为什么bert是双向transformer
BERT 是双向 Transformer,这是它的一个核心创新点。下面我从 技术原理、与传统 Transformer 的区别、以及双向性的实际意义 来详细解释为什么 BERT 被称为“双向 Transformer”。
一、什么是 BERT 的“双向”?
在 BERT 的论文中,双向的原文是 "Bidirectional", 更准确地说,BERT 是“深度双向(deeply bidirectional)”的 Transformer 编码器。
这个“双向”指的是:
在每一层 Transformer 中,每个词(token)的表示都能同时看到其左边和右边的上下文。
也就是说,BERT 在预训练阶段对句子的处理是 同时从左往右和从右往左都考虑上下文信息的。
二、对比:BERT vs GPT
| 模型 | 基于结构 | 上下文类型 | 是否双向 |
|---|---|---|---|
| GPT | Transformer Decoder | 单向(从左到右) | 否 |
| BERT | Transformer Encoder | 双向(同时看左右) | 是 |
GPT 采用左到右的自回归(AutoRegressive)语言建模方式,预测当前词时,只依赖其左边的词。
BERT 使用 Masked Language Model(MLM)来随机遮住输入中的一部分词,然后预测被遮住的词,它需要依赖左右两侧的词语来推理出被遮住的词。
三、为什么 BERT 是双向 Transformer?
1. BERT 的预训练任务:Masked Language Modeling(MLM)
BERT 用的是 Masked Language Model,即在输入中随机掩盖一部分 token(如 [MASK]),训练模型去预测这些被遮盖的词:
举例:
输入:
The man went to the [MASK]目标:预测
[MASK]为store或park等
此时,模型 必须利用 [MASK] 左右两侧的信息 来做预测。因此,它在每一层都需要看到整个句子(不是单向的)。
这一点和 GPT 的左到右建模完全不同。
2. Transformer 本身结构支持双向
Transformer 编码器(Encoder)中使用的是 自注意力机制(Self-Attention),它允许每个 token 与输入序列中的所有 token 建立联系:
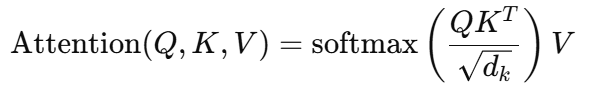
在 BERT 中,没有添加任何掩码(mask)来阻止右边的信息参与注意力,因此它是自然的双向结构。
GPT(Decoder)则添加了下三角 mask,阻止模型看见未来的信息,使得它只能看到左边。
四、BERT 的双向性优势
上下文更完整
传统语言模型(如 GPT)只能从一个方向理解上下文,而 BERT 可以同时考虑前后信息,对句子理解更深。
这对于命名实体识别、问答、自然语言推理等任务效果更好。
更强的表示能力
每一个 token 的 embedding 编码,融合了整句话的语义信息,有利于更复杂的语义建模。
对称建模句子结构
适用于文本蕴含、句子对匹配等需要对称理解的任务。
五、总结
BERT 是双向 Transformer,因为它在预训练阶段使用 MLM 任务,在每一层 Transformer 编码器中都能同时访问 token 的左右上下文。
双向性的实现依赖于 Transformer 编码器 的自注意力机制,不加入方向性掩码。
相比传统的单向语言模型(如 GPT),BERT 的双向特性使得它在多种自然语言理解任务中表现更强。