SeaweedFS深度解析(二):从Master到Volume
#作者:闫乾苓
文章目录
- 2、核心组件与工作机制
- 2.1 架构图
- 2.2 SeaweedFS 组件
- 2.2.1 主服务(Master service)
- 2.2.2 卷服务(Volume service)
- 2.2.3 Filer(文件目录服务)
2、核心组件与工作机制
2.1 架构图
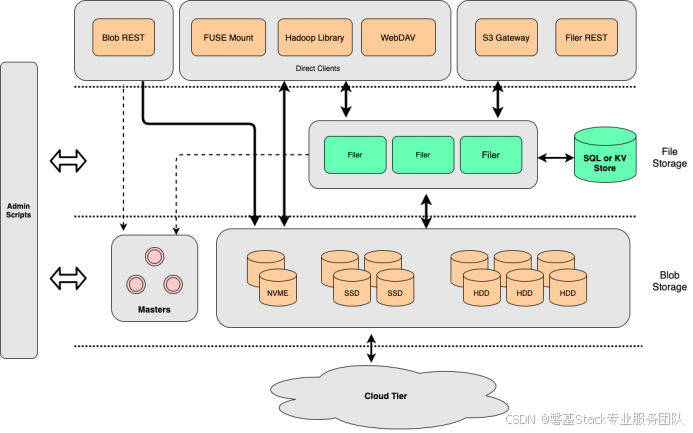
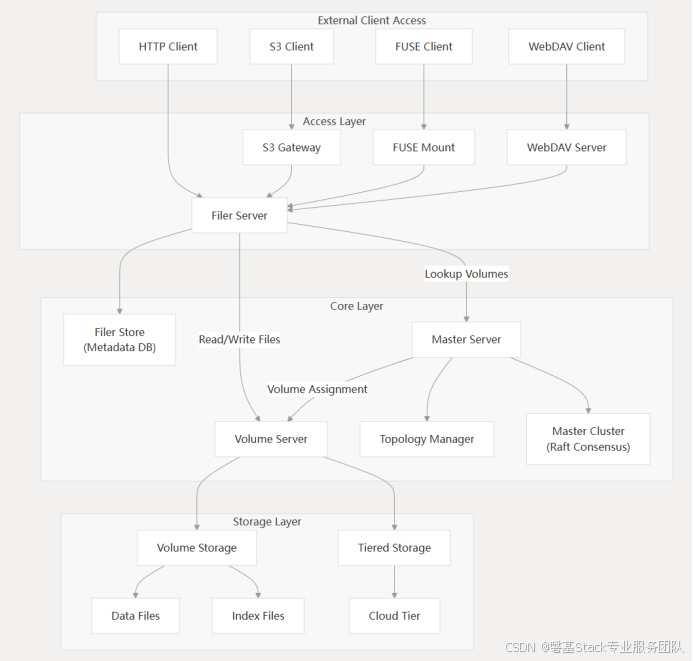
2.2 SeaweedFS 组件
SeaweedFS 由三个主要组件组成。主服务和卷服务共同提供分布式对象存储,并支持用户配置的复制和冗余机制。可选的文件服务和 S3 服务是对象存储之上的附加层。每个服务都可以在一个或多个操作系统上作为单个或单独的进程运行。
2.2.1 主服务(Master service)
功能:Master Service是整个SeaweedFS的核心,负责管理元数据和协调各个Volume Server之间的操作。它不直接存储用户数据,而是维护着集群中所有卷的位置信息。
特点:
- 支持高可用(通过多个 Master 组成集群,必须始终为奇数,基于 Raft 协议实现一致性)。
- 轻量级,不直接参与文件读写,仅处理元数据请求。
关键服务:
- 卷(Volume)的分配与负载均衡。
- 维护文件到卷的映射表(File ID → Volume ID)。
工作机制:
当客户端需要读取或写入数据时,首先会向Master Service请求卷的位置信息。Master Service根据当前的负载情况、卷的分布等因素决定将数据分配到哪个卷上,并返回该卷所在的Volume Server地址给客户端。此外,Master Service还负责处理卷的创建、删除等管理任务。
2.2.2 卷服务(Volume service)
功能:Volume Service运行在多个节点上,每个节点可以托管多个卷。卷是数据存储的基本单位,数据被分割并分布存储在不同的卷上。
特点:
- 支持多副本(Replication)或纠删码(Erasure Coding)保证数据冗余。
- 直接与客户端通信,避免主服务器成为性能瓶颈。
- 将每个文件元数据(文件名、大小、卷上的偏移位置等)存储在磁盘上并将它们缓存在内存中,以提供对它们的快速访问并提供 O(1) 磁盘读取操作
- SeaweedFS 还假设存在一个默认磁盘类型,该类型要么为空,要么为"hdd"。如果所有磁盘类型都是"ssd",则应将磁盘类型保留为空,因为磁盘类型本质上只是用于对卷进行分组的标签,简单来说就是,磁盘类型一致,可以不设置,只有类型不同时,才有必要设置类型。
存储单元:
- 每个卷(Volume)默认大小 30GB,默认 8 个卷。
- 文件以 VolumeID+FileID 唯一标识。
工作机制:
一旦客户端从Master Service获得了卷的位置信息后,就会直接与相应的Volume Server通信来执行具体的读写操作。每个卷都有一定的容量限制,当达到上限时,新的数据会被写入到新创建的卷中。
2.2.3 Filer(文件目录服务)
功能:
- 提供 POSIX 兼容的目录结构(类似传统文件系统),连接到主服务器以获取最新的卷位置,并在文件写入期间请求卷服务器 IP、卷 ID 和文件 ID。
- 处理文件和目录操作,例如创建、删除、读取、写入和重命名。
- 跟踪文件和目录的元数据,例如文件 ID、文件大小、上次修改时间和访问时间等
- 与主服务器通信以跟踪集群状态
- 记录和审核文件和目录操作
- 提供了以不同方式访问数据的入口点:
- 用于上传和下载文件的 HTTP 入口点。
- 通过 FUSE 挂载点直接将文件读写为本地目录。
- S3 兼容 API。
- 访问来自 Hadoop/Spark/Flink/等的文件。
- 网络DAV。
- Kubernetes CSI 驱动程序。
特点:
可选组件,支持目录和POSIX属性,是一个独立的线性可扩展的无状态服务器,默认 SeaweedFS 是扁平存储(通过 File ID 直接访问)。
支持元数据存储到数据库(如 MySQL、PostgreSQL、Redis 等),默认使用内置的 LevelDB。
用途:适用于需要目录结构的场景(如 Web 应用、共享存储)。
工作原理:
实际的数据存储在Volume Servers上。Filer通过查询Master Service来定位文件所在的具体卷位置,并进一步与对应的Volume Server交互完成文件操作。
2.2.4 S3 Server(兼容 Amazon S3 的接口)
功能:提供与 Amazon S3 兼容的RESTful API,方便集成现有S3生态工具。
特点:基于 Filer 实现,将 S3 操作转换为 SeaweedFS 原生操作。
工作原理:S3 Server接收来自客户端的S3协议请求,将其转换为对Filer和Volume Service的操作。这样,用户就可以像使用S3一样使用SeaweedFS进行对象存储。
2.2.5 Weed(命令行工具)
功能:管理集群的核心工具,支持以下操作:
启动 Master、Volume Server、Filer 等组件(如 weed master、weed volume)。
文件上传/下载(如 weed upload、weed download)。
系统状态监控(如 weed shell)。
工作原理:通过调用SeaweedFS的不同API,“Weed”命令行工具能够方便地与Master Service、Volume Service以及Filer进行交互,实现对集群的各种管理功能。