python毕业设计案例:基于python django的抖音数据分析与可视化系统,可视化有echarts,算法包括lstm+朴素贝叶斯算法
1 绪论
近年来,短视频平台的迅猛发展催生了大量用户生成内容,抖音作为行业领先的短视频平台,积累了海量用户数据。随着短视频行业的兴起,用户的行为模式、信息传播路径、内容热度变化等因素成为研究的热点。通过对抖音视频数据进行深入分析,可以揭示用户偏好、热点话题演变、内容传播规律及其对用户心理与消费行为的影响。
1.行业价值
通过数据分析可以为短视频平台运营者提供优化算法推荐、提升用户留存率、改进内容分发机制的依据,并可为广告营销提供精准投放策略。
企业可以利用该系统研究用户偏好,制定更精准的营销策略,提升品牌曝光度,提高短视频营销ROI(投资回报率)。
该系统可帮助内容创作者分析视频受众画像、优化内容策略,提高短视频的传播效果和用户互动度。
2.学术贡献
本研究可为社交媒体传播、用户行为分析、推荐系统优化等领域提供数据支持,探讨短视频传播模型、推荐算法对用户消费习惯的影响等问题。
通过对短视频推荐算法的研究,分析其对用户注意力分配、信息接受度的影响,为算法优化提供新思路。
研究用户行为模式、内容传播路径等,有助于进一步完善社交媒体的传播理论,为未来短视频平台的设计提供学术依据。
3.社会影响
随着短视频内容的日益普及,其对用户的行为和心理影响也日渐加深,特别是青少年用户群体。
通过深入分析抖音数据,可以帮助政策制定者优化内容监管机制,减少算法推荐带来的负面影响,如信息茧房、沉迷现象、低质量内容泛滥等问题。
该研究可为政府及社会管理者提供参考,探索更健康、更合理的短视频内容推荐机制,促进短视频行业的可持续发展。
近年来,随着移动互联网的发展,短视频平台迅速崛起,成为人们获取信息、社交娱乐和商业营销的重要途径。针对短视频的研究不断深入,
国外学者多从社交网络分析(SNA)角度研究短视频在用户群体中的扩散路径。Liao等人(2024)在对TikTok用户行为的研究中指出,用户间互动频率与内容转发链是影响传播深度的重要变量。研究者利用图神经网络(GNN)对用户节点间的影响力进行建模,增强传播预测能力。
1.数据采集
设计一个数据抓取模块,利用Python爬虫和抖音API采集抖音视频的相关数据,包括视频内容、评论、点赞、转发、用户信息等。
2.数据清洗与存储
对采集的数据进行去重、格式化、归一化处理,并存入MySQL数据库,以便后续分析。
3.用户行为分析
采用数据挖掘和机器学习方法,分析用户行为模式,如观看习惯、点赞偏好、热门视频传播路径、用户群体画像等。
4.情感分析
使用lstm和朴素贝叶斯算法,结合自然语言处理(NLP)技术,对用户评论数据进行情感分析,识别用户对不同视频内容的情绪倾向,为视频质量评估提供参考。
5.数据可视化
设计数据可视化系统,使用ECharts工具,直观呈现视频传播趋势、热门话题分布、用户互动情况等信息,增强数据分析的直观性和可解释性。
6.系统集成
结合Web前端(boostrap)+后端(django)+数据分析模块,搭建完整的抖音视频数据分析系统,并提供友好的交互界面。
Django是2005年被AdrianHolovaty和SimonWillison所开源的一个PythonWeb框架,它使用MTV(Model-Template-View)架构来尽量简化复杂网站的开发。它鼓励复用代码(即少写冗余代码Don'tRepeatYourself(DRY)),并且非常容易进行快速开发,包含了多种保护安全的功能帮助开发者避免经常发生的安全问题,比如SQL注入攻击、跨站脚本(XSS)攻击、跨站请求伪造(CSRF)攻击等等。Django通过提供强大管理后台、表单、身份验证以及URL设计等功能帮助开发者大大提高Web应用开发的效率和安全性。
抖音视频数据分析系统的设计与实现中,通过request库对抖音api进行发起一个请求,从而获取网页内容和数据,在利用特定的网页解析技术提取出我们想要的内容[8]。
另外可以通过设定参数中的请求头、参数、Cookie等信息等来达到防止网站的反爬。通过循环使用抖音API接口来获取用户评论等信息[9]。
循环神经网络(LRNN)中最为耀眼的明星非长短期记忆网络(LongShortTermMemory,LSTM)莫属,它也是构建时间序列数据处理必备的模块。
朴素贝叶斯是基于贝叶斯定理的简单分类算法,常用于文本分类。本文介绍了朴素贝叶斯模型的核心公式,并实现情感预测模型,强调了模型在处理特征独立性假设下的高效性。尽管模型泛化能力较弱,但在大量样本和特征时仍能展现出良好的预测效果。
为构建抖音视频数据分析系统,需围绕数据设计核心功能模块,具体需求如下:
本模块采用爬虫框架(requests)实现数据抓取,针对抖音平台设计页面解析策略,通过请求头伪装、IP代理池规避反爬机制。
情感分类器采用双层LSTM网络架构,嵌入层使用300维中文词向量,隐藏层设置128个神经元,通过Attention机制捕捉评论关键语义特征。训练数据采用人工标注的2000条评论语料,将准确率提升至80.7%。主题建模采用TF-IDF模型,提取高频主题簇。创新性地将情感标签(积极/消极)与主题进行关联分析,例如发现"不好看"主题在消极评论中出现频率是积极评论的4.3倍。聚类模块提供K-means,对评论进行聚类分析。
使用echarts可视化工具,开发多维度动态图表(如情感分布饼图、主题词云、时间趋势折线图)及地理信息热力图,支持按条件筛选与联动展示。
划分管理员与普通用户权限,支持账户注册、登录及角色分配;管理员可配置数据源、更新模型参数、管理用户权限,普通用户仅限查看分析结果与基础交互操作,确保数据安全与系统稳定性。系统功能图如下所示:
除了实现系统的基本功能,系统的非功能性需求的实现主要遵循了系统设计的四项基本原则,给予系统优良的性能和稳定性的基本保障。
系统业务流程包含数据采集、数据预处理、数据分析和建模、可视化展示结果。数据采集过程包含对抖音评论数据的采集过程。业务流程图见图3.2。

图3.2 系统业务流程图
系统采用前后台分离的三层架构设计,包括表现层、业务逻辑层和数据访问层。表现层采用Django框架作为后台实现用户界面,并通过响应式设计使系统可以在不同设备上有良好显示。表现层通过Ajax等技术向业务逻辑层请求数据,将数据显示或响应用户操作。系统业务逻辑层是对用户请求的处理逻辑和各功能模块的实现核心。本系统将用户认证模块、搜索模块、评论分析模块、情感分析模块作为业务逻辑层的组成部分。评论分析模块使用Echarts可视化图表,结合聚类分析、主题分析结果,将数据呈现。情感分析模块运用LSTM神经网络进行开发。
系统架构如图4.1所示。
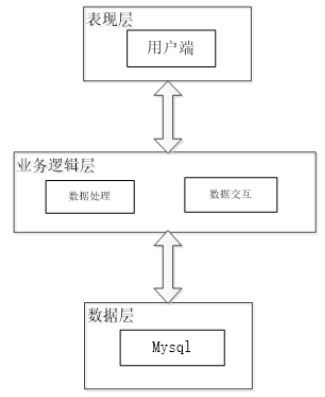
本系统对照功能实现,用户模块也就是系统使用者拥有登录注册、数据采集、数据可视化、情感预测等功能。
数据采集模块利用网络爬虫完成对抖音播放数据和评论的采集、解析和存储。以抖音为数据源,采用Python语言,并借助网络请求库(如requests)、数据解析库(如BeautifulSoup)、数据处理库(如pandas)、数据库操作库(如pymysql、sqlalchemy)等技术加以实现。数据采集流程图如图4.1所示。
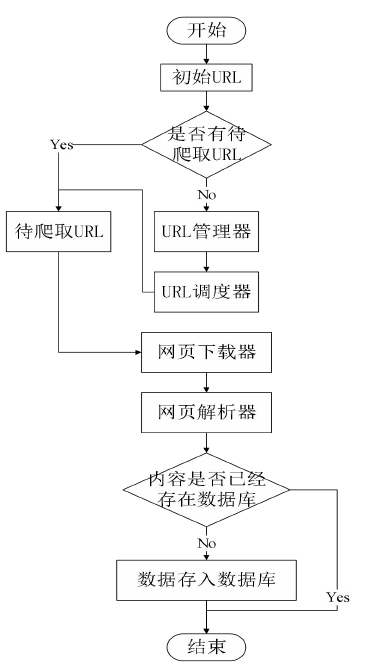
图4.1 数据采集流程图
用户注册时需在界面填写用户名、密码及邮箱信息,触发提交操作后前端将数据传递至服务器。后端对信息合法性进行校验,确认无误后存储至数据库完成账户创建。注册与登录流程图如图4.2所示。
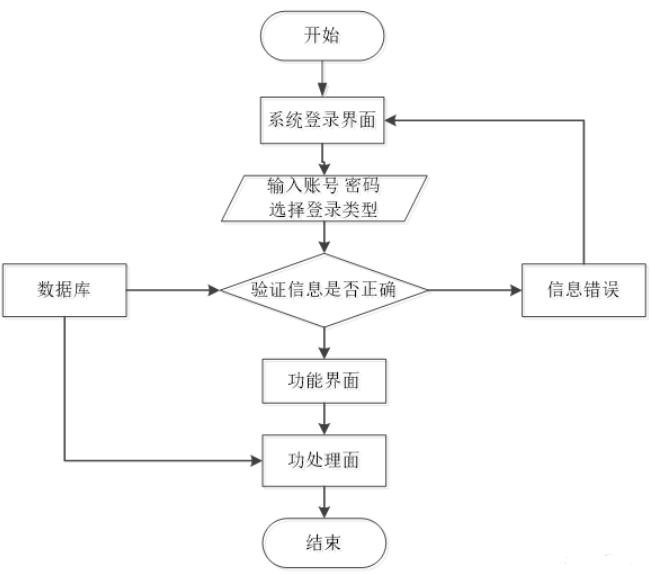
图4.2 注册登录流程图
可视化过程:当系统登录用户进入可视化界面时,前端将对用户的观看请求进行打包并发送给后端服务器。可视化的流程如图4.3所示。
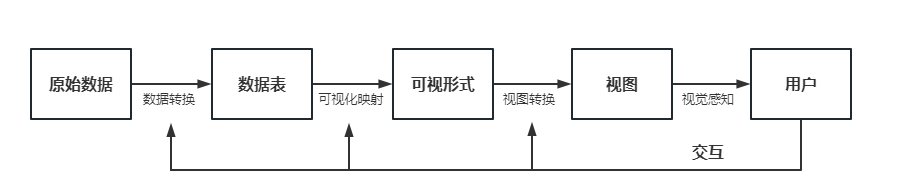
图4.3 数据可视化流程图
预测模块的流程主要分为数据准备、模型训练、预测生成3步,从数据库中准备数据,作为分析的基础,使用LSTM算法训练数据,并经过数据的预处理、词向量转换等方法,划分数据集和训练集进行训练,训练好的模型进行保存。再输入模型对应的文本等作为条件,从而实现预测该文本的情感倾向。模块流程如下图4.4所示。
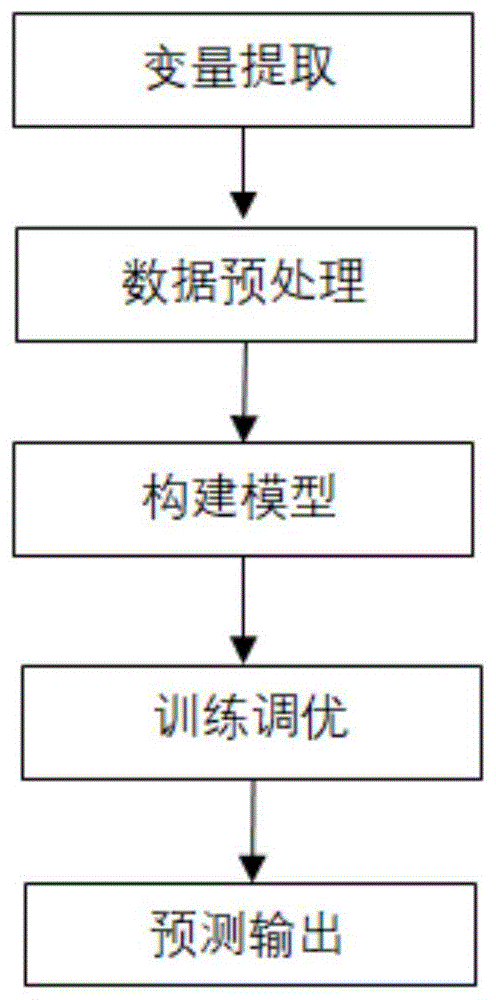
图4.4 情感预测流程图
根据该系统的数据库表的设计,将系统的数据种类归分为用户、评论信息2个实体。用户信息E-R图如图4.5所示,E-R图描述了“用户”实体及其相关属性,包括:ID、账号、密码、头像、姓名、性别、手机号和年龄,用于表示系统中用户的基本信息结构。
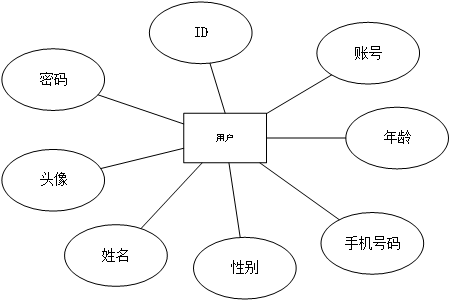
图4.5 用户E-R图
用户信息如表4.1所示,用户表存储用户相关数据,包括用户ID,用户名,密码,邮箱,地址,个人简介,手机号等数据,用户ID为键。
表4.1 用户表
字段名 | 类型 | 长度 | 说明 |
id | int | 0 | 用户编号(主键、自增) |
username | varchar | 255 | 用户名 |
password | varchar | 255 | 密码 |
text | 0 | 邮箱 | |
content | text | 0 | 简介 |
address | text | 0 | 地址 |
phone | text | 0 | 手机号 |
表4.2 评论信息表
字段名 | 类型 | 长度 | 说明 |
视频id | TEXT | 255 | 不为空 |
评论文本 | TEXT | 255 | 不为空 |
评论id | TEXT | 255 | (主键、自增) |
评论时间 | TEXT | 255 | 不为空 |
评论点赞数 | INTEGER | 255 | 不为空 |
评论回复总数 | INTEGER | 255 | 不为空 |
评论评论者 | TEXT | 255 | 不为空 |
评论评论者id | TEXT | 255 | 不为空 |
评论ip属地 | TEXT | 255 | |
评论类型 | TEXT | 255 | |
情感分析 | TEXT | 255 | |
情感分 | REAL | 255 |
根据Python设计抖音评论数据采集模块,借助网络爬虫可对抖音评论进行抓取、解析、储存,主要是抖音作为数据源,应用Python语言借助网络请求库(如requests)、数据解析库(如BeautifulSoup)、数据处理库(如pandas)、数据库操作库(如pymysql、sqlalchemy)等技术实现。具体实现:利用 Python 中的 requests 库模拟浏览器请求,通过访问抖音的 API 接口,按页数循环获取前5000的评论数据。爬取核心代码如图5.1所示:
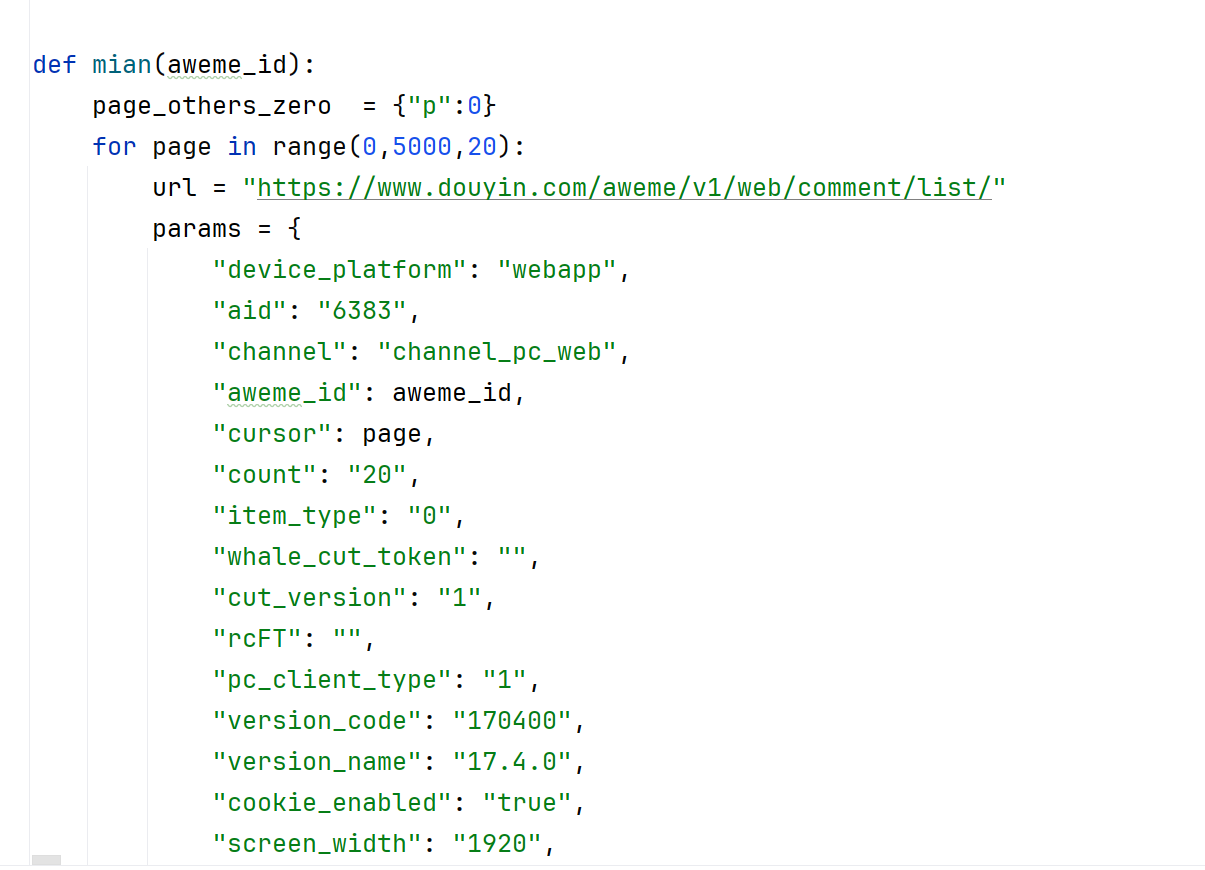
图5.1 数据采集核心代码
使用pandas库将爬取的数据存储在DataFrame中,方便后续处理和分析。数据采集结果如图5.2所示:
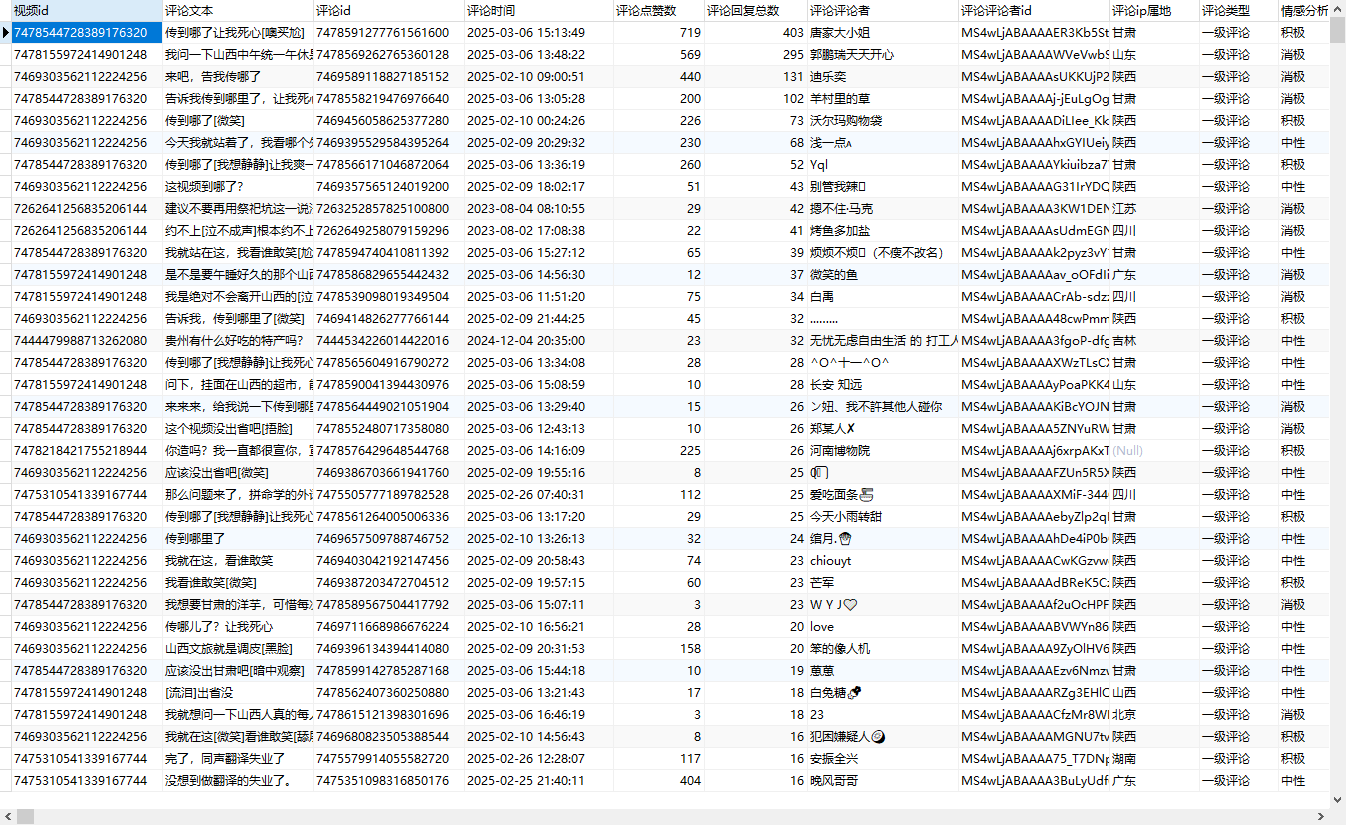
图5.2 数据采集结果
本论文实现了基于文本的数据预处理与数据清洗,即实现数据预览、词汇表构建、数字索引表示、词向量表示构建与数据保存功能。图5.4所示词向量构建:

图5.3 停用词结果

图5.4 词向量结果
模型实现流程如图5.5所示:
图5.5 模型实现流程
划分数据集。该数据集由已经分词的文本以及标签构成。其中标签2个:0代表正向标签,1代表负向标签。数据集整体被划分为训练集、测试集和验证集训练集数据如图5.6,测试数据如图5.7所示:

图5.6 训练集数据

图5.7 测试集数据
是否双向(bidirectional):指定是否使用双向LSTM,以更好地捕捉序列数据的上下文信息。具体参数详细见表5.1所示:
表5.1 LSTM模型参数设计
词汇量 | 嵌入维度 | 隐藏维度 | 数层 | 输出类别数 | 是否双向 | 训练迭代周期 | 学习率 |
54848 | 50 | 128 | 2 | 2 | True | 5 | 0.0001 |
模型训练过程如图5.8所示。

图5.8 训练过程
模型评估流程:通过定义val_accuary()函数,用于评估模型在验证集上的性能表现。
最终模型表现如表5.2所示,测试集表现如表5.3所示:
表5.2 训练集模型效果
accuracy | val_loss | F1_score | Recall | Confusion_matrix |
79.588% | 38.522 | 77.123% | 77.049% | [[22 5][ 9 25]] |
表5.3 测试集模型效果
Test accuracy | val_loss | F1_score | Recall | Confusion_matrix |
81.301% | 2.447 | 75.098% | 75.510% | [[21 2][10 16]] |
数据集划分是模型训练的基础环节,直接影响模型的泛化能力。本方案通过结构化处理原始数据,首先将不同情感标签的Excel文件(中性、负面、正面)合并为统一数据集,利用LabelEncoder将文本标签转化为数值标签(0/1/2),确保模型可处理性。数据集划分代码如下。
文本特征提取是自然语言处理的核心步骤。本方案采用TF-IDF(词频-逆文档频率)算法,通过TfidfVectorizer将原始文本转化为数值特征。特征工程包含多重优化策略:
最终生成稀疏矩阵特征,其中每行代表一个文本样本,每列对应一个词汇的TF-IDF权重。该过程将非结构化文本转化为模型可理解的数值表示,同时通过过滤和组合策略提升特征区分度,为分类模型提供高质量输入。稀疏矩阵结果如下图5.9所示:
图5.9 稀疏矩阵结果
模型训练采用多项式朴素贝叶斯(MultinomialNB),其假设特征条件独立,适合处理离散型TF-IDF特征。为优化性能,引入网格搜索(GridSearchCV)交叉验证调参:
图5.10 朴素贝叶斯最佳模型参数
评估环节通过多维度指标全面验证模型性能:
分类报告:输出各类别的精确率(预测正确的比例)、召回率(真实样本被找回的比例)和F1值(二者调和平均),揭示模型对少数类的处理能力,如图所示5.11所示:
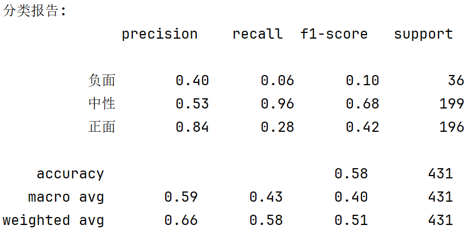
图5.11 朴素贝叶斯算法分类报告
混淆矩阵:热力图直观展示三类测试集中的真实-预测分布,对角线为正确分类数,非对角线反映“将负面误判为中性”等关键错误模式,混淆矩阵结果如下图5.12所示:
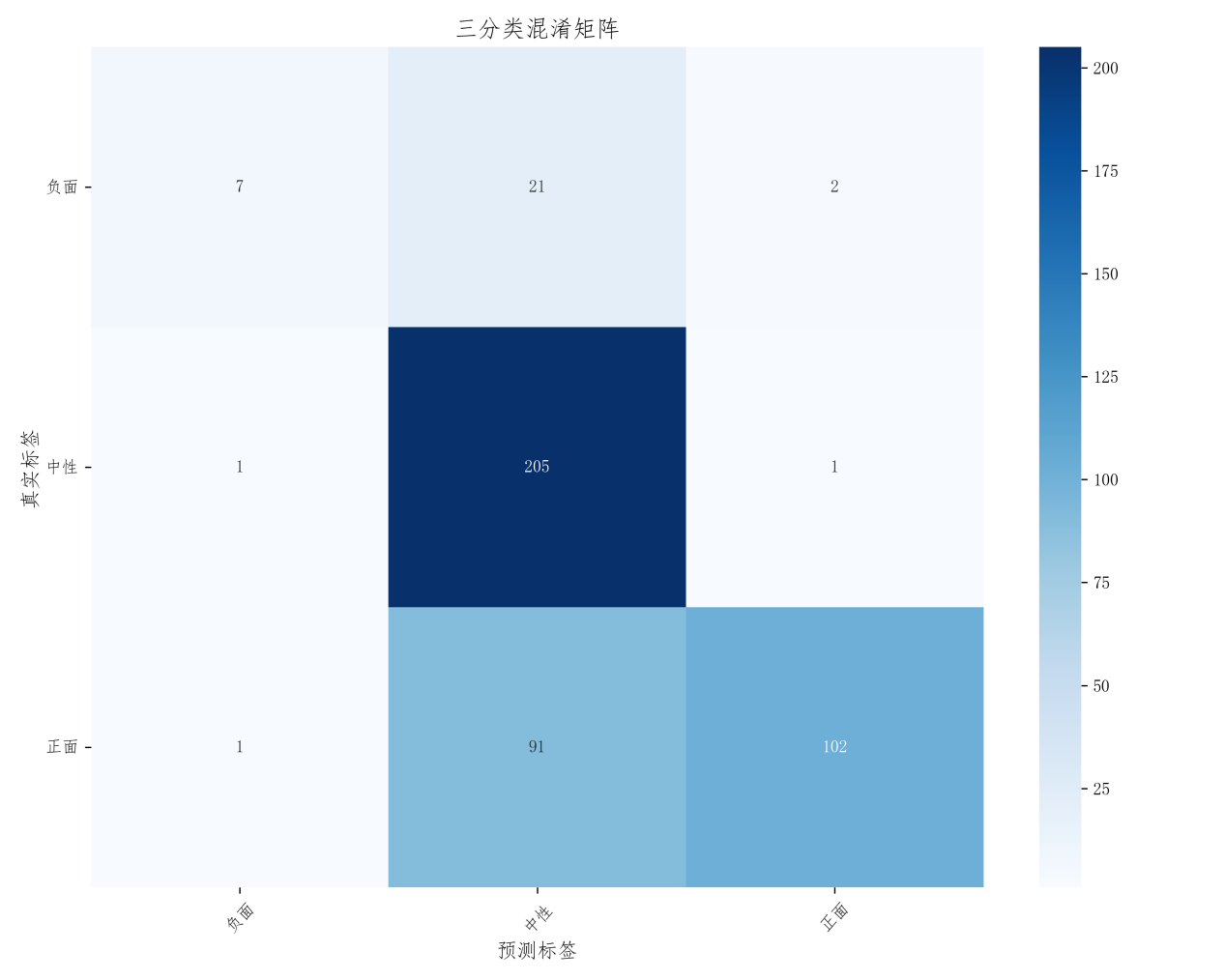
图5.12 朴素贝叶斯算法混淆矩阵结果
登录注册功能通过Django框架实现,结合表单验证和会话管理完成用户认证。如图6.1所示,登录窗口前端,如图6.2所示:

图6.1 注册窗口

图6.2 登录窗口
列表渲染单元以Jinja2模板渲染引擎和Bootstrap框架为基础,使用响应式布局(MobileFirst),即根据屏幕的宽度,自适应于台式机、笔记本电脑、平板以及移动设备(移动电话和触摸屏)。最终,数据展示的效果见图6.3:
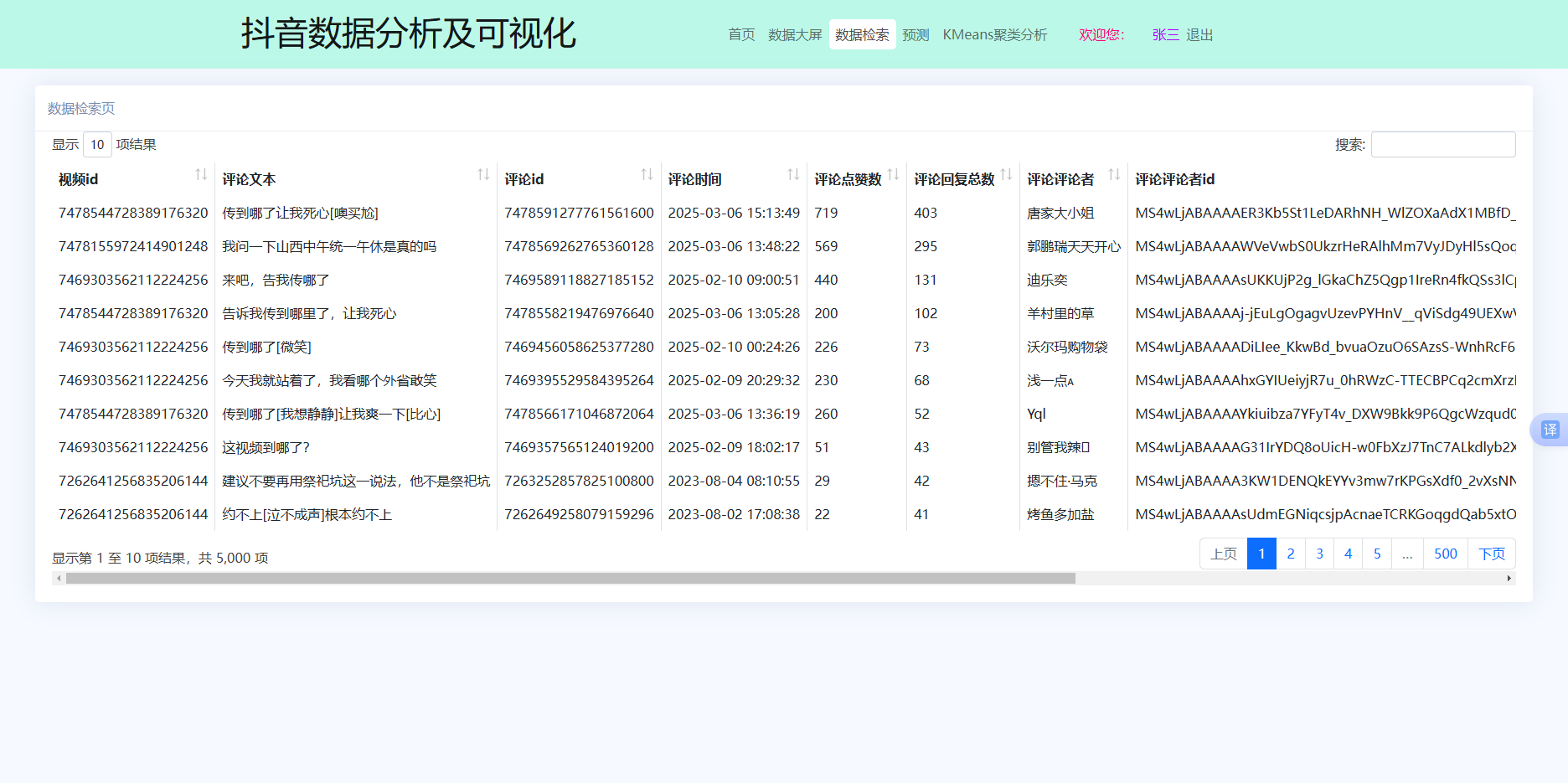
图6.3 数据展示图
数据大屏通过多维度可视化组件动态展示抖音视频评论分析结果。前端采用ECharts与Chart.js构建交互式图表,集成地图热力图、情感分布饼图、主题词云及时间趋势折线图,支持数据实时渲染与自适应布局。最终,数据大屏的效果见图6.4:
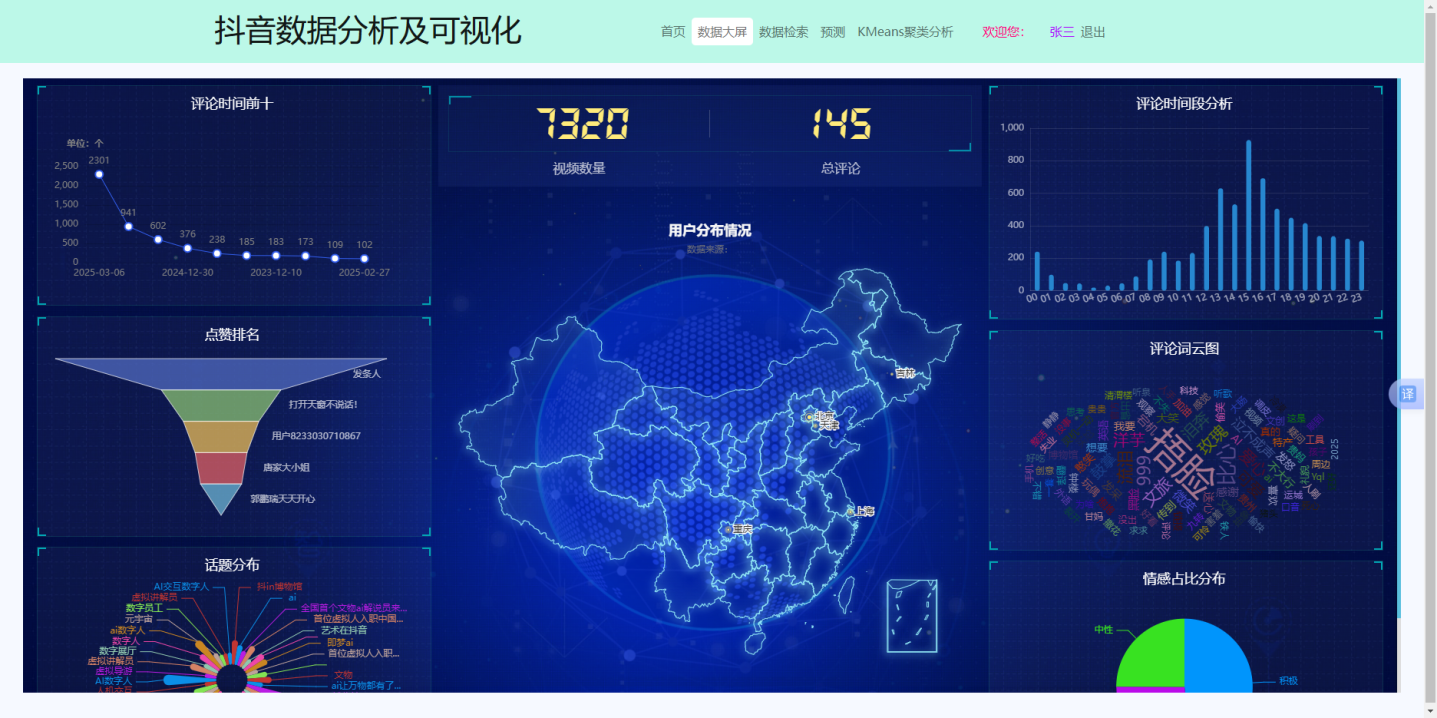
图6.4 数据大屏显示
该模块基于KMeans算法实现抖音评论主题聚类分析可视化。用户通过下拉菜单选择不同情感类型(如积极、消极),前端触发AJAX请求向后端发送类别参数。最终,效果见图6.6:
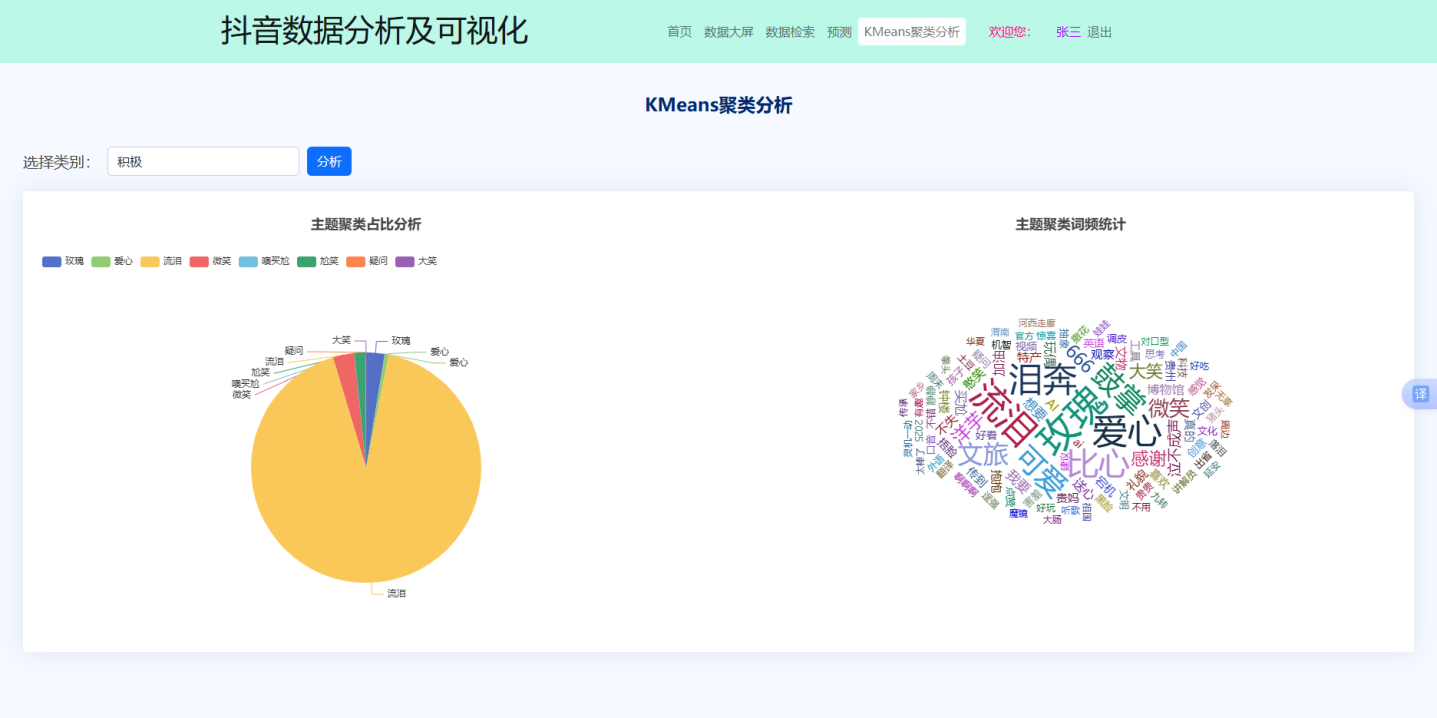
图 6.5 聚类分析效果图
该功能提供多模型情感极性预测服务,用户输入评论文本并选择算法模型(SVM、朴素贝叶斯、LSTM)后,前端通过AJAX将数据异步提交至/predict路由。最终,效果见图6.7:
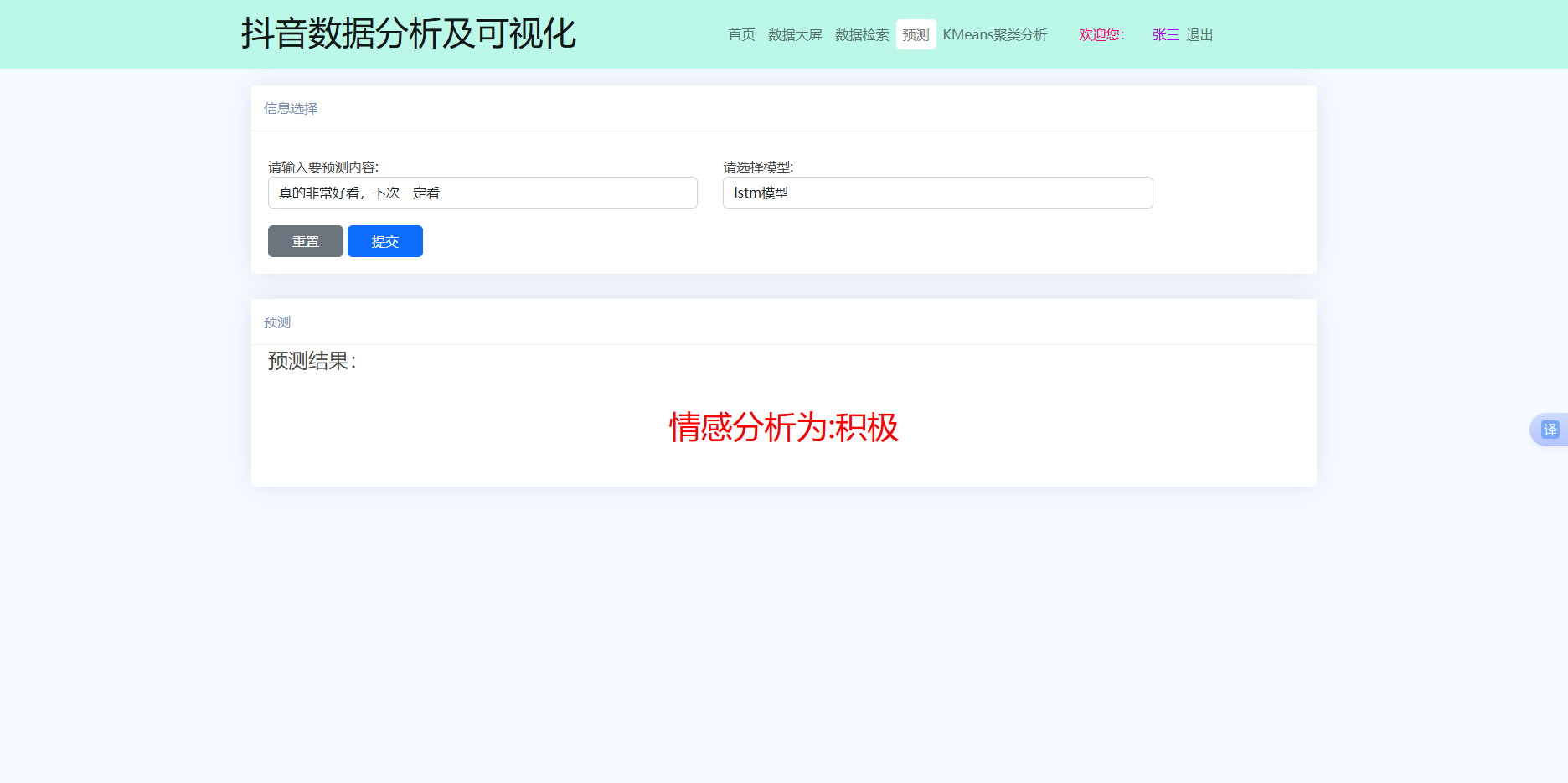
图 6.6 情感功能预测图