【机器学习深度学习】模型微调:多久才算微调完成?——如何判断微调收敛,何时终止训练
目录
前言
一、微调过程的目标:优化模型表现
二、微调需要多久?
微调时间无法确定
三、如何判断微调何时收敛?
3.1 观察Loss的下降趋势
3.2 损失值趋于平稳,意味着收敛
如何识别收敛?
3.3 验证Loss的波动:继续训练的权衡
四、是否可以继续训练?——延续训练与效果权衡
4.1 继续训练的效益
4.2 早停(Early Stopping)
五、微调周期的实用建议
六、训练示例图
6.1 执行代码
6.2 训练效果
总结:微调时间不是关键,收敛与效果更重要

前言
在大模型的应用中,微调(Fine-tuning)是一项至关重要的技术。通过微调,企业和研究者可以使通用大模型在特定任务上表现得更加出色。然而,很多人在进行模型微调时,都有一个常见的问题:“微调应该持续多久?”
答案并不是那么简单,但本文将深入探讨模型微调的时间、收敛状态以及如何判断何时终止训练,帮助你更好地掌控微调过程。
▲一句话讲明白:
模型微调时间因任务、数据、模型规模和硬件而异,通常通过监控损失函数loss趋平(如600轮次)判断收敛,可根据场景需求选择终止或基于检查点继续训练。
一、微调过程的目标:优化模型表现
微调的目标是让模型在特定任务上表现得更好。这个任务可能是情感分析、语音识别、文档分类、或者任何其他行业特定任务。
在微调过程中,模型会基于一个预先训练好的模型(如LLaMA、GPT等),使用新的数据集进行二次训练。这个过程可以使模型从“通用能力”转向“特定任务能力”,以便更加准确地理解特定领域的语言和任务。
二、微调需要多久?
微调时间无法确定
微调的时间并没有固定标准,它取决于多个因素:
数据量的大小:大数据集需要更多的训练时间。
模型的大小:更大的模型(如LLaMA 13B、GPT-3)训练时间会更长。
硬件配置:训练设备的性能(如GPU型号、数量、显存等)直接影响训练速度。
任务的复杂性:如果是高复杂度的任务,如深度推理或跨领域知识迁移,训练可能需要更多时间。
因此,无法简单地给出“微调多长时间才算完成”的答案。微调的时长需要根据实际情况进行调整和监控。
三、如何判断微调何时收敛?
微调的核心在于优化损失函数(Loss),即通过最小化误差来提升模型的准确性和表现。一个模型的损失函数值反映了其在特定任务上的表现。
3.1 观察Loss的下降趋势
在训练过程中,模型的损失值(Loss)应该逐渐下降。通常情况下,Loss值的下降趋势是判断训练是否有效的主要依据。
-
快速下降阶段:刚开始的训练阶段,模型的Loss通常会快速下降,表示模型正在从数据中学习并改进。
-
趋于平稳阶段:随着训练的深入,Loss值逐渐趋于平稳,说明模型在不断改进,但提升空间越来越小。
3.2 损失值趋于平稳,意味着收敛
当Loss下降到一定程度后,通常会进入收敛状态。这时,Loss下降的幅度变得非常小,甚至接近于平稳。这表明,模型已经学会了大部分任务内容,进一步训练的效果非常有限。
如何识别收敛?
如果训练曲线的Loss下降速度明显变慢,并且开始趋于平稳,可以考虑终止训练。
另外,**训练过程中的验证损失(Validation Loss)**也是一个重要参考指标。如果验证Loss持续下降,说明模型在训练集和验证集上都能保持较好的表现。
参考图:六、训练示例图
3.3 验证Loss的波动:继续训练的权衡
有时在继续训练时,验证集上的损失会出现短暂上升,然后再次下降。这是因为训练过程中,模型可能会在某些数据点上进行过拟合(overfitting)或欠拟合(underfitting)。这时候,继续训练可能会提高模型的鲁棒性和稳定性。
注意:如果验证Loss不断上升,训练时就应考虑停止。这通常表示模型在训练集上过拟合了,失去了泛化能力。
四、是否可以继续训练?——延续训练与效果权衡
4.1 继续训练的效益
微调过程中,模型可能在一段时间内进入“趋于平稳”阶段,此时,继续训练仍然可以缓慢下降Loss,但效果逐渐变得微弱。一般来说:
-
继续训练可能带来极小的性能提升,特别是在任务较为简单或训练数据质量较高时。
-
逐步学习(Incremental Learning):如果在微调过程中,某些特定领域的样本训练效果不佳,继续训练会帮助模型逐步学会特定领域的语言。
但这个效益是逐步递减的,过度训练可能会导致过拟合,甚至使模型性能下降。
4.2 早停(Early Stopping)
为了避免过度训练,很多微调任务采用早停法。早停法会在验证损失开始上升时自动停止训练,从而避免无效的训练并节省时间。
**Tip:**如果你使用的是LLaMAFactory或其他微调框架,可以设置早停条件。通过监控验证集的损失和性能来控制训练时长。
五、微调周期的实用建议
根据训练时的观察和经验,以下是一些常见的微调训练时长的参考值:
-
小型模型(如7B参数):训练时间通常为几小时到几天,具体取决于数据量和硬件条件。
-
中型模型(如13B、30B参数):训练可能需要数天到数周,特别是在数据量较大的情况下。
-
大型模型(如70B+参数):训练时间通常为数周甚至更长,尤其是如果硬件资源有限时。
**Tip:**可以使用分布式训练、混合精度训练等技术来加速微调过程。
六、训练示例图
以下通过代码的显示来呈现一个训练600轮次和2400轮次loss的变化。600轮次时loss的下降趋势逐渐趋于平缓,也就意味着收敛,训练可以终止。如果是面对需要与训练数据的回复标签非常接近的情况,那可以适当考虑再继续往下训练,随着训练轮次的叠加,模型的回复效果会逐渐趋近于训练数据的回复标签,到这里一定得注意一个问题,如果模型回复的东西与训练数据的回复标签100%接近,那就不能叫做人工智能了,而是检索器。
小结:在训练的过程中,训练的轮次一定得适当,主要把握的点就是看loss的变化趋势,loss的下降趋势基本处于平缓的状态,就可以考虑终止训练。如果面对回复标准比较严谨的场景(如:法律,医疗)就可以考虑在此基础上继续训练一段时间,训练时间越长,越接近于训练标签,但需要适当控制,避免过拟合。
6.1 执行代码
import numpy as np
import matplotlib.pyplot as plt# Function to simulate loss curves
def generate_loss_data(epochs, converged=True):# Simulate training loss: rapid initial drop, then slow declinex = np.linspace(0, epochs, epochs)train_loss = 2.5 / (1 + x / 50) + 0.2 # Asymptotic decay to ~0.2val_loss = train_loss + np.random.normal(0, 0.05, epochs) # Validation loss with noiseif not converged:# For 2400 epochs, add slight validation loss increase after convergenceval_loss[600:] += 0.1 * np.exp(-(x[600:] - 600) / 500) # Temporary rise then declinetrain_loss[600:] -= 0.05 * np.exp(-(x[600:] - 600) / 1000) # Slower declinereturn x, train_loss, val_loss# Generate data for 600 epochs (converged)
epochs_600 = 600
x_600, train_loss_600, val_loss_600 = generate_loss_data(epochs_600, converged=True)# Generate data for 2400 epochs (extended training)
epochs_2400 = 2400
x_2400, train_loss_2400, val_loss_2400 = generate_loss_data(epochs_2400, converged=False)# Plotting
plt.figure(figsize=(12, 5))# Plot for 600 epochs
plt.subplot(1, 2, 1)
plt.plot(x_600, val_loss_600, label='Validation Loss', color='orange', linestyle='--', alpha=0.7, linewidth=1.5)
plt.plot(x_600, train_loss_600, label='Training Loss', color='blue', linestyle='-', linewidth=2, zorder=10)
plt.title('Loss Curves (600 Epochs - Converged)')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)# Plot for 2400 epochs
plt.subplot(1, 2, 2)
plt.plot(x_2400, val_loss_2400, label='Validation Loss', color='orange', linestyle='--', alpha=0.7, linewidth=1.5)
plt.plot(x_2400, train_loss_2400, label='Training Loss', color='blue', linestyle='-', linewidth=2, zorder=10)
plt.title('Loss Curves (2400 Epochs - Extended)')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.savefig('loss_curves_fixed.png')
plt.show()6.2 训练效果
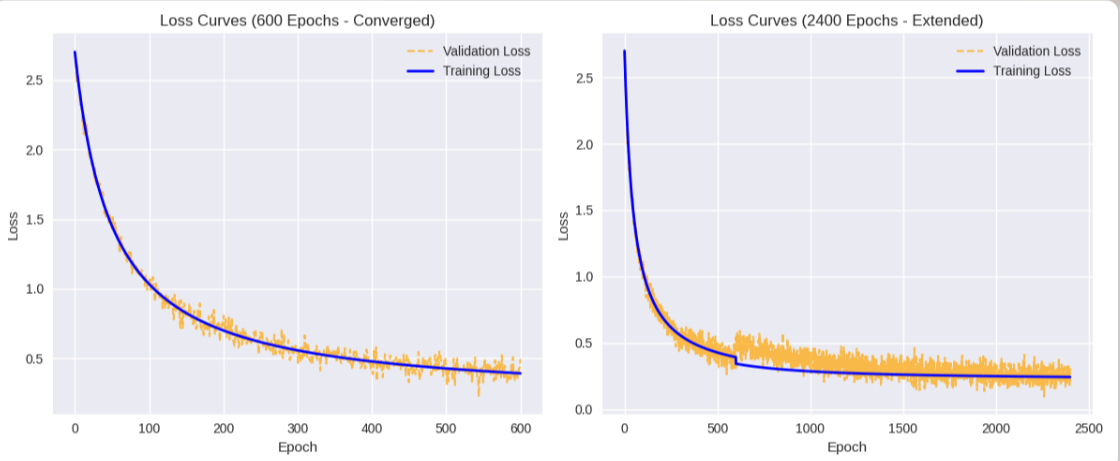
该示意图展示LLaMA-Factory微调中训练损失(蓝色实线)和验证损失(橙色虚线)的趋势,分600轮次(已收敛)和2400轮次(延长训练)两子图:
- 600轮次(左图):损失从2.5快速下降,约400轮次后趋平(约0.2),表明模型收敛,适合终止训练。
- 2400轮次(右图):前600轮次类似,后训练损失缓慢下降(至0.15),验证损失在600-1000轮次短暂上升(模拟过拟合),后稳定(约0.2)。
总结:微调时间不是关键,收敛与效果更重要
总结来说,微调的持续时间并没有固定答案,关键在于以下几个方面:
-
Loss的下降趋势:通过观察Loss的变化,你可以判断模型是否已经收敛。
-
训练与验证的权衡:要注意验证集上的Loss变化,避免过拟合。
-
继续训练的收益递减:继续训练虽可能带来微小改进,但训练时间过长可能导致无效训练。
最重要的是,根据实际应用的效果来决定微调的持续时间和停止点。对于企业来说,最核心的目标是通过微调让模型在特定任务中具备更强的处理能力,而不是单纯追求更低的损失值。