基于mnn架构在本地 c++运行llm与mllm模型
MNN(Mobile Neural Network)是阿里巴巴集团开源的轻量级深度学习推理框架,为移动端、服务器、个人电脑、嵌入式设备等多种设备提供高效的模型部署能力。MNN支持TensorFlow、Caffe、ONNX等主流模型格式,兼容CNN、RNN、GAN等多种网络结构。MNN具备轻量性、通用性、高性能和易用性特点,能在不依赖特定硬件NPU的情况下运行大型模型,支持模型量化和内存优化技术,能适应不同设备的算力和内存限制。MNN提供模型转换、压缩工具和丰富的API,让开发者能轻松地将深度学习模型部署到各种平台上。
https://ai-bot.cn/mnn/
本博文基于mnn框架实现mllm模型——qwen2vl的导出,并实现在c++下推理(调用cpu算力),23 token/s
1、基础环境安装
1.1 安装mnn等
参考 https://blog.csdn.net/HaoZiHuang/article/details/126146550 安装mnn,
安装命令 pip install -U MNN
pip install mnn -i https://pypi.tuna.tsinghua.edu.cn/simple

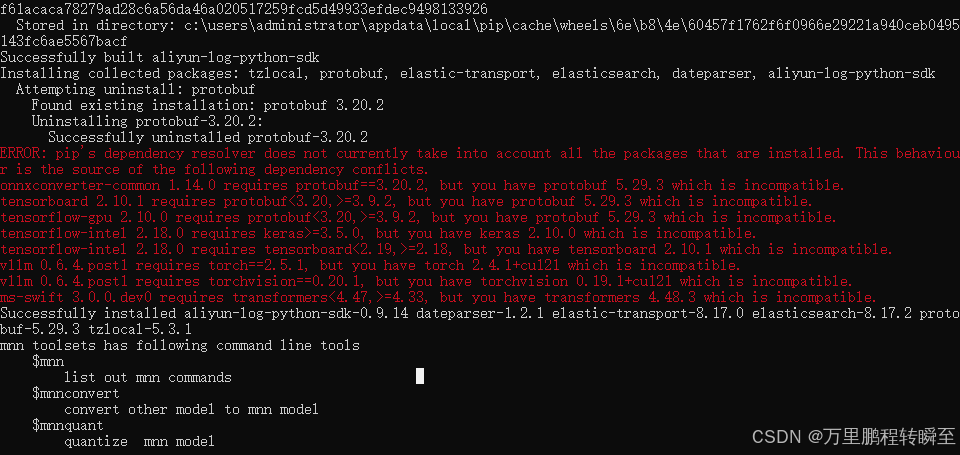
安装完毕之后,在命令行输入mnn,最后输出如下信息
同时在windows环境下构建wsl linux环境,同步在linux环境里,安装mnn
1.2 编译安装mnn库
mkdir build
cd build# 自动检测CUDA架构(或指定具体架构如Maxwell, Pascal等)cmake ../ -DMNN_LOW_MEMORY=true -DMNN_CPU_WEIGHT_DEQUANT_GEMM=true -DMNN_BUILD_LLM=true -DMNN_SUPPORT_TRANSFORMER_FUSE=true -DLLM_SUPPORT_VISION=true -DMNN_BUILD_OPENCV=true -DMNN_IMGCODECS=true
make -j16
cmake --build . --config Release -- /m:64
https://github.com/alibaba/MNN/blob/master/docs/compile/cmake.md
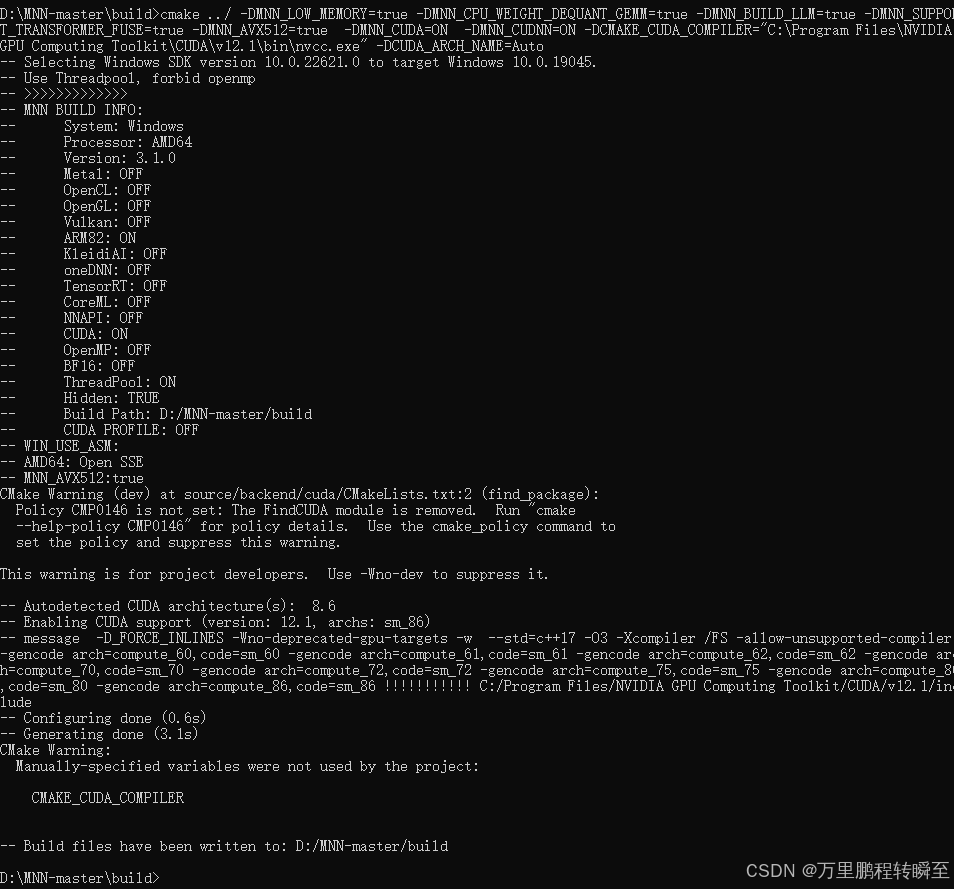
如果出现以下报错
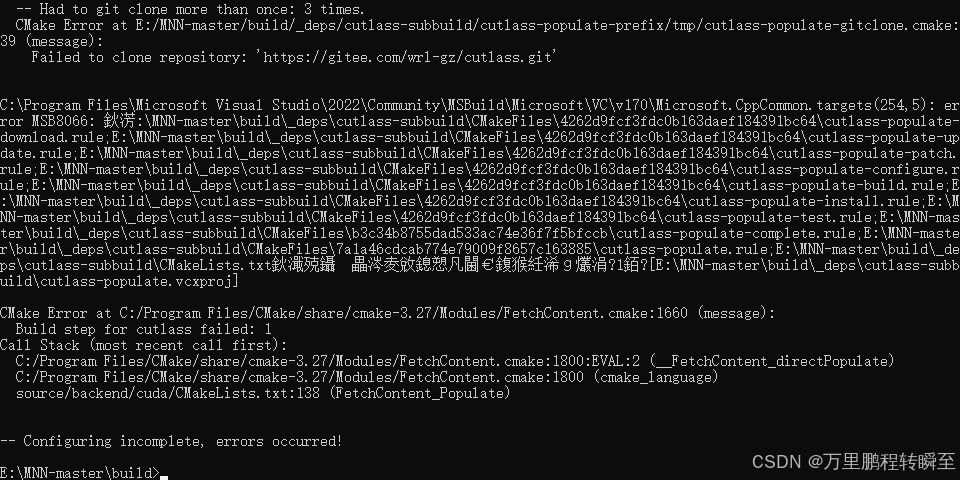
set(CUTLASS_SOURCE_DIR "${CMAKE_SOURCE_DIR}/3rd_party/cutlass/${CUTLASS_VERSION_NAME}")
FetchContent_Declare(cutlassGIT_REPOSITORY https://gitee.com/wrl-gz/cutlass.gitGIT_TAG ${CUTLASS_COMMIT_HASH}SOURCE_DIR ${CUTLASS_SOURCE_DIR}
)set(CUTLASS_SOURCE_DIR "${CMAKE_SOURCE_DIR}/3rd_party/cutlass")
FetchContent_Declare(cutlassSOURCE_DIR ${CUTLASS_SOURCE_DIR}
)
modelscope download --model Qwen/Qwen2.5-VL-3B-Instruct --local_dir ./big_model
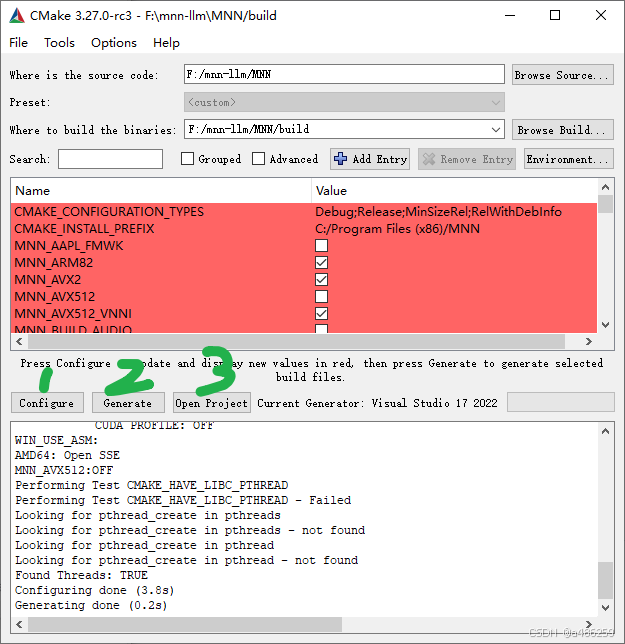
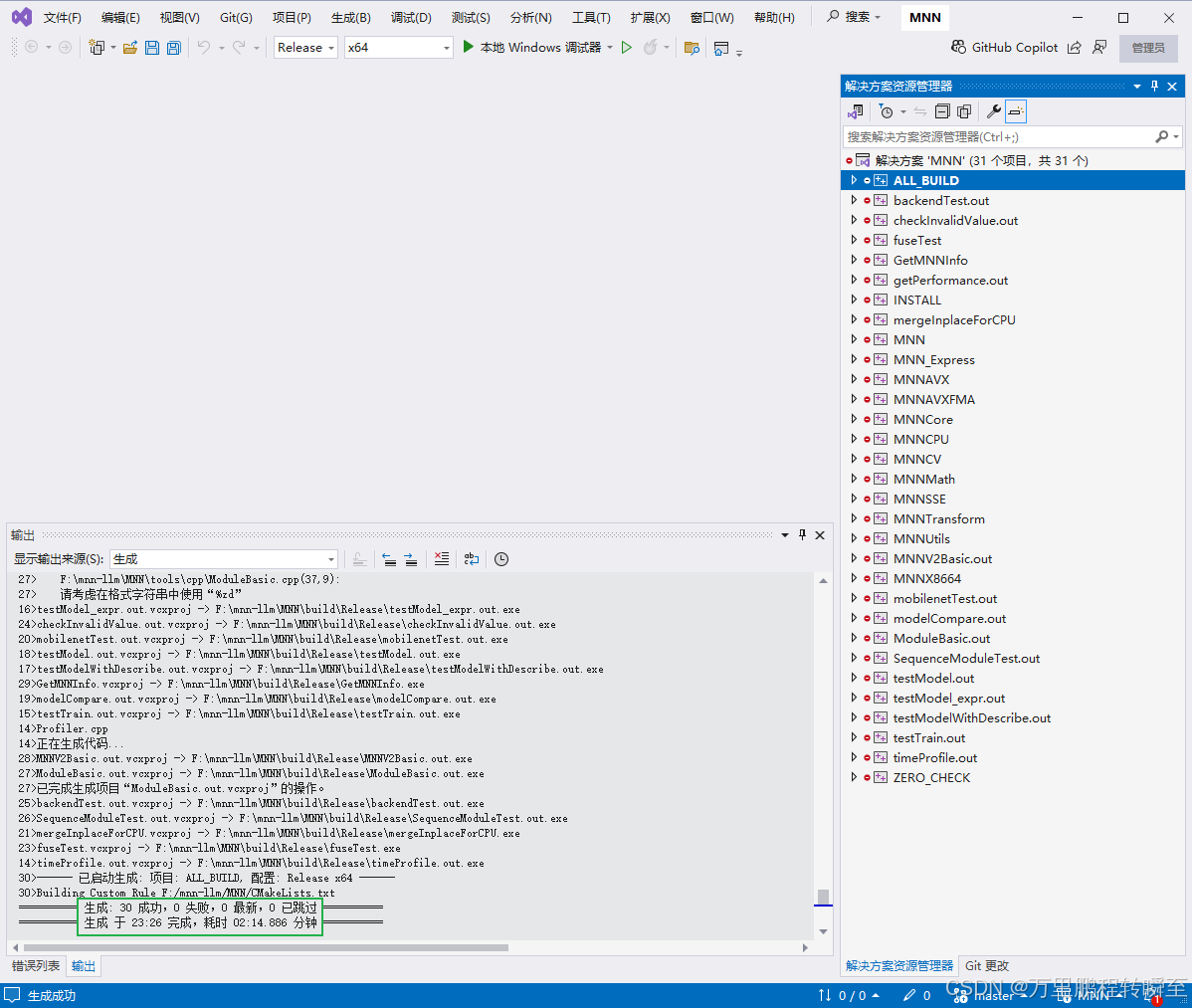
1.3 安装mmn-llm(无关操作)
mnn-llm不能直接基于pip安装,需要进行源码编译安装依赖工具
步骤一 下载mnn-llm项目代码及其附属依赖( --recurse-submodules 指定下载依赖包)
git clone --recurse-submodules https://github.com/wangzhaode/mnn-llm.git
如果附属依赖包没有下载好,可以单独执行git submodule update --init --recursive下载
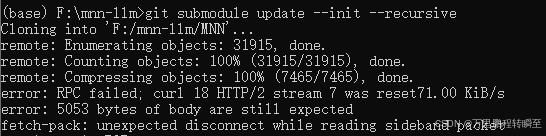
如果无法正常访问git,可以先进入mnn-llm目录,然后基于gitee下载依赖包
git clone https://gitee.com/alibaba/MNN.git
步骤二 编译安装,按照不同的环境执行命令
cd mnn-llm# linux
./script/build.sh# macos
./script/build.sh# windows msvc
./script/build.ps1# python wheel
./script/py_build.sh# android
./script/android_build.sh# android apk
./script/android_app_build.sh# ios
./script/ios_build.sh
步骤三(windows安装) windows执行./script/build.ps1可能会不支持,可以打开PowerShell(没有该软件可以下载安装)执行以下命令:
mkdir buildExpand-Archive .\resource\win_pthreads.zip
cp .\win_pthreads\Pre-built.2\lib\x64\pthreadVC2.lib build
cp .\win_pthreads\Pre-built.2\include\*.h .\include\cd build
cmake ..
cmake --build . --config Release -j 4
cd ..
最终的执行结果如下所示,这表明程序编译成功了
步骤四(python安装) windows执行./script/py_build.sh可能会不支持,可以打开PowerShell(没有该软件可以下载安装)执行以下命令:
mkdir build
cd build
cmake ..
make -j4
cd ..2、运行模型
2.1 下载模型
基于以下命令可以下载模型
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen2-VL-2B-Instruct',cache_dir=".cache_dir")
2.2 模型导出
需要在liunx环境下执行,windows环境可以安装wsl虚拟linux环境,然后安装torch等环境
linux下执行
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/pip install onnx
pip install transformers
pip install yaspin
pip install mnn
导出模型的命令如下:
cd MNN/transformers/llm/exportpython llmexport.py --path /mnt/f/DMT/.cache_dir/qwen/Qwen2-VL-2B-Instruct --export mnn --quant_bit 8 --quant_block 128

模型默认导出到model目录下。
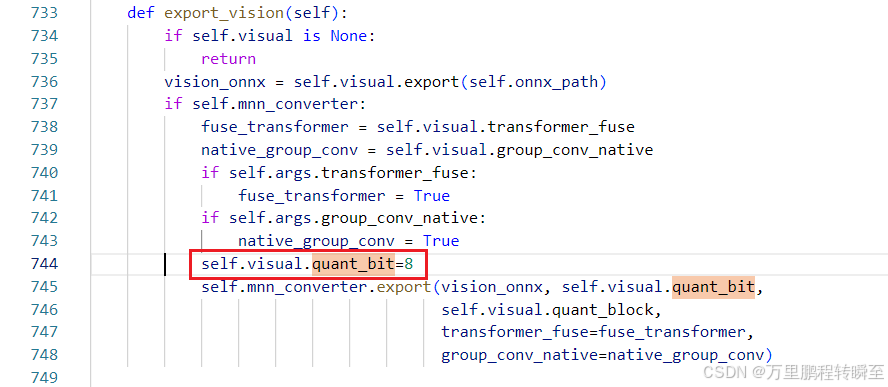
关于vit部分的量化,可以手动设置llmexport.py中的值。
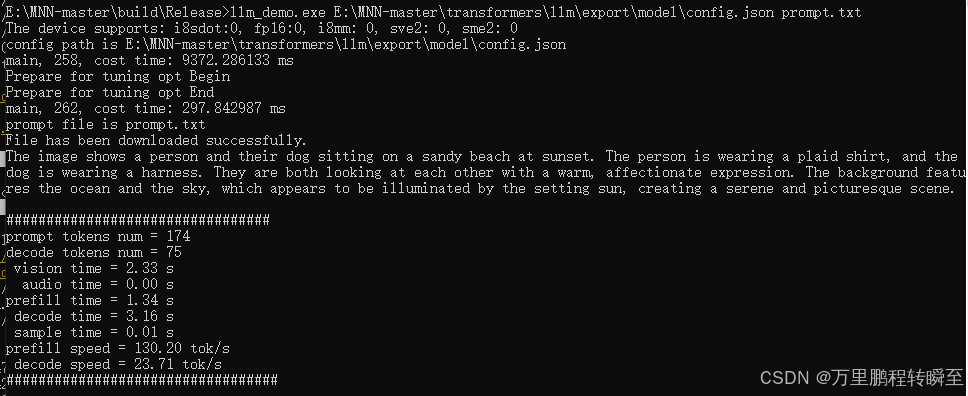
2.3 llm_demo推理
构建prompt.txt
#基于以下命令,可以将 命令写入txt
echo "<img><hw>280, 420</hw>https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg</img>Describe the content of the image." > prompt.txt
2.4 llm_demo.cpp
llm_demo对应源码 E:\MNN-master\transformers\llm\engine\demo\llm_demo.cpp
对应的cmakelist路径为: E:\MNN-master\transformers\llm\engine\CMakeLists.txt
//
// llm_demo.cpp
//
// Created by MNN on 2023/03/24.
// ZhaodeWang
//#include "llm/llm.hpp"
#define MNN_OPEN_TIME_TRACE
#include <MNN/AutoTime.hpp>
#include <MNN/expr/ExecutorScope.hpp>
#include <fstream>
#include <sstream>
#include <stdlib.h>
#include <initializer_list>
//#define LLM_SUPPORT_AUDIO
#ifdef LLM_SUPPORT_AUDIO
#include "audio/audio.hpp"
#endif
using namespace MNN::Transformer;static void tuning_prepare(Llm* llm) {MNN_PRINT("Prepare for tuning opt Begin\n");llm->tuning(OP_ENCODER_NUMBER, {1, 5, 10, 20, 30, 50, 100});MNN_PRINT("Prepare for tuning opt End\n");
}std::vector<std::vector<std::string>> parse_csv(const std::vector<std::string>& lines) {std::vector<std::vector<std::string>> csv_data;std::string line;std::vector<std::string> row;std::string cell;bool insideQuotes = false;bool startCollecting = false;// content to streamstd::string content = "";for (auto line : lines) {content = content + line + "\n";}std::istringstream stream(content);while (stream.peek() != EOF) {char c = stream.get();if (c == '"') {if (insideQuotes && stream.peek() == '"') { // quotecell += '"';stream.get(); // skip quote} else {insideQuotes = !insideQuotes; // start or end text in quote}startCollecting = true;} else if (c == ',' && !insideQuotes) { // end element, start new elementrow.push_back(cell);cell.clear();startCollecting = false;} else if ((c == '\n' || stream.peek() == EOF) && !insideQuotes) { // end linerow.push_back(cell);csv_data.push_back(row);cell.clear();row.clear();startCollecting = false;} else {cell += c;startCollecting = true;}}return csv_data;
}static int benchmark(Llm* llm, const std::vector<std::string>& prompts, int max_token_number) {int prompt_len = 0;int decode_len = 0;int64_t vision_time = 0;int64_t audio_time = 0;int64_t prefill_time = 0;int64_t decode_time = 0;int64_t sample_time = 0;// llm->warmup();auto context = llm->getContext();if (max_token_number > 0) {llm->set_config("{\"max_new_tokens\":1}");}
#ifdef LLM_SUPPORT_AUDIOstd::vector<float> waveform;llm->setWavformCallback([&](const float* ptr, size_t size, bool last_chunk) {waveform.reserve(waveform.size() + size);waveform.insert(waveform.end(), ptr, ptr + size);if (last_chunk) {auto waveform_var = MNN::Express::_Const(waveform.data(), {(int)waveform.size()}, MNN::Express::NCHW, halide_type_of<float>());MNN::AUDIO::save("output.wav", waveform_var, 24000);waveform.clear();}return true;});
#endiffor (int i = 0; i < prompts.size(); i++) {auto prompt = prompts[i];// #define MIMO_NO_THINKING#ifdef MIMO_NO_THINKING// update config.json and llm_config.json if need. example:llm->set_config("{\"assistant_prompt_template\":\"<|im_start|>assistant\\n<think>\\n</think>\%s<|im_end|>\\n\"}");prompt = prompt + "<think>\n</think>";#endif// prompt start with '#' will be ignoredif (prompt.substr(0, 1) == "#") {continue;}if (max_token_number >= 0) {llm->response(prompt, &std::cout, nullptr, 0);while (!llm->stoped() && context->gen_seq_len < max_token_number) {llm->generate(1);}} else {llm->response(prompt);}prompt_len += context->prompt_len;decode_len += context->gen_seq_len;vision_time += context->vision_us;audio_time += context->audio_us;prefill_time += context->prefill_us;decode_time += context->decode_us;sample_time += context->sample_us;}llm->generateWavform();float vision_s = vision_time / 1e6;float audio_s = audio_time / 1e6;float prefill_s = prefill_time / 1e6;float decode_s = decode_time / 1e6;float sample_s = sample_time / 1e6;printf("\n#################################\n");printf("prompt tokens num = %d\n", prompt_len);printf("decode tokens num = %d\n", decode_len);printf(" vision time = %.2f s\n", vision_s);printf(" audio time = %.2f s\n", audio_s);printf("prefill time = %.2f s\n", prefill_s);printf(" decode time = %.2f s\n", decode_s);printf(" sample time = %.2f s\n", sample_s);printf("prefill speed = %.2f tok/s\n", prompt_len / prefill_s);printf(" decode speed = %.2f tok/s\n", decode_len / decode_s);printf("##################################\n");return 0;
}static int ceval(Llm* llm, const std::vector<std::string>& lines, std::string filename) {auto csv_data = parse_csv(lines);int right = 0, wrong = 0;std::vector<std::string> answers;for (int i = 1; i < csv_data.size(); i++) {const auto& elements = csv_data[i];std::string prompt = elements[1];prompt += "\n\nA. " + elements[2];prompt += "\nB. " + elements[3];prompt += "\nC. " + elements[4];prompt += "\nD. " + elements[5];prompt += "\n\n";printf("%s", prompt.c_str());printf("## 杩涘害: %d / %lu\n", i, lines.size() - 1);std::ostringstream lineOs;llm->response(prompt.c_str(), &lineOs);auto line = lineOs.str();printf("%s", line.c_str());answers.push_back(line);}{auto position = filename.rfind("/");if (position != std::string::npos) {filename = filename.substr(position + 1, -1);}position = filename.find("_val");if (position != std::string::npos) {filename.replace(position, 4, "_res");}std::cout << "store to " << filename << std::endl;}std::ofstream ofp(filename);ofp << "id,answer" << std::endl;for (int i = 0; i < answers.size(); i++) {auto& answer = answers[i];ofp << i << ",\""<< answer << "\"" << std::endl;}ofp.close();return 0;
}static int eval(Llm* llm, std::string prompt_file, int max_token_number) {std::cout << "prompt file is " << prompt_file << std::endl;std::ifstream prompt_fs(prompt_file);std::vector<std::string> prompts;std::string prompt;
//#define LLM_DEMO_ONELINE
#ifdef LLM_DEMO_ONELINEstd::ostringstream tempOs;tempOs << prompt_fs.rdbuf();prompt = tempOs.str();prompts = {prompt};
#elsewhile (std::getline(prompt_fs, prompt)) {if (prompt.empty()) {continue;}if (prompt.back() == '\r') {prompt.pop_back();}prompts.push_back(prompt);}
#endifprompt_fs.close();if (prompts.empty()) {return 1;}// cevalif (prompts[0] == "id,question,A,B,C,D,answer") {return ceval(llm, prompts, prompt_file);}return benchmark(llm, prompts, max_token_number);
}void chat(Llm* llm) {ChatMessages messages;messages.emplace_back("system", "You are a helpful assistant.");auto context = llm->getContext();while (true) {std::cout << "\nUser: ";std::string user_str;std::getline(std::cin, user_str);if (user_str == "/exit") {return;}if (user_str == "/reset") {llm->reset();std::cout << "\nA: reset done." << std::endl;continue;}messages.emplace_back("user", user_str);std::cout << "\nA: " << std::flush;llm->response(messages);auto assistant_str = context->generate_str;messages.emplace_back("assistant", assistant_str);}
}
int main(int argc, const char* argv[]) {if (argc < 2) {std::cout << "Usage: " << argv[0] << " config.json <prompt.txt>" << std::endl;return 0;}MNN::BackendConfig backendConfig;auto executor = MNN::Express::Executor::newExecutor(MNN_FORWARD_CPU, backendConfig, 1);MNN::Express::ExecutorScope s(executor);std::string config_path = argv[1];std::cout << "config path is " << config_path << std::endl;std::unique_ptr<Llm> llm(Llm::createLLM(config_path));llm->set_config("{\"tmp_path\":\"tmp\"}");{AUTOTIME;llm->load();}if (true) {AUTOTIME;tuning_prepare(llm.get());}if (argc < 3) {chat(llm.get());return 0;}int max_token_number = -1;if (argc >= 4) {std::istringstream os(argv[3]);os >> max_token_number;}if (argc >= 5) {MNN_PRINT("Set not thinking, only valid for Qwen3\n");llm->set_config(R"({"jinja": {"context": {"enable_thinking":false}}})");}std::string prompt_file = argv[2];return eval(llm.get(), prompt_file, max_token_number);
}