【Redis】 Redis 基础命令和原理
一、Redis 存储结构
1.1 Redis 存储原理
-
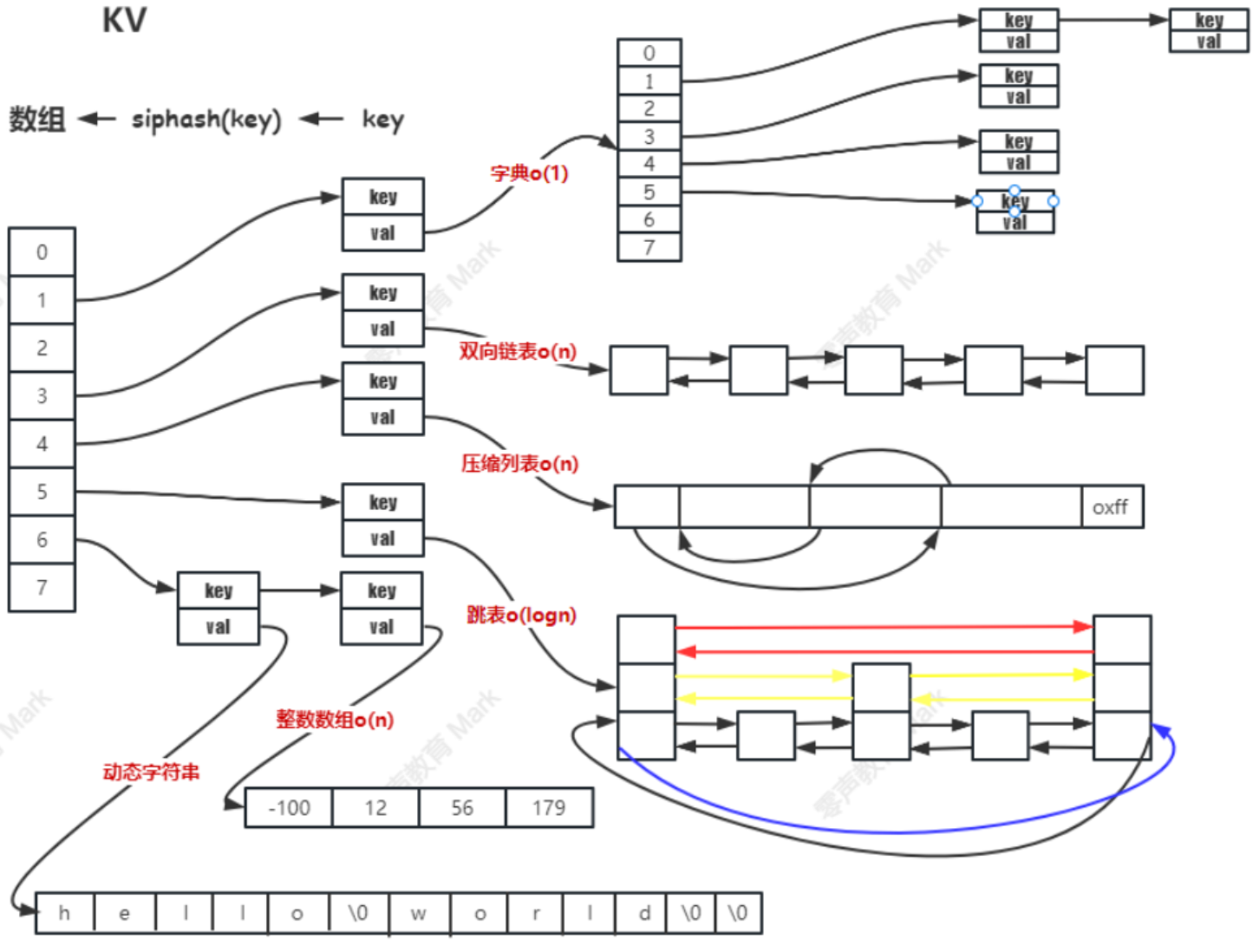
Redis 本质上是一个 Key-Value(键值对,KV)数据库,在它丰富多样的数据结构底层,都基于一种统一的键值对存储结构来进行数据的管理和操作
-
Redis 使用一个全局的哈希表来管理所有的键值对,这个哈希表就像是一个大字典,通过键(Key)能快速定位到对应的值(Value)。
-
从用户视角看,用户使用各种命令操作不同类型的数据结构(如 String、Hash、List 等),但从底层实现角度,它们都是以键值对形式存储在这个哈希表中。
-
Redis的存储分类的目的是,在数据量小的时候,追求存储效率高;在数据量大的时候,追求运行速度快。
1.1.1 Key 的本质与作用
- Key 的类型:本质是字符串(Redis 中统一以字符串标识 Key),例如
user:1001、product:2023,用于唯一标记对应 Value。 - 映射逻辑:Redis 通过哈希算法(如 siphash)将 Key 映射到哈希表的槽位,快速定位数据存储位置,保证 Key-Value 的高效读写。
1.1.2 Value 的动态编码设计
Redis 为不同数据类型(String/List/Hash/Set/Zset)设计了多编码策略,根据数据规模、内容自动切换编码,平衡性能与内存。
1. 字符串(string)
- 编码规则:根据字符串长度、内容动态选编码:
int:字符串长度 ≤20 且可转整数(如"123"),直接存整数,节省内存。embstr:字符串长度 ≤44 ,用连续内存块存储(优化缓存,适合短字符串)。raw:字符串长度 >44 ,用常规动态字符串存储(灵活处理长文本)。- (补充)部分场景还会结合 CPU 缓存行(64 字节)优化,但核心是长度驱动编码切换。
2. 列表(list)
- 编码规则:
quicklist(双向链表):Redis 3.2+ 后默认实现,是ziplist+ 双向链表的混合结构。小数据量时用ziplist压缩存储,数据量大时拆分链表节点,平衡内存与操作效率。ziplist(压缩列表):数据量小时间接使用(被quicklist封装),通过紧凑内存布局(多个元素连续存储)减少内存开销。
3. 哈希(hash)
- 编码规则:
ziplist:当哈希节点数 ≤512(hash-max-ziplist-entries)且字符串长度 ≤64(hash-max-ziplist-value),用压缩列表存储(键值对连续排列,省内存)。dict(字典):节点数 >512 或字符串过长,切换为哈希表(类似 JavaHashMap),保证大数量时的读写性能。
4. 集合(set)
- 编码规则:
intset(整数数组):元素全是整数且数量 ≤512(set-max-intset-entries),用紧凑数组存储(如{1,3,5}),节省内存。dict(字典):元素含非整数或数量 >512 ,切换为哈希表,支持任意字符串元素存储。
5. 有序集合(zset)
- 编码规则:
ziplist:元素数量 ≤128(zset-max-ziplist-entries)且字符串长度 ≤64(zset-max-ziplist-value),用压缩列表按 “分值 + 元素” 连续存储,小数据场景高效。skiplist(跳表):元素数量 >128 或字符串过长,用跳表 + 字典组合(跳表保证有序查询,字典快速定位元素),支持高性能范围查询(如ZRANGE)。
Value类型汇总表格如下:
| 数据类型(Value 所属类型) | 编码方式 | 触发条件 |
|---|---|---|
| string | int | 字符串长度 ≤ 20 且可转换为整数(如 "123") |
embstr | 字符串长度 ≤ 44 | |
raw | 字符串长度 > 44 | |
| cpu 缓存行优化 | (补充逻辑,基于缓存行 64 字节设计,辅助提升访问效率,非独立编码类型) | |
| list | quicklist | Redis 3.2+ 默认实现,是 ziplist + 双向链表的混合结构(动态适配数据量) |
ziplist | 数据量小时被 quicklist 间接使用(紧凑存储小列表) | |
| hash | ziplist | 节点数量 ≤ 512(hash-max-ziplist-entries)且字符串长度 ≤ 64(hash-max-ziplist-value) |
dict | 节点数量 > 512 或字符串长度 > 64 | |
| set | intset | 元素全为整数且数量 ≤ 512(set-max-intset-entries) |
dict | 元素含非整数或数量 > 512 | |
| zset | ziplist | 子节点数量 ≤ 128(zset-max-ziplist-entries)且字符串长度 ≤ 64(zset-max-ziplist-value) |
skiplist | 子节点数量 > 128 或字符串长度 > 64 |
1.2 String 类型
Redis 的 String(字符串)类型是最基础也最常用的数据结构,它以键值对(Key-Value)形式存储,支持多种操作和丰富的应用场景
String类型的特点
-
二进制安全
- 字符串可以存储任意二进制数据(如图片、音频、序列化对象等),Redis 不解析数据内容,仅按字节处理。例如:可直接存储图片的二进制流,或协议格式的二进制数据。
-
动态扩容机制
底层基于SDS(Simple Dynamic String)实现,长度会动态调整:- 字符串长度<1MB 时,扩容策略为 “加倍当前容量”(如从 20 字节扩到 40 字节);
- 长度≥1MB 时,每次扩容仅增加 1MB(避免过度分配内存);
- 最大长度限制为 512MB。
-
多编码存储优化
根据字符串内容和长度,自动选择最节省内存的编码方式:- int 编码:字符串长度≤20 且可转换为整数(如
"12345"),直接存储为整数(节省空间)。 - embstr 编码:字符串长度≤44,使用连续内存块存储(优化短字符串的读写效率)。
- raw 编码:字符串长度>44,使用常规动态字符串存储(适合长文本)。
- int 编码:字符串长度≤20 且可转换为整数(如
基础命令
基础读写命令:
| 命令 | 作用 | 示例 | 输出 / 效果 |
|---|---|---|---|
SET key value | 设置键值对 | SET user:name "Alice" | OK(设置成功) |
GET key | 获取键对应的值 | GET user:name | "Alice" |
DEL key | 删除键值对 | DEL user:name | 1(删除成功,返回受影响的数量) |
SETNX key value | 仅当键不存在时设置(原子操作) | SETNX lock "active"(键lock不存在时) | 1(设置成功);若已存在返回0 |
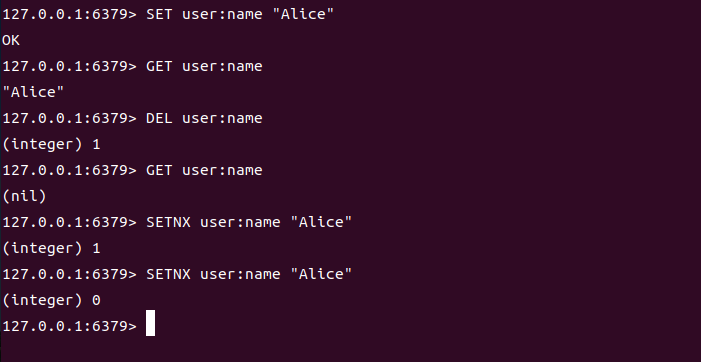
对应的操作如下:
SET user:name "Alice"
GET user:name
DEL user:name
GET user:name
SETINX user:name "Alice"
SETINX user:name "Alice"
2. 原子增减命令(适用于整数类型值)
| 命令 | 作用 | 示例 | 输出 / 效果 |
|---|---|---|---|
INCR key | 对值原子加 1(值需为整数) | SET count 10 → INCR count | 11(加 1 后结果) |
INCRBY key increment | 对值原子加指定整数 | INCRBY count 5 | 16(11+5 的结果) |
DECR key | 对值原子减 1 | DECR count | 15(16-1 的结果) |
DECRBY key decrement | 对值原子减指定整数 | DECRBY count 3 | 12(15-3 的结果) |
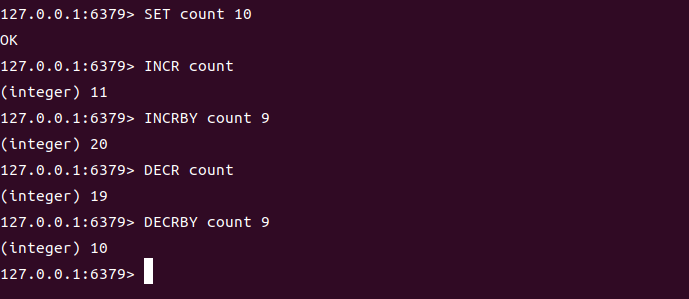
对应的操作如下:
SET count 10
INCR count
INCRBY count 9
DECR count
DECRBY count 9
3. 位操作命令(按二进制位操作)
String 类型可视为二进制位数组(每个字节 8 位),支持位级操作:
| 命令 | 作用 | 示例 | 输出 / 效果 |
|---|---|---|---|
SETBIT key offset value | 设置指定偏移量的 bit 值(0 或 1) | SETBIT user:online 0 1(第 0 位设为 1) | 0(返回该位原来的值) |
GETBIT key offset | 获取指定偏移量的 bit 值 | GETBIT user:online 0 | 1(返回第 0 位当前值) |
BITCOUNT key | 统计值为 1 的 bit 总数 | BITCOUNT user:online |
应用场景
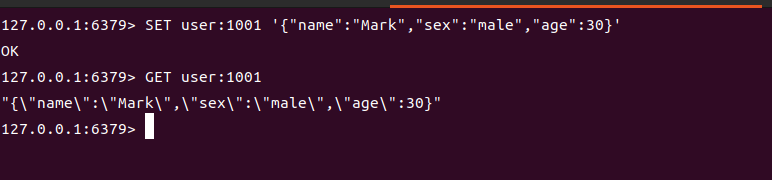
1. 存储对象(简单序列化)
适合存储字段少、修改频率低的对象(如用户基本信息),通常将对象序列化为 JSON 字符串:
# 存储用户ID=1001的信息
SET user:1001 '{"name":"Mark","sex":"male","age":30}'# 获取用户信息
GET user:1001
# 输出:'{"name":"Mark","sex":"male","age":30}'
2. 累加器(计数器)
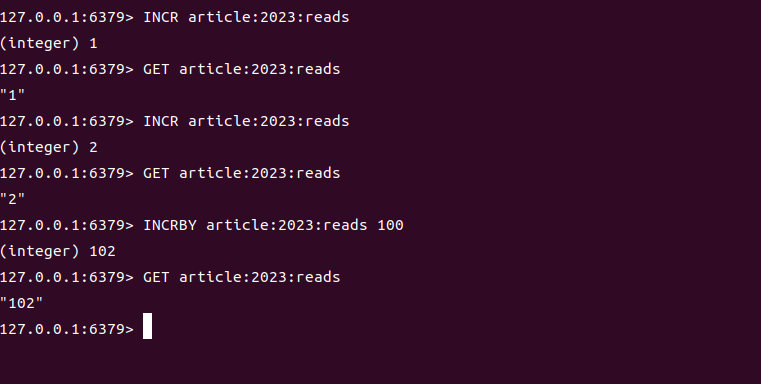
利用INCR/INCRBY的原子性,实现访问量、点赞数等统计:
# 统计文章ID=2023的阅读量(初始0)
INCR article:2023:reads # 第1次访问 → 1
INCR article:2023:reads # 第2次访问 → 2# 批量增加阅读量(一次加100)
INCRBY article:2023:reads 100 # 结果变为102
3. 分布式锁(基础实现)
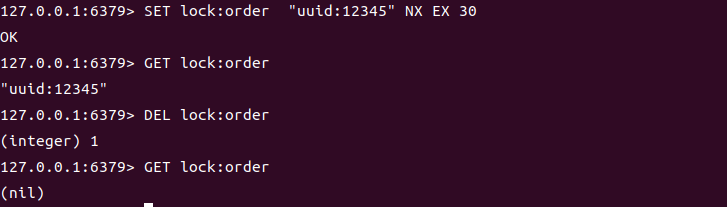
基于SETNX或SET key value NX EX的原子性,实现跨节点的资源互斥访问:
# 加锁:键`lock:order`不存在时设置,过期时间30秒(避免死锁)
SET lock:order "uuid:12345" NX EX 30
# 成功返回OK(获取锁);失败返回nil(锁已被占用)# 释放锁:先判断是否持有锁,再删除(避免误删他人锁)
# 伪代码逻辑:
if GET lock:order == "uuid:12345" DEL lock:order # 释放锁
4. 位运算(高效状态统计)
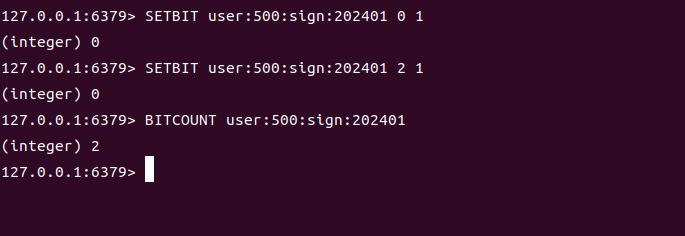
用 bit 位表示状态(如用户签到、在线状态),节省内存且支持批量统计:
# 记录用户签到(假设每月最多31天,用31个bit表示)
# 用户ID=500,1月1日签到 → 第0位设为1
SETBIT user:500:sign:202401 0 1
# 1月3日签到 → 第2位设为1
SETBIT user:500:sign:202401 2 1# 统计1月签到天数(bit为1的总数)
BITCOUNT user:500:sign:202401 # 输出:2(1日和3日签到)
1.3 List 类型
Redis 的 List(列表)类型是一种有序的字符串集合,底层基于双向链表(Redis 3.2 + 后优化为quicklist结构)实现,支持在首尾高效操作元素,适合实现栈、队列、消息队列等场景
List 类型的特点
-
有序性与可重复
列表中的元素按插入顺序排列,且允许重复(与 Set 不同)。例如:["a", "b", "a"]是合法的列表。 -
双向操作高效
首尾元素的插入(LPUSH/RPUSH)和删除(LPOP/RPOP)操作时间复杂度为O(1),但查找或操作中间元素需遍历,时间复杂度为O(n)。 -
底层存储优化(quicklist)
Redis 3.2 + 用quicklist替代传统双向链表,它是压缩列表(ziplist)+ 双向链表的混合结构:- 每个
quicklistNode节点包含一个ziplist(紧凑存储多个元素),减少内存碎片; - 元素压缩规则:若元素长度≥48 字节,或压缩前后长度差≤8 字节,则不压缩;否则用 LZF 算法压缩,节省内存。
- 每个
基础操作
1. 首尾操作(栈 / 队列核心)
| 命令 | 作用 | 示例 | 输出 / 效果 |
|---|---|---|---|
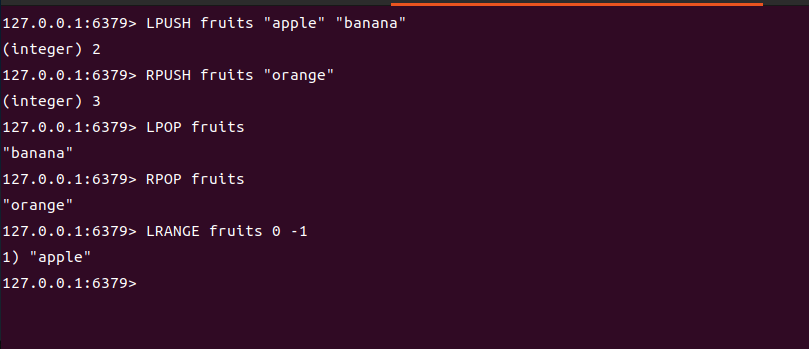
LPUSH key value... | 从左侧(头部)插入一个或多个元素 | LPUSH fruits "apple" "banana" | 2(插入后列表长度) |
RPUSH key value... | 从右侧(尾部)插入一个或多个元素 | RPUSH fruits "orange" | 3(列表变为["banana", "apple", "orange"]) |
LPOP key | 从左侧弹出一个元素 | LPOP fruits | "banana"(列表剩余["apple", "orange"]) |
RPOP key | 从右侧弹出一个元素 | RPOP fruits | "orange"(列表剩余["apple"]) |
LRANGE key start end | 返回指定索引范围的元素(0开始,-1表示最后) | LRANGE fruits 0 -1(假设列表为["a","b","c"]) | 1) "a" 2) "b" 3) "c" |
LPUSH fruits "apple" "banana"
RPUSH fruits "orange"
LPOP fruits
RPOP fruits
LRANGE fruits 0 -1
2. 其他常用命令
| 命令 | 作用 | 示例 | 输出 / 效果 |
|---|---|---|---|
LREM key count value | 移除列表中前count个值为value的元素 | LREM fruits 2 "apple"(移除 2 个 “apple”) | 1(实际移除的数量) |
LTRIM key start end | 裁剪列表,只保留start到end的元素 | LTRIM fruits 0 1(保留前 2 个元素) | OK |
BRPOP key timeout | 阻塞式右侧弹出(超时timeout秒返回nil) | BRPOP queue 10(10 秒内无元素则阻塞) |
应用场景
1. 栈(先进后出,FILO)
通过LPUSH(左侧入栈)+LPOP(左侧出栈)实现:
# 入栈:依次添加 1→2→3(左侧插入,栈顶为3)
LPUSH stack 1
LPUSH stack 2
LPUSH stack 3
# 栈结构:[3, 2, 1]# 出栈:从左侧弹出(先出3,再出2,最后出1)
LPOP stack # 返回3 → 栈变为[2,1]
LPOP stack # 返回2 → 栈变为[1]
2. 队列(先进先出,FIFO)
通过LPUSH(左侧入队)+RPOP(右侧出队)实现:
# 入队:依次添加任务A→B→C(左侧插入,队尾为A)
LPUSH queue "taskA"
LPUSH queue "taskB"
LPUSH queue "taskC"
# 队列结构:[taskC, taskB, taskA]# 出队:从右侧弹出(先出taskA,再出taskB,最后出taskC)
RPOP queue # 返回taskA → 队列变为[taskC, taskB]
RPOP queue # 返回taskB → 队列变为[taskC]
3. 阻塞队列(异步消息队列)
用LPUSH+BRPOP实现生产者 - 消费者模型(消费者阻塞等待消息):
# 生产者:添加消息到队列
LPUSH msg:queue "order:1001" # 订单1001待处理
LPUSH msg:queue "order:1002" # 订单1002待处理# 消费者:阻塞等待消息(超时时间30秒)
BRPOP msg:queue 30
# 立即返回:1) "msg:queue" 2) "order:1002"(处理订单1002)
BRPOP msg:queue 30
# 立即返回:1) "msg:queue" 2) "order:1001"(处理订单1001)
BRPOP msg:queue 30
# 30秒内无消息,返回(nil)
4. 固定窗口记录(如最近 N 条数据)
用LPUSH+LTRIM保留最新的 N 条记录(如最近 5 条用户动态):
# 插入用户动态(左侧插入,最新的在头部)
LPUSH user:1001:feeds "动态1:发布文章"
LPUSH user:1001:feeds "动态2:点赞内容"
LPUSH user:1001:feeds "动态3:评论好友"
LPUSH user:1001:feeds "动态4:分享链接"
LPUSH user:1001:feeds "动态5:关注博主"
LPUSH user:1001:feeds "动态6:收藏内容" # 此时有6条动态# 裁剪只保留最近5条(索引0到4)
LTRIM user:1001:feeds 0 4# 查看结果(最新的在最前)
LRANGE user:1001:feeds 0 -1
# 输出:动态6、动态5、动态4、动态3、动态2(仅保留最近5条)
1.3 Hash 类型
Redis 的 Hash(哈希)类型是一种键值对的集合,可视为 “嵌套版的 Key-Value”:外层用一个主 Key,内部用多个 Field-Value 键值对存储结构化数据。它类似编程语言中的 Map(如 Java HashMap、Python dict),适合存储对象、购物车等场景
Hash类型特点
- 结构化存储
- 一个 Hash 可包含多个 Field-Value 对,例如存储用户信息:
Key: user:1001
Field-Value: name → "Alice", age → 25, sex → "female"
- 动态编码优化
-
根据数据规模自动切换存储结构,平衡内存与性能:
-
ziplist(压缩列表):当 Hash 节点数 ≤512(
hash-max-ziplist-entries)且字符串长度 ≤64(hash-max-ziplist-value)时使用,紧凑存储节省内存。 -
dict(字典):节点数 >512 或字符串过长时切换为哈希表,保证大数量时的读写效率。
基础命令
1. 基本读写命令
| 命令 | 作用 | 示例 | 输出 / 效果 |
|---|---|---|---|
HSET key field value | 设置 Field-Value 对 | HSET user:1001 name "Bob" | 1(设置成功,返回新增数量) |
HGET key field | 获取指定 Field 的 Value | HGET user:1001 name | "Bob" |
HMSET key f1 v1 f2 v2... | 批量设置多个 Field-Value 对 | HMSET user:1001 age 30 sex "male" | OK(设置成功) |
HMGET key f1 f2... | 批量获取多个 Field 的 Value | HMGET user:1001 name age | 1) "Bob" 2) "30" |
HDEL key field... | 删除指定 Field | HDEL user:1001 sex | 1(删除成功,返回删除数量) |
HLEN key | 获取 Hash 的 Field 总数 | HLEN user:1001 | 2(剩余 |
HSET user:1001 name "Bob"
HGET user:1001 name
HMSET user:1001 age 30 sex "male"
HMGET user:1001 name age
HDEL user:1001 sex
HLEN user:1001
2. 原子增减命令(HINCRBY)
| 命令格式 | 作用 | 示例场景 | 初始状态(Hash: user:1001) | 执行命令 | 执行后结果(score 字段) | 说明 |
|---|---|---|---|---|---|---|
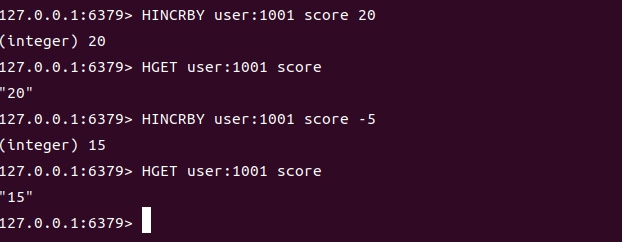
HINCRBY key field increment | 对 Hash 中指定 field 的数值执行原子性增减操作(increment 为正数则加,负数则减) | 增加用户积分 | score: 100 | HINCRBY user:1001 score 20 | 120 | increment=20,执行加 20 操作,结果原子性更新 |
| 减少用户积分 | score: 120 | HINCRBY user:1001 score -5 | 115 | increment=-5,执行减 5 操作,结果原子性更新 | ||
| 字段不存在时(默认从 0 开始) | 无score字段 | HINCRBY user:1001 score 50 | 50 | 若 field 不存在,默认初始值为 0,再执行加 50 |
应用场景
1. 存储对象(结构化数据)
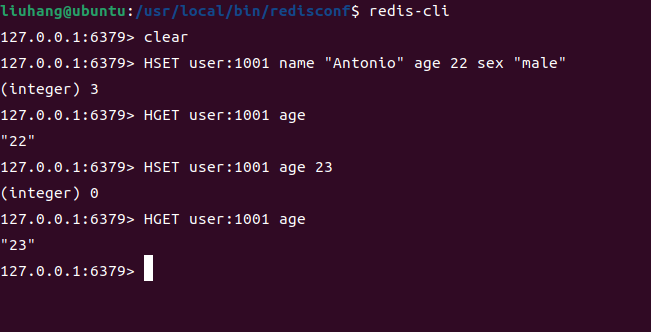
相比 String 存储 JSON 字符串,Hash 可按需更新字段,无需全量读写:
# 用 Hash 存储用户信息(推荐)
HMSET user:1001 name "Antonio" age 22 sex "male"# 按需修改字段(高效)
HSET user:1001 age 31 # 直接更新 age,无需解析整个对象# 用 String 存储 JSON(对比,低效)
SET user:1001 '{"name":"Antonio","age":22,"sex":"male"}'
# 修改 age 需:GET → 解析JSON → 修改 → 重新SET
2. 购物车场景
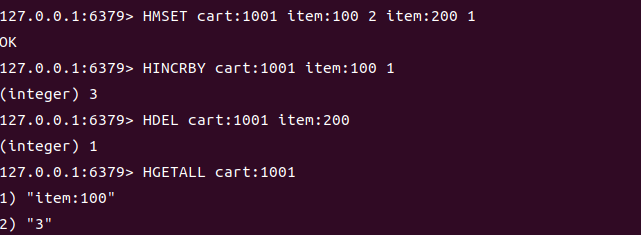
将用户 ID 作为 Hash 的 Key,商品 ID 作为 Field,数量作为 Value,灵活管理购物车
# 用户 1001 的购物车
HMSET cart:1001 item:100 2 item:200 1 # 商品100买2件,商品200买1件# 增加商品100的数量(原子操作)
HINCRBY cart:1001 item:100 1 # 数量变为3# 删除商品200
HDEL cart:1001 item:200 # 移除商品200# 查看购物车所有商品
HGETALL cart:1001
# 输出:1) "item:100" 2) "3"(仅保留商品100,数量3)
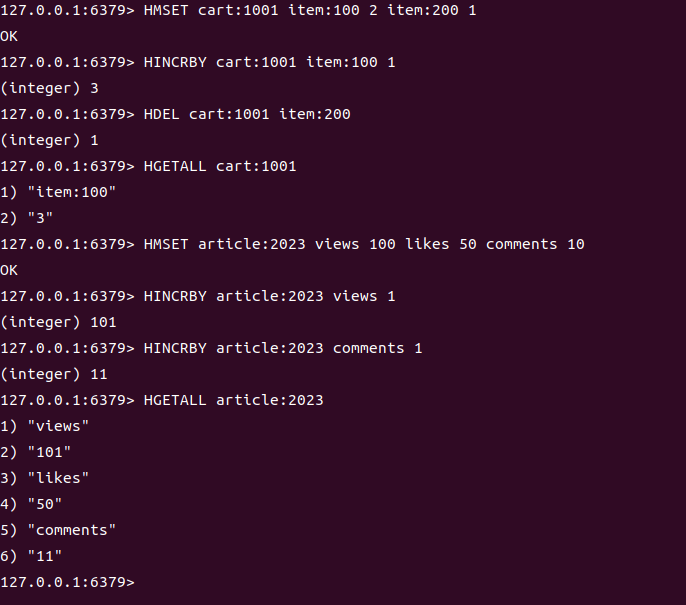
3. 统计信息(原子增减)
用 Hash 存储多维度统计数据,支持原子更新:
# 文章 2023 的互动数据
HMSET article:2023 views 100 likes 50 comments 10# 文章被浏览一次(原子增加)
HINCRBY article:2023 views 1 # views → 101# 新增一条评论(原子增加)
HINCRBY article:2023 comments 1 # comments → 11
与 String 存储 JSON 的对比
Hash 类型是 Redis 存储结构化数据的首选,通过 Field-Value 设计避免了 String 存储 JSON 的冗余操作,且动态编码机制(ziplist/dict)适配不同数据规模
| 场景 | Hash | String(JSON) |
|---|---|---|
| 更新字段 | 直接操作 Field(高效,O (1)) | 需全量读写、解析、重新存储(低效,O (n)) |
| 内存占用 | 小数据量时更省内存(ziplist 优化) | 存储冗余 JSON 格式,内存开销大 |
| 适用场景 | 结构化对象、按需更新字段(如用户信息) | 需存储复杂嵌套结构(如多层 JSON) |
1.4 Set 类型
Set 是 Redis 中的无序、唯一的字符串集合,适合存储需要去重且无需排序的数据,支持高效的交集、并集、差集运算。
Set 类型特点
-
唯一性:
- 集合中的元素不可重复(自动去重)。
-
无序性
- 元素存储顺序与插入顺序无关,无法通过索引访问。
-
动态编码:
- 当元素全为整数且数量 ≤512(
set-max-intset-entries)时,用整数数组(intset) 存储,节省内存。 - 当元素含非整数或数量 >512 时,用字典(dict) 存储,保证查询效率。
- 当元素全为整数且数量 ≤512(
基础命令
| 命令格式 | 作用 | 示例 | 输出 / 效果 |
|---|---|---|---|
SADD key member... | 向集合添加一个或多个元素(自动去重) | SADD fruits "apple" "banana" "apple" | 2(实际添加 2 个元素:apple、banana) |
SMEMBERS key | 返回集合中所有元素 | SMEMBERS fruits | 1) "apple" 2) "banana"(无序) |
SCARD key | 计算集合元素个数 | SCARD fruits | 2 |
SISMEMBER key member | 判断元素是否在集合中 | SISMEMBER fruits "apple" | 1(存在);0(不存在) |
SRANDMEMBER key [count] | 随机返回指定数量的元素(不删除) | SRANDMEMBER fruits 1 | 1) "banana"(随机返回 1 个) |
SPOP key [count] | 随机移除并返回指定数量的元素 | SPOP fruits 1 | 1) "apple"(移除并返回) |
SDIFF key1 key2... | 返回 key1 与其他集合的差集(只在 key1 中存在的元素) | SADD setA 1 2 3 → SADD setB 2 3 4 → SDIFF setA setB | 1) "1" |
SINTER key1 key2... | 返回所有集合的交集(共同存在的元素) | SINTER setA setB | 1) "2" 2) "3" |
SUNION key1 key2... | 返回所有集合的并集(合并去重) | SUNION setA setB | 1) "1" 2) "2" 3) "3" 4) "4" |
SADD fruits "apple" "banana" "apple"
SMEMBERS fruits
SCARD fruits
SISMEMBER fruits "apple"
SRANDMEMBER fruits 2
SPOP fruits 1
SADD setA 1 2 3
SADD setB 2 2 3
SDIFF setA setB
SINTER setA setB
SUNION setA setB
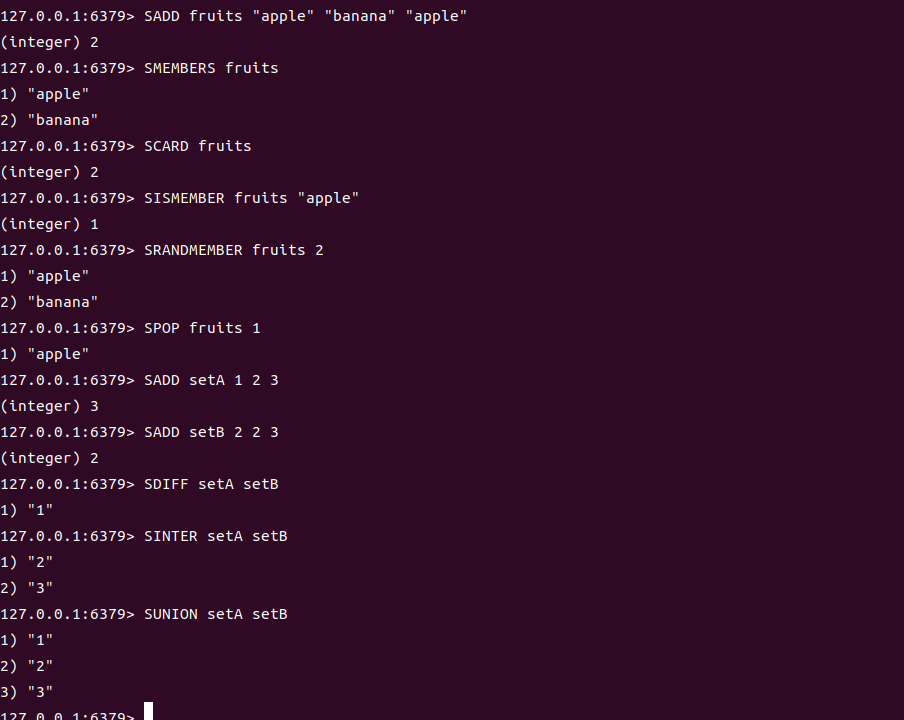
应用场景
1. 抽奖系统
存储参与用户 ID,随机抽取获奖者。
# 添加参与用户
SADD lottery:100 1001 1002 1003 1004 1005
# 随机抽取1名一等奖
SPOP lottery:100 1 # 返回如 "1003"(已从集合中移除)
# 随机抽取2名二等奖(不删除,可重复参与)
SRANDMEMBER lottery:100 2 # 返回如 "1001"、"1005"
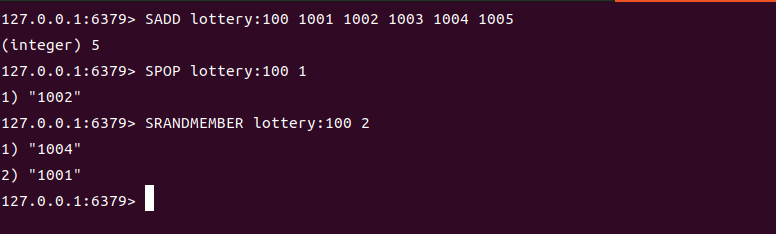
2. 共同关注 / 好友推荐
通过交集找共同好友,通过差集推荐可能认识的人
# A关注的人
SADD follow:A personB personC
# B关注的人
SADD follow:B personA personC personD
# A和B的共同关注
SINTER follow:A follow:B # 返回 "personC"
# 推荐B可能认识的人(A关注但B未关注的)
SDIFF follow:A follow:B # 返回 "personB"
# 推荐A可能认识的人(B关注但A未关注的)
SDIFF follow:B follow:A #返回"PersonA" "PersonD"
1.5 ZSet 类型
ZSet 是有序、唯一的字符串集合,每个元素关联一个分数(score),并按分数从小到大排序,适合实现排行榜、延时队列等场景。
ZSet 类型特点
-
有序性:
- 元素按分数(score)排序,支持范围查询。
-
唯一性:
- 元素不可重复,但分数可相同
-
动态编码:
- 当元素数量 ≤128(
zset-max-ziplist-entries)且字符串长度 ≤64(zset-max-ziplist-value)时,用压缩列表(ziplist) 存储,节省内存。 - 当元素数量 >128 或字符串过长时,用跳表(skiplist)+ 字典存储,跳表保证有序查询,字典快速定位元素。
- 当元素数量 ≤128(
基础命令
| 命令格式 | 作用 | 示例 | 输出 / 效果 |
|---|---|---|---|
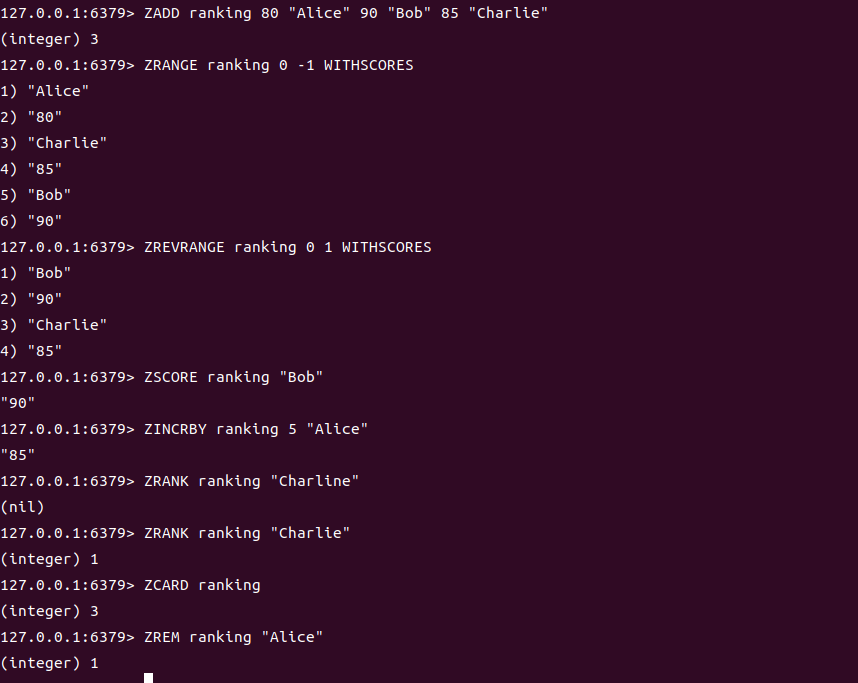
ZADD key score member... | 添加元素及分数(分数可重复) | ZADD ranking 80 "Alice" 90 "Bob" 85 "Charlie" | 3(添加 3 个元素) |
ZRANGE key start stop [WITHSCORES] | 按分数升序返回指定范围元素(0开始,-1表示所有) | ZRANGE ranking 0 -1 WITHSCORES | 1) "Alice" 2) "80" 3) "Charlie" 4) "85" 5) "Bob" 6) "90" |
ZREVRANGE key start stop [WITHSCORES] | 按分数降序返回指定范围元素 | ZREVRANGE ranking 0 1 WITHSCORES | 1) "Bob" 2) "90" 3) "Charlie" 4) "85"(取前 2 名) |
ZSCORE key member | 返回元素的分数 | ZSCORE ranking "Bob" | "90" |
ZINCRBY key increment member | 为元素分数增加增量(可负数) | ZINCRBY ranking 5 "Alice" | "85"(Alice 分数从 80→85) |
ZRANK key member | 返回元素的升序排名(从 0 开始) | ZRANK ranking "Charlie" | 1(升序第 2 位,索引 1) |
ZCARD key | 计算元素总数 | ZCARD ranking | 3 |
ZREM key member... | 删除元素 | ZREM ranking "Alice" | 1(删除成功) |
ZADD ranking 80 "Alice" 90 "Bob" 85 "Charlie"
ZRANGE ranking 0 -1 WITHSCORES
ZREVRANGE ranking 0 1 WITHSCORES
ZSCORE ranking "Bob"
ZINCRBY ranking 5 "Alice"
ZRANK ranking "Charlie"
ZCARD ranking
ZREM ranking ""Alice
应用场景
1. 排行榜
如热搜榜、游戏得分榜,按分数(点击量 / 得分)排序
# 记录新闻点击量(分数=点击次数)
ZINCRBY hot:20231001 1 "news:101" # 新闻101点击+1
ZINCRBY hot:20231001 1 "news:102" # 新闻102点击+1
# 获取当日热搜前3名(降序)
ZREVRANGE hot:20231001 0 2 WITHSCORES
# 输出:1) "news:101" 2) "50" 3) "news:102" 4) "30" ...
2. 延时队列
按时间戳作为分数存储消息,定时获取到期消息处理。
# 添加5秒后到期的消息(分数=当前时间+5)
ZADD delay:queue 1696000005 "msg:order1001" # 假设当前时间1696000000
# 轮询获取已到期消息(分数≤当前时间)
ZRANGEBYSCORE delay:queue 0 1696000005 LIMIT 0 1
# 返回 "msg:order1001"(处理后删除)
ZREM delay:queue "msg:order1001"
3. 时间窗口限流
限制用户某行为在指定时间内的次数(如 1 分钟内最多 5 次)。
# 用户1001的"评论"行为,1分钟内最多5次
# 分数=当前时间戳,存储行为记录
ZADD limit:1001:comment 1696000000 1696000000
ZADD limit:1001:comment 1696000030 1696000030 # 30秒后再评论
# 移除1分钟前的记录(只保留窗口内的)
ZREMRANGEBYSCORE limit:1001:comment 0 1695999940 # 1696000000-60=1695999940
# 检查窗口内次数(≤5则允许)
ZCARD limit:1001:comment # 返回2(允许继续评论)
Set 与 ZSet 的对比
| 特性 | Set(集合) | ZSet(有序集合) |
|---|---|---|
| 顺序 | 无序 | 按分数(score)有序 |
| 核心场景 | 去重、交集 / 差集运算(如共同好友) | 排序场景(如排行榜)、延时任务 |
| 底层结构 | 整数数组 / 字典 | 压缩列表 / 跳表 + 字典 |
| 元素唯一性 | 唯一 | 唯一(分数可重复) |
更多资料:https://github.com/0voice