Tranche Name通过LWLockRegisterTranche函数建立联系,然后再由LWLockInitialize函数进行初始化。
3、PostgreSQL常规锁
常规锁是用于给数据库对象,例如表,页面,元组等加锁的事务锁,它也是一种读写锁,但是和LWLock不同的在于它将锁等级分为了八个等级,所以他的相容性矩阵就比较麻烦。后续也会接着介绍是怎么演变到八个等级锁来的。
3.1、常规锁的锁模式
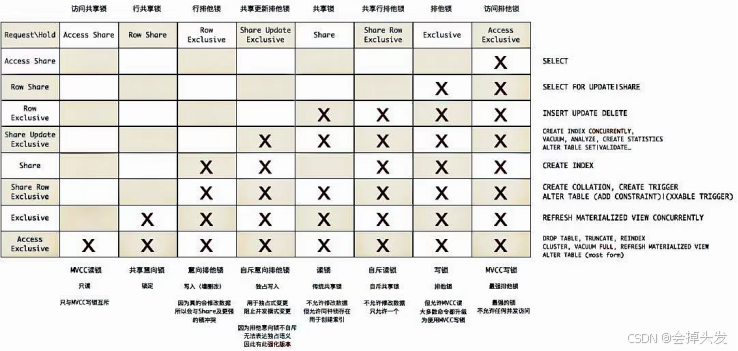
常规锁的锁模式分为八种,也就是八级锁,前三种锁称为弱锁,第四级既不是弱锁也不是强锁,后面四级为强锁。具体划分如下图所示:

由最开始的轻量锁的两种锁模式,共享和排他,到现在八级锁,各种锁之间的相容度也是随之变化的,常规锁的弱锁之间是相容的,强锁之前是不相容的,第四级锁于弱锁相容于强锁不相容,且于自己不相容。具体各级锁之前的冲突关系由下图的冲突矩阵表示:
3.2、常规锁的演变
最开始只有两种锁,就是读锁和写锁,即Share和Exclusive。
然后PG引入了多版本控制,多版本控制要求读写相互不阻塞,所以又引入了AccessShare和AccessExclusive锁,引入MVCC之后insert\update\delete操作仍然使用原来的Exclusive锁,但是普通的select操作则使用AccessShare锁,这样子就和原来的Exclusive不冲突了,这个时候读写之间互不阻塞,而之前的Share锁的主要应用场景为创建索引,而AccessExclusive锁就用于除了原来的增删改之外的其他的排他性变更(drop/truncate/reindex/vacuum full),但是写和写之间还是会有冲突,根据相容性矩阵可以看出在并发写入使用Exclusive锁的时候,这是个表级锁,粒度太大了,会影响并发操作。
所以就引入了意向锁,即RowShare和RowExclusive,意向锁之间都不冲突。 意向读与读锁兼容,但是与写锁冲突,因为在写的时候去读是徒劳的,用于select for update/share操作 意向写他与读锁和写锁都冲突,两者都阻止并发修改,用于insert,update,delete。
意向锁用于协调表锁和行锁之间的关系,比如说当某个进程想要修改某一行的时候,首先会在这个表上面加一把意向写锁,表示自己会在某一行上进行写操作,然后再在某一行上面增加写锁。举个例子,假设不存在意向锁。假设进程A获取了表上某行的行锁,持有行上的排他锁意味着进程A可以对这一行执行写入;同时因为不存在意向锁,进程B很顺利地获取了该表上的表级排他锁,这意味着进程B可以对整个表,包括A锁定对那一行进行修改,这就违背了常识逻辑。因此A需要在获取行锁前先获取表上的意向锁,这样后来的B就意识到自己无法获取整个表上的排他锁了(但B依然可以加一个意向锁,获取其他行上的行锁)。
RowShare就是行级共享锁对应的表级意向锁(SELECT FOR SHARE|UPDATE命令获取),而RowExclusive(INSERT|UPDATE|DELETE获取)则是行级排他锁对应的表级意向锁。
这个时候由有六把锁了,但是后面为什么又引入了另外两把锁,即ShareUpdateExclusiveLock 和ShareRowExclusiveLock这两把锁。首先ShareUpdateExclusiveLock 锁可以让 VACUUM 操作不应该阻止数据写入,但是又不能出现在一张表并发执行VACUUM操作,所以他又必须自斥。ShareRowExclusiveLock这种锁级别是介于 SHARE 锁和 EXCLUSIVE 锁之间的一种平衡选择,它比 SHARE 锁更严格,因为它阻止了更新操作,但比 EXCLUSIVE 锁更宽松,因为它允许并发读取,比如说在创建触发器的时候,应该阻止数据写入,因为这个时候无法判断是否需要触发触发器,但是又必须防止其他进程修改触发器,所以他又需要互斥。所以又引入了两把自斥锁。
3.3、常规锁的实现
3.3.1、常规锁的数据结构
在数据库启动的阶段,PostgreSQL通过InitLocks函数来初始化保存锁对象的共享内存空间,在共享内存中,有两个锁表用于保存锁对象,LockMethodLockHash主锁表和LockMethodProcLockHash进程锁表。
【共享内存】主锁表:LockMethodLockHash(存储所有锁对象)
【共享内存】锁进程关系表:LockMethodProcLockHash(查询当前进程阻塞了哪些进程,死锁检测)
【本地内存】本地锁表:对重复申请的锁计数,避免频繁访问(本地快速加锁,锁缓存)
【共享内存】本地弱锁fastpath(需要共享内存中查询是否有强锁FastPathStrongRelationLockData)
首先看一下主锁表在内存中的存储结构,具体如下:
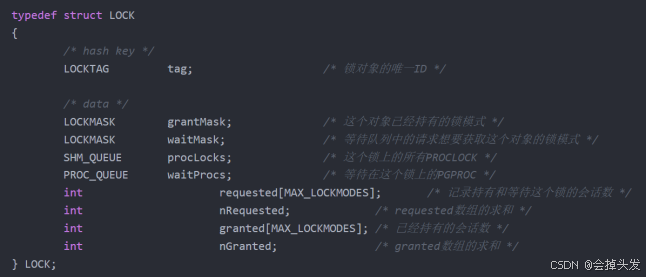
然后是进程锁表,它用于保存当前进程的事务锁状态,保存的是PROCLOCK结构体,主要是为了建立锁与申请锁的会话之间的关系:
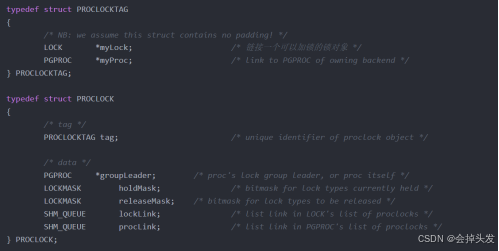
除此之外还有个结构,那就是本地锁表LocalLock。
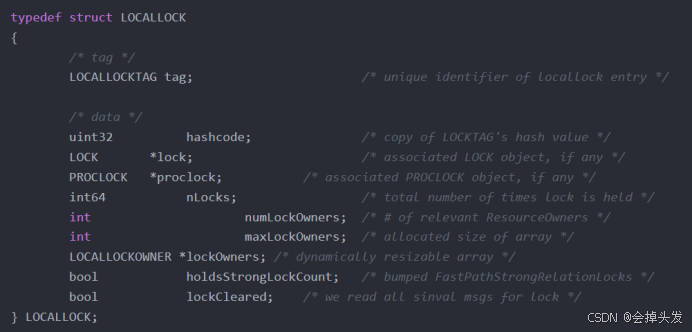
最后就是快速路径(Fast Path),这个快速路径分为强锁和弱锁,弱锁的访问保存到本进程,避免频繁的访问主锁表和进程锁表。 而对于强锁是存储在共享内存中的,这里的count数量是2(10)是1024,具体如下:
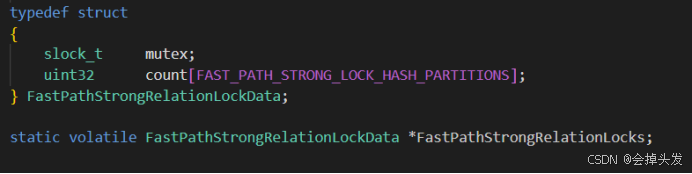
然后对于弱锁,是存储在进程的变量中的,即PGPROC结构体的fpLockBits和fpRelId。存储的结构也就是存储在fpLockBits这个64位的位图中的,每三位一组,标识八级锁对应的锁级别,而根据fpRelId的大小可以看出来,其实最多只能存储了16个锁,fpRelId顾名思义就是表的oid,也就是锁对象即锁表的oid。
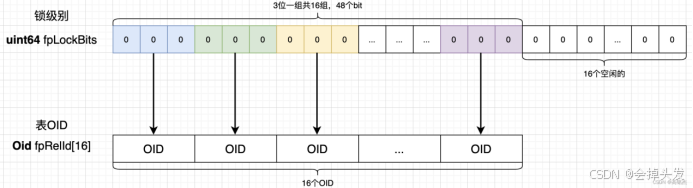
3.3.2、常规锁的申请
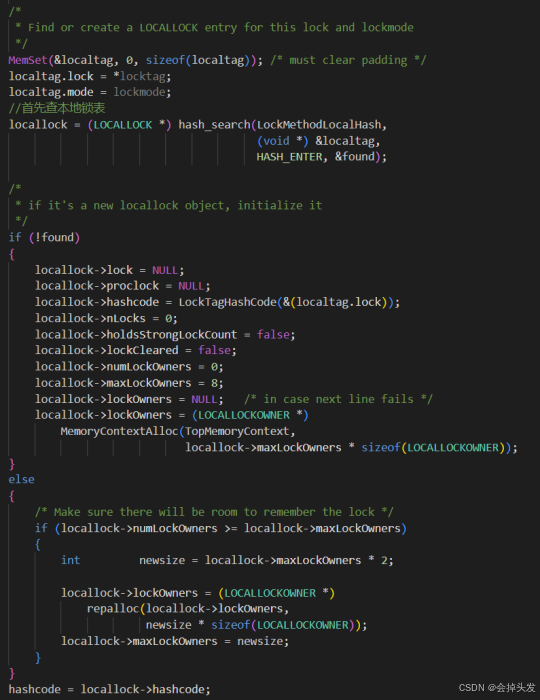
加锁的API是LockAcquire,但是在里面还是调用的是LockAcquireExtended,这个函数接受四个参数:分别是锁tag,申请锁模式,会话锁或事务锁,是否等待。详细的加锁流程如下:
(1)查找本地锁表
在Acquire Lock的时候首先查找的是本地锁表LocalLock,通过hash_search函数搜索,locktag作为查找的key值,返回一个LOCALLOCK*。如果在本地锁表没有找到的话就构造一条放入本地锁表。
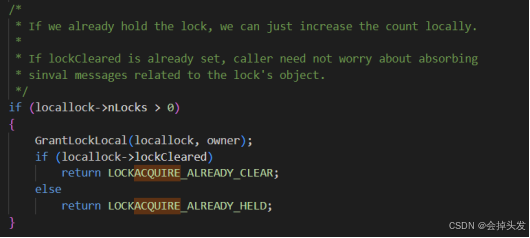
如果已经持有锁的话直接将持有的数量加1。
(2)查找fast path,判断弱锁。
在查找本地锁表之后,如果本地锁表内没有,则开始查找fast path,首先是通过EligibleForRelationFastPath宏定义进行判断:要求必须是非咨询锁 locktag_lockmethodid == DEFAULT_LOCKMETHOD,要求锁的对象为表 locktag_type == LOCKTAG_RELATION,要求必须是当前数据库的锁 locktag_field1 == MyDatabaseId,要求锁的级别必须是弱锁 (mode) < ShareUpdateExclusiveLock。
并且还有个条件需要判断的是,当前fastpath里面已经使用的数量是否超过了最大数。FastPathLocalUseCount < FP_LOCK_SLOTS_PER_BACKEND
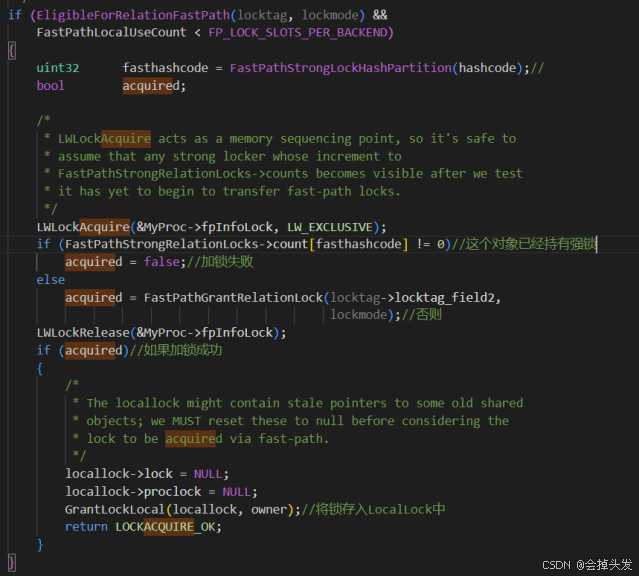
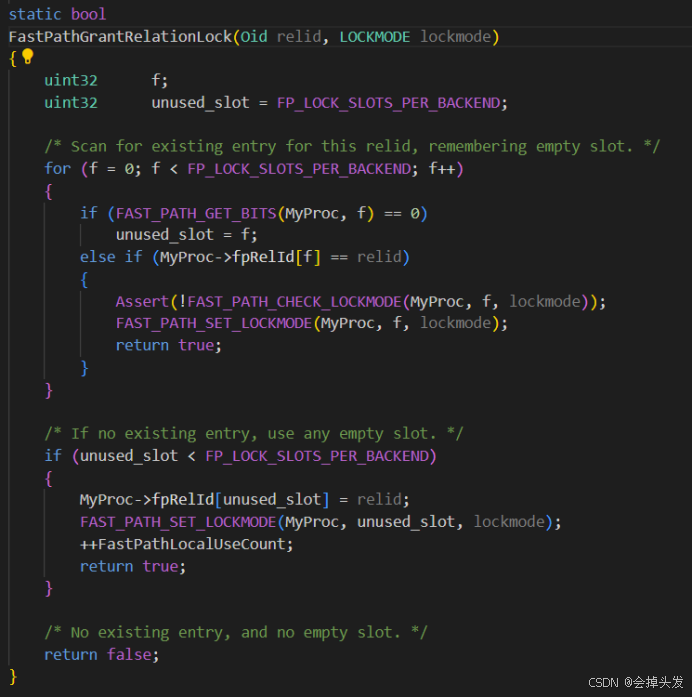
总的流程大致为用tag算的hashcode在%1024,落到1024数组FastPathStrongRelationLocks->count的某个位置上。这个位置上存储的是这个对象所持有的强锁,有强锁的话则加锁失败,否则使用FastPathGrantRelationLock函数加锁,这里传进去的参数locktag->locktag_field2是表的id,还有锁的模式。
FastPathGrantRelationLock逻辑:
-
3个bit一组按顺序查位图是不是空的,是空的就记录下来位置,不是空的就看下oid里面记的是不是需要的,如果正好Oid也是需要的,把当前请求锁模式或进去就可以返回了。
-
如果查了一遍位图,所有Oid都不是需要的,那就找一个空的位置,把锁级别记录到位图,OID记录到数组,然后返回。
-
如果查了一遍位图,没有一个空余位置,就返回false了。
-
如果申请的是强锁的情况。
强锁的判断和前面弱锁的判断比较相似,也是通过一个宏定义去判断的,这里给出宏定义如下:
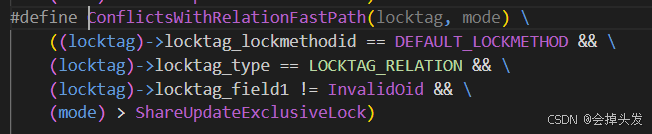
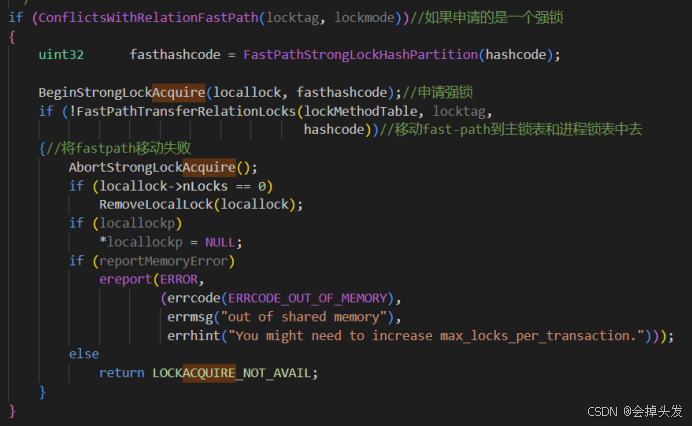
如果判断出来是强锁的话,那就开始处理强锁,走强锁的逻辑。首先就是通过BeginStrongLockAcquire函数去申请强锁,之后就将强锁对应的加锁对象的OID锁持有的弱锁,存储在fastpath中的,如果有的话就移动到主锁表和进程锁表中去,用于后期的锁冲突判断和死锁检测。
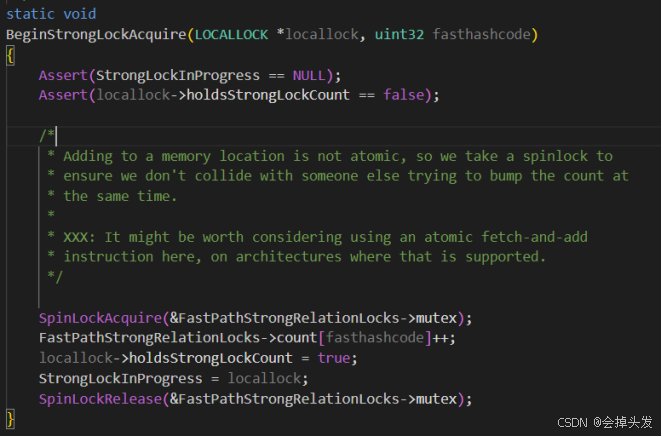
这里给出BeginStrongLockAcquire的实现逻辑:
-
共享内存强锁表对应位置++,FastPathStrongRelationLocks->count[fasthashcode]++;(重要!相当于禁用了后面这个对象后来的所有fastpath)
-
本地锁记录强锁存在locallock->holdsStrongLockCount = true
-
全局记录本地强锁StrongLockInProgress = locallock
然后给出将fastpath中对于弱锁转移到主锁表和进程锁表中去的代码逻辑:
-
轮询PGPROC,用表oid在fpRelId16数组中查询,如果找到了,用找到的锁级别去主锁表中加锁。
-
清理fastpath对应的位置。
-
完成转换:PGPROC记录的fastpath锁换成主锁表的锁,便于死锁检查。
-
注意这里只是把fastpath中已经存在弱锁换到主锁表了,并没有给当前请求LockAcquire的对象加锁。
这一块比较复杂,给出完整代码注释如下:
static bool
FastPathTransferRelationLocks(LockMethod lockMethodTable, const LOCKTAG *locktag,uint32 hashcode)
{LWLock *partitionLock = LockHashPartitionLock(hashcode);Oid relid = locktag->locktag_field2;uint32 i;/** Every PGPROC that can potentially hold a fast-path lock is present in* ProcGlobal->allProcs. Prepared transactions are not, but any* outstanding fast-path locks held by prepared transactions are* transferred to the main lock table.* 每个可能持有快速路径锁的PGPROC都存在于ProcGlobal->allProcs中。* 已准备事务不是,但由已准备事务持有的任何未完成的快速路径锁都会转移到主锁表。*/for (i = 0; i < ProcGlobal->allProcCount; i++)//遍历所有进程{PGPROC *proc = &ProcGlobal->allProcs[i];uint32 f;LWLockAcquire(&proc->fpInfoLock, LW_EXCLUSIVE);/** If the target backend isn't referencing the same database as the* lock, then we needn't examine the individual relation IDs at all;* none of them can be relevant.** proc->databaseId is set at backend startup time and never changes* thereafter, so it might be safe to perform this test before* acquiring &proc->fpInfoLock. In particular, it's certainly safe to* assume that if the target backend holds any fast-path locks, it* must have performed a memory-fencing operation (in particular, an* LWLock acquisition) since setting proc->databaseId. However, it's* less clear that our backend is certain to have performed a memory* fencing operation since the other backend set proc->databaseId. So* for now, we test it after acquiring the LWLock just to be safe.* 如果目标后端没有引用与锁相同的数据库,那么我们根本不需要检查各个关系id;没有一个是相关的。* proc->databaseId在后端启动时设置,此后永远不会改变,因此在获取&proc->fpInfoLock之前执行此测试可能是安全的。* 特别是,可以肯定地假设,如果目标后端持有任何快速路径锁,那么它在设置proc->databaseId之后一定执行了内存隔离操作(特别是LWLock获取)。* 然而,由于另一个后端设置了proc->databaseId,我们的后端是否确定执行了内存隔离操作就不太清楚了。* 所以现在,为了安全起见,我们在获得LWLock后进行测试。*/if (proc->databaseId != locktag->locktag_field1)//如果进程数据库id和当前数据库id不一致则跳过{LWLockRelease(&proc->fpInfoLock);continue;}for (f = 0; f < FP_LOCK_SLOTS_PER_BACKEND; f++)//如果是当前数据库id,则开始遍历16个槽{uint32 lockmode;/* Look for an allocated slot matching the given relid. */if (relid != proc->fpRelId[f] || FAST_PATH_GET_BITS(proc, f) == 0)//表的id不正确或者未加锁则跳过continue;/* Find or create lock object. 循环检查三种弱锁*/LWLockAcquire(partitionLock, LW_EXCLUSIVE);for (lockmode = FAST_PATH_LOCKNUMBER_OFFSET;lockmode < FAST_PATH_LOCKNUMBER_OFFSET + FAST_PATH_BITS_PER_SLOT;++lockmode){PROCLOCK *proclock;if (!FAST_PATH_CHECK_LOCKMODE(proc, f, lockmode))//检查某个进程是否持有某种锁,检查是否有这个是否持有弱锁continue;/* 如果持有弱锁,则将这个弱锁移动到主锁表和进程锁表中去 */proclock = SetupLockInTable(lockMethodTable, proc, locktag,hashcode, lockmode);if (!proclock)//如果失败{LWLockRelease(partitionLock);LWLockRelease(&proc->fpInfoLock);return false;}GrantLock(proclock->tag.myLock, proclock, lockmode);//增加本地锁表计数FAST_PATH_CLEAR_LOCKMODE(proc, f, lockmode);//清理fastpath,也就是pgproc里面}LWLockRelease(partitionLock);/* No need to examine remaining slots. */break;}LWLockRelease(&proc->fpInfoLock);}return true;
}如果前面都成功了,就可以申请强锁了。
![]()
如果申请失败则报错,但是如果申请成功就可以开始检测申请锁与等待队列中的锁是否冲突,比如说这里的lockmode是1,那么对应的lockMethodTable->conflicTab[lockmode]=10000000,表示1级锁与8级锁冲突。如果等待队列中不冲突的话,就要去检查是否与当前的其他事务所持有的锁模式是否存在冲突,这里是由LockCheckConflicts函数去实现的。
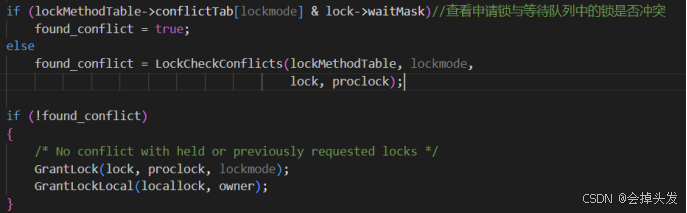
这里对LockCheckConflicts函数进行解释:
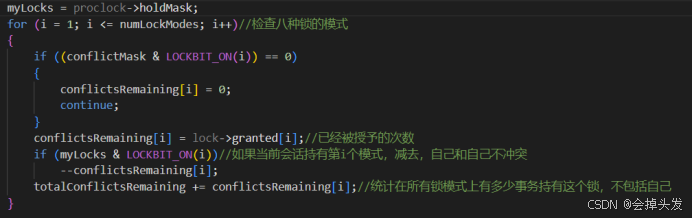
首先先直接拿出与当前锁模式冲突的锁模式与当前对象已经持有的锁模式进行比较,如果没有冲突则直接获取。

如果有冲突,则需要更进一步的检测,统计持有的模式中,冲突的数量,并且还得减去当前会话持有的数量,自己和自己不冲突。
然后再检查一遍,是否由冲突,没有冲突则直接获取。
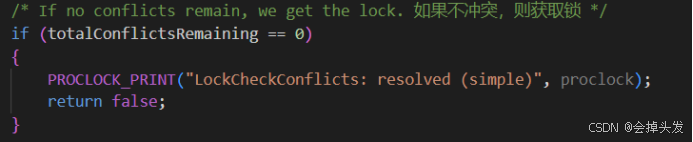
然后如果还是有冲突的话则需要再检测是否可能是组锁冲突,也就是可能这里面存在并行事务,同属一个锁组,不算冲突。
首先检查一下是否是单进程事务,不存在组锁,又存在冲突那么一定是存在冲突的。

如果是并行事务,且是针对表进行拓展操作,即锁的LOCKTAG是LOCKTAG_RELATION_EXTEND则为冲突,因为如果组锁的时候,一个进程要去拓展表的话,其他进程不能去拓展。
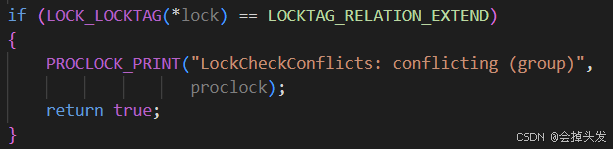
然后就是去检测并行操作, 如果其他进程与当前进程具有相同的groupleader,则不冲突,需要减去冲突计数。
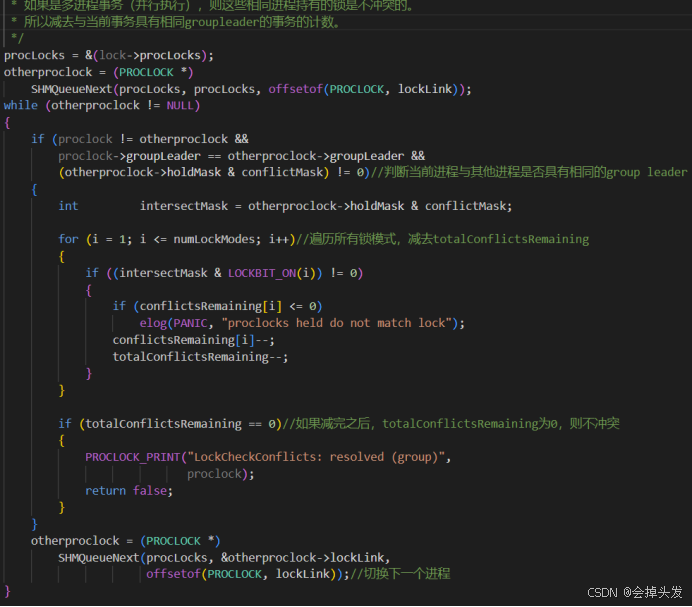
否则的话就意味着不能马上拿到锁,如果在申请的时候指明不等待的话,这个时候直接删除前面的操作,返回失败,如果指明等待的话则进入等待函数WaitOnLock(locallock, owner);。
在插入等待队列的时候需要注意注意一点,通常来说,如当前事务应该插入等待队列的末尾,但是如果本事务A除了当前申请的锁模式之外,已经持有了这个对象的其他锁模式,而且等待队列中某个事务B所等待的锁模式与当前事务A所持有的锁模式冲突,这个时候如果把事务A插入到这个等待者B的后面,则容易出现死锁,所以考虑将事务A插入到等待者的前面。
插入到等待队列之后,就需要进行死锁检测,这里给出调用逻辑:waitOnLock->ProcSleep->CheckDeadLock,详细的死锁检测在后面介绍。
3.3.3、常规锁的释放
相较于常规锁的申请,常规锁的释放就比较简单了。
-
从LockMethodLocalHash 查找LOCALLOCK,在它的owner数组里找到与当前进程对应的元素,解除LOCALLOCK与ResourceOwner之间的关联,并减小相应计数值。
-
将LOCALLOCK的加锁次数(nLocks)减1,如果减为0了,表示当前进程不再持有锁,则后续有两种解锁途径,分别是快速锁和主锁表。
-
对于快速锁,调用FastPathUnGrantRelationLock清除快速锁的加锁标记。如果解锁成功即可返回。
-
如果没找到快速锁,且LOCALLOCK.lock为空,说明被转移到了主锁表里(在加锁逻辑中,当申请快速锁成功时,会把LOCALLOCK.lock置空)。
-
查找主锁表LockMethodLockHash 以及 LockMethodProcLockHash,如果没有找到,则blog-error。找到了 调用UnGrantLock更新LOCK和PROCLOCK信息。
-
调用CleanUpLock:要么删除主表项,要么调用ProcLockWakeup()唤醒等待者,这里会按照 WFG 中构建的 soft-edge 以及 hard-edge 依赖关系进行唤醒。
3.5、死锁检测
在postgresql数据库中,对申请事务锁的顺序没有严格的限制,在申请锁时也没有严格的检查,因此不可避免的会发生死锁。PG使用“乐观锁”来检测死锁,即锁等待的时间超过了时间deadlock_timeout(postgresql.conf中配置,deadlock_timeout = 1s),那么开始进行死锁检测,如果没有死锁继续等待。
如果有一个事务A已经持有某个锁,这个时候事务B来申请这个锁,但是和事务A持有的锁冲突,需要等待A释放之后才能获取,这个时候就产生了等待,可以作为B->A,表示B等待事务A。而在数据库内核中事务是有限的,每个事务都在等待另一个事务,在这个等待的集合中就会出现环,也就是死锁,所以死锁的检测也就变成了环的检测。
还有另一个概念就是实边和虚边,其中实边定义为如果A持有某个对象的共享或者排他锁,这个时候B申请排他锁,就需要进入等待过程,即B——>A。而需边则为,如果事务A持有共享锁,B申请排他锁,然后进入等待队列,这个时候事务C又来申请共享锁,但是虽然C与A不冲突,但是和等待队列中B冲突,也需要进入等待过程。这个时候就产生了事务C等待事务B,即C--------->B。
所以如果产生死锁即检测到环的存在,如果这个环上全部都是实边,则必须结束掉一个事务来接触这个环,如果存在虚边,则可以通过调整等待队列实现解决死锁,即可以调整等待队列中C到B的前面,这个时候C和A不冲突,即可获取锁。
3.5.1、死锁检测中的数据结构
首先是死锁的状态定义:

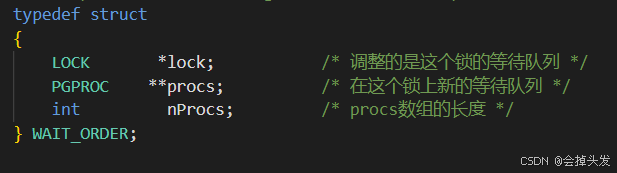
其他方面的话用PGPROC作为节点,EDGE作为边。

如果在换种存在虚边,则调整等待队列消除环,新的等待队列保存在waitOrders数组中,每个数组都是一个等待队列。
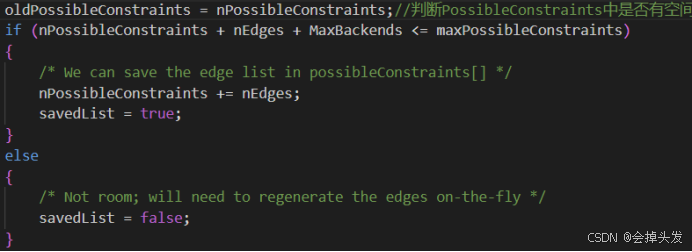
而在这个过程中,可以被调整的虚边记录在possibleConstraints中,每次都是从possibleConstraints找到一个虚边进行探索,而被探索的虚边则保存在curConstrains中,这两个数组的长度必须足够大,curConstrains的长度为MaxBackends,被调整的虚边数量不能超过这个值。
3.5.2、死锁的检测过程
首先进入到的是CheckDeadLock函数,死锁检测的过程是互斥的,就是说在死锁检测开始的时候,锁表就需要被保护起来,防止被其他人修改。

然后如果只有当前对话的话,就不会构成死锁。
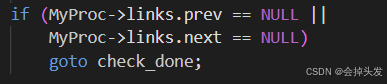
否则就开始检测死锁,即检测是否有环的存在。进入DeadLockCheck函数,在从中进入DeadLockCheckRecurse进行检测,接下来详解该函数:
进入函数之后首先进行是否有环的判断,通过TestConfiguration进行判断,该函数没有环则返回0,有实环则返回-1,其他情况则返回大于0的数。

然后检测对虚边的调整是否达到了最大值,如果达到了最大值,则认为产生了死锁。
![]()
而如果还有检测的空间,则将检测产生的虚边加入到考虑的范围。
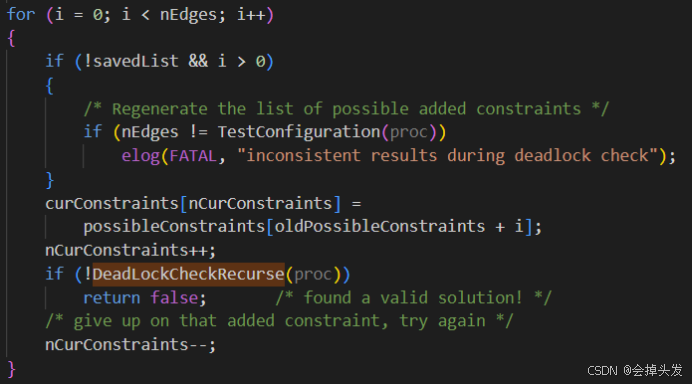
然后递归调用DeadLockCheckRecurse函数,判断是否有死锁。
在上面的TestConfiguration函数的作用就是调用FindLockCycle去检测是否有环。

并调用ExpandConstraints函数尝试对等待队列进行重排来尝试解除虚边死锁,如果存在环的话又将虚边保存到possibleConstraints数组中。
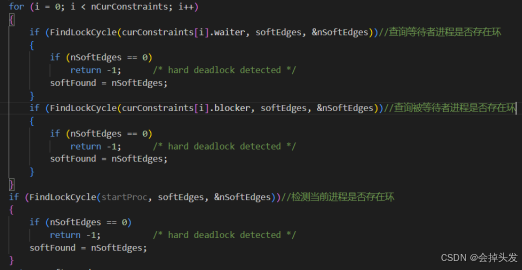
再接着对这里检测死锁所用到的函数FindLockCycle进行详解,但是其实际调用的又是FindLockCycleRecurse函数,接下来对其进行详解:
递归查找是否存在环,FindLockCycleRecurse函数查找的原理就是:在查找环时,先检查待测进程是否在visitedProcs数组中出现过,如果没出现过,就将待测进程存入到visitedProcs数组中,如果出现过,而且是在等待队列的起始处,则表明出现了死锁的环,返回死锁信息。
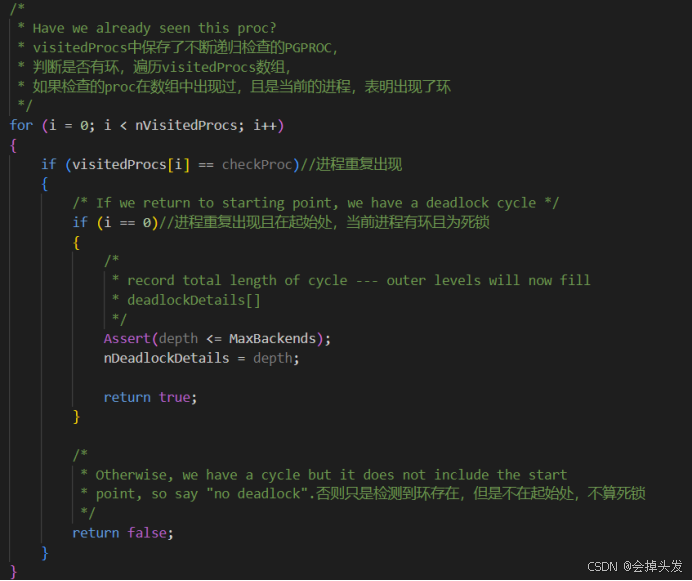
如果不存在环则将待检测进程存入visitedProcs数组中。

如果要检查的进程处于等待状态,那么就递归检测他的等待队列。
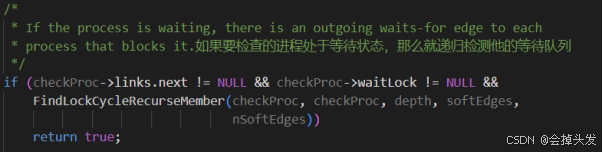
如果待测进程是锁组中的一部分,遍历锁组的每个成员进程,检查是否存在环。
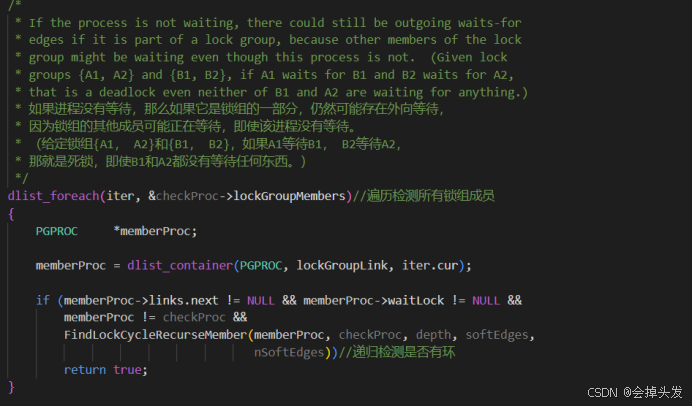
而在这里又提到了一个FindLockCycleRecurseMember函数,这个函数通过递归地检查进程的锁等待依赖关系来检测死锁循环。它区分了硬边(直接阻塞关系)和软边(可调整的等待关系),并在检测到死锁时记录相关信息。函数的设计确保了能够准确地识别死锁场景,并为可能的重排等待队列提供支持,以尝试解决死锁问题。
参考连接或文献
-
《PostgreSQL技术内幕 事务处理深度探索》,张树杰
-
《PostgreSQL数据库内核分析》,彭智勇
-
PostgreSQL · 内核特性 · 死锁检测与解决
-
PostgreSQL的全局死锁检测原理
-
11-pg内核之锁管理器(六)死锁检测
-
PostgreSQL中的表锁
-
PostgreSQL 并发控制 -- 锁体系实现原理
-
[自学分享]Postgres数据库锁机制(部分)
-
37.1 经典知识库:PostgreSQL中的锁 - 张树杰
-
postgresql源码学习(九)—— 常规锁②-强弱锁与Fast Path
-
postgresql源码学习(八)—— 常规锁①-加锁步骤与本地锁表
-
Postgresql源码(69)常规锁细节分析
-
postgresql源码学习(七)—— 自旋锁与轻量锁