DeepSeek实战--无头浏览器抓取技术
1. 背景
DeepSeek有很强的数据、语言分析能力,怎么获取最新的数据喂给大模型分析,是必须要解决的问题。对应页面上的静态数据抓取比较简单,前面有文章介绍过,不再敖述,感兴趣的同学,可以爬楼看一下。 一般的网站肯定不会那么傻,自己的数据,放到页面上,轻易的让大家[特别是竞对] 获取到,所以一般会有一些防爬的策略,比如:页面数据由服务端动态返回、风控等,那么就需要有一些高阶的技术手段来抓取数据,比如:无头浏览器 、客户端模式,今天我们先讲“无头浏览器 ”。
什么是无头浏览器 ?
指的是没有界面的浏览器。我们依然可以借助火狐,谷歌等浏览器进行数据的抓取,但不会产生界面。这项技术有一个比较常用的框架,叫做 Selenium,它是一个自动化测试和浏览器自动化的开源框架。它允许研发人员编写脚本,并借助浏览器和浏览器的驱动,来模拟在浏览器中的行为,自动执行一些列的操作,比如:点击按钮、填写表单、导航到不同的页面等。
目标:通过无头浏览器抓取招聘网站岗位信息,为 DeepSeek 大模型提供实时数据输入。
2. 环境准备
我准备了一台阿里云的ubuntu 20.04 64位 服务器
1)安装 selenium SDK:
pip install selenium==4.23.1
2)要装好浏览器以及浏览器驱动。我们选用 Chrome 浏览器,大厂产品更稳定,哈哈哈
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
3)更新依赖
# apt-get install -f
# sudo apt update
# sudo apt install -f
4)安装浏览器
dpkg -i google-chrome-stable_current_amd64.deb
5)检查安装结果
google-chrome --version

6)安装浏览器驱动
wget https://repo.huaweicloud.com/chromedriver/138.0.7204.168/chromedriver-linux64.zip```
无法访问国外网络,找了一个国内的镜像。注意版本要与浏览器的版本一致。
7)解压驱动
unzip chromedriver-linux64.zip
8)用测试代码验证一下selenium,测试代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
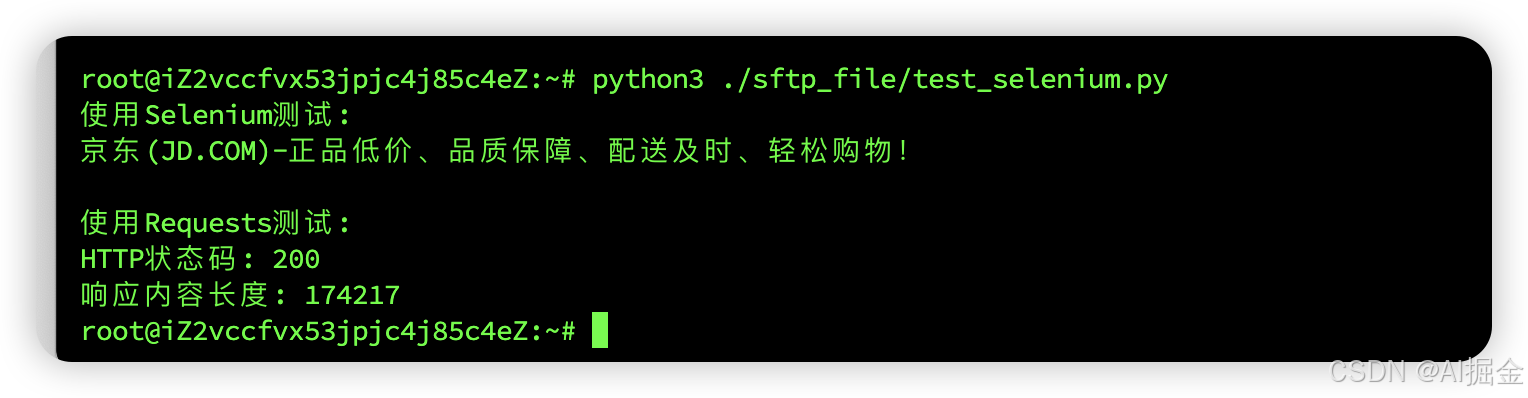
import requestsdef test():#定位到 可执行程序chromedriver_path="/root/chromedriver-linux64/chromedriver"# '--verbose', log_output=sys.stdout,service = Service(executable_path=chromedriver_path,service_args=['--headless=new','--no-sandbox','--disable-dev-shm-usage','--disable-gpu','--ignore-certificate-errors','--ignore-ssl-errors',])options = Options()options.add_argument('--headless')options.add_argument('--no-sandbox')options.add_argument('--disable-dev-shm-usage')options.add_argument('--ignore-certificate-errors')options.add_argument('--ignore-ssl-errors')driver = webdriver.Chrome(options=options,service=service)driver.set_page_load_timeout(30) # 减少超时时间driver.get("https://www.jd.com/")print(driver.title)driver.quit()def test_with_requests():try:headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36'}response = requests.get("https://www.jd.com/", headers=headers, timeout=30)print(f"HTTP状态码: {response.status_code}")print(f"响应内容长度: {len(response.text)}")return Trueexcept Exception as e:print(f"Requests请求失败: {e}")return Falseif __name__ == "__main__":print("使用Selenium测试:")test()print("\n使用Requests测试:")test_with_requests()
9)selenium验证结果
3. 实战:帮你抓取感兴趣的job
第1步:通过页面源代码,查看页面代码结构
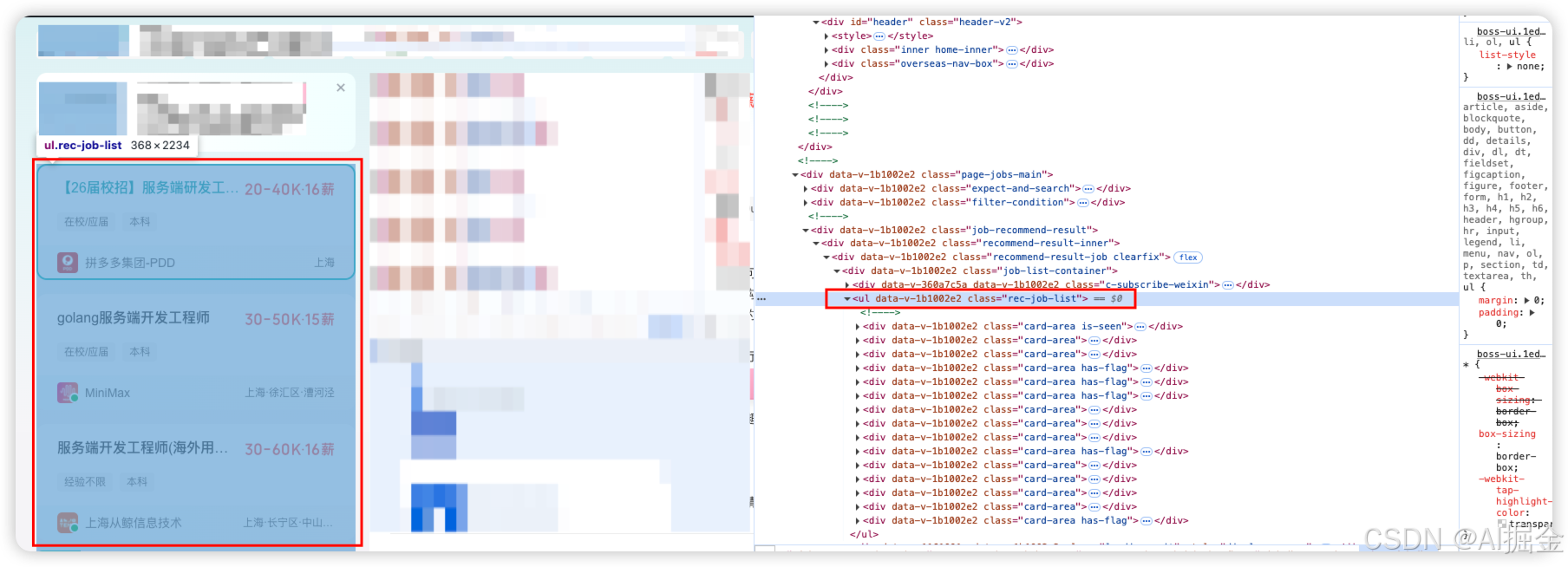
通过源代码可以看出,在 class=“rec-job-list”
下面有,我们需要的岗位信息,例如:岗位名称、薪资、base地…
第2步:写代码抓取页面要素内容
from urllib.parse import urlencode
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
import random
import time
import tempfile
import uuid
import os
import syslisturl = "https://www.zhipin.com/web/geek/jobs?{}"def get_UA():UA_list = ['Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36']randnum = random.randint(0, len(UA_list) - 1)UA = UA_list[randnum]return UAdef init_driver() -> webdriver.Chrome:print("初始化浏览器驱动...")# 检查 chromedriver 是否存在chromedriver_path = "/root/chromedriver-linux64/chromedriver"if not os.path.exists(chromedriver_path):print(f"ChromeDriver 不存在: {chromedriver_path}")return Noneprint(f"使用 ChromeDriver: {chromedriver_path}")service = Service(executable_path=chromedriver_path)options = Options()# 基础选项options.add_argument('--headless=new')options.add_argument('--no-sandbox')options.add_argument('--disable-dev-shm-usage')options.add_argument('--disable-gpu')options.add_argument('--disable-extensions')options.add_argument('--disable-plugins')options.add_argument('--user-agent=' + get_UA())# 创建唯一的用户数据目录unique_id = str(uuid.uuid4())temp_dir = f"/tmp/chrome_userdata_{unique_id}"options.add_argument(f'--user-data-dir={temp_dir}')print(f"使用用户数据目录: {temp_dir}")# 额外的稳定性选项options.add_argument('--disable-background-timer-throttling')options.add_argument('--disable-renderer-backgrounding')options.add_argument('--disable-backgrounding-occluded-windows')options.add_argument('--disable-ipc-flooding-protection')# 禁用自动化标识options.add_experimental_option("useAutomationExtension", False)options.add_experimental_option("excludeSwitches", ["enable-automation"])try:print("正在创建浏览器实例...")driver = webdriver.Chrome(options=options, service=service)print("浏览器实例创建成功")return driverexcept Exception as e:print(f"创建浏览器实例失败: {e}")import tracebacktraceback.print_exc()return Nonedef listjob_by_keyword(keyword: str, page: int = 1, size: int = 30) -> str:print(f"搜索职位关键词: {keyword}")url = listurl.format(urlencode({"query": keyword,"city": "101020100" # 上海}))print("访问URL: ", url)driver = init_driver()if driver is None:raise Exception("创建无头浏览器失败")try:print("正在访问页面...")driver.get(url)print("页面标题: ", driver.title)# 等待页面加载print("ob-recommend-result 等待页面元素加载...")WebDriverWait(driver, 1000).until(EC.presence_of_element_located((By.CSS_SELECTOR, '.rec-job-list')))print("job-recommend-result 加载完成")# 等待页面加载print("job-list-container 等待页面元素加载...")WebDriverWait(driver, 1000).until(EC.presence_of_element_located((By.CSS_SELECTOR, '.rec-job-list')))print("job-list-container 加载完成")# 等待页面加载print("rec-job-list 等待页面元素加载...")WebDriverWait(driver, 10000).until(EC.presence_of_element_located((By.CSS_SELECTOR, '.rec-job-list')))print("rec-job-list 页面元素加载完成")li_list = driver.find_elements(By.CSS_SELECTOR, "[class*='card-area']")print(f"找到 {len(li_list)} 个职位条目")jobs = []for i, li in enumerate(li_list):try:job_name_list = li.find_elements(By.CSS_SELECTOR, ".job-name")if len(job_name_list) == 0:continuejob = {}job["job_name"] = job_name_list[0].textprint(f"处理职位 {i + 1}: {job['job_name']}")job_salary_list = li.find_elements(By.CSS_SELECTOR, ".job-salary")job["job_salary"] = job_salary_list[0].text if job_salary_list else "暂无"job_tags_list = li.find_elements(By.CSS_SELECTOR, ".tag-list li")job["job_tags"] = [tag.text for tag in job_tags_list] if job_tags_list else []com_name_elements = li.find_elements(By.CSS_SELECTOR, ".boss-name")if not com_name_elements:continuejob["com_name"] = com_name_elements[0].textcom_tags_list = li.find_elements(By.CSS_SELECTOR, ".company-tag-list li")job["com_tags"] = [tag.text for tag in com_tags_list] if com_tags_list else []job_tags_list_footer = li.find_elements(By.CSS_SELECTOR, ".job-card-footer li")job["job_tags_footer"] = [tag.text for tag in job_tags_list_footer] if job_tags_list_footer else []companylocations = li.find_elements(By.CSS_SELECTOR, ".company-location")if not companylocations:continuejob["company_location"] = companylocations[0].textjobs.append(job)except Exception as e:print(f"处理第 {i + 1} 个职位时出错: {e}")continuejob_tpl = """
{}. 岗位名称: {}
公司名称: {}
岗位要求: {}
技能要求: {}
薪资待遇: {}
公司地址: {}"""ret = ""if len(jobs) > 0:for i, job in enumerate(jobs):job_desc = job_tpl.format(str(i + 1),job["job_name"],job["com_name"],",".join(job["job_tags"]),",".join(job["job_tags_footer"]),job["job_salary"],job["company_location"])ret += job_desc + "\n"print(f"完成直聘网分析,共找到 {len(jobs)} 个职位")else:ret = "没有找到任何岗位列表"return retexcept Exception as e:print(f"处理过程中出错: {e}")import tracebacktraceback.print_exc()return f"处理失败: {e}"finally:try:print("关闭浏览器...")driver.quit()except Exception as e:print(f"关闭浏览器时出错: {e}")if __name__ == "__main__":print("开始职位搜索")try:ret = listjob_by_keyword("服务端架构")print("搜索结果:")print(ret)except Exception as e:print(f"程序执行出错: {e}")import tracebacktraceback.print_exc()
我将调试过程的代码都附上了,方便大家了解整个程序执行过程
第3步:验证结果

4.总结
1)能抓到这些数据,后续我们可以做很多事情了,薪资抓出来乱码,平台故意脱敏的,后续有时间可以研究一下。从原理上来讲,页面上展示的内容,都能抓出。
2)在调试过程总遇到各种浏览器与系统版本不匹配、浏览器与驱动不匹配,系统不匹配这问题,折腾了半天,最初用的centos 结果centos 版本没法直接升级,阿里云没有稳定的版本centos,后面换的ubuntu
3)在调试抓取内容的时候,最好结合ai 编程工具,可以提升,编码速度