无源域自适应综合研究【2】
这篇论文聚焦于无监督无源域适应(SFUDA),全面梳理了该领域的研究现状与未来方向。SFUDA使预训练模型在无需访问原始训练数据的情况下,适应一个新的未标记域。
迁移学习可分为三种不同的范式(i)归纳式迁移学习,其中目标任务与源任务不同,但目标域的标签是可获取的。(ii)无监督迁移学习,其中目标任务与源任务不同,且源域和目标域的标签均不可获取。(iii)直推式迁移学习,其中源任务和目标任务是相同的但源域和目标域不同,且目标域中没有标记数据。
研究背景与目标
-
背景:传统无监督域适应(UDA)需同时输入源域和目标域数据,但在实际场景中,源数据可能涉及隐私或设备资源有限,难以获取。SFUDA应运而生,它让预训练模型在无需源数据的情况下适应新的未标记目标域,更贴合现实需求。SFUDA 通过将其工作流程分为两个不同的阶段来实现这一点:(i)预训练阶段,使用带注释的源样本对模型进行预训练;(ii)适应阶段,此时无法访问源样本,模型仅使用未标记的目标样本适应目标域。
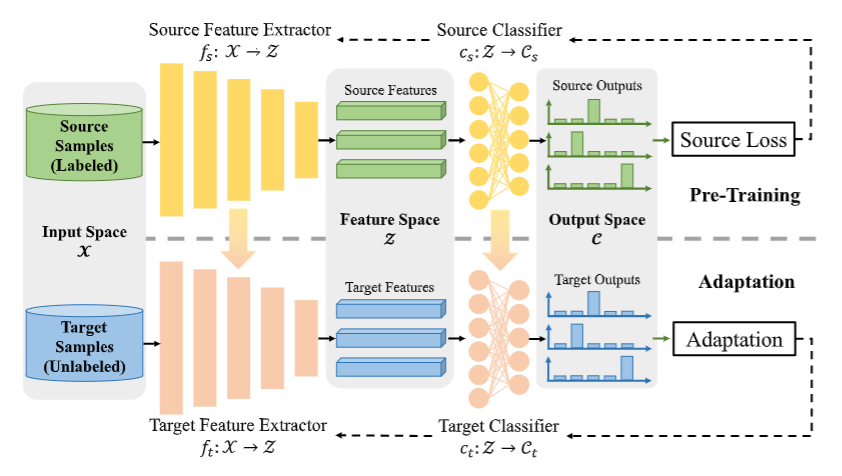
-
目标:对SFUDA方法和应用进行全面综述,按适应目标分类方法,分析优缺点,总结应用领域,并探讨未来研究方向。
核心内容
-
SFUDA方法分类:
按照在适应阶段(即 Stage 2)的核心目标是什么分类—— 也就是模型在适应目标域时,最终想通过学习达成什么效果。
【改参数、对齐特征、造样本三大类】
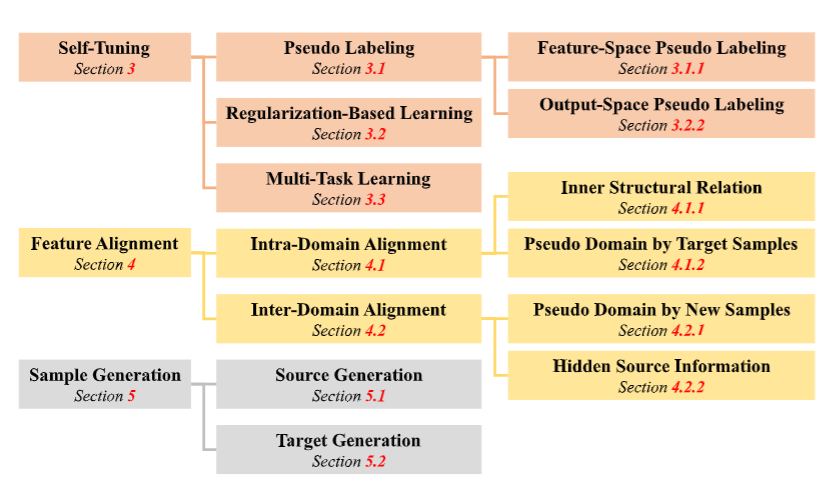
- 一、自调优方法:通过自我创建的监督信号适应模型,分为伪标签、基于正则化的学习和多任务学习三个子类别。
- 伪标签:为目标样本分配伪标签并基于此适应模型,又分特征空间和输出空间伪标签。特征空间伪标签通过构建类质心等方式生成伪标签;输出空间伪标签利用分类器预测获取伪标签,还常借助额外模型提升伪标签质量。
- 基于正则化的学习:仅通过正则化项适应模型,如信息最大化、雅可比范数、早期学习等正则化方法。
- 多任务学习:结合多个任务适应模型,包括辅助任务(如旋转预测等自监督任务)、特征对齐和伪标签任务。
- 二、特征对齐方法:通过对齐目标样本与目标数据结构内的内在信息或目标域之外的信息来适应模型,分为域内对齐和域间对齐。
- 域内对齐:探索目标数据结构,在目标域内寻找对齐参考,包括基于目标特征间内在结构关系和由源类似目标样本构建伪域两种类型。
- 域间对齐:在目标域之外寻找对齐参考,包括由生成新的源类似样本构建伪源域和提取源模型中的隐藏源信息两种类型。
- 三、样本生成方法:通过生成样本适应模型,分为源生成、目标生成和中间域生成。源生成将目标样本翻译为源类似样本;目标生成生成带标签的目标样本直接训练目标模型;中间域生成生成中间域来桥接源域和目标域。
- 一、自调优方法:通过自我创建的监督信号适应模型,分为伪标签、基于正则化的学习和多任务学习三个子类别。
-
应用领域:
- 计算机视觉:在分割、检测和分类任务中均有应用。例 如,在道路分割中,通过熵最小化和输出空间伪标签适应模型,提升在恶劣天气下的分割性能;在3D点云检测中,利用时间一致性估计缩放参数生成伪标签来适应模型。
- 其他领域:还应用于医疗、脑电数据处理、机械故障诊断等领域。如在自闭症诊断、肺炎诊断中,利用SFUDA处理医疗数据的域偏移问题;在机械故障诊断中,结合特征空间伪标签和信息最大化正则化适应模型。
创新点
- 分类方式创新:根据适应目标将SFUDA方法分为自调优、特征对齐和样本生成三大类,每类下又细分多个子类别,这种分类方式清晰且具有系统性。
- 全面的应用总结:详细梳理了SFUDA在计算机视觉(分割、检测、分类)以及医疗、脑电、机械等多个领域的应用,展现了其广泛的实用性。
- 未来方向展望:提出了灾难性遗忘、自监督学习、架构适配和基础模型适配等未来研究方向,为后续研究提供了清晰的指引。
未来方向
- 灾难性遗忘:研究在适应新域时不遗忘先前所学知识的SFUDA方法。
- 自监督学习:开发专门针对SFUDA的自监督学习方法,使其更好地利用源域知识并与其他SFUDA子任务协作。
- 架构适配:研究适配Transformer等新型架构的SFUDA方法,解决现有方法在Transformer架构上应用的挑战。
- 基础模型适配:设计针对大型基础模型的高效适配方法,在SFUDA框架下实现对基础模型的参数高效适配。
总结
这篇论文为SFUDA领域提供了全面且系统的综述,不仅有助于研究人员快速了解该领域的研究现状和应用情况,还为未来的研究指明了方向。其分类方法和对未来方向的探讨具有重要的参考价值,可推动SFUDA在更多实际场景中的应用和发展。
原文题目:Source-Free Unsupervised Domain Adaptation: Current research and future directions请大家自行搜索阅读原论文