DeepSpeed-FastGen:通过 MII 和 DeepSpeed-Inference 实现大语言模型的高吞吐文本生成
温馨提示:
本篇文章已同步至"AI专题精讲" DeepSpeed-FastGen:通过 MII 和 DeepSpeed-Inference 实现大语言模型的高吞吐文本生成
摘要
随着大语言模型(LLM)被广泛应用,其部署与扩展变得至关重要,用户对高吞吐量与低延迟的推理服务系统提出了更高的要求。现有的推理框架在应对长提示词任务时难以兼顾这两方面的需求。本文提出 DeepSpeed-FastGen,一个使用全新提示与生成阶段融合策略 —— Dynamic SplitFuse 的系统,相较于最先进的系统(如 vLLM),其实现了最多 2.3 倍的有效吞吐量提升、平均 2 倍的延迟降低,以及最多 3.7 倍的 token 级尾部延迟降低。该系统结合了 DeepSpeed-MII与 DeepSpeed-Inference 的优势,为 LLM 提供了高效且易于使用的推理服务平台。
DeepSpeed-FastGen 拥有先进的实现机制,支持多种模型,提供持久化与非持久化两种部署方式,适用于从交互式会话到长时间运行的各种场景。我们提出了详细的基准评估方法,通过 延迟-吞吐曲线 进行性能分析,并从 负载均衡 的角度探讨了系统的可扩展性。实验表明,在不同模型与硬件配置下,DeepSpeed-FastGen 在吞吐量与延迟方面均有显著改进。我们还讨论了未来的发展计划,包括支持更多模型与新型硬件后端。DeepSpeed-FastGen 的代码已开放,鼓励社区使用与贡献。
1 引言
大型语言模型(LLM)如 GPT-4 [1] 和 LLaMA [2] 已成为广泛应用中的主要算力负载。在从通用聊天模型、文档摘要,到自动驾驶及软件栈各层的 AI 助手等场景中,这类模型的部署与服务需求呈爆发式增长。虽然 DeepSpeed、PyTorch [3] 等框架在 LLM 训练期间通常能够实现较高的硬件利用率,但在推理阶段,尤其是涉及开放式文本生成任务时,由于计算强度较低,交互式应用的本质反而成为吞吐性能的瓶颈。
为此,诸如基于 PagedAttention 的 vLLM [4] 和研究系统 Orca [5] 等框架已经大幅提升了 LLM 推理性能。然而,这些系统仍难以为长提示任务提供稳定的服务质量。随着越来越多的模型(如 MPT-StoryWriter [6])和系统(如 DeepSpeed Ulysses [7])支持扩展到数万个 token 的上下文窗口,长提示任务正变得日益重要。
为了更好地理解问题空间,本文展示了文本生成过程的两个关键阶段:提示处理(prompt processing) 与 生成(generation)。当系统将这两个阶段分别处理时,生成过程会被提示阶段中断,从而有可能破坏服务级别协议(SLA)。
对此,本文提出 DeepSpeed-FastGen,该系统通过所提出的 Dynamic SplitFuse 技术克服上述限制,带来了最高 2.3 倍吞吐提升、2 倍延迟下降,以及 3.7 倍 token 级尾延迟降低,超越了现有最先进系统如 vLLM。DeepSpeed-FastGen 结合 DeepSpeed-MII 与 DeepSpeed-Inference,提供一个易于部署、性能卓越的 LLM 服务平台。
2 相关文献中的 LLM 服务技术
一个文本生成任务通常包括两个阶段:
1)提示处理(prompt processing):将用户提供的文本处理为一个 token 批次,并构建注意力机制所需的 key-value(KV)缓存;
2)token 生成(token generation):每次向 KV 缓存添加一个 token,同时生成下一个 token。
在完整生成一个文本序列的过程中,模型会进行多次前向调用,以逐步生成完整序列。已有文献与系统提出了两类主要技术,以应对这两个阶段中可能出现的各种瓶颈与限制。
2.1 分块 KV 缓存
vLLM 指出,传统 LLM 服务系统使用的大型连续 KV 缓存会导致显著的内存碎片问题,从而严重影响并发性能。为了解决这一问题,vLLM 提出了 PagedAttention [8],使缓存可以为非连续的,从而提高系统总吞吐量。
具体来说,PagedAttention 不再为每个请求分配一个可变大小的连续内存块,而是采用固定大小的块(page)进行存储。通过这种“分块 KV 缓存”方式,消除了因 KV 缓存造成的内存碎片,从而显著提升了系统能够同时服务的序列数量。
非连续 KV 缓存的实现也已在 HuggingFace TGI [9] 和 NVIDIA TensorRT-LLM [10] 中得到采用。
2.2 持续批处理
在早期,为提升 GPU 利用率,系统通常采用 动态批处理(dynamic batching):服务器会等待多个请求到达并同步处理。然而,这种方式存在明显缺陷 —— 要么需要对输入进行填充(pad)使其长度一致,要么会为了组建大批次而阻塞系统。
近期的 LLM 推理研究更注重细粒度调度与内存效率的优化。例如,Orca 提出了 迭代级调度(iteration-level scheduling),也称为 持续批处理(continuous batching),在模型的每次前向调用中都进行独立的调度决策。这种方式允许请求按需加入/离开批次,避免了填充输入的需要,从而提升整体吞吐量。
除了 Orca,NVIDIA TRT-LLM、HuggingFace TGI 和 vLLM 等系统也实现了持续批处理。
目前的系统中,持续批处理主要有两种实现方式:
- 在 TGI 与 vLLM 中,生成阶段可能会被中断以处理提示(在 TGI 中称为 infill),之后才继续生成;
- 在 Orca 中,不再区分提示处理与生成阶段,只要总序列数未超过预设上限,系统就可将新的提示加入正在运行的批次。
这些策略不同程度上都需要 暂停生成过程 来处理长提示(见第 3.2 节)。
为此,我们提出了一种全新的提示与生成融合策略 —— Dynamic SplitFuse,将在下一节详细讨论。
3 Dynamic SplitFuse:一种新颖的提示与生成融合策略
DeepSpeed-FastGen 构建于 持续批处理(continuous batching) 与 非连续 KV 缓存(non-contiguous KV caches)的基础之上,旨在提升 LLM 在数据中心中的并发率与响应能力,类似于 TRT-LLM、TGI 和 vLLM 等框架。为了在此基础上进一步提升性能,DeepSpeed-FastGen 引入了 SplitFuse 技术,它通过 动态提示与生成的拆解与融合(decomposition and unification),进一步优化持续批处理机制并提升系统吞吐能力。
3.1 三个性能洞察
在介绍 Dynamic SplitFuse 之前,我们先回答三个关键的性能问题,这些问题共同构成了其设计动机。
3.1.1 哪些因素会影响单次前向传递的性能?
为了实现有效的调度,有必要理解调度循环应控制哪些关键的独立变量。我们的观察表明,在一次前向传递中,序列的组成(即序列的 batch size)对性能的影响可以忽略不计,相比之下,前向传递中总的 token 数量才是决定性因素。这意味着,一个高效的调度器只需围绕“前向传递中的 token 数量”这一单一信号进行设计即可。
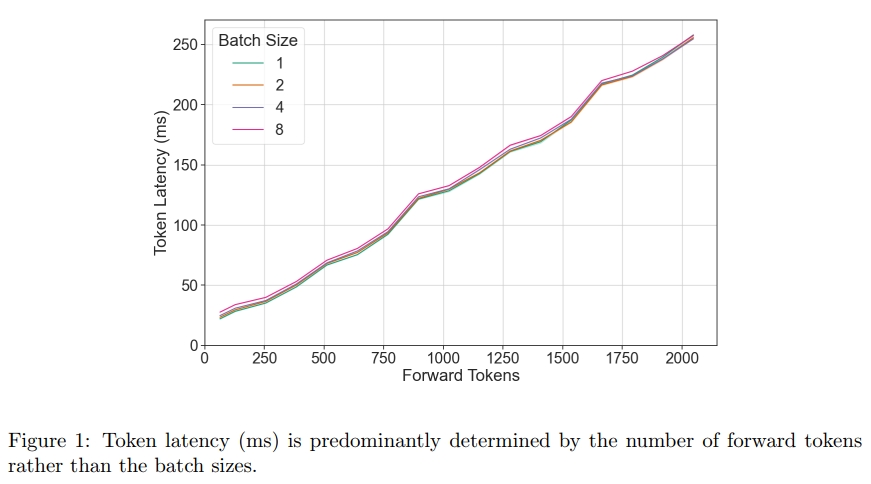
3.1.2 模型的吞吐量如何随着前向传递中 token 数量的变化而变化?
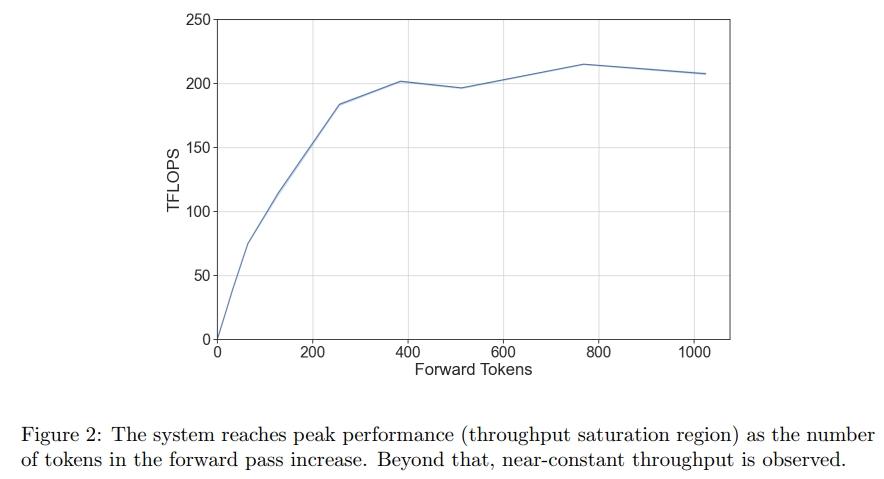
一个大型语言模型(LLM)在运行中存在两个主要的性能区域,并且它们之间的过渡相对陡峭:
- 当 token 数量较少 时,GPU 的瓶颈主要是从内存中读取模型参数,因此吞吐量会随着 token 数量的增加而线性提升;
- 当 token 数量较多 时,模型的瓶颈转为 计算资源,此时吞吐量趋于饱和,基本保持恒定。
因此,如果所有前向传递操作都处于吞吐量饱和区间,模型就能以极高的效率运行。
3.1.3 应如何在多个前向传递中调度一组 token?
我们在上文中观察到,对于对齐良好的输入,其 token 吞吐曲线是凹形的,这意味着二阶导数小于或等于 0。举例来说,设 f(x)f(x)f(x) 是一个模型从延迟到吞吐量的凹函数。对于凹函数 f(x)f(x)f(x),以下性质成立:
0≥limh→0f(x+h)−2f(x)+f(x−h)h20≥f(x+h)−2f(x)+f(x−h)2f(x)≥f(x+h)+f(x−h)\begin{array} { c } { 0 \geq \displaystyle \operatorname* { l i m } _ { h \to 0 } \frac { f ( x + h ) - 2 f ( x ) + f ( x - h ) } { h ^ { 2 } } } \\ { 0 \geq f ( x + h ) - 2 f ( x ) + f ( x - h ) } \\ { 2 f ( x ) \geq f ( x + h ) + f ( x - h ) } \end{array} 0≥h→0limh2f(x+h)−2f(x)+f(x−h)0≥f(x+h)−2f(x)+f(x−h)2f(x)≥f(x+h)+f(x−h)
这表明,对于给定的 2x 个 token,如果希望最大化吞吐量,最优的方式是将它们平均分配到两个 batch 中。更一般地说,在一个系统需要在 F 次前向传递中处理总共 P 个 token 的情况下,理想的划分策略是将这些 token 尽可能平均地分配。
3.2 Dynamic SplitFuse
Dynamic SplitFuse 是一种用于 prompt 处理与 token 生成的新型 token 组合策略。DeepSpeed-FastGen 利用 Dynamic SplitFuse 的策略,在每次前向传播中保持一致的 token 数量,具体方法是将 prompt 中的一部分 token 与生成部分组合在一起处理,从而实现统一的前向尺寸。类似的做法曾在 Sarathi [11] 中被提出,它将 prompt 拆分成更小的块,以便将更多的 token 生成与 prompt 处理结合起来,从而使前向传播保持一致的 batch 大小。
具体而言,Dynamic SplitFuse 执行以下两个关键行为:
- 将长 prompt 拆分为更小的块,并分配到多个前向传播(迭代)中,仅在最后一次前向传播中执行生成。
- 将短 prompt 组合起来以恰好填满目标 token 配额。即使是短 prompt,也可能被拆分,以确保 token 配额被精确满足,从而实现良好的前向对齐。
这两种技术结合在一起,为用户体验带来了如下显著优势:
- 更好的响应性:由于长 prompt 不再需要一次性进行极长的前向传播,模型响应客户请求的延迟降低,在同一时间窗口内可以完成更多的前向传播。
- 更高的效率:将短 prompt 融合以达到更大的 token 配额,使模型始终运行在高吞吐率的状态下。
- 更低的方差与更强的一致性:由于前向传播的 token 数量保持一致,而前向尺寸是性能的主要决定因素,因此每次前向传播的延迟比其他系统更加稳定,同时生成频率也更可预测。系统中不存在像其他系统中那样的中断或长时间运行的 prompt,从而不会导致延迟激增。正如我们在第 4 节所展示的,这种设计可将生成的 P95 延迟最多降低 3.7 倍。
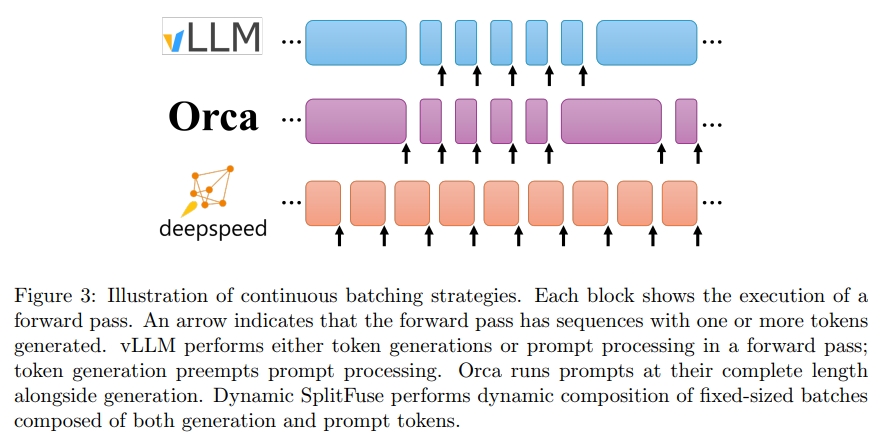
因此,DeepSpeed-FastGen 会以一种既能快速持续生成,又能增加系统利用率的速率消耗来自输入 prompt 的 tokens,从而相比其他先进的服务系统,为所有客户端提供更低延迟和更高吞吐量的流式生成。
温馨提示:
阅读全文请访问"AI深语解构" DeepSpeed-FastGen:通过 MII 和 DeepSpeed-Inference 实现大语言模型的高吞吐文本生成