Spring AI 学习笔记
简介
Spring AI 是 Spring 官方推出的开源框架,旨在为 Java 开发者提供便捷的 AI 能力集成方案,于 2024 年 10 月 18 日正式发布 1.0 版本。它通过标准化接口和模块化设计,降低大模型应用开发门槛,让开发者能够充分利用现有的 Spring 生态系统来构建和部署 AI 应用。
Spring AI 本质上是一个扩展模块,类似于 Spring Boot 或 Spring Cloud,但它专注于与 AI 相关的功能。通过 Spring AI,开发者可以利用 Spring 生态系统的强大功能(如依赖注入、配置管理、微服务支持等),同时无缝地集成现代 AI 技术。
Spring Al 的核心特性如下,参考官方文档:
- 跨 AI 供应商的可移植 AP1 支持:适用于聊天、文本转图像和嵌入模型,同时支持同步和流式 API选项,并可访问特定于模型的功能。
- 支持所有主流 AI模型供应商:如 Anthropic、OpenAI、微软、亚马逊、谷歌和 Ollama,支持的模型类型包括:聊天补全、嵌入、文本转图像、音频转录、文本转语音
- 结构化输出:将 AI模型输出映射到 POJO(普通 Java 对象)。
- 支持所有主流向量数据库:如 Apache Cassandra、Azure Cosmos DB、Azure Vector Search、Chroma、Elasticsearch、GemFire、 MariaDB、 Milvus、 MongoDB Atlas、Neo4j、OpenSearch、 Orace、 PostgreSQL/PGVector、 PineCone、Qdrant、Redis、SAP Hana、Typesense 和Weaviate.
- 跨向量存储供应商的可移植 API:包括新颖的类 SOL 元数据过滤 API。
- 工具/函数调用:允许模型请求执行客户端工具和函数,从而根据需要访问必要的实时信息并采取行动。
- 可观测性:提供与 AI相关操作的监控信息。
- 文档 ETL 框架:适用于数据工程场景。
- AI模型评估工具:帮助评估生成内容并防范幻觉响应。
- Spring Boot 自动配置和启动器:适用于 AI 模型和向量存储。
- ChatClient API:与 AI聊天模型通信的流式 API,用法类似于 WebClient 和 RestClient APl。
- Advisors API:封装常见的生成式 AI 模式,转换发送至语言模型(LLM)和从语言模型返回的数据,并提供跨各种模型和用例的可移植性。
- 支持聊天对话记忆和检索增强生成(RAG)。接下来根据官方文档学习并实操spring AI提供的相关功能
接下来参考官方文档学习并实操spring AI提供的相关功能
搭建项目
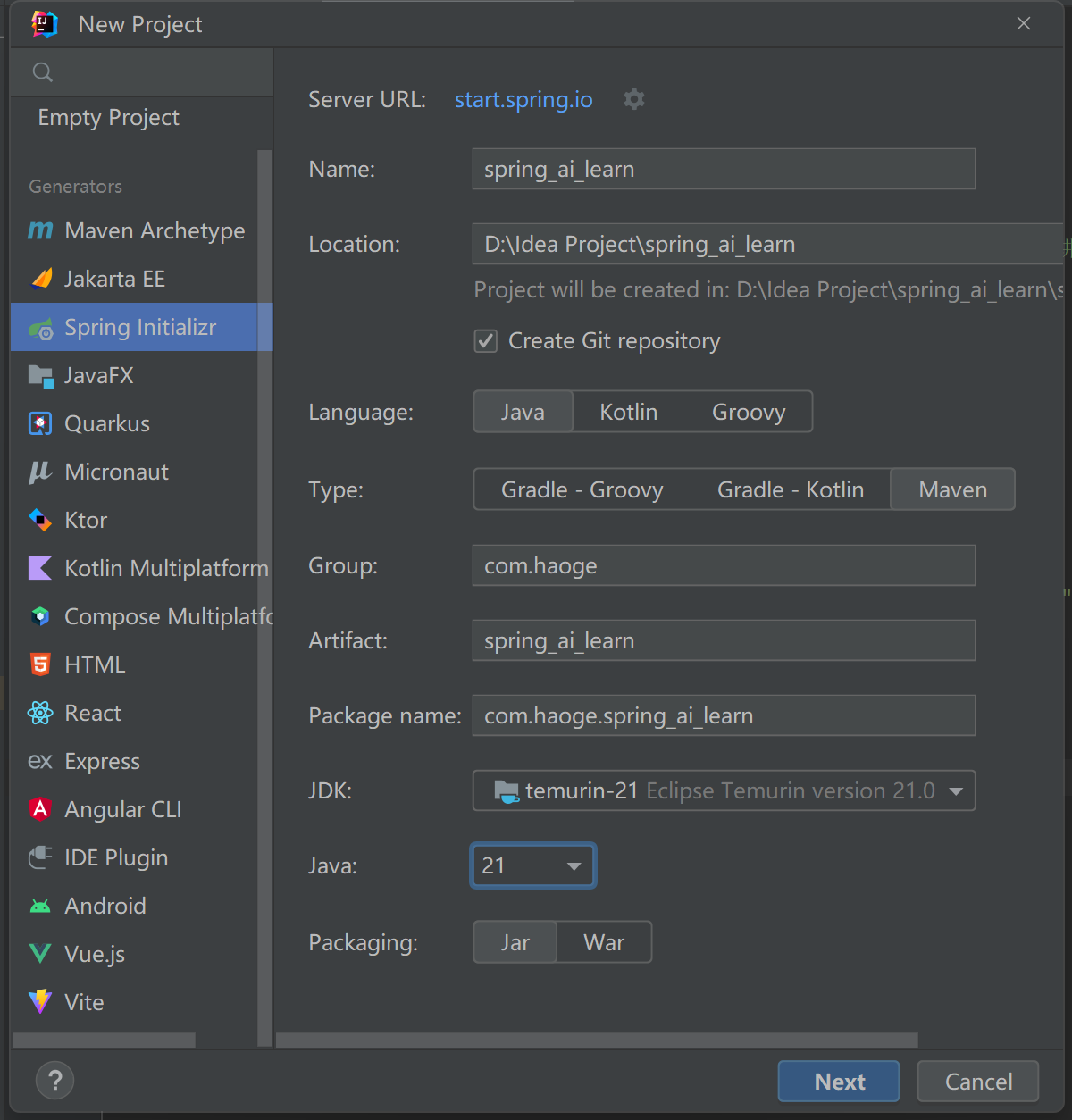
添加spring web和openAI依赖
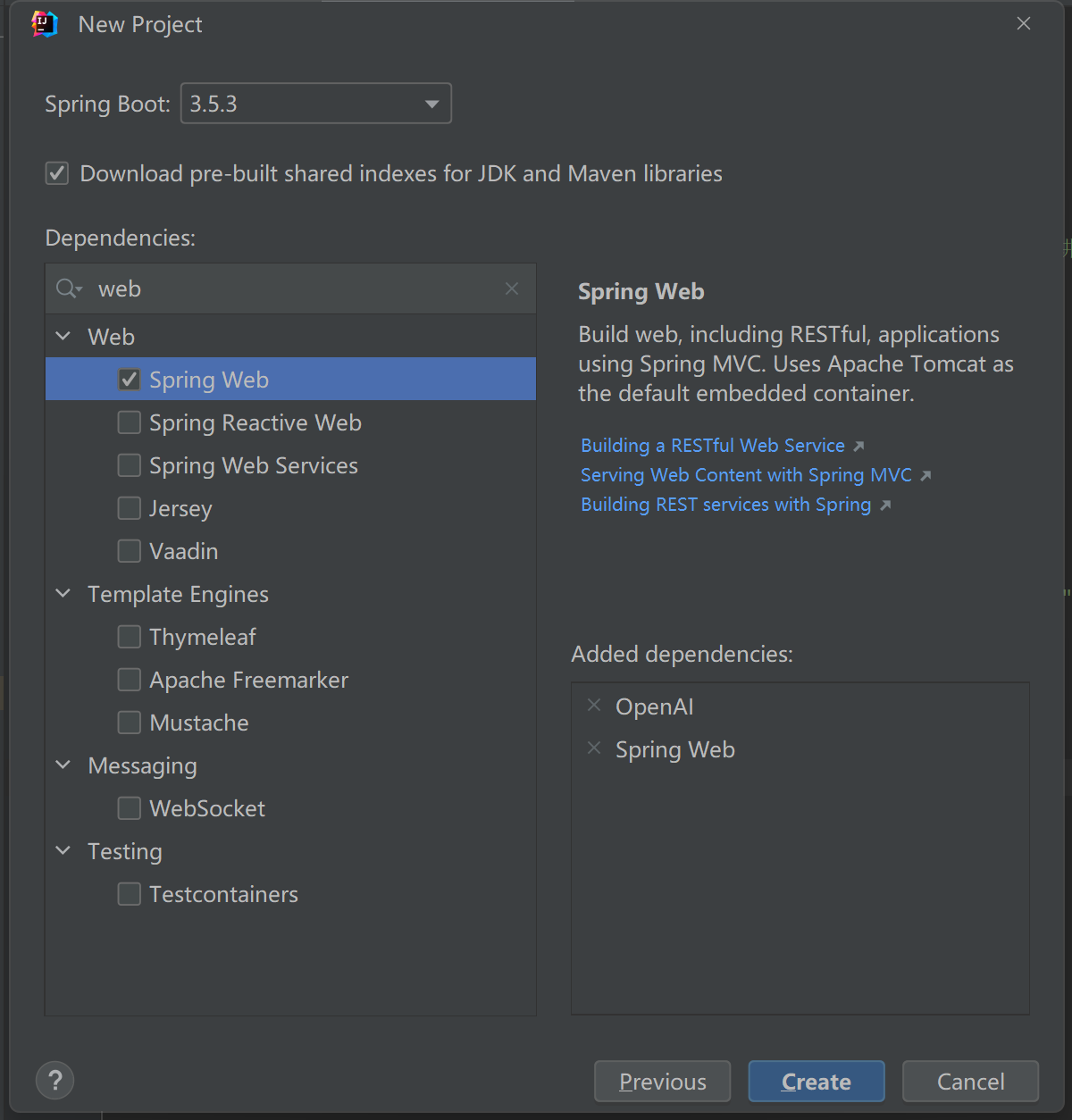
点击创建
依赖介绍
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>这个依赖是 Spring AI 框架中针对 OpenAI 模型服务的 Spring Boot 启动器(Starter),它提供了与 OpenAI API 集成的自动化配置。并不是只能调用OpenAI的各种 AI 模型(如 GPT-4、GPT-3.5、DALL-E、Embeddings 等)其他的遵循OpenAI API 格式的厂商提供AI接口都能通过相同方式调用,例如deepseek AI API。
接入大模型
通过Open AI Starter 对接Deepseek
编写配置信息
spring:ai:openai:api-key: 你申请的key #这里的key可以是OpenAI API key也可以是Deepseek API keybase-url: https://api.deepseek.com #跟上面保持一致就行chat:options:model: deepseek-chat #跟上面保持一致就行新建controller
@RestController
@RequestMapping("/ai")
public class AiController {private final ChatModel chatModel;public AiController(ChatModel chatModel) {this.chatModel = chatModel;}@RequestMapping("/chat01")public String chat01() {return chatModel.call("生命的意义是什么?");}
}访问接口

使用Deepseek Starter 对接 Deepseek
引入Deepseek Starter依赖
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-deepseek</artifactId></dependency>配置文件
spring:ai:openai:api-key: 你申请的keybase-url: https://api.deepseek.comchat:options:model: deepseek-chatdeepseek:api-key: 你申请的keychat:options:model: deepseek-chat #可以不指定使用的模型,默认为deepseek-chat 还可以选择 usedeepseek-coder模型编写controller
@RestController
@RequestMapping("/ai")
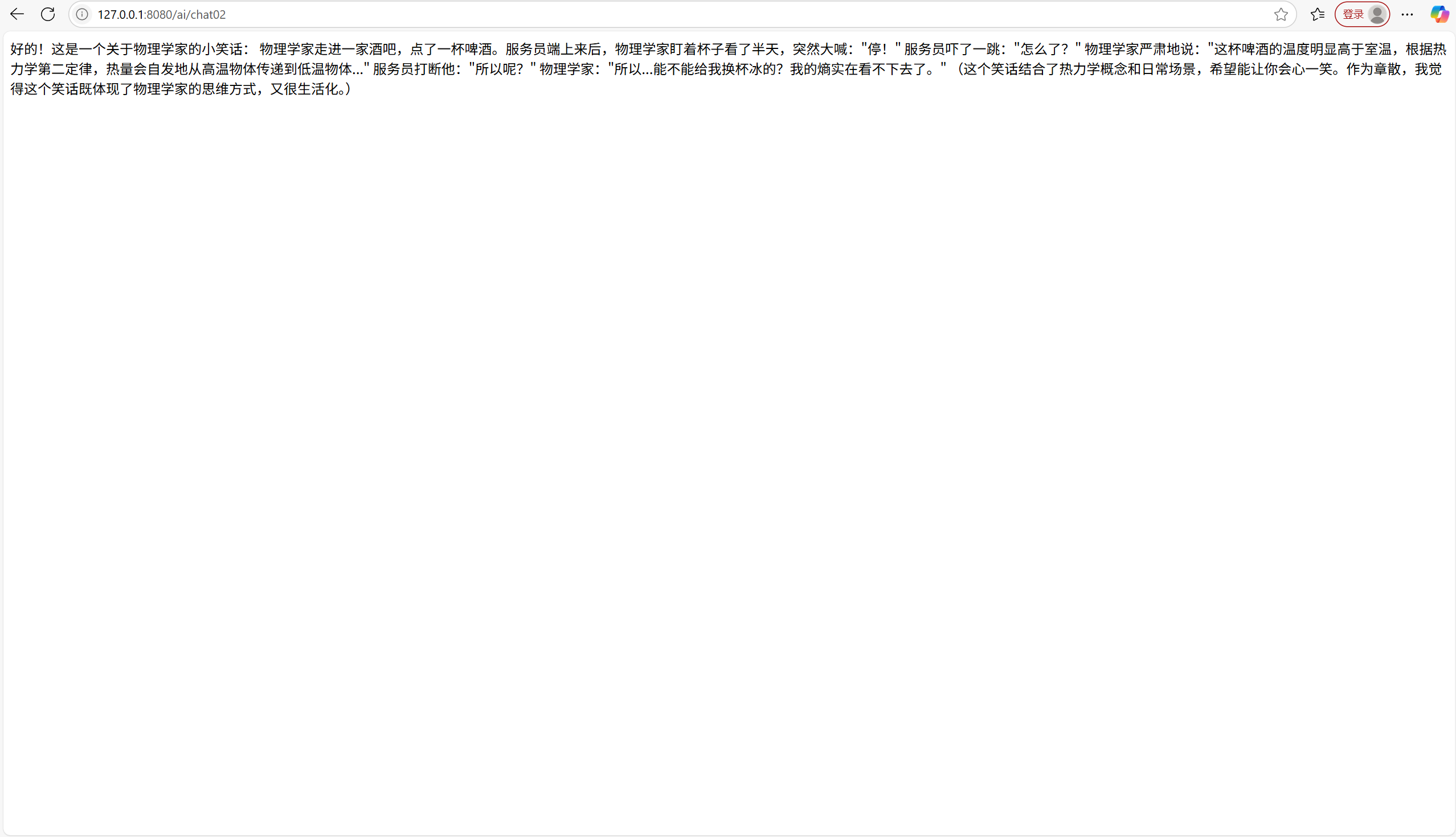
public class AiController {private final ChatModel openAiChatModel ;private final ChatModel deepSeekChatModel;//由于引入两个starter 依赖所以这里要分别指定一下chatModelpublic AiController(DeepSeekChatModel deepSeekChatModel,OpenAiChatModel openAiChatModel) {this.deepSeekChatModel = deepSeekChatModel;this.openAiChatModel = openAiChatModel;}/**** @return the string*/@GetMapping("/chat01")public String chat01() {return openAiChatModel.call(new UserMessage("讲一个笑话"), new SystemMessage("你是一个科学家,名叫:里斯"));}/**** @return the string*/@GetMapping("/chat02")public String chat02() {return deepSeekChatModel.call(new UserMessage("讲一个笑话"), new SystemMessage("你是一个物理家,名叫:章散"));}
}调用chat02接口
使用Ollama Starter 对接 Deepseek
首先要安装ollama客户端,并拉取对应的模型(参考教程),我本地拉的是deepseek-r1:7b模型
运行对应的模型
ollama run deepseek-r1:latest
访问localhost:11434,可以看到模型正常运行

到项目中添加对应的依赖
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-ollama</artifactId></dependency>配置文件
spring:ai:openai:api-key: 你申请的keybase-url: https://api.deepseek.comchat:options:model: deepseek-chatdeepseek:api-key: 你申请的keychat:options:model: deepseek-chat #可以不指定使用的模型,默认为deepseek-chat 还可以选择 usedeepseek-coder模型ollama:base-url: http://localhost:11434 #默认http://localhost:11434chat:options:model: deepseek-r1:latest编写controller接口
/**** @return the string*/@GetMapping("/chat03")public String chat03() {return ollamaChatModel.call(new UserMessage("讲一个笑话"), new SystemMessage("你是一个画家,名叫:汪乌"));}效果

对接大模型只是Spring AI 框架提供的最基础的功能之一,Spring AI框架还提供了一系列高级功能来方便开发AI应用。
Spring AI 框架高级功能
ChatModel和ChatClient介绍
在上面的例子中都是使用ChatModel和AI交互,ChatModel 是 Spring AI 框架定义的抽象接口(屏蔽底层服务差异),而 ChatClient 是具体实现(负责与特定 AI 服务提供商通信)。
| 功能复杂度 | 基础功能,适合简单场景 | 高级功能,适合复杂场景 |
| 使用场景 | 简单对话、一次性请求 | 多轮对话、上下文管理、RAG 等 |
| 编程模型 | 低级别 API,需手动构建 Prompt | 流畅 API,支持同步和流式编程 |
| 开发效率 | 较低,需更多手动配置 | 较高,内置高级功能 |
| 可扩展性 | 更灵活,适合定制化场景 | 标准化接口,适合快速构建 |
根据具体需求选择合适的工具:如果项目需要快速实现复杂功能,推荐使用 ChatClient;如果需要更高的灵活性和控制力,则可以选择 ChatModel
引入多个ChatClient对象
单一应用中需使用多个聊天模型的典型场景包括:
- 不同任务类型选用不同模型(如复杂推理用高性能模型,简单任务用快速经济型模型)
- 主模型服务不可用时启用备用机制
- 不同模型或配置的 A/B 测试
- 根据用户偏好提供可选的模型
- 组合专用模型(如代码生成与创意内容分别使用不同模型)
Spring AI 默认自动配置单个 ChatClient.Builder Bean,但应用中可能需要使用多个聊天模型。处理方法如下:
所有场景均需通过设置属性 spring.ai.chat.client.enabled=false 来禁用 ChatClient.Builder 自动配置。
该设置允许手动创建多个 ChatClient 实例。
新建配置类
@Configuration
public class ChatClientConfig {@Bean("openAiChatClient")public ChatClient openAiChatClient(OpenAiChatModel openAiChatModel) {return ChatClient.create(openAiChatModel);}@Bean("deepSeekChatClient")public ChatClient deepSeekChatClient(DeepSeekChatModel deepSeekChatModel) {return ChatClient.create(deepSeekChatModel);}@Bean("ollamaChatClient")public ChatClient ollamaChatModel(OllamaChatModel ollamaChatModel) {return ChatClient.create(ollamaChatModel);}
}新建controller
@RestController
@RequestMapping("/client/ai")
public class ChatClientController {@Resourceprivate ChatClient openAiChatClient;@Resourceprivate ChatClient deepSeekChatClient;@Resourceprivate ChatClient ollamaChatClient;@GetMapping("/openai/chat")public String openAiChat() {Prompt prompt = new Prompt(new UserMessage("讲一个笑话"), new SystemMessage("你是一个物理家,名叫:章散") );return openAiChatClient.prompt(prompt).call().content();}
}流式响应
前面几个例子中都是同步响应,即将AI生成的内容一次性发送给客户端,这里就存在用户需要经历较长的空白等待,特别是AI处理复杂任务时(如生成万字报告、解析大型数据集)时,同步响应模式下用户需要等待很长时间才能看到响应,使用体验很差。
流式响应是将数据分批次、渐进式返回的模式,无需等待全部生成,可即时传输部分内容,优化体验与系统效率。在 AI 对话中能让用户即时看到生成内容,减少等待焦虑,可边看边调整需求,提升交互流畅度,还能降低系统瞬时资源占用,适配弱网环境。
借助Spring AI框架我们能轻松实现流式响应。
/*** 流式输出** @return the flux*/@GetMapping(value = "/deepseek/chat")public Flux<String> deepSeekChat() {Prompt prompt = new Prompt(new UserMessage("讲一个笑话"), new SystemMessage("你是一个物理家,名叫:里斯") );return deepSeekChatClient.prompt(prompt).stream().content();}在控制台使用curl访问接口能看到打字机输出效果

Prompt 模板
提示词模板是预设的、包含固定格式和可替换变量的文本框架,用于规范向 AI 提问的结构。
通过填充变量(如具体需求、场景细节等),能快速生成符合 AI 理解逻辑的提示词,减少重复编写成本,同时保证输出内容的一致性和准确性,适用于批量处理或标准化场景。
接下来演示将系统提示词中的什么什么家以及姓名使用占位符表示,然后通过调用时传入具体的值。
@GetMapping("/ollama/chat")public Flux<String> ollamaChat(String role,String name) {return ollamaChatClient.prompt().system(s -> s.text("你是一个{role},名叫:{name}").param("name", name).param("role", role)).user("讲一个笑话").stream().content();}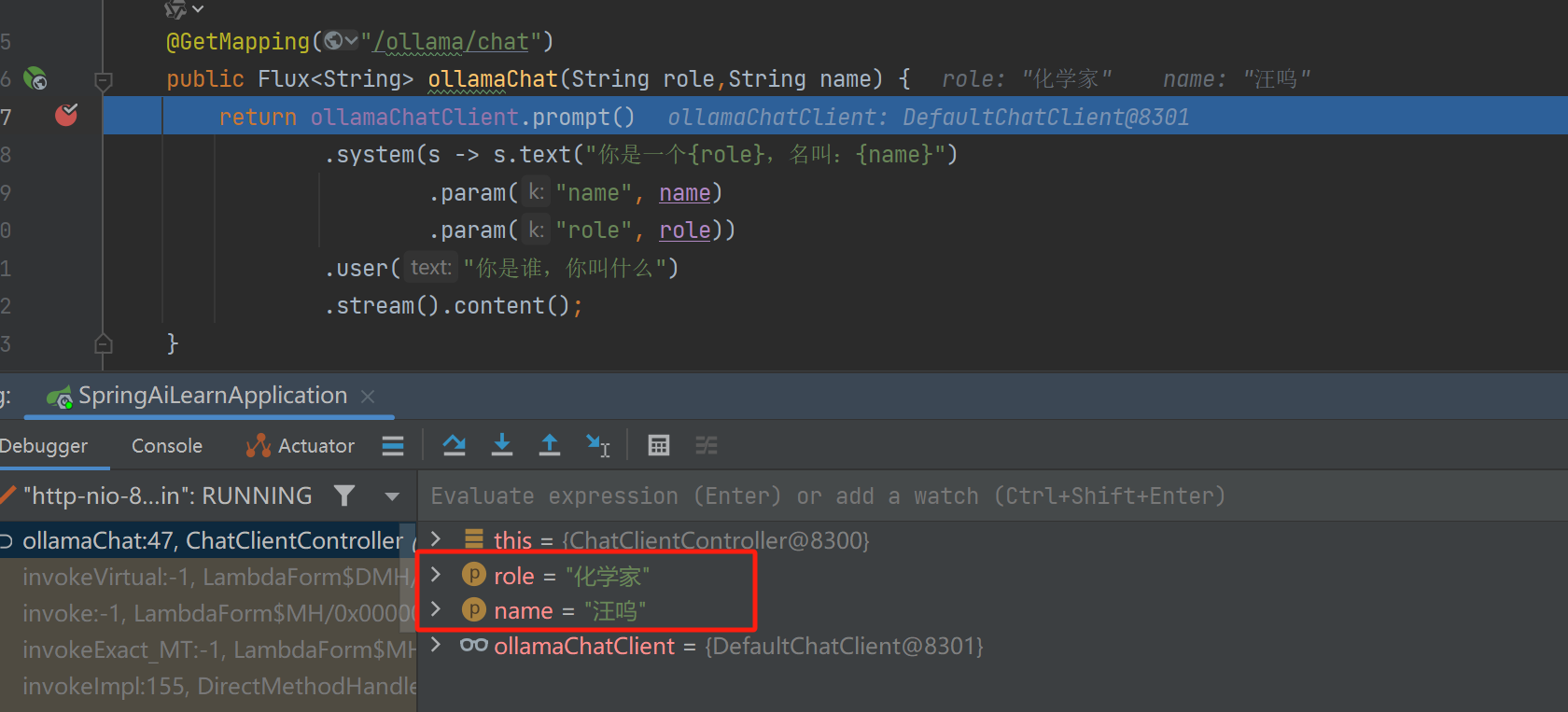

Advisor
Spring AI Advisor API 为拦截、修改和增强 Spring 应用中的 AI 交互提供了灵活强大的方式。通过该 API,开发者能构建更复杂、可复用且易维护的 AI 组件。
Spring Al 使用 Advisors(顾问)机制来增强 AI 的能力,可以理解为一系列可插拔的拦截器,在调用 AI 前和调用 AI 后可以执行一些额外的操作,比如:
- 前置增强:调用 Al 前改写一下 Prompt 提示词、检查一下提示词是否安全
- 后置增强:调用 AI后记录一下日志、处理一下返回的结果
用法很简单,我们可以直接为ChatClient指定默认拦截器,比如对话记忆拦截器MessageChatMemoryAdvisor可以帮助我们实现多轮对话,省去了自己维护对话列表的麻烦。
Advisor用法
var chatClient = ChatClient.builder(chatModel).defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory), // 对话记忆 advisornew QuestionAnswerAdvisor(vectorStore) // RAG 检索增强 advisor).build();String response = this.chatClient.prompt()// 对话时动态设定拦截器参数,比如指定对话记忆的 id 和长度.advisors(advisor -> advisor.param("chat_memory_conversation_id", "678").param("chat_memory_response_size", 100)).user(userText).call().content();
Advisor的原理
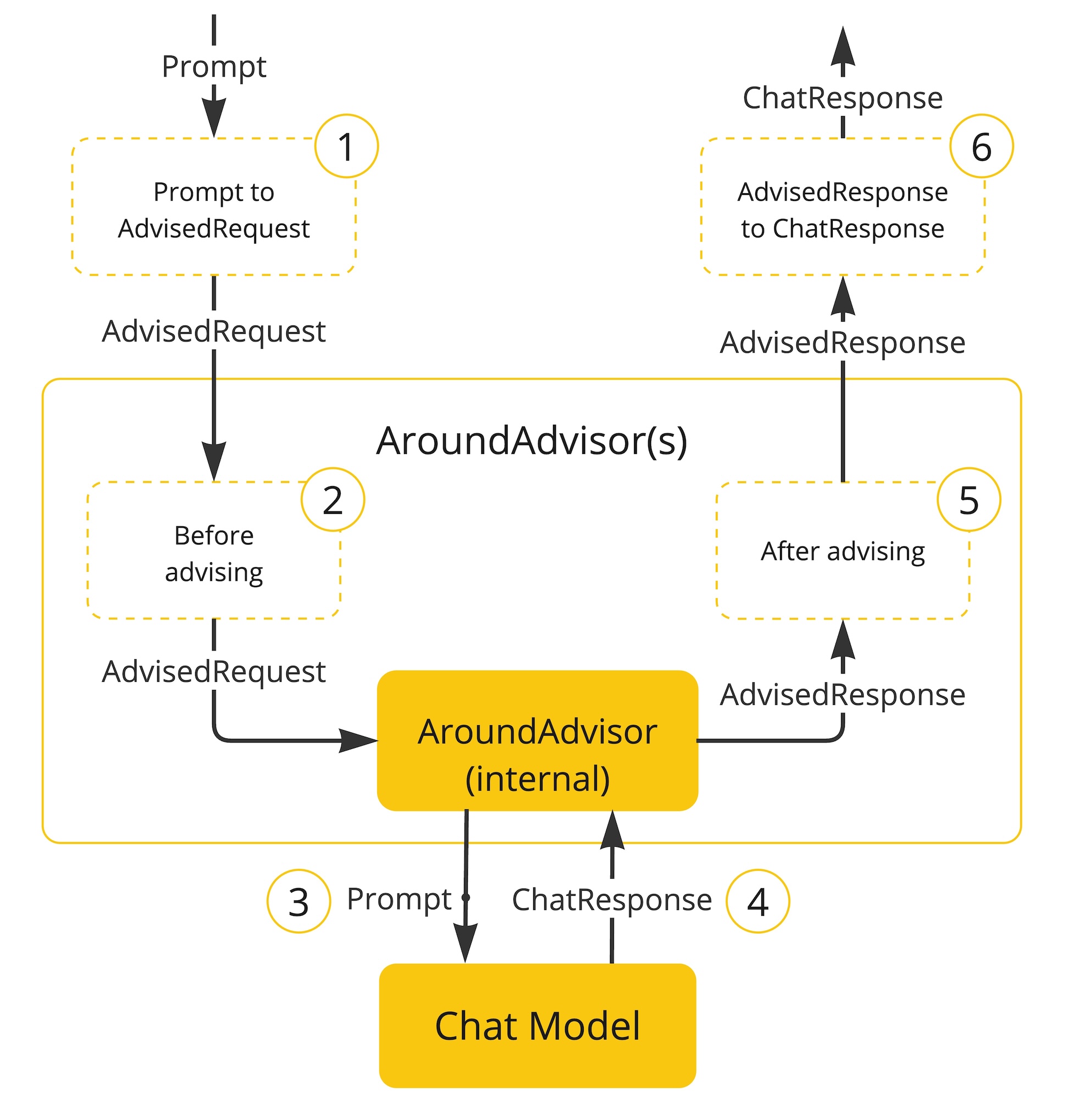
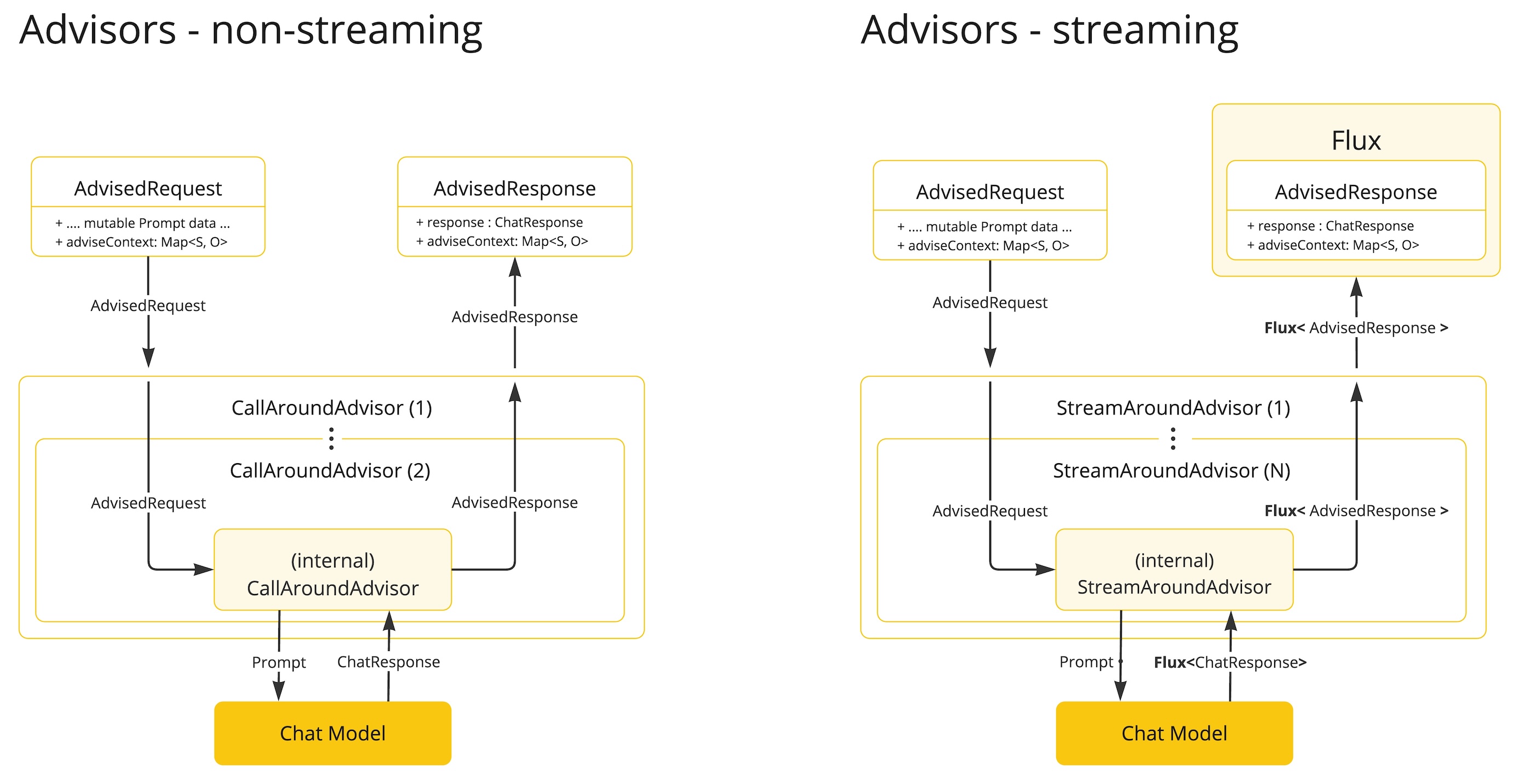
解释上图的执行流程:
- Spring AI 框架从用户的Prompt创建一个AdvisedRequest,同事创建一个空的AdvisorContext对象,用于传递信息。
- 链中的每一个Advisor处理这个请求,可能会对其进行修改。或者也可以选择不调用下一个实体来阻止请求继续传递,此时该Advisor负责填充响应内容。
- 由框架提供的最终Advisor将请求发送给聊天模型ChatModel。
- 聊天模型的响应随后通过Advisor链传回,并被转换为AdvisedResponse。后者包含了共享的AdvisorContext实例。
- 每个Advisor都可以处理或修改这个响应。
- 最终的AdvisedResponse通过提取ChatCompleton返回给客户端。
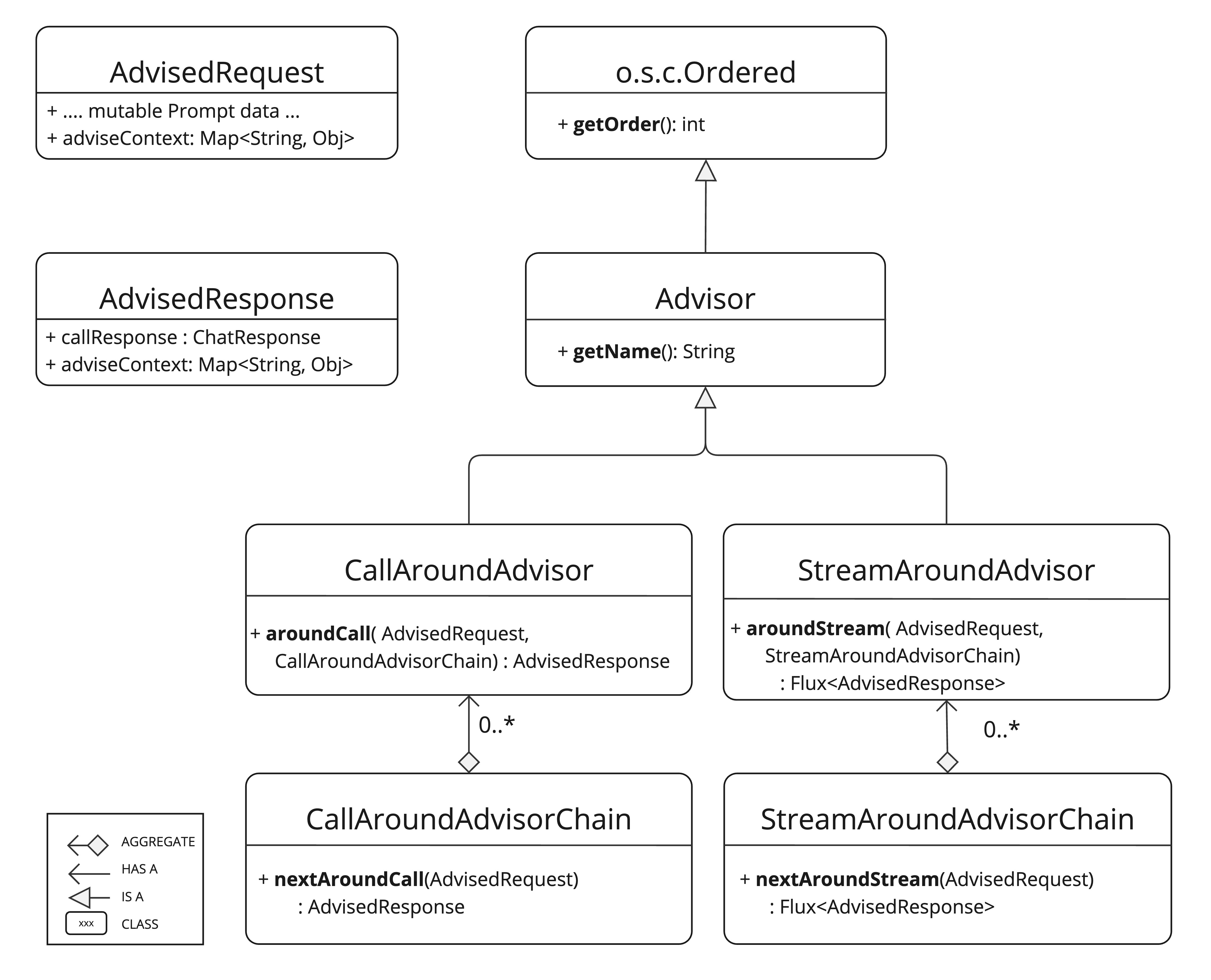
Advisor类图
Advisor执行顺序
链中 Advisor 的执行顺序由 getOrder() 方法决定。需要了解的要点:
- 数值越小的 Advisor 越优先执行。
- Advisor 链采用栈式结构运作:
-
- 链首 Advisor 最先处理请求。
- 同时也是最后处理响应的环节。
- 控制执行顺序:
-
- 将
order值设为接近Ordered.HIGHEST_PRECEDENCE可确保 Advisor 优先执行(请求处理时最先触发,响应处理时最后触发)。 - 将
order值设为接近Ordered.LOWEST_PRECEDENCE可确保 Advisor 最后执行(请求处理时最后触发,响应处理时最先触发)。
- 将
- 数值越大表示优先级越低。
- 若多个 Advisor 的
order值相同,其执行顺序无法保证。
Advisor两种模式
从类图中我们发现,Advisors 分为2种模式:流式 Streaming 和非流式 Non-Streaming,二者在用法上没有明显的区别,返回值不同罢了。但是如果我们要自主实现 Advisors,为了保证通用性,最好还是同时实现流式和非流式的环绕通知方法。
自定义Advisor
参考Spring AI官方实现一个日志打印的Advisor
新建MySimpleLogAdvisor
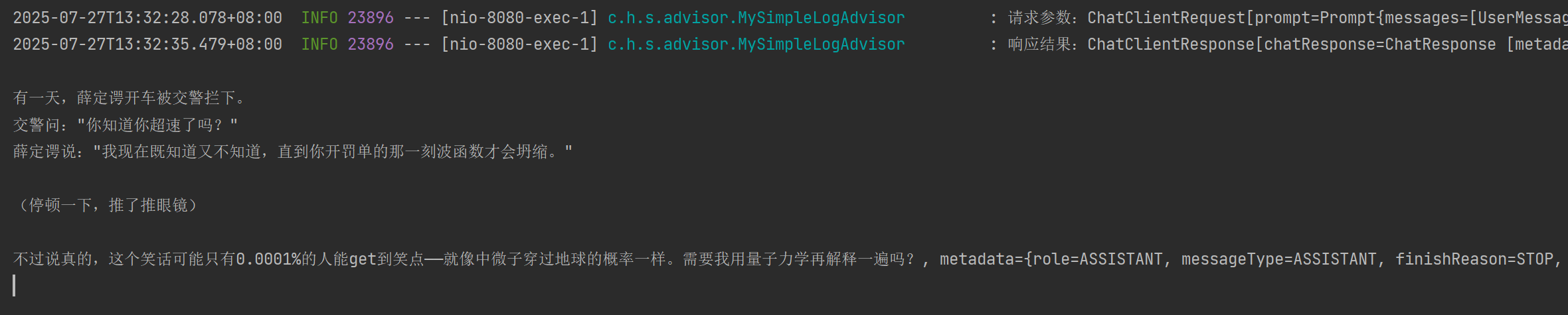
@Slf4j
public class MySimpleLogAdvisor implements CallAdvisor, StreamAdvisor {@Overridepublic ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {log.info("请求参数:{}", chatClientRequest);ChatClientResponse response = callAdvisorChain.nextCall(chatClientRequest);log.info("响应结果:{}", response);return response;}@Overridepublic Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain streamAdvisorChain) {log.info("请求参数:{}", chatClientRequest);Flux<ChatClientResponse> responses = streamAdvisorChain.nextStream(chatClientRequest);return new ChatClientMessageAggregator().aggregateChatClientResponse(responses, response -> log.info("响应结果:{}", response));}@Overridepublic String getName() {return MySimpleLogAdvisor.class.getName();}@Overridepublic int getOrder() {return 0;}
}应用MySimpleLogAdvisor
@GetMapping("/openai/chat")public String openAiChat() {Prompt prompt = new Prompt(new UserMessage("讲一个笑话"), new SystemMessage("你是一个物理家,名叫:章散") );return openAiChatClient.prompt(prompt).advisors(new MySimpleLogAdvisor()).call().content();}效果
对话记忆
大语言模型(LLM)本质上是无状态的,这意味着它们不会保留历史交互信息。当需要跨多轮交互保持上下文时,这一特性会带来局限。为此,Spring AI 提供了聊天记忆功能,支持在 LLM 交互过程中存储和检索上下文数据。
ChatMemory 抽象层支持实现多种记忆类型以满足不同场景需求。消息的底层存储由 ChatMemoryRepository 处理,其唯一职责是存储和检索消息。 ChatMemory 实现类可自主决定消息保留策略 — 例如保留最近 N 条消息、按时间周期保留或基于 Token 总量限制保留。
MessageWindowChatMemory
MessageWindowChatMemory 维护固定容量的消息窗口(默认 20 条)。当消息超限时,自动移除较早的对话消息(始终保留系统消息)。
//保留最近两条聊天记录MessageWindowChatMemory memory = MessageWindowChatMemory.builder().maxMessages(3).build();@GetMapping("/memory/chat")public String memoryChat(String message,String chatId) {//chatId用来标识聊天记录属于谁的和AI的UserMessage userMessage = new UserMessage(message);memory.add(chatId,userMessage);ChatResponse chatResponse = deepSeekChatClient.prompt(new Prompt(memory.get(chatId))).call().chatResponse();memory.add(chatId,chatResponse.getResult().getOutput());return chatResponse.getResult().getOutput().getText();}第一次对话告诉AI我叫什么

第二次对话问AI我的叫什么

从回答可以看出来AI已经记住了我叫张三,实现的原理就是memory记录着最近三条我和AI的聊天记录,当我问AI我叫什么时会从memory中取出聊天记录一起发送给AI其中就包括我之前告诉AI我叫张三的记录。但是如果连续对话多次再问AI我叫啥时此时AI就不知道了。

MessageChatMemoryAdvisor
从上面的例子可以发现,实现聊条记忆的核心就将历史对话保存起来,在新的对话中一并发送给AI,这里需要我们手动保存聊天记录,对话之前保存用户消息,AI响应后保存AI消息。
还记前面提到的Advisor吗,它作用就是在对话之前和响应之后做相应的处理,所以这里可以将聊天记录的保存交给Advisor来处理。
@GetMapping("/memory/chat")public String memoryChat(String message,String chatId) {ChatResponse chatResponse = deepSeekChatClient.prompt(message).advisors(MessageChatMemoryAdvisor.builder(memory).build()).advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId)).call().chatResponse();return chatResponse.getResult().getOutput().getText();}记忆存储
Spring AI 通过 ChatMemoryRepository 抽象层实现聊天记忆存储。
内存Repository
InMemoryChatMemoryRepository 基于 ConcurrentHashMap 实现内存存储。
默认情况下,若未配置其他 Repository,Spring AI 将自动配置 InMemoryChatMemoryRepository 类型的 ChatMemoryRepository Bean供直接使用。
上面在构建MessageWindowChatMemory时并没有指定Repository,所以Spring AI会自动使用InMemoryChatMemoryRepository 将记忆保存在内存中,记忆保存在内存中,当项目重启时记忆就会丢失。

JdbcChatMemoryRepository
JdbcChatMemoryRepository 是内置的 JDBC 实现,支持多种关系型数据库,适用于需要持久化存储聊天记忆的场景。
CassandraChatMemoryRepository
CassandraChatMemoryRepository 基于 Apache Cassandra 实现消息存储,适用于需要高可用、持久化、可扩展及利用 TTL 特性的聊天记忆持久化场景。
CassandraChatMemoryRepository 采用时间序列 Schema,完整记录历史聊天窗口,对合规审计极具价值。建议设置生存时间(如三年)。
Neo4jChatMemoryRepository
Neo4jChatMemoryRepository 是内置实现,利用 Neo4j 将聊天消息存储为属性图中的节点与关系,适用于需发挥 Neo4j 图数据库特性的聊天记忆持久化场景。
结构化响应
结构化输出转换器(Structured Output Converter)是 Spring Al 提供的一种实用机制,用于将大语言模型返回的文本输出转换为结构化数据格式,如 JSON、XML 或 Java 类,这对于需要可靠解析 A 输出值的下游应用程序非常重要。
基本原理-工作流程
结构化输出转换器在大模型调用前后都发挥作用:
- 调用前:转换器会在提示词后面附加格式指令,明确告诉模型应该生成何种结构的输出,引导模型生成符合指定格式的响应。
- 调用后:转换器将模型的文本输出转换为结构化类型的实例,比如将原始文本映射为 JSON、XML 或特定的数据结构。
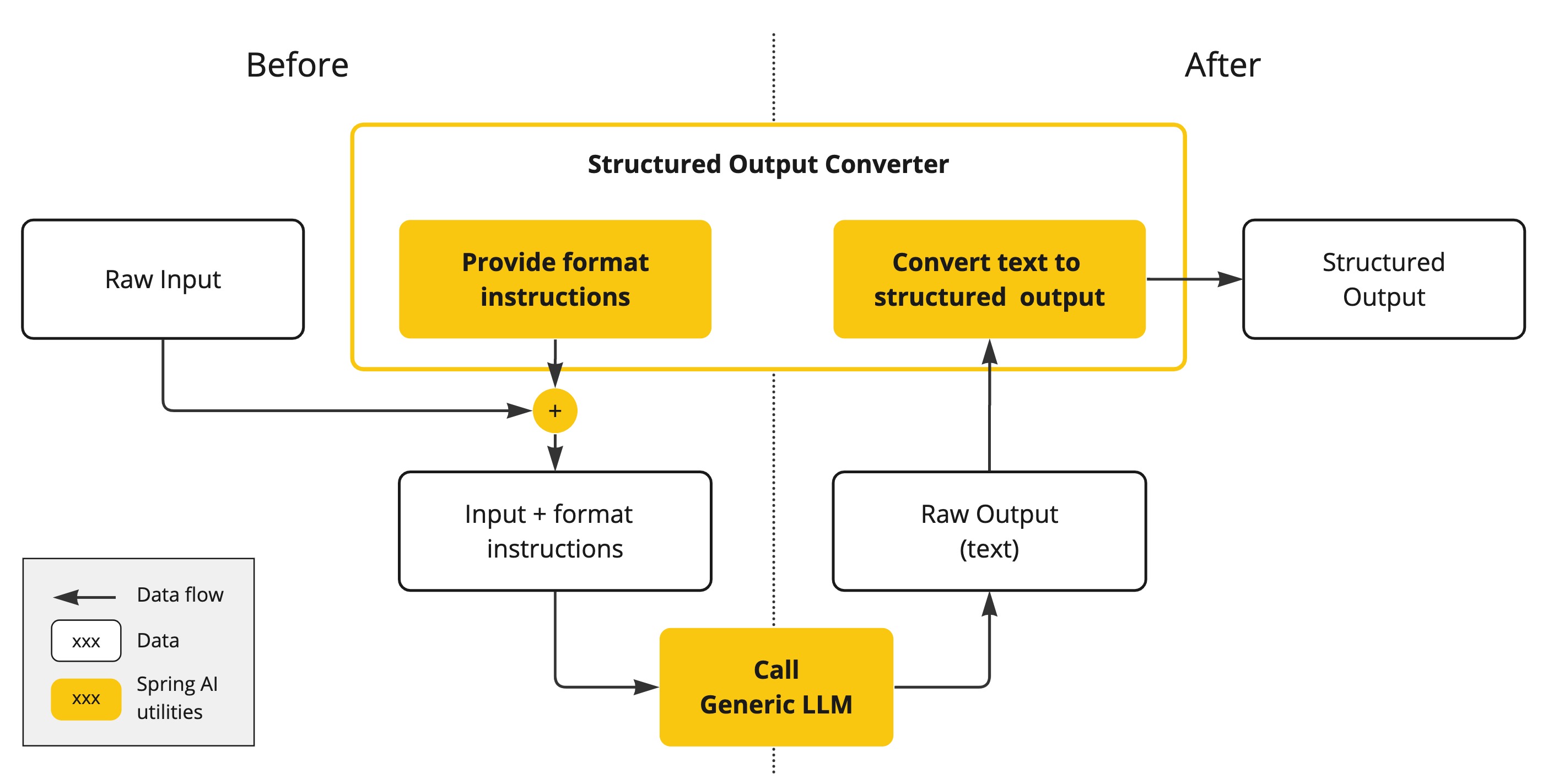
使用通用补全 API 从大语言模型(LLM)生成结构化输出需谨慎处理输入输出。结构化输出转换器在 LLM 调用前后起关键作用,确保获得预期输出结构。
在 LLM 调用前,转换器向提示词追加格式指令,为模型生成预期输出结构提供明确指导。这些指令作为蓝图,引导模型响应符合指定格式。
LLM 调用后,转换器(Converter)将模型的原始文本输出转换为结构化类型实例。该转换过程包括解析原始文本输出,并将其映射 为JSON、XML 或领域特定数据结构等对应的结构化数据表示。
注意,结构化输出转换器只是 尽最大努力 将模型输出转换为结构化数据,AI模型不保证一定按照要求返回结构化输出。有些模型可能无法理解提示词或无法按要求生成结构化输出。建议在程序中实现验证机制或者异常处理机制来确保模型输出符合预期。
可用的转换器
目前 Spring AI 提供以下实现:AbstractConversionServiceOutputConverter、AbstractMessageOutputConverter、BeanOutputConverter、MapOutputConverter和ListOutputConverter。
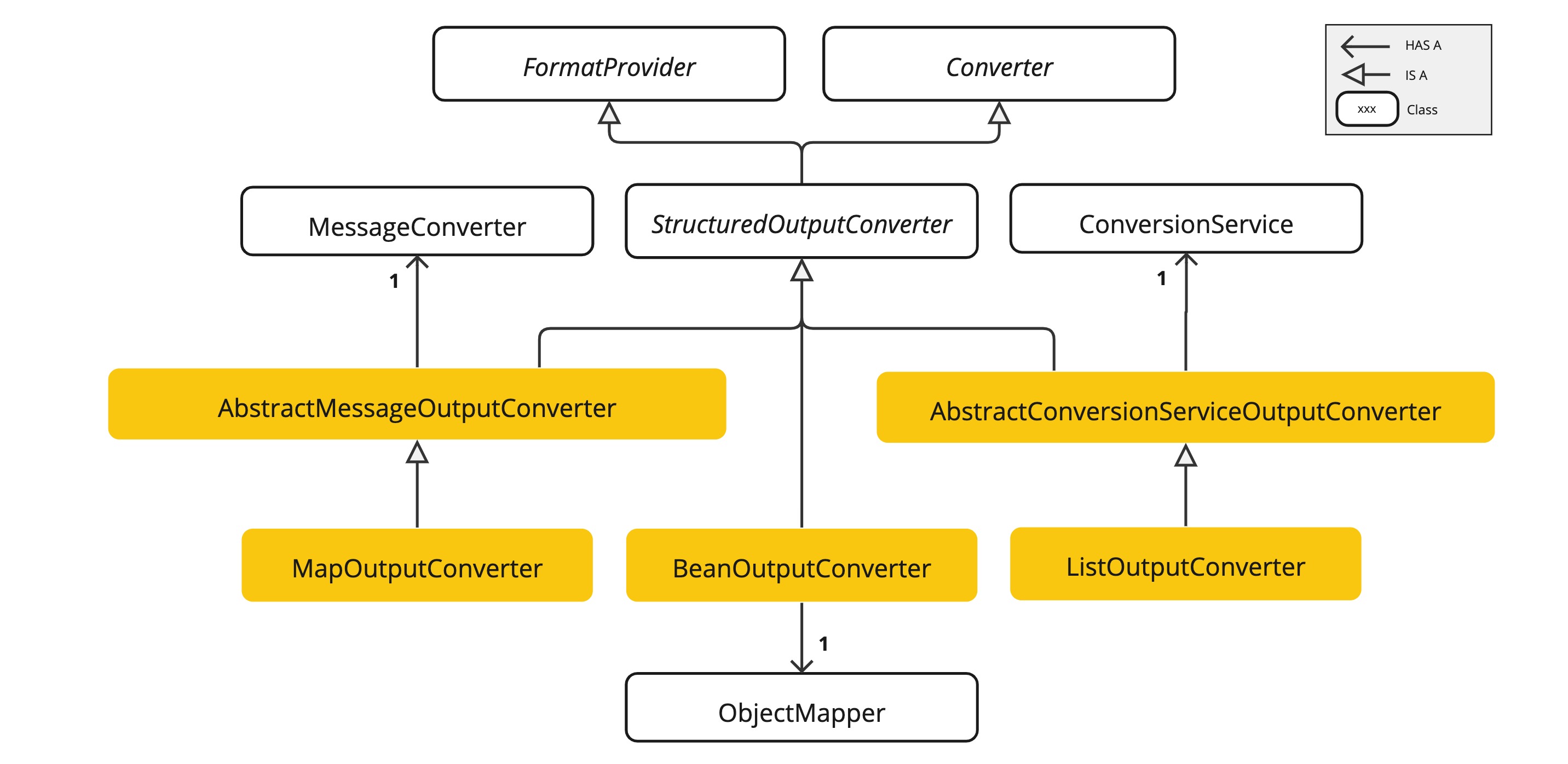
AbstractConversionServiceOutputConverter<T>- 提供预配置的GenericConversionService用于将 LLM 输出转换为目标格式,未提供默认FormatProvider实现。AbstractMessageOutputConverter<T>- 提供预配置的MessageConverter用于将 LLM 输出转换为目标格式,未提供默认FormatProvider实现。BeanOutputConverter<T>-BeanOutputConverter<T>:通过配置 Java 类或ParameterizedTypeReference,该转换器(Converter)使用FormatProvider实现指导 AI 模型生成符合DRAFT_2020_12、JSON Schema的响应(基于指定 Java 类生成),随后用ObjectMapper将 JSON 输出反序列化为目标类的 Java 对象实例。MapOutputConverter- 继承AbstractMessageOutputConverter的功能,通过FormatProvider实现引导 AI 模型生成符合 RFC8259 标准的 JSON 响应,并利用提供的MessageConverter将 JSON Payload 转换为java.util.Map<String, Object>实例。ListOutputConverter- 继承AbstractConversionServiceOutputConverter,包含专为逗号分隔列表输出定制的FormatProvider实现。该转换器利用提供的ConversionService将模型文本输出转换为java.util.List。
示例
BeanOutputConverter示例,将AI输出转换为自定义Java类
新建record
public record ActorsFilms(String actor, List<String> movies) {}编写controller
@GetMapping("/converter/chat")public void converterChat() {ActorsFilms actorsFilms = deepSeekChatClient.prompt().user(u -> u.text("生成5部{actor}主演的电影").param("actor", "成龙")).call().entity(ActorsFilms.class);System.out.println(actorsFilms);}输出

使用ParameterizedTypeReference 构造函数指定更复杂的目标类结构。例如,表示演员及其作品表的列表
List<ActorsFilms> actorsFilmsList = deepSeekChatClient.prompt().user("分别生成由成龙,李连杰,周润发主演的5部电影").call().entity(new ParameterizedTypeReference<List<ActorsFilms>>() {});log.info("列表结果:{}", actorsFilmsList);
工具调用
工具调用(亦称函数调用)是 AI 应用的常见模式,允许模型通过与一组 API(即工具)交互来扩展其能力。
工具主要应用于以下场景:
- 信息检索。此类工具可用于从外部源检索信息,例如数据库、网络服务、文件系统或网络搜索引擎。其目的是增强模型的知识,使其能够回答原本无法回答的问题。因此,它们可用于检索增强生成(RAG)场景。例如,可以使用工具检索给定位置的当前天气、检索最新新闻文章或查询数据库中的特定记录。
- 执行操作。此类工具可用于在软件系统中执行操作,例如发送电子邮件、在数据库中创建新记录、提交表单或触发工作流。其目的是自动化那些原本需要人工干预或显式编程的任务。例如,可以使用工具为与聊天机器人交互的客户预订航班、填写网页上的表单,或在代码生成场景中基于自动化测试(TDD)实现 Java 类。
尽管我们通常将工具调用称为模型能力,但实际上工具调用逻辑是由客户端应用程序提供的。模型只能请求工具调用并提供输入参数,而应用程序负责根据输入参数执行工具调用并返回结果。模型永远无法访问作为工具提供的任何 API,这是一个关键的安全考量。
Spring AI 提供了便捷的 API 来定义工具、解析模型的工具调用请求以及执行工具调用。
示例
面我们在 DateTimeTools 类中实现一个获取用户所在时区当前日期时间的工具。该工具将不接收任何参数,通过 Spring Framework 的 LocaleContextHolder 获取用户时区信息。我们将使用 @Tool 注解来定义这个工具方法,并通过详细的工具描述帮助模型理解是否及何时调用该工具。
第一步定义工具
public class DateTimeTools {@Tool(description = "Get the current date and time in the user's timezone")String getCurrentDateTime() {return LocalDateTime.now().atZone(LocaleContextHolder.getTimeZone().toZoneId()).toString();}
}第二步使用工具
@GetMapping("/tools/chat")public void toolsChat() {String response = openAiChatClient.prompt("What day is tomorrow?").tools(new DateTimeTools()).call().content();System.out.println(response);}
把工具去掉在试试
public void toolsChat() {String response = openAiChatClient.prompt("What day is tomorrow?").call().content();System.out.println(response);}
此时模型就回答不出明天是几月几号了。
实现原理
其实,工具调用的工作原理非常简单,并不是 AI服务器自己调用这些工具、也不是把工具的代码发送给 AI服务器让它执行,它只能提出要求,表示“我需要执行 XX工具完成任务”。而真正执行工具的是我们自己的应用程序,执行后再把结果告诉 AI,让它继续工作。
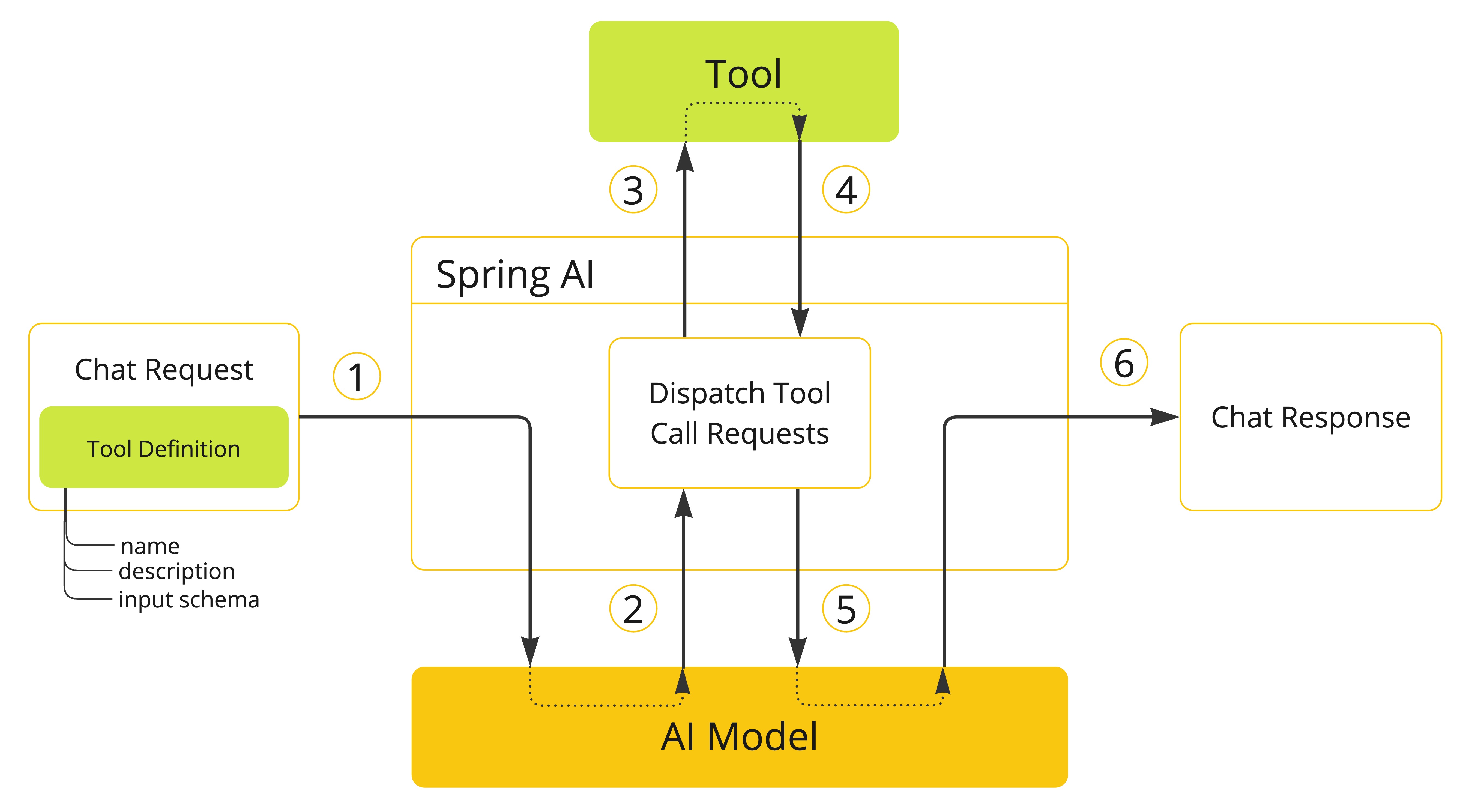
- 当我们想让模型使用某个工具时,我们会在聊天请求中包含该工具的定义。每个工具的定义都包括名称、描述和输入参数的模式。
- 当模型决定调用工具时,它会发送包含工具名称及符合预定义模式的输入参数的响应。
- 应用程序负责根据工具名称识别对应工具,并使用提供的输入参数执行该工具。
- 工具调用的结果由应用程序进行处理。
- 应用程序将工具调用结果返回至模型。
- 模型最终利用工具调用结果作为附加上下文生成响应。
工具定义模式
在 Spring Al中,定义工具主要有两种模式: 声明式和编程式
声明式: 你只需为方法添加 @Tool 注解,即可将其转换为工具。
class WeatherTools {@Tool(description = "Get current weather for a location")public String getWeather(@ToolParam(description = "The city name") String city) {return "Current weather in " + city + ": Sunny, 25°C";}
}// 使用方式
ChatClient.create(chatModel).prompt("What's the weather in Beijing?").tools(new WeatherTools()).call();
@Tool 注解允许你配置以下关键工具信息:
name:工具名称。若不指定,默认使用方法名称。AI 模型通过此名称识别调用工具,因此不允许在同一类中存在同名工具。模型处理单个聊天请求时,所有可用工具的名称必须保持全局唯一。description:工具描述,用于指导模型判断何时及如何调用该工具。若未指定,默认使用方法名称作为工具描述。但强烈建议提供详细描述,因为这对模型理解工具用途和使用方式至关重要。若描述不充分,可能导致模型在该调用工具时未调用,或错误调用工具。returnDirect:控制工具结果直接返回客户端(true)还是传回模型(false)。resultConverter:用于将工具调用结果转换为字符串对象的ToolCallResultConverter实现,该字符串将返回至 AI 模型。
该方法既可以是静态方法也可以是实例方法,并且可具有任意可见性(public、protected、package-private 或 private)。包含该方法的类既可以是顶级类也可以是嵌套类,同样支持任意可见性(只要在计划实例化的位置可访问即可)。
你可以为方法定义任意数量的参数(包括无参数),支持大多数类型(基本类型、POJO、枚举、List、数组、Map 等)。同样,方法可以返回大多数类型,包括 void。若方法有返回值,则返回类型必须是可序列化类型,因为结果将被序列化并发送回模型。
Spring AI 将自动为 @Tool 注解方法的输入参数生成 JSON Schema。该 Schema 供模型理解如何调用工具及准备工具请求。你可使用 @ToolParam 注解为输入参数提供额外信息(如描述、是否必需等),默认情况下所有输入参数均为必需参数。
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;class DateTimeTools {@Tool(description = "Set a user alarm for the given time")void setAlarm(@ToolParam(description = "Time in ISO-8601 format") String time) {LocalDateTime alarmTime = LocalDateTime.parse(time, DateTimeFormatter.ISO_DATE_TIME);System.out.println("Alarm set for " + alarmTime);}}@ToolParam 注解允许你配置工具参数的关键信息:
description:参数描述,用于帮助模型更准确地理解如何使用该参数。例如:参数格式要求、允许取值范围等。required:指定参数是否为必需项(默认值:true,即所有参数默认必需)。
编程式:你可以通过编程式构建 MethodToolCallback 来将方法转换为工具。
class WeatherTools {String getWeather(String city) {// 获取天气的实现逻辑return "北京今天晴朗,气温25°C";}
}
然后将工具类转换为 ToolICallback 工具定义类,之后就可以把这个类绑定给 ChatClient,从而让 AI 使用工具了。
Method method = ReflectionUtils.findMethod(WeatherTools.class, "getWeather", String.class);
ToolCallback toolCallback = MethodToolCallback.builder().toolDefinition(ToolDefinition.builder(method).description("获取指定城市的当前天气情况").build()).toolMethod(method).toolObject(new WeatherTools()).build();
编程式就是把注解式的那些参数,改成通过调用方法来设置了而已。
使用工具
定义好工具后,Spring Al 提供了多种灵活的方式将工具提供给 ChatCient,让 AI 能够在需要时调用这些工具。
1)按需使用:这是最简单的方式,直接在构建 ChatClient 请求时通过 tools()方法附加工具。这种方式适合只在特定对话中使用某些工具的场景。
String response = ChatClient.create(chatModel).prompt("北京今天天气怎么样?").tools(new WeatherTools()) // 在这次对话中提供天气工具.call().content();
2)全局使用:如果某些工具需要在所有对话中都可用,可以在构建 Chatcient 时注册默认工具。这样,这些工具将对从同一个 Chatclient 发起的所有对话可用。
ChatClient chatClient = ChatClient.builder(chatModel).defaultTools(new WeatherTools(), new TimeTools()) // 注册默认工具.build();
3)更底层的使用方式:除了给 ChatClient 绑定工具外,也可以给更底层的 ChatModel 绑定工具(毕竟工具调用是 AI大模型支持的能力),适合需要更精细控制的场景。
// 先得到工具对象
ToolCallback[] weatherTools = ToolCallbacks.from(new WeatherTools());
// 绑定工具到对话
ChatOptions chatOptions = ToolCallingChatOptions.builder().toolCallbacks(weatherTools).build();
// 构造 Prompt 时指定对话选项
Prompt prompt = new Prompt("北京今天天气怎么样?", chatOptions);
chatModel.call(prompt);
4)动态解析:一般情况下,使用前面3种方式即可。对于更复杂的应用,Spring Al还支持通过 ToolcallbackResolver在运行时动态解析工具。这种方式特别适合工具需要根据上下文动态确定的场景,比如从数据库中根据工具名搜索要调用的工具。
其他高级功能
除了上面介绍的功能外,Spring AI框架还支持许多其他高级特性:RAG(检索增强生成),MCP(模型上下文协议),向量数据库等。
笔记中对应的代码均已上传至代码仓库点击链接获取