Triton源代码分析 - 目录
torch.compile简介
Triton相对其他DL Compiler的主要优点就是Pytorch Native + Open Source。因此在介绍Triton之前,先简单介绍一下Pytorch的torch.compile。
在Pytorch 2.x中,引入了torch.compile特性,主要包含如下4个部分:
TorchDynamo:基于Python Frame Evaluation Hook技术,实现安全的Pytorch的计算图捕获。
AOTAutograd: AOT生成计算图的反向图。
PrimTorch:规范化2000+ PyTorch Operators为250+ Primitive Operators, 极大降低了开发Pytorch后端的难度。
TorchInductor:一个Deep Learning Compiler,为多种加速器生成高性能代码。对NVIDIA和AMD GPUs, 使用OpenAI Triton编译器作为Backend。
torch.compile编译过程如下:
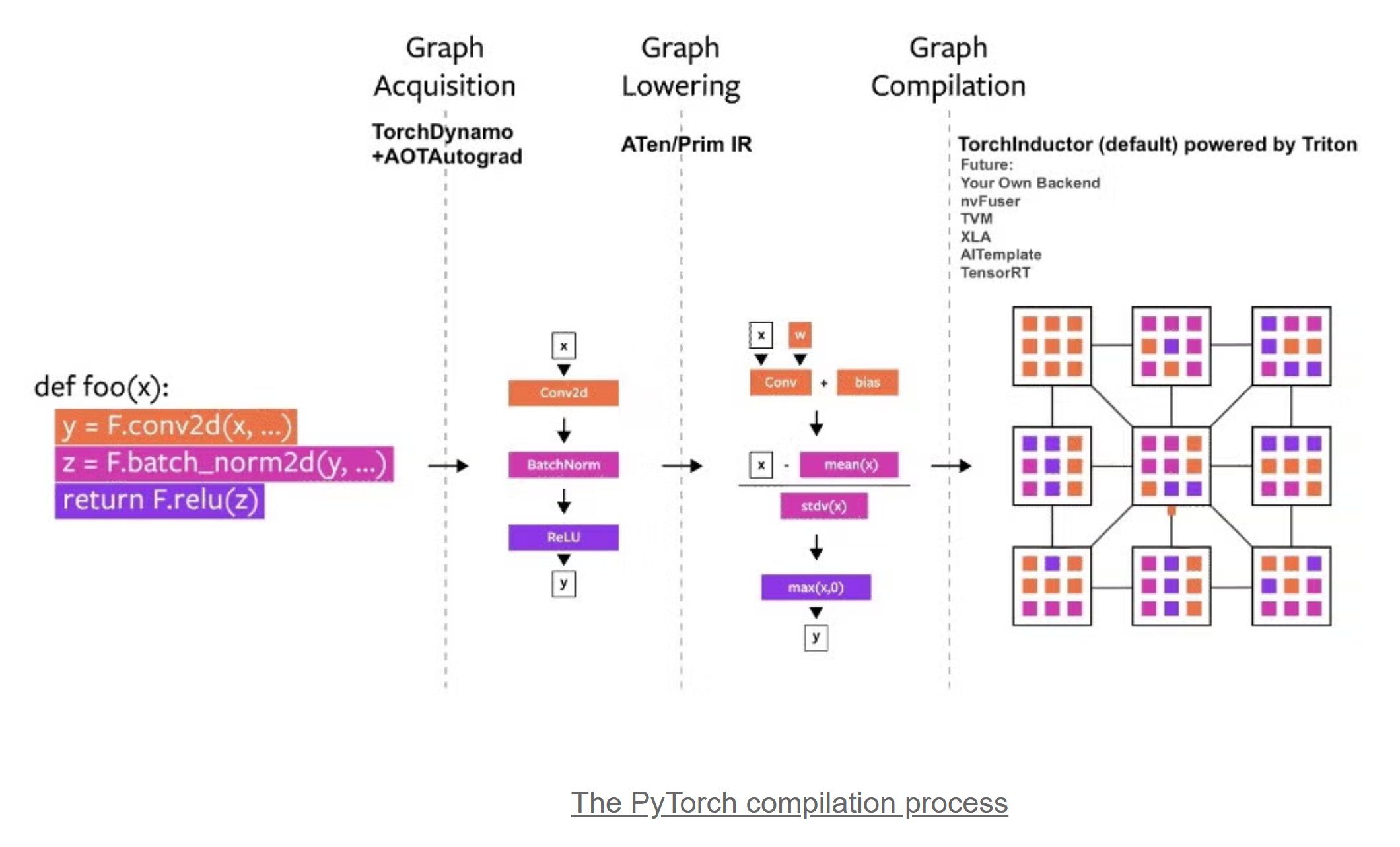
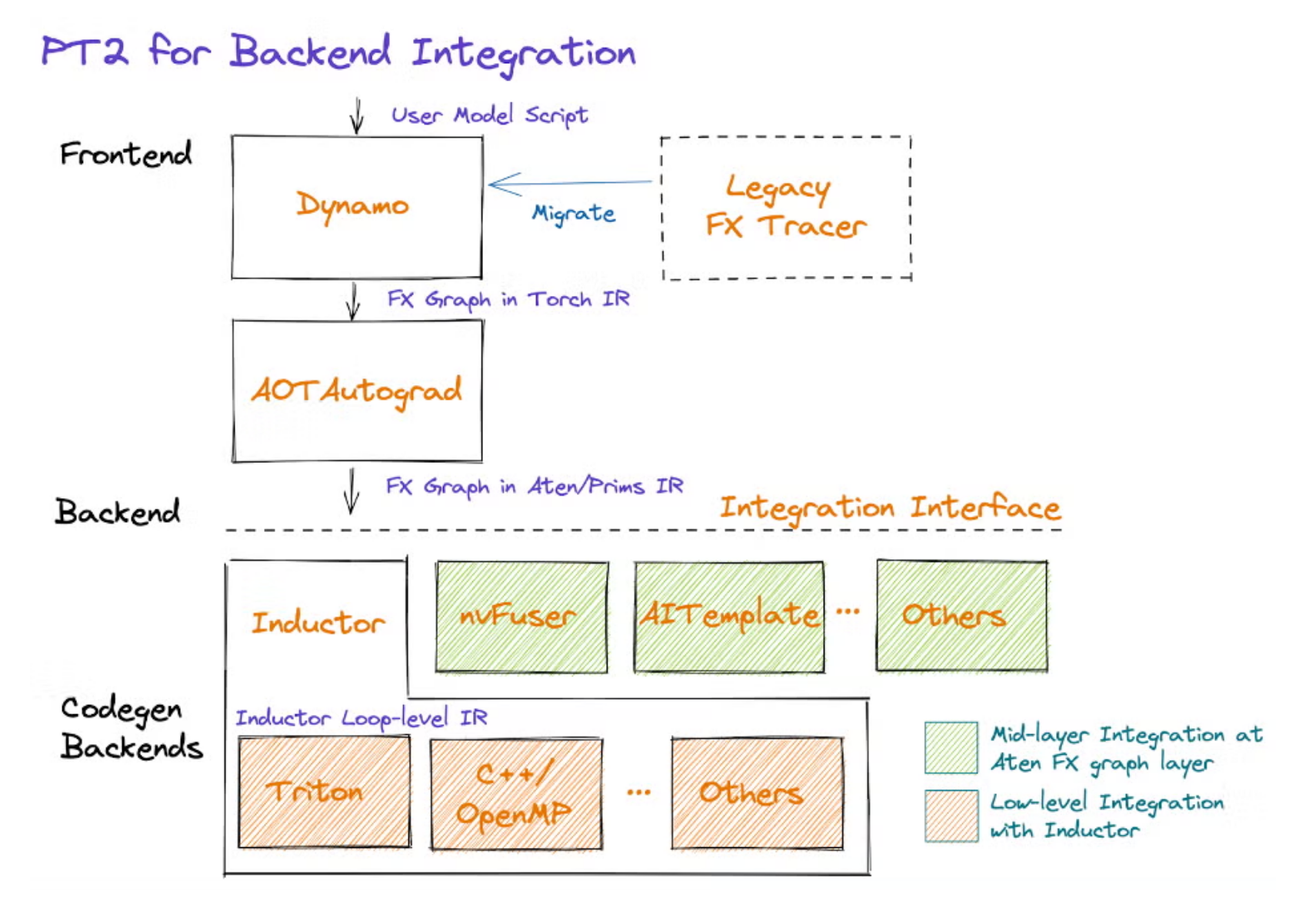
在图编译视角下,Pytorch的软件栈如下,Triton是Inductor的一个Codegen Backend:
Triton简介
Triton是一种为并行编程设计的语言和编译器,旨在提供一个Python-based编程环境,提升DNN compute kernels的开发效率的同时,也能最大化利用现代GPU硬件的计算吞吐能力。
Triton的编程模型抽象基于Block,和GPU传统的基于Thread的编程模型对比:

Triton Shared
原生的Triton编译器的编译管线与GPU深度绑定,微软在原生Triton的基础上,在社区贡献了triton-shared项目,对接到了MLIR的linalg Dialect,方便支持其他类型的AI加速器。
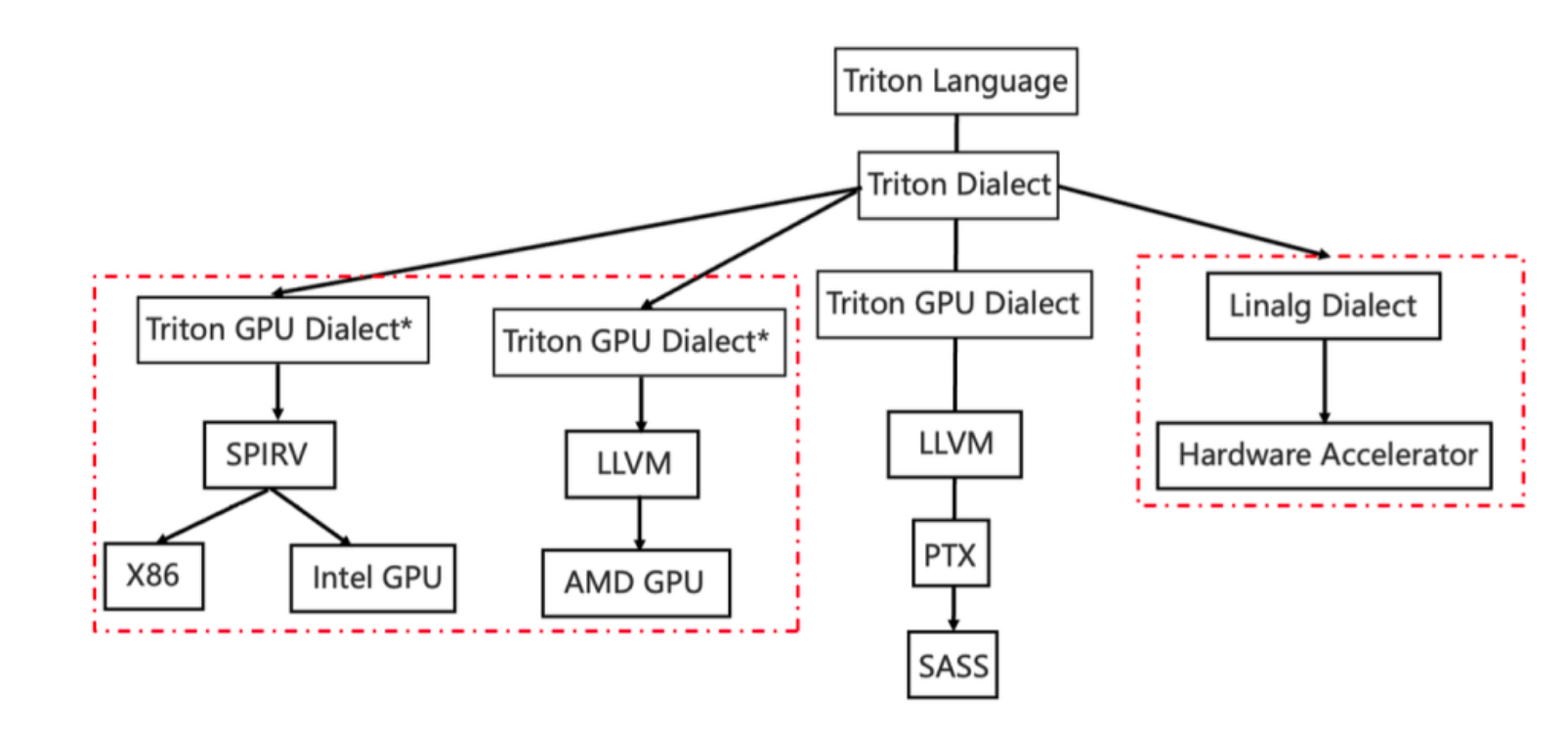
本系列文章先分析Triton-shared编译管线相关内容,后续视情况添加NVIDIA GPU编译管线相关内容,文章整理按照Dialect/Pass结构组织。
Triton Shared编译管线
待补充
Dialect目录
待补充
Pass目录
待补充
参考资料:
PyTorch 2.0: Our next generation release that is faster, more Pythonic and Dynamic as ever – PyTorch
TorchDynamo: An Experiment in Dynamic Python Bytecode Transformation - compiler - PyTorch Developer Mailing List
PyTorch 2.x
Welcome to Triton’s documentation! — Triton documentation
https://github.com/microsoft/triton-shared