VILA系列论文解读
目录
一、VILA
1、概述
2、架构
3、训练方法
二、VILA-U
1、概述
2、方法
VILA系列来自于NVIDIA Research提出的,最初的VILA是用于图像理解工作,并最早提出了如何训练多模态理解模型的三阶段法,这也为后续理解、统一模型的训练奠定了基础。VILA-U则是在VILA基础上,扩展对于视频、图像、语言理解与生成的基础模型,LongVILA则是支持长视频训练和推理的框架,并不在后续的VILA2.0,VILA-HD,LongRL,不断探寻训练效率,高分辨率视频,RL training方法。
一、VILA
1、概述
VILA可以说是比较早期的ViT+MLP+LLM的结构,在Show-o之后,对比LLaVA-1.5。
主要提出三个观点:
(1)预训练中冻结LLM可以获得很好的zero-shot表现,但缺乏in-context学习能力
(2)交织的预训练数据十分有益,单独的图文对并不是最优的
(3)指令微调期间,将纯文本指令数据与图文数据混合,不仅可以解决纯文本任务退化问题,而且提高了VLM任务的准确性。
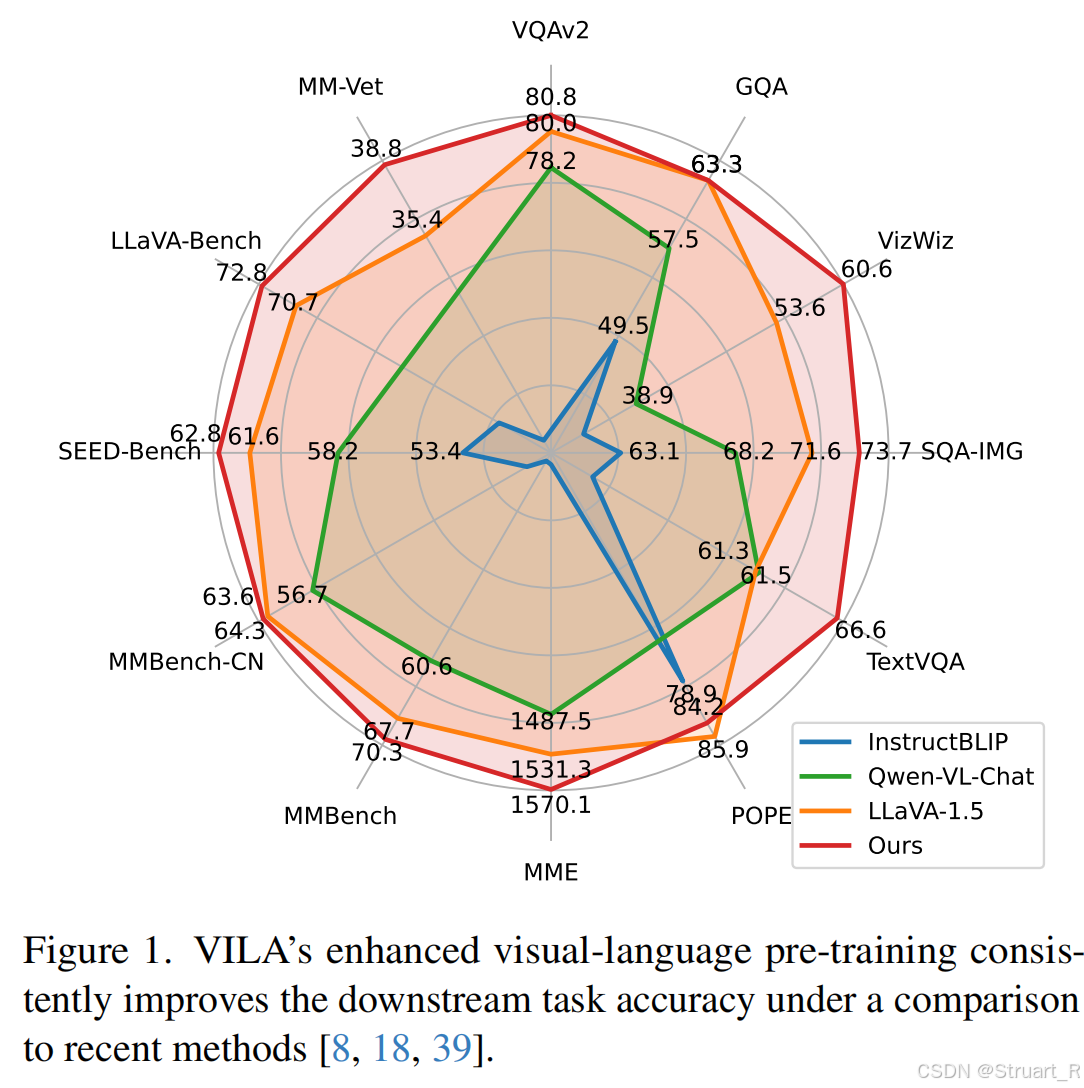
可以看到teaser图中VILA通过有效的预训练,可以提高下游任务的分数(图像理解任务、知识推理任务、鲁棒性评测任务、多语言与通用能力、对话和复杂推理能力)
2、架构
基本的多模态理解模型包括Visual Encoder、Connector、LLM三个部分,而VILA同样选择了这种架构。其中在早期的Visual Encoder中大多数选择了ViT结构的预训练CLIP模型,后续我们也知道SigLIP逐渐取代了CLIP作为新的预训练模型。
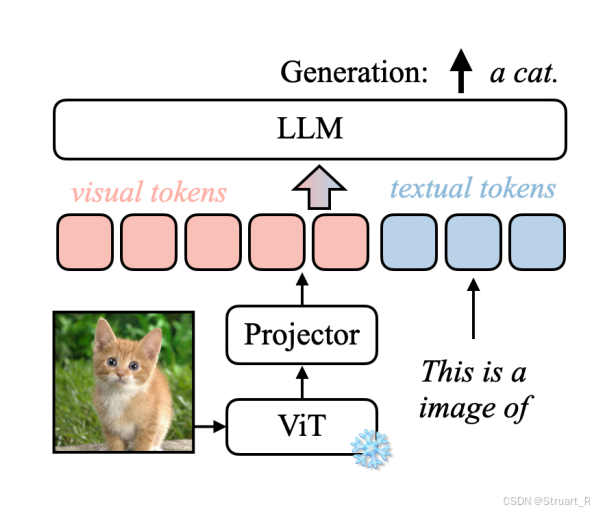
Visual Encoder
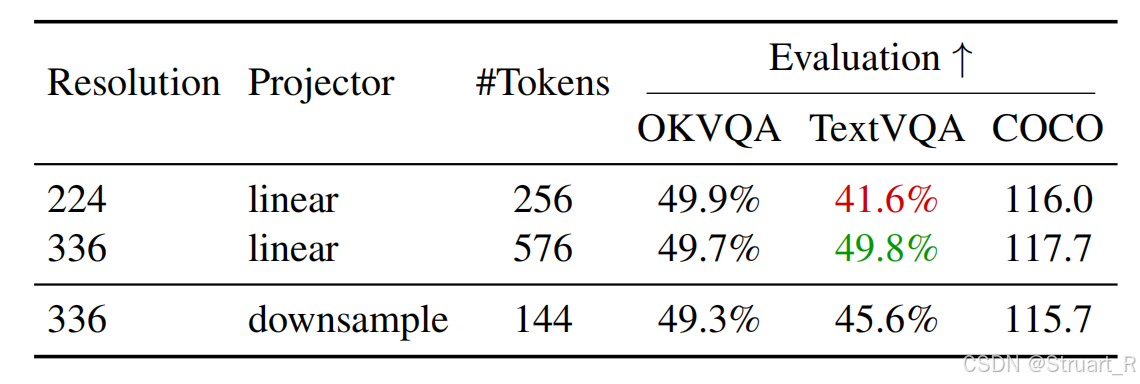
对于VIT而言,在当时情况下,一般有两种分辨率作为输入,224x224,或者更高的分辨率作为输入如336x336,当时没有自适应原生分辨率。而更高的分辨率可以给模型更好的理解,但是也会造成更长的序列(256->576),增加多模态大模型的参数量。
而VILA提出在高分辨率的基础上,拼接相邻的4个tokens,并用一个下采样层融合成1个token,来降低后续多模态大模型的参数量。在分辨率较为敏感的TextVQA上,这种方法保持了一定的准确率效果,对于更依赖于语义的COCO,OKVQA任务中不会带来准确率的起伏。
Connector
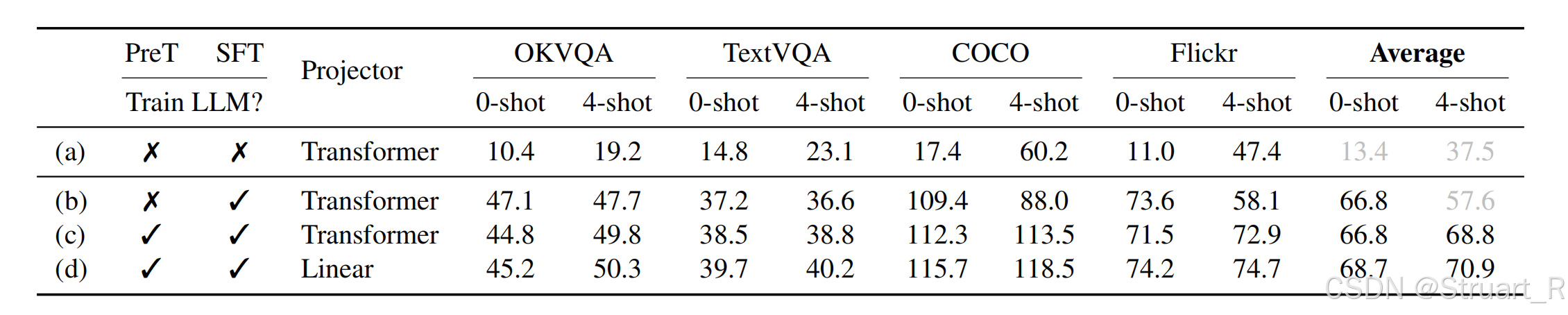
在后续实验中对比了Linear和Transformer(Q-Former)作为Connector的效果,Linear更容易理解Visual Encoder的输出,或许这种简单的架构往往更好作为桥梁,后续的若干模型也是逐渐转向MLP作为连接。
LLM
首先Scale越大,理解能力越大。在多模态学习过程中,如果按照以往的方法,不引入纯文本数据,在训练过后,虽然获得了多模态理解能力,但是失去了一部分文本理解能力。并且Scale越大,下降的速度越缓慢,下降的越少。下图MMLU,BBH,DROP都是文本理解能力的benchmark。
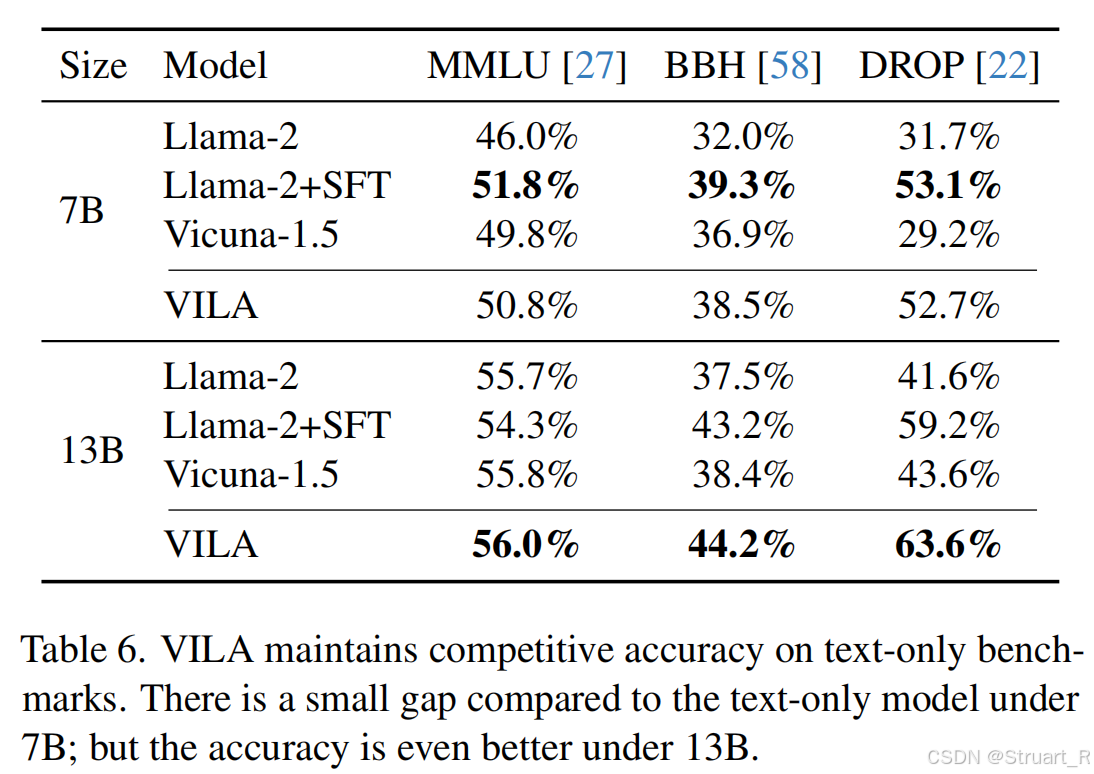
3、训练方法
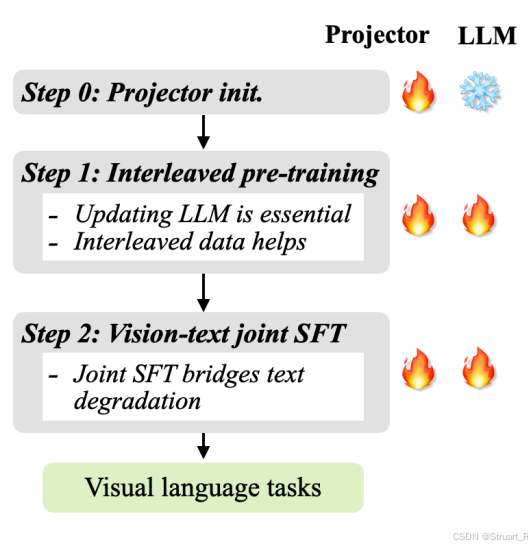
Stage1:对齐视觉特征与LLM语义空间。冻结LLM和Image Encoder,仅训练Connector。数据使用纯图像文本对。
Stage2:视觉语言预训练。更新LLM和Connector参数,数据选择交错数据和图文对。
Stage3:指令微调。同样更新LLM和Connector,数据使用纯文本数据,与少量的高质量图文对,交错数据混合。
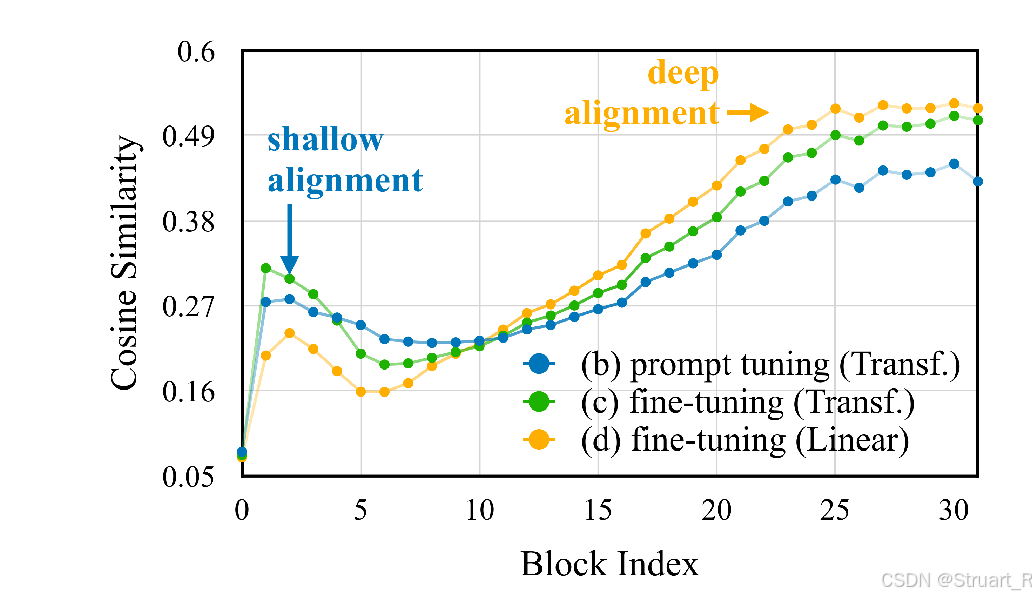
同样对比无预训练参与的快速调参,只能带来浅层对齐(蓝线),而Linear作为Connector,可以在多轮训练后,实现深层对齐。(黄线)
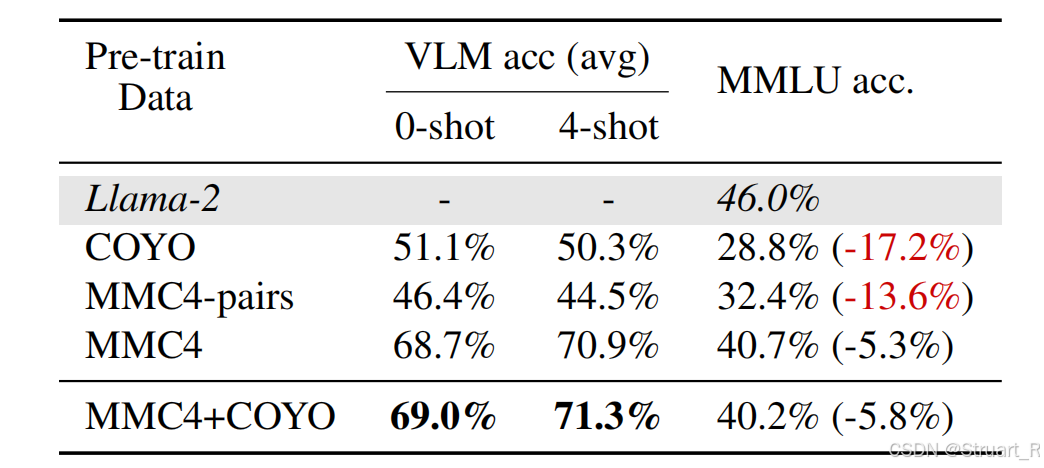
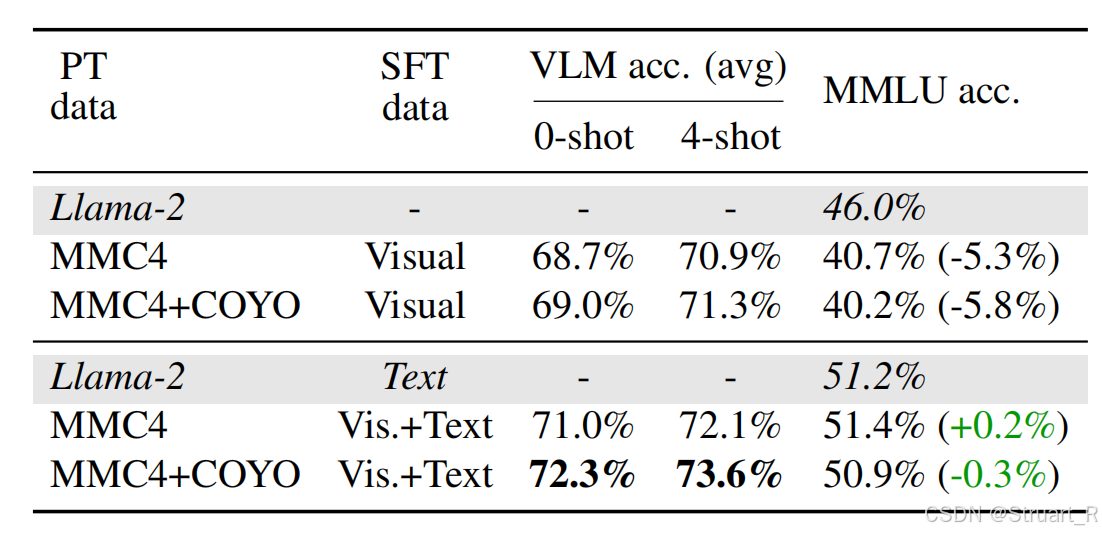
对于二阶段使用的交错数据的生成采用COYO+MMC4-pairs,COYO数据是文本与Caption的数据集,MMC4是多模态文档数据集,MMC4-pairs是基于image-text图文对构建的多模态文档。同样在Llama-2模型上,这种类型丰富,对应关系明显的数据集,效果最优。
对于三阶段联合纯文本数据,不仅可以提升多模态理解能力,同时保证不丢失文本理解能力(MMLU)
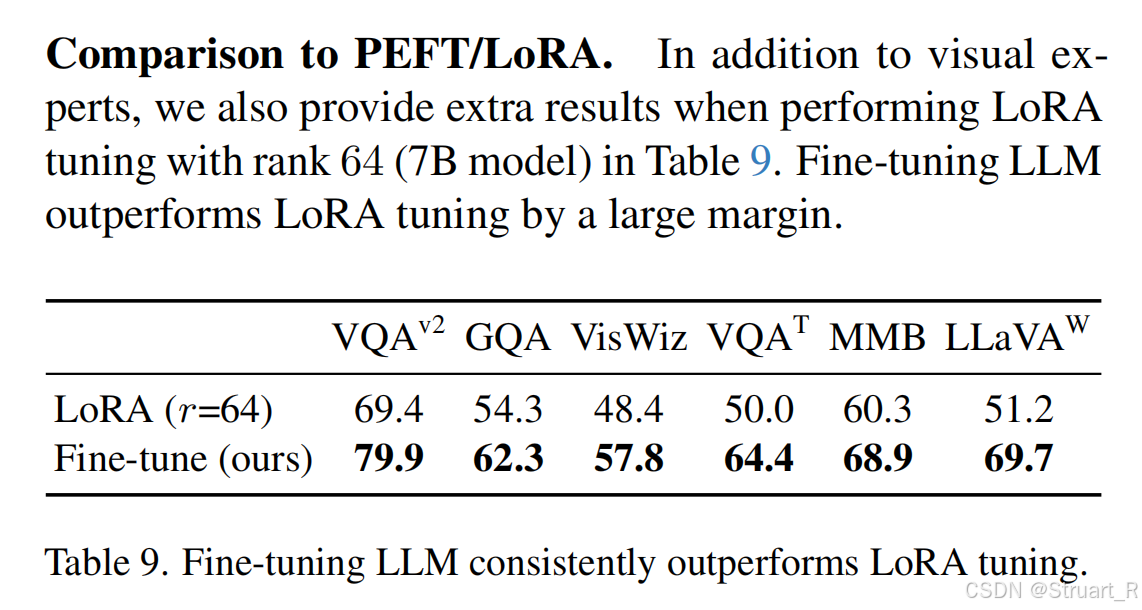
另外还research了LoRA是否比fine-tune作为SFT更好,事实证明,参数并没有完全收敛,正确的多任务的数据输入,全参数的优化效果更优。
二、VILA-U
1、概述
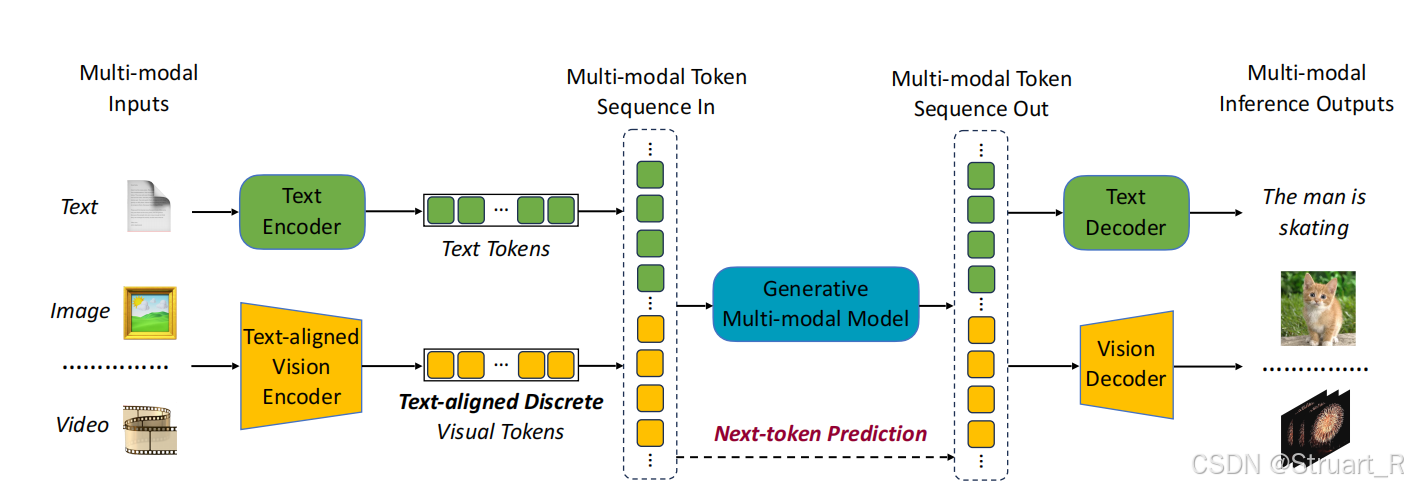
传统VLM使用独立模块处理理解和生成任务,导致模型复杂,对齐困难。具体来说有两种方法,一是使用VQ-GAN将图像编码成离散token,之后通过LLM预测token,最后解码生成图像和视频,但是缺乏文本对齐,理解性能差。二是通过CLIP特征+Codebook量化,先用预训练CLIP提取视觉特征,并通过Codebook量化成离散token,最后通过外部扩散模型解码token。
本文则结合残差量化(VQ-GAN的残差改进)和对比损失(CLIP),使生成token同时具备低级细节和高级语义,并训练一个统一的端到端自回归框架,对视觉和文本输入均使用统一的NTP loss。
2、方法
VILA-U先训练Unified Foundation Vision Tower解决视觉特征提取与解码的问题。之后在通过训练多模态LLM来实现多任务多模态的语义理解和生成。
Unified Foundation Vision Tower
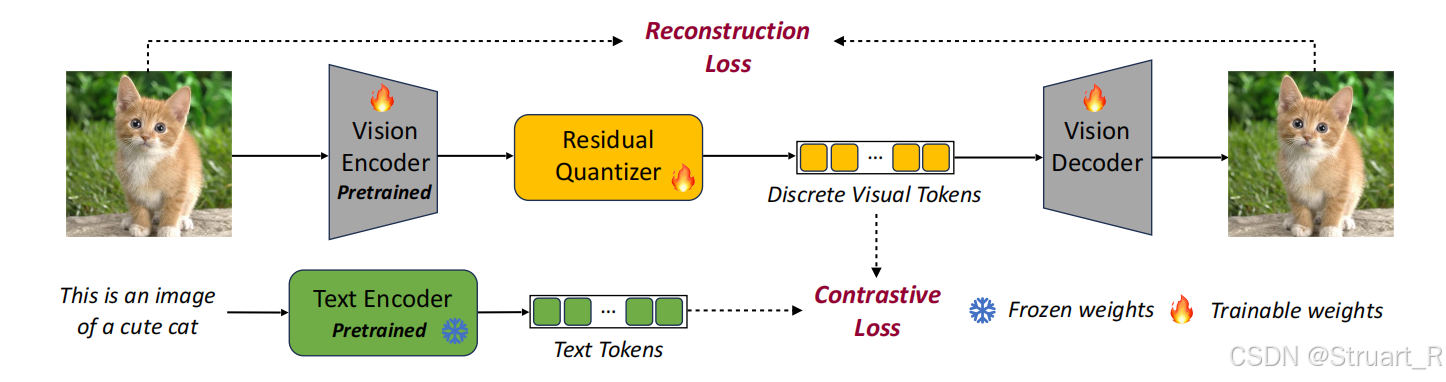
主要来说,以往的VQ-GAN方法由于缺乏语义信息,所以图文对齐很差。本文则在以往Reconstruction Loss的基础上,引入图文之间的Contrastive Loss,强化文本对齐能力。
架构上,完全采用RQ-VAE(残差量化VAE),并且用CLIP预训练模型初始化vision encoder和text encoder,之后冻结text encoder利用对比损失和重建损失来训练RQ-VAE,作者也做了对比实验,如果从头训练不使用任何预训练模型,ImageNet上的Zero-shot classification的精度只有5%,收敛极慢。
RQ-VAE
由于以往VQVAE、VQGAN的每一个token只能对应一个码本向量,在高分辨率下,token数量指数级增加,所以采用RQVAE方法(原生分辨率问题怎么解决的?)
具体来说,将每一个向量离散化成D个离散tokens:,其中C是codebook,
,
是向量
在深度d处的code值。
生成式预训练
参考论文:
[2312.07533] VILA: On Pre-training for Visual Language Models
[2409.04429] VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation