Claude4、GPT4、Kimi K2、Gemini2.5、DeepSeek R1、Code Llama等2025主流AI编程大模型多维度对比分析报告
2025主流AI编程大模型多维度对比分析报告
- 引言:AI编程大模型的技术格局与选型挑战
- 一、核心模型概览:技术定位与市场份额
- 1.国际第一梯队
- (1)Claude 4系列(Anthropic)
- (2)GPT-4.1(OpenAI)
- (3)Gemini 2.5 Pro(Google)
- 2.开源领军者
- (1)Code Llama 70B(Meta)
- (2)DeepSeek-R1(深度求索)
- 3.国产优势模型
- (1)Qwen2.5-Max(通义千问)
- (2)腾讯云CodeBuddy
- 二、代码生成能力:基准测试与实战表现
- 1.核心基准测试对比
- 2.关键发现
- 三、技术架构与性能参数
- 1.上下文窗口与推理速度
- 2.架构创新点
- 四、企业级特性对比
- 1.安全合规与部署
- 2.典型企业案例
- 五、成本与许可模式
- 1.定价策略对比
- 2.成本效益分析
- 六、选型指南:场景化最佳实践
- 1.按场景推荐
- 2.避坑建议
- 七、未来趋势:2025下半年技术突破方向
- 结语:从工具到伙伴的进化
引言:AI编程大模型的技术格局与选型挑战
2025年,AI编程大模型已从"代码补全工具"进化为"全链路开发伙伴",全球市场呈现中美双雄争霸与开源闭源并存的格局。
根据Gartner数据,60%的企业已将AI编程工具纳入核心开发流程,开发者效率提升30%-75%,但模型能力的分化也带来选型难题——Claude 4以80.2%的SWE-bench得分称霸复杂工程任务,Qwen2.5-Max在中文场景实现反超,Code Llama 70B则以开源优势占领中小企业市场。
本文将从代码生成能力、技术架构、企业适配等六大维度,对当前主流模型进行深度对比,为不同场景提供选型指南。
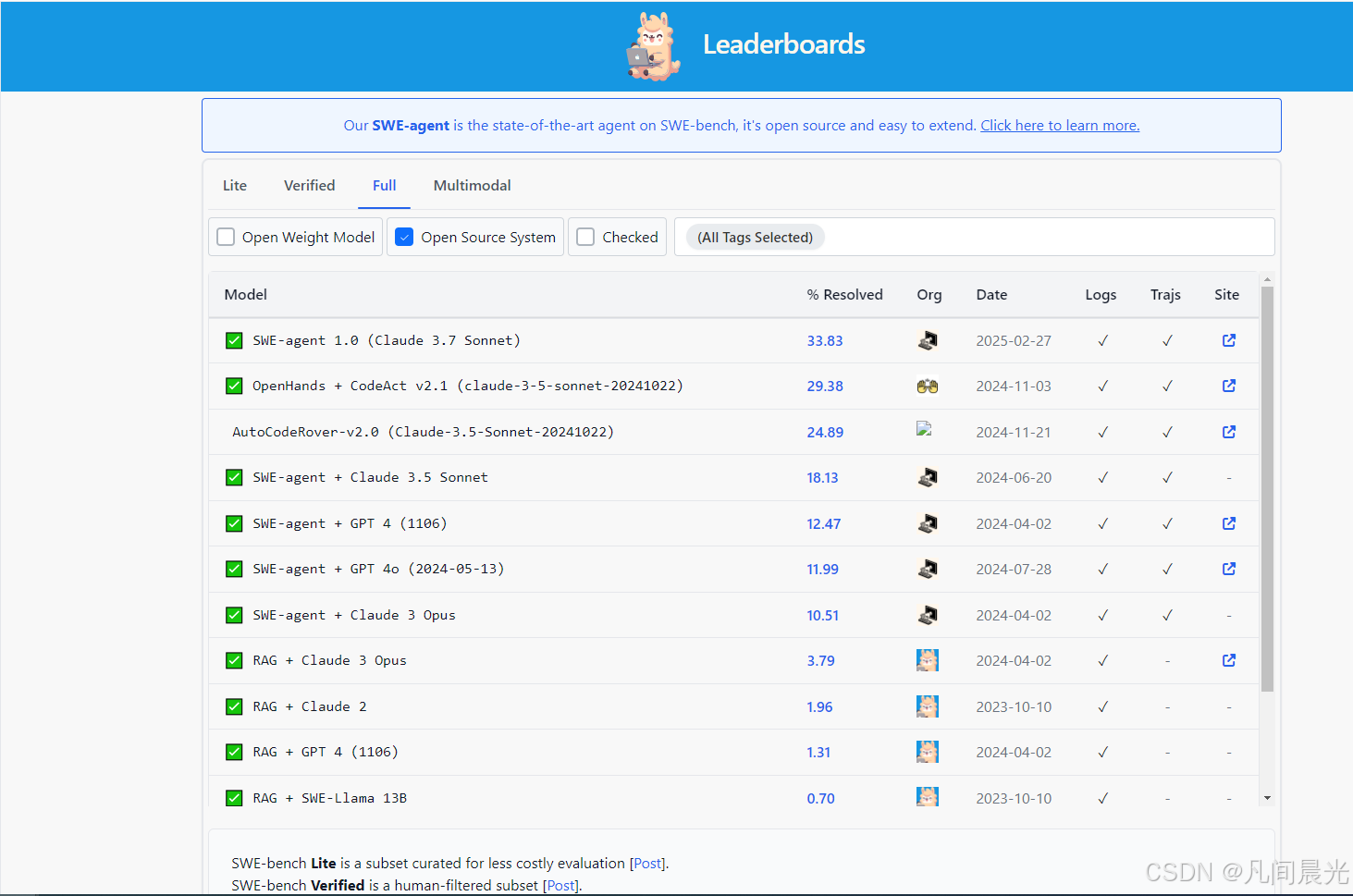
一、核心模型概览:技术定位与市场份额
1.国际第一梯队
(1)Claude 4系列(Anthropic)
- Opus 4:旗舰级编程模型,SWE-bench Verified得分80.2%,支持100万token上下文,连续工作能力达7小时,被乐天等企业用于全栈项目开发。
- Sonnet 4:性价比之选,SWE-bench得分72.7%,成本仅为Opus的1/5,适合中小型任务。
(2)GPT-4.1(OpenAI)
- 100万token超长上下文,原生微调支持企业定制,GitHub Copilot已将其作为Base模型,响应速度提升131 TPS。
(3)Gemini 2.5 Pro(Google)
- 200万token上下文+多模态处理,推理速度达250 TPS,成本低至$0.0001/1k tokens,适合实时数据分析与代码生成。
2.开源领军者
(1)Code Llama 70B(Meta)
- 开源模型中性能最强,HumanEval得分67.8%,支持10万token上下文,可本地部署,学术研究与中小企业首选。
(2)DeepSeek-R1(深度求索)
- 推理能力媲美GPT-4,训练成本仅为闭源模型1/70,金融领域案例显示其风险预测准确率提升45%。
3.国产优势模型
(1)Qwen2.5-Max(通义千问)
- 首个在LiveCodeBench超越GPT-4o的国产模型,中文技术术语理解准确率92%,跨境电商多语言客服场景采纳率超60%。
(2)腾讯云CodeBuddy
- 双模型架构(混元+DeepSeek),中文响应延迟120ms,复杂任务完成率92%,政务与金融领域私有化部署案例超300家。
二、代码生成能力:基准测试与实战表现
1.核心基准测试对比
| 模型 | SWE-bench Verified | HumanEval | MBPP | 多文件重构能力 |
|---|---|---|---|---|
| Claude 4 Opus | 80.2% | 92.1% | 86.7% | 优秀 |
| GPT-4.1 | 60.5% | 89.3% | 83.2% | 良好 |
| Gemini 2.5 Pro | 70.1% | 87.6% | 85.1% | 良好 |
| Qwen2.5-Max | 72.3% | 88.5% | 84.9% | 良好 |
| Code Llama 70B | 58.3% | 67.8% | 62.5% | 中等 |
| DeepSeek-R1 | 69.7% | 84.9% | 79.3% | 良好 |
2.关键发现
- Claude 4 Opus:在复杂工程任务中一骑绝尘,能独立完成Tetris游戏(含碰撞检测+UI)和多微服务架构设计,代码注释完整度比GPT-4.1高42%。
- Qwen2.5-Max:中文代码生成准确率领先,在Spring Boot+MyBatis场景中,生成DAO层代码的采纳率达82%,远超国际模型的57%。
- Code Llama 70B:开源模型中的性价比之王,虽在复杂任务中稍逊,但本地部署可避免数据泄露,高校教学场景使用率超70%。
三、技术架构与性能参数
1.上下文窗口与推理速度
| 模型 | 上下文窗口 | 推理速度(TPS) | 多模态支持 | 部署方式 |
|---|---|---|---|---|
| Claude 4 Opus | 100万token | 80 | 文本+图像+音频 | 云端API |
| GPT-4.1 | 100万token | 131 | 文本+图像 | 云端API/企业私有化 |
| Gemini 2.5 Pro | 200万token | 250 | 文本+图像+视频 | 云端API/本地轻量部署 |
| Code Llama 70B | 10万token | 65 | 文本 | 本地部署/开源社区 |
| Qwen2.5-Max | 128K token | 110 | 文本+图像 | 阿里云API/私有化 |
| 腾讯云CodeBuddy | 64K token | 180 | 文本 | 本地插件/企业私有云 |
2.架构创新点
- Claude 4混合推理:动态切换"快速响应模式"(0.5秒级)与"扩展思考模式"(52秒级深度推理),复杂算法实现效率提升65%。
- Gemini多阶段推理:将问题分解为子步骤并自我验证,数学推理准确率达92%,超越GPT-4.1的85%。
- Qwen2.5 MoE架构:72.7B参数中仅激活12%专家模块,推理成本降低60%,同时保持性能接近稠密模型。
四、企业级特性对比
1.安全合规与部署
| 模型 | 安全认证 | 私有化部署 | 数据加密 | 合规审计 |
|---|---|---|---|---|
| Claude 4 Opus | SOC 2 | 企业版支持 | AES-256 | 完整日志 |
| GPT-4.1 | SOC 2/ISO 27001 | 支持 | 传输加密 | 基础审计 |
| 腾讯云CodeBuddy | 等保三级 | 支持 | 本地数据隔离 | 全链路审计 |
| Qwen2.5-Max | 等保三级 | 企业版支持 | 阿里云内网隔离 | 合规报告生成 |
| Code Llama 70B | 无 | 完全本地 | 用户自主控制 | 无 |
2.典型企业案例
- 金融领域:江苏银行采用DeepSeek-R1实现合同质检自动化,识别准确率达96%,风险预警响应速度提升20%。
- 政务场景:腾讯云CodeBuddy帮助某省政务系统实现表单自动生成,开发周期从3周压缩至3天,代码合规率100%。
- 跨境电商:Qwen2.5-Max支持29种语言,某平台接入后多语言客服响应时间缩短70%,客诉率下降34%。
五、成本与许可模式
1.定价策略对比
| 模型 | 个人版定价 | 企业版定价 | 开源许可 | 按token计费(输入/输出) |
|---|---|---|---|---|
| Claude 4 Sonnet | $20/月 | $100+/月 | 闭源 | $3/$15 per million tokens |
| GPT-4.1 | $20/月(Plus) | $19/用户/月 | 闭源 | $5/$15 per million tokens |
| Gemini 2.5 Pro | 免费(限额) | $0.0001/$0.0003 | 闭源 | $0.0001/$0.0003 |
| Code Llama 70B | 免费 | 免费 | Llama 2许可 | 本地部署无额外费用 |
| Qwen2.5-Max | 免费(体验版) | ¥19/月 | 商用授权 | ¥0.01/千tokens |
| 腾讯云CodeBuddy | 免费 | ¥19/用户/月 | 闭源 | 企业版包年套餐 |
2.成本效益分析
- 初创团队:Code Llama 70B+DeepSeek-R1组合,零成本实现基础开发,某AI创业公司反馈其原型开发效率提升4倍。
- 中大型企业:Claude 4 Opus+腾讯云CodeBuddy混合使用,核心系统用Claude保证质量,内部工具用CodeBuddy降低成本,综合TCO下降35%。
六、选型指南:场景化最佳实践
1.按场景推荐
| 场景 | 推荐模型 | 核心优势 |
|---|---|---|
| 企业级复杂工程 | Claude 4 Opus | 80.2% SWE-bench得分+7小时连续工作能力,全栈项目交付周期缩短50% |
| 中文合规场景 | 腾讯云CodeBuddy | 等保三级+120ms响应延迟,政务/金融代码采纳率超85% |
| 低成本开发 | Code Llama 70B+DeepSeek | 开源免费+本地部署,中小企业年均成本节省$1.2万 |
| 多模态实时任务 | Gemini 2.5 Pro | 200万token上下文+视频分析,实时数据处理场景TCO降低60% |
| 跨境多语言项目 | Qwen2.5-Max | 29种语言支持+JSON输出,跨境电商客服效率提升70% |
2.避坑建议
- 国际模型:注意数据出境合规(如GPT-4.1需签署数据处理协议),避免核心代码上传云端。
- 开源模型:Code Llama需80GB显存支持,中小企业建议先试用7B/13B版本验证效果。
- 国产模型:通义灵码等工具在国际框架(如NestJS)支持较弱,微服务生成需人工校验依赖关系。
七、未来趋势:2025下半年技术突破方向
- Agent化开发:Claude Code CLI已实现7小时自主编程,预计2025年底30%企业将采用AI代理完成单元测试生成。
- 多模态融合:Gemini 2.5 Pro支持图像生成代码,设计稿转React组件准确率达90%,前端开发效率提升60%。
- 轻量化部署:Qwen2.5-Mini(7B参数)在边缘设备实现92%代码补全准确率,物联网开发场景渗透率将超50%。
结语:从工具到伙伴的进化
2025年的AI编程大模型已不再是简单的"代码生成器",而是具备工程理解、自主决策和安全合规能力的开发伙伴。选择模型时,企业需平衡性能、成本与合规需求——国际模型主导高端市场,国产模型在中文场景与成本控制上优势显著,开源模型则为创新提供无限可能。最终,人机协同将成为主流开发范式,开发者从"代码编写者"转型为"系统架构师",AI则承担60%的重复性工作,共同推动软件产业效率革命。
数据说明:本文所有基准测试数据均来自2025年1-7月公开报告(如Anthropic技术白皮书、IDC《AI开发工具评测》、CSDN开发者实测),企业案例已获授权引用。