分布式数据库中间件ShardingSphere
数据库中间件ShardingSphere
介绍
Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
解决问题
主要适用于解决“读写分离”和“数据分片”架构。
《阿里巴巴开发手册》单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
读写分离(分散数据库的读写压力)
读写分离原理:读写分离的基本原理是将数据库读写操作分散到不同的节点上,从而缓解服务器压力,提高服务器吞吐量。
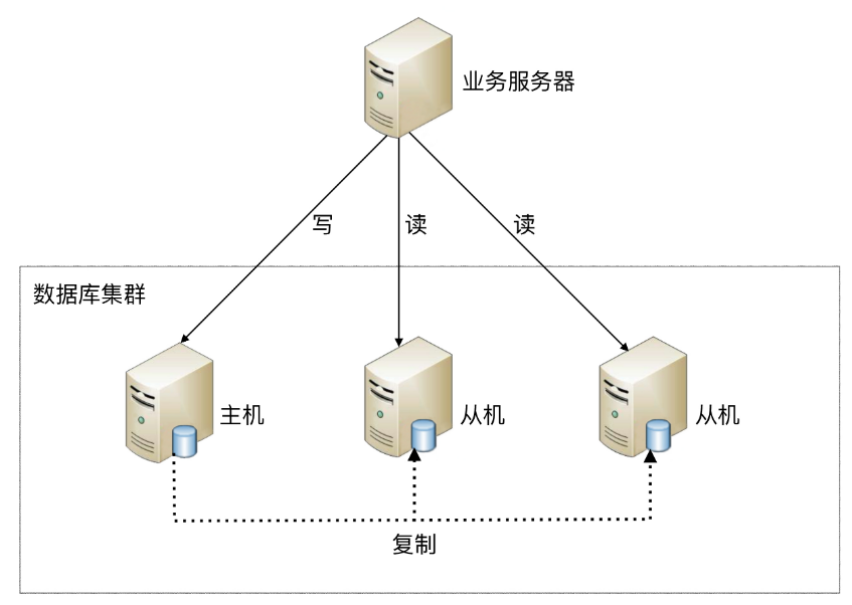
读写分离的基本实现:
-
主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
-
读写分离是根据 SQL 语义的分析,将写操作和读操作分别路由至主库与从库。
-
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。
-
使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
CAP 理论:
CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer's theorem),是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年的 ACM PODC 上提出的一个猜想。对于设计分布式系统的架构师来说,CAP 是必须掌握的理论。
在一个分布式系统中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
-
C 一致性(Consistency):对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
-
A 可用性(Availability):非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
-
P 分区容忍性(Partition Tolerance):当出现网络分区后(可能是丢包,也可能是连接中断,还可能是拥塞),系统能够继续“履行职责”
CAP特点:
-
在实际设计过程中,每个系统不可能只处理一种数据,而是包含多种类型的数据,有的数据必须选择 CP,有的数据必须选择 AP,分布式系统理论上不可能选择 CA 架构。
-
CP:为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 需要返回 Error,提示客户端 “系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
-
AP:为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。
CAP 理论中的 C 在实践中是不可能完美实现的,在数据复制的过程中,节点N1 和节点 N2 的数据并不一致(强一致性)。即使无法做到强一致性,但应用可以采用适合的方式达到最终一致性。具有如下特点:
-
基本可用(Basically Available):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
-
软状态(Soft State):允许系统存在中间状态,而该中间状态不会影响系统整体可用性。这里的中间状态就是 CAP 理论中的数据不一致。
-
最终一致性(Eventual Consistency):系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
数据分片(分散数据库的存储压力)
数据分片原理:将存放在单一数据库中的数据分散地存放至多个数据库或表中,以达到提升性能瓶颈以及可用性的效果。 数据分片有效手段是对关系型数据库进行分库和分表。数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
垂直分库:根据业务将数据库进行划分,主要理念是专库专用。在拆分之前一个数据库是由多个表组成,拆分后将多个表根据业务类型分别存储在不同的数据库里,就是专库专用。
垂直分表:主要是将数据库中不常用的字段分离出来,放在另一个表中。这样可以在查询常用字段时速度得到同生,但是会导致整个数据库的表数量增加,同时在查询非常用字段时变得更加复杂。
水平分片
水平分库:相对于垂直分库,不再根据业务进行拆分,而是根据某字段的特征进行拆分,如奇数、偶数来拆分开。
如一台服务器无法满足性能需求,则需要进行分库。
水平分表:跟上述相同,如果一台服务器可以满足业务需求,就不要分到不同服务器上,可以避免复杂性。
实现方式
读写分离和数据分片具体的实现方式一般有两种: 程序代码封装和中间件封装。
ShardingSphere实现
ShardingSphere-JDBC读写分离
-
依赖添加
-
配置读写分离
# 应用名称 spring:application:name: sharging-jdbc-demo# 开发环境设置profiles:active: devshardingsphere:mode:type: Memory # 配置真实数据源 datasource:names: master,slave1,slave2 # 配置第 1 个数据源master:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://192.168.100.201:3306/db_userusername: rootpassword: 123456 # 配置第 2 个数据源slave1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://192.168.100.201:3307/db_userusername: rootpassword: 123456 # 配置第 3 个数据源slave2:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://192.168.100.201:3308/db_userusername: rootpassword: 123456 # 读写分离规则 rules:readwrite-splitting:data-sources:myds:type: Static #静态Static或者动态Dynamicprops:write-data-source-name: master #数据源名称read-data-source-names: slave1,slave2 #多数据源用,隔开load-balancer-name: alg_round #负载均衡算法名称 # 负载均衡算法配置load-balancers:alg_round: #轮询算法type: ROUND_ROBIN alg_random: #随机算法type: RANDOM alg_weight: #权重算法type: WEIGHTprops:slave1: 1slave2: 2 # 全局属性打印sql日志 props:sql-show: true
-
事务设置
为了保证主从库间的事务一致性,避免跨服务的分布式事务,ShardingSphere-JDBC的主从模型中,事务中的数据读写均用主库。
-
不添加@Transactional:insert对主库操作,select对从库操作。
-
添加@Transactional:则insert和select均对主库操作。
-
注意:在JUnit环境下的@Transactional注解,默认情况下就会对事务进行回滚(即使在没加注解@Rollback,也会对事务回滚)。
ShardingSphere-JDBC垂直分片
配置垂直分片
# 应用名称 spring:application:name: sharding-jdbc-demo# 环境设置profiles:active: devshardingsphere:# 配置真实数据源datasource:names: server-user,server-order# 配置第 1 个数据源server-user:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://192.168.100.201:3301/db_userusername: rootpassword: 123456 # 配置第 2 个数据源server-order:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://192.168.100.201:3302/db_orderusername: rootpassword: 123456 # 标准分片表配置(数据节点) rules:sharding:tables:t_user:actual-data-nodes: server-user.t_usert_order:actual-data-nodes: server-order.t_order # 打印 SQL props:sql-show: true
ShardingSphere-JDBC水平分片
配置水平分片
# 应用名称
spring:application:name: sharging-jdbc-demo# 开发环境设置profiles:active: dev
shardingsphere:# 内存模式mode:type: Memory
# 打印 SQL
props:sql-show: true
# 配置真实数据源
datasource:names: server-user,server-order0,server-order1
# 配置第 1 个数据源server-user:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://192.168.100.201:3301/db_userusername: rootpassword: 123456
# 配置第 2 个数据源server-order0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://192.168.100.201:3310/db_orderusername: rootpassword: 123456
# 配置第 3 个数据源server-order1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://192.168.100.201:3311/db_orderusername: rootpassword: 123456
# 分片规则
rules:sharding:tables:t_user:actual-data-nodes: server-user.t_usert_order:actual-data-nodes: server-order0.t_order0,server-order0.t_order1,server-order1.t_order0,server-order1.t_order1
# 值由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
# 分库策略
spring:shardingsphere:rules:sharding:tables:t_order:database-strategy:standard:# 分片列名称sharding-column: user_id# 分片算法名称sharding-algorithm-name: alg_inline_userid
# 分片算法配置sharding-algorithms:alg_inline_userid:type: INLINEprops:algorithm-expression: server-order$->{user_id % 2}
alg_mod:type: MODprops:sharding-count: 2
SQL执行原理
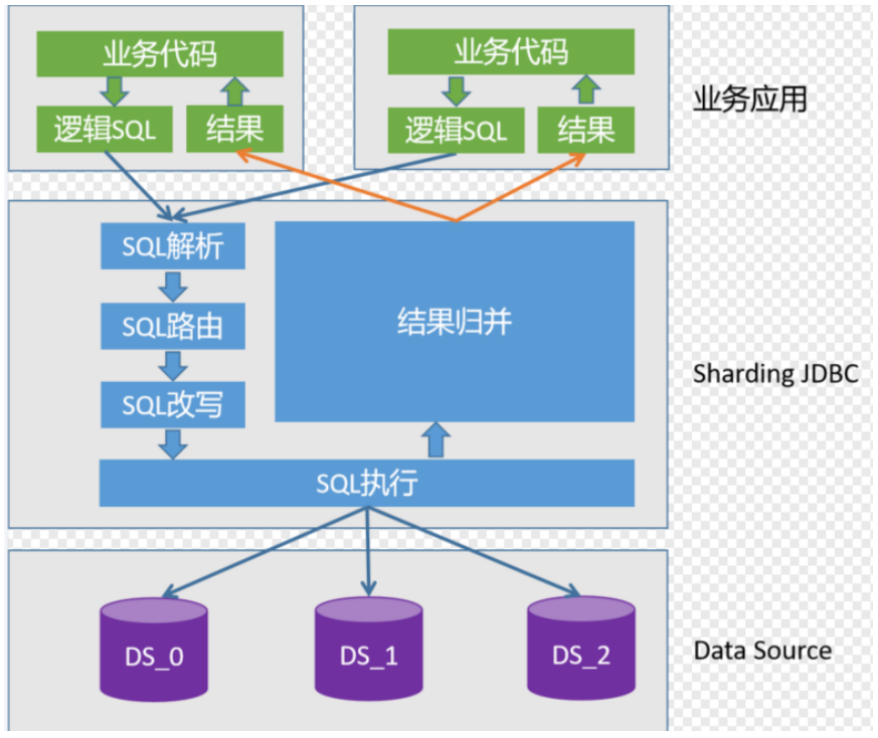
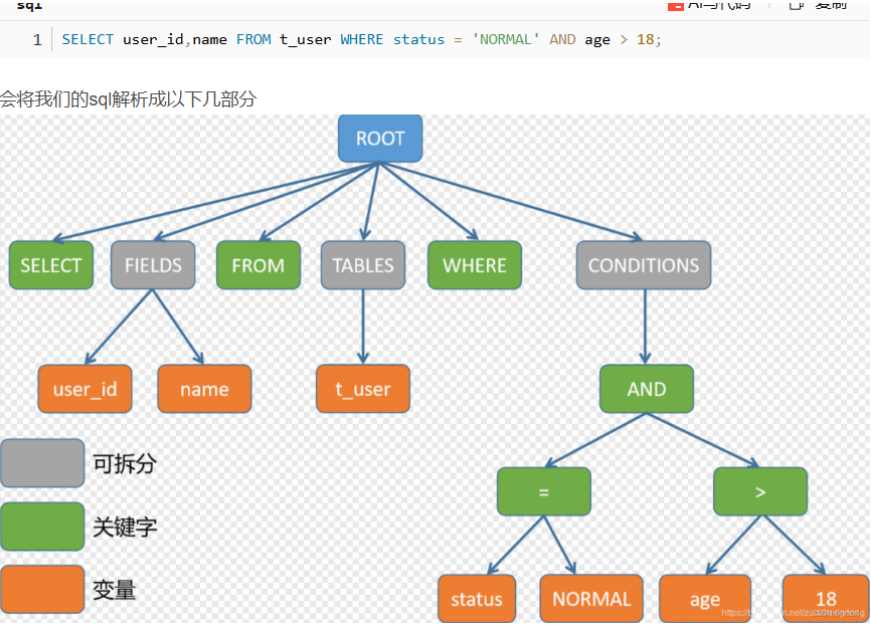
1.SQL解析
查询时,查询的不是真实的数据库,Sharding会根据我们的关键字位置改写我们的SQL语句,使其能查询到真正的数据库。
2.SQL路由
主要起一个映射的作用,将我们的逻辑sql操作映射到真正的数据节点的操作。根据解析上下文匹配数据库和表的分片策略,并生成路由路径。
根据分片键进行路由的场景可分为直接路由、标准路由、笛卡尔路由等。
标准路由
适用于不包含关联查询或仅包含绑定表之间关系的路由,把sql拆分成多条用于执行的真实sql。
笛卡尔路由
无法根据绑定表的关系定位分片规则,因此非绑定表之间的关联查询需要拆解为笛卡尔积组合执行。
全库表路由: 对于不携带分片键的SQL,则采取广播路由的方式。根据SQL类型又可以划分为全库表路由、全库路由、全实例路由、单播路由和阻断路由这5种类型。其中全库表路由用于处理对数据库中与其逻辑表相关的所有真实表的操作,主要包括不带分片键的DQL(数据查询)和DML(数据操纵),以及DDL(数据定义)等。
3.SQL改写
因为我们在开发过程中面向逻辑表书写的SQL并不能够直接在真实的数据库中执行,需要将逻辑SQL改写为能在真实数据库中可以正确执行的SQL。
4.SQL执行
Sharding-JDBC采用一套自动化的执行引擎,负责将路由和改写完成之后的真实SQL安全且高效发送到底层数据源执行。 它不是简单地将SQL通过JDBC直接发送至数据源执行,也不是直接将执行请求放入线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题。 执行引擎的目标是自动化的平衡资源控制与执行效率,他能在以下两种模式自适应切换:
内存限制模式: 使用此模式的前提是, Sharding-JDBC对一次操作所耗费的数据库连接数量不做限制。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,则对每张表创建一个新的数据库连接,并通过多线程的方式并发处理,以达成执行效率最大化。
连接限制模式: 使用此模式的前提是,Sharding-JDBC对一次操作所耗费的数据库连接数量严格控制。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,那么只会创建唯一的数据库连接,并对其200张表串行处理。 如果一次操作中的分片散落在不同的数据库,仍然采用多线程处理对不同库的操作,但每个库的每次操作仍然只创建一个唯一的数据库连接。
内存限制模式适用于OLAP操作(面向事务,事务不可能弄多线程。),可以通过放宽对数据库连接的限制提升系统吞吐量; 连接限制模式适用于OLTP操作,OLTP通常带有分片键,会路由到单一的分片,因此严格控制数据库连接,以保证在线系统数据库资源能够被更多的应用所使用,是明智的选择。
5.结果归并
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
结果归并从功能划分可分为:遍历、排序、分组、分页和 聚合 5种类型,它们是组合而非互斥的关系。
遍历归并
它是最为简单的归并方式。 只需将多个数据结果集合并为一个单向链表即可
排序归并
由于在SQL中存在ORDER BY语句,因此每个数据结果集自身是有序的,因此只需要将数据结果集当前游标指向的数据值进行排序即可。
聚合归并
无论是流式分组归并还是内存分组归并,对聚合函数的处理都是一致的。 除了分组的SQL之外,不进行分组的SQL也可以使用聚合函数。 因此,聚合归并是在之前介绍的归并类的之上追加的归并能力,即装饰者模式。聚合函数可以归类为比较、累加和求平均值这3种类型。
内存归并
很容易理解,他是将所有分片结果集的数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等计算之后,再将其封装成为逐条访问的数据结果集返回。
流式归并
是指每一次从数据库结果集中获取到的数据,都能够通过游标逐条获取的方式返回正确的单条数据,它与数据库原生的返回结果集的方式最为契合。遍历、排序以及流式分组都属于流式归并的一种。
原文链接:ShardingSphere数据库中间件基础学习_shardingsphere 默认数据源-CSDN博客