Protobuf学习
Protobuf:
使用特点:protobuf是要依赖通过编译生成的头文件和源文件来使用的。
编写 .proto ⽂件,⽬的是为了定义结构对象(message)及属性内容。
使⽤ protoc 编译器编译 .proto ⽂件,⽣成⼀系列接⼝代码(用来操作message内部字段的接口),存放在新⽣成头⽂件和源⽂件中。
依赖⽣成的接⼝,将编译⽣成的头⽂件包含进我们的代码中,实现对 .proto ⽂件中定义的字段进⾏设置和获取,和对 message 对象进⾏序列化和反序列化。
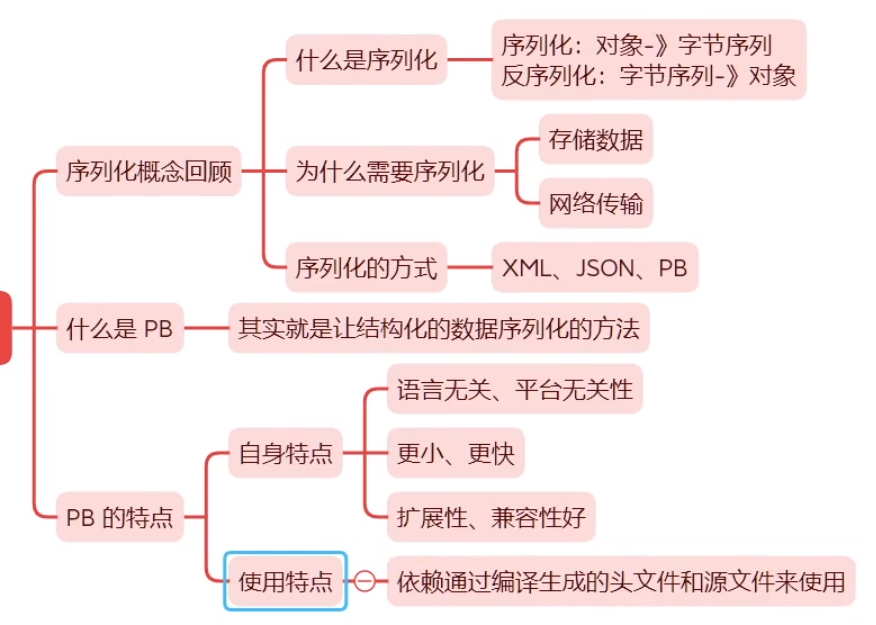
字段唯⼀编号的范围: 1 ~ 536,870,911 (2^29 - 1) ,其中 19000 ~ 19999 不可⽤。
19000 ~ 19999 不可⽤是因为:在 Protobuf 协议的实现中,对这些数进⾏了预留。如果⾮要在.proto ⽂件中使⽤这些预留标识号,例如将 name 字段的编号设置为19000,编译时就会报警。
例如:对proto文件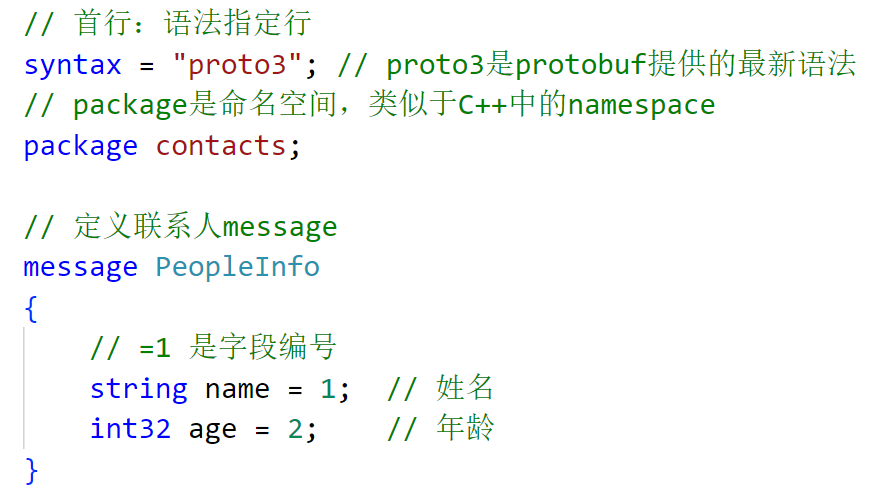
进行编译:protoc --cpp_out=. contacts.proto;就会生成依赖的头文件和源文件contacts.pb.cc和contacts.pb.h。
在contacts.pb.h中就会生成对应字段的操作方法还有序列化和反序列化接口。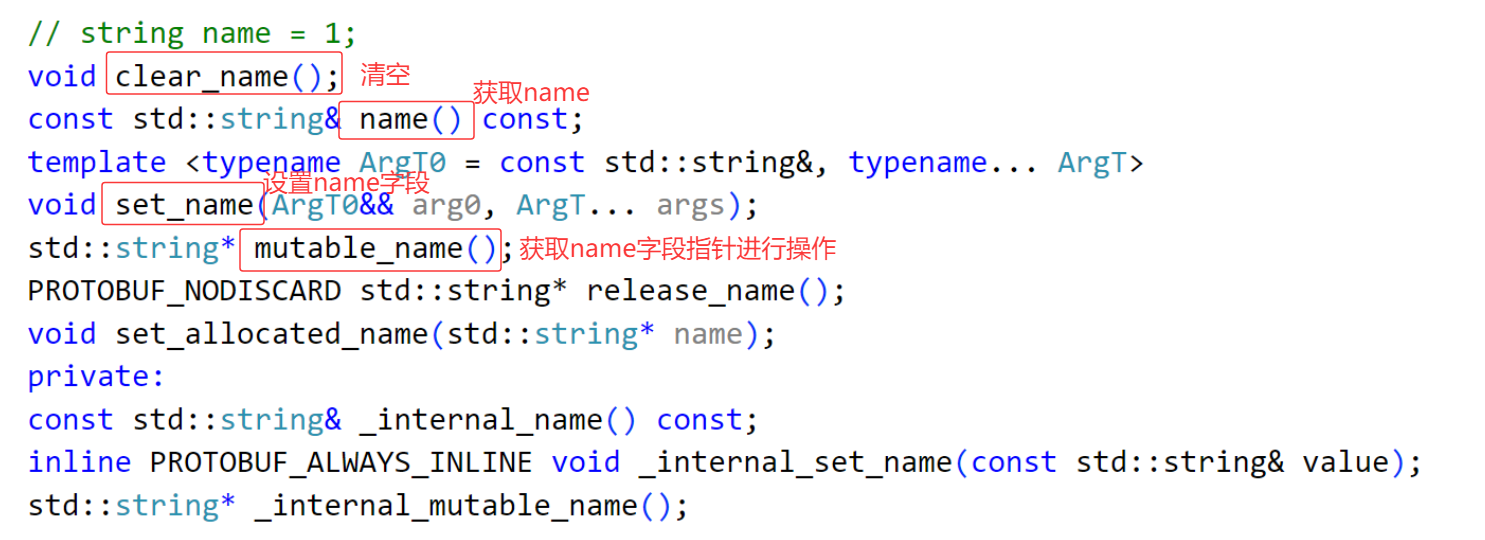
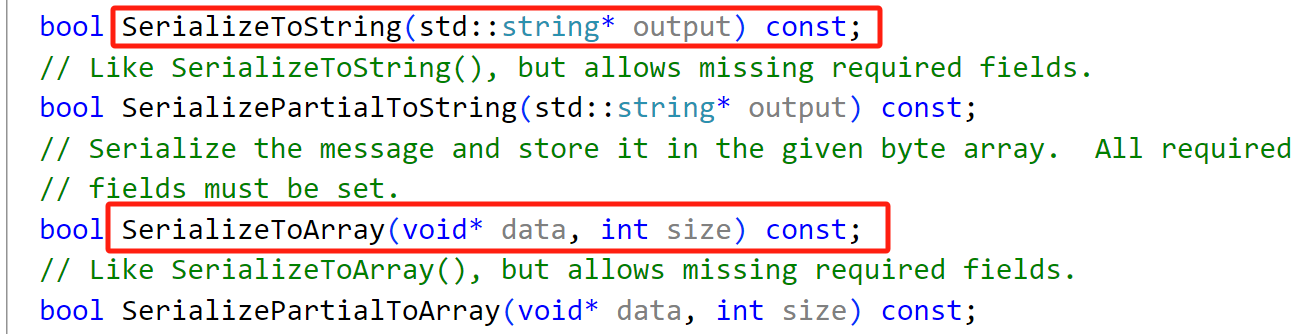

序列化的结果为⼆进制字节序列,而非文本格式。
下面测试一下:
对⼀个联系⼈的信息使⽤ PB 进⾏序列化,并将结果打印出来。 然后对序列化后的内容使⽤ PB 进⾏反序列,解析出联系⼈信息并打印出来。
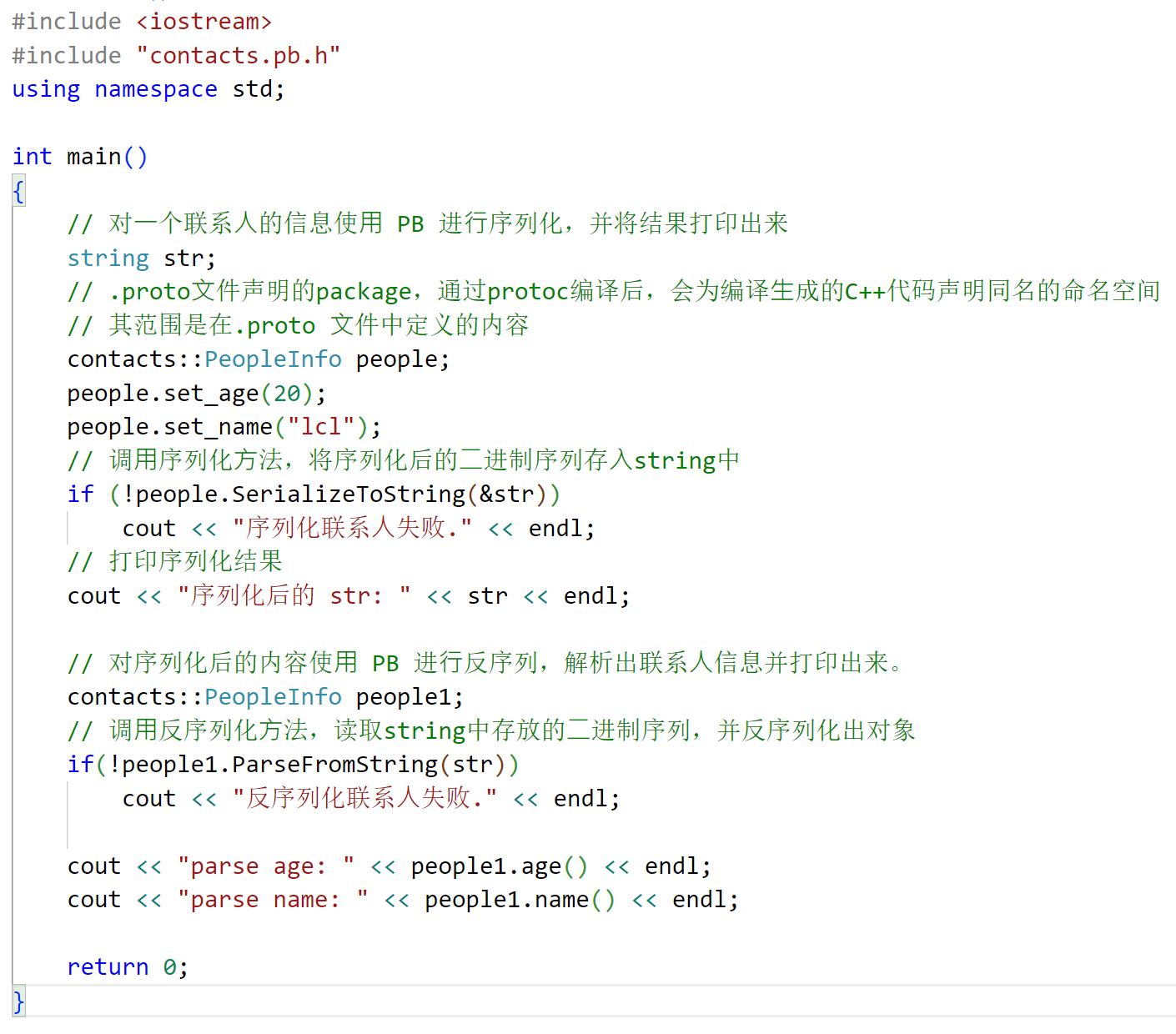
进行编译:g++ main.cc contacts.pb.cc -o TestProtoBuf -std=c++11 -lprotobuf

由于 ProtoBuf 是把联系⼈对象序列化成了⼆进制序列,这⾥⽤ string 来作为接收⼆进制序列的容器。 所以在终端打印的时候会有换⾏等⼀些乱码显⽰。 所以相对于 xml 和 JSON 来说,因为被编码成⼆进制,破解成本增⼤,ProtoBuf 编码是相对安全的。
下面对上面的.proto进行改进,写成一个通讯录:

新增了一个Phone的message,在每一个用户中对Phone用repeated修饰,表示是数组类型,最终多个用户信息构成通讯录。
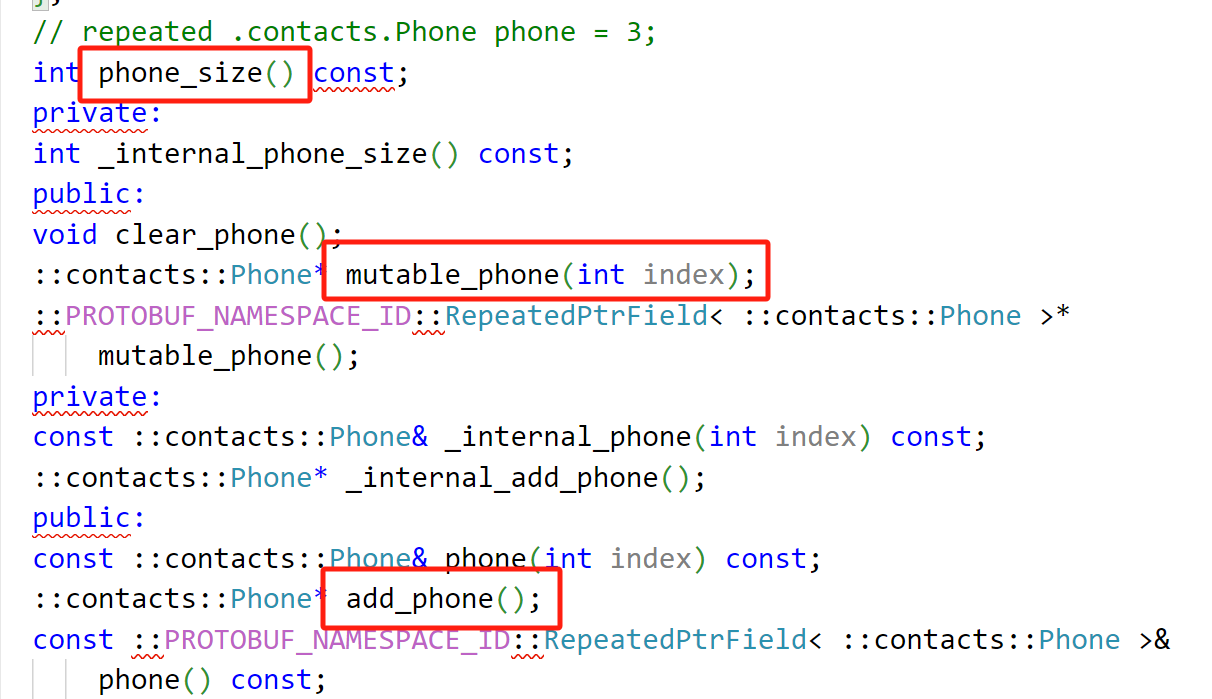
对于使用 repeated 修饰的字段,也就是数组类型,pb 为我们提供了 add_ 方法来新增⼀个值, 并且提供了 _size 方法来判断数组存放元素的个数。
升级测试:
write:将通讯录序列化后写入文件,不是打印;
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;void AddPeopleInfo(contacts::PeopleInfo *people)
{cout << "-------------新增联系⼈-------------" << endl;cout << "请输入联系人姓名:";string name;getline(cin, name);people->set_name(name);cout << "请输入联系人年龄:";int age;cin >> age;people->set_age(age);// 清除输入缓冲区的内容,当遇到\n停止清除,即清除掉\n前面的内容// 若一直清除到256个字符还没有遇到\n也停止清除cin.ignore(256, '\n');for (int i = 0; ; i++){cout << "请输入联系人电话" << i + 1 << "(只输⼊回⻋完成电话新增):";string number;getline(cin, number);if (number.empty()){break;}contacts::Phone *phone = people->add_phone();phone->set_number(number);}cout << "-----------添加联系⼈成功-----------" << endl;
}int main()
{contacts::Contacts contacts;// 读取本地已存在的通讯录文件fstream input("contacts.bin", ios::in | ios::binary);if (!input){cout << "contacts.bin not find, create new file!" << endl;}else if (!contacts.ParseFromIstream(&input)){cerr << "parse error!" << endl;input.close();return -1;}// 向通讯录中添加一个联系人AddPeopleInfo(contacts.add_contacts());// 将通讯录写入本地文件中fstream output("contacts.bin", ios::out | ios::trunc | ios::binary);if (!contacts.SerializeToOstream(&output)){cerr << "write error!" << endl;input.close();output.close();return -1;}cout << "write success!" << endl;input.close();output.close();return 0;
}编译运行:
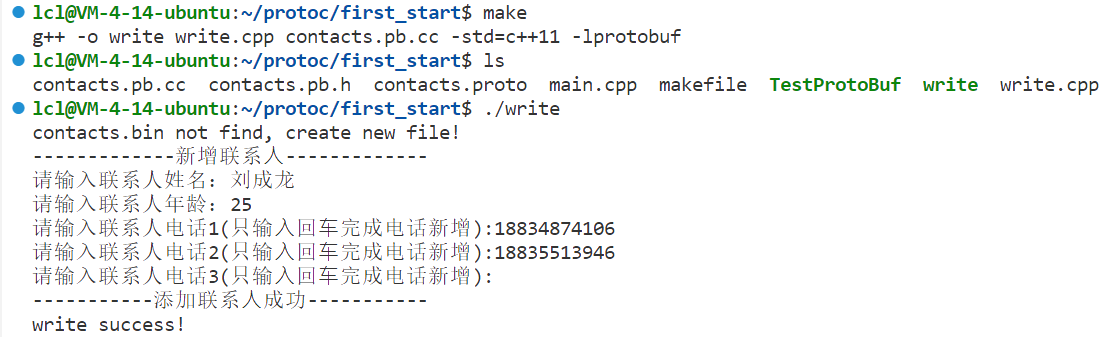
在目标文件中就会有对应的信息:
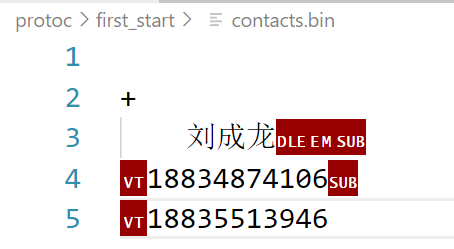
因为是二进制写入,所以有乱码情况。上面代码中就使用到了protobuf生成的依赖文件所提供的操作字段的方法,如:set_name、set_age、add_phone、add_contacts等。
read:对通讯录进行反序列化,得到联系人信息,进行打印:
#include <iostream>
#include <fstream>
#include "contacts.pb.h"using namespace std;void PrintContacts(contacts::Contacts &contacts)
{for (int i = 0; i < contacts.contacts_size(); i++){cout << "---------------联系人" << i + 1 << "---------------" << endl;const contacts::PeopleInfo &people = contacts.contacts(i);cout << "联系人姓名:" << people.name() << endl;cout << "联系人年龄:" << people.age() << endl;for (int j = 0; j < people.phone_size(); j++){const contacts::Phone &phone = people.phone(j);cout << "联系人电话" << j + 1 << ":" << phone.number();}}
}
int main()
{contacts::Contacts contacts;// 读取本地已存在的通讯录文件fstream input("contacts.bin", ios::in | ios::binary);if (!contacts.ParseFromIstream(&input)){cerr << "parse error!" << endl;input.close();return -1;}// 打印通讯录列表PrintContacts(contacts);return 0;
}编译运行后:
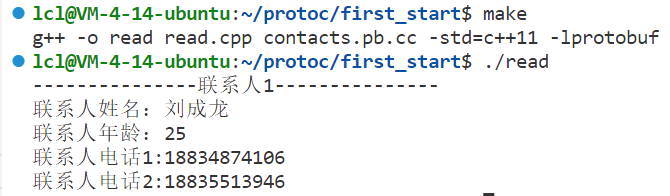
前面保存的联系人信息就打印出来了。上面代码中的contacts.contacts_size()、people.name()、const contacts::Phone &phone = people.phone(j)等都是protobuf生成的依赖中提供的操作方法。
枚举类型enum:
在.proto⽂件中枚举类型的书写规范为:
枚举类型名称: 使⽤驼峰命名法,⾸字⺟⼤写。 例如: MyEnum
常量值名称: 全⼤写字⺟,多个字⺟之间⽤ _ 连接。例如: ENUM_CONST = 0;
要注意枚举类型的定义有以下⼏种规则:
1:0 值常量必须存在,且要作为第⼀个元素。这是为了与 proto2 的语义兼容:第⼀个元素作为默认值,且值为 0。
2:枚举类型可以在消息外定义,也可以在消息体内定义(嵌套)。
3:枚举的常量值在 32 位整数的范围内。但因负值⽆效因⽽不建议使⽤(与编码规则有关)。
需要注意的是:
1、同级(同层)的枚举类型,各个枚举类型中的常量不能重名。
// ---------------------- 情况1:同级枚举类型包含相同枚举值名称--------------------
enum PhoneType
{MP = 0; // 移动电话TEL = 1; // 固定电话
}
enum PhoneTypeCopy
{MP = 0; // 移动电话 // 编译后报错:MP 已经定义
}上面的MP就重复了。
2、单个 .proto ⽂件下,最外层枚举类型和嵌套枚举类型,不算同级。
enum PhoneTypeCopy
{MP = 0; // 移动电话 // ⽤法正确
}
message Phone
{string number = 1; // 电话号码enum PhoneType {MP = 0; // 移动电话TEL = 1; // 固定电话}
}3、多个 .proto ⽂件下,若⼀个⽂件引⼊了其他⽂件,且每个⽂件都未声明 package,每个 proto ⽂件中的枚举类型都在最外层,算同级。
4、多个 .proto ⽂件下,若⼀个⽂件引⼊了其他⽂件,且每个⽂件都声明了 package(相当于有自己的命名空间),不算同级。
升级通讯录:
在.proto中增加枚举类型,将电话号码分类型,移动电话和固定电话。
syntax = "proto3";
package contacts;message Phone
{string number = 1;enum PhoneType{MP = 0; // 移动电话TEL = 1; // 固定电话}PhoneType type = 2;
}
// 定义联系人message
message PeopleInfo
{// =1 是字段编号string name = 1; // 姓名int32 age = 2; // 年龄 repeated Phone phone = 3; // 电话信息
}// 通讯录message
message Contacts
{repeated PeopleInfo contacts = 1;
}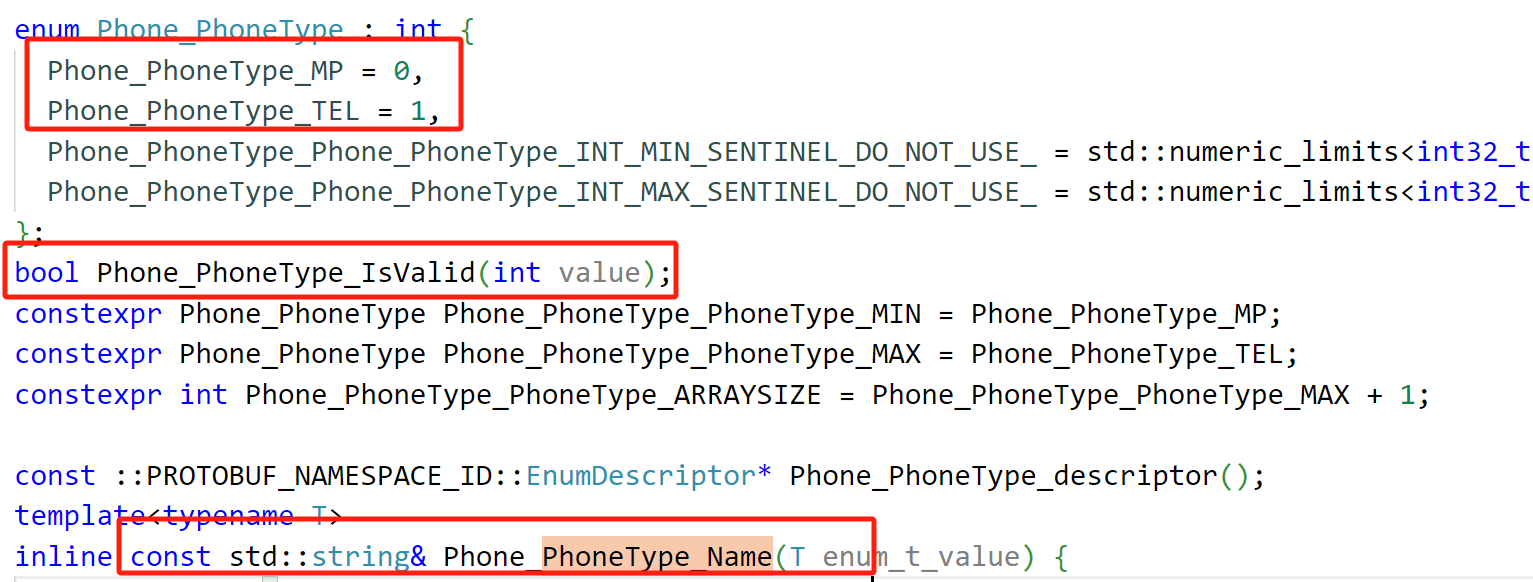

最终在生成的依赖文件中会有对应的字段操作方法。对于在.proto⽂件中定义的枚举类型,编译⽣成的代码中会含有与之对应的枚举类型、校验枚举 值是否有效的⽅法 _IsValid、以及获取枚举值名称的⽅法 _Name。
更新上面的write和read代码:
void AddPeopleInfo(contacts::PeopleInfo *people)
{cout << "-------------新增联系⼈-------------" << endl;cout << "请输入联系人姓名:";string name;getline(cin, name);people->set_name(name);cout << "请输入联系人年龄:";int age;cin >> age;people->set_age(age);cin.ignore(256, '\n');for (int i = 0; ; i++){cout << "请输入联系人电话" << i + 1 << "(只输⼊回⻋完成电话新增):";string number;getline(cin, number);if (number.empty()){break;}contacts::Phone *phone = people->add_phone();phone->set_number(number);// 输入完电话后输入电话类型cout << "请输入该电话类型(1、移动电话 2、固定电话): ";int type;cin >> type;cin.ignore(256, '\n');switch (type){case 1:phone->set_type(contacts::Phone_PhoneType::Phone_PhoneType_MP);break;case 2:phone->set_type(contacts::Phone_PhoneType::Phone_PhoneType_TEL);break;default:cout << "选择有误!" << endl;break;}}cout << "-----------添加联系⼈成功-----------" << endl;
}
void PrintContacts(contacts::Contacts &contacts)
{for (int i = 0; i < contacts.contacts_size(); i++){cout << "---------------联系人" << i + 1 << "---------------" << endl;const contacts::PeopleInfo &people = contacts.contacts(i);cout << "联系人姓名:" << people.name() << endl;cout << "联系人年龄:" << people.age() << endl;for (int j = 0; j < people.phone_size(); j++){const contacts::Phone &phone = people.phone(j);cout << "联系人电话" << j + 1 << ":" << phone.number();// 联系人电话1:1311111 (MP)// phone.type()返回的是枚举常量值,PhoneType_Name返回的是枚举名称cout << " (" << phone.PhoneType_Name(phone.type()) << ")" << endl;}}
}编译运行:新增加联系人刘宇龙:
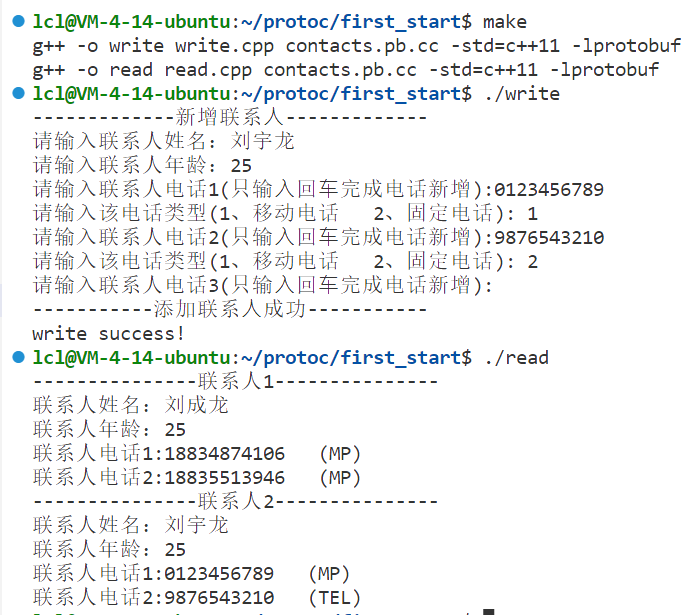
可以发现上面新增加的刘宇龙的电话号码都有自己的类型,但是还有一个现象是原来刘成龙的电话并没有设置类型,但是在.proto中增加了类型字段后,刘成龙的电话也有了类型标识。这是protobuf在反序列化时会为没有设置类型的字段设置一个默认值。
Any类型:
Any 类型,可以理解为泛型类型。使⽤时可以在 Any 中存储任意消息类型。Any 类 型的字段也⽤ repeated 来修饰。 Any 类型是 google 已经帮我们定义好的类型,在安装 ProtoBuf 时,其中的 include ⽬录下查找所有 google 已经定义好的 .proto ⽂件。
更新.proto:增加Any类型:
syntax = "proto3";
package contacts;
import "google/protobuf/any.proto";message Address
{string home = 1; // 家庭地址string unit = 2; // 单位地址
}
message Phone
{string number = 1;enum PhoneType{MP = 0; // 移动电话TEL = 1; // 固定电话}PhoneType type = 2;
}
// 定义联系人message
message PeopleInfo
{// =1 是字段编号string name = 1; // 姓名int32 age = 2; // 年龄 repeated Phone phone = 3; // 电话信息google.protobuf.Any data = 4;
}// 通讯录message
message Contacts
{repeated PeopleInfo contacts = 1;
}
对于message Address,protobuf生成的依赖中的操作字段不在赘述,下面来看PeopleInfo中的Any类型的data:
// .google.protobuf.Any data = 4;bool has_data() const;void clear_data();const ::PROTOBUF_NAMESPACE_ID::Any& data() const;PROTOBUF_NODISCARD ::PROTOBUF_NAMESPACE_ID::Any* release_data();::PROTOBUF_NAMESPACE_ID::Any* mutable_data();void set_allocated_data(::PROTOBUF_NAMESPACE_ID::Any* data);设置和获取:获取⽅法的⽅法名称与⼩写字段名称完全相同(data)。设置⽅法可以使⽤ mutable_ ⽅法,返回值为Any类型的指针,这类⽅法会为我们开辟好空间,可以通过该指针直接对这块空间的内容进⾏修改。
我们可以在 Any 字段中存储任意消息类型,这就要涉及到任意消息类型 和 Any 类型的互转。
bool PackFrom(const ::PROTOBUF_NAMESPACE_ID::Message& message) {...
}bool UnpackTo(::PROTOBUF_NAMESPACE_ID::Message* message) const {...
}
使⽤ PackFrom() ⽅法可以将任意消息类型转为 Any 类型。
使⽤ UnpackTo() ⽅法可以将 Any 类型转回之前设置的任意消息类型。
更新上面的write和read:
在write的AddPeopleInfo中添加:
// 先定义一个消息类型,然后再转成Any类型contacts::Address address;cout << "请输入联系人家庭地址:";string home_address;getline(cin, home_address);address.set_home(home_address);cout << "请输入联系人单位地址:";string unit_address;getline(cin, unit_address);address.set_unit(unit_address);// Address类型->Any类型// mutable_data会开辟一块空间用来存放data,返回一个指针用来操作// Any中的PackFrom用来将message的对象转为Any对象people->mutable_data()->PackFrom(address);在read的PrintContacts中添加:
if (people.has_data() && people.data().Is<contacts::Address>()){contacts::Address address; // UnpackTo将Any类型转换为message对象people.data().UnpackTo(&address);if (!address.home().empty()){cout << "联系人家庭地址:" << address.home() << endl;}if (!address.unit().empty()){cout << "联系人单位地址:" << address.unit() << endl;}}然后重新编译运行:添加联系人乖乖:
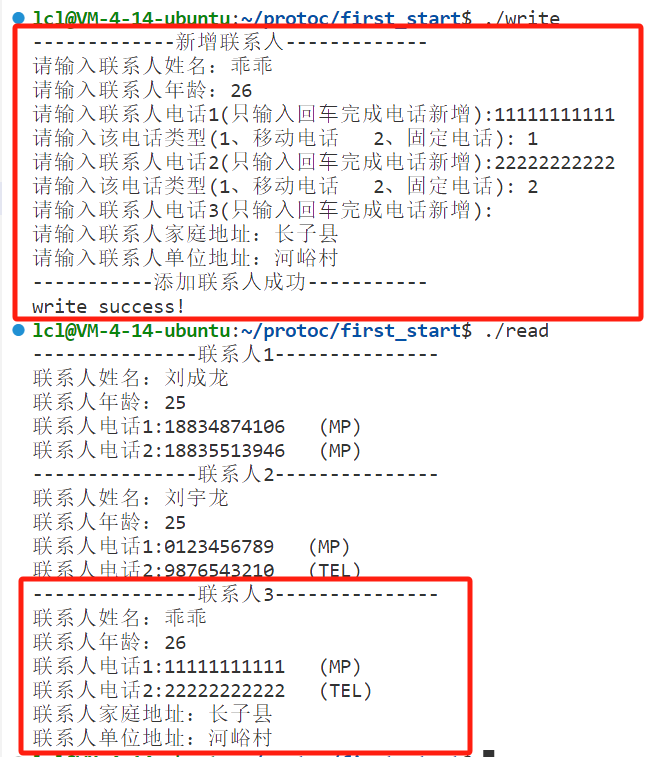
可以看到使用Any类型将联系人的地址信息进行了添加。
oneof 类型:
如果消息中有很多可选字段, 并且将来同时只有⼀个字段会被设置, 那么就可以使⽤ oneof 加强这 个⾏为,也能有节约内存的效果。
需要注意的是:
1、可选字段中的字段编号,不能与⾮可选字段的编号冲突。
2、不能在 oneof 中使⽤ repeated 字段。
3、将来在设置 oneof 字段中值时,如果将 oneof 中的字段设置多个,那么只会保留最后⼀次设置的成 员,之前设置的 oneof 成员会⾃动清除。
map 类型:
map<key_type, value_type> map_field = N;1、key_type 是除了 float 和 bytes 类型以外的任意标量类型。 value_type 可以是任意类型。
2、map 字段不可以⽤ repeated 修饰 ;
3、map 中存⼊的元素是⽆序的。
升级之前的.proto文件:增加map字段remark:
message PeopleInfo
{// =1 是字段编号string name = 1; // 姓名int32 age = 2; // 年龄 repeated Phone phone = 3; // 电话信息google.protobuf.Any data = 4;map<string, string> remark = 5;
}生成的依赖文件中,对其的操作方法和之前的也类同。
更新write和read:
write添加:
for (int i = 0; ; i++){cout << "请输入备注" << i + 1 << "标题(只输入回车完成备注新增):";string remark_key;getline(cin, remark_key);if (remark_key.empty()){break;}cout << "请输入备注" << i + 1 << "内容: ";string remark_value;getline(cin, remark_value);people->mutable_remark()->insert({remark_key, remark_value});}read添加:
if (people.remark_size()){cout << "备注信息:" << endl;}for (auto it = people.remark().cbegin(); it != people.remark().cend(); it++){cout << " " << it->first << ": " << it->second << endl;}重新编译运行,添加新的联系人信息:
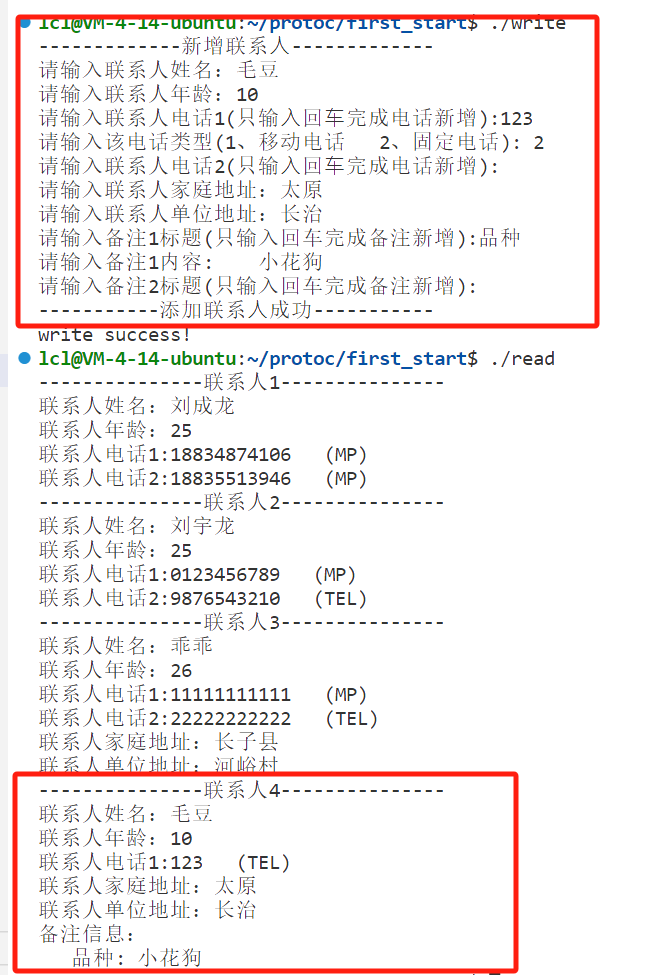
保留字段 reserved:
如果通过 删除 或 注释掉 字段来更新消息类型,未来的⽤户在添加新字段时,有可能会使⽤以前已经存在,但已经被删除或注释掉的字段编号。将来使⽤该 .proto 的旧版本时的程序会引发很多问题:数据损坏、隐私错误等等。
例如:之前的示例中,加入开始的字段编号2是年龄,新增了联系人1:张三,20;打印出的结果是姓名:张三,年龄:20;现在有个需求是将年龄字段删除,新增一个生日字段:假如现在的操作是将原来的年龄字段删除或直接注释,那么新增的生日字段编号设置为2后,这时新增联系人2:李四,0112;这里的0112是生日,然后再打印,会出现两个联系人:分别是姓名:张三,年龄:20;姓名:李四,年龄:0112;但是实际上并没有对李四设置年龄,而是将生日信息放到了年龄信息上,这是因为之前的字段编号都用的是2,导致了数据错误现象。
所以要使用reserved来将该字段设置为保留字段,保证后续不会再用与该字段相同的字段编号。
reserved 100, 101, 200 to 299;
reserved "field3", "field4";保留字段编号,保留字段名称。