Python - 100天从新手到大师 - Day6
引言
这里主要是依托于 jackfrued 仓库 Python-100-Days 进行学习,记录自己的学习过程和心得体会。
1 文件读写和异常处理
实际开发中常常会遇到对数据进行持久化的场景,所谓持久化是指将数据从无法长久保存数据的存储介质(通常是内存)转移到可以长久保存数据的存储介质(通常是硬盘)中。实现数据持久化最直接简单的方式就是通过文件系统将数据保存到文件中。
计算机的文件系统是一种存储和组织计算机数据的方法,它使得对数据的访问和查找变得容易,文件系统使用文件和树形目录的抽象逻辑概念代替了硬盘、光盘、闪存等物理设备的数据块概念,用户使用文件系统来保存数据时,不必关心数据实际保存在硬盘的哪个数据块上,只需要记住这个文件的路径和文件名。在写入新数据之前,用户不必关心硬盘上的哪个数据块没有被使用,硬盘上的存储空间管理(分配和释放)功能由文件系统自动完成,用户只需要记住数据被写入到了哪个文件中。
1.1 打开和关闭文件
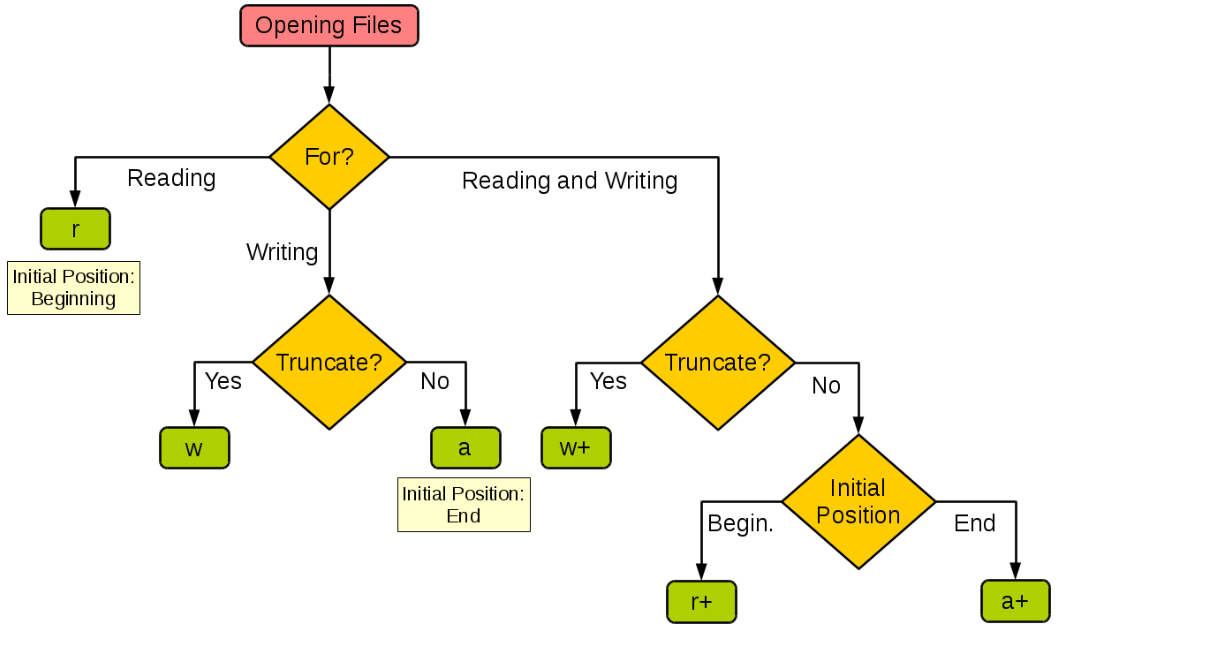
有了文件系统,我们可以非常方便的通过文件来读写数据;在Python中要实现文件操作是非常简单的。我们可以使用Python内置的open函数来打开文件,在使用open函数时,我们可以通过函数的参数指定文件名、操作模式和字符编码等信息,接下来就可以对文件进行读写操作了。这里所说的操作模式是指要打开什么样的文件(字符文件或二进制文件)以及做什么样的操作(读、写或追加),具体如下表所示。
| 操作模式 | 具体含义 |
|---|---|
'r' | 读取 (默认) |
'w' | 写入(会先截断之前的内容) |
'x' | 写入,如果文件已经存在会产生异常 |
'a' | 追加,将内容写入到已有文件的末尾 |
'b' | 二进制模式 |
't' | 文本模式(默认) |
'+' | 更新(既可以读又可以写) |
下图展示了如何根据程序的需要来设置open函数的操作模式。
在使用open函数时,如果打开的文件是字符文件(文本文件),可以通过encoding参数来指定读写文件使用的字符编码。如果对字符编码和字符集这些概念不了解,可以看看《字符集和字符编码》一文,此处不再进行赘述。
使用open函数打开文件成功后会返回一个文件对象,通过这个对象,我们就可以实现对文件的读写操作;如果打开文件失败,open函数会引发异常,稍后会对此加以说明。如果要关闭打开的文件,可以使用文件对象的close方法,这样可以在结束文件操作时释放掉这个文件。
1.2 读写文本文件
用open函数打开文本文件时,需要指定文件名并将文件的操作模式设置为'r',如果不指定,默认值也是'r';如果需要指定字符编码,可以传入encoding参数,如果不指定,默认值是None,那么在读取文件时使用的是操作系统默认的编码。需要提醒大家,如果不能保证保存文件时使用的编码方式与encoding参数指定的编码方式是一致的,那么就可能因无法解码字符而导致读取文件失败。
下面的例子演示了如何读取一个纯文本文件(一般指只有字符原生编码构成的文件,与富文本相比,纯文本不包含字符样式的控制元素,能够被最简单的文本编辑器直接读取)。
file = open('致橡树.txt', 'r', encoding='utf-8')
print(file.read())
file.close()

说明:《致橡树》是舒婷老师在1977年3月创建的爱情诗,也是我最喜欢的现代诗之一。
除了使用文件对象的read方法读取文件之外,还可以使用for-in循环逐行读取或者用readlines方法将文件按行读取到一个列表容器中,代码如下所示。
file = open('致橡树.txt', 'r', encoding='utf-8')
for line in file:print(line, end='')
file.close()file = open('致橡树.txt', 'r', encoding='utf-8')
lines = file.readlines()
for line in lines:print(line, end='')
file.close()
如果要向文件中写入内容,可以在打开文件时使用w或者a作为操作模式,前者会截断之前的文本内容写入新的内容,后者是在原来内容的尾部追加新的内容。
file = open("致橡树.txt", 'a+', encoding="utf-8")
file.write('\n\n标题:《致橡树》')
file.write('\n作者:舒婷')
file.write('\n时间:1977年3月')# 关键:将文件指针移动到开头
file.seek(0)lines = file.readlines()
for line in lines:print(line, end='')
file.close()
1.3 异常处理机制
请注意上面的代码,如果open函数指定的文件并不存在或者无法打开,那么将引发异常状况导致程序崩溃。为了让代码具有健壮性和容错性,我们可以使用Python的异常机制对可能在运行时发生状况的代码进行适当的处理。Python中和异常相关的关键字有五个,分别是try、except、else、finally和raise,我们先看看下面的代码,再来为大家介绍这些关键字的用法。
file = None
try:file = open('致橡树.txt', 'r', encoding='utf-8')print(file.read())
except FileNotFoundError:print('无法打开指定的文件!')
except LookupError:print('指定了未知的编码!')
except UnicodeDecodeError:print('读取文件时解码错误!')
finally:if file:file.close()
在Python中,我们可以将运行时会出现状况的代码放在try代码块中,在try后面可以跟上一个或多个except块来捕获异常并进行相应的处理。例如,在上面的代码中,文件找不到会引发FileNotFoundError,指定了未知的编码会引发LookupError,而如果读取文件时无法按指定编码方式解码文件会引发UnicodeDecodeError,所以我们在try后面跟上了三个except分别处理这三种不同的异常状况。在except后面,我们还可以加上else代码块,这是try 中的代码没有出现异常时会执行的代码,而且else中的代码不会再进行异常捕获,也就是说如果遇到异常状况,程序会因异常而终止并报告异常信息。最后我们使用finally代码块来关闭打开的文件,释放掉程序中获取的外部资源。由于finally块的代码不论程序正常还是异常都会执行,甚至是调用了sys模块的exit函数终止Python程序,finally块中的代码仍然会被执行(因为exit函数的本质是引发了SystemExit异常),因此我们把finally代码块称为“总是执行代码块”,它最适合用来做释放外部资源的操作。
Python中内置了大量的异常类型,除了上面代码中用到的异常类型以及之前的课程中遇到过的异常类型外,还有许多的异常类型,其继承结构如下所示。
BaseException+-- SystemExit+-- KeyboardInterrupt+-- GeneratorExit+-- Exception+-- StopIteration+-- StopAsyncIteration+-- ArithmeticError| +-- FloatingPointError| +-- OverflowError| +-- ZeroDivisionError+-- AssertionError+-- AttributeError+-- BufferError+-- EOFError+-- ImportError| +-- ModuleNotFoundError+-- LookupError| +-- IndexError| +-- KeyError+-- MemoryError+-- NameError| +-- UnboundLocalError+-- OSError| +-- BlockingIOError| +-- ChildProcessError| +-- ConnectionError| | +-- BrokenPipeError| | +-- ConnectionAbortedError| | +-- ConnectionRefusedError| | +-- ConnectionResetError| +-- FileExistsError| +-- FileNotFoundError| +-- InterruptedError| +-- IsADirectoryError| +-- NotADirectoryError| +-- PermissionError| +-- ProcessLookupError| +-- TimeoutError+-- ReferenceError+-- RuntimeError| +-- NotImplementedError| +-- RecursionError+-- SyntaxError| +-- IndentationError| +-- TabError+-- SystemError+-- TypeError+-- ValueError| +-- UnicodeError| +-- UnicodeDecodeError| +-- UnicodeEncodeError| +-- UnicodeTranslateError+-- Warning+-- DeprecationWarning+-- PendingDeprecationWarning+-- RuntimeWarning+-- SyntaxWarning+-- UserWarning+-- FutureWarning+-- ImportWarning+-- UnicodeWarning+-- BytesWarning+-- ResourceWarning
从上面的继承结构可以看出,Python中所有的异常都是BaseException的子类型,它有四个直接的子类,分别是:SystemExit、KeyboardInterrupt、GeneratorExit和Exception。其中:
SystemExit表示解释器请求退出;KeyboardInterrupt是用户中断程序执行(按下Ctrl+c);GeneratorExit表示生成器发生异常通知退出,不理解这些异常没有关系,继续学习就好了。- 值得一提的是
Exception类,它是常规异常类型的父类型,很多的异常都是直接或间接的继承自Exception类。
如果Python内置的异常类型不能满足应用程序的需要,我们可以自定义异常类型,而自定义的异常类型也应该直接或间接继承自Exception类,当然还可以根据需要重写或添加方法。
在Python中,可以使用raise关键字来引发异常(抛出异常对象),而调用者可以通过try...except...结构来捕获并处理异常。例如在函数中,当函数的执行条件不满足时,可以使用抛出异常的方式来告知调用者问题的所在,而调用者可以通过捕获处理异常来使得代码从异常中恢复,定义异常和抛出异常的代码如下所示。
class InputError(ValueError):"""自定义异常类型"""passdef fac(num):"""求阶乘"""if num < 0:raise InputError('只能计算非负整数的阶乘')if num in (0, 1):return 1return num * fac(num - 1)fac(-1)
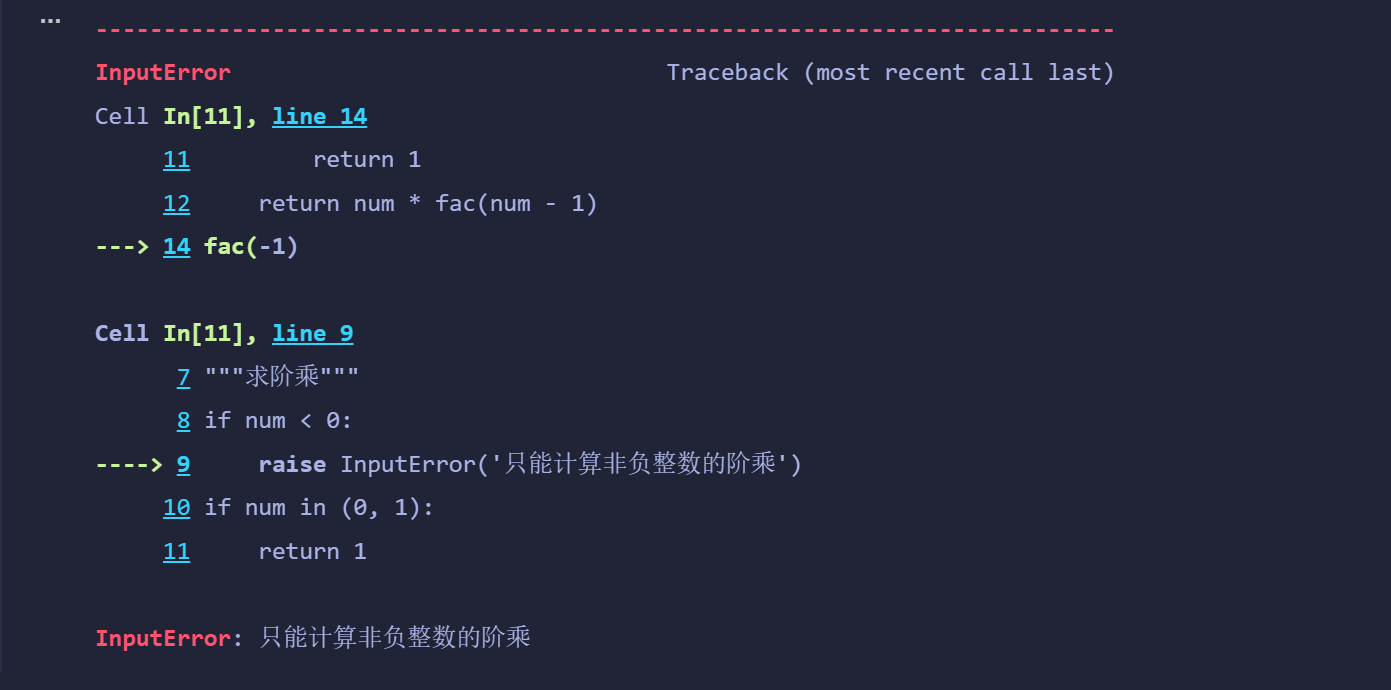
调用求阶乘的函数fac,通过try...except...结构捕获输入错误的异常并打印异常对象(显示异常信息),如果输入正确就计算阶乘并结束程序。
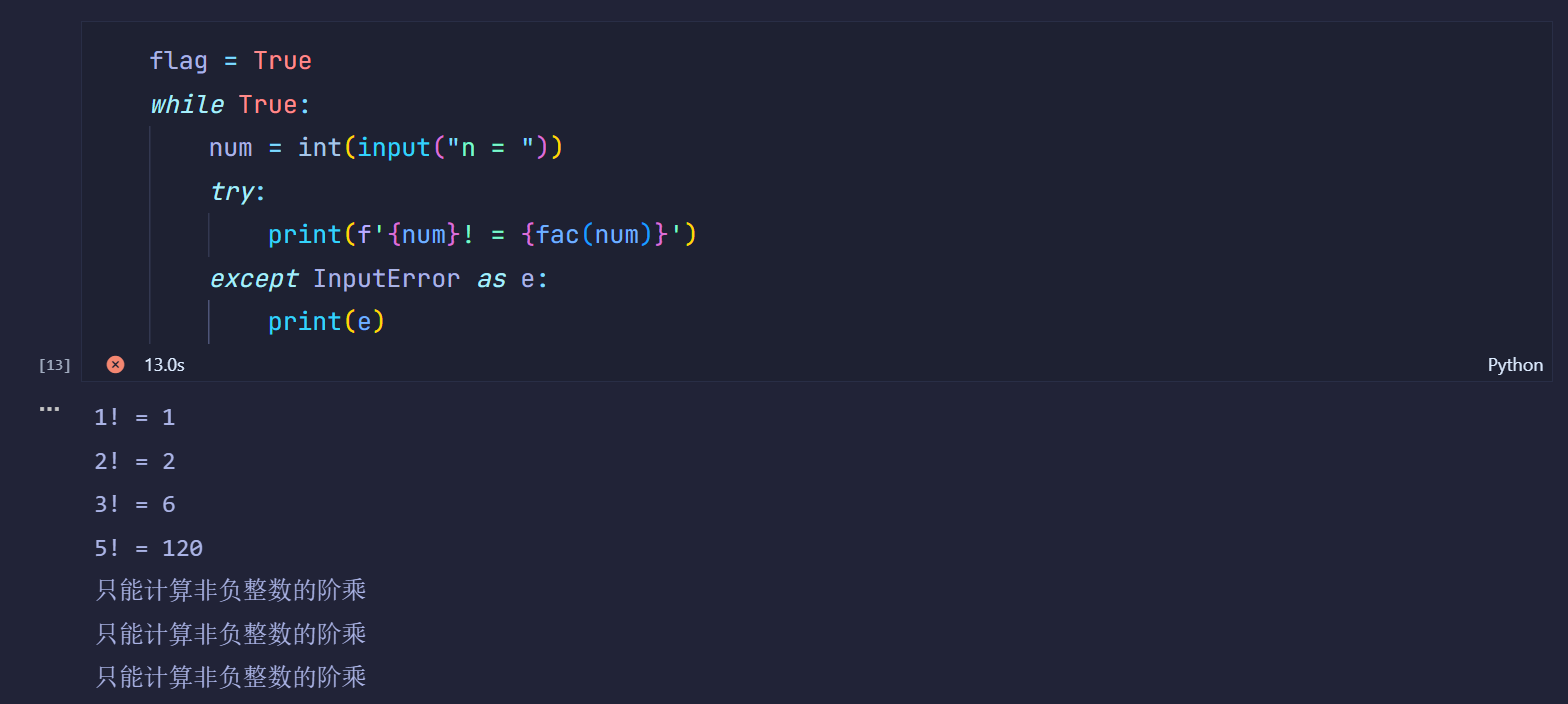
flag = True
while flag:num = int(input('n = '))try:print(f'{num}! = {fac(num)}')flag = Falseexcept InputError as err:print(err)
1.4 上下文管理器语法
对于open函数返回的文件对象,还可以使用with上下文管理器语法在文件操作完成后自动执行文件对象的close方法,这样可以让代码变得更加简单优雅,因为不需要再写finally代码块来执行关闭文件释放资源的操作。需要提醒大家的是,并不是所有的对象都可以放在with上下文语法中,只有符合上下文管理器协议(有__enter__和__exit__魔术方法)的对象才能使用这种语法,Python标准库中的contextlib模块也提供了对with上下文语法的支持,后面再为大家进行讲解。
用with上下文语法改写后的代码如下所示。
try:with open('致橡树.txt', 'r', encoding='utf-8') as file:print(file.read())
except FileNotFoundError:print('无法打开指定的文件!')
except LookupError:print('指定了未知的编码!')
except UnicodeDecodeError:print('读取文件时解码错误!')
1.5 读写二进制文件
读写二进制文件跟读写文本文件的操作类似,但是需要注意,在使用open函数打开文件时,如果要进行读操作,操作模式是'rb',如果要进行写操作,操作模式是'wb'。还有一点,读写文本文件时,read方法的返回值以及write方法的参数是str对象(字符串),而读写二进制文件时,read方法的返回值以及write方法的参数是bytes-like对象(字节串)。下面的代码实现了将当前路径下名为Penry.jpg的图片文件复制到BIT.jpg文件中的操作。
try:with open('Penry.jpg', 'rb') as file1:data = file1.read()with open('BIT.jpg', 'wb') as file2:file2.write(data)
except FileNotFoundError:print('指定的文件无法打开.')
except IOError:print('读写文件时出现错误.')
print('程序执行结束.')
如果要复制的图片文件很大,一次将文件内容直接读入内存中可能会造成非常大的内存开销,为了减少对内存的占用,可以为read方法传入size参数来指定每次读取的字节数,通过循环读取和写入的方式来完成上面的操作,代码如下所示。
try:with open('guido.jpg', 'rb') as file1, open('吉多.jpg', 'wb') as file2:data = file1.read(512)while data:file2.write(data)data = file1.read()
except FileNotFoundError:print('指定的文件无法打开.')
except IOError:print('读写文件时出现错误.')
print('程序执行结束.')
1.6 总结
通过读写文件的操作,我们可以实现数据持久化。在Python中可以通过open函数来获得文件对象,可以通过文件对象的read和write方法实现文件读写操作。程序在运行时可能遭遇无法预料的异常状况,可以使用Python的异常机制来处理这些状况。Python的异常机制主要包括try、except、else、finally和raise这五个核心关键字。try后面的except语句不是必须的,finally语句也不是必须的,但是二者必须要有一个;except语句可以有一个或多个,多个except会按照书写的顺序依次匹配指定的异常,如果异常已经处理就不会再进入后续的except语句;except语句中还可以通过元组同时指定多个异常类型进行捕获;except语句后面如果不指定异常类型,则默认捕获所有异常;捕获异常后可以使用raise要再次抛出,但是不建议捕获并抛出同一个异常;不建议在不清楚逻辑的情况下捕获所有异常,这可能会掩盖程序中严重的问题。最后强调一点,不要使用异常机制来处理正常业务逻辑或控制程序流程,简单的说就是不要滥用异常机制,这是初学者常犯的错误。
2 对象的序列化和反序列化
2.1 JSON概述
通过上面的讲解,我们已经知道如何将文本数据和二进制数据保存到文件中,那么这里还有一个问题,如果希望把一个列表或者一个字典中的数据保存到文件中又该怎么做呢?在Python中,我们可以将程序中的数据以JSON格式进行保存。JSON是“JavaScript Object Notation”的缩写,它本来是JavaScript语言中创建对象的一种字面量语法,现在已经被广泛的应用于跨语言跨平台的数据交换。使用JSON的原因非常简单,因为它结构紧凑而且是纯文本,任何操作系统和编程语言都能处理纯文本,这就是实现跨语言跨平台数据交换的前提条件。目前JSON基本上已经取代了XML(可扩展标记语言)作为异构系统间交换数据的事实标准。可以在JSON的官方网站找到更多关于JSON的知识,这个网站还提供了每种语言处理JSON数据格式可以使用的工具或三方库。
{name: "Penry",age: 21,friends: ["Taco", "Cruise"],cars: [{"brand": "BMW", "max_speed": 240},{"brand": "Benz", "max_speed": 280},{"brand": "Audi", "max_speed": 280}]
}
上面是JSON的一个简单例子,大家可能已经注意到了,它跟Python中的字典非常类似而且支持嵌套结构,就好比Python字典中的值可以是另一个字典。我们可以尝试把下面的代码输入浏览器的控制台(对于Chrome浏览器,可以通过“更多工具”菜单找到“开发者工具”子菜单,就可以打开浏览器的控制台),浏览器的控制台提供了一个运行JavaScript代码的交互式环境(类似于Python的交互式环境),下面的代码会帮我们创建出一个JavaScript的对象,我们将其赋值给名为obj的变量。
let obj = {name: "Penry",age: 21,friends: ["Taco", "Cruise"],cars: [{"brand": "BMW", "max_speed": 240},{"brand": "Benz", "max_speed": 280},{"brand": "Audi", "max_speed": 280}]
}
上面的obj就是JavaScript中的一个对象,我们可以通过obj.name或obj["name"]两种方式获取到name对应的值,如下图所示。可以注意到,obj["name"]这种获取数据的方式跟Python字典通过键获取值的索引操作是完全一致的,而Python中也通过名为json的模块提供了字典与JSON双向转换的支持。
我们在JSON中使用的数据类型(JavaScript数据类型)和Python中的数据类型也是很容易找到对应关系的,大家可以看看下面的两张表。
表1:JavaScript数据类型(值)对应的Python数据类型(值)
| JSON | Python |
|---|---|
object | dict |
array | list |
string | str |
number | int / float |
number (real) | float |
boolean (true / false) | bool (True / False) |
null | None |
表2:Python数据类型(值)对应的JavaScript数据类型(值)
| Python | JSON |
|---|---|
dict | object |
list / tuple | array |
str | string |
int / float | number |
bool (True / False) | boolean (true / false) |
None | null |
2.2 读写JSON格式的数据
在Python中,如果要将字典处理成JSON格式(以字符串形式存在),可以使用json模块的dumps函数,代码如下所示。
import jsonmy_dict = {'name': 'Penry','age': 21,'friends': ['Taco', 'Cruise'],'cars': [{'brand': 'BMW', 'max_speed': 240},{'brand': 'Audi', 'max_speed': 280},{'brand': 'Benz', 'max_speed': 280}]
}
print(json.dumps(my_dict))
运行上面的代码,输出如下所示,可以注意到中文字符都是用Unicode编码显示的。
{"name": "Penry", "age": 21, "friends": ["Taco", "Cruise"], "cars": [{"brand": "BMW", "max_speed": 240}, {"brand": "Audi", "max_speed": 280}, {"brand": "Benz", "max_speed": 280}]}
如果要将字典处理成JSON格式并写入文本文件,只需要将dumps函数换成dump函数并传入文件对象即可,代码如下所示。
import jsonmy_dict = {'name': 'Penry','age': 21,'friends': ['Taco', 'Cruise'],'cars': [{'brand': 'BMW', 'max_speed': 240},{'brand': 'Audi', 'max_speed': 280},{'brand': 'Benz', 'max_speed': 280}]
}try:with open("data.json", "w") as file:json.dump(my_dict, file)
except Exception as e:print(e)# 验证json文件
try:with open("data.json", "r") as file:data = json.load(file)print(data)
except Exception as e:print(e)
执行上面的代码,会创建data.json文件,文件的内容跟上面代码的输出是一样的。
json模块有四个比较重要的函数,分别是:
dump- 将Python对象按照JSON格式序列化到文件中dumps- 将Python对象处理成JSON格式的字符串load- 将文件中的JSON数据反序列化成对象loads- 将字符串的内容反序列化成Python对象
这里出现了两个概念,一个叫序列化,一个叫反序列化,维基百科上的解释是:“序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换为可以存储或传输的形式,这样在需要的时候能够恢复到原先的状态,而且通过序列化的数据重新获取字节时,可以利用这些字节来产生原始对象的副本(拷贝)。与这个过程相反的动作,即从一系列字节中提取数据结构的操作,就是反序列化(deserialization)”。
我们可以通过下面的代码,读取上面创建的data.json文件,将JSON格式的数据还原成Python中的字典。
import jsonwith open('data.json', 'r') as file:my_dict = json.load(file)print(type(my_dict))print(my_dict)
2.3 包管理工具pip
Python标准库中的json模块在数据序列化和反序列化时性能并不是非常理想,为了解决这个问题,可以使用三方库ujson来替换json。所谓三方库,是指非公司内部开发和使用的,也不是来自于官方标准库的Python模块,这些模块通常由其他公司、组织或个人开发,所以被称为三方库。虽然Python语言的标准库虽然已经提供了诸多模块来方便我们的开发,但是对于一个强大的语言来说,它的生态圈一定也是非常繁荣的。
之前安装Python解释器时,默认情况下已经勾选了安装pip,大家可以在命令提示符或终端中通过pip --version来确定是否已经拥有了pip。pip是Python的包管理工具,通过pip可以查找、安装、卸载、更新Python的三方库或工具,macOS和Linux系统应该使用pip3。例如要安装替代json模块的ujson,可以使用下面的命令。
pip install ujson
在默认情况下,pip会访问https://pypi.org/simple/来获得三方库相关的数据,但是国内访问这个网站的速度并不是十分理想,因此国内用户可以使用豆瓣网提供的镜像来替代这个默认的下载源,操作如下所示。
pip install ujson
可以通过pip search命令根据名字查找需要的三方库,可以通过pip list命令来查看已经安装过的三方库。如果想更新某个三方库,可以使用pip install -U或pip install --upgrade;如果要删除某个三方库,可以使用pip uninstall命令。
搜索ujson三方库。
pip search ujsonmicropython-cpython-ujson (0.2) - MicroPython module ujson ported to CPython
pycopy-cpython-ujson (0.2) - Pycopy module ujson ported to CPython
ujson (3.0.0) - Ultra fast JSON encoder and decoder for Python
ujson-bedframe (1.33.0) - Ultra fast JSON encoder and decoder for Python
ujson-segfault (2.1.57) - Ultra fast JSON encoder and decoder for Python. Continuing development.
ujson-ia (2.1.1) - Ultra fast JSON encoder and decoder for Python (Internet Archive fork)
ujson-x (1.37) - Ultra fast JSON encoder and decoder for Python
ujson-x-legacy (1.35.1) - Ultra fast JSON encoder and decoder for Python
drf_ujson (1.2) - Django Rest Framework UJSON Renderer
drf-ujson2 (1.6.1) - Django Rest Framework UJSON Renderer
ujsonDB (0.1.0) - A lightweight and simple database using ujson.
fast-json (0.3.2) - Combines best parts of json and ujson for fast serialization
decimal-monkeypatch (0.4.3) - Python 2 performance patches: decimal to cdecimal, json to ujson for psycopg2
查看已经安装的三方库。
pip listPackage Version
----------------------------- ----------
aiohttp 3.5.4
alipay 0.7.4
altgraph 0.16.1
amqp 2.4.2
... ...
更新ujson三方库。
pip install -U ujson
删除ujson三方库。
pip uninstall -y ujson
提示:如果要更新
pip自身,对于macOS系统来说,可以使用命令pip install -U pip。在Windows系统上,可以将命令替换为python -m pip install -U --user pip。
2.4 使用网络API获取数据
如果想在我们自己的程序中显示天气、路况、航班等信息,这些信息我们自己没有能力提供,所以必须使用网络数据服务。目前绝大多数的网络数据服务(或称之为网络API)都是基于HTTP或HTTPS提供JSON格式的数据,我们可以通过Python程序发送HTTP请求给指定的URL(统一资源定位符),这个URL就是所谓的网络API,如果请求成功,它会返回HTTP响应,而HTTP响应的消息体中就有我们需要的JSON格式的数据。关于HTTP的相关知识,可以看看阮一峰的《HTTP协议入门》一文。
国内有很多提供网络API接口的网站,例如聚合数据、阿凡达数据等,这些网站上有免费的和付费的数据接口,国外的{API}Search网站也提供了类似的功能,有兴趣的可以自行研究。下面的例子演示了如何使用requests库(基于HTTP进行网络资源访问的三方库)访问网络API获取国内新闻并显示新闻标题和链接。在这个例子中,我们使用了名为天行数据的网站提供的国内新闻数据接口,其中的APIKey需要自己到网站上注册申请。在天行数据网站注册账号后会自动分配APIKey,但是要访问接口获取数据,需要绑定验证邮箱或手机,然后还要申请需要使用的接口,如下图所示。

Python通过URL接入网络,我们推荐大家使用requests三方库,它简单且强大,但需要自行安装。
pip install requests
获取国内新闻并显示新闻标题和链接。
import requests
import jsondef fetch_and_save_news():"""获取新闻数据并保存到data_news.json文件"""print("🚀 开始获取新闻数据...")try:# 发送API请求# 注意这里参数更换为自己的APIKEYresp = requests.get("https://apis.tianapi.com/guonei/index?key=APIKEY&num=10")if resp.status_code == 200:data_model = resp.json()print("✅ API请求成功!")# 检查返回的数据结构if 'result' in data_model and 'newslist' in data_model['result']:news_count = len(data_model['result']['newslist'])print(f"📊 获取到 {news_count} 条新闻")# 保存完整数据到 data_news.jsontry:with open("data_news.json", "w", encoding="utf-8") as file:json.dump(data_model, file, ensure_ascii=False, indent=4)print("💾 新闻数据已成功保存到 data_news.json")except Exception as e:print(f"❌ 保存文件时出错: {e}")return# 显示新闻标题预览print("\n📰 新闻列表预览:")print("=" * 80)for i, news in enumerate(data_model['result']['newslist'], 1):print(f"{i:2d}. 📝 {news['title']}")print(f" ⏰ 时间: {news['ctime']}")print(f" 📺 来源: {news['source']}")if news.get('picUrl'):print(f" 🖼️ 图片: 有")print("-" * 80)# 验证保存的文件print("\n🔍 验证保存的文件...")try:with open("data_news.json", "r", encoding="utf-8") as file:saved_data = json.load(file)saved_count = len(saved_data['result']['newslist'])print(f"✅ 文件验证成功!保存了 {saved_count} 条新闻")# 显示文件大小import osfile_size = os.path.getsize("data_news.json")print(f"📁 文件大小: {file_size} 字节 ({file_size/1024:.2f} KB)")except Exception as e:print(f"❌ 验证文件时出错: {e}")else:print("❌ API返回数据格式异常")print("返回的数据:", data_model)else:print(f"❌ 请求失败,状态码: {resp.status_code}")print(f"响应内容: {resp.text}")except requests.exceptions.RequestException as e:print(f"❌ 网络请求异常: {e}")except json.JSONDecodeError as e:print(f"❌ JSON解析错误: {e}")except Exception as e:print(f"❌ 发生未知错误: {e}")def read_saved_news():"""读取并显示保存的新闻数据"""print("\n" + "="*80)print("📖 读取保存的新闻数据...")print("="*80)try:with open("data_news.json", "r", encoding="utf-8") as file:data = json.load(file)if 'result' in data and 'newslist' in data['result']:newslist = data['result']['newslist']print(f"📊 文件中共有 {len(newslist)} 条新闻")print(f"📅 数据获取时间: {data.get('msg', '未知')}")# 显示详细新闻信息for i, news in enumerate(newslist, 1):print(f"\n📰 新闻 {i}:")print(f"📝 标题: {news['title']}")print(f"⏰ 时间: {news['ctime']}")print(f"📺 来源: {news['source']}")print(f"🔗 链接: {news['url']}")if news.get('description'):print(f"📄 描述: {news['description']}")if news.get('picUrl'):print(f"🖼️ 图片: {news['picUrl']}")print("-" * 60)else:print("❌ 文件格式异常")except FileNotFoundError:print("❌ 文件 data_news.json 不存在,请先运行获取新闻的功能")except json.JSONDecodeError:print("❌ 文件格式错误,不是有效的JSON文件")except Exception as e:print(f"❌ 读取文件时出错: {e}")if __name__ == "__main__":# 获取并保存新闻fetch_and_save_news()# 读取并显示保存的新闻read_saved_news()print("\n" + "="*80)print("✨ 程序执行完成!")print("📁 新闻数据已保存在 data_news.json 文件中")print("="*80)
上面的代码通过requests模块的get函数向天行数据的国内新闻接口发起了一次请求,如果请求过程没有出现问题,get函数会返回一个Response对象,通过该对象的status_code属性表示HTTP响应状态码,如果不理解没关系,你只需要关注它的值,如果值等于200或者其他2字头的值,那么我们的请求是成功的。通过Response对象的json()方法可以将返回的JSON格式的数据直接处理成Python字典,非常方便。天行数据国内新闻接口返回的JSON格式的数据(部分)如下图所示。
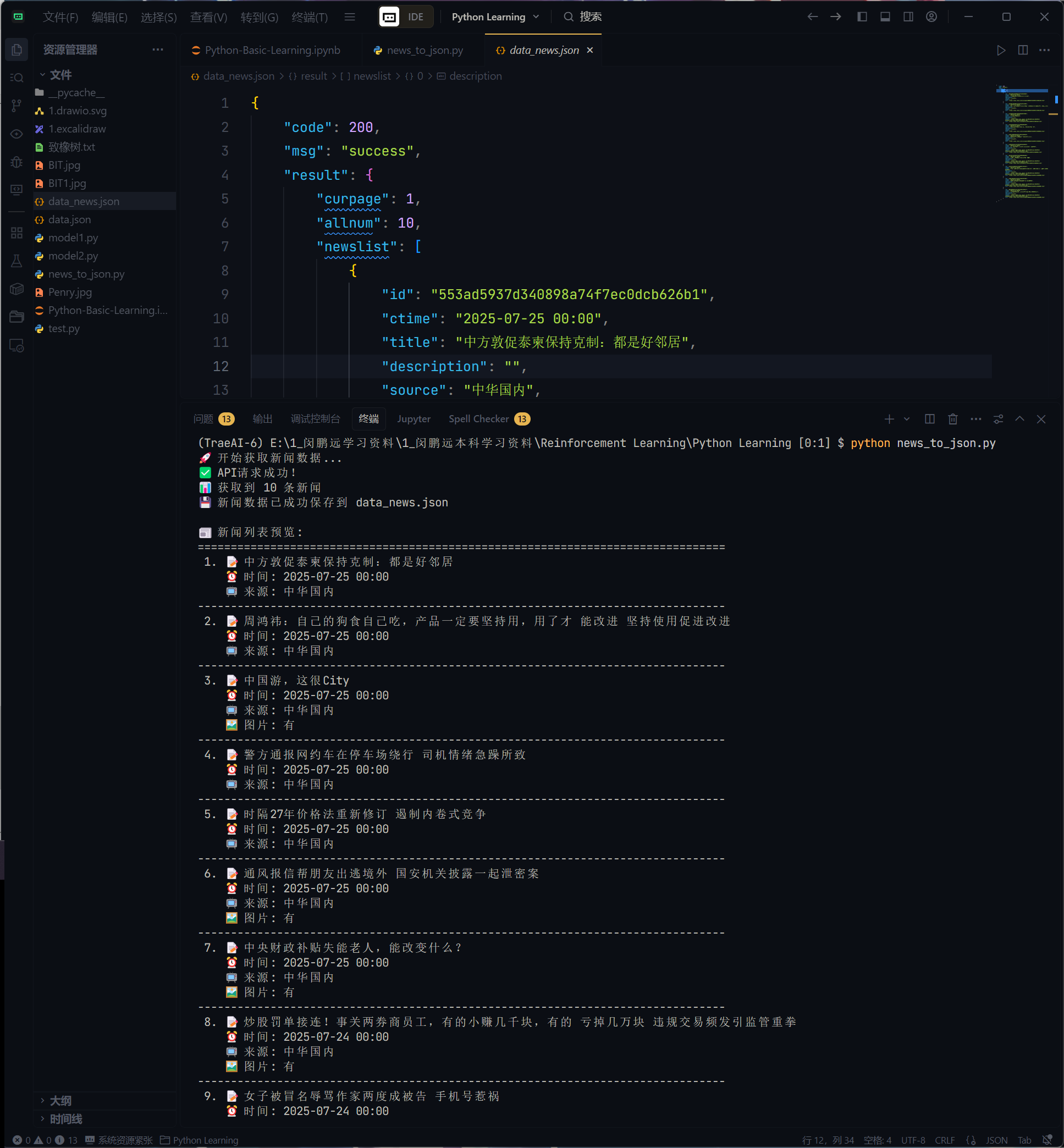
提示:上面代码中的APIKey需要换成自己在天行数据网站申请的APIKey。天行数据网站上还有提供了很多非常有意思的API接口,例如:垃圾分类、周公解梦等,大家可以仿照上面的代码来调用这些接口。每个接口都有对应的接口文档,文档中有关于如何使用接口的详细说明。
2.5 总结
Python中实现序列化和反序列化除了使用json模块之外,还可以使用pickle和shelve模块,但是这两个模块是使用特有的序列化协议来序列化数据,因此序列化后的数据只能被Python识别,关于这两个模块的相关知识,有兴趣的读者可以自己查找网络上的资料。处理JSON格式的数据很显然是程序员必须掌握的一项技能,因为不管是访问网络API接口还是提供网络API接口给他人使用,都需要具备处理JSON格式数据的相关知识。
3 Python读写CSV文件
3.1 CSV文件介绍
CSV(Comma Separated Values)全称逗号分隔值文件是一种简单、通用的文件格式,被广泛的应用于应用程序(数据库、电子表格等)数据的导入和导出以及异构系统之间的数据交换。因为CSV是纯文本文件,不管是什么操作系统和编程语言都是可以处理纯文本的,而且很多编程语言中都提供了对读写CSV文件的支持,因此CSV格式在数据处理和数据科学中被广泛应用。
CSV文件有以下特点:
- 纯文本,使用某种字符集(如ASCII、Unicode、GB2312)等);
- 由一条条的记录组成(典型的是每行一条记录);
- 每条记录被分隔符(如逗号、分号、制表符等)分隔为字段(列);
- 每条记录都有同样的字段序列。
CSV文件可以使用文本编辑器或类似于Excel电子表格这类工具打开和编辑,当使用Excel这类电子表格打开CSV文件时,你甚至感觉不到CSV和Excel文件的区别。很多数据库系统都支持将数据导出到CSV文件中,当然也支持从CSV文件中读入数据保存到数据库中,这些内容并不是现在要讨论的重点。
3.2 将数据写入CSV文件
现有五个学生三门课程的考试成绩需要保存到一个CSV文件中,要达成这个目标,可以使用Python标准库中的csv模块,该模块的writer函数会返回一个csvwriter对象,通过该对象的writerow或writerows方法就可以将数据写入到CSV文件中,具体的代码如下所示。
import csv
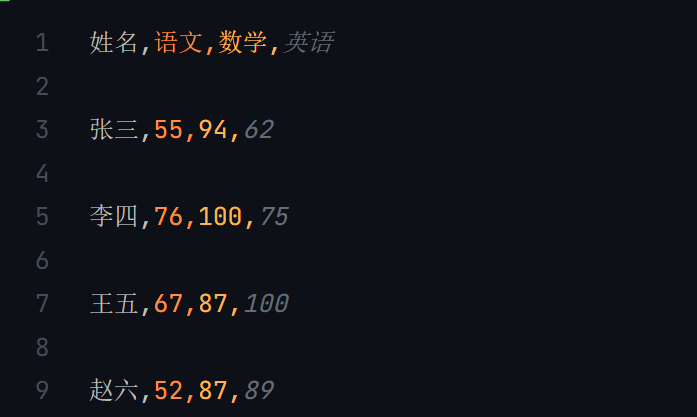
import randomwith open("scores.csv", "w") as f:writer = csv.writer(f)writer.writerow(["姓名", "语文", "数学", "英语"])names = ["张三", "李四", "王五", "赵六"]for name in names:scores = [random.randrange(50, 101) for _ in range(3)]scores.insert(0, name)writer.writerow(scores)
生成的CSV文件的内容。
需要说明的是上面的writer函数,除了传入要写入数据的文件对象外,还可以dialect参数,它表示CSV文件的方言,默认值是excel。除此之外,还可以通过delimiter、quotechar、quoting参数来指定分隔符(默认是逗号)、包围值的字符(默认是双引号)以及包围的方式。其中,包围值的字符主要用于当字段中有特殊符号时,通过添加包围值的字符可以避免二义性。大家可以尝试下面的代码,然后查看生成的CSV文件。
import csv
import randomwith open("scores_1.csv", "w") as f:writer = csv.writer(f, delimiter='|', quoting=csv.QUOTE_ALL)writer.writerow(["姓名", "语文", "数学", "英语"])names = ["张三", "李四", "王五", "赵六"]for name in names:scores = [random.randrange(50, 101) for _ in range(3)]scores.insert(0, name)writer.writerow(scores)生成的CSV文件的内容。

3.3 从CSV文件读取数据
如果要读取刚才创建的CSV文件,可以使用下面的代码,通过csv模块的reader函数可以创建出csvreader对象,该对象是一个迭代器,可以通过next函数或for-in循环读取到文件中的数据。
import csvwith open('scores_1.csv', 'r') as f:reader = csv.reader(f, delimiter='|')for data_list in reader:print(reader.line_num, end = '\t')for elem in data_list:print(elem, end = '\t')print()
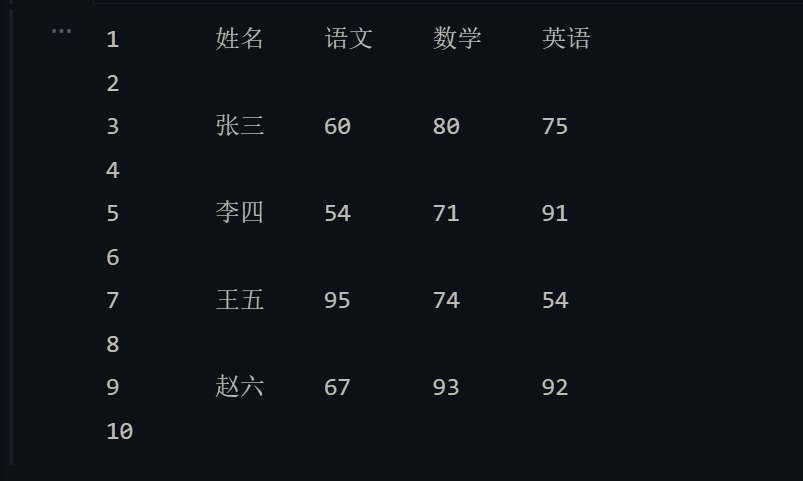
注意:上面的代码对
csvreader对象做for循环时,每次会取出一个列表对象,该列表对象包含了一行中所有的字段。
3.4 不同引用模式对比
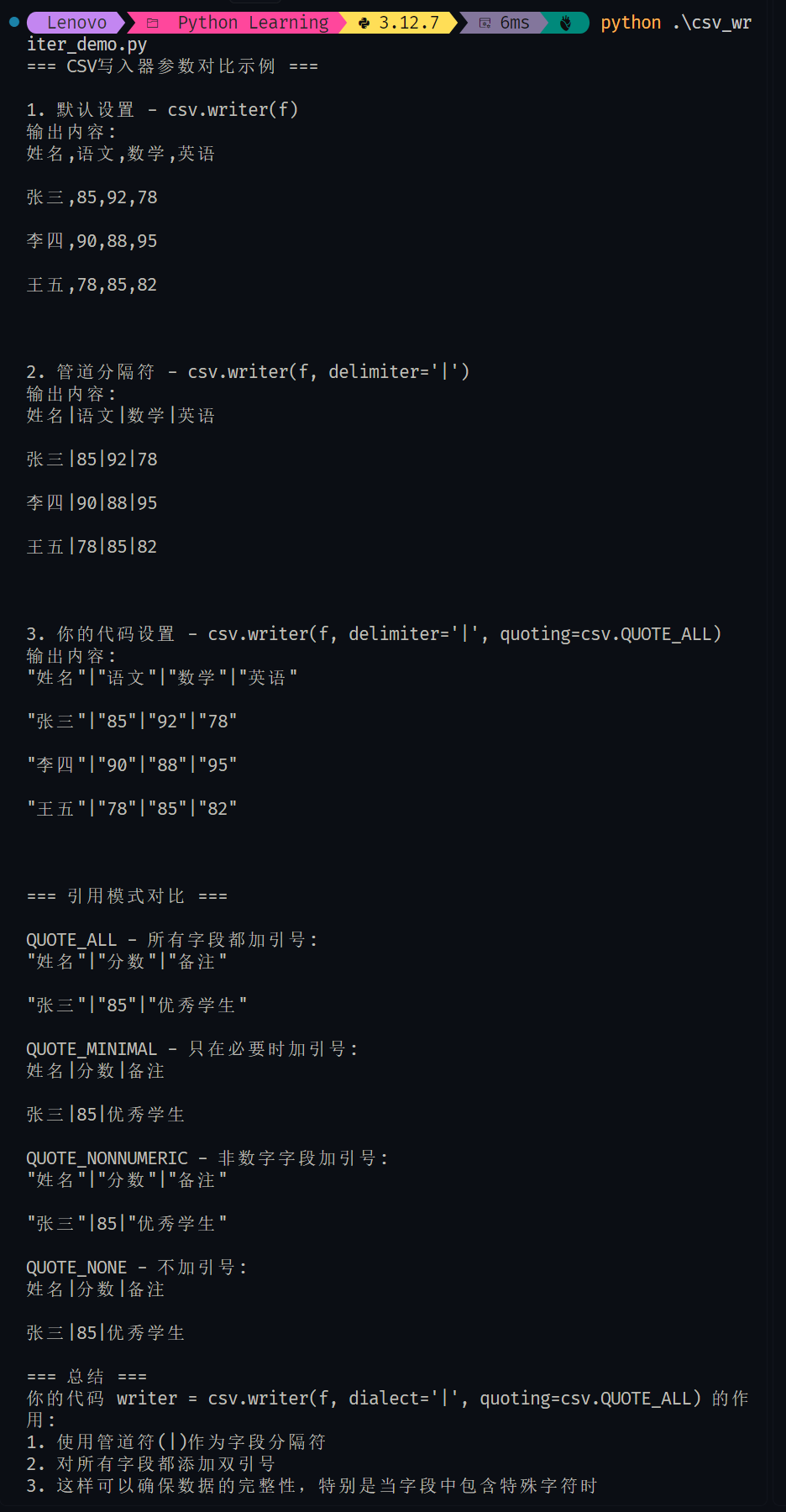
import csv# 示例数据
data = [["姓名", "语文", "数学", "英语"],["张三", 85, 92, 78],["李四", 90, 88, 95],["王五", 78, 85, 82]
]print("=== CSV写入器参数对比示例 ===\n")# 1. 默认设置(逗号分隔,智能引用)
print("1. 默认设置 - csv.writer(f)")
with open("example_default.csv", "w", encoding="utf-8") as f:writer = csv.writer(f)for row in data:writer.writerow(row)with open("example_default.csv", "r", encoding="utf-8") as f:content = f.read()print("输出内容:")print(content)# 2. 管道分隔符,默认引用
print("\n2. 管道分隔符 - csv.writer(f, delimiter='|')")
with open("example_pipe.csv", "w", encoding="utf-8") as f:writer = csv.writer(f, delimiter='|')for row in data:writer.writerow(row)with open("example_pipe.csv", "r", encoding="utf-8") as f:content = f.read()print("输出内容:")print(content)# 3. 管道分隔符 + 全部引用(你的代码)
print("\n3. 你的代码设置 - csv.writer(f, delimiter='|', quoting=csv.QUOTE_ALL)")
with open("example_pipe_quote_all.csv", "w", encoding="utf-8") as f:writer = csv.writer(f, delimiter='|', quoting=csv.QUOTE_ALL)for row in data:writer.writerow(row)with open("example_pipe_quote_all.csv", "r", encoding="utf-8") as f:content = f.read()print("输出内容:")print(content)# 4. 不同引用模式对比
print("\n=== 引用模式对比 ===")quote_modes = [(csv.QUOTE_ALL, "QUOTE_ALL - 所有字段都加引号"),(csv.QUOTE_MINIMAL, "QUOTE_MINIMAL - 只在必要时加引号"),(csv.QUOTE_NONNUMERIC, "QUOTE_NONNUMERIC - 非数字字段加引号"),(csv.QUOTE_NONE, "QUOTE_NONE - 不加引号")
]for mode, description in quote_modes:print(f"\n{description}:")try:with open(f"example_{mode}.csv", "w", encoding="utf-8") as f:writer = csv.writer(f, delimiter='|', quoting=mode)writer.writerow(["姓名", "分数", "备注"])writer.writerow(["张三", 85, "优秀学生"])with open(f"example_{mode}.csv", "r", encoding="utf-8") as f:content = f.read()print(content.strip())except Exception as e:print(f"错误: {e}")print("\n=== 总结 ===")
print("你的代码 writer = csv.writer(f, dialect='|', quoting=csv.QUOTE_ALL) 的作用:")
print("1. 使用管道符(|)作为字段分隔符")
print("2. 对所有字段都添加双引号")
print("3. 这样可以确保数据的完整性,特别是当字段中包含特殊字符时")
3.5 总结
将来如果大家使用Python做数据分析,很有可能会用到名为pandas的三方库,它是Python数据分析的神器之一。pandas中封装了名为read_csv和to_csv的函数用来读写CSV文件,其中read_CSV会将读取到的数据变成一个DataFrame对象,而DataFrame就是pandas库中最重要的类型,它封装了一系列用于数据处理的方法(清洗、转换、聚合等);而to_csv会将DataFrame对象中的数据写入CSV文件,完成数据的持久化。read_csv函数和to_csv函数远远比原生的csvreader和csvwriter强大。
4 Python读写Excel文件-1
4.1 Excel简介
Excel 是 Microsoft(微软)为使用 Windows 和 macOS 操作系统开发的一款电子表格软件。Excel 凭借其直观的界面、出色的计算功能和图表工具,再加上成功的市场营销,一直以来都是最为流行的个人计算机数据处理软件。当然,Excel 也有很多竞品,例如 Google Sheets、LibreOffice Calc、Numbers 等,这些竞品基本上也能够兼容 Excel,至少能够读写较新版本的 Excel 文件,当然这些不是我们讨论的重点。掌握用 Python 程序操作 Excel 文件,可以让日常办公自动化的工作更加轻松愉快,而且在很多商业项目中,导入导出 Excel 文件都是特别常见的功能。
Python 操作 Excel 需要三方库的支持,如果要兼容 Excel 2007 以前的版本,也就是xls格式的 Excel 文件,可以使用三方库xlrd和xlwt,前者用于读 Excel 文件,后者用于写 Excel 文件。如果使用较新版本的 Excel,即xlsx格式的 Excel 文件,可以使用openpyxl库,当然这个库不仅仅可以操作Excel,还可以操作其他基于 Office Open XML 的电子表格文件。
本章我们先讲解基于xlwt和xlrd操作 Excel 文件,大家可以先使用下面的命令安装这两个三方库以及配合使用的工具模块xlutils。
pip install xlwt xlrd xlutils
4.2 读Excel文件
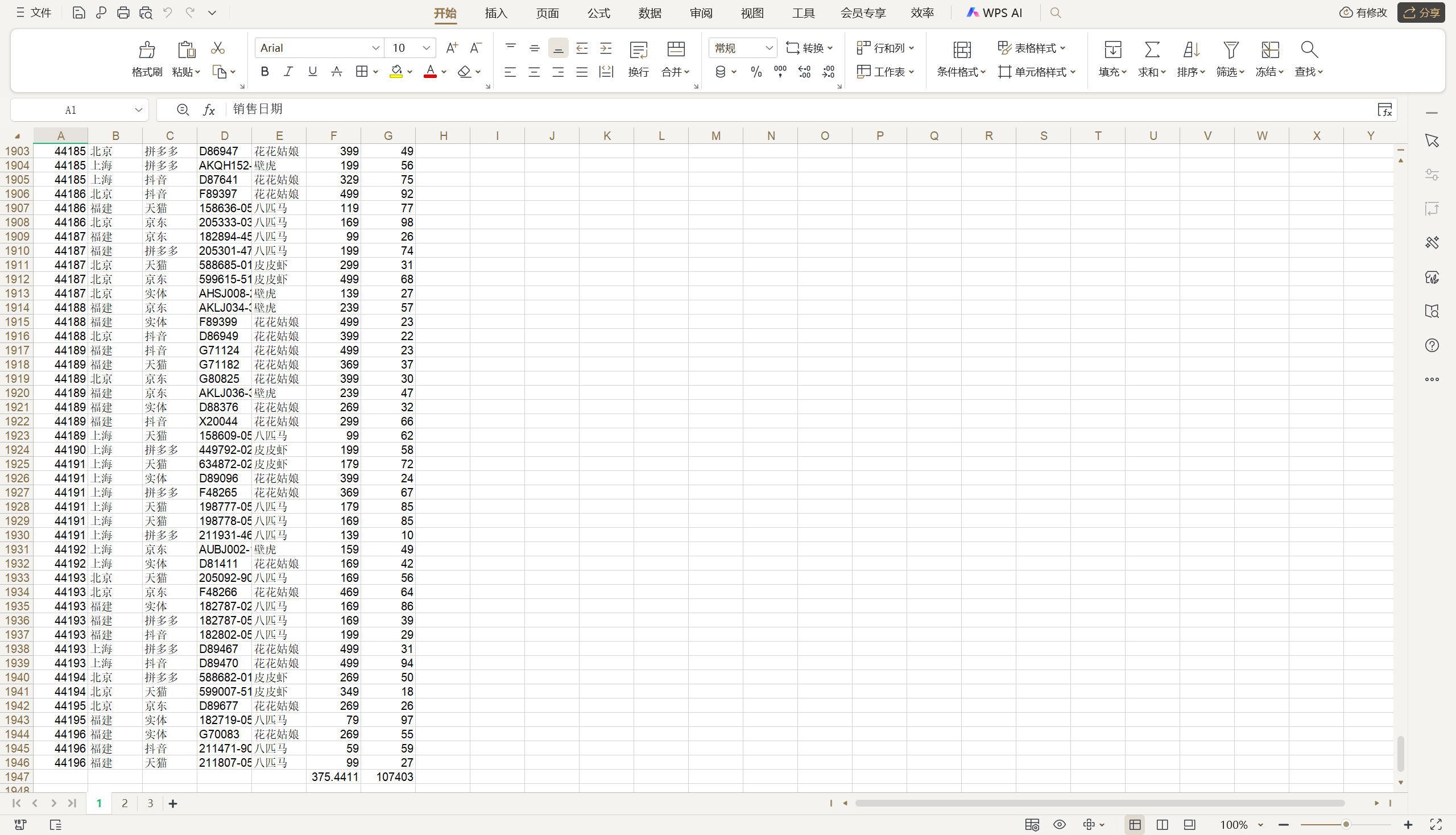
例如在当前文件夹下有一个名为“阿里巴巴2020年股票数据.xls”的 Excel 文件,如果想读取并显示该文件的内容,可以通过如下所示的代码来完成。
import xlrd# 使用xlrd模块的open_workbook函数打开指定Excel文件并获得Book对象(工作簿)
book = xlrd.open_workbook('data/阿里巴巴2020年股票数据.xls')
# 通过Book对象的sheet_names方法可以获取所有表单名称
sheet_names = book.sheet_names()
print(sheet_names)
# 通过指定的表单名称获取Sheet对象(工作表)
sheet = book.sheet_by_name(sheet_names[0])
# 通过Sheet对象的nrows和ncols属性获取表单的行数和列数
print(sheet.nrows,sheet.ncols)for row in range(sheet.nrows):for col in range(sheet.ncols):# 通过Sheet对象的cell方法获取指定Cell对象(单元格)# 通过Cell对象的value属性获取单元格中的值value = sheet.cell(row, col).value# 对除首行外的其他行进行数据格式化处理if row > 0:# 第1列的xldate类型先转成元组再格式化为“年月日”的格式if col == 0:# xldate_as_tuple函数的第二个参数只有0和1两个取值# 其中0代表以1900-01-01为基准的日期,1代表以1904-01-01为基准的日期value = xlrd.xldate_as_tuple(value, 0)value = f'{value[0]}年{value[1]:>02d}月{value[2]:>02d}日'# 其他列的number类型处理成小数点后保留两位有效数字的浮点数elif isinstance(value,(int, float)):value = f'{value:.2f}'print(value, end='\t')print()
提示:上面代码中使用的Excel文件“阿里巴巴2020年股票数据.xls”可以通过后面的百度云盘地址进行获取。链接:https://pan.quark.cn/s/dfbd00457072?pwd=n3uY。
相信通过上面的代码,大家已经了解到了如何读取一个 Excel 文件,如果想知道更多关于xlrd模块的知识,可以阅读它的官方文档。
4.3 写Excel文件
写入 Excel 文件可以通过xlwt 模块的Workbook类创建工作簿对象,通过工作簿对象的add_sheet方法可以添加工作表,通过工作表对象的write方法可以向指定单元格中写入数据,最后通过工作簿对象的save方法将工作簿写入到指定的文件或内存中。下面的代码实现了将5 个学生 3 门课程的考试成绩写入 Excel 文件的操作。
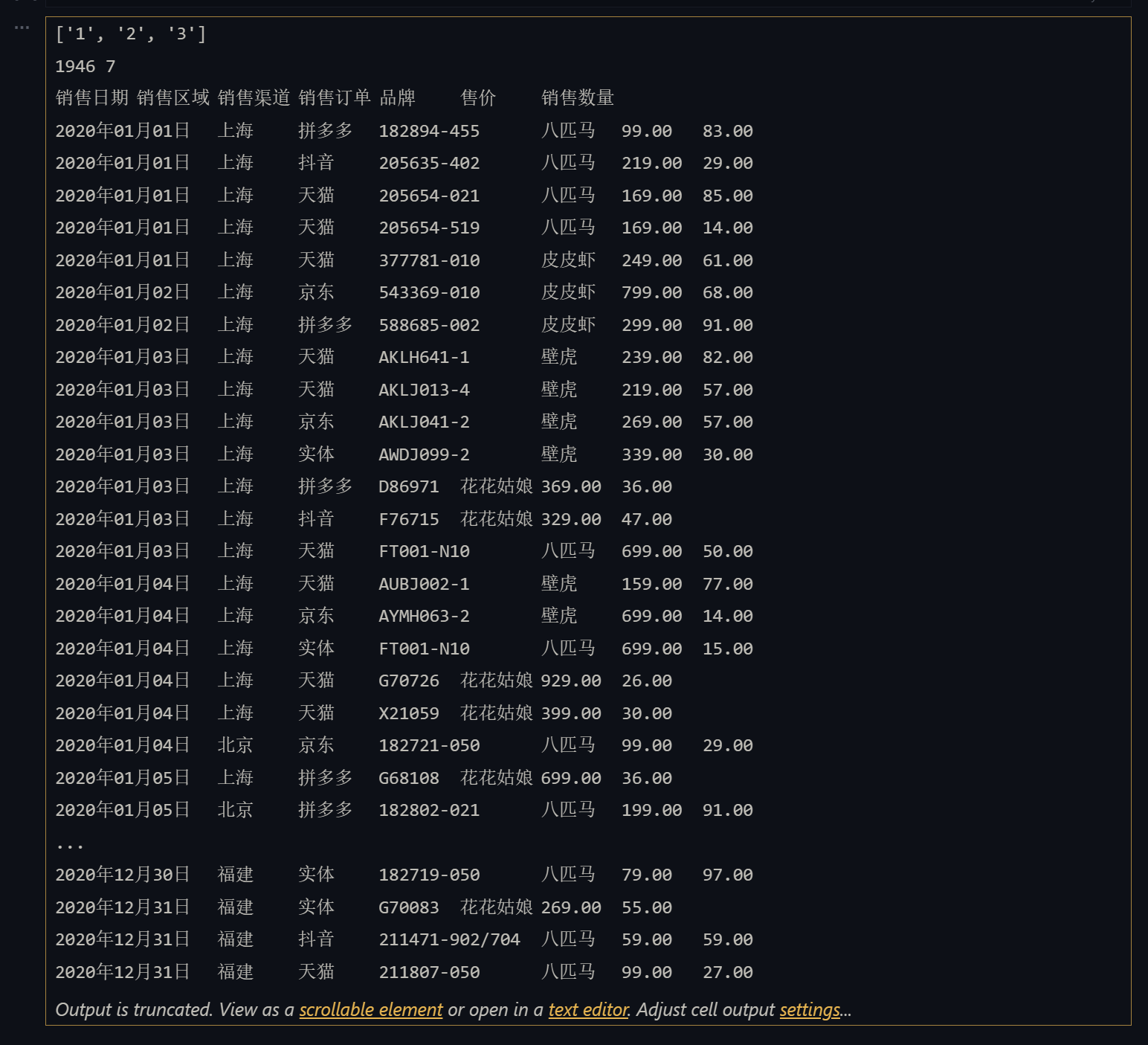
import random
import xlwtstudent_names = ['Penry', 'Cruise', 'Taco', 'Ma']
scores = [[random.randrange(60, 101) for _ in range(3)] for _ in range(4)]
# 创建工作簿对象
workbook = xlwt.Workbook()
# 创建工作表对象
worksheet = workbook.add_sheet("239宿舍")
# 添加表头
titles = ('姓名', '卫生', '健康', '体育')
for index, title in enumerate(titles):worksheet.write(0, index, title)
# 将学生姓名和得分写入单元格
for row in range(len(scores)):worksheet.write(row + 1, 0, student_names[row])for col in range(len(scores[row])):worksheet.write(row + 1, col + 1, scores[row][col])
# 保存Excel工作簿
workbook.save('data/成绩表.xls') 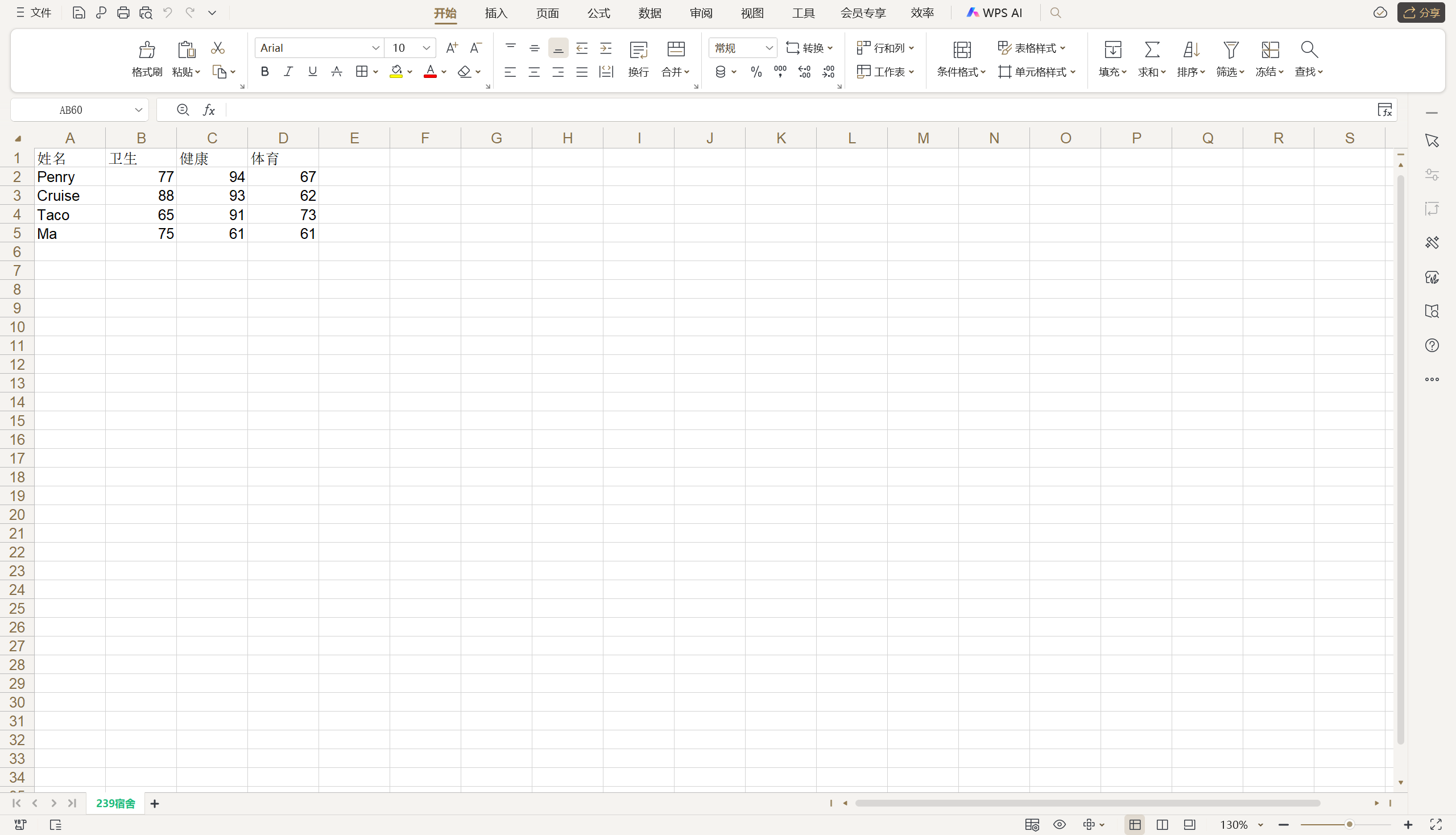
4.4 调整单元格样式
在写Excel文件时,我们还可以为单元格设置样式,主要包括字体(Font)、对齐方式(Alignment)、边框(Border)和背景(Background)的设置,xlwt对这几项设置都封装了对应的类来支持。要设置单元格样式需要首先创建一个XFStyle对象,再通过该对象的属性对字体、对齐方式、边框等进行设定,例如在上面的例子中,如果希望将表头单元格的背景色修改为黄色,可以按照如下的方式进行操作。
header_style = xlwt.XFStyle()
pattern = xlwt.Pattern()
pattern.pattern = xlwt.Pattern.SOLID_PATTERN
# 0 - 黑色、1 - 白色、2 - 红色、3 - 绿色、4 - 蓝色、5 - 黄色、6 - 粉色、7 - 青色
pattern.pattern_fore_colour = 5
header_style.pattern = pattern
titles = ('姓名', '语文', '数学', '英语')
for index, title in enumerate(titles):sheet.write(0, index, title, header_style)
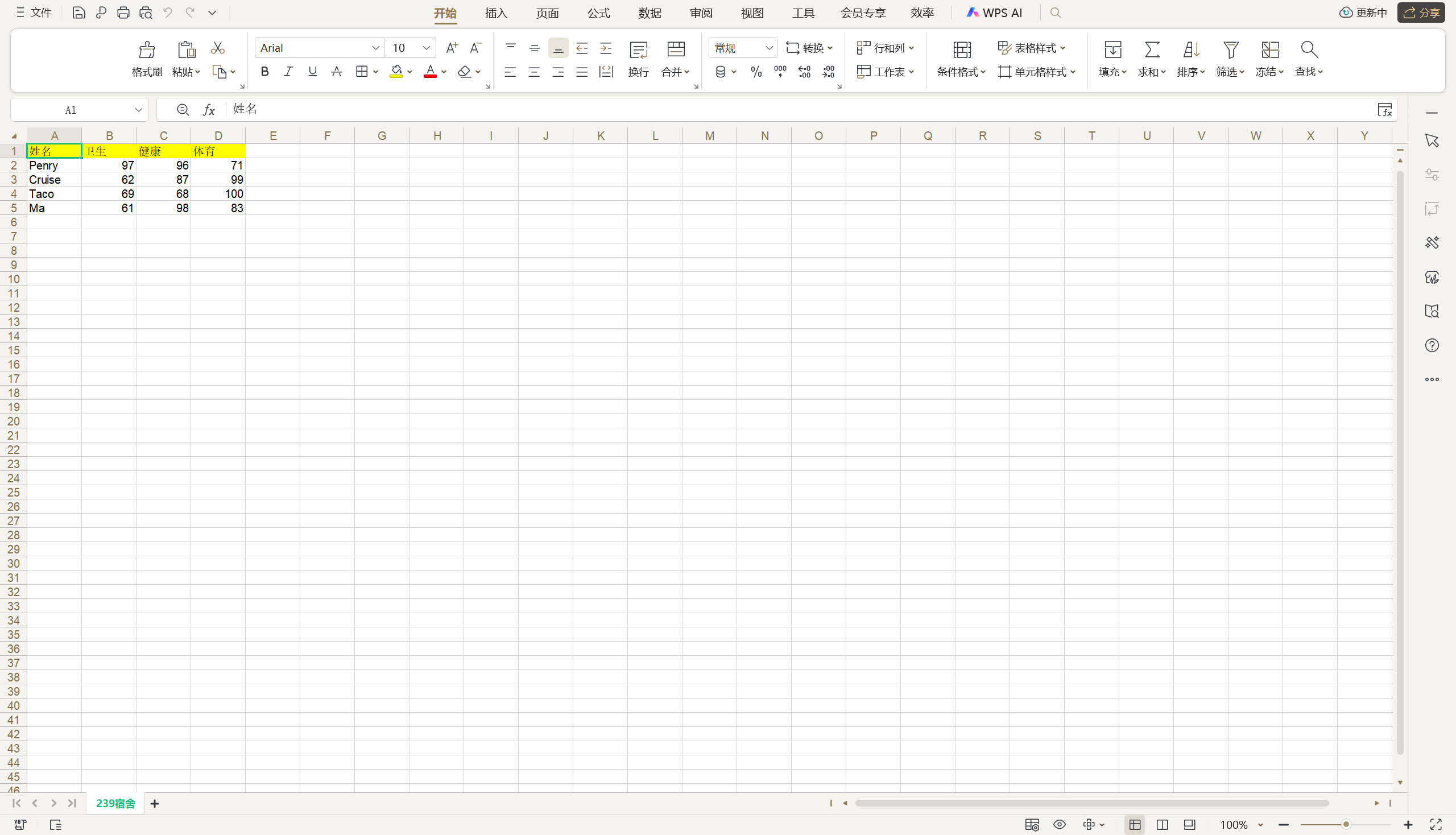
如果希望为表头设置指定的字体,可以使用Font类并添加如下所示的代码。
font = xlwt.Font()
# 字体名称
font.name = '华文楷体'
# 字体大小(20是基准单位,18表示18px)
font.height = 20 * 18
# 是否使用粗体
font.bold = True
# 是否使用斜体
font.italic = False
# 字体颜色
font.colour_index = 1
header_style.font = font
注意:上面代码中指定的字体名(
font.name)应当是本地系统有的字体,例如在我的电脑上有名为“华文楷体”的字体。
如果希望表头垂直居中对齐,可以使用下面的代码进行设置。
align = xlwt.Alignment()
# 垂直方向的对齐方式
align.vert = xlwt.Alignment.VERT_CENTER
# 水平方向的对齐方式
align.horz = xlwt.Alignment.HORZ_CENTER
header_style.alignment = align
如果希望给表头加上黄色的虚线边框,可以使用下面的代码来设置。
borders = xlwt.Borders()
props = (('top', 'top_colour'), ('right', 'right_colour'),('bottom', 'bottom_colour'), ('left', 'left_colour')
)
# 通过循环对四个方向的边框样式及颜色进行设定
for position, color in props:# 使用setattr内置函数动态给对象指定的属性赋值setattr(borders, position, xlwt.Borders.DASHED)setattr(borders, color, 5)
header_style.borders = borders
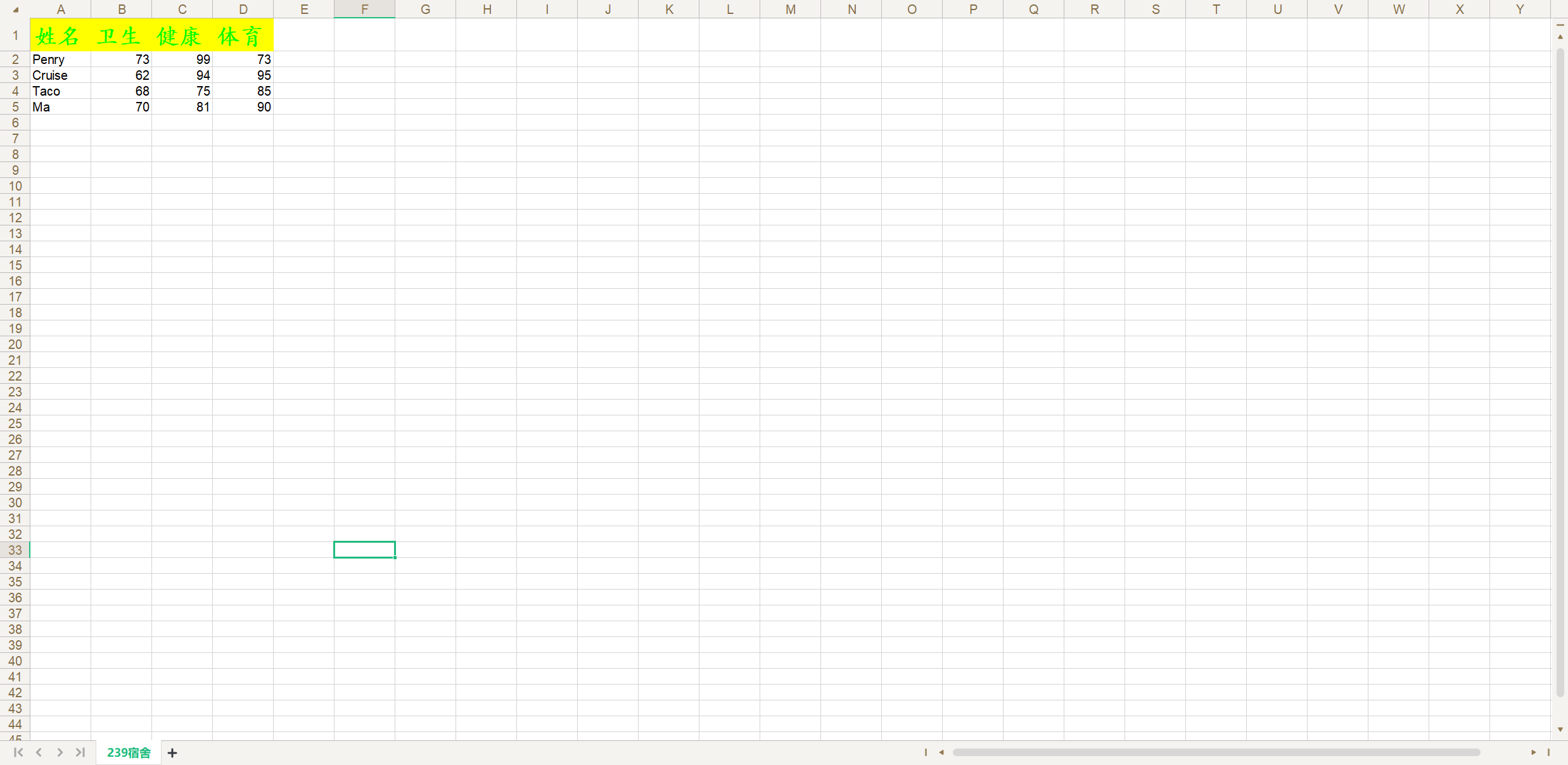
如果要调整单元格的宽度(列宽)和表头的高度(行高),可以按照下面的代码进行操作。
# 设置行高为40px
sheet.row(0).set_style(xlwt.easyxf(f'font:height {20 * 40}'))
titles = ('姓名', '语文', '数学', '英语')
for index, title in enumerate(titles):# 设置列宽为200pxsheet.col(index).width = 20 * 200# 设置单元格的数据和样式sheet.write(0, index, title, header_style)
4.5 公式计算
对于前面打开的“阿里巴巴2020年股票数据.xls”文件,如果要统计售价平均值以及销售数量的总和,可以使用Excel的公式计算即可。我们可以先使用xlrd读取Excel文件夹,然后通过xlutils三方库提供的copy函数将读取到的Excel文件转成Workbook对象进行写操作,在调用write方法时,可以将一个Formula对象写入单元格。
实现公式计算的代码如下所示。
import xlrd
import xlwt
from xlutils.copy import copywb_for_read = xlrd.open_workbook('阿里巴巴2020年股票数据.xls')
sheet1 = wb_for_read.sheet_by_index(0)
nrows, ncols = sheet1.nrows, sheet1.ncols
wb_for_write = copy(wb_for_read)
sheet2 = wb_for_write.get_sheet(0)
sheet2.write(nrows, 4, xlwt.Formula(f'average(E2:E{nrows})'))
sheet2.write(nrows, 6, xlwt.Formula(f'sum(G2:G{nrows})'))
wb_for_write.save('阿里巴巴2020年股票数据汇总.xls')
说明:上面的代码有一些小瑕疵,有兴趣的读者可以自行探索并思考如何解决。
4.6 总结
掌握了 Python 程序操作 Excel 的方法,可以解决日常办公中很多繁琐的处理 Excel 电子表格工作,最常见就是将多个数据格式相同的 Excel 文件合并到一个文件以及从多个 Excel 文件或表单中提取指定的数据。当然,如果要对表格数据进行处理,使用 Python 数据分析神器之一的 pandas 库可能更为方便。
5 Python读写Excel文件-2
5.1 Excel简介
Excel 是 Microsoft(微软)为使用 Windows 和 macOS 操作系统开发的一款电子表格软件。Excel 凭借其直观的界面、出色的计算功能和图表工具,再加上成功的市场营销,一直以来都是最为流行的个人计算机数据处理软件。当然,Excel 也有很多竞品,例如 Google Sheets、LibreOffice Calc、Numbers 等,这些竞品基本上也能够兼容 Excel,至少能够读写较新版本的 Excel 文件,当然这些不是我们讨论的重点。掌握用 Python 程序操作 Excel 文件,可以让日常办公自动化的工作更加轻松愉快,而且在很多商业项目中,导入导出 Excel 文件都是特别常见的功能。
本章我们继续讲解基于另一个三方库openpyxl如何进行 Excel 文件操作,首先需要先安装它。
pip install openpyxl
openpyxl的优点在于,当我们打开一个 Excel 文件后,既可以对它进行读操作,又可以对它进行写操作,而且在操作的便捷性上是优于xlwt和xlrd的。此外,如果要进行样式编辑和公式计算,使用openpyxl也远比上一个章节我们讲解的方式更为简单,而且openpyxl还支持数据透视和插入图表等操作,功能非常强大。有一点需要再次强调,openpyxl并不支持操作 Office 2007 以前版本的 Excel 文件。
5.2 读取Excel文件
例如在data文件夹下有一个名为“阿里巴巴2020年股票数据.xlsx”的 Excel 文件,如果想读取并显示该文件的内容,可以通过如下所示的代码来完成。
import datetime
import openpyxl# 加载一个工作簿 ---> Workbook
wb = openpyxl.load_workbook('data/阿里巴巴2020年股票数据.xlsx')
# 获取工作表名称
print(wb.sheetnames)
# 获取工作表 ---> Worksheet
sheet = wb.worksheets[0]
# 获取单元格范围
print(sheet.dimensions)
# 获取行数和列数
print(sheet.max_row, sheet.max_column)# 获取指定单元格的值
print(sheet.cell(3, 3).value)
print(sheet['C3'].value)
print(sheet['G255'].value)# 获取多个单元格(嵌套元组)
print(sheet['A2:C5'])# 读取所有单元格的数据
for row_ch in range(2, sheet.max_row + 1):for col_ch in 'ABCDEFG':value = sheet[f'{col_ch}{row_ch}'].valueif type(value) == datetime.datetime:print(value.strftime('%Y年%m月%d日'), end='\t')elif type(value) == int:print(f'{value:<10d}', end='\t')elif type(value) == float:print(f'{value:.4f}', end='\t')else:print(value, end='\t')print()
需要提醒大家一点,openpyxl获取指定的单元格有两种方式,一种是通过cell方法,需要注意,该方法的行索引和列索引都是从1开始的,这是为了照顾用惯了 Excel 的人的习惯;另一种是通过索引运算,通过指定单元格的坐标,例如C3、G255,也可以取得对应的单元格,再通过单元格对象的value属性,就可以获取到单元格的值。通过上面的代码,相信大家还注意到了,可以通过类似sheet['A2:C5']或sheet['A2':'C5']这样的切片操作获取多个单元格,该操作将返回嵌套的元组,相当于获取到了多行多列。
5.3 写Excel文件
下面我们使用openpyxl来进行写 Excel 操作。
import openpyxl
import random# 第一步:创建工作簿(Workbook)
wb = openpyxl.Workbook()# 第二步:添加工作表(Worksheet)
sheet = wb.active
sheet.title = '期末成绩'# 第三步:写入数据titles = ('姓名', '语文', '数学', '英语')
for col_index, title in enumerate(titles):sheet.cell(1, col_index+1, title)names = ('关羽', '张飞', '赵云', '马超', '黄忠')
for row_index, name in enumerate(names):sheet.cell(row_index+2, 1, name)for col_index in range(2, 5):sheet.cell(row_index+2, col_index, random.randrange(60, 101))# 第四步:保存工作簿
wb.save('data/期末成绩.xlsx')
5.4 调整样式和公式计算
在使用openpyxl操作 Excel 时,如果要调整单元格的样式,可以直接通过单元格对象(Cell对象)的属性进行操作。单元格对象的属性包括字体(font)、对齐(alignment)、边框(border)等,具体的可以参考openpyxl的官方文档。在使用openpyxl时,如果需要做公式计算,可以完全按照 Excel 中的操作方式来进行,具体的代码如下所示。
import openpyxl
from openpyxl.styles import Font, Alignment, Border, Side# 对齐方式
alignment = Alignment(horizontal='center', vertical='center')
# 边框线条
side = Side(style='mediumDashed', color='ff7f50')wb = openpyxl.load_workbook('data/期末成绩.xlsx')
sheet = wb.worksheets[0]# 调整行高和行宽
sheet.row_dimensions[1].height = 30
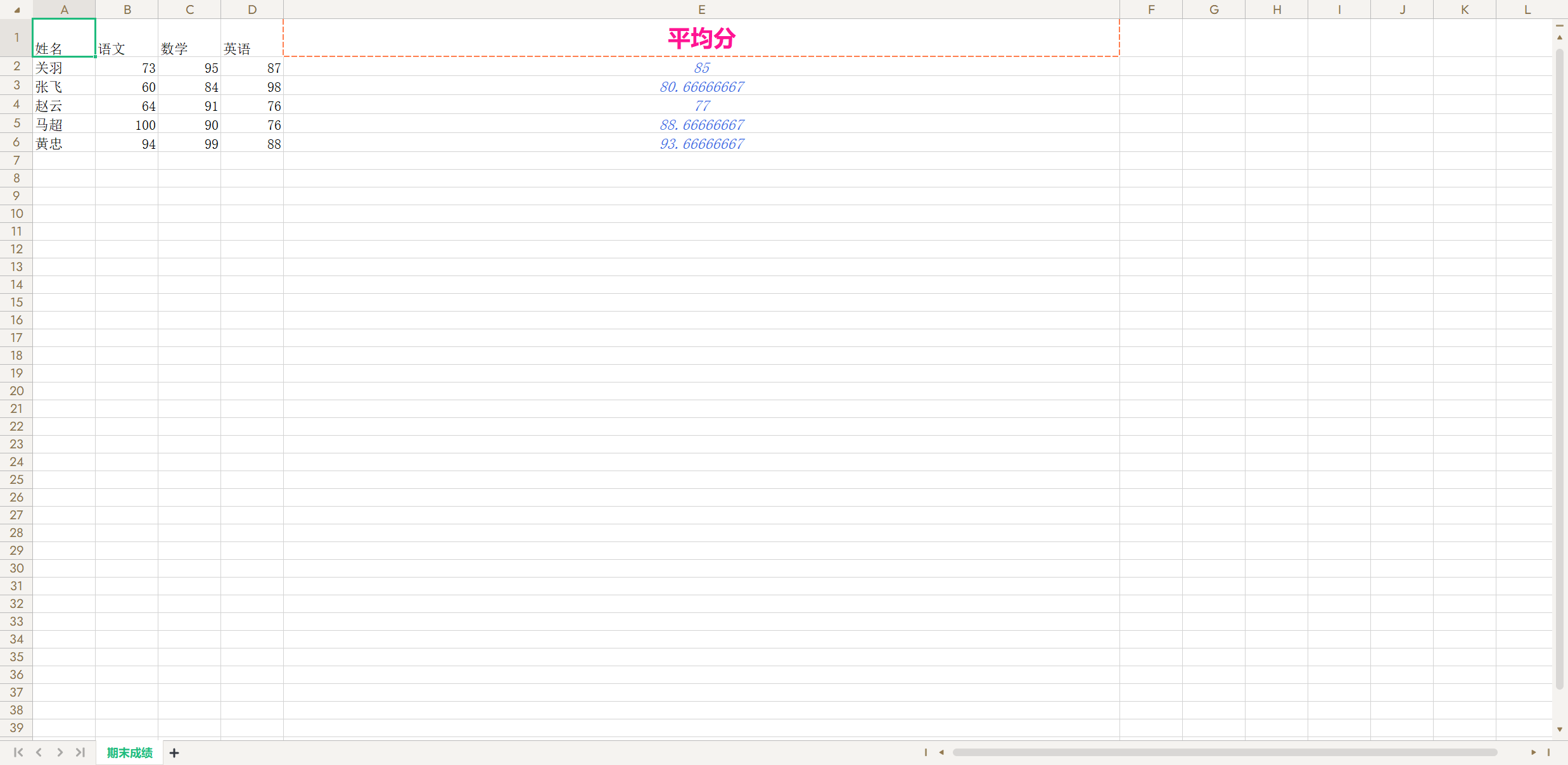
sheet.column_dimensions['E'].width = 120sheet['E1'] = '平均分'# 设置字体
sheet.cell(1, 5).font = Font(name='微软雅黑', size=18, bold=True, color='ff1493')
# 设置对齐方式
sheet.cell(1, 5).alignment = alignment
# 设置单元格边框
sheet.cell(1, 5).border = Border(left=side, top=side, right=side, bottom=side)
for i in range(2, 7):# 公式计算每个学生的平均分sheet[f'E{i}'] = f'=average(B{i}:D{i})'sheet.cell(i, 5).font = Font(size=12, color='4169e1', italic=True)sheet.cell(i, 5).alignment = alignmentwb.save('data/考试成绩表.xlsx')
5.5 生成统计图表
通过openpyxl库,可以直接向 Excel 中插入统计图表,具体的做法跟在 Excel 中插入图表大体一致。我们可以创建指定类型的图表对象,然后通过该对象的属性对图表进行设置。当然,最为重要的是为图表绑定数据,即横轴代表什么,纵轴代表什么,具体的数值是多少。最后,可以将图表对象添加到表单中,具体的代码如下所示。
from openpyxl import Workbook
from openpyxl.chart import BarChart, Referencewb = Workbook(write_only=True)
sheet = wb.create_sheet()rows = [('类别', '销售A组', '销售B组'),('手机', 40, 30),('平板', 50, 60),('笔记本', 80, 70),('外围设备', 20, 10),
]# 向表单中添加行
for row in rows:sheet.append(row)# 创建图表对象
chart = BarChart()
chart.type = 'col'
chart.style = 10
# 设置图表的标题
chart.title = '销售统计图'
# 设置图表纵轴的标题
chart.y_axis.title = '销量'
# 设置图表横轴的标题
chart.x_axis.title = '商品类别'
# 设置数据的范围
data = Reference(sheet, min_col=2, min_row=1, max_row=5, max_col=3)
# 设置分类的范围
cats = Reference(sheet, min_col=1, min_row=2, max_row=5)
# 给图表添加数据
chart.add_data(data, titles_from_data=True)
# 给图表设置分类
chart.set_categories(cats)
chart.shape = 4
# 将图表添加到表单指定的单元格中
sheet.add_chart(chart, 'A10')wb.save('demo.xlsx')
运行上面的代码,打开生成的 Excel 文件,效果如下图所示。
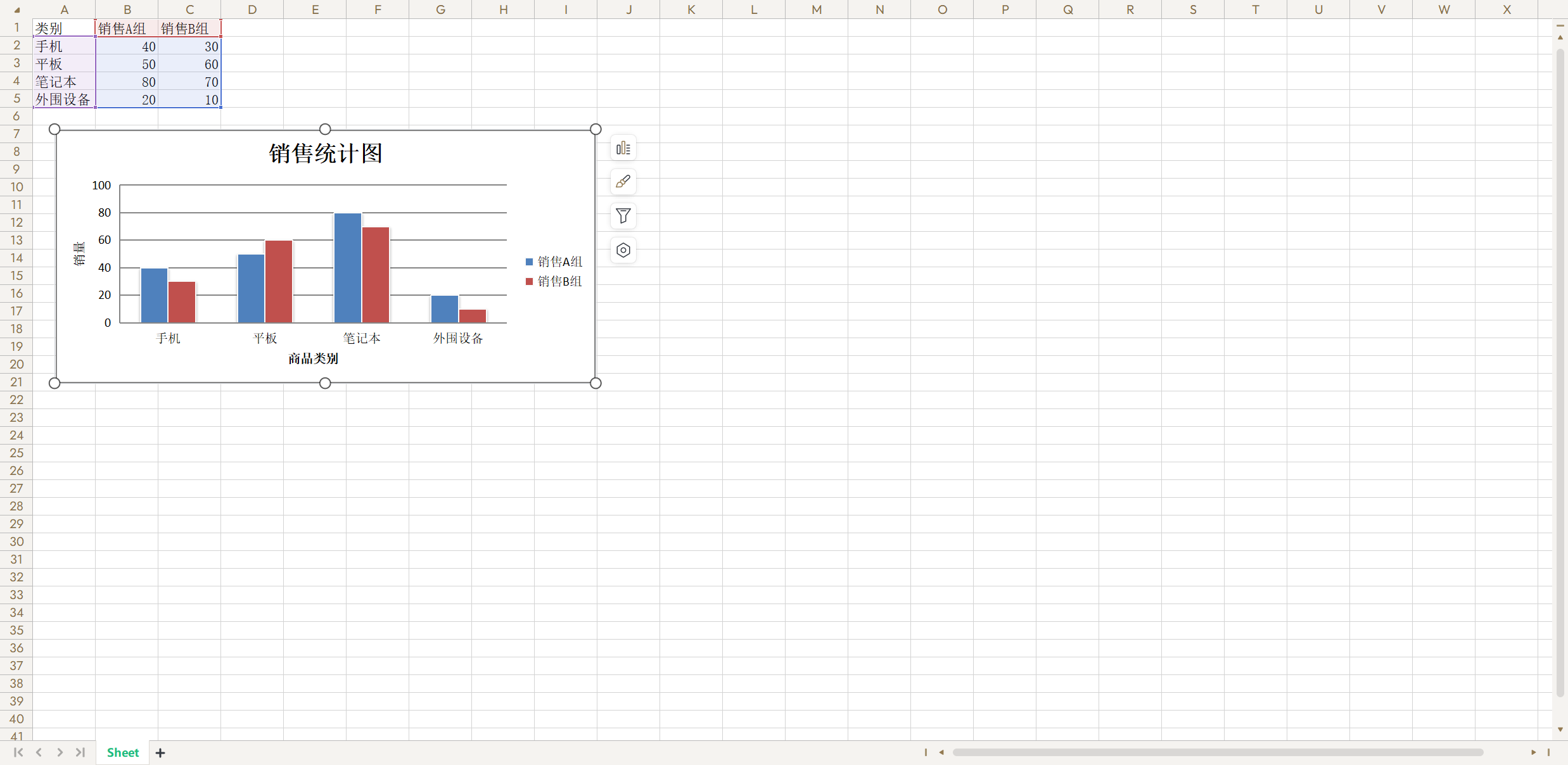
5.6 总结
掌握了 Python 程序操作 Excel 的方法,可以解决日常办公中很多繁琐的处理 Excel 电子表格工作,最常见就是将多个数据格式相同的Excel 文件合并到一个文件以及从多个 Excel 文件或表单中提取指定的数据。如果数据体量较大或者处理数据的方式比较复杂,我们还是推荐大家使用 Python 数据分析神器之一的 pandas 库。
6 Python操作Word和PowerPoint文件
在日常工作中,有很多简单重复的劳动其实完全可以交给 Python 程序,比如根据样板文件(模板文件)批量的生成很多个 Word 文件或 PowerPoint 文件。Word 是微软公司开发的文字处理程序,相信大家都不陌生,日常办公中很多正式的文档都是用 Word 进行撰写和编辑的,目前使用的 Word 文件后缀名一般为.docx。PowerPoint 是微软公司开发的演示文稿程序,是微软的 Office 系列软件中的一员,被商业人士、教师、学生等群体广泛使用,通常也将其称之为“幻灯片”。在 Python 中,可以使用名为python-docx 的三方库来操作 Word,可以使用名为python-pptx的三方库来生成 PowerPoint。
6.1 操作Word文档
我们可以先通过下面的命令来安装python-docx三方库。
pip install python-docx
按照官方文档的介绍,我们可以使用如下所示的代码来生成一个简单的 Word 文档。
from docx import Document
from docx.shared import Cm, Ptfrom docx.document import Document as Doc# 创建代表Word文档的Doc对象
document = Document() # type: Doc
# 添加大标题
document.add_heading('快快乐乐学Python', 0)
# 添加段落
p = document.add_paragraph('Python是一门非常流行的编程语言,它')
run = p.add_run('简单')
run.bold = True
run.font.size = Pt(18)
p.add_run('而且')
run = p.add_run('优雅')
run.font.size = Pt(18)
run.underline = True
p.add_run('。')# 添加一级标题
document.add_heading('Heading, level 1', level=1)
# 添加带样式的段落
document.add_paragraph('Intense quote', style='Intense Quote')
# 添加无序列表
document.add_paragraph('first item in unordered list', style='List Bullet'
)
document.add_paragraph('second item in ordered list', style='List Bullet'
)
# 添加有序列表
document.add_paragraph('first item in ordered list', style='List Number'
)
document.add_paragraph('second item in ordered list', style='List Number'
)# 添加图片(注意路径和图片必须要存在)
document.add_picture('resources/dm10.jpg', width=Cm(5.2))# 添加分节符
document.add_section()records = (('Penry', '男', '2004-05'),('Doudou', '女', '2005-05')
)
# 添加表格
table = document.add_table(rows=1, cols=3)
table.style = 'Dark List'
hdr_cells = table.rows[0].cells
hdr_cells[0].text = '姓名'
hdr_cells[1].text = '性别'
hdr_cells[2].text = '出生日期'
# 为表格添加行
for name, sex, birthday in records:row_cells = table.add_row().cellsrow_cells[0].text = namerow_cells[1].text = sexrow_cells[2].text = birthday# 添加分页符
document.add_page_break()# 保存文档
document.save('Intermediate file/demo.docx')
提示:上面代码第7行中的注释
# type: Doc是为了在PyCharm中获得代码补全提示,因为如果不清楚对象具体的数据类型,PyCharm 无法在后续代码中给出Doc对象的代码补全提示。
执行上面的代码,打开生成的 Word 文档,效果如下图所示。
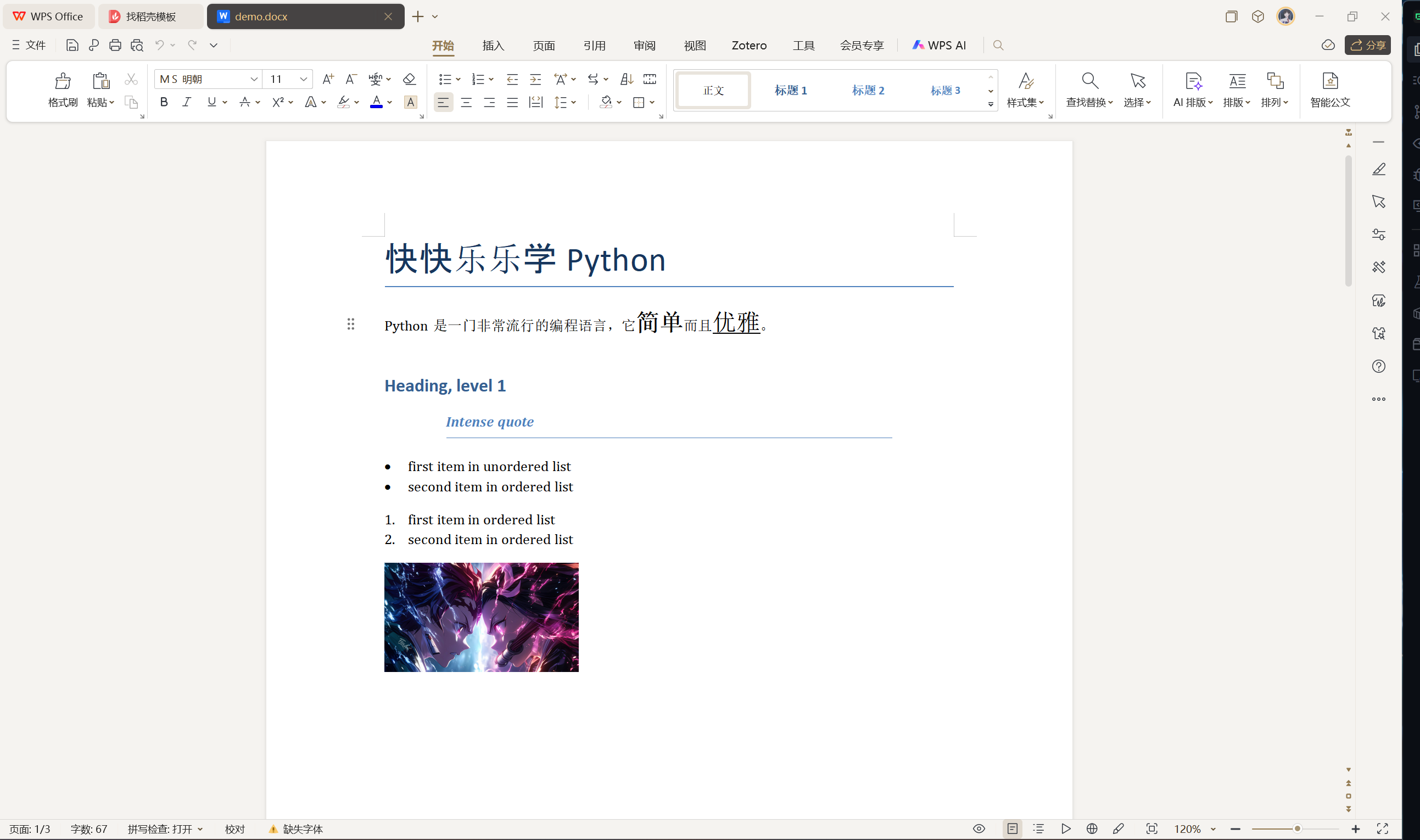
对于一个已经存在的 Word 文件,我们可以通过下面的代码去遍历它所有的段落并获取对应的内容。
from docx import Document
from docx.document import Document as Docdoc = Document('resources/离职证明.docx') # type: Doc
for no, p in enumerate(doc.paragraphs):print(no, p.text)
提示:如果需要上面代码中的 Word 文件,可以通过下面的百度云盘地址进行获取。链接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g 提取码:e7b4。
读取到的内容如下所示。
0 快快乐乐学Python
1 Python是一门非常流行的编程语言,它简单而且优雅。
2 Heading, level 1
3 Intense quote
4 first item in unordered list
5 second item in ordered list
6 first item in ordered list
7 second item in ordered list
8
9
10
讲到这里,相信很多读者已经想到了,我们可以把离职证明制作成一个模板文件,把姓名、身份证号、入职和离职日期等信息用占位符代替,这样通过对占位符的替换,就可以根据实际需要写入对应的信息,这样就可以批量的生成 Word 文档。
按照上面的思路,我们首先编辑一个离职证明的模板文件,如下图所示。

接下来我们读取该文件,将占位符替换为真实信息,就可以生成一个新的 Word 文档,如下所示。
from docx import Document
from docx.document import Document as Doc# 将真实信息用字典的方式保存在列表中
employees = [{'name': '赵云','id': '100200198011280001','sdate': '2008年3月1日','edate': '2012年2月29日','department': '产品研发','position': '架构师','company': '成都华为技术有限公司'},{'name': '王大锤','id': '510210199012125566','sdate': '2019年1月1日','edate': '2021年4月30日','department': '产品研发','position': 'Python开发工程师','company': '成都谷道科技有限公司'},{'name': '李元芳','id': '2102101995103221599','sdate': '2020年5月10日','edate': '2021年3月5日','department': '产品研发','position': 'Java开发工程师','company': '同城企业管理集团有限公司'},
]
# 对列表进行循环遍历,批量生成Word文档
for emp_dict in employees:# 读取离职证明模板文件doc = Document('resources/离职证明模板.docx') # type: Doc# 循环遍历所有段落寻找占位符for p in doc.paragraphs:if '{' not in p.text:continue# 不能直接修改段落内容,否则会丢失样式# 所以需要对段落中的元素进行遍历并进行查找替换for run in p.runs:if '{' not in run.text:continue# 将占位符换成实际内容start, end = run.text.find('{'), run.text.find('}')key, place_holder = run.text[start + 1:end], run.text[start:end + 1]run.text = run.text.replace(place_holder, emp_dict[key])# 每个人对应保存一个Word文档doc.save(f'{emp_dict["name"]}离职证明.docx')
执行上面的代码,会在当前路径下生成三个 Word 文档。
6.2 生成PowerPoint
首先我们需要安装名为python-pptx的三方库,命令如下所示。
pip install python-pptx
用 Python 操作 PowerPoint 的内容,因为实际应用场景不算很多,我不打算在这里进行赘述,有兴趣的读者可以自行阅读python-pptx的官方文档,下面仅展示一段来自于官方文档的代码。
from pptx import Presentation# 创建幻灯片对象
pres = Presentation()# 选择母版添加一页
title_slide_layout = pres.slide_layouts[0]
slide = pres.slides.add_slide(title_slide_layout)
# 获取标题栏和副标题栏
title = slide.shapes.title
subtitle = slide.placeholders[1]
# 编辑标题和副标题
title.text = "Welcome to Python"
subtitle.text = "Life is short, I use Python"# 选择母版添加一页
bullet_slide_layout = pres.slide_layouts[1]
slide = pres.slides.add_slide(bullet_slide_layout)
# 获取页面上所有形状
shapes = slide.shapes
# 获取标题和主体
title_shape = shapes.title
body_shape = shapes.placeholders[1]
# 编辑标题
title_shape.text = 'Introduction'
# 编辑主体内容
tf = body_shape.text_frame
tf.text = 'History of Python'
# 添加一个一级段落
p = tf.add_paragraph()
p.text = 'X\'max 1989'
p.level = 1
# 添加一个二级段落
p = tf.add_paragraph()
p.text = 'Guido began to write interpreter for Python.'
p.level = 2# 保存幻灯片
pres.save('test.pptx')
运行上面的代码,生成的 PowerPoint 文件如下图所示。
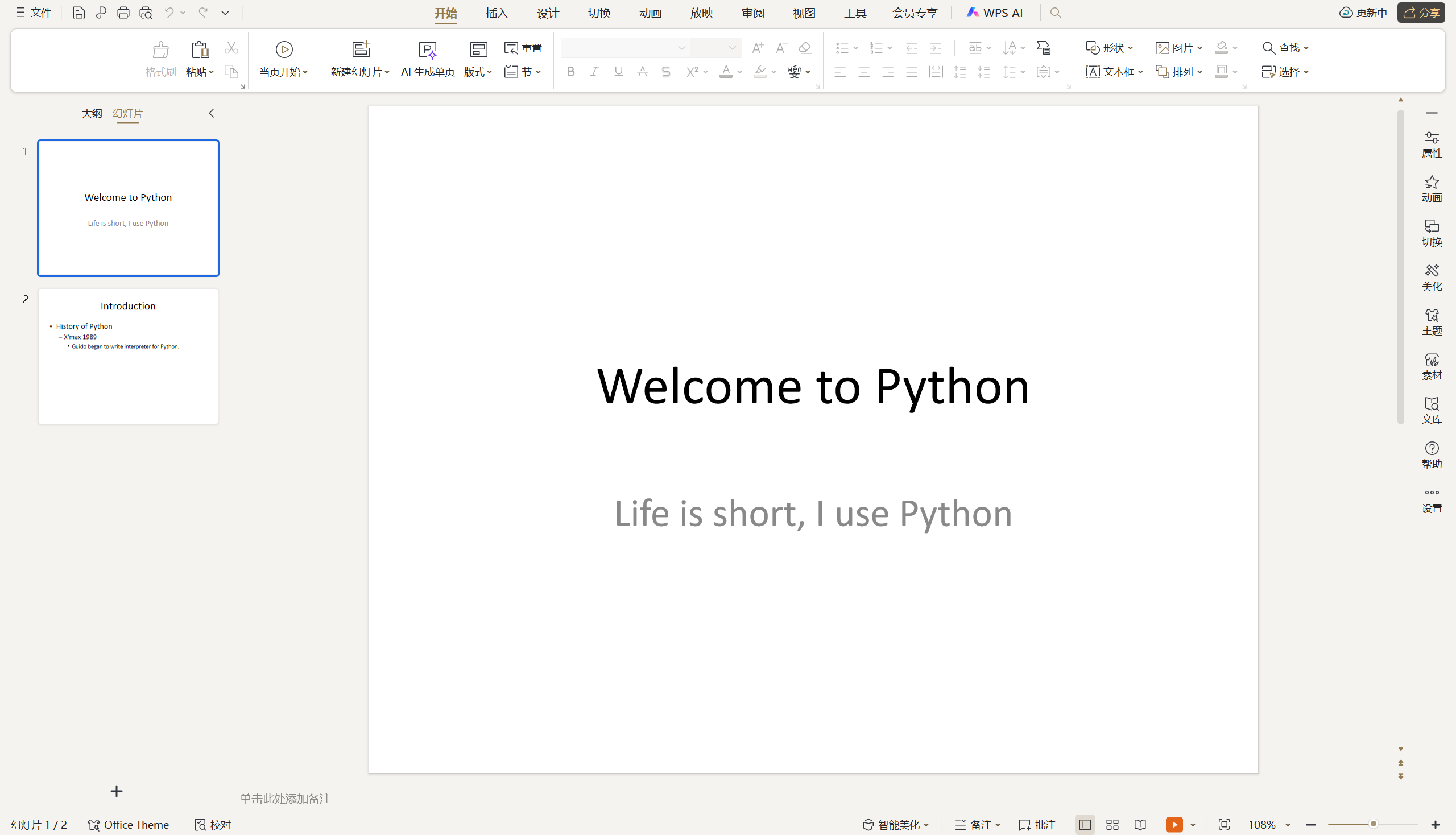
6.3 总结
用 Python 程序解决办公自动化的问题真的非常酷,它可以将我们从繁琐乏味的劳动中解放出来。写这类代码就是去做一件一劳永逸的事情,写代码的过程即便不怎么愉快,使用这些代码的时候应该是非常开心的。
7 正则表达式的应用
7.1 正则表达式相关知识
在编写处理字符串的程时,经常会遇到在一段文本中查找符合某些规则的字符串的需求,正则表达式就是用于描述这些规则的工具,换句话说,我们可以使用正则表达式来定义字符串的匹配模式,即如何检查一个字符串是否有跟某种模式匹配的部分或者从一个字符串中将与模式匹配的部分提取出来或者替换掉。
举一个简单的例子,如果你在 Windows 操作系统中使用过文件查找并且在指定文件名时使用过通配符(*和?),那么正则表达式也是与之类似的用 来进行文本匹配的工具,只不过比起通配符正则表达式更强大,它能更精确地描述你的需求,当然你付出的代价是书写一个正则表达式比使用通配符要复杂得多,因为任何给你带来好处的东西都需要你付出对应的代价。
再举一个例子,我们从某个地方(可能是一个文本文件,也可能是网络上的一则新闻)获得了一个字符串,希望在字符串中找出手机号和座机号。当然我们可以设定手机号是 11 位的数字(注意并不是随机的 11 位数字,因为你没有见过“25012345678”这样的手机号),而座机号则是类似于“区号-号码”这样的模式,如果不使用正则表达式要完成这个任务就会比较麻烦。最初计算机是为了做数学运算而诞生的,处理的信息基本上都是数值,而今天我们在日常工作中处理的信息很多都是文本数据,我们希望计算机能够识别和处理符合某些模式的文本,正则表达式就显得非常重要了。今天几乎所有的编程语言都提供了对正则表达式操作的支持,Python 通过标准库中的re模块来支持正则表达式操作。
关于正则表达式的相关知识,大家可以阅读一篇非常有名的博文叫《正则表达式30分钟入门教程》,读完这篇文章后你就可以看懂下面的表格,这是我们对正则表达式中的一些基本符号进行的扼要总结。
| 符号 | 解释 | 示例 | 说明 |
|---|---|---|---|
. | 匹配任意字符 | b.t | 可以匹配bat / but / b#t / b1t等 |
\w | 匹配字母/数字/下划线 | b\wt | 可以匹配bat / b1t / b_t等 但不能匹配b#t |
\s | 匹配空白字符(包括\r、\n、\t等) | love\syou | 可以匹配love you |
\d | 匹配数字 | \d\d | 可以匹配01 / 23 / 99等 |
\b | 匹配单词的边界 | \bThe\b | |
^ | 匹配字符串的开始 | ^The | 可以匹配The开头的字符串 |
$ | 匹配字符串的结束 | .exe$ | 可以匹配.exe结尾的字符串 |
\W | 匹配非字母/数字/下划线 | b\Wt | 可以匹配b#t / b@t等 但不能匹配but / b1t / b_t等 |
\S | 匹配非空白字符 | love\Syou | 可以匹配love#you等 但不能匹配love you |
\D | 匹配非数字 | \d\D | 可以匹配9a / 3# / 0F等 |
\B | 匹配非单词边界 | \Bio\B | |
[] | 匹配来自字符集的任意单一字符 | [aeiou] | 可以匹配任一元音字母字符 |
[^] | 匹配不在字符集中的任意单一字符 | [^aeiou] | 可以匹配任一非元音字母字符 |
* | 匹配0次或多次 | \w* | |
+ | 匹配1次或多次 | \w+ | |
? | 匹配0次或1次 | \w? | |
{N} | 匹配N次 | \w{3} | |
{M,} | 匹配至少M次 | \w{3,} | |
{M,N} | 匹配至少M次至多N次 | \w{3,6} | |
| | 分支 | foo|bar | 可以匹配foo或者bar |
(?#) | 注释 | ||
(exp) | 匹配exp并捕获到自动命名的组中 | ||
(?<name>exp) | 匹配exp并捕获到名为name的组中 | ||
(?:exp) | 匹配exp但是不捕获匹配的文本 | ||
(?=exp) | 匹配exp前面的位置 | \b\w+(?=ing) | 可以匹配I’m dancing中的danc |
(?<=exp) | 匹配exp后面的位置 | (?<=\bdanc)\w+\b | 可以匹配I love dancing and reading中的第一个ing |
(?!exp) | 匹配后面不是exp的位置 | ||
(?<!exp) | 匹配前面不是exp的位置 | ||
*? | 重复任意次,但尽可能少重复 | a.*ba.*?b | 将正则表达式应用于aabab,前者会匹配整个字符串aabab,后者会匹配aab和ab两个字符串 |
+? | 重复1次或多次,但尽可能少重复 | ||
?? | 重复0次或1次,但尽可能少重复 | ||
{M,N}? | 重复M到N次,但尽可能少重复 | ||
{M,}? | 重复M次以上,但尽可能少重复 |
说明: 如果需要匹配的字符是正则表达式中的特殊字符,那么可以使用
\进行转义处理,例如想匹配小数点可以写成\.就可以了,因为直接写.会匹配任意字符;同理,想匹配圆括号必须写成\(和\),否则圆括号被视为正则表达式中的分组。
7.2 Python对正则表达式的支持
Python 提供了re模块来支持正则表达式相关操作,下面是re模块中的核心函数。
| 函数 | 说明 |
|---|---|
compile(pattern, flags=0) | 编译正则表达式返回正则表达式对象 |
match(pattern, string, flags=0) | 用正则表达式匹配字符串 成功返回匹配对象 否则返回None |
search(pattern, string, flags=0) | 搜索字符串中第一次出现正则表达式的模式 成功返回匹配对象 否则返回None |
split(pattern, string, maxsplit=0, flags=0) | 用正则表达式指定的模式分隔符拆分字符串 返回列表 |
sub(pattern, repl, string, count=0, flags=0) | 用指定的字符串替换原字符串中与正则表达式匹配的模式 可以用count指定替换的次数 |
fullmatch(pattern, string, flags=0) | match函数的完全匹配(从字符串开头到结尾)版本 |
findall(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回字符串的列表 |
finditer(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回一个迭代器 |
purge() | 清除隐式编译的正则表达式的缓存 |
re.I / re.IGNORECASE | 忽略大小写匹配标记 |
re.M / re.MULTILINE | 多行匹配标记 |
说明: 上面提到的
re模块中的这些函数,实际开发中也可以用正则表达式对象(Pattern对象)的方法替代对这些函数的使用,如果一个正则表达式需要重复的使用,那么先通过compile函数编译正则表达式并创建出正则表达式对象无疑是更为明智的选择。
下面我们通过一系列的例子来告诉大家在Python中如何使用正则表达式。
例子1:验证输入用户名和QQ号是否有效并给出对应的提示信息。
"""
要求:用户名必须由字母、数字或下划线构成且长度在6~20个字符之间,QQ号是5~12的数字且首位不能为0
"""
import reusername = input('请输入用户名: ')
qq = input('请输入QQ号: ')
# match函数的第一个参数是正则表达式字符串或正则表达式对象
# match函数的第二个参数是要跟正则表达式做匹配的字符串对象
m1 = re.match(r'^[0-9a-zA-Z_]{6,20}$', username)
if not m1:print('请输入有效的用户名.')
# fullmatch函数要求字符串和正则表达式完全匹配
# 所以正则表达式没有写起始符和结束符
m2 = re.fullmatch(r'[1-9]\d{4,11}', qq)
if not m2:print('请输入有效的QQ号.')
if m1 and m2:print('你输入的信息是有效的!')
提示: 上面在书写正则表达式时使用了“原始字符串”的写法(在字符串前面加上了
r),所谓“原始字符串”就是字符串中的每个字符都是它原始的意义,说得更直接一点就是字符串中没有所谓的转义字符啦。因为正则表达式中有很多元字符和需要进行转义的地方,如果不使用原始字符串就需要将反斜杠写作\\,例如表示数字的\d得书写成\\d,这样不仅写起来不方便,阅读的时候也会很吃力。
例子2:从一段文字中提取出国内手机号码。
下面这张图是截止到 2017 年底,国内三家运营商推出的手机号段。

import re# 创建正则表达式对象,使用了前瞻和回顾来保证手机号前后不应该再出现数字
pattern = re.compile(r'(?<=\D)1[34578]\d{9}(?=\D)')
sentence = '''重要的事情说8130123456789遍,我的手机号是13512346789这个靓号,
不是15600998765,也不是110或119,王大锤的手机号才是15600998765。'''
# 方法一:查找所有匹配并保存到一个列表中
tels_list = re.findall(pattern, sentence)
for tel in tels_list:print(tel)
print('--------华丽的分隔线--------')# 方法二:通过迭代器取出匹配对象并获得匹配的内容
for temp in pattern.finditer(sentence):print(temp.group())
print('--------华丽的分隔线--------')# 方法三:通过search函数指定搜索位置找出所有匹配
m = pattern.search(sentence)
while m:print(m.group())m = pattern.search(sentence, m.end())
说明: 上面匹配国内手机号的正则表达式并不够好,因为像 14 开头的号码只有 145 或 147,而上面的正则表达式并没有考虑这种情况,要匹配国内手机号,更好的正则表达式的写法是:
(?<=\D)(1[38]\d{9}|14[57]\d{8}|15[0-35-9]\d{8}|17[678]\d{8})(?=\D),国内好像已经有 19 和 16 开头的手机号了,但是这个暂时不在我们考虑之列。
例子3:替换字符串中的不良内容
import resentence = 'Oh, shit! 你是傻逼吗? Fuck you.'
purified = re.sub('fuck|shit|[傻煞沙][比笔逼叉缺吊碉雕]','*', sentence, flags=re.IGNORECASE)
print(purified) # Oh, *! 你是*吗? * you.
说明:
re模块的正则表达式相关函数中都有一个flags参数,它代表了正则表达式的匹配标记,可以通过该标记来指定匹配时是否忽略大小写、是否进行多行匹配、是否显示调试信息等。如果需要为flags参数指定多个值,可以使用按位或运算符进行叠加,如flags=re.I | re.M。
例子4:拆分长字符串
import repoem = '窗前明月光,疑是地上霜。举头望明月,低头思故乡。'
sentences_list = re.split(r'[,。]', poem)
sentences_list = [sentence for sentence in sentences_list if sentence]
for sentence in sentences_list:print(sentence)
7.3 总结
正则表达式在字符串的处理和匹配上真的非常强大,通过上面的例子相信大家已经感受到了正则表达式的魅力,当然写一个正则表达式对新手来说并不是那么容易,但是很多事情都是熟能生巧,大胆的去尝试就行了,有一个在线的正则表达式测试工具相信能够在一定程度上帮到大家。