MySQL - 主从复制与读写分离
主从复制
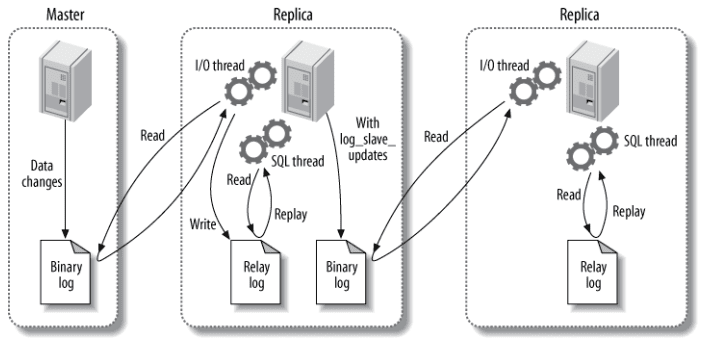
1. 主从复制的三个核心线程
(1)主库的 binlog 线程(Binlog Dump Thread)
- 职责:
当主库(Master)的数据发生变更(如 INSERT/UPDATE/DELETE)时,binlog 线程负责将这些变更事件写入二进制日志(Binary Log,即 binlog)。 - 关键点:
- 每个主库只会为每个连接的从库创建一个 binlog 线程(而非全局唯一)。
- 线程名称示例:
Binlog Dump GTID(MySQL 5.6+ 支持 GTID 时)。
(2)从库的 I/O 线程(Slave I/O Thread)
- 职责:
- 连接到主库,请求 binlog 事件(从上次复制的位置或 GTID 开始)。
- 将获取的 binlog 事件写入从库的中继日志(Relay Log)。
- 关键点:
- I/O 线程是从库主动拉取主库的 binlog,而非主库推送。
- 网络中断时,I/O 线程会尝试重连主库。
- 线程状态查看:
SHOW SLAVE STATUS\G
-- 输出中的 Slave_IO_Running: Yes/No 表示 I/O 线程状态(3)从库的 SQL 线程(Slave SQL Thread)
- 职责:
- 读取中继日志中的事件。
- **重放(Replay)**这些事件(即执行对应的 SQL 或行变更操作)。
- 关键点:
- 默认情况下,SQL 线程是单线程的(可能导致复制延迟,MySQL 5.6+ 支持多线程复制)。
- 重放时会模拟主库的事务环境(如相同的
server_id和thread_id)。
- 线程状态查看:
SHOW SLAVE STATUS\G
-- 输出中的 Slave_SQL_Running: Yes/No 表示 SQL 线程状态2. 主从复制的完整流程
- 主库数据变更:
- 事务提交时,存储引擎(如 InnoDB)将变更写入 binlog。
- binlog 线程发送事件:
- 主库的 binlog 线程将 binlog 事件发送给从库的 I/O 线程。
- 从库写入中继日志:
- 从库的 I/O 线程将事件写入中继日志(
relay-log.xxxxxx)。
- 从库的 I/O 线程将事件写入中继日志(
- 从库重放事件:
- SQL 线程从中继日志读取事件并执行,应用数据变更。
3. 知识点补充
- binlog 的生成:
- binlog 由主库的事务提交过程生成(通过
sync_binlog参数控制刷盘策略)。
- binlog 由主库的事务提交过程生成(通过
- GTID 复制(MySQL 5.6+):
- 使用全局事务 ID(GTID)替代传统的 binlog 文件名和位置,简化故障恢复。
- 多线程复制(MySQL 5.6+):
- 从库的 SQL 线程可拆分为多个 worker 线程(通过
slave_parallel_workers配置),提升复制性能。
- 从库的 SQL 线程可拆分为多个 worker 线程(通过
4. 主从复制的线程模型(图示)
主库(Master) 从库(Slave)
+-------------------+ +-------------------+
| | | |
| 1. 事务提交写入 | | |
| binlog | | |
| | | |
| 2. Binlog Dump | <-------> | 3. I/O Thread |
| Thread | (网络) | (拉取 binlog) |
| | | |
| | | 4. 写入 Relay Log |
| | | |
| | | 5. SQL Thread |
| | | (重放事件) |
+-------------------+ +-------------------+5. 常见问题排查
(1)复制延迟(Replication Lag)
- 原因:
- 主库写入压力大,从库 SQL 线程单线程重放跟不上。
- 从库机器性能不足(如磁盘 I/O 慢)。
- 解决方案:
- 启用多线程复制(
slave_parallel_workers > 1)。 - 升级从库硬件或优化主库写入(如批量插入)。
- 启用多线程复制(
(2)复制中断
- 常见错误:
Duplicate entry(主键冲突):从库数据被手动修改,与主库不一致。Could not execute Write_rows event:从库缺少某行数据。
- 修复方法:
- 跳过错误(临时):
SET GLOBAL sql_slave_skip_counter = 1;
START SLAVE;- 重建一致性:通过
mysqldump或xtrabackup重新同步从库。
- 重建一致性:通过
6. 总结
- 主库线程:
- Binlog Dump Thread:向从库发送 binlog 事件(每个从库连接一个线程)。
- 从库线程:
- I/O Thread:拉取 binlog 并写入中继日志。
- SQL Thread:重放中继日志中的事件(默认单线程)。
- 注意:
- binlog 由主库事务提交生成,binlog 线程仅负责发送。
- 从库是主动拉取(Pull)模式,而非主库推送(Push)。
通过理解这些线程的协作机制,可以更好地优化和排查主从复制问题。
读写分离
主服务器处理写操作以及实时性要求比较高的读操作,而从服务器处理读操作。
读写分离能提高性能的原因在于:
- 主从服务器负责各自的读和写,极大程度缓解了锁的争用;
- 从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
- 增加冗余,提高可用性。
读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。
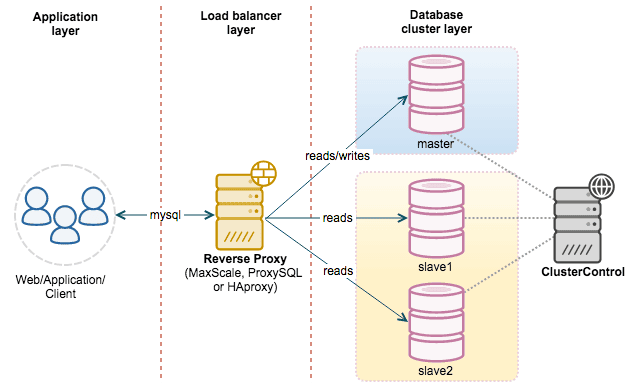
一、读写分离基本概念
读写分离(Read/Write Splitting)是MySQL数据库架构优化的一种常见方式,其核心思想是将数据库的读操作和写操作分离到不同的服务器上处理。
1.1 基本架构
典型的MySQL读写分离架构包含以下组件:
- 主服务器(Master):负责处理所有写操作(INSERT、UPDATE、DELETE等)和部分实时性要求高的读操作
- 从服务器(Slave):负责处理大部分读操作(SELECT),通常配置多个从库以分担读负载
- 代理层:负责将应用请求路由到正确的服务器(主库或从库)
二、读写分离的工作原理
2.1 主从复制机制
读写分离的基础是MySQL的主从复制(Replication)功能:
- 主库记录所有数据变更到二进制日志(binlog)
- 从库的I/O线程从主库拉取binlog并写入中继日志(relay log)
- 从库的SQL线程重放中继日志中的事件,保持与主库数据同步
2.2 读写请求路由
读写分离的核心是请求路由机制:
- 写请求:所有写操作必须发送到主库
- 读请求:可以分发到任意从库
- 特殊读请求:需要强一致性的读请求应发送到主库
三、实现读写分离的常见方案
3.1 基于中间件实现
3.1.1 专用代理服务器
- MySQL Router:MySQL官方提供的轻量级中间件
- ProxySQL:高性能MySQL代理,支持灵活的读写分离规则
- MaxScale:MariaDB提供的数据库代理
3.1.2 配置示例(ProxySQL)
-- 添加服务器
INSERT INTO mysql_servers(hostgroup_id,hostname,port) VALUES
(10,'master',3306), -- 主库hostgroup=10
(20,'slave1',3306), -- 从库hostgroup=20
(20,'slave2',3306); -- 从库hostgroup=20-- 配置读写分离规则
INSERT INTO mysql_query_rules (rule_id,active,match_pattern,destination_hostgroup,apply) VALUES
(1,1,'^SELECT.*FOR UPDATE',10,1), -- SELECT FOR UPDATE 发送到主库
(2,1,'^SELECT',20,1), -- 普通SELECT发送到从库
(3,1,'^INSERT',10,1), -- 写操作发送到主库
(4,1,'^UPDATE',10,1),
(5,1,'^DELETE',10,1);3.2 基于客户端实现
3.2.1 框架集成方案
- ShardingSphere-JDBC:在应用层实现读写分离
- MyBatis插件:自定义拦截器实现读写分离
3.2.2 代码示例(Spring Boot + ShardingSphere)
# application.yml
spring:shardingsphere:datasource:names: master,slave0,slave1master:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://master:3306/dbusername: rootpassword: passwordslave0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://slave0:3306/dbusername: rootpassword: passwordslave1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://slave1:3306/dbusername: rootpassword: passwordmasterslave:load-balance-algorithm-type: round_robinname: msmaster-data-source-name: masterslave-data-source-names: slave0,slave1props:sql.show: true四、读写分离的优势
4.1 性能提升
- 减轻主库负载:将读压力分散到多个从库
- 提高并发能力:多台服务器并行处理请求
- 优化资源利用:主库专注写操作,从库专注读操作
4.2 高可用性
- 故障转移:主库故障时可提升从库为主库
- 负载均衡:多个从库分担读请求
- 容灾备份:从库可作为数据备份
五、读写分离的挑战与解决方案
5.1 主从延迟问题
问题描述
从库数据同步存在延迟,可能导致读取到过期数据
解决方案
- 强制读主库:对一致性要求高的查询指定走主库
// Spring注解方式,作用是 强制该查询操作走主库(Master)
@Transactional(readOnly = false)
public User getCurrentUser(Long id) {return userRepository.findById(id);
}- 半同步复制:确保至少一个从库接收数据后才返回成功
-- 主库配置
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
SET GLOBAL rpl_semi_sync_master_enabled = 1;- 延迟监控:实时监控Seconds_Behind_Master指标
SHOW SLAVE STATUS\G5.2 事务一致性
问题描述
跨主从库的事务难以保证一致性
解决方案
- 事务内强制读主库
@Transactional
public void updateAndQuery(User user) {userRepository.update(user); // 写操作// 事务内查询自动走主库User updated = userRepository.findById(user.getId());
}- 使用分布式事务(XA)
XA START 'transaction1';
UPDATE account SET balance = balance - 100 WHERE id = 1;
XA END 'transaction1';
XA PREPARE 'transaction1';
XA COMMIT 'transaction1';六、最佳实践建议
6.1 部署建议
- 从库数量:根据读负载配置足够数量的从库(通常3-5个)
- 硬件配置:从库配置可与主库不同(如更大的内存用于缓存)
- 网络优化:确保主从之间网络延迟低
6.2 监控指标
- 复制延迟:
Seconds_Behind_Master - 从库负载:QPS、CPU使用率、IO等待
- 代理层状态:连接数、请求分发情况
6.3 故障处理
- 从库故障:自动从负载均衡池中移除
- 主库故障:快速故障转移(需配合VIP或DNS切换)
- 代理层故障:部署多节点+Keepalived实现高可用
七、读写分离适用场景
7.1 适合场景
- 读多写少:如内容网站、电商商品页
- 报表查询:大量分析查询可分流到专用从库
- 地理分布式:不同地区访问最近的从库
7.2 不适合场景
- 强一致性要求高:如金融交易系统
- 写密集:如高频交易系统
- 简单应用:低流量应用可能增加复杂度而不带来明显收益
通过合理实施读写分离,可以显著提升MySQL数据库的整体性能和可用性,但需要根据业务特点权衡一致性与性能的关系。