【数据结构】二叉树进阶算法题
目录
1. 606. 根据二叉树创建字符串 - 力扣(LeetCode)
思想:
2. 102. 二叉树的层序遍历 - 力扣(LeetCode)107. 二叉树的层序遍历 II - 力扣(LeetCode)
分析:
思想:
思路一:
思路二:
3. 236. 二叉树的最近公共祖先 - 力扣(LeetCode)
思想:
编辑思路1:
思路2:
4. LCR 155. 将二叉搜索树转化为排序的双向链表 - 力扣(LeetCode)
思想:
思路1:
思路2:
5. 105. 从前序与中序遍历序列构造二叉树 - 力扣(LeetCode)106. 从中序与后序遍历序列构造二叉树 - 力扣(LeetCode)编辑106. 从中序与后序遍历序列构造二叉树 - 力扣(LeetCode)
思想:
6. 144. 二叉树的前序遍历 - 力扣(LeetCode)94. 二叉树的中序遍历 - 力扣(LeetCode)145. 二叉树的后序遍历 - 力扣(LeetCode)
非递归迭代实现思想:
前序遍历非递归思想
中序遍历非递归思想
后续遍历非递归思想
在数据结构初阶部分已经讲了常见的一些经典二叉树相关的算法题题目,二叉树部分难度还是有的,所以一些不适合用C语言实现和一些难度越大一些的算法题(二叉树非递归等)我们就放到这里用C++进行讲解。
1. 606. 根据二叉树创建字符串 - 力扣(LeetCode)
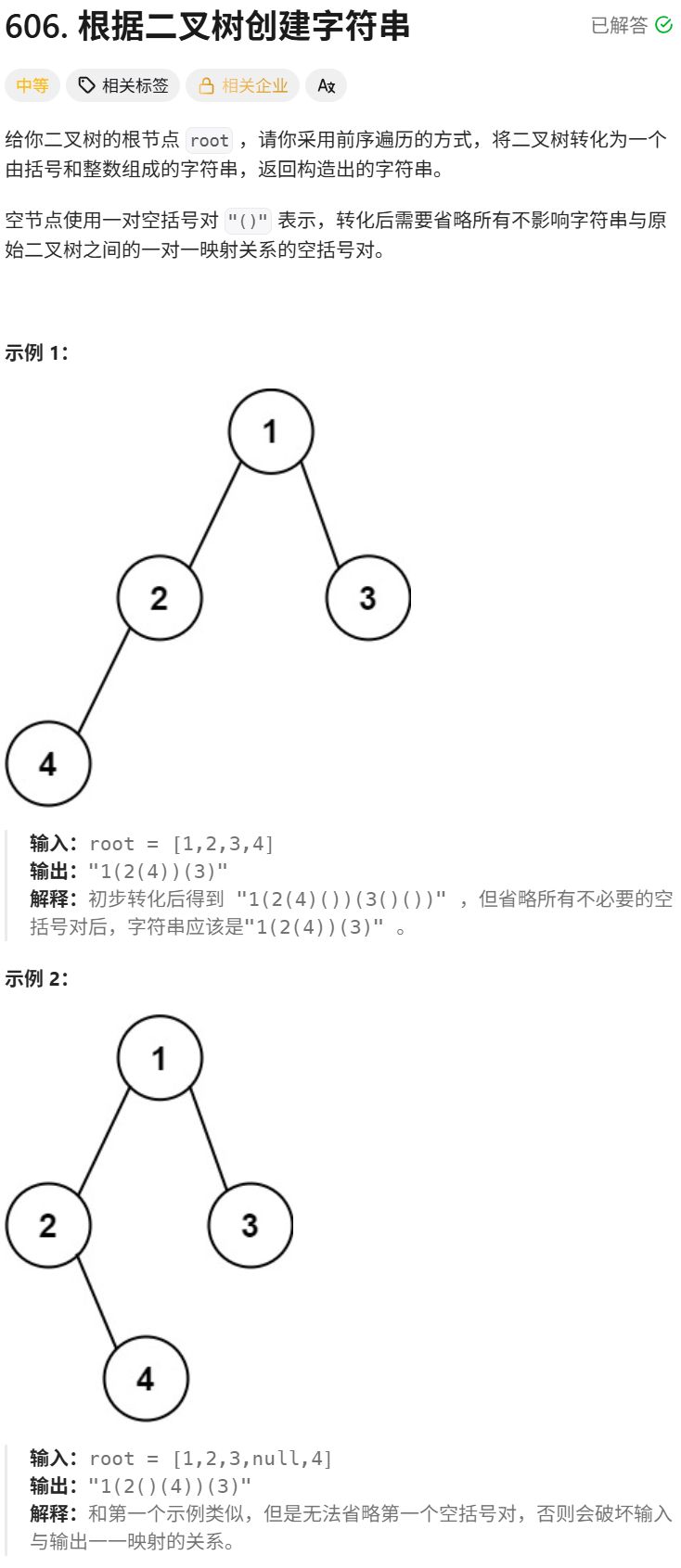
思想:
这个题本身难度不大,就是一个前序遍历转成字符串,把子树用括号包起来,空树的情况特殊处理一下(根据给出的样例要注意1、左右都为空,要省略括号,2、右为空,要省略括号,3、左为空,右不为空,不能省略括号,左边和右边有一个为空,左边必须有括号)。
这个题目就不适合用c语言去实现,c实现符数组开多大就是麻烦事,用C++string的+=就方便了很多。
代码:
class Solution {
public:// 走前序遍历二叉树转换string tree2str(TreeNode* root) {string ret;if (root == nullptr)return ret;ret += to_string(root->val);//左不为空,需要递归获取子树括号括起来//左为空,右不为空,左边的空括号需要保留if (root->left || root->right){ret += '(';ret += tree2str(root->left);ret += ')';}//右不为空,需要递归获取子树括号括起来//右边只要是空的,空括号不需要了if (root->right){ret += '(';ret += tree2str(root->right);ret += ')';}return ret;}
};2. 102. 二叉树的层序遍历 - 力扣(LeetCode)
107. 二叉树的层序遍历 II - 力扣(LeetCode)
分析:
层序遍历本身难度不大,用队列先进先出的性质,上一层每个结点出的时候,带入下一层的子结点,下一次循环重复上一次操作,层序遍历就实现了,这个我们数据结构二叉树阶段已经讲过了。这里题目的问题是,需要把每层的结点单独拿出来,放到二维数组的一行中,这个就相对麻烦一些。
思想:
思路一:

针对每层节点单独放一组数组,思路一我们可以多开一个队列来记录每个节点对应的层号,最后处理的时候,我们按层号把对应节点放到同一数组中。
相对来说思路一操作并不简便,而且多了O(n)的空间消耗。不推荐。
思路二:
我们在层序遍历过程中,增加一个levelSize,记录每层的数据个数,树不为空的情况下,第1层levelSize=1,循环控制,第1层出完了),第2层就都进队列了(这时候队列中都是第二层的节点,队列的size就是第2层的数据个数。以此类推,假设levelSize为第n层的数据个数,因为层序遍历思想为当前层结点出队列,带入下一层结点(也就是子结点),循环控制第n层数据出完了,那么第n+1结点都进队列了,队列size,就是下一层的levelSize,这样我们就能控制一个levelsize对应一层,进而将一层节点放到同一个数组中了。
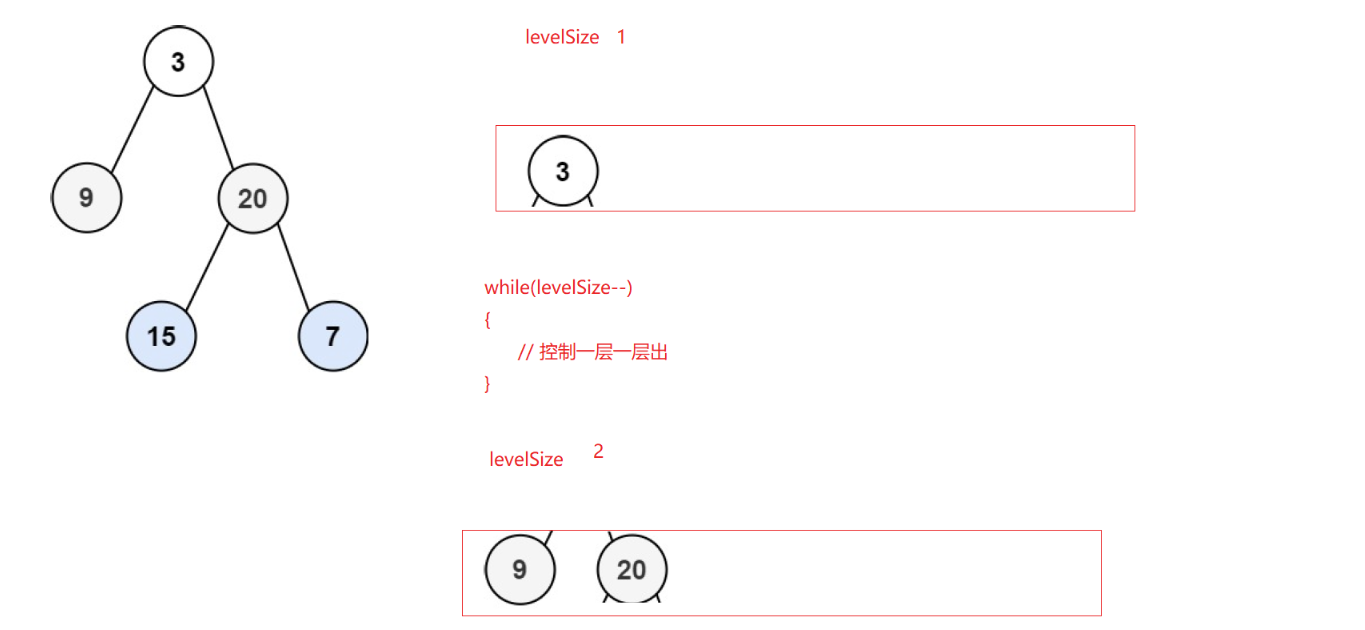
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> vv;queue<TreeNode*> q;int levelSize = 0;if (root){q.push(root);levelSize = 1;}while (!q.empty()){vector<int> v;// 控制一层出完,一层一层出while (levelSize--){TreeNode* front = q.front();q.pop();v.push_back(front->val);//下一层孩子入队列if (front->left)q.push(front->left);if (front->right)q.push(front->right);}// 当前层出完了,下一层都进队列了,队列size就是下一层数据个数levelSize = q.size();// 获取到每一层数据放到二维数组中vv.push_back(v);}return vv;}
};
107的第二个题目,观察结果与102题正好相反,是从下往上地一层一层,因此这题我们逆向思考,先仿照102题遍历得出结果,再将102题的结果二维数组逆置一下就可以得到结果。
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> vv;queue<TreeNode*> q;int levelSize = 0;if (root){q.push(root);levelSize = 1;}while (!q.empty()){vector<int> v;// 控制一层出完,一层一层出while (levelSize--){TreeNode* front = q.front();q.pop();v.push_back(front->val);//下一层孩子入队列if (front->left)q.push(front->left);if (front->right)q.push(front->right);}// 当前层出完了,下一层都进队列了,队列size就是下一层数据个数levelSize = q.size();// 获取到每一层数据放到二维数组中vv.push_back(v);}reverse(vv.begin(),vv.end());return vv;}
};3. 236. 二叉树的最近公共祖先 - 力扣(LeetCode)

思想:
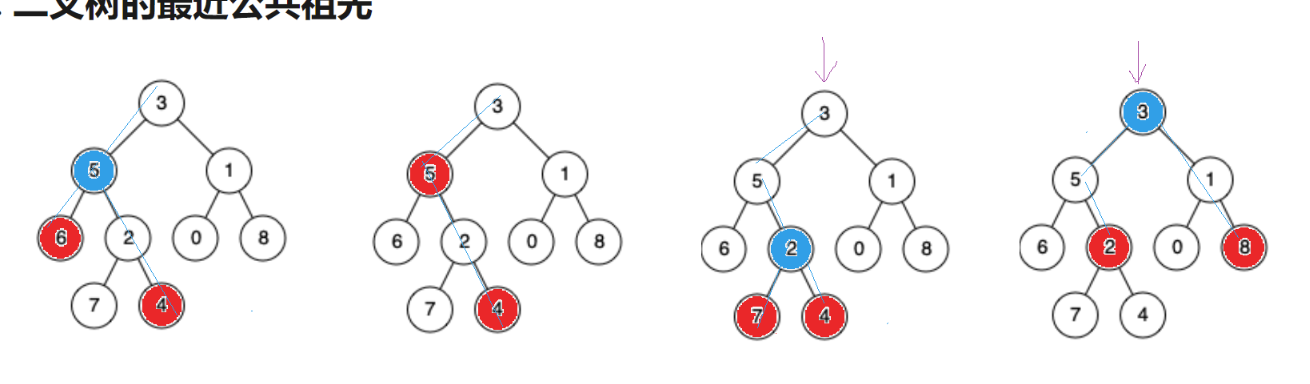
思路1:
仔细观察一下,我们发现两个结点,最近公共祖先的特征就是一个结点在最近公共祖先的左边,一个结点在最近公共祖先的右边。比如6和4的公共祖先有5和3,但是只有最近公共祖先5满足6在左边,4在右边。如果不是最近公共祖先,那么两个节点只能在该公共祖先节点的同一边。
基于这个特点,我们只需要判断两个目标节点在节点的哪一侧,如果两个节点在同一侧,那么我们就将所在同一侧子树的的根作为新节点递归处理,重复上述操作,判断两个目标节点在新节点的哪侧(这里我们就进行查找操作,因为题目规定节点必然存在,那么目标节点要么在当前节点的左侧要么在右侧);如果两个目标节点在新节点的两侧,那么这时新节点就是最近公共祖先节点。
class Solution {
public:// 查找x是否在树中bool IsInTree(TreeNode* root, TreeNode* x){if (root == nullptr)return false;return root == x|| IsInTree(root->left, x)|| IsInTree(root->right, x);}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {if (root == NULL)return NULL;if (root == p || root == q){return root;}// 这里要注意,这里的命名非常关键,命名好了,代码可读性大大增强bool pInLeft, pInRight, qInLeft, qInRight;// 题目中有说明p和q一定是树中的结点// p不在左树就在右树pInLeft = IsInTree(root->left, p);pInRight = !pInLeft;// q不在左树就在右树qInLeft = IsInTree(root->left, q);qInRight = !qInLeft;// 一个在左,一个在右,那么root就是最近公共祖先// 都在左,递归去左树查找// 都在右,递归去右树查找if ((pInLeft && qInRight) || (qInLeft && pInRight)){return root;}else if (pInLeft && qInLeft){return lowestCommonAncestor(root->left, p, q);}else if (pInRight && qInRight){return lowestCommonAncestor(root->right, p, q);}// 虽然执行逻辑不会走到这里,但是如果不写这个代码,语法逻辑过不去(相当于语法上走//到这没返回值)// 编译器会报语法错误。assert(false);return NULL;}
};
但是需要注意的是,我们判断目标节点在哪侧是递归的,判断最近公共祖先也是递归的,如果遇到上面这种情况,判断目标节点在哪侧需要遍历树,当前节点不是最近公共祖先,还需要再次递归遍历那么我们算法的时间复杂度就会退化到
。
思路2:
换个角度思考,目标节点各自到根是一条路径,这时我们求两个目标节点的最近公共祖先节点,不就是各自从目标节点出发到根,两条路径最早相交的节点处吗?所以如果我们能求出两个结点到根的路径,那么就可以转换为链表相交问题(两个链表相交,长链表先走差距步,然后两链表同时走,相遇处就是交点)。
如:6到根3的路径为6->5->3,4到根3的路径为4->2->5->3,那么看做两个链表找交点,交点5就是最近公共祖先。
因此这里为了转换成链表相交问题,我们需要记录路径,这里我们采用前序遍历方式查找节点,用栈来记录路径,遇到节点先入栈,如果当前子树查找不到目标节点,我们再将节点出栈,进行回退,去其他分支继续查找节点。
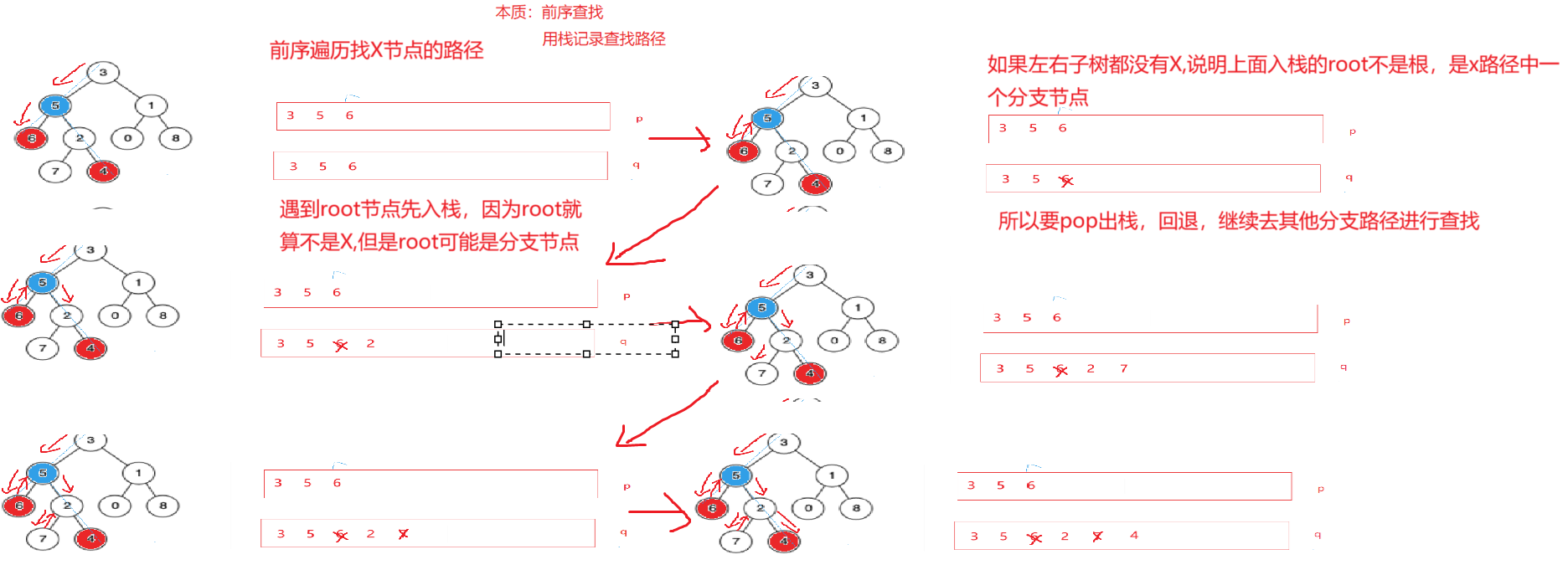
代码:
class Solution {
public:bool GetPath(TreeNode* root, TreeNode* x, stack<TreeNode*>& path){if (root == nullptr)return false;// 前序遍历的思路,找x结点的路径// 遇到root结点先push入栈,因为root就算不是x,但是root可能是根->x路径中一个分//支结点path.push(root);if (root == x)return true;if (GetPath(root->left, x, path))return true;if (GetPath(root->right, x, path))return true;// 如果左右子树都没有x,那么说明上面入栈的root不是根->x路径中一个分支结点// 所以要pop出栈,回退,继续去其他分支路径进行查找path.pop();return false;}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {stack<TreeNode*> pPath, qPath;GetPath(root, p, pPath);GetPath(root, q, qPath);// 模拟链表相交,两个路径找交点// 长的先走差距步,再一起走找交点while (pPath.size() != qPath.size()){if (pPath.size() > qPath.size())pPath.pop();elseqPath.pop();}while (pPath.top() != qPath.top()){pPath.pop();qPath.pop();}return pPath.top();}
};4. LCR 155. 将二叉搜索树转化为排序的双向链表 - 力扣(LeetCode)
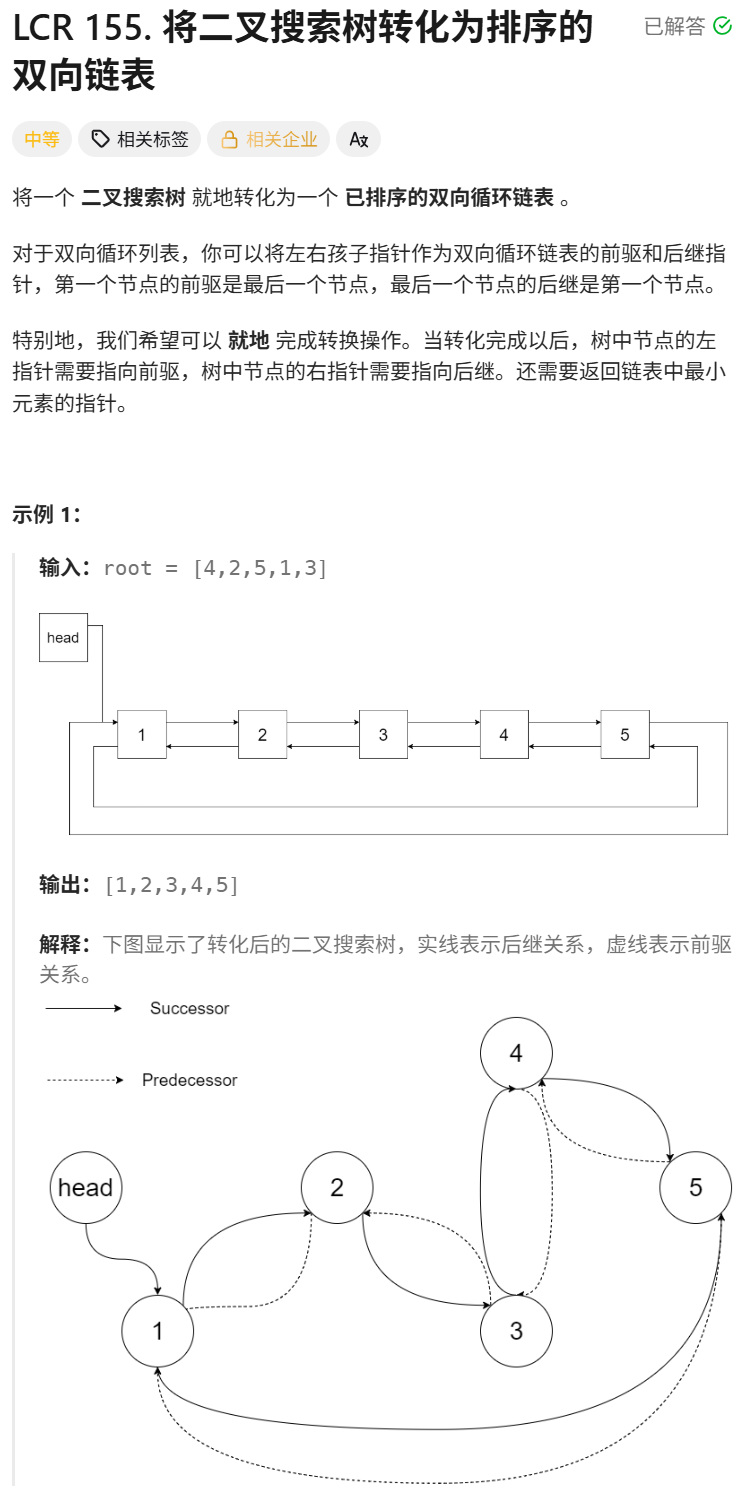
思想:
根据题意,我们最终排出来的双向循环链表要求是有序的,搜索二叉树走中序是有序的,因此本体要使用中序遍历,本题目要求原地修改,也就是不能创建新的结点。
思路1:
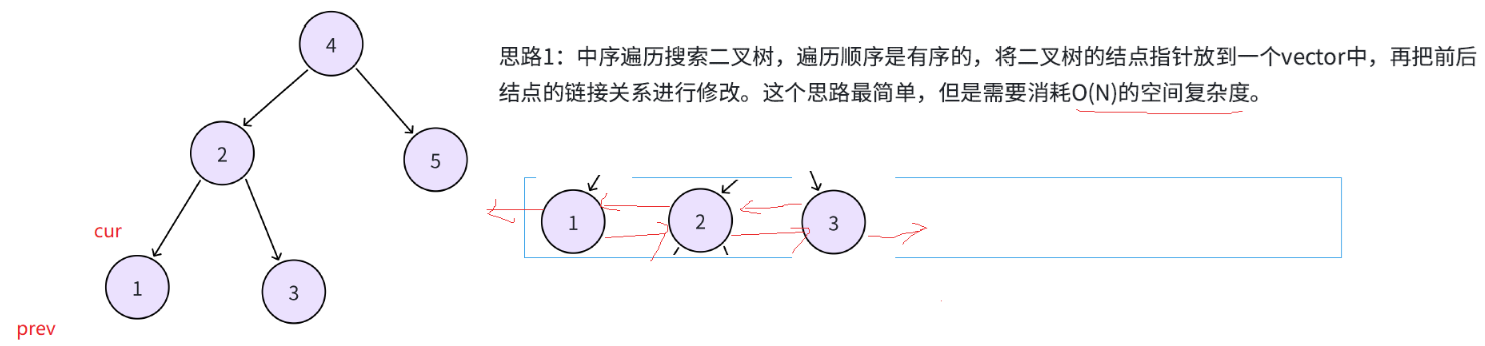
中序遍历搜索二叉树,遍历顺序是有序的,将二叉树的结点指针放到一个vector中,再把前后结点的链接关系进行修改。这个思路最简单,但是需要消耗O(N)的空间复杂度。
思路2:
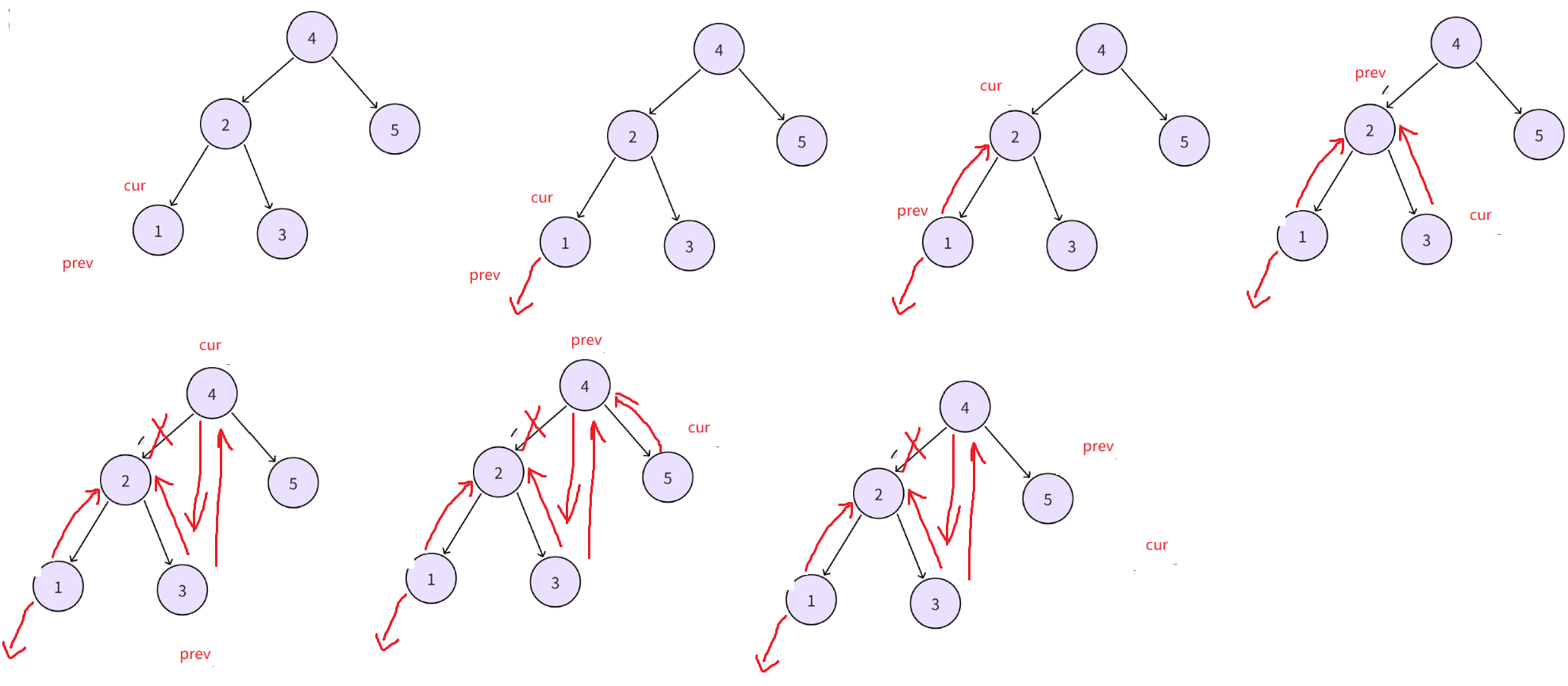
依旧中序遍历搜索二叉树,因为遍历顺序是有序的,所以遍历过程中修改左指针为前驱和右指针为后继指针。记录一个cur和prev,cur为当前中序遍历到的结点,prev为上一个中序遍历的结点,cur->left指向prev,cur->right无法指向中序下一个,因为不知道中序下一个是谁,但是这时候prev是cur的前一个节点这时确定的,因此修改prev->right指向cur;也就是说每个结点的左是在中遍历到当前结点时修改指向前驱的,但是当前结点的右,是在遍历到下一个结点时,修改指向后继的。当cur为树最左节点时,prev为空,cur指向前驱节点指向空,当cur遍历到空时循环结束,prev在最后节点,而最右节点后驱指针正好指向空,不用修改。
最后,为了让链表循环,我们需要找到链表第一个和最后一个节点,这时候prev是最后一个节点,我们只需要找到第一个节点,因为链表双向,我们根据prev节点一直向前遍历,直到前驱节点为0,此时节点为第一个节点,然后将该节点与prev相连。
代码:
class Solution {
public:void InOrderConvert(Node* cur, Node*& prev){if (cur == nullptr)return;// 中序遍历InOrderConvert(cur->left, prev);// 当前结点的左,指向前一个结点cur->left = prev;// 前一个结点的右,指向当前结点if (prev)//prev为空时不用处理prev->right = cur;prev = cur;InOrderConvert(cur->right, prev);}Node* treeToDoublyList(Node* root) {if (root == nullptr)return nullptr;Node* prev = nullptr;InOrderConvert(root, prev);// 从根开始往左走,找到第一个结点Node* head = root;while (head->left){head = head->left;}// head为第一个结点,prev是最后一个结点// 题目要求为循环链表,进行一些链接head->left = prev;prev->right = head;return head;}
};5. 105. 从前序与中序遍历序列构造二叉树 - 力扣(LeetCode)
106. 从中序与后序遍历序列构造二叉树 - 力扣(LeetCode)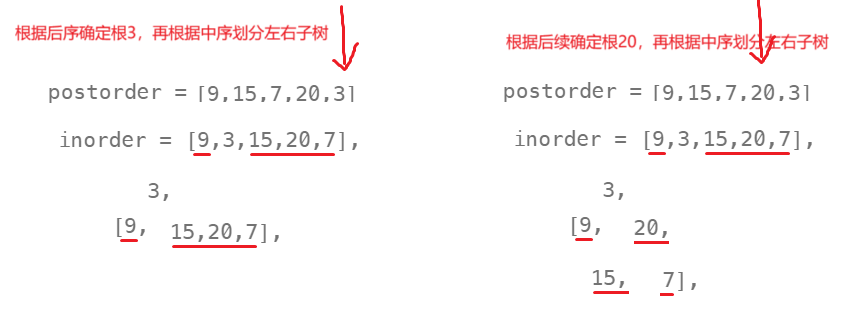 106. 从中序与后序遍历序列构造二叉树 - 力扣(LeetCode)
106. 从中序与后序遍历序列构造二叉树 - 力扣(LeetCode)
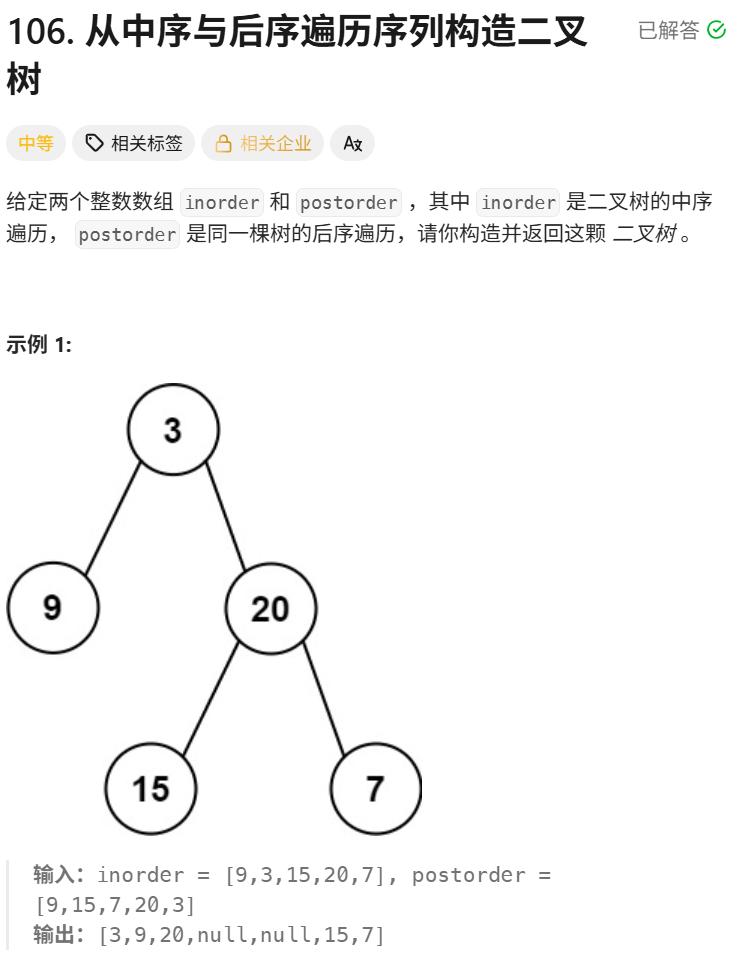
思想:
105题的问题,前序的方式构建树,根据前序,我们可以确定当前构建树的根,再根据根分割中序的左子树和右子树,再分别递归构建左子树和右子树,重复上述操作(根据前序确定根,根据中序确定左右子树)。
preorder = [3, 9, 20, 15, 7] 根 左子树 右子树
inorder = [9, 3, 15, 20, 7] 左子树 根 右子树
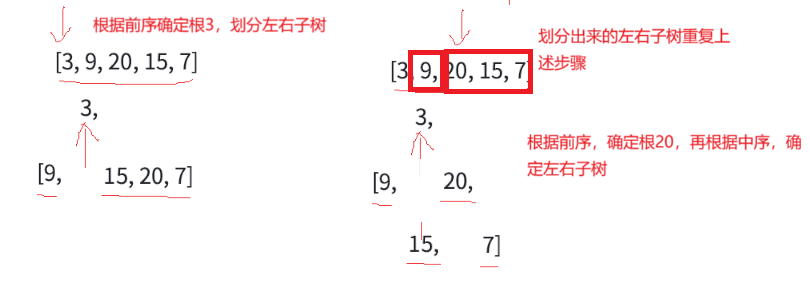
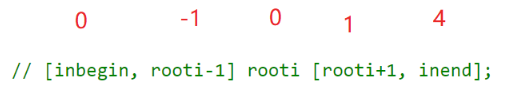
需要注意的是对于前序第一个数,划分左右子树会出现上述非法区间,因此需要处理非法区间的情况。
class Solution {
public:TreeNode* _buildTree(vector<int>& preorder, vector<int>& inorder, int&prei, int inbegin, int inend) {if (inbegin > inend)return nullptr;// 前序确定根TreeNode* root = new TreeNode(preorder[prei++]);// 根分割中序左右子区间int rooti = inbegin;while (rooti <= inend){if (inorder[rooti] == root->val)break;elserooti++;}// 递归左右子区间,递归构建左右子树// [inbegin, rooti-1] rooti [rooti+1, inend]root->left = _buildTree(preorder, inorder, prei, inbegin, rooti - 1);root->right = _buildTree(preorder, inorder, prei, rooti + 1, inend);return root;}TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {int i = 0;TreeNode* root = _buildTree(preorder, inorder, i, 0, inorder.size() - 1);return root;}
};106的题思想跟105题类似,不过是后序倒着确定根,再分别递归构造右子树和左子树。
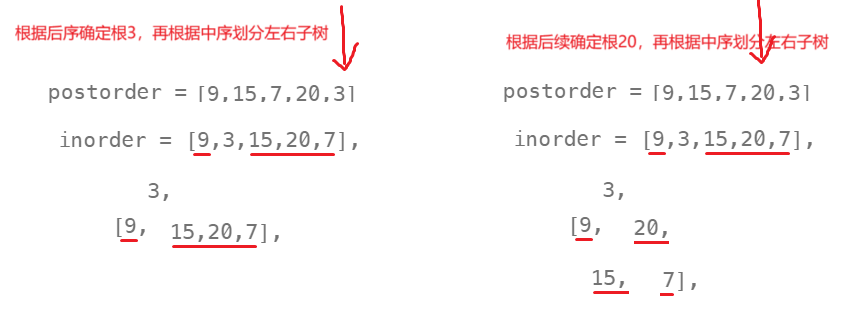
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:TreeNode* _buildTree(vector<int>& postorder, vector<int>& inorder, int& posti, int inbegin, int inend) {if (inbegin > inend)return nullptr;//后序确定根TreeNode* root = new TreeNode(postorder[posti]);int rooti = inbegin;while (inorder[rooti] != postorder[posti]) {rooti++;}posti--;// 递归左右子区间,递归构建左右子树// [inbegin, rooti-1] rooti [rooti+1, inend]root->right = _buildTree(postorder, inorder, posti, rooti + 1, inend);root->left = _buildTree(postorder, inorder, posti, inbegin, rooti - 1);return root;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {int i = postorder.size() - 1;return _buildTree(postorder, inorder, i, 0, inorder.size() - 1); }
};6. 144. 二叉树的前序遍历 - 力扣(LeetCode)
94. 二叉树的中序遍历 - 力扣(LeetCode)
145. 二叉树的后序遍历 - 力扣(LeetCode)
非递归迭代实现思想:
要迭代非递归实现二叉树前序遍历,首先还是要借助递归的类似的思想,我们需要先理解每次递归是在存储什么信息,再将对应信息通过栈保存起来,而这题中访问树,本质上是每次根据节点的左右指针访问对应的左右子树的根,再由左右子树的根重复上述操作。
因此每次遍历对应节点,我们需要把结点存在栈中,方便类似递归回退时取父路径结点。
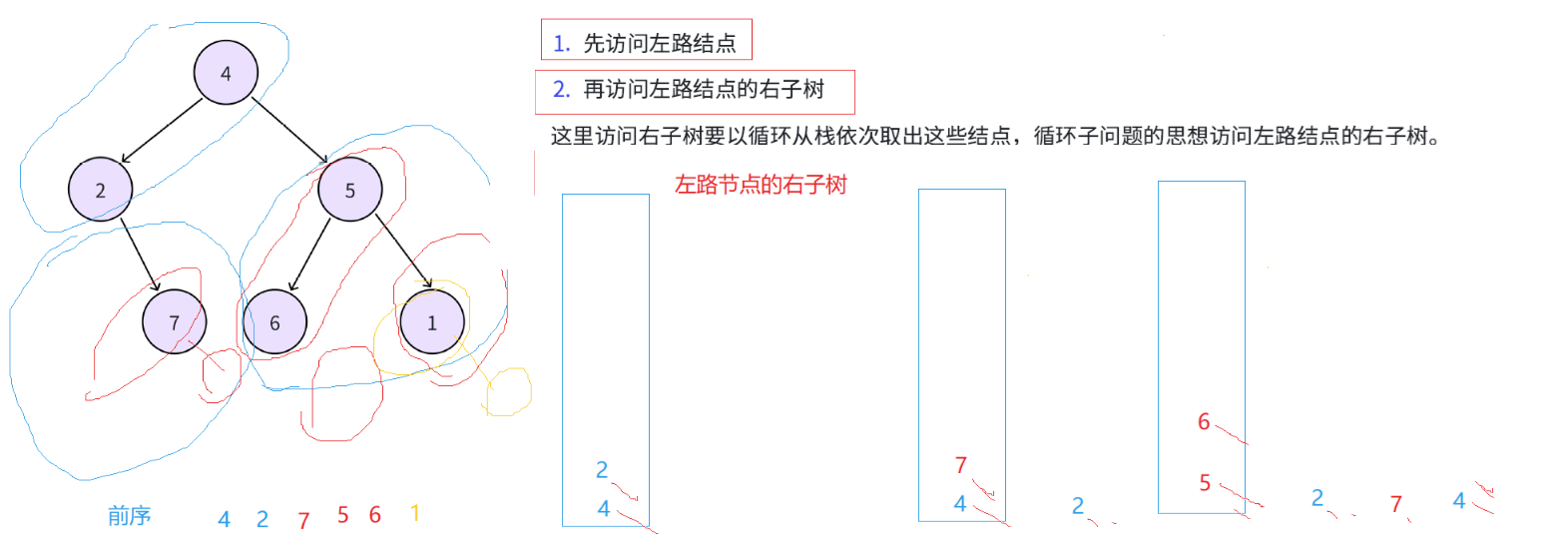
前序遍历非递归思想
复盘前序遍历的思路,我们每次是先访问根节点,再访问左子树,再访问右子树,也即是说要遍历右子树之前,会先遍历左子树,只有当左子树为空,才算遍历完,才会回退去访问右子树
因此这里把一棵二叉树分为两个部分:
1. 先访问左路结点,先访问根节点(按照题目要求打印或者存储到容器用于返回之类操作),遇到左路节点入栈,这样当左子树都遍历完成,按照后进先出的原则,得到最底层的左子树的根(左子树为空,访问完成,可以访问根节点)访问,
2. 再访问左路结点的右子树,将右子树的根作为新根入栈,重复左路节点-左路节点右子树顺序循环处理。
这里右子树访问完,再循环从栈依次取出所有结点重复上述操作处理,循环子问题的思想访问左路结点的右子树。
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {stack<TreeNode*> s;vector<int> v;TreeNode* cur = root;while (cur || !s.empty()){// 访问一颗树的开始// 1、访问左路结点,左路结点入栈while (cur){v.push_back(cur->val);s.push(cur);cur = cur->left;}// 2、从栈中取出一个左路结点的右子树出来访问TreeNode* top = s.top();s.pop();// 循环子问题方式访问左路结点的右子树cur = top->right;}return v;}
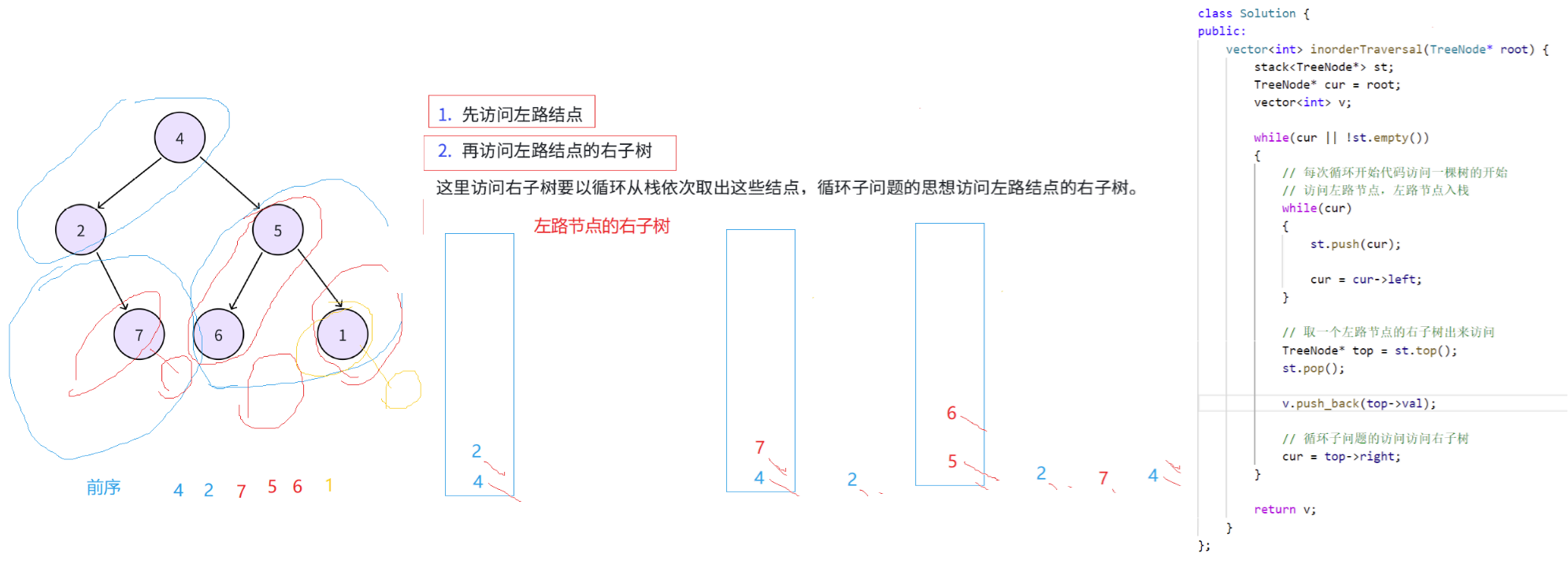
};中序遍历非递归思想
中序和后序跟前序的思路完全一致,只是先访问根还是后访问根的问题(这里访问即按照要求处理结果,是直接打印值还是放到结构中用于返回)。

class Solution {
public:vector<int> inorderTraversal(TreeNode* root) {stack<TreeNode*> st;TreeNode* cur = root;vector<int> v;while (cur || !st.empty()){// 访问一颗树的开始// 1、访问左路节点,左路结点入栈while (cur){st.push(cur);cur = cur->left;}// 访问问左路结点 和 左路结点的右子树TreeNode* top = st.top();st.pop();v.push_back(top->val);// 循环子问题方式访问右子树cur = top->right;}return v;}
};后续遍历非递归思想
后序稍微麻烦一些,因为后序遍历的顺序是左子树-右子树-根,那么当问题就是对于根来说,如何判断右子树是否访问完成,自己是否可以访问了。
因此当树取到左路结点的右子时,需要想办法标记判断右子树是否访问过了,如果访问过了,就直接访问根,如果访问过需要先访问右子树。
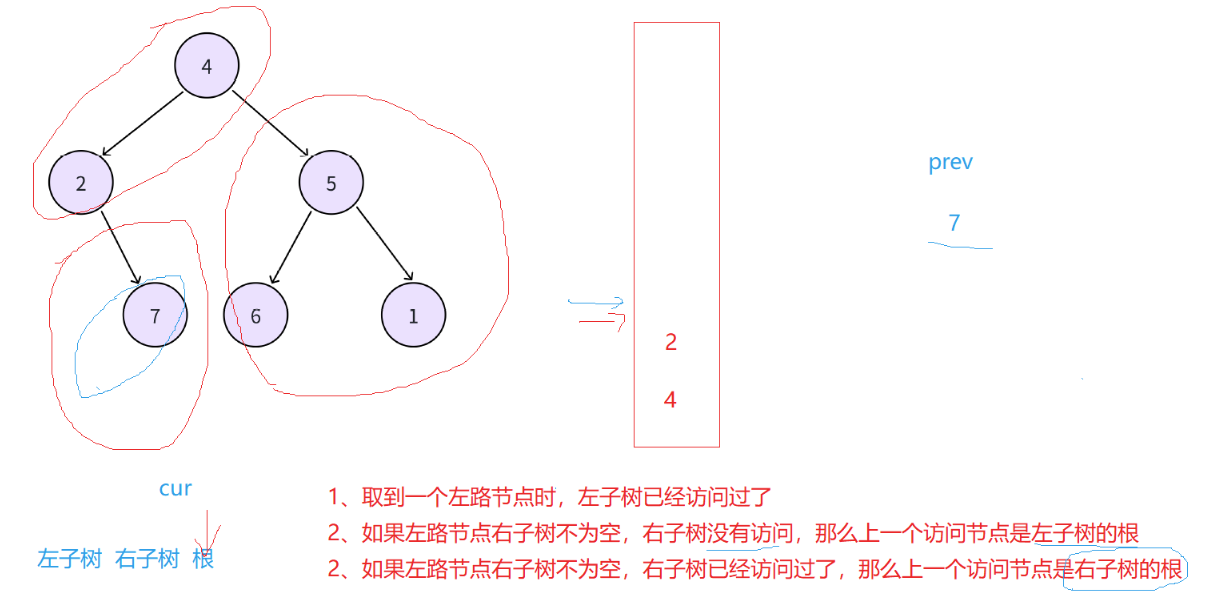
因此这里我们利用栈后进先出和后续遍历的特点,我们通过cur和prev来记录访问的节点,cur记录当前访问节点,prev记录上一个访问节点。我们发现如果左子树-右子树-根顺序访问,那么当prev记录的是左子树并且右子树不为空,那么就说明上一次访问是左子树,这时候右子树还没有访问,我们就不能访问根节点;如果右路节点不为空,且prev记录的是右子树,那么说明右子树我们已经访问完成,这时候从栈中取到根,我们就可以进行访问了。
class Solution {
public:vector<int> postorderTraversal(TreeNode* root) {TreeNode* cur = root;stack<TreeNode*> s;vector<int> v;TreeNode* prev = nullptr;while (cur || !s.empty()){// 1、访问一颗树的开始//访问左路节点,左路节点入栈while (cur){s.push(cur);cur = cur->left;}//取一个左路节点的右子树出来访问,这是代表左路节点的左子树已经访问过了TreeNode* top = s.top();//右子树为空或者上一个访问的节点是右子树的根,代表右子树也访问过了//可以访问当前根节点if (top->right == nullptr || top->right == prev){s.pop();v.push_back(top->val);prev = top;}else{//循环子问题的访问右子树cur = top->right;}}return v;}
};