ElasticSearch基础数据管理详解
目录
一、 ElasticSearch核心概念
1. 全文搜索(Full-Text Search)
2. 倒排索引(Inverted Index)
3. ElasticSearch常用术语
3.1 映射(Mapping)
3.2 索引(Index)
3.3 文档(Document)
二、映射管理(Mapping)
三、索引管理(Index)
1. 索引的基本操作
1.1 创建索引
1.2 删除索引
1.3 查询索引
1.4 修改索引
2. 索引别名
如何为索引添加别名
多索引检索的实现方案
四、文档管理(Document)
1. 文档的基本操作
1.1 新增文档
1.2 查询文档
1.3 删除文档
1.4 更新文档
五、Elasticsearch 多表关联方案详解
1. 方案对比概览
2. 嵌套对象 (Nested Object)
3. Join 父子文档 (Parent-Child)
4. 宽表冗余存储 (Denormalization)
5. 终极建议
一、 ElasticSearch核心概念
1. 全文搜索(Full-Text Search)
全文搜索是通过扫描文档内容,为每个词语建立包含出现次数和位置信息的索引。当用户发起查询时,系统根据预先构建的索引快速定位匹配结果并返回。
在Elasticsearch中,全文搜索专门针对文本类型(text)字段,能够智能处理自然语言:它不仅匹配精确词语,还会识别词语变体和同义词,并按相关性对结果进行排序。
2. 倒排索引(Inverted Index)
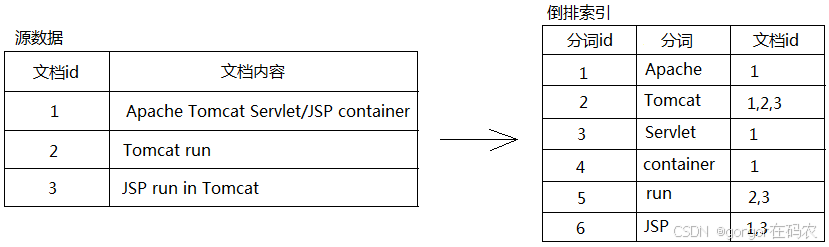
倒排索引是全文检索系统的核心数据结构。与传统正排索引(通过文档ID定位文档内容)不同,倒排索引通过单词(term)反向查找包含该词的文档。
倒排索引包含两个关键组成部分:
- 词典:存储所有不重复单词的列表
- 倒排列表:记录每个单词对应的所有文档信息,包括出现位置、频率等关键数据
3. ElasticSearch常用术语
我们可以对比MySQL来理解Elasticsearch,如下图所示。左侧是MySQL的基本概念,右侧是Elasticsearch对应的相似概念的定义。借由这种对比,我们可以更直观地看出Elasticsearch与传统数据库之间的关系及差异。
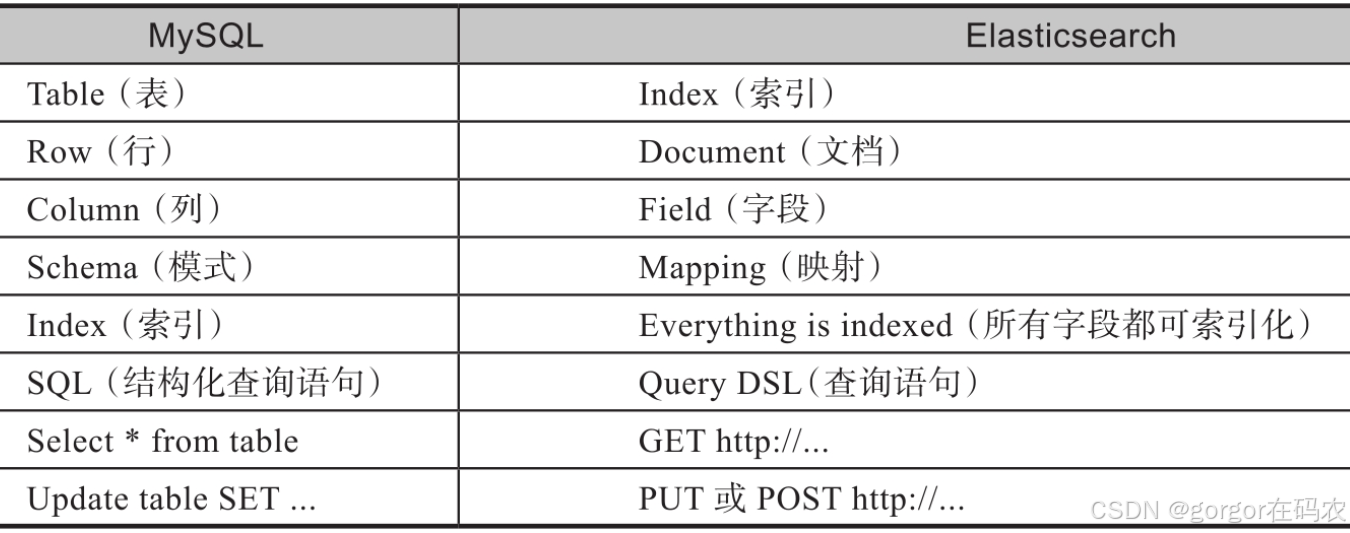
注意:在Elasticsearch 6.X之前的版本中,索引类似于SQL数据库,而type(类型)类似于表。然而,从ES 7.x版本开始,类型已经被弃用,一个索引只能包含一个文档类型。
3.1 映射(Mapping)
定义:
映射是索引的数据结构定义,相当于关系型数据库的表结构(Schema)。
3.2 索引(Index)
定义:
索引是文档的容器,相当于关系型数据库中的表。
注意:在Elasticsearch 6.X之前的版本中,索引类似于SQL数据库,从ES 7.x版本开始,一个索引只能包含一个文档类型。
3.3 文档(Document)
定义:
文档是 Elasticsearch 中的基本数据单元,相当于关系型数据库中的一行记录。
二、映射管理(Mapping)
映射是索引的数据结构定义,相当于关系型数据库的表结构(Schema)。创建表的时候,需要加上表结构,而在elasticSearch中,创建索引,也就需要映射。
创建索引基本语法
PUT /索引名称
{"settings": {// 索引设置},"mappings": {"properties": {// 字段映射}}
}详细栗子
PUT /books
{"settings": {"analysis": { // 自定义分析器配置"analyzer": {"my_custom_analyzer": { // 自定义分析器"type": "custom","tokenizer": "ik_max_word", // 使用IK分词器"filter": ["lowercase", "asciifolding"] // 转小写+去音标符号}}},"number_of_shards": 3, // 主分片数"number_of_replicas": 1 // 副本数},"mappings": {"dynamic": "strict", // 动态映射策略:strict=禁止未知字段"_source": { // 源数据存储控制"enabled": true, // 存储原始JSON"excludes": ["internal_notes"] // 排除敏感字段},"properties": {// 文本类型字段"title": { "type": "text","analyzer": "ik_max_word", // 索引时使用细粒度分词"search_analyzer": "ik_smart", // 搜索时使用粗粒度分词"fields": { // 多字段配置(多字段配置 - 为同一数据创建多种索引方式)"keyword": { // 子字段用于精确匹配"type": "keyword","ignore_above": 256 // 超过256字符不索引(意思就是大于256字符,就不会查询得到)},"english": { // 英文分词字段"type": "text","analyzer": "english"}},"norms": false, // 是否存储长度信息"index_options": "positions" // 存储位置信息用于短语查询(存储哪些内容)},// 关键词类型字段"author": { "type": "keyword","null_value": "佚名", // 空值替换"ignore_above": 256 // 超长值处理},// 数值类型字段"price": { "type": "scaled_float", // 推荐数值类型"scaling_factor": 100, // 放大因子(存储整数)"doc_values": true // 启用聚合排序},"discount_rate": {"type": "float", // 标准浮点类型"index": false // 禁用索引},// 日期类型字段"publish_date": { "type": "date","format": "yyyy-MM-dd||epoch_millis", // 多格式支持"doc_values": false, // 禁用列式存储"ignore_malformed": true // 忽略格式错误},// 复杂类型字段"tags": { "type": "keyword", // 标签数组"index": true, // 启用索引"boost": 2.0 // 权重提升},"metadata": { // 对象类型"type": "object","properties": {"isbn": {"type": "keyword"},"page_count": {"type": "integer"}}},"reviews": { // 嵌套类型"type": "nested", // 保持数组对象独立"properties": {"user": {"type": "keyword"},"rating": {"type": "byte"},"comment": {"type": "text"}}},// 其他特殊类型"description": { "type": "text","index": false, // 仅存储不索引"store": true // 单独存储},"cover_image": {"type": "binary", // 二进制类型"store": true},"last_access_ip": {"type": "ip" // IP地址类型},"coordinates": {"type": "geo_point" // 地理坐标},"embedding": { // 向量搜索(8.x+)"type": "dense_vector","dims": 128, // 向量维度"index": true,"similarity": "dot_product" // 相似度算法}}}
}字段类型定义(type)
-
文本类型:
text(全文搜索),keyword(精确匹配) -
数值类型:
long,integer,float,double -
日期类型:
date -
复杂类型:
object,nested
具体关键配置详解如下
-
字段类型定义
| 类型 | 配置参数 | 说明 | 适用场景 |
|---|---|---|---|
| text | analyzersearch_analyzer | 指定分词器 | 中文内容、描述文本 |
| keyword | ignore_abovenull_value | 长度限制/空值处理 | ID、状态码、标签 |
| scaled_float | scaling_factor | 数值缩放因子 | 价格、评分等小数 |
| date | formatignore_malformed | 格式/容错处理 | 时间戳、日期 |
| nested | - | 保持数组对象独立 | 评论、子文档 |
| dense_vector | dimssimilarity | 维度/相似度算法 | AI向量搜索 |
-
分析器配置
| 分析器类型 | 特点 | 示例值 |
|---|---|---|
standard | 单字拆分 | "中国" → ["中","国"] |
ik_smart | 最粗粒度 | "中国人民银行" → ["中国人民银行"] |
ik_max_word | 最细粒度 | "中国人民银行" → ["中国人","中国","人民","银行"] |
english | 英文处理 | "running" → ["run"] |
| 自定义分析器 | 组合处理 | IK分词+小写转换 |
- 索引控制参数
| 参数 | 值范围 | 作用 | 性能影响 |
|---|---|---|---|
index | true/false | 是否创建倒排索引 | 禁用可节省90%存储 |
doc_values | true/false | 是否启用列式存储 | 禁用将无法聚合排序 |
store | true/false | 是否单独存储 | 增加存储但加速检索 |
norms | true/false | 是否存储长度信息 | 节省5-10%空间 |
index_options | docs/freqs/positions | 索引内容粒度 | 位置信息支持短语查询 |
ignore_above | 数字 | 超长值处理 | 避免大字段影响性能 |
null_value | 指定值 | 空值替换 | 保证数据完整性 |
index_options 参数详解
index_options 是 Elasticsearch 中控制倒排索引内容粒度的关键参数,它决定了在索引过程中存储哪些信息,直接影响搜索功能和性能。以下是深度解析:
可选值及含义:
| 值 | 存储内容 | 支持功能 | 资源消耗 | 适用场景 | 限制 |
|---|---|---|---|---|---|
docs | 只存储文档ID | 仅能判断文档是否存在 | 最低 | 过滤型字段(如状态标志) | ❌ 不支持相关性排序 ❌ 不支持短语查询 |
freqs | 文档ID + 词频 | 支持相关性评分 | 中等 | 简单搜索(无需短语查询) | ❌ 不支持短语查询 ❌ 不支持高亮 |
positions (默认) | 文档ID + 词频 + 位置 | 支持短语/邻近查询 | 较高 | 常规文本字段 | ❌ 高亮效率较低 |
offsets | 文档ID + 词频 + 位置 + 字符偏移 | 支持高亮显示 | 最高 | 需要高亮的字段 | ⚠️ 存储开销增加40% |
注:该参数仅适用于
text和keyword类型字段
-
高级特性
| 特性 | 配置 | 说明 |
|---|---|---|
| 多字段 | fields | 同一字段多种索引方式 |
| 动态映射 | dynamic: strict | 禁止未知字段自动映射 |
| 源数据过滤 | _source.excludes | 排除敏感字段 |
| 字段权重 | boost | 提升特定字段相关性 |
| 时间序列 | time_series | 优化时序数据存储(8.10+) |
动态映射 dynamic 参数用于控制如何处理文档中出现的未在映射中定义的字段(即动态字段)。它有 4 种可选值,每种值对应不同的处理策略:
| 值 | 行为 | 适用场景 | 风险/限制 |
|---|---|---|---|
true (默认值) | 自动检测新字段类型并添加到映射 | 开发环境、数据结构变化频繁 | 映射膨胀、类型推断错误 |
false | 忽略新字段(不索引),但保留在 _source | 日志类数据、未知字段不需搜索 | 无法搜索新字段 |
strict | 拒绝包含新字段的文档 | 生产环境、严格数据管控 | 需预先定义完整映射 |
runtime (7.11+) | 将新字段作为运行时字段处理 | 灵活查询未定义字段 | 性能低于索引字段 |
三、索引管理(Index)
索引是文档的容器,相当于关系型数据库中的表。索引是具有相同结构的文档的集合,由唯一索引名称标定。一个集群中有多个索引,不同的索引代表不同的业务类型数据。
1. 索引的基本操作
1.1 创建索引
创建索引的基本语法如下:
PUT /index_name
{"settings": {// 索引设置},"mappings": {"properties": {// 字段映射}}
}- 索引名称 (index_name):索引名称必须是小写字母,可以包含数字和下划线。
- 索引设置 (settings)
-
分片数量 (number_of_shards):一个索引的分片数决定了索引的并行度和数据分布。
-
副本数量 (number_of_replicas):副本提高了数据的可用性和容错能力。
-
-
映射 (mappings):字段属性 (properties)定义索引中文档的字段及其类型。
具体定义看映射管理。
实践练习
创建一个名为 student_index 的索引,并设置一些以下自定义字段
- name(学生姓名):text 类型
- age(年龄):integer 类型
- enrolled_date(入学日期):date 类型
PUT /student_index
{"settings": {"number_of_shards": 1,"number_of_replicas": 1},"mappings": {"properties": {"name": {"type": "text"},"age": {"type": "integer"},"enrolled_date": {"type": "date"}}}
}插入一条文档,方便下面进行测试
POST /student_index/_create/1
{"name": "John","age": 18,"enrolled_date": "2006-12-12"
}
1.2 删除索引
DELETE /student_index // 谨慎操作!不可逆1.3 查询索引
查询操作可以分为两类:检索索引信息和搜索索引中的文档。
1.3.1 检索索引信息
基本语法如下:
GET /index_name栗子
GET student_index1.3.2 搜索索引中的文档。
基本语法如下:
GET /index_name/_search
{ "query": { // 查询条件 }
}栗子
# 搜索 name 字段包含 John 的文档
GET /student_index/_search
{"query": {"match": {"name": "John"}}
}
1.4 修改索引
1.4.1 动态更新 settings
基本语法
PUT /index_name/_settings
{"index": {"setting_name": "setting_value"}
}
代码示例
将 student_index 的副本数量更新为 2:
PUT /student_index/_settings
{"index": {"number_of_replicas": 2}
}
1.4.2 动态更新 mapping
基本语法
PUT /index_name/_mapping
{"properties": {"new_field": {"type": "field_type"}}
}
代码示例
向 student_index 添加一个名为 grade 的新字段,类型为 integer:
PUT /student_index/_mapping
{"properties": {"grade": {"type": "integer"}}
}2. 索引别名
索引别名是 Elasticsearch 中一个强大的功能,它允许你为索引创建一个或多个替代名称,类似于文件系统中的快捷方式或符号链接。下面我将全面解析索引别名的概念、用法和实战场景。
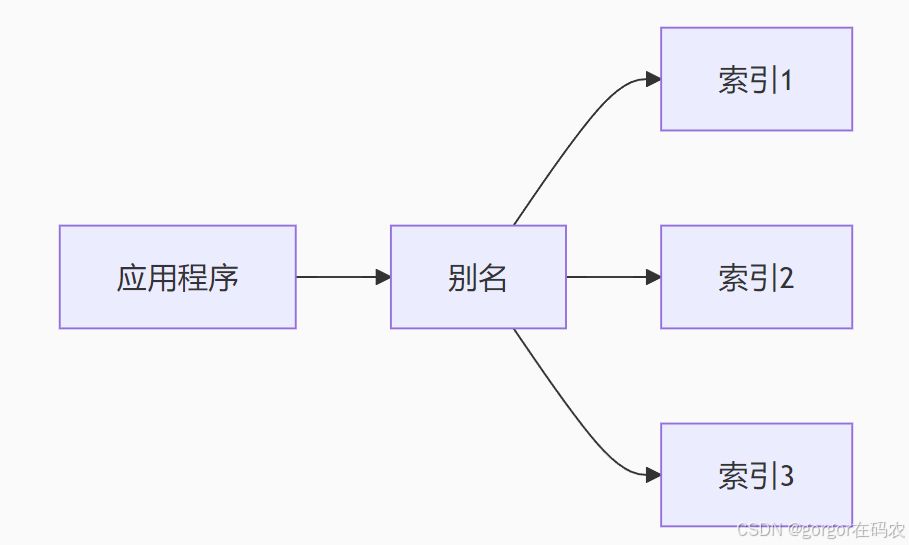
-
一个逻辑名称,可以指向一个或多个物理索引
-
提供抽象层,解耦应用和物理存储结构
-
支持无缝切换索引(零停机维护)
如何为索引添加别名
- 创建索引的时候可以指定别名
PUT student_index
{"aliases": {"student_index_alias": {}},"settings": {"refresh_interval": "30s","number_of_shards": 1,"number_of_replicas": 0},"mappings": {"properties": {"name": {"type": "text"},"age": {"type": "integer"},"enrolled_date": {"type": "date"}}}
}- 为已有索引添加别名
POST /_aliases
{"actions": [{"add": {"index": "student_index","alias": "student_index_alias"}}]
}多索引检索的实现方案
- 不使用别名的方案
- 方式一:使用逗号对多个索引名称进行分隔
POST gorgor_logs_202501,gorgor_logs_202502,gorgor_logs_202503/_search- 方式二:使用通配符进行多索引检索
POST gorgor_logs_*/_search- 使用别名的方案
PUT gorgor_logs_202501
PUT gorgor_logs_202502
PUT gorgor_logs_202503POST _aliases
{"actions": [{"add": {"index": "gorgor_logs_202501","alias": "gorgor_logs_2025"}},{"add": {"index": "gorgor_logs_202502","alias": "gorgor_logs_2025"}},{"add": {"index": "gorgor_logs_202503","alias": "gorgor_logs_2025"}}]
}POST gorgor_logs_2025/_search四、文档管理(Document)
文档是 Elasticsearch 中的基本数据单元,相当于关系型数据库中的一行记录。文档是指存储在Elasticsearch索引中的JSON对象。
1. 文档的基本操作
1.1 新增文档
在ES8.x中,新增文档的操作可以通过POST或PUT请求完成,具体取决于是否指定了文档的唯一性标识(即ID)。如果在创建数据时指定了唯一性标识,可以使用POST或PUT请求;如果没有指定唯一性标识,只能使用POST请求。
简单理解:PUT 必须指定唯一性标识,POST可以指定,也可以不指定,不指定则 elasticsearch 会帮忙生成一个。
1.1.1 使用POST请求新增文档
当不指定文档ID时,可以使用POST请求来新增文档,Elasticsearch会自动生成一个唯一的ID。语法如下:
POST /<index_name>/_doc
{"field1": "value1","field2": "value2",// ... 其他字段
}
1.1.2 使用PUT请求新增文档
当指定了文档的唯一性标识(ID)时,可以使用PUT请求来新增或更新文档。如果指定的ID在索引中不存在,则会创建一个新文档;如果已存在,则会替换现有文档。语法如下:
PUT /<index_name>/_doc/<document_id>
{"field1": "value1","field2": "value2",// ... 其他字段
}
在Elasticsearch 8.x中,批量新增文档可以通过_bulk API来实现。这个API允许您将多个索引、更新或删除操作组合成一个单一的请求,从而提高批量操作的效率。
- Index: 用于创建新文档或替换已有文档。
- Create: 如果文档不存在则创建,如果文档已存在则返回错误。
- Update: 用于更新现有文档。
- Delete: 用于删除指定的文档。
以下是使用_bulk API的基本语法:
POST /<index_name>/_bulk
# index
{ "index" : { "_index" : "<index_name>", "_id" : "<optional_document_id>" } }
{ "field1" : "value1", "field2" : "value2", ... }# update
{ "update" : { "_index" : "<index_name>", "_id" : "<document_id>" } }
{ "doc" : {"field1" : "new_value1", "field2" : "new_value2", ... }, "_op_type" : "update" }# delete
{ "delete" : { "_index" : "<index_name>", "_id" : "<document_id>" } }# create
{ "create" : { "_index" : "<index_name>", "_id" : "<optional_document_id>" } }
{ "field1" : "value1", "field2" : "value2", ... }- 指定文档ID:
- PUT请求在创建或更新文档时必须指定文档的唯一ID。如果指定的ID已经存在,PUT请求会替换现有文档;如果不存在,则创建一个新文档。
- POST请求在创建新文档时可以指定ID,也可以不指定。如果不指定ID,Elasticsearch会自动生成一个唯一的ID。
- 幂等性:
- PUT请求是幂等的,这意味着多次执行相同的PUT请求,即使是针对同一个文档,最终的结果都是一致的。
- POST请求不是幂等的,多次执行相同的POST请求可能会导致创建多个文档。
- 更新行为:
- PUT请求在更新文档时会替换整个文档的内容,即使是文档中未更改的部分也会被新内容覆盖。
- POST请求在更新文档时可以使用_update API,这样可以只更新文档中的特定字段,而不是替换整个文档。
1.2 查询文档
1.2.1 根据id查询文档
在Elasticsearch 8.x中,根据文档的ID查询单个文档的标准语法是使用GET请求配合文档所在的索引名和文档ID。以下是具体的请求格式:
GET /<index_name>/_doc/<document_id>1.2.2 根据id批量查询文档
在Elasticsearch 8.x中,使用Multi GET API可以根据ID查询多个文档。该API允许您在单个请求中指定多个文档的ID,并返回这些文档的信息。以下是Multi GET API的基本语法:
GET /<index_name>/_mget
{"ids" : ["id1", "id2", "id3", ...]
}1.2.3 根据搜索关键词查询文档
在Elasticsearch 8.x中,查询文档通常使用Query DSL(Domain Specific Language),这是一种基于JSON的语言,用于构建复杂的搜索查询。
以下是一些常用的查询语法:
- 匹配所有文档
GET /<index_name>/_search
{"query": {"match_all": {}}
}- 模糊匹配(分词)
GET /<index_name>/_search
{"query": {"match": {"<field_name>": "<query_string>"}}
}- 精确匹配(不分词)
GET /<index_name>/_search
{"query": {"term": {"<field_name>": {"value": "<exact_value>"}}}
}- 范围查询
-
GET /<index_name>/_search {"query": {"range": {"<field_name>": {"gte": <lower_bound>,"lte": <upper_bound>}}} }
1.3 删除文档
1.3.1 删除单个文档
在Elasticsearch 8.x中,删除单个文档的基本HTTP请求语法是:
DELETE /<index_name>/_doc/<document_id>1.3.2 批量删除文档
- 使用 _bulk API_bulk API允许您发送一系列操作请求,包括删除操作。每个删除请求是一个独立的JSON对象,格式如下:
POST /_bulk
{ "delete": {"_index": "{index_name}", "_id": "{id}"} }
{ "delete": {"_index": "{index_name}", "_id": "{id}"} }
{ "delete": {"_index": "{index_name}", "_id": "{id}"} }
- 使用 _delete_by_query API_delete_by_query API允许您根据查询条件删除文档。如果您想删除特定索引中匹配特定查询的所有文档,可以使用以下请求格式:
POST /{index_name}/_delete_by_query
{"query": {"<your_query>"}
}
1.4 更新文档
1.4.1 更新单个文档
在Elasticsearch 8.x版本中,更新操作通常通过_update接口执行,该接口允许您部分更新现有文档的字段。以下是更新文档的基本语法:
POST /{index_name}/_update/{id}
{"doc": {"<field>: <value>"}
}1.4.2 批量更新文档
- 使用 _bulk API
POST /_bulk
{ "update" : {"_index" : "<index_name>", "_id" : "<document_id>"} }
{ "doc" : {"field1" : "new_value1", "field2" : "new_value2"}, "upsert" : {"field1" : "new_value1", "field2" : "new_value2"} }
...
在这个请求中,每个update块代表一个更新操作,其中_index和_id指定了要更新的文档,doc部分包含了更新后的文档内容,upsert部分定义了如果文档不存在时应该插入的内容。
- 使用 _update_by_query API_update_by_query API允许您根据查询条件更新多个文档。这个操作是原子性的,意味着要么所有匹配的文档都被更新,要么一个都不会被更新。
POST /<index_name>/_update_by_query
{"query": {<!-- 定义更新文档的查询条件 -->},"script": {"source": "ctx._source.field = 'new_value'","lang": "painless"}
}
在这个请求中,是您要更新的索引名称,query部分定义了哪些文档需要被更新,script部分定义了如何更新这些文档的字段。
并发场景下更新文档如何保证线程安全
在Elasticsearch 7.x及以后的版本中,_seq_no和_primary_term取代了旧版本的_version字段,用于控制文档的版本。_seq_no代表文档在特定分片中的序列号,而_primary_term代表文档所在主分片的任期编号。这两个字段共同构成了文档的唯一版本标识符,用于实现乐观锁机制,确保在高并发环境下文档的一致性和正确更新。
当在高并发环境下使用乐观锁机制修改文档时,要带上当前文档的_seq_no和_primary_term进行更新:
POST /employee/_doc/1?if_seq_no=13&if_primary_term=1
{"name": "小明","sex": 1,"age": 25
}如果_seq_no和_primary_term不对,会抛出版本冲突异常:
{ "error": { "root_cause": [ { "type": "version_conflict_engine_exception", "reason": "[1]: version conflict, required seqNo [13], primary term [1]. current document has seqNo [14] and primary term [1]", "index_uuid": "7JwW1djNRKymS5P9FWgv7Q", "shard": "0", "index": "employee" } ], "type": "version_conflict_engine_exception", "reason": "[1]: version conflict, required seqNo [13], primary term [1]. current document has seqNo [14] and primary term [1]", "index_uuid": "7JwW1djNRKymS5P9FWgv7Q", "shard": "0", "index": "employee" }, "status": 409 }
五、Elasticsearch 多表关联方案详解
在 Elasticsearch 中实现类似关系型数据库的多表关联,主要有四种核心方案,各有适用场景和性能特点:
1. 方案对比概览
| 方案 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 嵌套对象 | 文档内嵌子对象 | 查询快、数据局部性 | 更新成本高 | 一对少、读多写少 |
| Join父子文档 | 父子文档跨存储 | 支持一对多、独立更新 | 查询性能较低 | 频繁更新子文档 |
| 宽表冗余 | 字段冗余存储 | 最佳性能、简单 | 数据冗余、更新复杂 | 读密集型场景 |
| 业务端关联 | 应用层处理 | 灵活、无ES限制 | 网络开销大 | 复杂关联关系 |
各项详解:
- 嵌套对象(Nested Object)
- Join父子文档类型
- 宽表冗余存储
- 业务端关联
2. 嵌套对象 (Nested Object)
原理
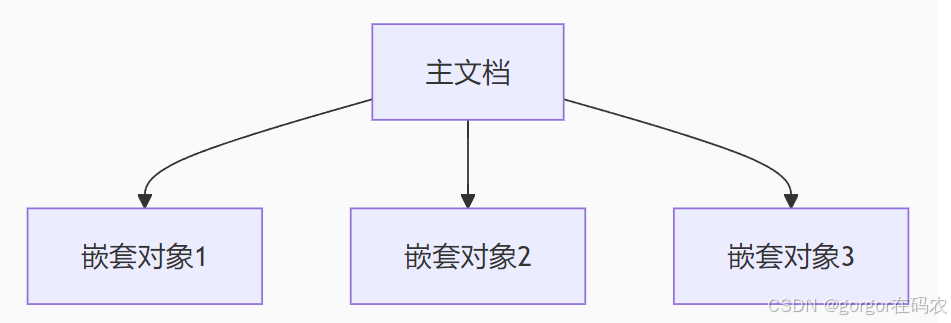
-
将关联数据作为内嵌对象数组存储
-
每个嵌套对象独立索引和查询
示例:订单与商品
PUT /orders
{"mappings": {"properties": {"order_id": {"type": "keyword"},"order_date": {"type": "date"},"items": {"type": "nested", // 关键声明"properties": {"product_id": {"type": "keyword"},"name": {"type": "text"},"price": {"type": "float"},"quantity": {"type": "integer"}}}}}
}查询嵌套对象
GET /orders/_search
{"query": {"nested": {"path": "items","query": {"bool": {"must": [{"match": {"items.name": "手机"}},{"range": {"items.price": {"lt": 3000}}}]}}}}
}适用场景
-
订单项与订单
-
文章与评论
-
用户与地址
3. Join 父子文档 (Parent-Child)
原理
-
父子文档独立存储在同一分片
-
通过
join类型字段建立关联
示例:部门与员工
PUT /company
{"mappings": {"properties": {"relation": {"type": "join", // 声明父子关系"relations": {"department": "employee" // 部门是父,员工是子}},"name": {"type": "text"},"budget": {"type": "float"}}}
}插入数据
// 父文档(部门)
PUT /company/_doc/d001
{"name": "研发部","budget": 5000000,"relation": "department" // 类型标识
}// 子文档(员工)
PUT /company/_doc/e001?routing=d001 // 必须指定路由
{"name": "张三","salary": 25000,"relation": {"name": "employee", // 类型标识"parent": "d001" // 父文档ID}
}查询父子文档
// 1. 查询部门下所有员工
GET /company/_search
{"query": {"parent_id": {"type": "employee","id": "d001"}}
}// 2. 查询高薪员工的部门
GET /company/_search
{"query": {"has_child": {"type": "employee","query": {"range": {"salary": {"gte": 30000}}}}}
}适用场景
-
部门与员工
-
产品与评论
-
博客与点赞
4. 宽表冗余存储 (Denormalization)
原理
-
将关联数据直接复制到主文档
-
通过应用层维护一致性
示例:用户+最新订单
PUT /users
{"mappings": {"properties": {"user_id": {"type": "keyword"},"name": {"type": "text"},"latest_order": { // 冗余订单数据"properties": {"order_id": {"type": "keyword"},"amount": {"type": "float"},"items": {"type": "nested","properties": {...}}}}}}
}查询包含特定商品的用户
GET /users/_search
{"query": {"nested": {"path": "latest_order.items","query": {"bool": {"must": [{"match": {"latest_order.items.product_name": "手机"}}]}}}},"highlight": {"fields": {"latest_order.items.product_name": {}}}
}适用场景
-
用户最新订单
-
商品最新评论
-
实时统计指标
5. 终极建议
-
读多写少 → 嵌套对象
-
频繁更新 → 父子文档
-
极致性能 → 宽表冗余
-
复杂关联 → 业务端处理