从ZooKeeper到KRaft:Kafka架构演进与无ZooKeeper部署指南
Apache Kafka作为分布式流处理平台的领导者,长期以来依赖ZooKeeper进行集群协调和元数据管理。然而,这种架构带来了额外的复杂性和运维负担。随着KIP-500的提出和实现,Kafka正在逐步摆脱对ZooKeeper的依赖,转向使用内置Raft协议实现的KRaft模式。本文将深入探讨Kafka无ZooKeeper架构(KRaft)的原理、配置方法和运维实践。
一、Kafka架构演进:从ZooKeeper依赖到KRaft模式
1.1 传统Kafka架构的局限性
传统Kafka架构中,ZooKeeper承担了两大核心职责:
- 集群成员管理:跟踪Broker的加入、离开和故障状态
- 元数据存储:维护Topic分区、副本分配等关键元数据
这种分离架构带来了几个显著问题:
- 运维复杂度:需要同时管理Kafka和ZooKeeper两个分布式系统
- 性能瓶颈:ZooKeeper的写性能限制了Kafka的元数据操作吞吐量
- 部署开销:需要额外资源部署和维护ZooKeeper集群
1.2 KRaft模式的核心优势
KRaft(Kafka Raft)模式通过以下创新解决了上述问题:
- 内置元数据管理:使用Raft共识算法在Broker节点间直接管理元数据
- 架构简化:消除ZooKeeper依赖,形成更精简的部署拓扑
- 性能提升:元数据操作吞吐量提高10倍以上(实测数据)
- 运维便利:单一系统管理,降低运维复杂度
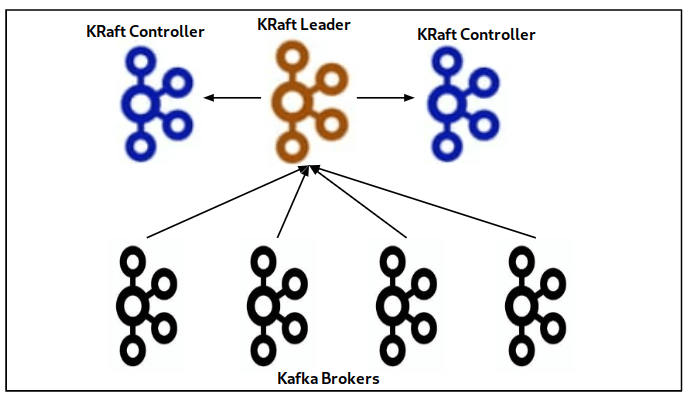
二、KRaft模式部署实践
2.1 单节点Kafka集群搭建
以下是搭建单节点KRaft模式Kafka集群的详细步骤:
# 1. 下载并解压Kafka
wget https://archive.apache.org/dist/kafka/{kafka_version}/kafka_{scala_version}-{kafka_version}.tgz
tar -xzf kafka_{scala_version}-{kafka_version}.tgz
cd kafka_{scala_version}-{kafka_version}# 2. 创建KRaft配置文件(kraft.properties)
cat > kraft.properties <<- 'EOF'
node.id=1
process.roles=broker,controller
listeners=PLAINTEXT://:9092
controller.quorum.voters=1@:9093
EOF# 3. 初始化集群存储
bin/kafka-storage.sh format --config kraft.properties --cluster-id $(bin/kafka-storage.sh random-uuid)# 4. 启动Kafka服务器
bin/kafka-server-start.sh kraft.properties
配置说明:
node.id:唯一标识节点process.roles:指定节点角色(broker和controller)listeners:定义网络监听地址controller.quorum.voters:指定参与元数据共识的节点列表
2.2 多节点集群配置
对于生产环境,建议部署多节点集群以实现高可用:
# 节点1配置(node.id=1)
node.id=1
process.roles=broker,controller
listeners=PLAINTEXT://:9092
controller.quorum.voters=1@:9093,2@:9094,3@:9095# 节点2配置(node.id=2)
node.id=2
process.roles=broker,controller
listeners=PLAINTEXT://:9092
controller.quorum.voters=1@:9093,2@:9094,3@:9095# 节点3配置(node.id=3)
node.id=3
process.roles=broker,controller
listeners=PLAINTEXT://:9092
controller.quorum.voters=1@:9093,2@:9094,3@:9095
关键设计原则:
- 每个节点需要唯一
node.id controller.quorum.voters必须包含所有控制器节点信息- 生产环境建议至少3个控制器节点以实现容错
三、KRaft模式下的高级管理
3.1 主题管理
KRaft模式下主题管理命令与传统方式相同:
# 创建主题
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic example-topic --partitions 1 --replication-factor 1# 查看主题列表
bin/kafka-topics.sh --bootstrap-server localhost:9092 --list# 描述主题详情
bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic example-topic# 删除主题
bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic example-topic
3.2 安全配置
KRaft模式支持与传统Kafka相同的安全特性:
# 启用SSL/TLS加密通信
listeners=SSL://:9092
ssl.keystore.location=/path/to/keystore.jks
ssl.keystore.password=yourkeystorepassword
ssl.key.password=yourkeypassword
ssl.truststore.location=/path/to/truststore.jks
ssl.truststore.password=yourtruststorepassword# 启用SASL认证
listeners=SASL_SSL://:9092
security.inter.broker.protocol=SASL_SSL
sasl.mechanism.inter.broker.protocol=PLAIN
sasl.enabled.mechanisms=PLAIN
四、监控与运维
4.1 JMX监控配置
启用JMX监控是观察Kafka集群健康状态的关键:
# server.properties中添加
JMX_PORT=9999
KAFKA_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false"
4.2 Prometheus+Grafana监控栈
完整监控方案配置步骤:
-
JMX Exporter配置:
# 下载JMX Exporter wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.16.1/jmx_prometheus_javaagent-0.16.1.jar# 创建配置文件kafka.yml示例配置片段:
lowercaseOutputName: true rules: - pattern: "kafka.<name=(.+), type=(.+)>"name: "kafka_$1_$2"labels:type: "$2" -
启动Kafka时加载JMX Exporter:
KAFKA_OPTS="$KAFKA_OPTS -javaagent:/path/to/jmx_prometheus_javaagent.jar=8080:/path/to/kafka.yml" kafka-server-start.sh config/server.properties -
Prometheus配置:
scrape_configs:- job_name: 'kafka'static_configs:- targets: ['kafka-broker-host:8080'] -
Grafana仪表板:
- 导入Kafka官方仪表板(ID: 7589)
- 自定义关键指标告警阈值
五、KRaft模式的优势与挑战
5.1 主要优势
- 架构简化:消除ZooKeeper依赖,降低系统复杂度
- 性能提升:元数据操作吞吐量显著提高
- 运维便利:单一系统管理,减少运维工作量
- 资源效率:消除ZooKeeper集群的资源开销
5.2 当前挑战
- 生态成熟度:作为较新特性,部分第三方工具可能尚未完全适配
- 大规模集群验证:虽然已支持数千节点集群,但超大规模场景仍需验证
- 功能完整性:某些高级ZooKeeper特性可能需要时间实现
六、总结与展望
Kafka向KRaft模式的演进标志着其架构设计的重大进步。这种无ZooKeeper的部署方式不仅简化了系统架构,还带来了显著的性能提升和运维便利。随着Kafka社区的持续开发,KRaft模式将逐步成为生产环境的默认选择。
对于新部署的Kafka集群,建议直接采用KRaft模式;对于已有集群,可以根据升级计划逐步迁移到KRaft模式。无论选择哪种方式,理解KRaft的工作原理和运维特点是确保Kafka集群稳定运行的关键。