人工智能——Opencv图像色彩空间转换、灰度实验、图像二值化处理、仿射变化
一、图像色彩空间转换
(一)颜色加法
1、直接相加
1、直接相加
2、调用cv.add()函数进行饱和操作
在OpenCV中进行颜色的加法,我们说图像即数组,所以从数据类型来说我们可以直接用numpy的知识来进行直接相加,但是存在溢出错误。
因为如果直接numpy进行直接相加,会进行取模运算,对256取模,相加后超出的值会又从0开始向上,例如250+10最后的值是4,导致色彩失真
#如果直接numpy进行直接相加,会进行取模运算,对256取模,相加后超出的值会又从0开始向上,例如250+10最后的值是4 dst2=pig+cao #举例子 x=np.uint8([[250]]) y=np.uint8([[10]]) print(x+y) print(cv.add(x,y))
正常进行图像颜色加法时,调用库中的API:饱和操作cv.add(img1,img2) 类型是np.uint8 0~255 例如250+10最后到255就饱和不加了
#饱和操作cv.add(img1,img2) np.uint8 0~255 例如250+10最后只能到255到饱和 dst1=cv.add(pig,cao)

2、颜色加权加法:cv.addWeighted(img1,α,img2,β,,γ)
α、β分别是img1和img2的权重参数
γ是亮度调整值,
γ>0时,整体亮度增加
γ<0时,整体亮度降低
γ=0时,亮度不变
#颜色加权加法 cv.addWeighted(img1,α,img2,β,,γ) 其中γ是亮度调整值,γ>0时,整体亮度增加,γ<0时,整体亮度降低,γ=0时,亮度不变 dst3 =cv.addWeighted(pig,0.7,cao,0.3,0)
(二)色彩空间转换
图像的颜色表示有很多方式,除了RGB外,还有HCV,Gray(灰度)等。
HSV颜色空间使用色调(Hue)、饱和度(Saturation)和亮度(Value)三个参数来表示颜色,色调H表示颜色的种类,如红色、绿色、蓝色等;饱和度表示颜色的纯度或强度,如红色越纯,饱和度就越高;亮度表示颜色的明暗程度,如黑色比白色亮度低
H: 0— 180
S: 0— 255
V: 0— 255
Gray灰度图像在进行二值化处理时需要使用,也经常需要对彩色图像进行转换
cv2.cvtColor:是OpenCV中的一个函数,用于图像颜色空间的转换。可以将一个图像从一个颜色空间转换为另一个颜色空间,比如从RGB到灰度图,或者从RGB到HSV的转换等
语法:cv2.cvtColor(img,code)
img:输入图像
code:指定转换的类型,比如
cv.COLOR_RGB2GRAY表示从rgb到灰度图像的转换cv.COLOR_RGB2HSV表示从GGB图像转换到HSV图像
import cv2 as cv #读取图像 img = cv.imread("../images/1.jpg") cv.imshow("img",img)#颜色转换cv.cvtcolor(img,code) (得到的是一个新的图像数组,所以是有返回值的) #转灰度 gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY) cv.imshow("gray",gray) #转HSV hsv = cv.cvtColor(img,cv.COLOR_BGR2HSV) cv.imshow("hsv",hsv) #转RGB rgb = cv.cvtColor(img,cv.COLOR_BGR2RGB) cv.imshow("rgb",rgb)cv.waitKey(0) cv.destroyAllWindows()
二、灰度实验
灰度图与彩色图最大的不同就是:彩色图是由R、G、B三个通道组成,而灰度图只有一个通道,也称为单通道图像,所以彩色图转成灰度图的过程本质上就是将R、G、B三通道合并成一个通道的过程
(一)最大值法
对于彩色图像的每个像素,它会从R、G、B三个通道的值中选出最大的一个,并将其作为灰度图像中对应位置的像素值
创建的思路:
- 首先需要读取一张图片
- 然后创建一个和图片一样大小的全0的图像用来存储图片中的像素值
- 通过依次遍历行列,然后取到每个像素对应三通道的值,用max小函数取出来赋值给当前像素即可
代码实现:
import cv2 as cv import numpy as npimg = cv.imread('../images/pig.png')#创一个一样大小的全0图像 img1 = np.zeros((img.shape[0],img.shape[1]),dtype=np.uint8)#循环遍历每一行,img[0,0,0] for i in range(img.shape[0]): # 遍历行for j in range(img.shape[1]): # 遍历列img1[i,j]=max(img[i,j,0],img[i,j,1],img[i,j,2]) # 取最大值cv.imshow('img1',img1) cv.waitKey(0) cv.destroyAllWindows()
(二)平均值法
对于彩色图像的每个像素,它会将R、G、B三个通道的像素值全部加起来,然后再除以三,得到的平均值就是灰度图像中对应位置的像素值
方法:
- 读取一张图片
- 创建一样大的全0的图像存放新的像素点
- 依次遍历行列,然后取到每个像素对应三通道的值,加起来整除3(注意,此处取到的三通道的值都是uint8(无符号8为整数,数值范围在0~255)直接这样相加可能存中值溢出,所以我们需要先将读取到的图片转为int类型后再进行相加)
- 最后再把计算得到的int类型的通道值转为uint8
代码实现:
import cv2 as cv import numpy as npimg = cv.imread('../images/pig.png')#创一个一样大小的全0图像 img1 = np.zeros((img.shape[0],img.shape[1]),dtype=np.uint8)#循环遍历每一行,img[0,0,0] for i in range(img.shape[0]): # 遍历行for j in range(img.shape[1]): # 遍历列#为什么要先转换为int类型呢?因为图像数组通常都是uint8(无符号 8 位整数)取值范围是 0 - 255,# 三个数直接相加可能会溢出,所以需要转为int有符号的整数避免溢出,再用np.uint8给转回来#//3 整除3是因为我们的像素值的通道都是整数img1[i,j]=np.uint8((int(img[i,j,0])+int(img[i,j,1])+int(img[i,j,2]))//3)cv.imshow('img1',img1) cv.waitKey(0) cv.destroyAllWindows()
(三 )加权平均值法
对于彩色图像的每个像素,它会按照一定的权重去乘以每个通道的像素值,并将其相加,得到最后的值就是灰度图像中对应位置的像素值
权重可以自行设定,所使用的权重之和应该等于1,方法与平均值法相似只是多了
- 读取一张图片
- 创建一样大的全0的图像存放新的像素点
- 依次遍历行列,然后取到每个像素对应三通道的值,加起来整除3(注意,此处和权重相乘后通常会出现小数,但像素值又只能为整数,系统会自动向下或向上取整,为了让结果更准确,所以会用round()函数进行四舍五入)
- 最后再把计算得到的int类型的通道值转为uint8
代码实现:
import cv2 as cv import numpy as npimg = cv.imread('../images/pig.png')#创一个一样大小的全0图像 img1 = np.zeros((img.shape[0],img.shape[1]),dtype=np.uint8)# 定义权重 wb,wg,wr = 0.114,0.587,0.299#循环遍历每一行,img[0,0,0] for i in range(img.shape[0]): # 遍历行for j in range(img.shape[1]): # 遍历列#为什么要先转换为int类型呢?因为图像数组通常都是uint8(无符号 8 位整数)取值范围是 0 - 255,# 三个数直接相加可能会溢出,所以需要转为int有符号的整数避免溢出,再用np.uint8给转回来#//3 整除3是因为我们的像素值的通道都是整数#round()四舍五入img1[i,j]=np.uint8(round(wb*img[i,j,0]+wg*img[i,j,1]+wr*img[i,j,2])//3)cv.imshow('img1',img1) cv.waitKey(0) cv.destroyAllWindows()
三、图像二值化处理
二值图像的二维矩阵仅由0、1两个值构成,“0”代表黑色,“1”代白色(也就是255的值),其操作的图像是必须是灰度图
(一)全局阈值法
语法:_,binary = cv2.threshold(img,thresh,maxval,type)
img:输入图像,要进行二值化处理的灰度图。
thresh:设定的阈值。当像素值大于(或小于,取决于阈值类型)thresh时,该像素被赋予的值。包括:
type:阈值处理的类型,
阈值法:cv.threshold(img, thresh, max_value, cv.THRESH_BINARY)
反阈值法:cv.threshold(img, thresh, max_value, cv.THRESH_BINARY_INV)
截断阈值法:cv.threshold(img, thresh, max_value, cv.THRESH_TRUNC)
低阈值零处理法:cv.threshold(img, thresh, max_value, cv.THRESH_TOZERO)
超阈值零处理法cv.threshold(img, thresh, max_value, cv.THRESH_TOZERO_INV)
OTSU阈值法:cv.threshold(img, thresh, max_value, cv.THRESH_OSTU)或cv.threshold(img, thresh, max_value, cv.THRESH_OSTU_INV)
返回值:
第一个值(通常用下划线表示):计算出的阈值,若使用自适应阈值法,会根据算法自动计算出这个值。
第二个值(binary):二值化后的图像矩阵。与输入图像尺寸相同。
阈值法:通过设置一个阈值,将灰度图中的每一个像素值与该阈值进行比较,小于等于阈值的像素就被设置为0(通常代表背景),大于阈值的像素就被设置为maxval(通常代表前景)
反阈值法:与阈值法相反。反阈值法是当灰度图的像素值大于阈值时,该像素值将会变成0(黑),当灰度图的像素值小于等于阈值时,该像素值将会变成maxval。
截断阈值法:将灰度图中的所有像素与阈值进行比较,像素值大于阈值的部分将会被修改为阈值,小于等于阈值的部分不变
低阈值零处理:字面意思,就是像素值小于等于阈值的部分被置为0,大于阈值的部分不变
超阈值零处理:将灰度图中的每个像素与阈值进行比较,像素值大于阈值的部分置为0(也就是黑色),像素值小于等于阈值的部分不变。
OSTU阈值法:OSTU阈值法 并不是一个有效的阈值类型,THRESH_OTSU 本身并不是一个独立的阈值化方法,通常与 THRESH_BINARY 或 THRESH_BINARY_INV 结合使用 默认情况下它会与 `THRESH_BINARY` 结合使用。也就是说,当你仅指定了 `cv2.THRESH_OTSU`,实际上等同于同时指定了 `cv2.THRESH_BINARY + cv2.THRESH_OTSU`
OSTU 阈值法是一种基于图像灰度直方图统计特性的阈值确定方法,目的是将图像分为前景和背景两部分,使得分割后的两类之间的差异最大,也就是让类间方差最大,从而找到一个最佳的阈值来实现二值化
遍历所有可能的阈值,将设当前阈值为t,遍历t到最大像素值减1,分别计算每个t对应的类间方差,使得类间方差值最大的那个t值就是OSTU算法所确定的最佳阈值,将图像中灰度值小于等于这个阈值的像素设置为
0(黑色,代表背景),大于这个阈值的像素设置为255(白色,代表前景),就完成了基于 OSTU 阈值法的二值化处理。
代码实现:
import cv2 as cvflower = cv.imread('../images/flower.png')
# 读取灰色图像
# flower1 = cv.imread('../images/flower.png',0)#h灰度化处理
flower1 = cv.cvtColor(flower,cv.COLOR_BGR2GRAY)
flower1 = cv.resize(flower1,(360,360))
cv.imshow('flower1',flower1)#二值化,阈值法
_,binary = cv.threshold(flower1,127,255,cv.THRESH_BINARY)
cv.imshow('binary',binary)# 反阈值法,为什么前面用下划线,因为此处返回的值是thresh,本身就是我们传的参数,所以没必要接收,就可以用下划线占位
_,binary_inv = cv.threshold(flower1,127,255,cv.THRESH_BINARY_INV)
cv.imshow('binary_inv',binary_inv)#截断阈值法
_,binary_trunc= cv.threshold(flower1,180,255,cv.THRESH_TRUNC)
cv.imshow('binary_trunc',binary_trunc)#低阈值0处理
_,binary_zero =cv.threshold(flower1,127,255,cv.THRESH_TOZERO)
cv.imshow('binary_zero',binary_zero)#超阈值0处理
_,binary_zero_inv =cv.threshold(flower1,127,255,cv.THRESH_TOZERO_INV)
cv.imshow('binary_zero_inv',binary_zero_inv)#OTSU阈值法 默认结合了cv.THRESH_BINARY THRESH_BINARY=THRESH_BINARY+THRESH_OTSU
thresh1,otsu=cv.threshold(flower1,200,255,cv.THRESH_OTSU)
cv.imshow('otsu',otsu)
print(thresh1)
# otsu阈值结合反阈值法
thresh2,otsu_inv = cv.threshold(flower1,200,255,cv.THRESH_BINARY_INV+cv.THRESH_OTSU)
cv.imshow('otsu_inv',otsu_inv)
print(thresh2)#自适应二值化,小区域计算
#取均值
auto_mean =cv.adaptiveThreshold(flower1,255,cv.ADAPTIVE_THRESH_MEAN_C,cv.THRESH_BINARY,11,2)
cv.imshow('auto_mean',auto_mean)
#高斯加权法
auto_gauss = cv.adaptiveThreshold(flower1,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,cv.THRESH_BINARY,11,2)
cv.imshow('auto_gauss',auto_gauss)#显示效果
cv.waitKey(0)
cv.destroyAllWindows()四、图像翻转和仿射变换
1、图像的镜像翻转:
在OpenCV中,图片的镜像旋转是以图像的中心为原点进行镜像翻转的
- cv2.flip(img,flipcode)**
- 参数
- img: 要翻转的图像
- flipcode: 指定翻转类型的标志
- flipcode=0: 垂直翻转,图片像素点沿x轴翻转
- flipcode>0: 水平翻转,图片像素点沿y轴翻转
- flipcode<0: 水平垂直翻转,水平翻转和垂直翻转的结合import cv2 as cv face= cv.imread('../images/face.png') cv.imshow('face',face) #翻转镜像旋转,以图像的中心为原点cv.flip(img,flipcode) #flipcode=0:垂直翻转 沿x轴上下翻转 flip_0 = cv.flip(face,0) cv.imshow('flip_0',flip_0)#flipcode>0:沿y轴水平翻转(左右翻转) flip_1 = cv.flip(face,1) cv.imshow('flip_1',flip_1)#flipcode<0:沿xy轴同时翻转(垂直水平都翻转) flip_2 = cv.flip(face,-1) cv.imshow('flip_2',flip_2)cv.waitKey(0) cv.destroyAllWindows()
2、仿射变换:
仿射变换(Affine Transformation)是一种线性变换,保持了点之间的相对距离不变。
仿射变换的基本性质:
保持直线
保持平行
比例不变性
不保持角度和长度常见的仿射变换类型:旋转,平移,缩放,剪切
对于仿射变换,最重要的一步是获得变换矩阵,通过变换矩阵是的目标点变换到预定位置
原理:
对于 2D 图像,任意像素点的坐标可以表示为齐次坐标形式
(x, y, 1)(增加维度便于统一处理平移)。仿射变换矩阵M是一个3×3的矩阵实际使用中常简化为2×3,通过补全最后一行[0,0,1]变为齐次矩阵)
原像素点
(x, y)经过矩阵M变换后,得到新像素点(x', y'),计算公式为:
展开后
此处的思维是我们再思考的时候进行的正向思考,通过变换矩阵得到变换后的像素点对应的值。
实际在图像变换中,,我们通常需要根据目标图像的像素点
(x', y')反推它在原图像中的对应像素点(x, y),这一过程称为 “逆变换当我们对图像进行旋转得到新图像后,新图像中某个像素
(x', y')的颜色,实际上来自原图像中某个像素(x, y)的颜色。为了准确填充新图像的像素值,必须找到(x', y')对应的(x, y)。此时,就需要通过仿射矩阵
M的逆矩阵M^{-1}来实现反推,通过逆矩阵来求解原像素点变换过程:
已知目标像素
(x', y'),通过逆矩阵M^{-1}求解原像素(x, y)
展开后:其中
(a', b', c', d', e', f')是逆矩阵的元素
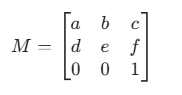

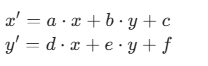
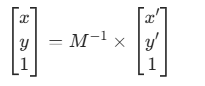
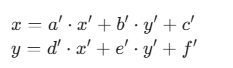
在 OpenCV 的 warpAffine 等变换函数中,内部会自动通过逆矩阵计算:
- 遍历目标图像的每个像素
(x', y'); - 用逆矩阵
M^{-1}计算其在原图像中的对应点(x, y); - 取原图像
(x, y)的像素值,赋给目标图像的(x', y')
仿射变换函数:
cv2.warpAffine(img,M,dsize)img:输入图像。
M:2x3的变换矩阵,类型为np.float32。
-dsize:输出图像的尺寸,形式为(width,height)
在实际运用时,最主要的是得到变换矩阵
图像旋转:
首先利用cv2.getRotationMatrix2D()函数得到旋转矩阵:
cv2.getRotationMatrix2D(center,angle,scale)
- center:旋转中心点的坐标,格式为`(x,y)`。
- angle:旋转角度,单位为度,正值表示逆时针旋转负值表示顺时针旋转。
- scale:缩放比例,若设为1,则不缩放。
- 返回值:M,2x3的旋转矩阵。
import cv2 as cv #读图 cat = cv.imread("../images/1.jpg")#获取旋转矩阵 cv2.getRotationMatrix20(center,angle,scale) M = cv.getRotationMatrix2D((200,300),30,1) print(M)cat = cv.warpAffine(cat,M,(640,580)) cv.imshow("cat",cat)cv.waitKey(0) cv.destroyAllWindows()
图像平移:
移操作可以将图像中的每个点沿着某个方向移动一定的距离
假设我们有一个点 P(x,y),希望将其沿x轴方向平移t_x个单位,沿y轴方向平移t_y个单位到新的位置P′(x′,y′),那么平移公式如下:
x′=x+tx
y′=y+ty
在矩阵形式下,该变换可以表示为:
import cv2 as cv import numpy as np #读图 cat = cv.imread("../images/1.jpg")#定义平移量 tx=80 ty=120#定义平移矩阵 M = np.float32([[1,0,tx],[0,1,ty]])#仿射变换的API cat = cv.warpAffine(cat,M,(1000,1000)) cv.imshow("cat",cat)cv.waitKey(0) cv.destroyAllWindows()
图像缩放
假设要把图像的宽高分别缩放为0.5和0.8,那么对应的缩放因子sx=0.5,sy=0.8。
点$P(x,y)$对应到新的位置P'(x',y'),缩放公式为:
x′=s_x*x
y′=s_y*y
在矩阵形式下,该变换可以表示为
import cv2 as cv import numpy as np #读图 cat = cv.imread("../images/1.jpg")#定义缩放因子 sx=0.8 sy=0.5#定义缩放矩阵,最后一列是平移量 M = np.float32([[sx,0,0],[0,sy,0]])#仿射变换的API cat = cv.warpAffine(cat,M,(1000,1000)) cv.imshow("cat",cat)cv.waitKey(0) cv.destroyAllWindows()