Linux重定向的理解
目录
1.task_struct和struct file的关联
2.file
3.文件描述符下标的分配规则以及输出重定向的实现
1.task_struct和struct file的关联
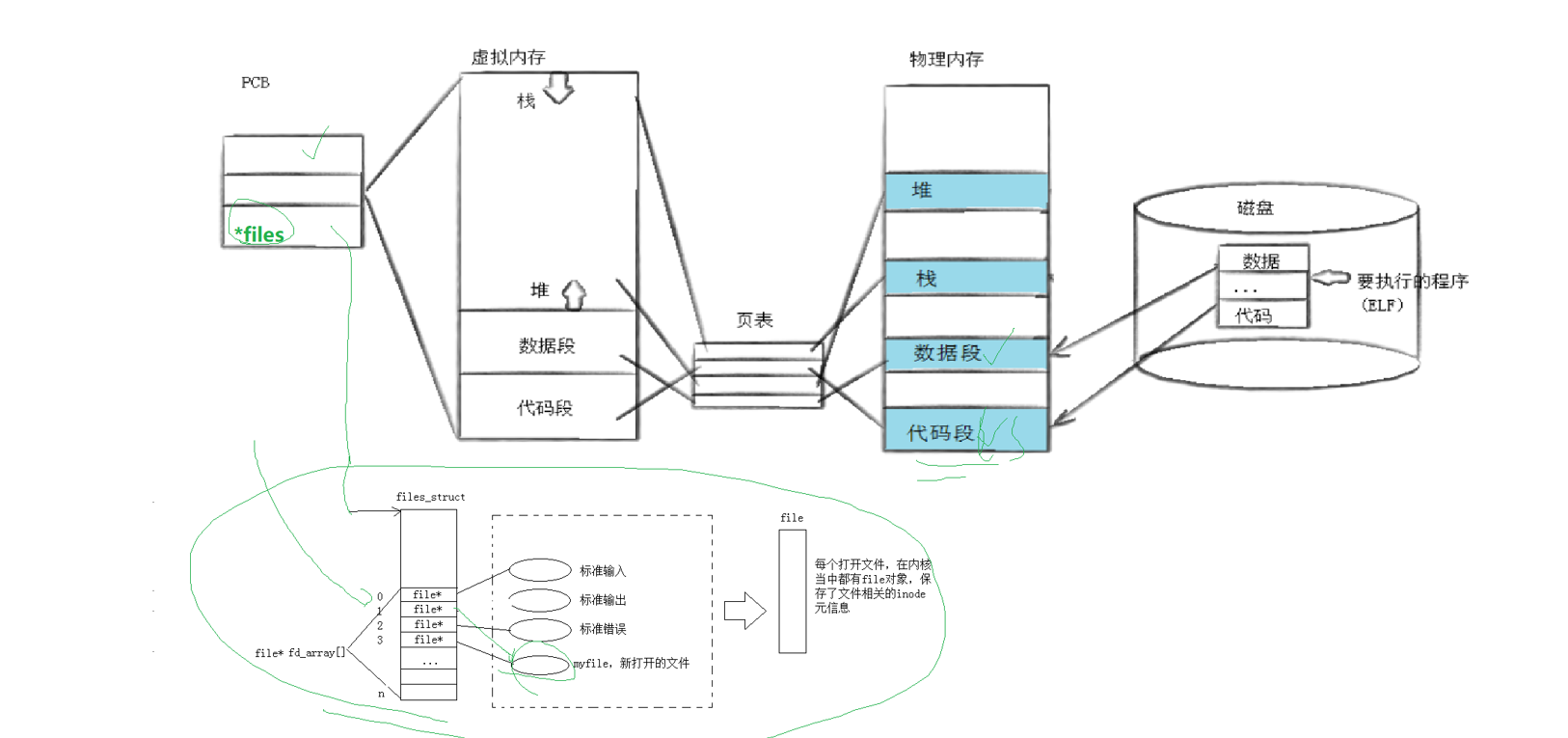
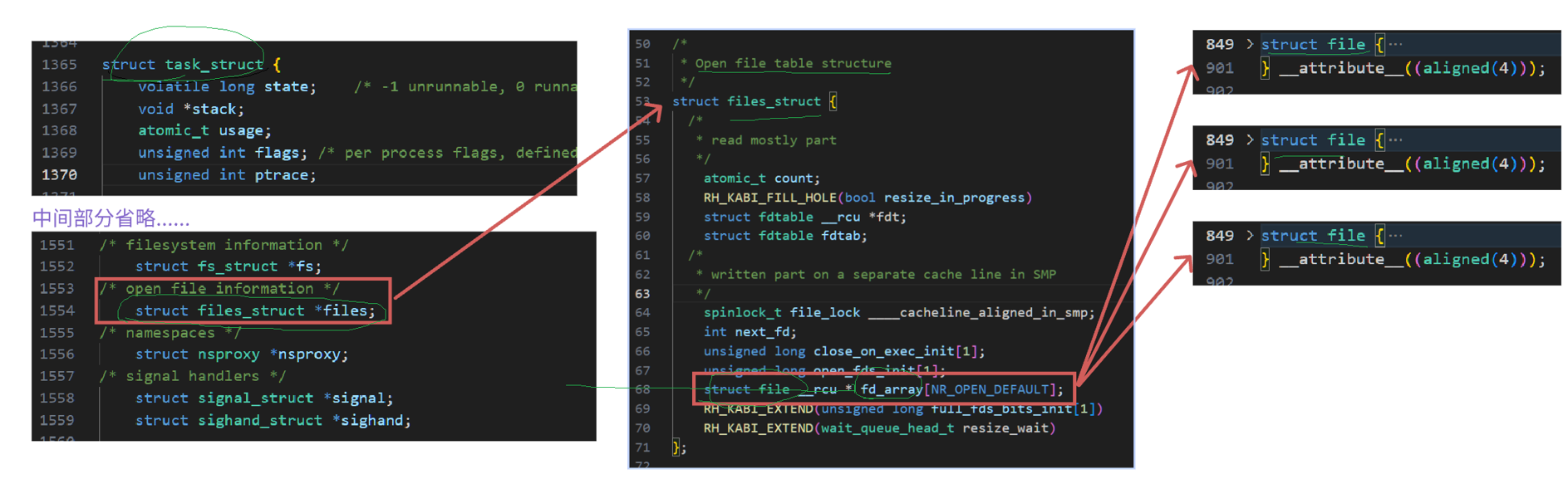
我们的操作系统为了管理进程,用PCB来描述进程的属性,用双链表把进程之间进行关联实现了对进程的管理,那么我们为了管理进程打开的文件,我们的进程里就有一个数组,里面存储的是struct file的指针,我们被进程打开的文件,我们通过数组下标就可以找到这个进程中对应的文件了,同样的我们描述文件用struct file,管理文件还是双链表,我们所有的进程打开的文件被双链表统一管理。这样局部每个进程都管理了它打开的文件,整体上操作系统也通过链表管理了全部被打开的文件。
得出结论:我们的文件描述符本质就是文件描述符表的下标,进程打开时会默认打开三个文件,它们分别是stdin,stdout,stderr,每个被打开的文件都有一个file,然后进程有一个数组统一指向每个文件的file,这样通过下标我们就可以知道文件在进程的位置了。
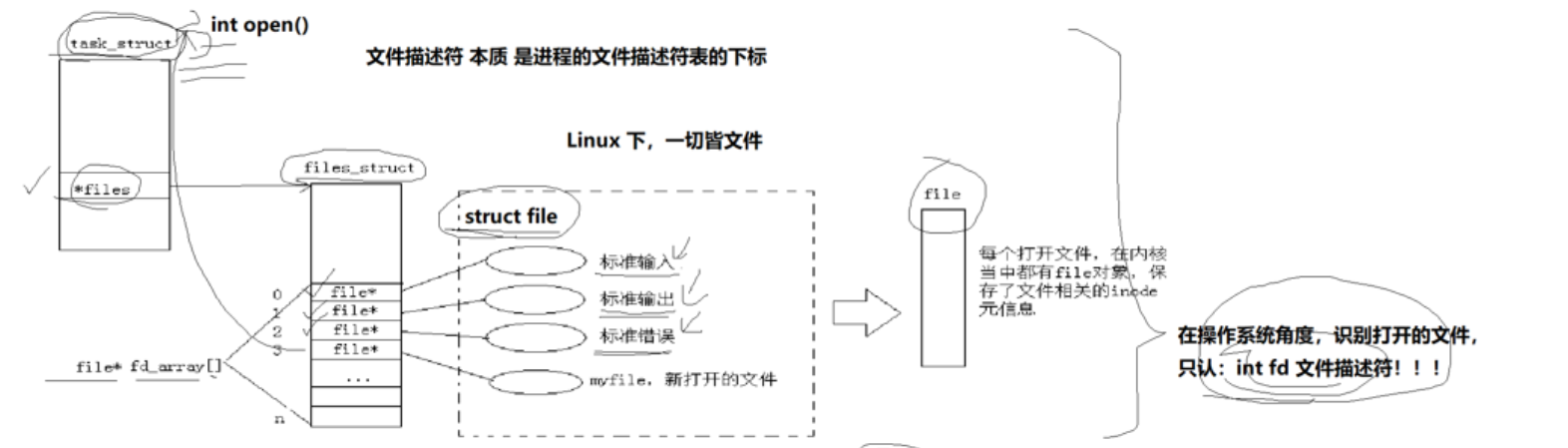
我们还会发现我们调open这样的系统接口返回的是int,这个int就是文件在进程的数组的下标,但是我们调fopen这种C语言被封装好的接口,我们返回的FILE,那么file是对文件的描述,那么我的FILE也是由标准库提供的一个结构体。我们也可以推测,这个FILE里面一定封装了int fd,因为我们要通过fd找到文件啊!本质C接口底层还是要调系统调用。
下面给一段Linux内的源码实现来佐证我们的所说!
2.file
我们的file,我们需要知道当我们往文件里写数据时,它不是直接直接把我们的数据直接写入到磁盘,因为磁盘的速度是非常慢的,试想,我们write一个helloworld它就要进行一次写入,这样大量频繁的写入会降低我们的效率,我们不希望这样的事情发生,所以我们在file里面定义了一个文件缓冲区,当我们往文件里写数据时,实际上数据是先存到文件缓存区内的,然后由操作系统决定什么时候写入到磁盘里去。
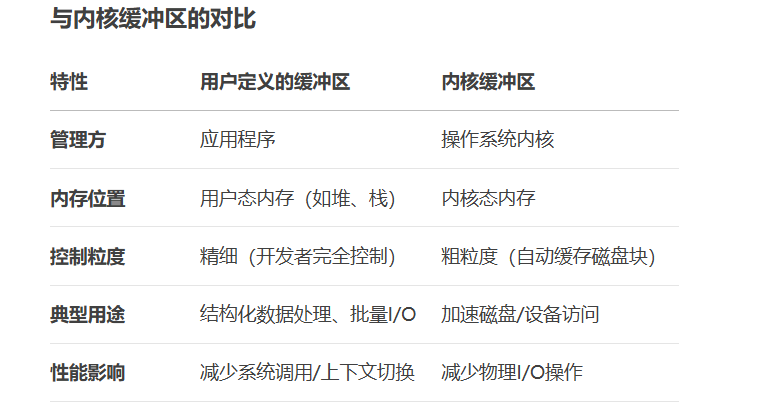

实际上,我们对文件进行增删查改,都要先写到文件缓冲区里,不然大量频繁的与磁盘进行交流会降低我们的效率,所以我们的write根本就不是什么把数据写入到文件,而是把我们的用户空间的数据拷贝到文件的文件内核缓冲区内!!!
3.文件描述符下标的分配规则以及输出重定向的实现
我们文件被进程打开,这个文件的存储在哪里,是存储在最小的下标里去的,从文件描述符表中寻找一个最小的,未被使用的下标,作为文件的fd。
知道了这个规则,我们就可以进行重定向的实现了,当我们关闭我们的stdin,然后打开我们的一个文件,然后printf就会往我们下标为1的文件里打印,这样就实现了输出重定向,相当于欺骗了操作系统!!!

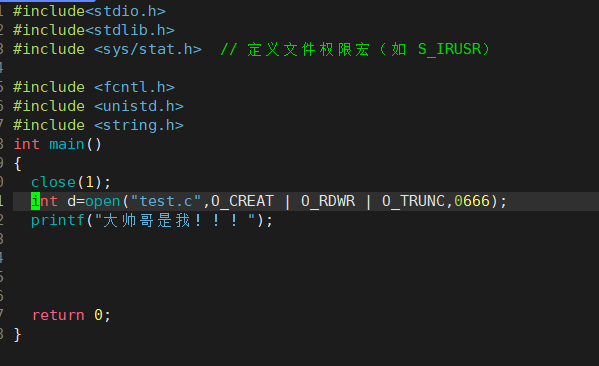
c ? ? ?? buffers 1 #include<stdio.h>2 #include<stdlib.h>3 #include <sys/stat.h> // 定义文件权限宏(如 S_IRUSR)4 5 #include <fcntl.h>6 #include <unistd.h>7 #include <string.h>8 int main()9 {10 close(1);
W> 11 int d=open("test.c",O_CREAT | O_RDWR | O_TRUNC,0666); 12 printf("大帅哥是我!!!");13 14 15 16 17 return 0;18 }~~
![]()
我们这样就实现了往屏幕上打印往文件打印,这样我们就实现了重定向,那么我们的追加重定向不就是换了一个选项吗?我们的这个选项是覆盖的打印,那么我们换成append选项不就变成了追加重定向了吗?
还有一个函数dup()来帮助我们实现重定向,它是把oldfd重定向到newfd中。这样往newfd中写东西就变成了往oldfd中写东西完成了重定向!!!
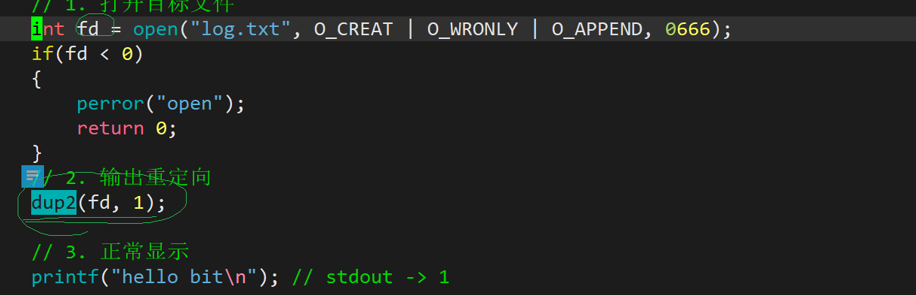
这段代码的意思就是把fd重定向到1,这样往1中输入就变成了往fd中输入,这样就完成了重定向。
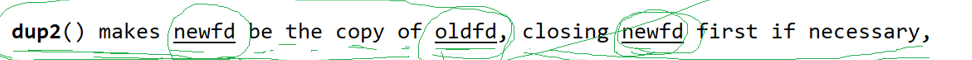
所以当我们理解了重定向的本质之后,那么我们创建子进程,子进程是如何看待父进程打开的文件的?
如果我们做exec程序替换,不会创建新进程那么会影响我们历史打开的文件吗?
当然不会,我们知道了我们的程序替换是对代码和数据的替换,但是进程还是那个进程,它并不影响我们的管理file的数组,所以我们进行程序替换不影响我们的进程打开文件。
而且当我们创建一个子进程,那么它会和父进程的打开文件一样的,我们打印都是往同一个文件里进行打印!!!所以只要父进程打开的012,那么子进程进行指针的拷贝也相当于打开了012!!!,
我们的task_struct和file还有属性代码和数据的关系就这样自然而然的出来了!!!