结合实战项目分析locust
1 locust脚本
from locust import HttpUser, task, between, constant_throughput# 生产批次信息页面
class ProdbatchUser(HttpUser):wait_time = constant_throughput(1)@task(1)def find_batch_list(self):# 默认查询条件self.client.post(url="/xxx/f1/list",headers={"Authorization": "xxx","Content-Type": "application/json; charset=UTF-8"},json={"currentPage": 1,"pagesSize": 20,"keyword": "","conditions": [],"sorts": [],"onlyShowProduce": True,"groupId": [],"batchType": "NORMAL"})@taskdef find_by_keywords(self):# 关键字查询self.client.post(url="/xxx/f1/list",headers={"Authorization": "xxx","Content-Type": "application/json; charset=UTF-8"},json={"currentPage": 1,"pagesSize": 20,"keyword": "keyword","conditions": [],"sorts": [],"onlyShowProduce": True,"currentQueryParams": True,"groupId": [],"batchType": "NORMAL"})
1.1 @task
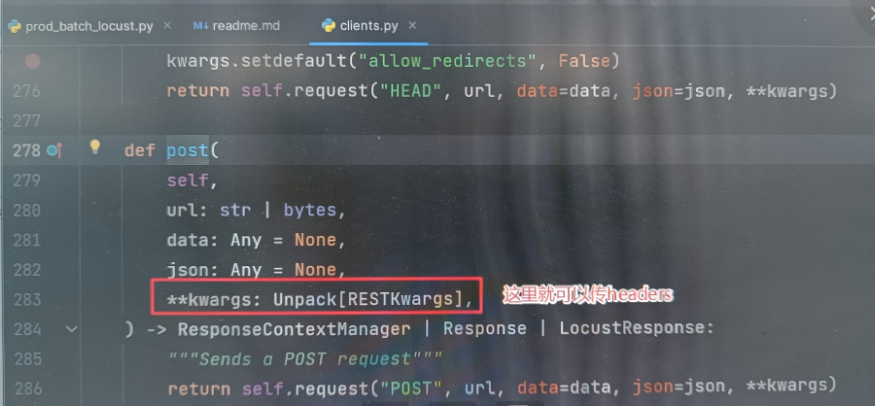
被它装饰的method代表一个任务,在任务里的请求将会按照顺序执行。self.client.post() 里的参数可以点进post去查看,注意url不需要跟域名,只跟路径即可
1.2 wait_time
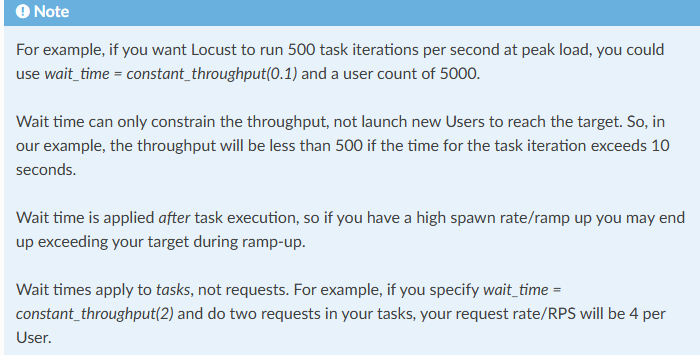
wait_time = between(1, 5):用户每完成一个请求后,会等待 1~5秒 再执行下一个请求
wait_time = constant_throughput(0.1):每个用户每秒最多执行 0.1 个请求(即每 10 秒 1 个请求)
注意,用户 ≠ 请求
- 你设置的 1个用户 并不代表只发 1个请求。Locust 中,每个用户会持续循环执行其 TaskSet 或 @task
定义的任务,直到测试停止。 - 如果用户的任务中没有延迟(或延迟很短),单个用户可以在短时间内发起大量请求。
constant_throughput关键特性:
1. 严格全局限速:所有用户的请求会协调分配,避免瞬时峰值。2. 无视任务耗时:即使任务执行时间很短,也会强制等待以满足吞吐量要求。3.适合场景:需要精确控制总 RPS 的压测(如 API 配额测试)。
官方文档说明
1.3 onstart
运行文件
如果文件名为locustfile.py,则直接在控制台输入
$ locust
但若自定义了名称,则需要使用 -f 指定
$ locust -f test_performance.py
web端分析
2.1 locust文件启动成功后,控制台会输出网站Url,点击进入:
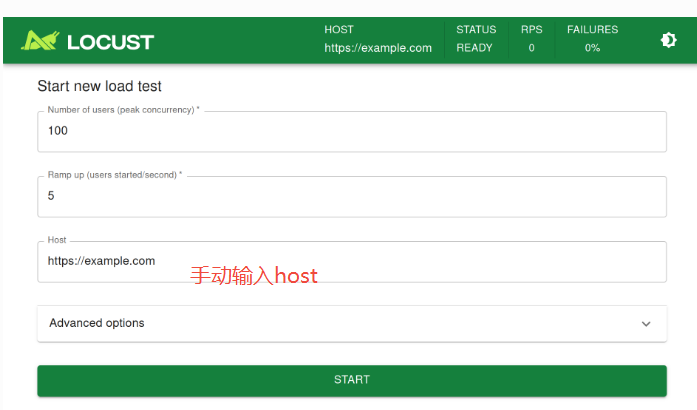
- Number of users(peak concurrency) : 达到峰值时,需要模拟的用户数。
- Ramp up(users started/second): 每秒启动的用户数
注意和Jmeter的 Ramp-Up Period 区分
Jmeter 中的 Ramp-Up Period :所有线程的启动时间。
因此这个数据在Jmeter设置越小,线程数达到峰值的时间越短;但在locust中,则需要Ramp up设置得越大,线程数达到峰值的时间就越短。
2.2 STAT测试后进入网页,程序开始产生请求
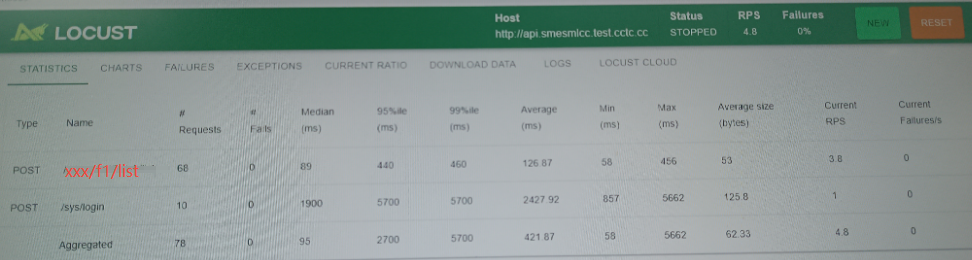
注意程序会一直发送请求,直到我们点击了STOP