CNN卷积神经网络之模型评估指标(二)
CNN卷积神经网络之模型评估指标(二)
文章目录
- CNN卷积神经网络之模型评估指标(二)
- 1. 模型评估指标的四个最基础的名词:TP、TN、FP、FN
- 2. 常用指标速查表(含公式 & 代码)
- 3. 一行代码算所有指标(多分类示例)
- 4. 把结果画成混淆矩阵
- 5. 二分类专属 ROC 曲线 & AUC
- 6. 一张图记住指标关系
- 7. 小结 & 使用建议
本文从零开始讲解分类任务常用的评估指标,所有示例数据均在代码中现场生成,复制即可运行,无需任何外部文件。
1. 模型评估指标的四个最基础的名词:TP、TN、FP、FN
做二分类(例如“是不是垃圾邮件”)时,模型对每一封邮件只有两种预测结果:垃圾或正常。把预测结果和真实标签一对比,就得到 4 种情况:
真正例(True Positive, TP)
定义 :模型正确地预测为正类的样本数量。
通俗解释 :假设你有一个垃圾邮件分类器,它会把邮件标记为垃圾邮件或非垃圾邮件。真正例就是那些被正确标记为垃圾邮件的邮件数量。
例子 :
你有 100 封邮件。
其中 30 封是垃圾邮件。
模型正确地将 25 封垃圾邮件标记为垃圾邮件。
那么 TP = 25。
真负例(True Negative, TN)
定义 :模型正确地预测为负类的样本数量。
通俗解释 :假设你有一个垃圾邮件分类器,它会把邮件标记为垃圾邮件或非垃圾邮件。真负例就是那些被正确标记为非垃圾邮件的邮件数量。
例子 :
你有 100 封邮件。
其中 70 封是非垃圾邮件。
模型正确地将 60 封非垃圾邮件标记为非垃圾邮件。
那么 TN = 60。
假正例(False Positive, FP)
定义 :模型错误地预测为正类的样本数量。
通俗解释 :假设你有一个垃圾邮件分类器,它会把邮件标记为垃圾邮件或非垃圾邮件。假正例就是那些被错误地标记为垃圾邮件的非垃圾邮件数量。
例子 :
你有 100 封邮件。
其中 70 封是非垃圾邮件。
模型错误地将 10 封非垃圾邮件标记为垃圾邮件。
那么 FP = 10。
假负例(False Negative, FN)
定义 :模型错误地预测为负类的样本数量。
通俗解释 :假设你有一个垃圾邮件分类器,它会把邮件标记为垃圾邮件或非垃圾邮件。假负例就是那些被错误地标记为非垃圾邮件的垃圾邮件数量。
例子 :
你有 100 封邮件。
其中 30 封是垃圾邮件。
模型错误地将 5 封垃圾邮件标记为非垃圾邮件。
那么 FN = 5。
| 缩写 | 全称 | 中文解释 | 垃圾邮件例子(共 100 封:30 垃圾 / 70 正常) |
|---|---|---|---|
| TP | True Positive | 真正例:真实是垃圾,也预测成垃圾 | 25 封 |
| TN | True Negative | 真负例:真实是正常,也预测成正常 | 60 封 |
| FP | False Positive | 假正例:真实是正常,却被误判成垃圾 | 10 封 |
| FN | False Negative | 假负例:真实是垃圾,却被漏判成正常 | 5 封 |
2. 常用指标速查表(含公式 & 代码)
| 指标 | 公式 | 关注点 | 适用场景 |
|---|---|---|---|
| Accuracy 准确率 | TP+TNTP+TN+FP+FN\frac{TP+TN}{TP+TN+FP+FN} TP+TN+FP+FNTP+TN | 整体猜对的比率 | 类别分布均衡 |
| Precision 精确率 | TPTP+FP\frac{TP}{TP+FP} TP+FPTP | “预测为垃圾的”里多少真的是垃圾 | 宁可漏掉,也别误杀 |
| Recall 召回率 | TPTP+FN\frac{TP}{TP+FN} TP+FNTP | “所有垃圾”里多少被成功找到 | 宁可误杀,也别漏掉 |
| F1-Score | 2⋅P⋅RP+R2\cdot\frac{P\cdot R}{P+R} 2⋅P+RP⋅R | Precision 与 Recall 的调和平均 | 两者都要兼顾 |
3. 一行代码算所有指标(多分类示例)
下面用 sklearn 现场造一份 3 分类数据并计算上述指标,你复制即可跑:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt# 1. 现场生成 3 分类数据集(无需外部文件)
X, y = make_classification(n_samples=1000, n_classes=3,n_informative=4, n_redundant=0,random_state=42)# 2. 训练 / 预测
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
clf = LogisticRegression(max_iter=1000).fit(X_train, y_train)
y_pred = clf.predict(X_test)# 3. 输出指标
print('Accuracy :', accuracy_score(y_test, y_pred))
print('Precision:', precision_score(y_test, y_pred, average='macro'))
print('Recall :', recall_score(y_test, y_pred, average='macro'))
print('F1-Score :', f1_score(y_test, y_pred, average='macro'))
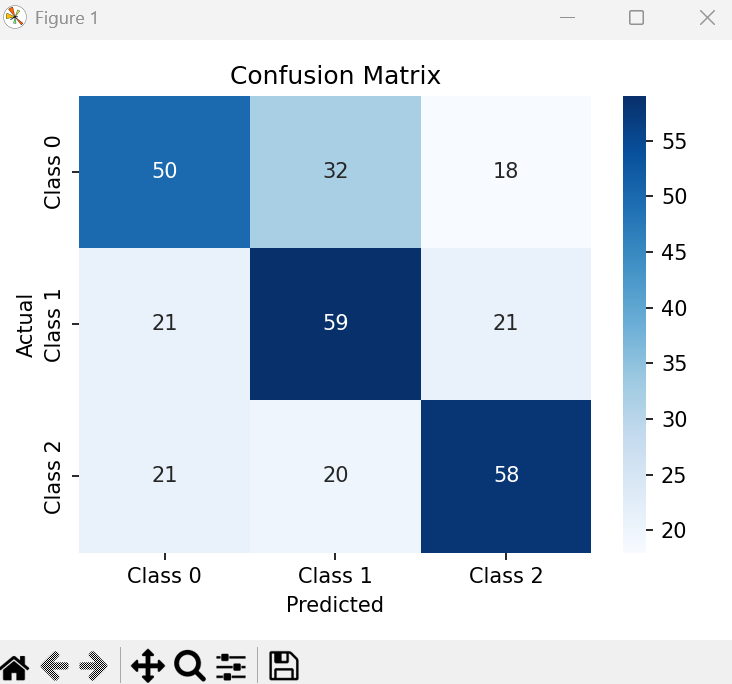
4. 把结果画成混淆矩阵
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix# 1. 生成 3 分类数据集(1000 个样本,20 个特征)
X, y = make_classification(n_samples=1000,n_features=20,n_classes=3,n_informative=6,n_redundant=0,random_state=42
)# 2. 训练 / 测试划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y
)# 3. 训练模型
clf = LogisticRegression(max_iter=1000)
clf.fit(X_train, y_train)# 4. 预测
y_pred = clf.predict(X_test)# 5. 计算并可视化混淆矩阵
cm = confusion_matrix(y_test, y_pred)plt.figure(figsize=(5, 4))
sns.heatmap(cm,annot=True,fmt='d',cmap='Blues',xticklabels=['Class 0', 'Class 1', 'Class 2'],yticklabels=['Class 0', 'Class 1', 'Class 2']
)
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.tight_layout()
plt.show()
- 运行示例:
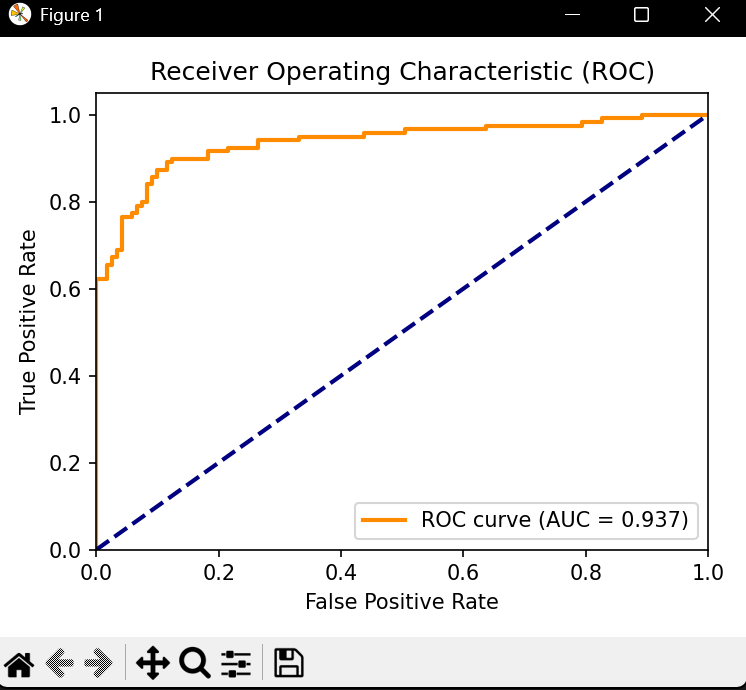
5. 二分类专属 ROC 曲线 & AUC
当任务只有 2 个类别时,可进一步画 ROC 曲线,看模型在不同阈值下的表现。
# ============================================
# 5. 完整版:二分类 ROC 曲线 & AUC
# ============================================
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score# 1. 生成二分类数据集(800 个样本,20 个特征)
X, y = make_classification(n_samples=800,n_features=20,n_classes=2,n_informative=2,n_redundant=10,random_state=1
)# 2. 训练 / 测试划分(分层抽样,保证正负比例一致)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y
)# 3. 训练模型
clf = LogisticRegression(max_iter=1000)
clf.fit(X_train, y_train)# 4. 预测正类概率
y_scores = clf.predict_proba(X_test)[:, 1]# 5. 计算 ROC 曲线 & AUC
fpr, tpr, thresholds = roc_curve(y_test, y_scores)
auc = roc_auc_score(y_test, y_scores)# 6. 绘制 ROC 曲线
plt.figure(figsize=(5, 4))
plt.plot(fpr, tpr, color='darkorange', lw=2,label=f'ROC curve (AUC = {auc:.3f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc='lower right')
plt.tight_layout()
plt.show()
- 运行示例:
6. 一张图记住指标关系
真实垃圾 真实正常
预测垃圾 TP FP
预测正常 FN TN
- Precision = TP / (TP + FP) —— 竖着看
- Recall = TP / (TP + FN) —— 横着看
7. 小结 & 使用建议
| 场景 | 推荐先看 |
|---|---|
| 类别均衡、成本对称 | Accuracy |
| 类别不均衡 | F1-Score 或 AUC |
| 漏检代价高(疾病筛查) | Recall |
| 误检代价高(垃圾邮件) | Precision |
| 想整体看犯错分布 | Confusion Matrix |