清华大学层次化空间记忆助力具身导航!Mem4Nav:基于层次化空间认知长短期记忆系统的城市环境视觉语言导航

- 作者:Lixuan He, Haoyu Dong, Zhenxing Chen, Yangcheng Yu, Jie Feng, Yong Li
- 单位:清华大学信息国家研究中心电子工程系
- 论文标题:Mem4Nav: Boosting Vision-and-Language Navigation in Urban Environments with a Hierarchical Spatial-Cognition Long-Short Memory System
- 论文链接:https://arxiv.org/pdf/2506.19433v1
- 代码链接:https://github.com/tsinghua-fib-lab/Mem4Nav (coming soon)
主要贡献
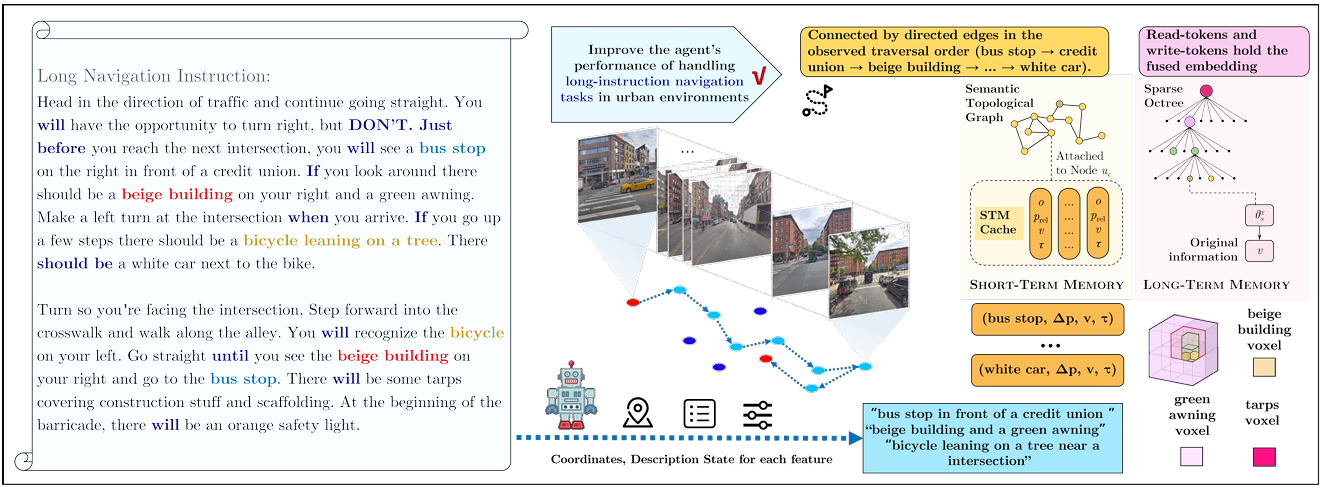
- 提出了层次化的空间认知长短期记忆系统Mem4Nav,通过结合稀疏八叉树索引和语义拓扑图,统一了细粒度几何信息和地标连通性,并设计了一种可逆的Transformer记忆模块,能够无损地压缩和检索空间锚定的观测数据,同时开发了短期记忆缓存用于高频本地查询,以及统一的检索机制动态平衡短期和长期记忆。
- 在Touchdown和Map2Seq两个街景VLN基准测试中,使用三种不同的骨干网络(非端到端的模块化管道、基于提示的LLM导航智能体和基于步进注意力的MLLM导航智能体),Mem4Nav在任务完成率、路径保真度和距离指标上均取得了显著的改进,绝对提升幅度为7到13个百分点。
- 通过消融研究验证了系统各组件的必要性,证明了稀疏八叉树、语义图、长期记忆Token和短期缓存对于性能提升都至关重要。
研究背景
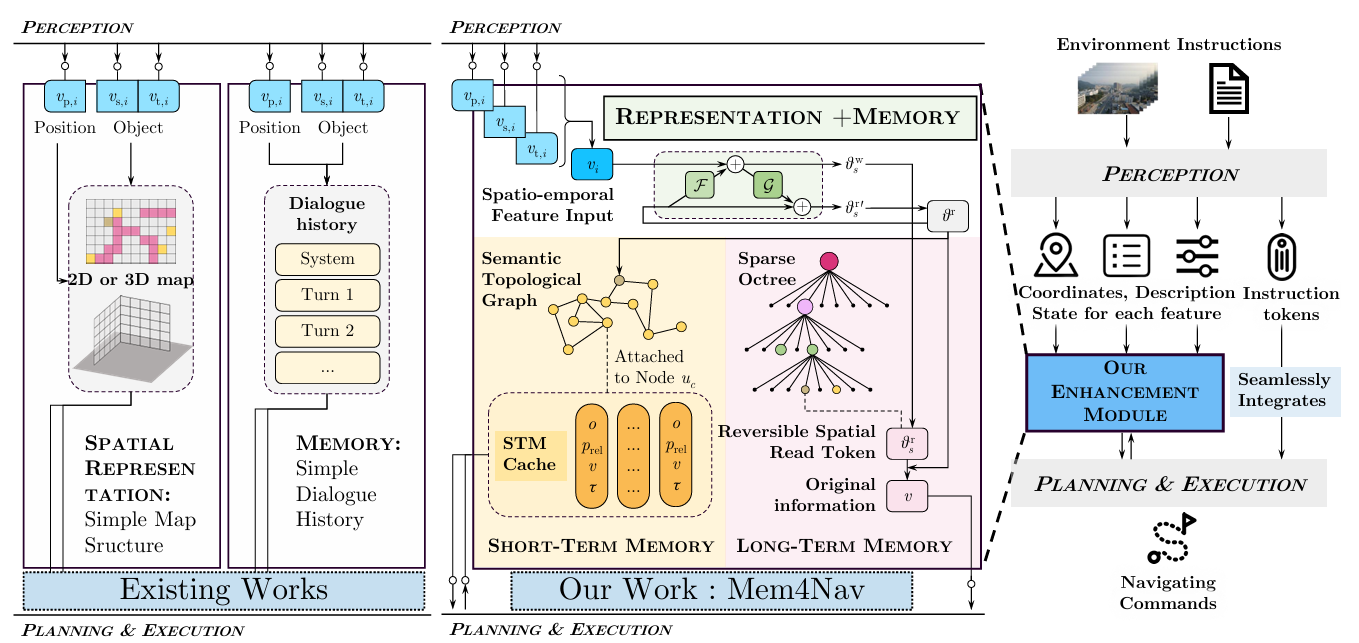
- 视觉语言导航(VLN)任务的挑战:在大规模城市环境中进行VLN任务要求智能体能够将自然语言指令与复杂场景中的视觉信息相结合,并在长时间跨度内回忆相关经验。现有的方法主要集中在室内VLN任务,而在室外城市环境中,智能体需要处理更复杂的3D场景、更长的指令以及更动态的环境。
- 现有方法的局限性:一方面,层次化模块化管道虽然具有可解释性,但缺乏统一的记忆;另一方面,基于(多模态)大型语言模型的端到端方法虽然在融合视觉和语言方面表现出色,但受到固定上下文窗口和隐式空间推理的限制,无法高效地存储和检索大规模3D结构,也无法快速适应动态的局部变化。
Mem4Nav方法
层次化空间表示
Mem4Nav通过两种互补的空间结构来组织环境信息,以实现细粒度几何信息和高层次路线规划的结合:
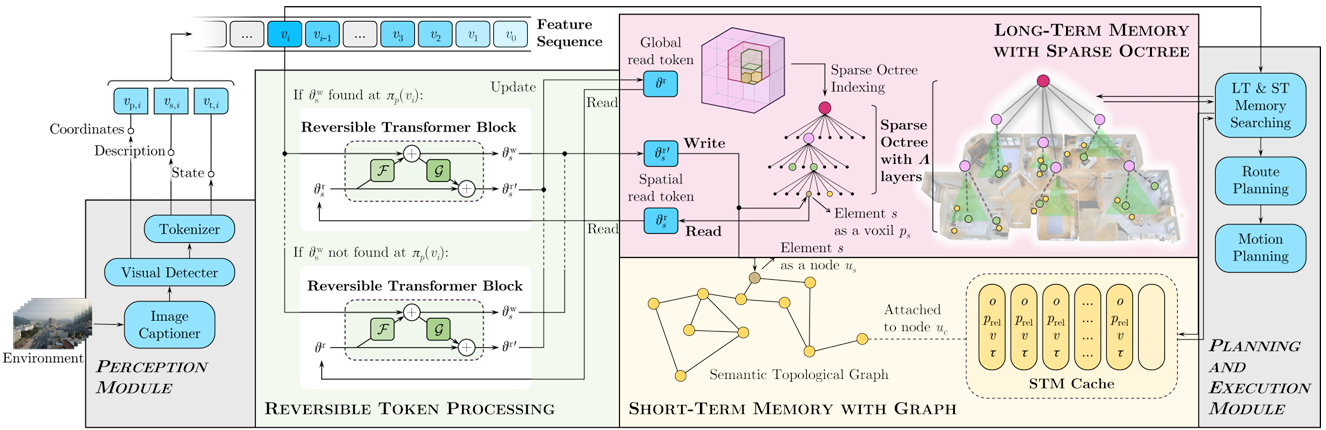
- 稀疏八叉树索引
- 八叉树结构:将连续的3D空间离散化为最大深度为Λ的稀疏八叉树,每一层ℓ的立方体边长为L/2ℓ。只有智能体访问过或包含相关观测的叶子节点才会被实例化并存储在哈希表中,确保稀疏性和O(1)平均查找时间。
- Morton码地址:智能体的位置pt=(xt,yt,zt)p_t = (x_t, y_t, z_t)pt=(xt,yt,zt)被量化为整数索引pˉt\bar{p}_tpˉt,并通过交织位形成Morton码κ(pt)\kappa(p_t)κ(pt),唯一标识访问过的叶子节点。
- 叶子节点嵌入更新:每个实例化的叶子节点维护其立方体内的观测聚合嵌入。当智能体重新访问时,通过可逆更新算子将当前特征向量vtv_tvt融合到嵌入中,既保证效率又保证信息保真度。
- 语义拓扑图
- 图结构:维护一个动态有向图G=(V,E)G = (V, E)G=(V,E),其中节点u∈Vu \in Vu∈V对应地标或交叉口,边(ui,uj)∈E(u_i, u_j) \in E(ui,uj)∈E编码可遍历性和成本。
- 节点创建:当当前嵌入vtv_tvt与现有节点描述符的差异大于阈值δ时,创建新节点,并将其位置设为ptp_tpt,初始化描述符为vtv_tvt。
- 边权重计算:当智能体从节点ut−1u_{t-1}ut−1移动到节点utu_tut时,添加或更新有向边(ut−1,ut)(u_{t-1}, u_t)(ut−1,ut),边权重由欧几里得距离和基于指令的惩罚(如转弯)共同决定。
长期记忆
长期记忆(LTM)通过在八叉树叶子和语义图节点中嵌入虚拟“记忆Token”来提供高容量、无损存储空间锚定的观测数据。
- 可逆Transformer块:采用可逆架构,输入(x1ℓ,x2ℓ)(x_1^\ell, x_2^\ell)(x1ℓ,x2ℓ)通过两个子模块FℓF_\ellFℓ和GℓG_\ellGℓ进行变换,实现可逆的更新操作。每个空间元素sss(叶子或节点)维护一个读取Tokenθrs\theta_r^sθrs和写入Tokenθws\theta_w^sθws,新观测vtv_tvt通过双射更新写入LTM,原始信息可以通过逆变换精确恢复。
- 循环一致性训练:通过最小化循环一致性损失来训练可逆块,确保信息的忠实重构。
- 从LTM检索:在决策时,如果本地缓存未命中,则通过HNSW(层次化可导航小世界)图进行近似最近邻查找,恢复原始嵌入并通过解码器获取位置和描述信息。
短期记忆缓存
短期记忆(STM)是一个固定大小、高频的缓冲区,附加在当前语义节点上,用于快速本地查找和动态障碍物规避。
- 条目结构:每个STM条目包含对象标识符、相对于当前节点的坐标、多模态嵌入和时间戳。
- 替换策略:结合频率和最近使用情况,采用“频率-最近最少使用”策略来决定何时替换条目,以最大化命中率。
- STM检索:在给定当前嵌入和相对查询的情况下,通过过滤和计算余弦相似度来检索STM条目。
多级记忆检索与决策机制
在每个时间步,智能体首先尝试从短期记忆中检索信息,如果未命中,则回退到长期记忆:
- 短期记忆检索:计算相对查询向量,过滤STM条目,并按余弦相似度排序。如果最高相似度超过阈值τ,则聚合前k个STM嵌入;否则,回退到长期记忆。
- 长期记忆检索:通过HNSW图对所有读取Token进行搜索,解码前m个令牌,并聚合它们。
- 决策融合:最终的记忆向量与基线的键和值在策略的交叉注意力中进行聚合,并通过学习的门控机制结合,以驱动路径和运动规划。
实验
数据集和评估指标
- 数据集:
- Touchdown:包含9,326条指令-轨迹对,采集自纽约市的StreetLearn环境。指令通常涉及城市地标,需要精确对齐到复杂的交叉口。
- Map2Seq:包含7,672条指令-轨迹对,采集自更密集的城市子集。
- 评估指标:
- 任务完成率:智能体在3米内停止的百分比(越高越好)。
- 最短路径距离:智能体最终位置到目标的平均测地线距离(越低越好)。
- 归一化动态时间弯曲:智能体轨迹与专家轨迹的对齐程度(越高越好)。
实现和骨干网络
训练设置
- 使用单个NVIDIA A100 GPU进行训练。
- 训练分为三个阶段:
- 视觉前端微调:使用ResNet-50主干网络和6层Vision Transformer,对训练全景图进行掩码重建目标的微调,共10个周期。
- 可逆Transformer记忆Token预训练:使用循环一致性损失对合成导航轨迹进行预训练,共5个周期。
- 端到端导航微调:解冻所有模块,进行端到端导航微调,共30个周期。
骨干网络
- 层次化模块化管道:非端到端系统,由大型语言模型生成场景描述,嵌入到稀疏八叉树和语义图中,分层规划器将指令分解为地标、对象和运动子目标,轻量级策略网络融合规划输出和检索记忆以选择动作。
- VELMA:基于提示的LLM智能体,将最近的全景图描述、模板化的地标/交叉口观测和语言化的记忆总结拼接到提示中,自回归地发出下一个导航动作。
- FLAME:多模态LLM,具有步进交叉注意力:将每个全景图编码为补丁标记,关注最近K次观测(增强记忆标记作为额外的键和值),并通过线性头解码四向动作。
主要结果
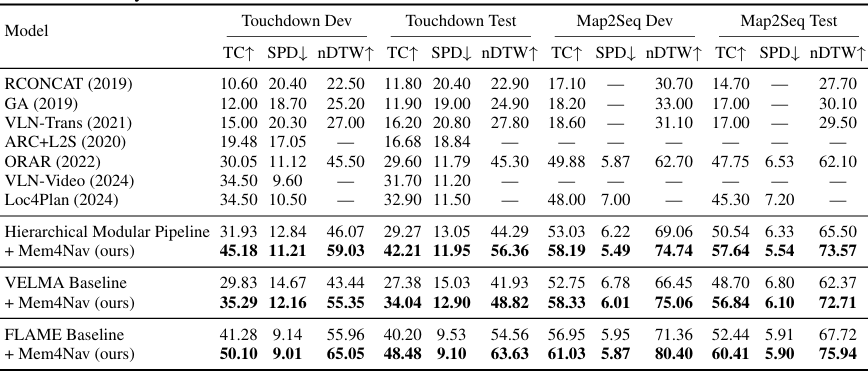
- 性能提升:
- 层次化模块化管道:在Touchdown Dev上,任务完成率(TC)从31.93%提升到45.18%(+13.25个百分点),最短路径距离(SPD)降低了1.63米,归一化动态时间弯曲(nDTW)提升了12.96个百分点。在Touchdown Test和Map2Seq上也有类似的提升。
- VELMA:在Touchdown Dev上,TC提升了5.46个百分点,SPD降低了约2.5米,nDTW提升了超过10个百分点。在Map2Seq Dev上,TC提升了5.14个百分点,nDTW提升了超过10个百分点。
- FLAME:在Touchdown Dev上,TC从41.28%提升到50.10%(+8.82个百分点),SPD降低了0.13米,nDTW提升了9.09个百分点。在Map2Seq Dev上,TC提升了4.08个百分点,nDTW提升了8.08个百分点。
- 结论:Mem4Nav在不同的骨干网络上均实现了显著的性能提升,尤其是在任务完成率和轨迹对齐方面。这表明Mem4Nav能够有效地增强智能体的空间认知和记忆能力,从而提高导航性能。
消融研究
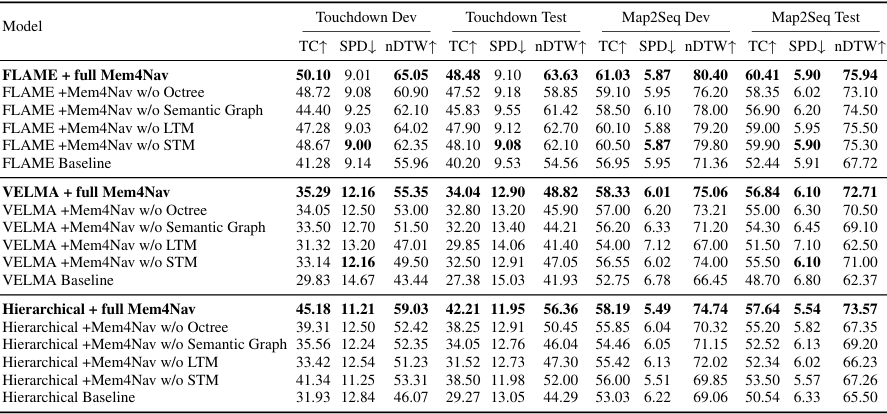
- 消融实验设计:对于每个骨干网络,移除Mem4Nav的一个组件(稀疏八叉树、语义拓扑图、长期记忆Token或短期记忆缓存),并用最小的回退方案替换,以验证每个组件对性能的贡献。
- 结果分析:
- 层次化模块化管道:移除稀疏八叉树会导致TC降低5.87个百分点,nDTW降低6.61个百分点;移除语义图会导致TC降低9.62个百分点,SPD增加1.03米;移除长期记忆会导致TC降低11.76个百分点,SPD增加1.33米;移除短期记忆主要影响nDTW,降低了5.70个百分点。
- VELMA:移除长期记忆会导致TC降低3.97个百分点,SPD增加1.04米;移除短期记忆会导致nDTW降低5.85个百分点。移除稀疏八叉树或语义图对性能的影响较小。
- FLAME:移除可逆Token导致TC降低2.82个百分点;移除稀疏八叉树会导致nDTW降低4.15个百分点;移除语义图会导致TC降低5.70个百分点。
- 结论:消融研究表明,Mem4Nav的每个组件(稀疏八叉树、语义图、长期记忆Token和短期记忆缓存)都对性能提升起到了关键作用。尤其是对于层次化模块化管道,每个组件的移除都会导致显著的性能下降。
结论与未来工作
- 结论:
- Mem4Nav通过将可逆记忆Token嵌入稀疏八叉树和语义拓扑图中,并结合短期记忆缓存,为VLN智能体提供了层次化的空间回忆和适应能力。
- 实验结果表明,Mem4Nav能够在不同的骨干网络上一致地提升导航成功率、减少目标距离并改善轨迹对齐,且每个组件都对性能提升起到了关键作用。
- 未来工作:
- 计划将Mem4Nav扩展到多智能体协调和真实世界的机器人部署中,探索动态城市场景中的自适应记忆巩固和终身学习。
