【系统全面】Linux进程——基础知识介绍
- 学习建议:先知道怎么操作再去理解内核
进程
$ ps aux- a: 查看所有终端的信息- u: 查看用户相关的信息- x: 显示和终端无关的进程信息
进程(Process)是正在运行的程序,是操作系统进行资源分配和调度的 基本单位。
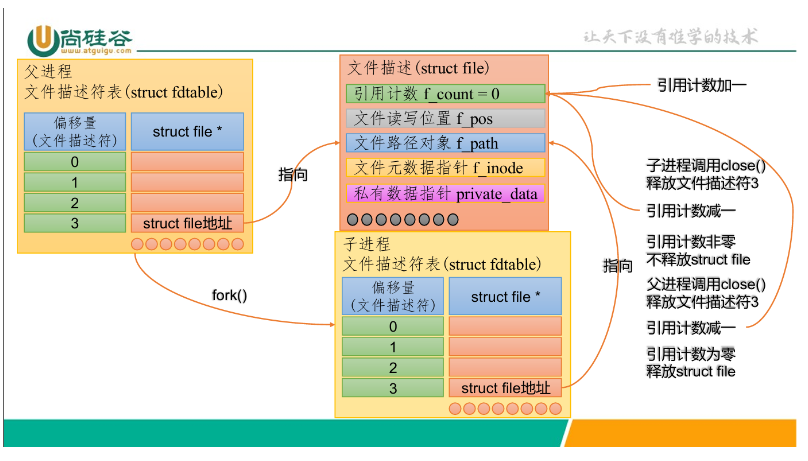
子进程通过close()释放文件描述符之后,父进程 对于相同的文件描述符执行write()操作仍然成功了。这是为什么?
struct file 结构体中有一个属性为引用计数,记录的是与当前struct file绑定 的文件描述符数量。close()系统调用的作用是将当前进程中的文件描述符和对应的 struct file 结构体解绑,使得引用计数减一。如果 close()执行之后,引用计数变为 0, 则会释放struct file 相关的所有资源。
进程创建
进程创建
int main()
{// 在父进程中创建子进程pid_t pid = fork();printf("当前进程fork()的返回值: %d\n", pid);if(pid > 0){// 父进程执行的逻辑printf("我是父进程, pid = %d\n", getpid());}else if(pid == 0){// 子进程执行的逻辑printf("我是子进程, pid = %d, 我爹是: %d\n", getpid(), getppid());}else // pid == -1{// 创建子进程失败了}// 不加判断, 父子进程都会执行这个循环for(int i=0; i<5; ++i){printf("%d\n", i);}return 0;}
book@100ask:~$ gcc pthread_create.c -o app
book@100ask:~$ ./app
当前进程fork()的返回值: 21803
我是父进程, pid = 21802
0
1
2
3
当前进程fork()的返回值: 0
4
我是子进程, pid = 21803, 我爹是: 21802
0
1
2
3
4
循环创建子进程
// process_loop.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>int main()
{for(int i=0; i<3; ++i){pid_t pid = fork();printf("当前进程pid: %d\n", getpid());}return 0;
}# 编译
$ gcc process_loop.c# 执行
$ ./a.out
# 最终得到了 8个进程
当前进程pid: 18774 ------ 1
当前进程pid: 18774 ------ 1
当前进程pid: 18774 ------ 1
当前进程pid: 18777 ------ 2
当前进程pid: 18776 ------ 3
当前进程pid: 18776 ------ 3
当前进程pid: 18775 ------ 4
当前进程pid: 18775 ------ 4
当前进程pid: 18775 ------ 4
当前进程pid: 18778 ------ 5
当前进程pid: 18780 ------ 6
当前进程pid: 18779 ------ 7
当前进程pid: 18779 ------ 7
当前进程pid: 18781 ------ 8
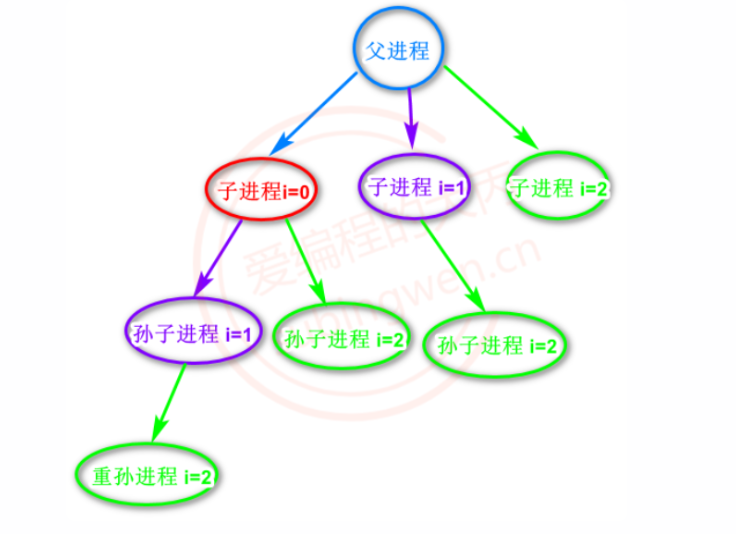
上图中的树状结构,蓝色节点代表父进程:
循环第一次 i = 0,创建出一个子进程,即红色节点,子进程变量值来自父进程拷贝,因此 i=0
循环第二次 i = 1,蓝色父进程和红色子进程都去创建子进程,得到两个紫色进程,子进程变量值来自父进程拷贝,因此 i=1
循环第三次 i = 2,蓝色父进程和红色、紫色子进程都去创建子进程,因此得到4个绿色子进程,子进程变量值来自父进程拷贝,因此 i=2
循环第三次 i = 3,所有进程都不满足条件 for(int i=0; i<3; ++i)因此不进入循环,退出了。
通过上面的分析,最终得到解决方案,我们可以只让父进程创建子进程,如果是子进程不让其继续创建子进程,因此只需要在程序中添加关于父子进程的判断即可。
//修改之后的代码如下:
// 需要在上边的程序中控制不让子进程, 再创建子进程即可
// process_loop.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>int main()
{pid_t pid;// 在循环中创建子进程for(int i=0; i<3; ++i){pid = fork();if(pid == 0){// 不让子进程执行循环, 直接跳出break;}}printf("当前进程pid: %d\n", getpid());return 0;
}
最后编译并执行程序,查看最终结果,可以看到最后确实得到了4个不同的进程,pid最小的为父进程,其余为子进程:# 编译
$ gcc process_loop.c# 执行
$ ./a.out
当前进程pid: 2727
当前进程pid: 2730
当前进程pid: 2729
当前进程pid: 2728
- 两个进程中是不能通过全局变量实现数据交互的,因为每个进程都有自己的地址空间,两个同名全局变量存储在不同的虚拟地址空间中,二者没有任何关联性。如果要进行进程间通信需要使用:管道,共享内存,本地套接字,内存映射区,消息队列等方式。
- 在 main 函数中直接使用 return也可以退出进程, 假如是在一个普通函数中调用 return 只能返回到调用者的位置,而不能退出进程。
1号进程就是systemd,它由内核创建,是第一个进程,负责初始化系统, 启动其他所有用户空间的服务和进程。它是所有进程的祖先。 pstree命令会以树状图展示所有用户进程的依赖关系,可以看到,systemd是所有 用户进程的祖先。
execve 函数
int execve(const char *pathname, char *const argv[], char *const envp[]);
- 实现 shell:shell 程序使用
fork()创建子进程,然后子进程使用execve()执行用户指定的命令。 - 程序加载器:在 Linux 中,当执行一个程序时,内核会使用类似
execve()的机制来加载并执行该程序。 - 自定义命令执行:在需要控制命令执行环境(如环境变量、参数等)的场景下使用。
waitpid函数
调用waitpid在父进程中等待子进程完成并执行回收工作。
孤儿进程
在一个启动的进程中创建子进程,这时候父子进程同时运行,但是父进程由于某种原因先退出了,子进程还在运行,这时候这个子进程就可以被称之为孤儿进程(跟现实是一样的)。
操作系统是非常关爱运行的每一个进程的,当检测到某一个进程变成了孤儿进程,这时候系统中就会有一个固定的进程领养这个孤儿进程(有干爹了)。如果使用Linux没有桌面终端,这个领养孤儿进程的进程就是 init 进程(PID=1),如果有桌面终端,这个领养孤儿进程就是桌面进程。
那么问题来了,系统为什么要领养这个孤儿进程呢?在子进程退出的时候, 进程中的用户区可以自己释放, 但是进程内核区的pcb资源自己无法释放,必须要由父进程来释放子进程的pcb资源,孤儿进程被领养之后,这件事儿干爹就可以代劳了,这样可以避免系统资源的浪费。
下面这段代码就可以得到一个孤儿进程:
int main()
{// 创建子进程pid_t pid = fork();// 父进程if(pid > 0){printf("我是父进程, pid=%d\n", getpid());}else if(pid == 0){sleep(1); // 强迫子进程睡眠1s, 这个期间, 父进程退出, 当前进程变成了孤儿进程// 子进程printf("我是子进程, pid=%d, 父进程ID: %d\n", getpid(), getppid());}return 0;}
# 程序输出的结果
$ ./a.out
我是父进程, pid=22459
我是子进程, pid=22460, 父进程ID: 1 # 父进程向退出, 子进程变成孤儿进程, 子进程被1号进程回收
孤儿进程会被其祖先自动领养。此时的子进程因为和终端切断了 联系,所以很难再进行标准输入使其停止了,所以写代码的时候一定要注意避免出现孤儿 进程。
僵尸进程
在一个启动的进程中创建子进程,这时候就有了父子两个进程,父进程正常运行, 子进程先与父进程结束, 子进程无法释放自己的PCB资源, 需要父进程来做这个件事儿, 但是如果父进程也不管, 这时候子进程就变成了僵尸进程。
僵尸进程不能将它看成是一个正常的进程,这个进程已经死亡了,用户区资源已经被释放了,只是还占用着一些内核资源(PCB)。 僵尸进程就相当于是一副已经腐烂只剩下骨头的尸体。
僵尸进程的出现是由于这个已死亡的进程的父进程不作为造成的。
运行下面的代码就可以得到一个僵尸进程了:
int main()
{pid_t pid;// 创建子进程for(int i=0; i<5; ++i){pid = fork();if(pid == 0){break;}}// 父进程if(pid > 0){// 需要保证父进程一直在运行// 一直运行不退出, 并且也做回收, 就会出现僵尸进程while(1){printf("我是父进程, pid=%d\n", getpid());sleep(1);}}else if(pid == 0){// 子进程, 执行这句代码之后, 子进程退出了printf("我是子进程, pid=%d, 父进程ID: %d\n", getpid(), getppid());}return 0;}# ps aux 查看进程信息# Z+ --> 这个进程是僵尸进程, defunct, 表示进程已经死亡robin 22598 0.0 0.0 4352 624 pts/2 S+ 10:11 0:00 ./app
robin 22599 0.0 0.0 0 0 pts/2 Z+ 10:11 0:00 [app] <defunct> # 子进程
robin 22600 0.0 0.0 0 0 pts/2 Z+ 10:11 0:00 [app] <defunct> # 子进程
robin 22601 0.0 0.0 0 0 pts/2 Z+ 10:11 0:00 [app] <defunct> # 子进程
robin 22602 0.0 0.0 0 0 pts/2 Z+ 10:11 0:00 [app] <defunct> # 子进程
robin 22603 0.0 0.0 0 0 pts/2 Z+ 10:11 0:00 [app] <defunct> # 子进程
消灭僵尸进程的方法是,杀死这个僵尸进程的父进程,这样僵尸进程的资源就被系统回收了。通过kill -9 僵尸进程PID的方式是不能消灭僵尸进程的,这个命令只对活着的进程有效,僵尸进程已经死了,鞭尸是不能解决问题的。
进程回收
为了避免僵尸进程的产生,一般我们会在父进程中进行子进程的资源回收,回收方式有两种,一种是阻塞方式wait(),一种是非阻塞方式waitpid()。
wait
这是个阻塞函数,如果没有子进程退出, 函数会一直阻塞等待, 当检测到子进程退出了, 该函数阻塞解除回收子进程资源。这个函数被调用一次, 只能回收一个子进程的资源,如果有多个子进程需要资源回收, 函数需要被调用多次。
函数原型如下:
// man 2 wait
#include <sys/wait.h>pid_t wait(int *status);
参数:传出参数,通过传递出的信息判断回收的进程是怎么退出的,如果不需要该信息可以指定为 NULL。取出整形变量中的数据需要使用一些宏函数,具体操作方式如下:
WIFEXITED(status): 返回1, 进程是正常退出的
WEXITSTATUS(status):得到进程退出时候的状态码,相当于 return 后边的数值, 或者 exit()函数的参数
WIFSIGNALED(status): 返回1, 进程是被信号杀死了
WTERMSIG(status): 获得进程是被哪个信号杀死的,会得到信号的编号
返回值:
成功:返回被回收的子进程的进程ID
失败: -1
没有子进程资源可以回收了, 函数的阻塞会自动解除, 返回-1
回收子进程资源的时候出现了异常
参数:传出参数,通过传递出的信息判断回收的进程是怎么退出的,如果不需要该信息可以指定为 NULL。取出整形变量中的数据需要使用一些宏函数,具体操作方式如下:
WIFEXITED(status): 返回1, 进程是正常退出的
WEXITSTATUS(status):得到进程退出时候的状态码,相当于 return 后边的数值, 或者 exit()函数的参数
WIFSIGNALED(status): 返回1, 进程是被信号杀死了
WTERMSIG(status): 获得进程是被哪个信号杀死的,会得到信号的编号
返回值:
成功:返回被回收的子进程的进程ID
失败: -1
没有子进程资源可以回收了, 函数的阻塞会自动解除, 返回-1
回收子进程资源的时候出现了异常
下面代码演示了如何通过 wait()回收多个子进程资源:
//下面代码演示了如何通过 wait()回收多个子进程资源:
// wait 函数回收子进程资源
#include <sys/wait.h>int main()
{pid_t pid;// 创建子进程for(int i=0; i<5; ++i){pid = fork();if(pid == 0){break;}}// 父进程if(pid > 0){// 需要保证父进程一直在运行while(1){// 回收子进程的资源// 子进程由多个, 需要循环回收子进程资源pid_t ret = wait(NULL);if(ret > 0){printf("成功回收了子进程资源, 子进程PID: %d\n", ret);}else{printf("回收失败, 或者是已经没有子进程了...\n");break;}printf("我是父进程, pid=%d\n", getpid());}}else if(pid == 0){// 子进程, 执行这句代码之后, 子进程退出了printf("我是子进程, pid=%d, 父进程ID: %d\n", getpid(), getppid());}return 0;}}
waitpid
waitpid() 函数可以看做是 wait() 函数的升级版,通过该函数可以控制回收子进程资源的方式是阻塞还是非阻塞,另外还可以通过该函数进行精准打击,可以精确指定回收某个或者某一类或者是全部子进程资源。
该函数函数原型如下:
// man 2 waitpid
#include <sys/wait.h>
// 这个函数可以设置阻塞, 也可以设置为非阻塞
// 这个函数可以指定回收哪些子进程的资源
pid_t waitpid(pid_t pid, int *status, int options);
参数:
pid:-1:回收所有的子进程资源, 和wait()是一样的, 无差别回收,并不是一次性就可以回收多个, 也是需要循环回收的
大于0:指定回收某一个进程的资源 ,pid是要回收的子进程的进程ID
0:回收当前进程组的所有子进程ID
小于 -1:pid 的绝对值代表进程组ID,表示要回收这个进程组的所有子进程资源
status: NULL, 和wait的参数是一样的options: 控制函数是阻塞还是非阻塞
0: 函数是行为是阻塞的 ==> 和wait一样
WNOHANG: 函数是行为是非阻塞的
返回值:
如果函数是非阻塞的, 并且子进程还在运行, 返回0
成功: 得到子进程的进程ID
失败: -1
没有子进程资源可以回收了, 函数如果是阻塞的, 阻塞会解除, 直接返回-1
回收子进程资源的时候出现了异常
//下面代码演示了如何通过 waitpid()阻塞回收多个子进程资源:
// 和wait() 行为一样, 阻塞
#include <sys/wait.h>int main()
{pid_t pid;// 创建子进程for(int i=0; i<5; ++i){pid = fork();if(pid == 0){break;}}// 父进程if(pid > 0){// 需要保证父进程一直在运行while(1){// 回收子进程的资源// 子进程由多个, 需要循环回收子进程资源int status;pid_t ret = waitpid(-1, &status, 0); // == wait(NULL);if(ret > 0){printf("成功回收了子进程资源, 子进程PID: %d\n", ret);// 判断进程是不是正常退出if(WIFEXITED(status)){printf("子进程退出时候的状态码: %d\n", WEXITSTATUS(status));}if(WIFSIGNALED(status)){printf("子进程是被这个信号杀死的: %d\n", WTERMSIG(status));}}else{printf("回收失败, 或者是已经没有子进程了...\n");break;}printf("我是父进程, pid=%d\n", getpid());}}else if(pid == 0){// 子进程, 执行这句代码之后, 子进程退出了printf("===我是子进程, pid=%d, 父进程ID: %d\n", getpid(), getppid());}return 0;}
下面代码演示了如何通过 waitpid()非阻塞回收多个子进程资源:
// 非阻塞处理
#include <sys/wait.h>int main()
{pid_t pid;// 创建子进程for(int i=0; i<5; ++i){pid = fork();if(pid == 0){break;}}// 父进程if(pid > 0){// 需要保证父进程一直在运行while(1){// 回收子进程的资源// 子进程由多个, 需要循环回收子进程资源// 子进程退出了就回收, // 没退出就不回收, 返回0int status;pid_t ret = waitpid(-1, &status, WNOHANG); // 非阻塞if(ret > 0){printf("成功回收了子进程资源, 子进程PID: %d\n", ret);// 判断进程是不是正常退出if(WIFEXITED(status)){printf("子进程退出时候的状态码: %d\n", WEXITSTATUS(status));}if(WIFSIGNALED(status)){printf("子进程是被这个信号杀死的: %d\n", WTERMSIG(status));}}else if(ret == 0){printf("子进程还没有退出, 不做任何处理...\n");}else{printf("回收失败, 或者是已经没有子进程了...\n");break;}printf("我是父进程, pid=%d\n", getpid());}}else if(pid == 0){// 子进程, 执行这句代码之后, 子进程退出了printf("===我是子进程, pid=%d, 父进程ID: %d\n", getpid(), getppid());}return 0;
}
1. 阻塞 (Blocking)
阻塞是指当一个操作(如读、写、等待进程结束等)没有完成时,进程会被挂起,直到该操作完成才能继续执行。这意味着在等待的过程中,进程会被“阻塞”或“暂停”,不执行后续的操作,直到得到所需的资源或事件。
阻塞的例子:
wait()系统调用:如果父进程调用wait()等待子进程结束,那么父进程会被阻塞,直到一个子进程退出。read()系统调用:如果从一个文件或管道中读取数据,且数据暂时不可用,进程会阻塞,直到有数据可以读取。
阻塞的特点:
- 在操作完成之前,进程会一直停在那里,无法做其他事情。
- 适用于某些操作需要等待资源的情况,如文件读取、网络通信等。
- 简单易理解,但在某些高并发场景下,可能会导致程序的效率低下或响应迟缓。
2. 非阻塞 (Non-blocking)
非阻塞是指当一个操作无法立即完成时,进程不会被挂起,而是继续执行其他任务,直到操作可以成功完成。非阻塞操作通常会立即返回一个状态(如失败),而不是让进程等待操作完成。
非阻塞的例子:
waitpid(WNOHANG):当父进程调用waitpid()并传入WNOHANG参数时,它会非阻塞地检查子进程是否已退出。如果没有子进程退出,它会立即返回,而不是让父进程停在那里等待。- 非阻塞的
read()或write():在非阻塞模式下,如果没有数据可以读取,read()会立即返回,而不会让进程等待数据。
非阻塞的特点:
- 如果操作不能立即完成,进程不会停下来等待,而是会继续执行其他代码。
- 适用于高并发或实时性要求较高的场景。
- 可以提高效率,但需要额外的逻辑来检查操作是否完成,通常会使代码更复杂。
利用内存映射区进行文件的拷贝
如何用直接利用虚拟地址进行读写与拷贝(进程通信)
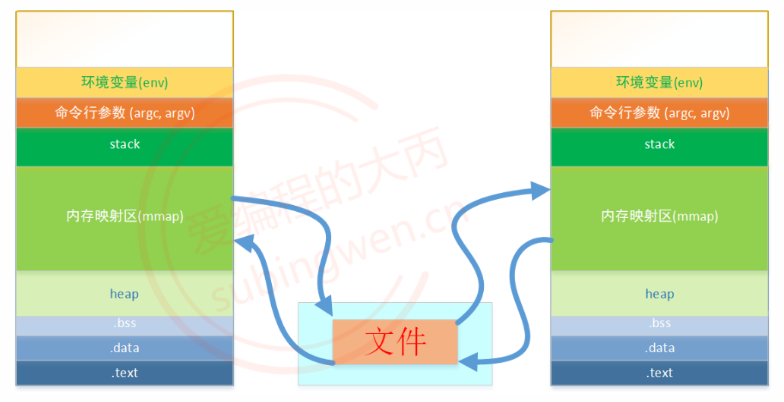
磁盘文件数据可以完全加载到进程的内存映射区也可以部分加载到进程的内存映射区,当进程A中的内存映射区数据被修改了,数据会被自动同步到磁盘文件,同时和磁盘文件建立映射关系的其他进程内存映射区中的数据也会和磁盘文件进行数据的实时同步,这个同步机制保障了各个进程之间的数据共享。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <fcntl.h>
#include <sys/mman.h>int main()
{// 1. 打开一个操盘文件english.txt得到文件描述符int fd = open("./english.txt", O_RDWR);// 计算文件大小int size = lseek(fd, 0, SEEK_END);// 2. 创建内存映射区和english.txt进行关联, 得到映射区起始地址void* ptrA = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);if(ptrA == MAP_FAILED){perror("mmap");exit(0);}// 3. 创建一个新文件, 存储拷贝的数据int fd1 = open("./copy.txt", O_RDWR|O_CREAT, 0664);// 拓展这个新文件ftruncate(fd1, size);// 4. 创建一个映射区和新文件进行关联, 得到映射区的起始地址secondvoid* ptrB = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED, fd1, 0);if(ptrB == MAP_FAILED){perror("mmap----");exit(0);}// 5. 使用memcpy拷贝映射区数据// 这两个指针指向两块内存, 都是内存映射区// 指针指向有效的内存, 拷贝的是内存中的数据memcpy(ptrB, ptrA, size);// 6. 释放内存映射区munmap(ptrA, size);munmap(ptrB, size);close(fd);close(fd1);return 0;
}
使用内存映射区拷贝文件思路:
打开被拷贝文件,得到文件描述符 fd1,并计算出这个文件的大小 size
创建内存映射区A并且和被拷贝文件关联,也就是和fd1关联起来,得到映射区地址 ptrA
创建新文件,得到文件描述符 fd2,用于存储被拷贝的数据,并且将这个文件大小拓展为 size
创建内存映射区B并且和新创建的文件关联,也就是和fd2关联起来,得到映射区地址 ptrB
进程地址空间之间的数据拷贝,memcpy(ptrB, ptrA,size),数据自动同步到新建文件中
关闭内存映射区
匿名管道Pipe
一个容纳要传递的东西的管子,一头写一头读
两个人通过一根吸管传纸条,顺序传递,没有标记。
int pipe(int filedes[2]);
返回值
管道函数 pipe() 的返回值有两种情况:
- 成功:返回
0- 表示管道创建成功
- 此时
filedes[0]被设置为读取端文件描述符 filedes[1]被设置为写入端文件描述符
- 失败:返回
-1- 表示管道创建失败
- 同时会设置全局错误变量
errno来指示具体的错误原因
了父进程将argv[1]写入匿名管道,子进程读取并输出到控制台的过程,例程如下。
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h> int main(int argc, char const *argv[])
{ int pipefd[2]; pid_t cpid; char buf; if (argc != 2) { fprintf(stderr, "%s:请填写需要传递的信息\n", argv[0]); exit(EXIT_FAILURE); } if (pipe(pipefd) == -1) { perror("创建管道失败\n"); exit(EXIT_FAILURE); } cpid = fork(); if (cpid == -1) { perror("邀请新学员失败!\n"); exit(EXIT_FAILURE); } if (cpid == 0) { // 新学员读数据 关闭写端 close(pipefd[1]); char str[100]={0}; sprintf(str,"新学员%d收到邀请\n",getpid()); write(STDOUT_FILENO, str, sizeof(str)); // 一直读取读端的数据 单个字节读取方便读取结尾 直到数据结束或出错 while (read(pipefd[0], &buf, 1) > 0){ // 将读取数据写到标准输出 write(STDOUT_FILENO, &buf, 1); } // 输出换行 write(STDOUT_FILENO, "\n", 1); close(pipefd[0]); _exit(EXIT_SUCCESS); } else { // 老学员写数据 关闭读端 close(pipefd[0]); // 写入传入的参数到管道的写端 printf("老学员%d发出邀请\n",getpid()); write(pipefd[1], argv[1], strlen(argv[1])); // 写完之后关闭写端 读端会返回0 close(pipefd[1]); // 等待子进程结束 waitpid(cpid,NULL,0); exit(EXIT_SUCCESS); }
}
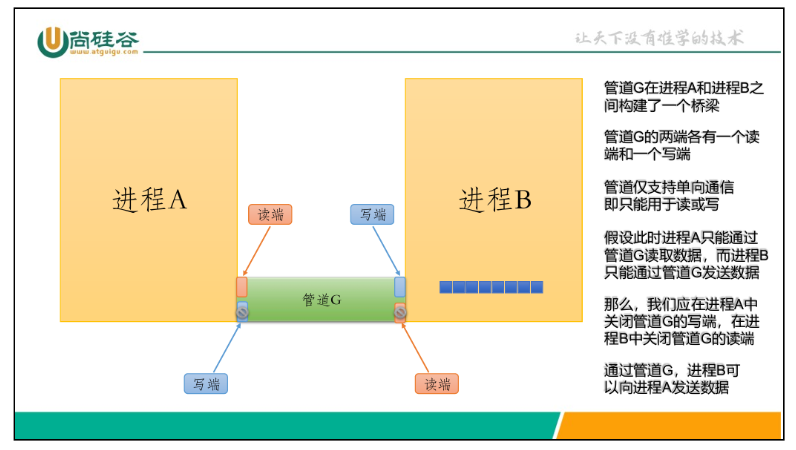
使用管道的限制:
(1)两个进程通过一个管道只能实现单向通信,比如上面的例子,父进程写子进程读, 如果有时候也需要子进程写父进程读,就必须另开一个管道。
(2)管道的读写端通过打开的文件描述符来传递,因此要通信的两个进程必须从它们 的公共祖先那里继承管道文件描述符。上面的例子是父进程把文件描述符传给子进程之后父子进程之间通信,也可以父进程fork两次,把文件描述符传给两个子进程,然后两个子 进程之间通信,总之需要通过fork传递文件描述符使两个进程都能访问同一管道,它们才 能通信。
管道返回的文件描述符:
管道返回的两个文件描述符分别表示读写,各自指向一个struct file结构体,然 而,它们并不对应真正的文件。 当我们开启管道时,父进程会创建两个struct file结构体用于管道的读写操作, 并为二者各自分配一个文件描述符。它们的private_data属性指向同一个struct pipe_inode_info 的结构体,由后者管理对于管道缓冲区的读写。通过fork()创建一个 子进程,后者会继承文件描述符,指向相同的struct file结构体,如下。
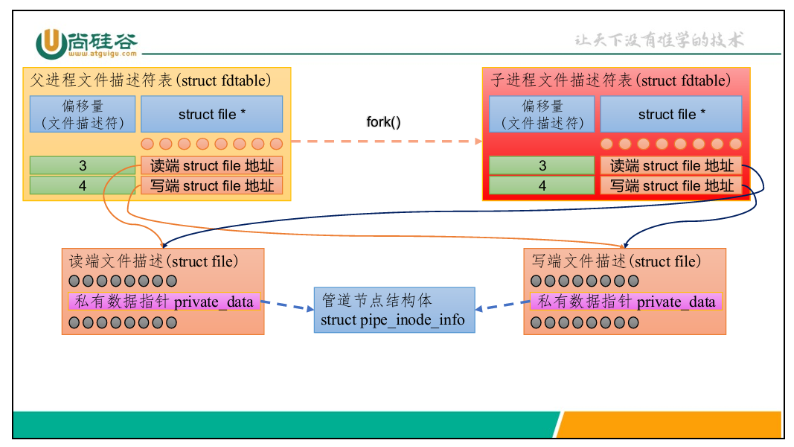
有名管道FIFO
FIFO (First In First Out),也称为命名管道,是一种特殊的文件类型,用于在无关进程之间进行通信。与匿名管道不同,FIFO 有一个在文件系统中的路径名,允许不相关的进程通过这个路径名来通信。
上文介绍的Pipe是匿名管道,只能在有父子关系的进程间使用,某些场景下并不能 满足需求。与匿名管道相对的是有名管道,在Linux中称为FIFO,即First In First Out,先进先出队列。
FIFO和Pipe一样,提供了双向进程间通信渠道。但要注意的是,无论是有名管道还 是匿名管道,同一条管道只应用于单向通信,否则可能出现通信混乱(进程读到自己发的 数据)。
有名管道可以用于任何进程之间的通信。
mkfifo() 函数 - 创建 FIFO
c
复制int mkfifo(const char *pathname, mode_t mode);
返回值:
- 成功:返回
0(不是文件描述符) - 失败:返回
-1并设置errno
mkfifo() 只是创建了一个特殊的文件,它本身并不打开这个文件,因此不会返回文件描述符。它只是告诉你创建成功与否。
2. open() 函数 - 打开 FIFO
c
复制int open(const char *pathname, int flags);
返回值:
- 成功:返回一个非负整数,这个是文件描述符
- 失败:返回
-1并设置errno
当你用 open() 打开 FIFO 文件时,它会返回一个文件描述符,就像打开普通文件一样。这个文件描述符用于后续的读写操作。
调用open()打开有名管道时,flags设置为O_WRONLY则当前进程用于向有名管道写 入数据,设置为O_RDONLY则当前进程用于从有名管道读取数据。设置为O_RDWR从技术 上是可行的,但正如上文提到的,此时管道既读又写很可能导致一个进程读取到自己发送 的数据,通信出现混乱。因此,打开有名管道时,flags只应为O_WRONLY或O_RDONLY。
内核为每个被进程打开的FIFO专用文件维护一个管道对象。当进程 通过FIFO交换数 据时,内核会在内部传递所有数据,不会将其写入文件系统。因此,/tmp/myfifo文件大 小始终为0。
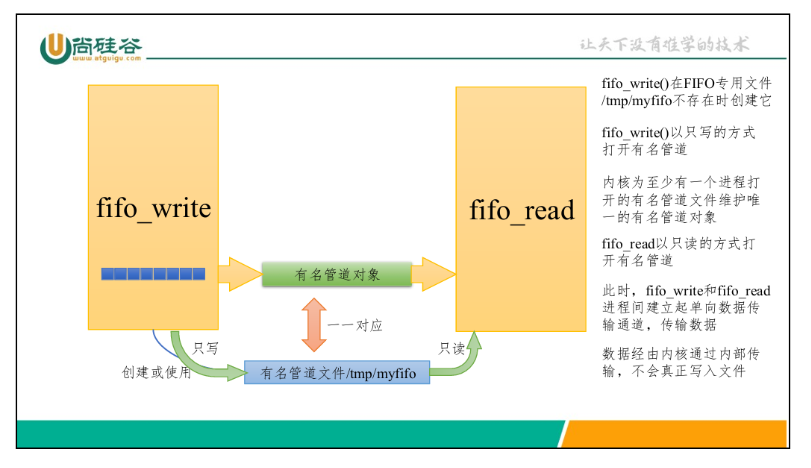
有名管道打开会有一个文件和他对应,他的作用是什么,匿名管道有吗?
- 有名管道(Named Pipe):
- 有名管道是一种具有文件路径的管道,允许不同的进程通过它进行通信。它与文件系统中的文件类似,因此它是“有名的”。
- 有名管道的作用是允许不相关的进程进行数据交换。因为它是基于文件系统的,可以在不同的系统间进行通信(在支持有名管道的操作系统之间)。
- 在有名管道的实现中,通常会在创建管道时指定一个路径,这个路径就像一个文件一样。通过这个路径,进程就能连接到管道进行读写。
- 一些常见的应用场景包括跨进程数据传输,比如服务器和客户端之间的通信。
- 匿名管道(Anonymous Pipe):
- 匿名管道是没有文件路径的,只能在同一台机器上的相关进程间进行通信。它通常是临时的,只在创建它的父进程和子进程之间有效。
- 它是一种非常简单的IPC机制,通常用于父子进程之间的数据传输,不需要进行文件路径管理。
- 匿名管道的特点是:它没有明确的“名字”,因此它只能在创建它的进程之间使用,一旦进程结束,管道也就消失了。
区别:
- 有名管道:有一个文件路径,允许不同的进程(甚至跨机器)进行通信,适用于需要长期存在的管道。
- 匿名管道:没有文件路径,通常用于父子进程之间的短期通信,只在相关进程中有效。
共享内存
共享内存用的时候要先关联,共享内存是共享的,是直接对内存操作,共享内存和内存映射区的区别
shm_open可以开启一块内存共享对象,我们可以像使用一般文件描述符一般使用这 块内存对象。
// 根据路径生成一个key_t
key_t key = ftok("/home/robin", 'a');
// 创建或打开共享内存
shmget(key, 4096, IPC_CREATE|0664);
调用linux的系统API创建一块共享内存
- 这块内存不属于任何进程, 默认进程不能对其进行操作
准备好进程A, 和进程B, 这两个进程需要和创建的共享内存进行关联
- 关联操作: 调用linux的 api
- 关联成功之后, 得到了这块共享内存的起始地址
在进程A或者进程B中对共享内存进行读写操作
- 读内存: printf() 等;
- 写内存: memcpy() 等;
通信完成, 可以让进程A和B和共享内存解除关联
- 解除成功, 进程A和B不能再操作共享内存了
- 共享内存不受进程生命周期的影响的
共享内存不在使用之后, 将其删除
- 调用linux的api函数, 删除之后这块内存被内核回收了
//写共享内存的进程代码:
#include <stdio.h>
#include <sys/shm.h>
#include <string.h>int main()
{// 1. 创建共享内存, 大小为4kint shmid = shmget(1000, 4096, IPC_CREAT|0664);if(shmid == -1){perror("shmget error");return -1;}// 2. 当前进程和共享内存关联void* ptr = shmat(shmid, NULL, 0);if(ptr == (void *) -1){perror("shmat error");return -1;}// 3. 写共享内存const char* p = "hello, world, 共享内存真香...";memcpy(ptr, p, strlen(p)+1);// 阻塞程序printf("按任意键继续, 删除共享内存\n");getchar();shmdt(ptr);// 删除共享内存shmctl(shmid, IPC_RMID, NULL);printf("共享内存已经被删除...\n");return 0;
}
//读共享内存的进程代码:
#include <stdio.h>
#include <sys/shm.h>
#include <string.h>int main()
{// 1. 创建共享内存, 大小为4kint shmid = shmget(1000, 0, 0);if(shmid == -1){perror("shmget error");return -1;}// 2. 当前进程和共享内存关联void* ptr = shmat(shmid, NULL, 0);if(ptr == (void *) -1){perror("shmat error");return -1;}// 3. 读共享内存printf("共享内存数据: %s\n", (char*)ptr);// 阻塞程序printf("按任意键继续, 删除共享内存\n");getchar();shmdt(ptr);// 删除共享内存shmctl(shmid, IPC_RMID, NULL);printf("共享内存已经被删除...\n");return 0;
}
truncate()和ftruncate()
truncate和ftruncate都可以将文件缩放到指定大小,二者的行为类似:如果文件 被缩小,截断部分的数据丢失,如果文件空间被放大,扩展的部分均为\0字符。缩放前后 文件的偏移量不会更改。缩放成功返回0,失败返回-1。
不同的是,前者需要指定路径,而后者需要提供文件描述符;ftruncate缩放的文件 描述符可以是通过shm_open()开启的内存对象,而truncate缩放的文件必须是文件系 统已存在文件,若文件不存在或没有权限则会失败。
shm和mmap的区别
共享内存和内存映射区都可以实现进程间通信,下面来分析一下二者的区别:
实现进程间通信的方式
shm: 多个进程只需要一块共享内存就够了,共享内存不属于进程,需要和进程关联才能使用
内存映射区: 位于每个进程的虚拟地址空间中, 并且需要关联同一个磁盘文件才能实现进程间数据通信
效率:
shm: 直接对内存操作,效率高
内存映射区: 需要内存和文件之间的数据同步,效率低
生命周期
**内存映射区:**进程退出, 内存映射区也就没有了
**shm:**进程退出对共享内存没有影响,调用相关函数/命令/ 关机才能删除共享内存
数据的完整性 -> 突发状态下数据能不能被保存下来(比如: 突然断电)
**内存映射区:**可以完整的保存数据, 内存映射区数据会同步到磁盘文件
**shm:**数据存储在物理内存中, 断电之后系统关闭, 内存数据也就丢失了
临时文件系统
Linux的临时文件系统(tmpfs)是一种基于内存的文件系统,它将数据存储在RAM 或者在需要时部分使用交换空间(swap)。tmpfs访问速度快,但因为存储在内存,重启 后数据清空,通常用于存储一些临时文件。
我们可以通过df -h查看当前操作系统已挂载的文件系统。
内存共享对象在临时文件系统中的表示位于/dev/shm目录下。
消息队列
和管道类似,但消息队列是一个收发信箱,信件有编号、优先级,多个收发者可以参与。
管道和消息队列都像是“容器”一样传递数据,但消息队列功能更强大、结构更复杂、使用更灵活,适合更复杂的场景。
相关数据类型:实质上是int类型的别名。
typedef int mqd_t;
struct mq_attr
/** * @brief 消息队列的属性信息 * mq_flags 标记,对于mq_open,忽略它,因为这个标记是通过前者的调用传递的 * mq_maxmgs 队列可以容纳的消息的最大数量 * mq_msgsize 单条消息的最大允许大小,以字节为单位 * mq_curmsgs 当前队列中的消息数量,对于mq_open,忽略它 */
struct mq_attr {
long mq_flags; /* Flags (ignored for mq_open()) */
long mq_maxmsg; /* Max. # of messages on queue */
long mq_msgsize; /* Max. message size (bytes) */
long mq_curmsgs; /* # of messages currently in queue (ignored for mq_open()) */
};
/** * @brief 时间结构体,提供了纳秒级的UNIX时间戳 * tv_sec 秒 * tv_nsec 纳秒 */
struct timespec {
time_t tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
};
非父子进程通信案例
我们创建两个进程:生产者和消费者,前者从控制台接收数据并写入消息队列,后者 从消息队列接收数据并打印到控制台。
producer.c
#include <time.h>
#include <mqueue.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h> int main()
{ //以斜杠开头的名称,这是POSIX消息队列的命名规范,表示这是一个全局可访问的队列名称。char *mq_name = "/p_c_mq"; struct mq_attr attr; attr.mq_flags = 0; // 非阻塞标志,设为0表示阻塞模式attr.mq_maxmsg = 10; // 队列能容纳的最大消息数attr.mq_msgsize = 100; // 每条消息的最大字节数attr.mq_curmsgs = 0; // 当前队列中的消息数(初始化为0)// 创建或打开消息队列 //O_CREAT: 如果队列不存在则创建//O_WRONLY: 以只写模式打开//0666: 设置权限(所有用户可读写)mqd_t mqdes = mq_open(mq_name, O_CREAT | O_WRONLY, 0666, &attr); if (mqdes == (mqd_t)-1) { perror("mq_open"); } char writeBuf[100]; struct timespec time_info; while (1) { // 清空写缓冲区 memset(writeBuf, 0, 100); // 从命令行标准输入读取数据 ssize_t read_count = read(0, writeBuf, 100); if (read_count == -1) { perror("read"); continue; } else if (read_count == 0) { } // 获取当前时间中5s之后的timespec对象 clock_gettime(CLOCK_REALTIME, &time_info); time_info.tv_sec += 5; // 发送数据 // 如果接收到命令行的EOF,read将返回0,此时向消费者端发送信息并退出 if (read_count == 0) { printf("Received EOF, exit...\n"); char eof = EOF; //参数1:消息队列描述符//参数2:要发送的消息内容//参数3:消息长度//参数4:消息优先级(0表示默认)//参数5:超时时间(如果队列已满,将等待直到超时)if (mq_timedsend(mqdes, &eof, 1, 0, &time_info) == -1) { perror("mq_timedsend"); } break; } // 没有接收到EOF,正常发送数据 if (mq_timedsend(mqdes, writeBuf, strlen(writeBuf), 0, &time_info) == -1) { perror("mq_timesend"); } printf("从命令行接收到数据,已发送至消费者端\n"); } // 关闭描述符 close(mqdes); // mq_unlink 只应调用一次,我们选择在消费者中完成此操作 return 0;
} consumer.c
#include <time.h>
#include <mqueue.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h> int main()
{ char *mq_name = "/p_c_mq"; struct mq_attr attr; attr.mq_flags = 0; attr.mq_maxmsg = 10; attr.mq_msgsize = 100; attr.mq_curmsgs = 0; // 创建或打开消息队列 mqd_t mqdes = mq_open(mq_name, O_CREAT | O_RDONLY, 0666, &attr); if (mqdes == -1) { perror("mq_open"); } char readBuf[100]; struct timespec time_info; while (1) { memset(readBuf, 0, 100); // 获取1天后的time_spec结构对象,目的是在测试期间使得消费者一直等待生产者发送的数据 clock_gettime(CLOCK_REALTIME, &time_info); time_info.tv_sec += 86400; // 接收数据 if (mq_timedreceive(mqdes, readBuf, 100, NULL, &time_info) == 1) { perror("mq_timedreceive"); } // 如果收到生产者发送的EOF,则结束进程 if (readBuf[0] == EOF) { printf("接收到生产者的终止信号,准备退出...\n"); break; } // 如果没有收到EOF,将接收到的数据打印到标准输出 printf("接收到来自于生产者的数据\n%s", readBuf); } // 释放消息队列描述符 close(mqdes); // mq_unlink 只应调用一次 // 清除消息队列 mq_unlink(mq_name);
}
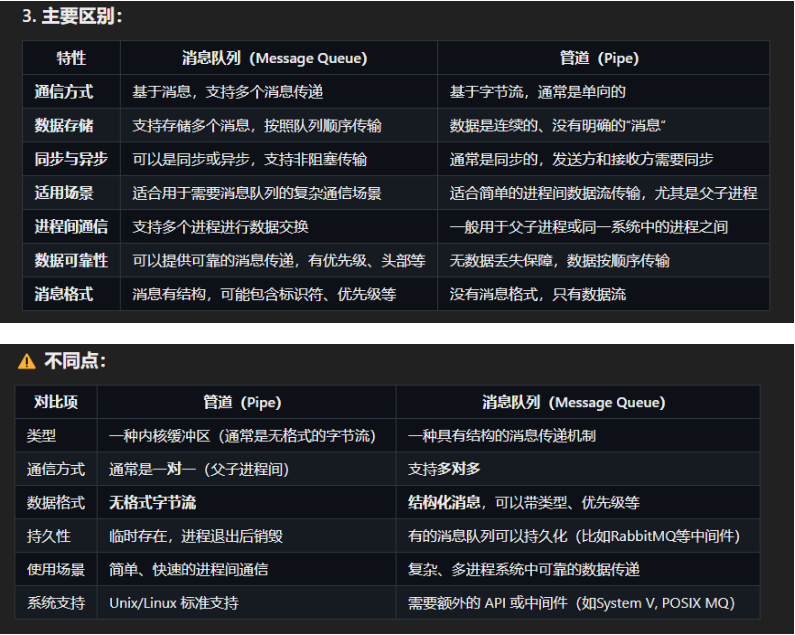
我们可以通过设置POSIX消息队列的模式为O_RDWR,使它可以用于收发数据,从技 术上讲,单条消息队列可以用于双向通信,但是这会导致消息混乱,无法确定队列中的数 据是本进程写入的还是读取的,因此,不会这么做,通常单条消息队列只用于单向通信。 为了实现全双工通信,我们可以使用两条消息队列,分别负责两个方向的通信。类似于管道。
信号
在Linux 中,信号是一种用于通知进程发生了某种事件的机制。信号可以由内核、其 他进程或者通过命令行工具发送给目标进程。Linux系统中有多种信号,每种信号都用一 个唯一的整数值来表示
可以通过signal系统调用注册信号处理函数:
单片机里的中断回调类似
#include <signal.h> // 信号处理函数声明
typedef void (*sighandler_t)(int); /** * signal系统调用会注册某一信号对应的处理函数。如果注册成功,当进程收到这一
信号时,将不会调用默认的处理函数,而是调用这里的自定义函数 * * int signum: 要处理的信号 * sighandler_t handler: 当收到对应的signum信号时,要调用的函数 * return: sighandler_t 返回之前的信号处理函数,如果错误会返回SEG_ERR */
sighandler_t signal(int signum, sighandler_t handler);
信号捕捉
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/time.h>
#include <signal.h>// 定时器信号的处理动作
void doing(int arg)
{printf("当前捕捉到的信号是: %d\n", arg);// 打印当前的时间
}int main()
{// 注册要捕捉哪一个信号, 执行什么样的处理动作signal(SIGALRM, doing);// 1. 调用定时器函数设置定时器函数struct itimerval newact;// 3s之后发出第一个定时器信号, 之后每隔1s发出一个定时器信号newact.it_value.tv_sec = 3;newact.it_value.tv_usec = 0;newact.it_interval.tv_sec = 1;newact.it_interval.tv_usec = 0;// 这个函数也不是阻塞函数, 函数调用成功, 倒计时开始// 倒计时过程中程序是继续运行的setitimer(ITIMER_REAL, &newact, NULL);// 编写一个业务处理, 阻止当前进程自己结束, 让当前进程被发出的信号杀死while(1){sleep(1000000);}return 0;
}
SIGCHLD信号
当子进程退出、暂停、从暂停回复运行的时候,在子进程中会产生一个********SIGCHLD信号****,并将其发送给父进程,但是父进程收到这个信号之后默认就忽略了。我们可以在父进程中对这个信号加以利用,基于这个信号来回收子进程的资源,因此需要在父进程中捕捉子进程发送过来的这个信号。
以下这段代码的例子,主要演示了如何通过捕捉 SIGCHLD 信号来处理子进程的退出事件,回收(清理)子进程的资源。通过这种方式,父进程可以确保在子进程退出后,正确地回收它们的资源,避免僵尸进程的产生。代码的核心是信号处理、子进程管理和信号阻塞与解除阻塞。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
#include <signal.h>// 回收子进程处理函数
void recycle(int num)
{printf("捕捉到的信号是: %d\n", num);// 子进程的资源回收, 非阻塞// SIGCHLD信号17号信号, 1-31号信号不支持排队// 如果这些信号同时产生多个, 最终处理的时候只处理一次// 假设多个子进程同时退出, 父进程同时收到了多个sigchld信号// 父进程只会处理一次这个信号, 因此当前函数被调用了一次, waitpid被调用一次// 相当于只回收了一个子进程, 但是是同时死了多个子进程, 因此就出现了僵尸进程// 解决方案: 循环回收即可while(1){// 如果是阻塞回收, 就回不到另外一个处理逻辑上去了pid_t pid = waitpid(-1, NULL, WNOHANG);if(pid > 0){printf("child died, pid = %d\n", pid);}else if(pid == 0){// 没有死亡的子进程, 直接退出当前循环break;}else if(pid == -1){printf("所有子进程都回收完毕了, 拜拜...\n");break;}}
}
/*
SIGCHLD 信号:该信号会在一个子进程退出时发送给父进程。父进程可以通过捕捉这个信号来回收子进程的资源(避免僵尸进程)。waitpid(-1, NULL, WNOHANG):此函数用于非阻塞地回收子进程的资源。-1:表示等待任意一个子进程。
NULL:表示我们不关心子进程的退出状态。
WNOHANG:表示非阻塞方式,如果没有子进程退出,它不会阻塞,直接返回。
pid > 0:当 waitpid 返回一个正数时,表示成功回收了一个子进程,pid 是该子进程的进程ID。pid == 0:表示没有子进程退出,当前没有需要回收的子进程,退出循环。pid == -1:表示没有更多的子进程可以回收,意味着所有的子进程都已经退出并且被回收了。通过 while(1) 循环不断调用 waitpid 来回收所有的子进程,直到没有需要回收的子进程为止。
*/int main()
{// 设置sigchld信号阻塞sigset_t myset;//创建一个信号集 mysetsigemptyset(&myset);//初始化信号集sigaddset(&myset, SIGCHLD);//将 SIGCHLD 信号添加到该信号集中sigprocmask(SIG_BLOCK, &myset, NULL);//阻塞 SIGCHLD 信号:通过 sigprocmask(SIG_BLOCK, &myset, NULL) 阻塞 //SIGCHLD 信号,这意味着在子进程退出时,父进程不会立刻接收到 SIGCHLD 信号,而 //是将其阻塞住,直到父进程明确解除阻塞。// 循环创建多个子进程 - 20;父进程通过 fork 创建 20 个子进程。pid_t pid;for(int i=0; i<20; ++i){pid = fork();if(pid == 0){break;}}
//此时,子进程会开始执行下面的代码,而父进程继续执行父进程部分的代码。if(pid == 0){printf("我是子进程, pid = %d\n", getpid());}else if(pid > 0){printf("我是父进程, pid = %d\n", getpid());// 注册信号捕捉, 捕捉sigchldstruct sigaction act;//声明一个 sigaction 结构体,sigaction 用来定义当特定信号到来时,应该如何处理该信号。act.sa_flags =0;//设置 sa_flags 为 0,表示没有特殊的标志,这里没有附加额外的处理选项。act.sa_handler = recycle;//指定信号处理函数为 recycle。当父进程收到 SIGCHLD 信号时,内核会调用 recycle 函数来 //处理信号。sigemptyset(&act.sa_mask);//清空 sa_mask,sa_mask 是一个信号集,它用于在信号处理函数执行期间阻塞其他信号。这里清 //空 sa_mask 表示在处理 SIGCHLD 信号时,不会阻塞其他信号。// 注册信号捕捉, 委托内核处理将来产生的信号// 当信号产生之后, 当前进程优先处理信号, 之前的处理动作会暂停// 信号处理完毕之后, 回到原来的暂停的位置继续运行//使用 sigaction 函数注册信号处理器。这里将 SIGCHLD 信号的处理程序设置为 recycle,也就是说,当 SIGCHLD 信号发生 //时,父进程会调用 recycle 函数来处理。sigaction(SIGCHLD, &act, NULL);// 解除sigcld信号的阻塞// 信号被阻塞之后,就捕捉不到了, 解除阻塞之后才能捕捉到这个信号//在程序开始时,我们通过 sigprocmask(SIG_BLOCK, &myset, NULL); 阻塞了 SIGCHLD 信号。这样做的目的是让父进程可以 //先执行其他工作,等到合适的时机再捕捉并处理 SIGCHLD 信号。//这行代码的作用是解除阻塞,这样父进程可以正常捕捉到 SIGCHLD 信号。解除阻塞之后,当有子进程退出时,父进程就会收到 //SIGCHLD 信号,进而执行 recycle 函数来回收子进程的资源。sigprocmask(SIG_UNBLOCK, &myset, NULL);// 父进程执行其他业务逻辑就可以了// 默认父进程执行这个while循环, 但是信号产生了, 这个执行逻辑或强迫暂停// 父进程去处理信号的处理函数while(1){sleep(100);}}return 0;
}
主要流程
- 父进程:
- 父进程首先通过
sigprocmask(SIG_BLOCK, ...)阻塞SIGCHLD信号,以防在创建子进程后立即处理该信号。- 然后通过
sigaction注册SIGCHLD信号的处理函数recycle,这样当有子进程退出时,父进程会处理这个信号并回收子进程的资源。- 解除对
SIGCHLD的阻塞,允许父进程捕捉并处理信号。- 父进程进入一个
while(1)循环,通过sleep(100)保持运行,等待信号的到来。当子进程退出并发送SIGCHLD信号时,父进程会暂停当前的执行,转而调用recycle函数处理信号。- 信号处理:
- 当子进程退出时,内核会向父进程发送
SIGCHLD信号。- 父进程捕捉到该信号后,执行
recycle函数,该函数会调用waitpid非阻塞地回收子进程资源,避免产生僵尸进程。- 如果有多个子进程退出,
recycle会在while(1)循环中继续回收直到所有退出的子进程都被回收。
守护进程
守护进程是 Linux 中的后台服务进程。它是一个生存期较长的进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。一般采用以d结尾的名字。
守护进程通常由会话技术生成,会话就是与一组相关的进程的集合(他所在的圈子),守护进程就是后台的一个独立运行的程序与某类无关,所以要让他彻底脱离当前的会话也就是之前与他相关的所有的进程集合(他所在的圈子)。
其中有如下知识要注意,使用这个函数的注意事项:
调用这个函数的进程不能是组长进程, 如果是该函数调用失败,如果保证这个函数能调用成功呢?
先fork()创建子进程, 终止父进程, 让子进程调用这个函数
如果调用这个函数的进程不是进程组长, 会话创建成功
这个进程会变成当前会话中的第一个进程,同时也会变成新的进程组的组长
该函数调用成功之后, 当前进程就脱离了控制终端,因此不会阻塞终端
什么是会话(Session)?
在 UNIX 系统中,会话(Session) 是一组相关的进程集合。每个会话都有一个会话领导进程(Session Leader),通常是第一个启动的进程,其他进程都属于这个会话。
会话的管理包括以下几个方面:
- 会话领导进程:是会话中的第一个进程,通常是终端启动的进程(如 shell)。
- 会话成员:属于这个会话的所有进程,可以是子进程或其他派生的进程。
- 终端控制:会话领导进程通常会与某个终端关联。会话中的进程可以通过终端进行交互式操作。
什么是守护进程(Daemon)?
守护进程(Daemon) 是一种在后台运行、通常没有用户交互的进程。它通常会在系统启动时自动启动,并且负责某些长期运行的服务任务。守护进程的特点包括:
- 不与终端关联:守护进程不会通过终端与用户交互。它通常会与某个终端脱离,并且不依赖于用户的登录或退出。
- 后台运行:守护进程通常在后台持续运行,负责处理某些任务,比如定时任务、网络服务等。
- 独立于父进程:守护进程通常会脱离原来的控制终端,并且在创建时会被“孤立”,因此它不受父进程的影响。
守护进程和会话的关系
守护进程的创建过程通常涉及到会话的管理。具体来说,守护进程通常是通过以下几个步骤与会话进行关联的:
创建子进程:
- 通常,守护进程是通过调用
fork()来创建的。父进程会退出,子进程继续运行。父进程的退出确保了守护进程不会依赖于终端的生命周期。脱离控制终端,成为新的会话领导进程:
- 调用
setsid()函数是将子进程变成一个新的会话的领导进程,脱离原先的终端控制。这样,守护进程就不再是原会话的一部分,它从新的会话开始独立运行,成为新的会话的“会话领导进程”。- 这也使得守护进程从原先的终端和控制进程(如父进程)中独立出来,避免了它们与终端的依赖关系。
与会话的其他进程隔离:
- 调用
setsid()后,守护进程成为新会话的领导进程,但它也会脱离与任何终端的联系(如果有的话)。这意味着它不再接受任何终端的输入或输出,成为一个不依赖终端的后台进程。工作目录和文件权限:
守护进程通常会调用
chdir()来更改工作目录,通常将其更改为一个稳定的、不会被删除的目录(例如/或/home/robin),避免在父进程终止或终端关闭时对工作目录造成影响。此外,守护进程还会调用
umask()设置文件权限,以保证文件创建时有适当的权限。为什么守护进程要脱离会话?
脱离当前会话的原因在于:
- 独立性:守护进程通常不依赖于用户的登录会话,脱离会话可以确保守护进程在后台独立运行,不会因为终端关闭、用户退出等操作而终止。
- 避免信号干扰:如果守护进程仍然处于原会话中,它可能会接收到由终端或父进程发送的信号(例如,终端关闭时会发送
SIGHUP信号)。通过setsid()将其脱离会话,可以避免这些干扰。- 确保后台运行:守护进程脱离控制终端后,不再与用户交互,也不会被用户终端关闭而终止。这样,它就可以在后台持续运行执行特定任务。
总结
- 会话 是一组相关进程的集合,一个会话通常由一个会话领导进程和若干会话成员进程组成。
- 守护进程 是脱离会话的独立后台进程,它通常不与终端或任何用户会话挂钩。
- 守护进程与会话的关系:守护进程创建时通常会调用
setsid()来成为一个新的会话领导进程,并且脱离原始会话与终端的关联。这样可以确保守护进程在后台独立运行,不受父进程或终端会话的影响。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <signal.h>
#include <sys/time.h>
#include <time.h>// 信号的处理动作
void writeFile(int num)
{// 得到系统时间time_t seconds = time(NULL);// 时间转换, 总秒数 -> 可以识别的时间字符串struct tm* loc = localtime(&seconds);// sprintf();char* curtime = asctime(loc); // 自带换行// 打开一个文件, 如果文件不存在, 就创建, 文件需要有追加属性// ./对应的是哪个目录? /home/robin// 0664 & ~022int fd = open("./time+++++++.log", O_WRONLY|O_CREAT|O_APPEND, 0664);write(fd, curtime, strlen(curtime));close(fd);
}int main()
{// 1. 创建子进程, 杀死父进程:创建子进程, 让父进程退出是因为父进程有可能是组长进程,不符合条件,也没有什么利用价值,退出即 //可子进程没有任何职务, 目的是让子进程最终变成一个会话, 最终就会得到守护进程pid_t pid = fork();if(pid > 0){// 父进程exit(0); // kill(getpid(), 9); raise(9); abort();}// 2. 子进程, 将其变成会话, 脱离当前终端。让子进程成为新的会话领袖(Session Leader),脱离当前终端。这是创建守护进程的标 //准做法,目的是让子进程不再与终端挂钩,从而成为一个真正的后台进程。setsid();// 3. 修改进程的工作目录, 修改到一个不能被修改和删除的目录中 /home/robinchdir("/home/robin");// 4. 设置掩码, 在进程中创建文件的时候这个掩码就起作用了//掩码: umask, 在创建新文件的时候需要和这个掩码进行运算, 去掉文件的某些权限//设置进程的文件创建掩码,文件权限会被掩码过滤。例如,掩码 022 表示创建文件时,文件的权限会去掉写权限,使得创建的文件对其他 //用户不可写。默认的文件权限是 0666(所有用户都可以读写),应用掩码后,创建的文件权限变为 0644。umask(022);// 5. 重定向和终端关联的文件描述符 -> /dev/null//dev/null 是一个特殊的设备文件,所有写入到它的数据都会被丢弃,相当于黑洞。这意味着守护进程不会输出任何日志或错误信息到终 //端,保持后台静默运行。int fd = open("/dev/null", O_RDWR);dup2(fd, STDIN_FILENO);dup2(fd, STDOUT_FILENO);dup2(fd, STDERR_FILENO);// 5. 委托内核捕捉并处理将来发生的信号-SIGALRM(14)//SIGALRM 通常用于定时任务,这里用来触发写入日志文件的操作。struct sigaction act;act.sa_flags = 0;act.sa_handler = writeFile;sigemptyset(&act.sa_mask);sigaction(SIGALRM, &act, NULL);// 6. 设置定时器struct itimerval val;val.it_value.tv_sec = 2;val.it_value.tv_usec = 0;val.it_interval.tv_sec = 2;val.it_interval.tv_usec = 0;setitimer(ITIMER_REAL, &val, NULL);
//进入一个无限循环,保持进程持续运行。虽然程序在不停地调用 sleep(100) 让进程休眠,但定时器和信号仍会按预定的间隔触发,调用 //writeFile 函数将当前时间记录到文件中。while(1){sleep(100);}return 0;
}
总结
- 创建子进程:通过
fork()创建子进程,父进程终止,子进程成为守护进程。- 守护进程配置:通过
setsid()脱离终端,chdir()改变工作目录,umask()设置文件创建掩码,重定向标准输入输出到/dev/null。- 信号处理:通过
sigaction()注册SIGALRM信号处理函数为writeFile,定时触发信号并写入日志文件。- 定时器设置:通过
setitimer()设置定时器,触发信号,每隔 2 秒写入当前时间。这段代码的主要作用是创建一个后台守护进程,每隔 2 秒将当前时间写入到
time+++++++.log文件中。