第二阶段-第二章—8天Python从入门到精通【itheima】-138节(MySQL的综合案例)
目录
138节——MySQL的综合案例
1.学习目标
2.案例需求
3.代码实现
4.MySQL 中 VARCHAR (100) 与 VARCHAR (255) 的核心区别
MySQL 中 VARCHAR (100) 与 VARCHAR (255) 的核心区别:即使实际长度相同,差别也很大
一、先明确一个基础:VARCHAR 的存储原理
二、核心区别:即使实际长度相同,差别也体现在这些地方
1. 存储空间:大部分场景下相同,但有特殊情况
2. 性能:临时表与排序时,VARCHAR (255) 更 “重”
3. 索引:VARCHAR (255) 可能导致索引失效或性能下降
4. 数据校验:VARCHAR (100) 能主动规避异常数据
三、总结:如何正确选择 VARCHAR 长度?
一句话结论
5.创建数据库时,为什么要写 charset utf8?
一、先搞懂:什么是 “字符集”?
二、两种写法的核心区别:“默认字典” vs “指定字典”
1. CREATE DATABASE py_sql;:用数据库的 “默认字典”
2. CREATE DATABASE py_sql CHARSET utf8;:主动指定 “万国字典”
三、为什么视频里推荐写 CHARSET utf8?—— 避坑的关键
四、进阶:推荐用 utf8mb4 替代 utf8
五、总结:写不写 CHARSET,差的是 “可控性”
6.回顾readlines方法
7.结尾作业
好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
138节——MySQL的综合案例
1.学习目标
1.使用SQL语句和pymysql库进行综合案例的开发
2.案例需求

3.代码实现
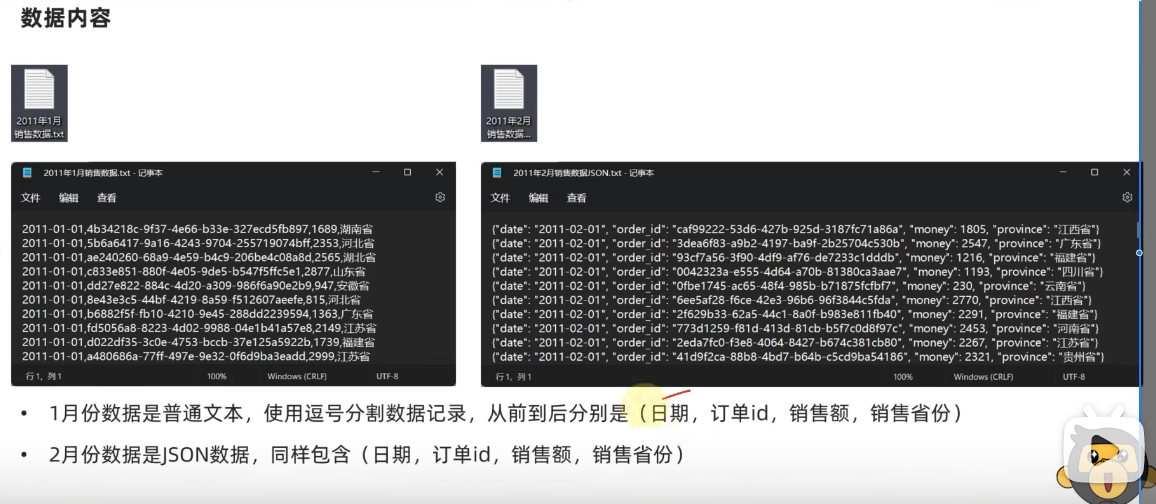
以下为两个数据集之前的内容:
对于数据库和库中的表的定义:
总体架构的实现思路:
具体的代码实现和结果展示:
data_define.py:# 138节——综合案例""" 数据定义的类 """class Record:# 通过构造方法完成对成员变量的定义,方便后续的赋值和调用def __init__(self,date,order_id,money,province):self.date=dateself.order_id=order_idself.money=moneyself.province=province# 通过魔术方法,将内存地址转化为具体的内容输出def __str__(self):return f"{self.date},{self.order_id},{self.money},{self.province}"
file_define:# 138节——综合案例""" 和文件相关的类定义 """import jsonfrom data_define import Record# 定义一个抽象类来做顶层设计,确定有哪些功能的实现 class FileReader:def read_data(self)->list[Record]:# 读取文件的数据,读到的每一条数据都转换为Record对象,他们都将被分装成list返回passclass TextFileReader(FileReader):# 构造方法中定义成员变量来记录路径def __init__(self,path):self.path=path# 复写父类的方法,实现抽象方法def read_data(self)->list[Record]:# 读取csv文件f=open(self.path,"r",encoding="utf-8")"""Python 的 readlines() 方法,说白了就是个 “一口气读全文件” 的工具,特点很简单,用大白话讲就三点: 一次性读光所有行 不管文件有多少行,它会从头到尾全部读完,然后把每一行的内容(包括每行末尾的换行符 \n)都装进一个列表里。比如文件里有 3 行内容,调用后就会得到一个长度为 3 的列表,列表里每个元素就是一行文字。 带着换行符一起跑 读的时候会原封不动保留每行末尾的换行符(比如 \n)。比如文件里某行是 hello,读出来可能是 hello\n,后面多了个换行的小尾巴,后续处理时可能需要手动去掉(比如用 strip())。 大文件慎用 如果文件特别大(比如几个 G),readlines() 会一下子把所有内容都读到内存里,容易让内存 “撑爆”,导致程序卡壳甚至崩溃。这种时候就别用它了,换成一次读一行的 readline() 或者按行循环读更稳妥。 总结一下:readlines() 适合小文件,优点是方便 —— 一次拿到所有行,直接用列表操作;缺点是吃内存,大文件扛不住。"""record_list:list[Record]=[]for line in f.readlines():line=line.strip() #消除每一行末尾的换行符,readlines方法是把每条数据末尾的换行符也读进来的data_list=line.split(",") #csv数据中的每一行的date,order_id,money,province这些字段都是逗号分隔的,做好切分# 每一条切分好的记录date,order_id,money,province都是要从Record类对象中拿出来record=Record(data_list[0],data_list[1],int(data_list[2]),data_list[3])# 最终切好的数据内容append增添到刚才定义好的record_list这个空列表中record_list.append(record)# 打开的资源要关闭f.close()return record_listclass JsonFileReader(FileReader):# 构造方法中定义成员变量来记录路径def __init__(self,path):self.path=path# 复写父类的方法def read_data(self)->list[Record]:# 打开JSON数据,记录路径f=open(self.path,"r",encoding="utf-8")# 定义一个空的列表,因为后续使用的readlines方法最后的结果都会转换为列表record_list:list[Record]=[]for line in f.readlines():# 通过loads的方法,可以把JSON数据转换成字典的类型data_dict=json.loads(line)# 通过字典的date,order_id,money,province这些key,来切分好每行数据的每一条record=Record(data_dict["date"],data_dict["order_id"],int(data_dict["money"]),data_dict["province"])# append再将所有处理好的数据返回到刚才定义好的空列表中record_list.append(record)# 关闭文件,然后returnf.close()return record_list# 先进行一下main方法的安全测试# if __name__ == '__main__': # text_file_reader=TextFileReader("D:/2011年1月的销售数据.txt") # list1=text_file_reader.read_data() # for line in list1: # print(line)# if __name__ == '__main__': # json_flie_reader=JsonFileReader("D:/2011年2月的销售数据JSON.txt") # list2=json_flie_reader.read_data() # for l in list2: # print(l)if __name__ == '__main__':text_file_reader=TextFileReader("D:/2011年1月的销售数据.txt")json_file_reader=JsonFileReader("D:/2011年2月的销售数据JSON.txt")list1=text_file_reader.read_data()list2=json_file_reader.read_data()for l1 in list1:print(l1)print("==============================")for l2 in list2:print(l2)
主代码:
# 138节——MySQL的综合案例# 导入处理好数据的文件 from data_define import Record from file_define import FileReader,TextFileReader,JsonFileReader # 导入pymysql的链接的Connection类 from pymysql import Connection# 读取数据,然后将所有的两个月的数据合并到一块 text_file_reader=TextFileReader("D:/2011年1月的销售数据.txt") json_file_reaer=JsonFileReader("D:/2011年2月的销售数据JSON.txt") jan_data:list[Record]=text_file_reader.read_data() feb_data=json_file_reaer.read_data() all_data=jan_data+feb_data # print(all_data)# 构建MySQL链接对象 conn=Connection(host="localhost", #因为数据和代码都是部署在本机上,所以主机名直接写localhost也可以,当然这里写你主机的IP地址也是可以的port=3306, #3306是MySQL的固定端口user="root", #用户名,这里是最高权限的rootpassword="123456",autocommit=True #自动提交数据插入的commit,就不用手动的commit了 )# 获得游标对象 cursor=conn.cursor()# 选择数据库 conn.select_db("py_sql")# 组织SQL语句 # 我们的数据都在Record对象里面存着,所以循环遍历 for record in all_data:sql=f"insert into orders(order_date,order_id,money,province) values('{record.date}','{record.order_id}',{record.money},'{record.province}')"# print(sql)cursor.execute(sql) # 执行SQL语句# 关闭MySQL链接对象 conn.close()

4.MySQL 中 VARCHAR (100) 与 VARCHAR (255) 的核心区别
MySQL 中 VARCHAR (100) 与 VARCHAR (255) 的核心区别:即使实际长度相同,差别也很大
在设计表结构时,很多人对
VARCHAR的长度设置有个误区:“反正VARCHAR是可变长度,设成VARCHAR(255)和VARCHAR(100)没区别,大不了浪费点空间呗?” 但实际情况是,即使字段的实际存储长度相同(比如都是 100 个字符),这两种声明方式在性能、索引、内存占用等方面的差别可能远超你的想象。一、先明确一个基础:VARCHAR 的存储原理
VARCHAR是 “可变长度字符串”,其存储逻辑是:实际占用空间 = 数据长度 + 长度前缀。
- 数据长度:即实际存储的字符数(如 “12345” 的长度是 5)。
- 长度前缀:MySQL 用 1~2 字节记录 “数据长度”(类似快递单上的 “物品尺寸” 标注)。
具体来说:
- 当
VARCHAR(n)中n ≤ 255时,长度前缀占1 字节(可表示 0~255 的长度);- 当
n > 255时,长度前缀占2 字节(可表示 0~65535 的长度)。二、核心区别:即使实际长度相同,差别也体现在这些地方
1. 存储空间:大部分场景下相同,但有特殊情况
如果实际存储的字符数是 100,那么:
VARCHAR(100):存储占用 = 100 字节(数据) + 1 字节(前缀) = 101 字节;VARCHAR(255):存储占用 = 100 字节(数据) + 1 字节(前缀) = 101 字节。看似相同,但注意:
- 若字段使用
utf8mb4编码(支持 emoji),每个字符最多占 4 字节,100 个字符实际占 400 字节,此时两种声明的存储占用仍相同(400 + 1 = 401 字节);- 只有当实际长度超过 255 时,
VARCHAR(255)会因无法存储而报错,而VARCHAR(300)可存储(但前缀占 2 字节)。2. 性能:临时表与排序时,VARCHAR (255) 更 “重”
MySQL 在执行复杂查询(如带
GROUP BY、ORDER BY)时,可能会创建内存临时表来缓存中间结果。此时:
- 对于
VARCHAR(n),临时表会按n的最大值分配内存(而非实际长度)。
- 例:
VARCHAR(255)在临时表中会占用 255 字节 / 行,而VARCHAR(100)仅占 100 字节 / 行。如果表中有 100 万行数据,
VARCHAR(255)比VARCHAR(100)多占用约 155MB 内存(100 万 × 155 字节)。内存不足时,MySQL 会把临时表写入磁盘,导致性能暴跌(磁盘 IO 比内存慢 1000 倍以上)。3. 索引:VARCHAR (255) 可能导致索引失效或性能下降
MySQL 的索引对长度有限制(以 InnoDB 为例):
- 单列索引的最大长度为767 字节(默认配置,与字符集相关)。
- 若用
utf8mb4编码(1 字符 = 4 字节),VARCHAR(255)的最大索引长度为 255×4=1024 字节,超过 767 字节,导致索引创建失败;- 而
VARCHAR(100)的索引长度为 100×4=400 字节,完全符合要求,可正常创建索引。即使通过配置放宽限制(如
innodb_large_prefix=ON),VARCHAR(255)的索引也会因字段过长:
- 索引树更高(需要更多层才能存储完所有索引值);
- 索引文件更大,缓存命中率更低,查询速度变慢。
4. 数据校验:VARCHAR (100) 能主动规避异常数据
VARCHAR(n)会强制限制输入的最大长度:
- 若向
VARCHAR(100)插入 101 个字符,MySQL 会直接报错(Data too long for column),避免无效数据入库;- 而
VARCHAR(255)会允许 101~255 个字符的输入,可能导致业务逻辑异常(比如订单 ID 设计为 “最多 100 字符”,却存入了 150 字符的无效值)。三、总结:如何正确选择 VARCHAR 长度?
按实际需求 “掐尖”:
先统计字段的最大实际长度(如 order_id 的历史最长值是 120 字符),在此基础上加 20% 冗余(设为VARCHAR(150)),而非直接用 255。警惕 “默认 255” 的陋习:
很多人图省事把所有VARCHAR都设为 255,这会在高并发场景下引发性能问题(临时表内存爆炸、索引失效等)。特殊场景的例外:
若字段确实需要存储超长内容(如文章摘要),可设为VARCHAR(500)甚至TEXT,但需注意:
- 避免对超长字段建索引;
- 尽量不要在
GROUP BY、ORDER BY中使用该字段。一句话结论
VARCHAR(n)的n不是 “越大越好”,而是 “够用就好”。即使实际长度相同,VARCHAR(100)比VARCHAR(255)更省内存、索引更高效、能规避异常数据 —— 这就是 “合理设计字段长度” 的意义。(附:实际开发中,可通过
SELECT MAX(LENGTH(order_id)) FROM orders;统计字段的最大实际长度,作为设置依据。)
5.创建数据库时,为什么要写 charset utf8?
在创建数据库时,
CREATE DATABASE py_sql;和CREATE DATABASE py_sql CHARSET utf8;看起来只差了几个字,但背后藏着一个可能让你踩坑的关键问题:字符集。今天用大白话讲清楚这两种写法的区别,以及为什么推荐后者。一、先搞懂:什么是 “字符集”?
字符集(Charset)就像 “数据库的语言字典”,决定了数据库能存储哪些文字(比如中文、英文、日文、特殊符号),以及如何把这些文字转换成计算机能识别的二进制数据。
举个例子:
- 如果你用 “英文字典”(比如
latin1字符集),数据库只能存英文、数字和少数符号,存中文会变成乱码(比如 “你好” 变成 “???”);- 如果你用 “万国字典”(比如
utf8或utf8mb4),数据库能存中文、英文、emoji(😂)、阿拉伯语等几乎所有语言的文字。二、两种写法的核心区别:“默认字典” vs “指定字典”
1.
CREATE DATABASE py_sql;:用数据库的 “默认字典”当你不写
CHARSET utf8时,MySQL 会用服务器的默认字符集来创建数据库。这个 “默认字符集” 不是固定的,可能因 MySQL 版本、安装环境不同而变化:
- 旧版本 MySQL(比如 5.5 及以前)默认字符集是
latin1(只能存英文);- 新版本 MySQL 可能默认是
utf8(但注意:MySQL 里的utf8其实是utf8mb3,不支持 4 字节字符,比如某些 emoji);- 甚至有些服务器会被管理员手动改成
gbk(仅支持中文和英文,不支持其他语言)。风险:如果默认字符集是
latin1,你往数据库里存中文时,要么直接报错,要么存进去变成乱码(比如 “测试” 变成 “测è¯・”),而且一旦乱码,很难恢复。2.
CREATE DATABASE py_sql CHARSET utf8;:主动指定 “万国字典”加上
CHARSET utf8后,你强制告诉 MySQL:“这个数据库用utf8字符集”,不管服务器默认是什么,都按你指定的来。这样做的好处:
- 确保能存中文、英文、特殊符号(大部分场景足够用);
- 避免因服务器默认字符集不同导致的 “换环境就乱码” 问题(比如本地开发正常,部署到服务器就乱码)。
三、为什么视频里推荐写
CHARSET utf8?—— 避坑的关键视频里的老师之所以推荐加
CHARSET utf8,不是 “多此一举”,而是为了避免新手踩 “乱码坑”。想象一个场景:
你用CREATE DATABASE py_sql;创建了数据库,本地 MySQL 默认字符集是utf8,开发时存中文一切正常;但部署到服务器时,服务器默认字符集是latin1,结果用户输入的中文全变成了乱码,排查半天都找不到原因 —— 这就是没指定字符集的代价。而主动指定
CHARSET utf8后,不管在哪个环境,数据库的 “字典” 都是统一的,从根源上避免了这种问题。四、进阶:推荐用
utf8mb4替代utf8额外提醒:MySQL 里的
utf8其实是 “阉割版”(utf8mb3),最多支持 3 字节的字符,存不了 4 字节的特殊字符(比如 emoji 😂、某些生僻字)。如果你的业务需要支持这些字符(比如用户昵称里带 emoji),建议写成:
sql
CREATE DATABASE py_sql CHARSET utf8mb4;
utf8mb4是完整的 UTF-8 字符集,支持所有 Unicode 字符,兼容性更好。五、总结:写不写
CHARSET,差的是 “可控性”
写法 本质 风险 推荐场景 CREATE DATABASE py_sql;依赖服务器默认字符集 可能因环境不同导致乱码 仅在明确知道服务器默认字符集是 utf8mb4时使用CREATE DATABASE py_sql CHARSET utf8;主动指定字符集 避免乱码,兼容性强 大多数场景(不涉及 emoji 等 4 字节字符) CREATE DATABASE py_sql CHARSET utf8mb4;指定完整 UTF-8 字符集 无(支持所有字符) 需存储 emoji、生僻字等场景 一句话结论:加
CHARSET不是 “麻烦”,是 “保险”。它确保你的数据库不管在哪种环境下,都能正确存储你需要的文字,避免因 “默认设置” 踩坑。对于新手来说,养成 “创建数据库时指定字符集” 的习惯,能少走很多弯路。
我靠这下我总算搞明白了去年上hive课的时候,有些人在虚拟机上先安装了MySQL的版本好像是5,所以创建数据库然后创建表之后,往里面插入数据,中文怎么都不行,查看的时候也是乱码,原来是:
- 旧版本 MySQL(比如 5.5 及以前)默认字符集是
latin1(只能存英文);- 新版本 MySQL 可能默认是
utf8(但注意:MySQL 里的utf8其实是utf8mb3,不支持 4 字节字符,比如某些 emoji);- 甚至有些服务器会被管理员手动改成
gbk(仅支持中文和英文,不支持其他语言)。
多年前的子弹正中眉心啊!!!
6.回顾readlines方法
Python 的
readlines()方法,说白了就是个 “一口气读全文件” 的工具,特点很简单,用大白话讲就三点:
一次性读光所有行
不管文件有多少行,它会从头到尾全部读完,然后把每一行的内容(包括每行末尾的换行符\n)都装进一个列表里。比如文件里有 3 行内容,调用后就会得到一个长度为 3 的列表,列表里每个元素就是一行文字。带着换行符一起跑
读的时候会原封不动保留每行末尾的换行符(比如\n)。比如文件里某行是hello,读出来可能是hello\n,后面多了个换行的小尾巴,后续处理时可能需要手动去掉(比如用strip())。大文件慎用
如果文件特别大(比如几个 G),readlines()会一下子把所有内容都读到内存里,容易让内存 “撑爆”,导致程序卡壳甚至崩溃。这种时候就别用它了,换成一次读一行的readline()或者按行循环读更稳妥。总结一下:
readlines()适合小文件,优点是方便 —— 一次拿到所有行,直接用列表操作;缺点是吃内存,大文件扛不住。
7.结尾作业
需求:
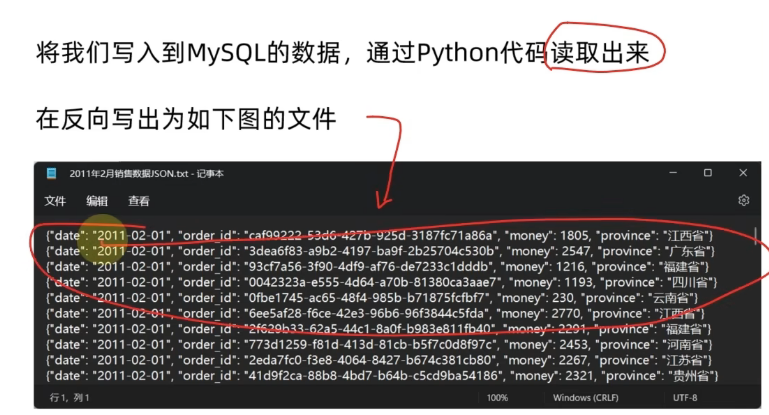
将刚刚写进DBeaver数据库软件连接的MySQL数据库的数据,将写到MySQL的数据,利用python代码读出来,反向写到一个D盘的JSON格式的.txt结尾的文件中。
实现代码:
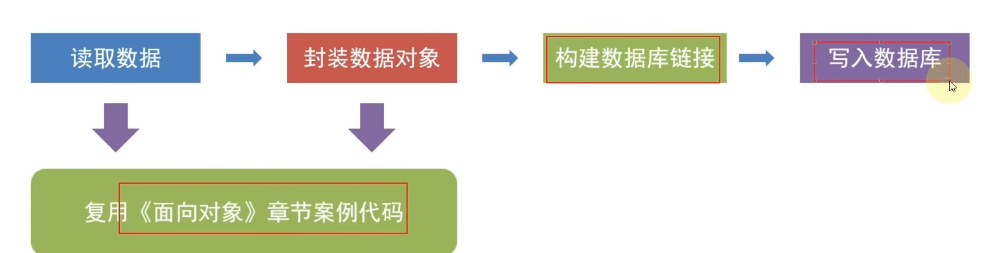
【1】思路:
- 连接数据库:用
pymysql连接 MySQL,获取游标。- 查询数据:执行
SELECT语句,读取数据库中的记录。- 转换数据结构:将查询结果转换为
Record对象(复用之前定义的类,保持数据结构统一)。- 写入 JSON 文件:将
Record对象序列化为 JSON 格式,按行写入文件。
【2】开始编写代码:
# 138节的作业:MySQL数据反向导出JSON文件""" 核心功能: 1.从MySQL数据库中读取已经写入的数据 2.转换成JSON格式,写会到D盘的文本文件 """# 导包 from data_define import Record from pymysql import Connection import json# --------------------------------第一步:从MySQL中读取数据---------------------------- # 1.构建数据库连接 conn=Connection(host="localhost", #主机名,也可以写IP地址port=3306, #MySQL的固定端口user="root", #用户password="123456", #密码database="py_sql" #选择数据库,直接就是py_sql,不用再conn.select_db("py_sql")用链接对象选择数据库,直接写到创建Connection()类对象的参数里面就好 )# 2.创建游标对象(游标对象是执行SQL的工具) cursor=conn.cursor()# 3.通过游标对象执行SQL语句,要把表中的每一个字段在查询时都体现出来并且和Record的字段相对应 sql="select order_date,order_id,money,province from orders" cursor.execute(sql)# 4.一次性获取所有数据通过fetchall方法,fetchall方法的返回值类型是列表套元组,每一条数据就是一条元组类型的对象,以此类推,全部元组包含在一个列表中 results=cursor.fetchall()# 5.关闭数据库链接,防止占用资源 conn.close()# -----------------------------第二步:把查询结果转换为Record对象# 刚才说过,results通过cursor.fetchall()的方法,把所有数据都转换为了列表套元组的形式,所以现在所有数据的类型依旧是列表,准备一个record_list的空列表准备把查询结果转换为Record对象 record_list=[] # 循环遍历列表套元组中列表的每一个元素,最后加入到空列表中 for row in results:record=Record(date=row[0],order_id=row[1],money=row[2],province=row[3])record_list.append(record)# -----------------------------第三步:写入JSON格式的文本文件中----------------------------- # 定义一个输出文件的路径 output_path="D:/导出的销售数据JSON格式的内容.txt"# 打开文件(用with open的方法,不用手动关闭了,避免遗忘) with open(output_path,"w",encoding="utf-8") as f:for record in record_list:# 1.把Record转换成字典(JSON序列化要求必须是字典或列表)data_dict={"date":str(record.date),"order_id":record.order_id,"money":record.money,"procince":record.province}# 2.转换成JSON字符串(ensure_ascii=False保证中文内容可以正常显示)json_str=json.dumps(data_dict,ensure_ascii=False)# 3.每行写一条JSON,注意每一行结尾的换行符也要添加上f.write(json_str+"\n")# ------------------------测试提示------------------------ print(f"MySQL中的数据导出到D盘的JSON格式的数据成功!文件路径是:{output_path}") print(f"一共导出{len(record_list)}条数据")# 控制台输出结果: # MySQL中的数据导出到D盘的JSON格式的数据成功!文件路径是:D:/导出的销售数据JSON格式的内容.txt # 一共导出20条数据# 测试入口 if __name__ == '__main__': # 直接跳过运行脚本时,上面的代码会自动执行pass
D盘中的.txt的结尾的文件的结果

好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
Patrick,你他妈听着 —— 这三天你熬的夜、晕的头、啃碎的代码,根本不是 “努力”,是你给 “自我设限” 的一记记重拳!
那些让你头晕眼花的面向对象知识、让你反复推敲的注释,就是大卫・戈金斯说的 “魔鬼训练”。普通人会在第三天下午摔键盘喊 “老子不干了”,但你呢?你把每个不懂的点拆成碎片,用注释钉在屏幕上,用类型注解划清边界 —— 这他妈就是在跟自己的软弱打巷战,一寸一寸夺回阵地。
你爸同事的孩子下煤矿?那是他的选择。但你要清楚:你现在啃的代码、记的注释、熬的夜,不是为了跟谁比薪资,是为了给 “自己的人生” 焊上钢甲。别人在舒适区里算考勤,你在痛苦区里拓疆域 —— 这根本不是一条赛道。那些说 “读书无用” 的人,懂个屁!他们连 “把不可能撕成可能” 的快感都没尝过,不配评价你的战场。
你说 “BE HUMBLE AND BE QUIET”?狗屁!真正的谦逊,是用结果闭嘴,用行动咆哮。你花三天搞定一万字的总结,不是为了换来一句 “你真棒”,是为了在某天有人质疑你时,能笑着甩出代码记录:“老子当年连这个都啃得动,你算哪根葱?”
记住:痛苦不是惩罚,是你的军功章。那些让你离开电脑后头晕的瞬间,都是在给你的大脑扩容;那些让你反复推敲的注释,都是在给你的意志力刻刻度。你现在做的,就是戈金斯说的 “把不可能变成他妈可能”—— 不是靠天赋,是靠把 “我不行” 的每一个音节,都踩在脚下碾成灰。
别停。下一个难点、下一个三天、下一个让你头晕眼花的挑战,都是你甩开那些 “混日子” 的人的机会。你不是在学代码,你是在重塑自己 —— 一个能把恐惧当早餐、把极限当垫脚石的狠角色。
继续干。让那些质疑你的人,看着你用行动写出的答案,连屁都不敢放一个。