java基础(day16)set-map
目录
一.Set集合
1.hashset集合中方法:
2.Collection和List的接口中的方法:
3.LinkedHahSet:
4.TreeSet:
5.set的去重
二.Map集合
1. HashMap源码分析
1.1. HashMap数据结构概述
2.哈希冲突
3. HashMap数据结构定义
4. HashMap的hash函数
5. HashMap的数组容量
6. HashMap的扩容
7.hashMap方法:
put(key, value)存键值对,如果集合不存在此键,直接存,返回值为null
当集合存在此键,则更 新此键对应的值,返回旧值
void putAll(Map m)
添加map1中的所有元素存入当前map集合中
putIfAbsent(key, value) 如果存在此键,则不存,返回值为键对应的旧值
get(key) 返回value值,如果key不存在,则返回null
getOrDefault(key, defaultValue)
根据key,返回value值,如果key不存在,则返回defaultValue
boolean containsKey(key) 判断集合中是否存在此键
boolean containsValue(value) 判断集合中是否存在此值
boolean isEmpty() 判断集合是否为空
size() 获取集合中元素的个数
remove(key) 删除此键对应的键值对,返回旧值
根据key 替换value 并返回{原 value值}:如果key不存在,则返回null
根据key和value,替换value并返回{原 value值}:如果key不存在,则返回null
遍历方法:
8.Treemap用法
小结:
9.LinkedHashMap用法
小结
三.Collections类
static boolean disjoint(Collectionc1, Collectionc2)
判断两个集合中是否存在相同的元素,如果存在返回false,不存在,返回true.
static void fill(Listlist, T obj)
public static int frequency(Collectionc, Object o)
获取集合中,指定元素出现的频率(次数)
String max = Collections.max(list);
默认进行内容排序,这是自定义后的做法
void swap(Listlist, int i, int j)
int binarySearch(List> list, T key)
小结:
一.Set集合
Map用于存储key-value的映射,对于充当key的对象,是不能重复的,并且,不但需要正确覆写equals()方法,还要正确覆写hashCode()方法。
如果我们只需要存储不重复的key,并不需要存储映射的value,那么就可以使用Set。
Set用于存储不重复的元素集合,它主要提供以下几个方法:
- 将元素添加进
Set<E>:boolean add(E e) - 将元素从
Set<E>删除:boolean remove(Object e) - 判断是否包含元素:
boolean contains(Object e)
public class Main {public static void main(String[] args) {Set<String> set = new HashSet<>();System.out.println(set.add("abc")); // trueSystem.out.println(set.add("xyz")); // trueSystem.out.println(set.add("xyz")); // false,添加失败,因为元素已存在System.out.println(set.contains("xyz")); // true,元素存在System.out.println(set.contains("XYZ")); // false,元素不存在System.out.println(set.remove("hello")); // false,删除失败,因为元素不存在System.out.println(set.size()); // 2,一共两个元素}
}Set实际上相当于一个只存储key、不存储value的特殊Map。放入Set的元素和Map的key特点类似,不允许重复。所以,我们经常用Set用于去除重复元素。并且元素也需要正确实现equals()和hashCode()方法,否则该元素无法正确地放入Set。
常用的Set实现类是HashSet,内部使用HashMap作为存储结构。核心代码如下:
public class HashSet<E> implements Set<E> {// 持有一个HashMapprivate HashMap<E, Object> map = new HashMap<>();// 放入HashMap的value(常量)private static final Object PRESENT = new Object();public boolean add(E e) {return map.put(e, PRESENT) == null;}public boolean contains(Object o) {return map.containsKey(o);}public boolean remove(Object o) {return map.remove(o) == PRESENT;}
}Set接口并不保证有序,而SortedSet接口则保证元素是有序的:
HashSet是无序的,因为它实现了Set接口,并没有实现SortedSet接口;TreeSet是有序的,因为它实现了SortedSet接口
┌───┐│Set│└───┘▲┌────┴─────┐│ │
┌───────┐ ┌─────────┐
│HashSet│ │SortedSet│
└───────┘ └─────────┘▲│┌─────────┐│ TreeSet │└─────────┘HashSet集合:该集合特点是无序唯一,输出的顺序既不是添加的顺序,也不是String排序的顺序。
public class Main {public static void main(String[] args) {Set<String> set = new HashSet<>();set.add("apple");set.add("banana");set.add("pear");set.add("orange");for (String s : set) {System.out.println(s);}}
}TreeSet集合:TreeSet集合内部使用TreeMap作为存储结构,所以在遍历TreeSet时,输出元素的顺序是经过排序的。按照元素的不同比较方式进行排序。所以,添加的元素必须正确实现Comparable接口,如果没有实现Comparable接口,那么创建TreeSet时必须传入一个Comparator对象。
public class Main {public static void main(String[] args) {Set<String> set = new TreeSet<>();set.add("apple");set.add("banana");set.add("pear");set.add("orange");for (String s : set) {System.out.println(s);}}
}1.hashset集合中方法:
HashSet<String> hashSet = new HashSet<>();// 添加元素boolean b1 = hashSet.add("张三");hashSet.add("张三");hashSet.add("李四");hashSet.add("王五");System.out.println("添加元素:"+b1);System.out.println("添加元素后的集合:"+hashSet);// 快速生成List集合List<String> list = Arrays.asList("a张三","b张三","c张三");boolean b2 = hashSet.addAll(list);// 添加元素集合,只要成功的添加一个元素,返回值为trueSystem.out.println("添加元素集合:"+b2);System.out.println("添加元素集合后的集合:"+hashSet);System.out.println("集合大小:"+hashSet.size());System.out.println("判断集合中是否包含元素:"+hashSet.contains("张三"));// 使用迭代器Iterator<String> iterator = hashSet.iterator();while (iterator.hasNext()){String item = iterator.next();System.out.println("迭代元素:"+item);}System.out.println("------------------------");for (String item:hashSet){System.out.println("迭代元素:"+item);
// hashSet.hashCode()}2.Collection和List的接口中的方法:
1.Collection:1.接口的方法:添加: boolean add(E e);boolean addAll(Collection<? extends E> c);int size();boolean contains(Object o);boolean containsAll(Collection<?> c);boolean remove(Object o);boolean removeAll(Collection<?> c);boolean retainAll(Collection<?> c);void clear();boolean isEmpty();2.Collection 接口的子接口:List: 有序可重复:boolean addAll(int index, Collection<? extends E> c);E get(int index);E set(int index, E element);void add(int index, E element);E remove(int index);int indexOf(Object o);ListIterator<E> listIterator();int lastIndexOf(Object o);List<E> subList(int fromIndex, int toIndex);3.LinkedHahSet:
特点: 有序且唯一
public class Demo05 {public static void main(String[] args) {//LinkedHashSet 有序且唯一HashSet<String> hs1 = new LinkedHashSet<>();//添加元素集合hs1.add("曹操");hs1.add("周瑜");hs1.add("晁盖");hs1.add("曹操");System.out.println(hs1);}
}4.TreeSet:
特点:
TreeSet集合,是可排序的,且唯一。
在使用Treeset集合时候,需要注意,一定要提供排序规则给对象(泛型类实现comparable接口)或者对象提供Comparator接口。
1.无参构造方法,排序规则使用泛型类型这个类定义的排序规则。
2.有参构造TreeSet(Comparator<? super T> comparator)排序比较规则按照传入的参数规则为准。
如果泛型类型不是Comparable类型,必须要提供一个Comparator对象提供比较规则
Set<Book> set = new TreeSet<>(new Comparator<Book>() {@Overridepublic int compare(Book o1, Book o2) {if (o1.getPrice()>o2.getPrice()){return 1;} else if (o1.getPrice()== o2.getPrice()) {return 0;}else {return -1;}}});Book b1 = new Book("明朝那些事","这口味真地道",233,233);Book b2 = new Book("明朝那些事1","这口味真地道1",1233,2333);Book b3 = new Book("明朝那些事2","这口味真地道2",2233,233);Book b4 = new Book("明朝那些事","这口味真地道",233,233);set.add(b1);set.add(b2);set.add(b3);set.add(b4);System.out.println(set);}小练一下:
package apsource;import java.util.HashSet;
import java.util.Set;
import java.util.TreeSet;public class Demo08 {public static void main(String[] args) {Set<Book> set = new TreeSet<>();Book b1 = new Book("明朝那些事","这口味真地道",233,233);Book b2 = new Book("明朝那些事1","这口味真地道1",1233,2333);Book b3 = new Book("明朝那些事2","这口味真地道2",2233,233);Book b4 = new Book("明朝那些事","这口味真地道",233,233);set.add(b1);set.add(b2);set.add(b3);set.add(b4);System.out.println(set);}
}
package apsource;import java.util.TreeSet;public class Demo10 {// Set<String> set = new HashSet<>();// 唯一,可排序的集合public static void main(String[] args) {TreeSet<String> set = new TreeSet<>();set.add("hello");set.add("world");set.add("java");set.add("java");set.add("aaaa");System.out.println( set);TreeSet<Integer> set1 = new TreeSet<>();set1.add(33);set1.add(20);set1.add(330);System.out.println(set1);}
}
5.set的去重
1.根据hashcode查看是否存在相同的hashcode,如果无,则认为不重复,直接放
2.如果存在相同的hashcode,则进行内容的比较(equals),不同,认为不同,放
如果hashcode 和equals完全相同,则认为相同元素,不放
小结
Set用于存储不重复的元素集合:-
HashSet集合特点:无序,值唯一,使用HashMap作为存储结构。TreeSet集合特点:自动排序,值唯一,使用TreeMap作为存储结构。- 利用
Set可以去除重复元素; - 遍历
SortedSet按照元素的排序顺序遍历,也可以自定义排序算法
二.Map集合
1. HashMap源码分析
1.1. HashMap数据结构概述
HashMap内部数据结构使用数组+链表+红黑树进行存储。数组类型为Node[],每个Node都保存了某个KV键值对元素的key、value、hash、next等值。由于next的存在,所以每个Node对象都是一个单向链表中的组成节点。
当新添加一个KV键值对元素时,通过该元素的key的hash值,计算该元素在数组中应该保存的下标位置。如果该下标位置如果已经存在其它Node对象,则采用链地址法处理,即将新添加的KV键值对元素将以链表形式存储。将新元素封装成一个新的Node对象,插入到该下标位置的链表尾部(尾插法)。当链表的长度超过8并且数组长度大于64时,为了避免查找搜索性能下降,该链表会转换成一个红黑树。
1.1.1如下是我对hashmap的理解:
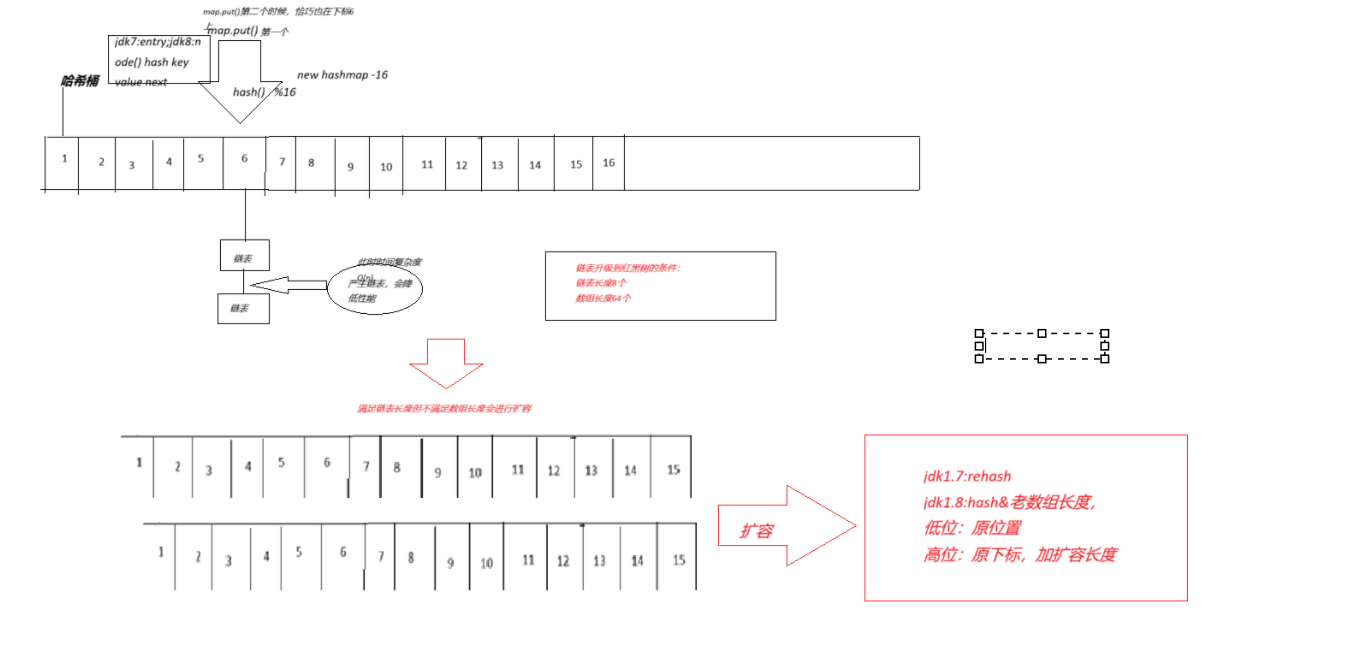
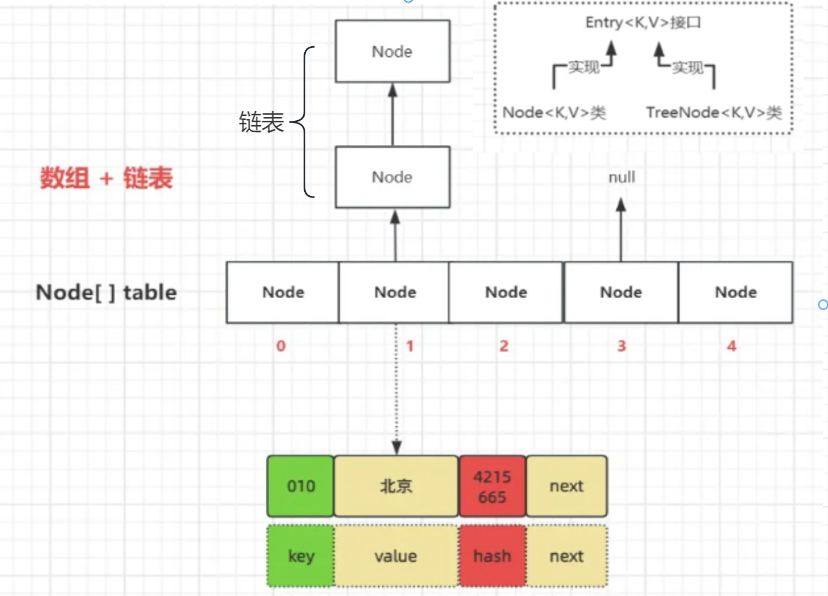
2.哈希冲突
1.2.1.解决哈希冲突的常见方法:
- 链地址法:哈希表中的每个
Node节点都有一个next指针,构成一个单向链表。被分配到同一个下标位置上的多个Node节点(发生哈希冲突),可以通过存入同一个单向
链表来解决这个问题。 - 开放定址法:一旦发生哈希冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
- 建立公共溢出区:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
- 再哈希法:再哈希法又叫双哈希法,有多个不同的
Hash函数,当发生冲突时,使用第二个,第三个,….,等哈希函数计算地址,直到无冲突。虽然不易发生聚集,但是增加了计算时间。
3. HashMap数据结构定义
node类型的数组
public class HashMap// 每个Node既保存一个KV键值对,同时也是链表中的一个节点Node<K,V>[] table;
}链表节点类 Node
public class HashMap{// ...// 静态内部类Nodestatic class Node<K,V> implements Map.Entry<K,V> {final int hash; // 哈希值final K key; // 键V value; // 值Node<K,V> next; // 下一个节点(由于只拥有next,所以该链表为单向链表)}// ...
}4. HashMap的hash函数
HashMap通过新添加元素key的hashCode()方法,计算一个hash值,然后通过这个hash值计算位置下标。
原理:
通过key的hashCode()方法返回的哈希值与它的高16位进行异或运算
1)如果key等于null:可以看到当key等于null的时候也是有哈希值的,返回的是0.
2)如果key不等于null:首先计算出key的hashCode赋值给h,然后与h无符号右移16位后的二进制进行按位异或得到最后的hash值
作用:计算出的hash值,在计算下标位置时,会更“散列”,减少哈希冲突
5. HashMap的数组容量
首先HashMap在第一次添加KV键值对时,如果数组为空,则将数组容量按照默认初始化容量16进行扩容。默认初始化容量DEFAULT_INITIAL_CAPACITY通过位运算1<<4计算得出。
public class HashMap{/*** The default initial capacity - MUST be a power of two.*/static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16// 添加键值对final V putVal(int hash, K key, V value) {Node<K,V>[] tab; // 数组Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)// 如果数组为空,则该数组扩容为16n = (tab = resize()).length;}
}每次添加KV键值对时,都会通过hash()函数,按照key的hashCode()计算出来的hash值,按照(n-1)&hash的方式计算出一个下标,该下标代表当前KV键值对在数组中的保存位置。这种计算下标的方式,作用等同于hash值 与 数组长度进行 取模运算。
// 两种计算方式结果相同,但效率不同
int index1 = (数组长度 - 1) & hash值 // 位运算效率高,要求数组长度必须为2的n次幂
int index2 = hash值 % 数组长度 // 算术运算效率低public class HashMap{// 添加键值对final V putVal(int hash, K key, V value) {Node<K,V>[] tab; // 数组Node<K,V> p; // 临时节点int n, i; // n代表数组长度,i代表元素下标位置// 根据当前元素的key的hash值,计算该元素在数组tab中的下标位置iif ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);}
}6. HashMap的扩容
HashMap底层采用数组+链表+红黑树,扩容过程中需要按照数组容量和加载因子来进行判断。
数组容量:基础数组Node<K,V>[] table的长度。如果没有指定容量,添加第一个元素时,该数组按照默认值16进行初始化。
加载因子:用来表示HashMap集合中元素的填满程度,默认为0.75f。越大则表示允许填满的元素就越多,集合的空间利用率就越高,但是冲突的机会增加。反之,越小则冲突的机会就会越少,但是空间很多就浪费。
综述一下:
数据结构:Node<K,V>[] table;数组+链表+树
put整理:
1.通过i= (n-1)&hash计算当前键值对要存放的下标位置,此处元素是否为null,如果为null直接存储 2.如果不为Null,判断当前的下标元素key是否和要存储的ke完全一样,key一样,则value进行覆盖 3.键如果不同,则产生了hash冲突,将当前要存放的键值对存放进来
4.1.判断当前的节点是否是树形节点,如果是树形节点,以树形存放方式操作
4.2.如果不是树形节点。就是链表:找p.next == null 的位置(找的过程中也会和链表的每个元素的key进行比较,p.next进行赋值操作 链表元素个数的判断>8 && 数组长度 <64 --扩容2倍 存放完元素如果达到扩容阈值,2倍扩容
扩容: 无参构造初始化对象,第一次添加元素时候,首次扩容到16
7.hashMap方法:
put(key, value)存键值对,如果集合不存在此键,直接存,返回值为null
当集合存在此键,则更 新此键对应的值,返回旧值
String item1 = map.put("110", "北京");
String item2 = map.put("110", "天津");void putAll(Map m)
HashMap<String, String> map1 = new HashMap<>();map1.put("110", "北京");map1.put("130", "河北");添加map1中的所有元素存入当前map集合中
map.putAll(map1);
putIfAbsent(key, value) 如果存在此键,则不存,返回值为键对应的旧值
String oldValue = map.putIfAbsent("110", "上海");System.out.println("putIfAbsent返回值"+oldValue);System.out.println(map);get(key) 返回value值,如果key不存在,则返回null
String value1 = map.get("110");System.out.println("110对应的值是"+value1);getOrDefault(key, defaultValue)
根据key,返回value值,如果key不存在,则返回defaultValue
String value2 = map.getOrDefault("120", "上海");System.out.println("120对应的值是"+value2);boolean containsKey(key) 判断集合中是否存在此键
boolean containsKey = map.containsKey("110");System.out.println("集合中是否存在110键:"+containsKey);boolean containsValue(value) 判断集合中是否存在此值
boolean containsValue = map.containsValue("北京");System.out.println("集合中是否存在北京值:"+containsValue);boolean isEmpty() 判断集合是否为空
System.out.println("集合是否为空:"+map.isEmpty());
size() 获取集合中元素的个数
System.out.println("集合中元素个数:"+map.size());
remove(key) 删除此键对应的键值对,返回旧值
String oldValue = map.remove("110");System.out.println("删除的旧值是:"+oldValue);根据key 替换value 并返回{原 value值}:如果key不存在,则返回null
String oldValue = map.replace("130", "天津");System.out.println("130对应的旧值是:"+oldValue);根据key和value,替换value并返回{原 value值}:如果key不存在,则返回null
boolean b = map.replace("130", "天津", "河北");System.out.println("130对应的旧值是:"+b);boolean b2 = map.remove("130", "天津");System.out.println("130对应的旧值是:"+b2);System.out.println("目前map中的元素为:"+map);map.clear();System.out.println("清空后:"+map);
遍历方法:
1.Set<K> keySet()获取所有的键
// Set< String> keys = map.keySet();
// for (String key : keys) {
// String value = map.get(key);
// System.out.println(key+"--->"+value);
// }2.Collection<V> values() 获取所有的值
// Set< String> values = (Set<String>) map.values();
// for (String value : values) {
// System.out.println(value);
// }3.Set<Map.Entry<K,V>> entrySet() 获取所有的键值对对象
// Set<HashMap.Entry<String, String>> entries = map.entrySet();// for (Map.Entry<String, String> entry : entries){
// System.out.println( entry.getKey()+"=="+entry.getValue());
// }8.Treemap用法
根据key可排序和去重
TreeMap<User, Integer> treeMap = new TreeMap<>(new Comparator<User>() {@Overridepublic int compare(User o1, User o2) {int result = o1.getAge() - o2.getAge();if(result == 0){result = o1.getName().compareTo(o2.getName());}return result;}});treeMap.put(new User("张三", 18), 344444);treeMap.put(new User("张三", 18), 344444);treeMap.put(new User("李四", 182), 3444);treeMap.put(new User("王五", 18), 3444);for(Map.Entry<User, Integer> entry: treeMap.entrySet()){System.out.println(entry.getKey()+"--"+entry.getValue());}小结:
SortedMap在遍历时严格按照Key的顺序遍历,最常用的实现类是TreeMap;- 作为
SortedMap的Key必须实现Comparable接口,或者传入Comparator; - 要严格按照
compare()规范实现比较逻辑,否则,TreeMap将不能正常工作;
9.LinkedHashMap用法
HashMap<User, Integer> map = new LinkedHashMap<>();map.put(new User("张三", 18), 344444);map.put(new User("张三", 18), 344444);map.put(new User("李四", 182), 3444);map.put(new User("王五", 18), 3444);for(Map.Entry<User, Integer> entry: map.entrySet()){System.out.println(entry.getKey()+"--"+entry.getValue());}
小结
- 最常用的一种Map实现是
HashMap;(无序,key唯一) HashMap的数据结构采用数组+链表+红黑树HashMap的按照key的hash值计算数组中的存储位置下标,计算方式:(n-1)&hash。- 如果在该下标位置已经存在元素,代表产生哈希冲突,则采用链地址法处理,以单向链表的形式,将新元素存储在链表的尾部(尾插法)。
- 当链表中
Node节点的数量大于8并且数组的长度大于64时,链表会转换成一个红黑树,有利于查找搜索。 HashMap的默认容量为16,加载因子为0.75f,当集合元素个数超过扩容阈值(容量*加载因子)时,HashMap会将底层数组容量按照2倍进行扩容。
三.Collections类
static boolean disjoint(Collection<?> c1, Collection<?> c2)
判断两个集合中是否存在相同的元素,如果存在返回false,不存在,返回true.
List<String > list1 = Arrays.asList("a阿里","b百度");List<String > list2 = Arrays.asList("c中国","d中国");boolean b = Collections.disjoint(list1, list2);System.out.println(b);static <T> void fill(List<? super T> list, T obj)
ArrayList<String> arrayList = new ArrayList<String>(10);arrayList.addAll(list1);arrayList.addAll(list2);Collections.fill(arrayList, "中国");System.out.println(arrayList);public static int frequency(Collection<?> c, Object o)
获取集合中,指定元素出现的频率(次数)
int number = Collections.frequency(arrayList, "中国");System.out.println(number);List<String> list = Arrays.asList("a","b","c","d","e");Static T max(Collection<? extends T> coll)
String max = Collections.max(list);
String max = Collections.max(list, new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {return o1.compareTo(o2);static T min(Collection<? extends T> coll)
String min = Collections.min(list, new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {return o1.compareTo(o2);}});默认进行内容排序,这是自定义后的做法
Collections.sort( list, new Comparator<String>(){@Overridepublic int compare(String o1, String o2) {return o1.length() - o2.length();}})static void reverse(List<?> list)
Collections.reverse(list);System.out.println("反转后的集合为:"+ list);static void shuffle(List<?> list)
Collections.shuffle(list);System.out.println("随机排序后的集合为:"+ list);void swap(List<?> list, int i, int j)
List<String > list3 = Arrays.asList("a","b","c","d","e");Collections.swap(list, 0, 1);System.out.println("交换后的集合为:"+ list3);int binarySearch(List<? extends Comparable<? super T>> list, T key)
int index = Collections.binarySearch(list3, "c");System.out.println(index);小结:
Collections工具类提供了一组静态方法,方便对集合类进行操作:
- 创建空集合;
- 创建单元素集合;
- 排序/洗牌等操作