10-day07文本分类
文本分类使用场景


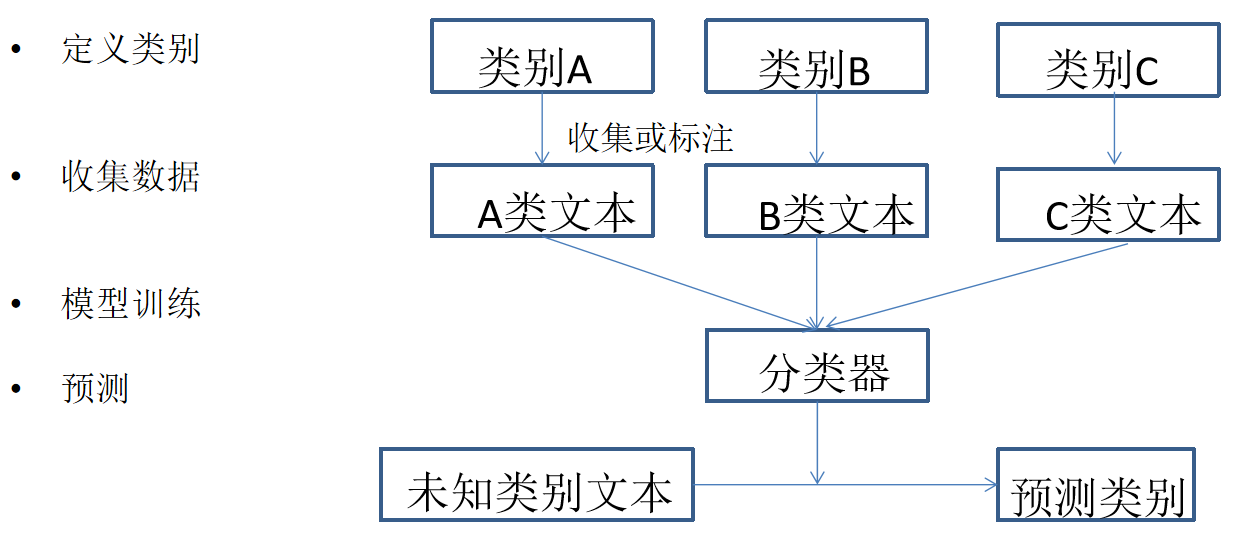
- 文本分类任务

- 文本分类-机器学习
贝叶斯算法
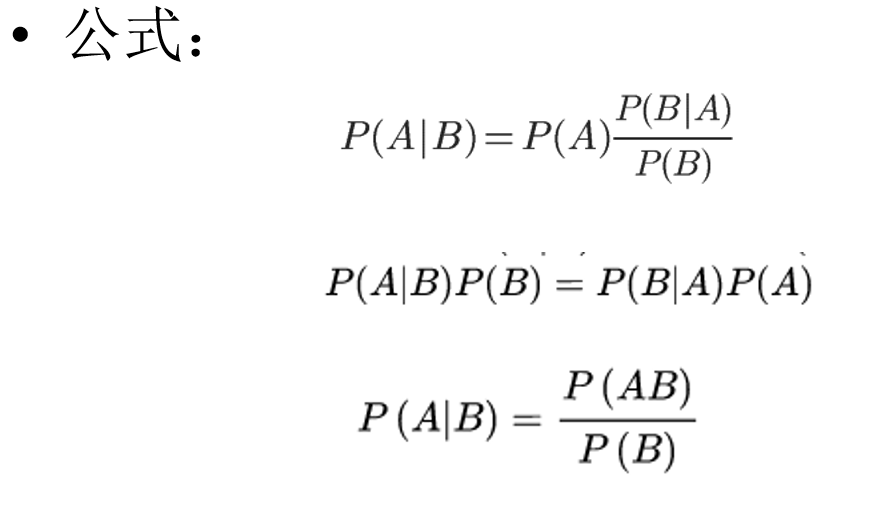
- 应用

- 在NLP中的应用
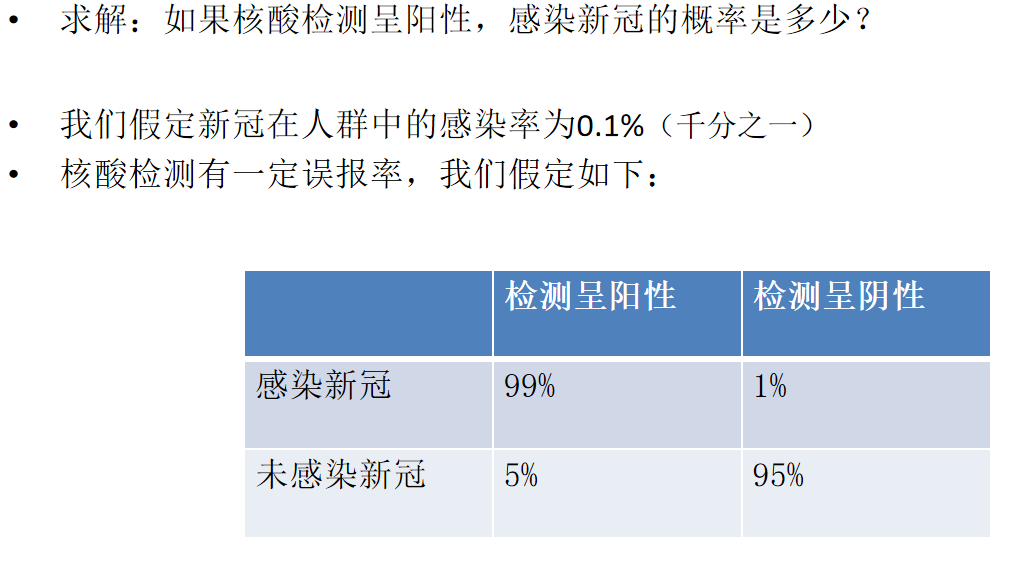
用贝叶斯公式处理文本分类任务
一个合理假设:
文本属于哪个类别,与文本中包含哪些词相关
任务:
知道文本中有哪些词,预测文本属于某类别的概率

- 贝叶斯算法优点
1.简单高效
2.一定的可解释性
3.如果样本覆盖的好,效果是不错的
4.训练数据可以很好的分批处理 - 贝叶斯算法缺点
1.如果样本不均衡会极大影响先验概率
2.对于未见过的特征或样本,条件概率为零,失去预测的意义(可以引入平滑)
3.特征独立假设只是个假设
4.没有考虑语序,也没有词义
import jieba
import json
from collections import defaultdictjieba.initialize()
"""
贝叶斯分类实践
P(A|B) = (P(A) * P(B|A)) / P(B)
事件A:文本属于类别x1。文本属于类别x的概率,记做P(x1)
事件B:文本为s (s=w1w2w3..wn)
P(x1|s) = 文本为s,属于x1类的概率. #求解目标#
P(x1|s) = P(x1|w1, w2, w3...wn) = P(w1, w2..wn|x1) * P(x1) / P(w1, w2, w3...wn)
P(x1) 任意样本属于x1的概率。x1样本数/总样本数
P(w1, w2..wn|x1) = P(w1|x1) * P(w2|x1)...P(wn|x1) 词的独立性假设
P(w1|x1) x1类样本中,w1出现的频率
公共分母的计算,使用全概率公式:
P(w1, w2, w3...wn) = P(w1,w2..Wn|x1)*P(x1) + P(w1,w2..Wn|x2)*P(x2) ... P(w1,w2..Wn|xn)*P(xn)
"""
class BayesApproach:def __init__(self, data_path):self.p_class = defaultdict(int)self.word_class_prob = defaultdict(dict)self.load(data_path)def load(self, path):self.class_name_to_word_freq = defaultdict(dict)self.all_words = set() #汇总一个词表with open(path, encoding="utf8") as f:for line in f:line = json.loads(line)class_name = line["tag"]title = line["title"]words = jieba.lcut(title)self.all_words = self.all_words.union(set(words))self.p_class[class_name] += 1 #记录每个类别样本数量word_freq = self.class_name_to_word_freq[class_name]#记录每个类别下的词频for word in words:if word not in word_freq:word_freq[word] = 1else:word_freq[word] += 1self.freq_to_prob()return#将记录的词频和样本频率都转化为概率def freq_to_prob(self):#样本概率计算total_sample_count = sum(self.p_class.values())self.p_class = dict([c, self.p_class[c] / total_sample_count] for c in self.p_class)#词概率计算self.word_class_prob = defaultdict(dict)for class_name, word_freq in self.class_name_to_word_freq.items():total_word_count = sum(count for count in word_freq.values()) #每个类别总词数for word in word_freq:#加1平滑,避免出现概率为0,计算P(wn|x1)prob = (word_freq[word] + 1) / (total_word_count + len(self.all_words))self.word_class_prob[class_name][word] = probself.word_class_prob[class_name]["<unk>"] = 1/(total_word_count + len(self.all_words))return#P(w1|x1) * P(w2|x1)...P(wn|x1)def get_words_class_prob(self, words, class_name):result = 1for word in words:unk_prob = self.word_class_prob[class_name]["<unk>"]result *= self.word_class_prob[class_name].get(word, unk_prob)return result#计算P(w1, w2..wn|x1) * P(x1)def get_class_prob(self, words, class_name):#P(x1)p_x = self.p_class[class_name]# P(w1, w2..wn|x1) = P(w1|x1) * P(w2|x1)...P(wn|x1)p_w_x = self.get_words_class_prob(words, class_name)return p_x * p_w_x#做文本分类def classify(self, sentence):words = jieba.lcut(sentence) #切词results = []for class_name in self.p_class:prob = self.get_class_prob(words, class_name) #计算class_name类概率results.append([class_name, prob])results = sorted(results, key=lambda x:x[1], reverse=True) #排序#计算公共分母:P(w1, w2, w3...wn) = P(w1,w2..Wn|x1)*P(x1) + P(w1,w2..Wn|x2)*P(x2) ... P(w1,w2..Wn|xn)*P(xn)#不做这一步也可以,对顺序没影响,只不过得到的不是0-1之间的概率值pw = sum([x[1] for x in results]) #P(w1, w2, w3...wn)results = [[c, prob/pw] for c, prob in results]#打印结果for class_name, prob in results:print("属于类别[%s]的概率为%f" % (class_name, prob))return resultsif __name__ == "__main__":path = "../data/train_tag_news.json"ba = BayesApproach(path)query = "中国三款导弹可发射多弹头 美无法防御很急躁"ba.classify(query)
支持向量机SVM
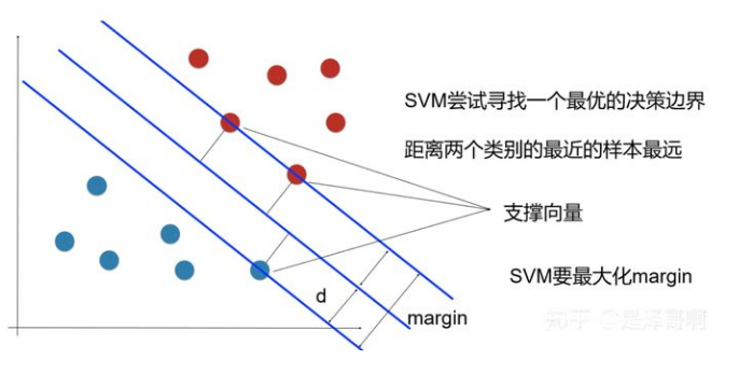
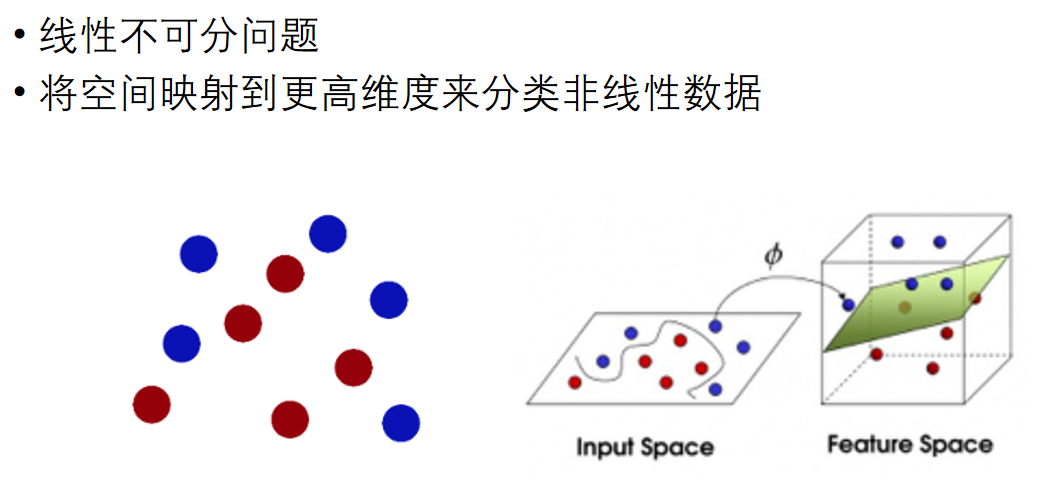
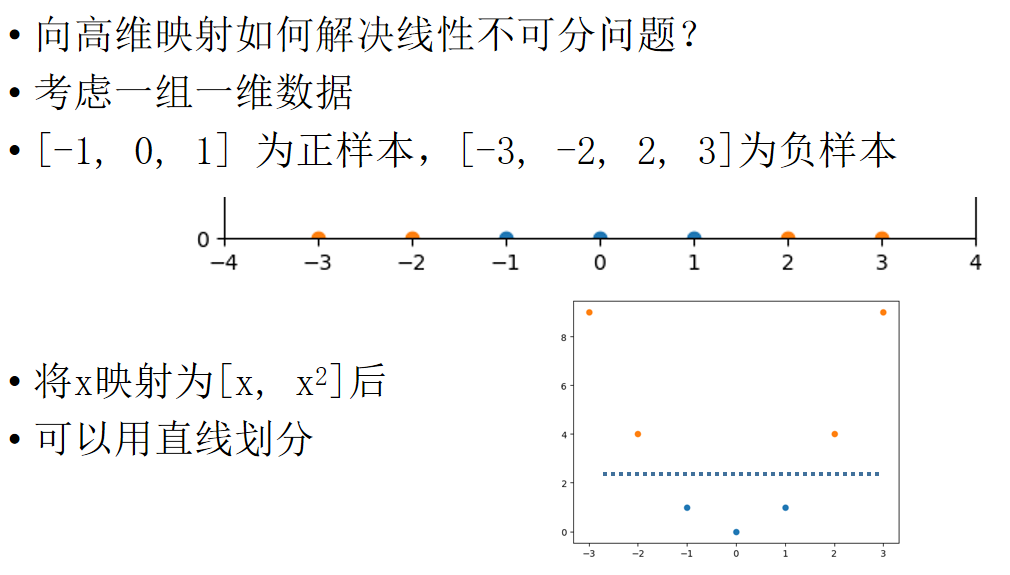
解决多分类
假设要解决一个K分类问题,即有K个目标类别
-
one vs one方式
建立 K(K - 1)/2 个svm分类器,每个分类器负责K个类别中的两个类别,判断输入样本属于哪个类别
对于一个待预测的样本,使用所有分类器进行分类,最后保留被预测词数最多的类别
假设类别有[A,B,C]
X->SVM(A,B)->A
X->SVM(A,C)->A
X->SVM(B,C)->B
最终判断 X->A -
one vs rest方式
建立K个svm分类器,每个分类器负责划分输入样本属于K个类别中的“某一个类别,还是其他类别”
最后保留预测分值最高的类别
假设类别有[A,B,C]
X->SVM(A,rest)->0.1
X->SVM(B,rest)->0.2
X->SVM(C,rest)->0.5
最终判断 X->C -
支持向量机优点
1.少数支持向量决定了最终结果,对异常值不敏感
2.对于样本数量需求较低
3.可以处理高维度数据 -
支持向量机缺点
1.少数支持向量决定了最终结果,对异常值不敏感
2.对于样本数量需求较低
3.可以处理高维度数据