血条识别功能实现及原理
从零开始学Python图像处理 - 血条识别
从实际问题中能快速的学习特定技能,通过完成一个能自动刷怪的工具,达成快速学习python图像处理和识别。
自动刷怪需要先识别怪物,在游戏中怪物类型很多,同时在移动中形态会一直发生变化,通过怪物图片来匹配难度太大,因此需要另辟蹊径。通过观察在所有怪物头顶存在红色血条,这个问题可以转化成识别红色血条,将 Y 坐标下移即是怪物的位置。
基本功能实现
import cv2 as cv
import numpy as npdef main_findMonster():"""主函数:用于检测图像中的特定目标(如怪物)该函数读取图像,将其从BGR颜色空间转换为HSV颜色空间,然后使用预定义的HSV范围创建阈值掩码,以识别图像中的特定目标。最后,使用形态学处理和轮廓检测来定位目标,并显示结果图像。"""# 读取目标图像,图像为BGR三通道格式target_bgr = cv.imread(image_path)# 将图像从BGR颜色空间转换为HSV颜色空间target_hsv = cv.cvtColor(target_bgr, cv.COLOR_BGR2HSV)# 创建两个阈值掩码,分别针对HSV颜色空间中的两个不同范围# 这是为了更好地检测图像中的特定颜色(如红色)threshold_mask1 = cv.inRange(target_hsv, (0, 180, 150), (10, 255, 255))threshold_mask2 = cv.inRange(target_hsv, (175, 180, 150), (180, 255, 255))# 将两个阈值掩码合并,以覆盖更广的颜色范围threshold_mask = threshold_mask1 + threshold_mask2# 设置形态学处理的核kernel_size = (5, 5)kernel = cv.getStructuringElement(cv.MORPH_RECT, kernel_size)# 形态学操作mask1 = cv.morphologyEx(threshold_mask, cv.MORPH_CLOSE, kernel)mask2 = cv.dilate(mask1, kernel, iterations=2)# 显示拼接图target_gray = cv.cvtColor(target_bgr, cv.COLOR_BGR2GRAY)# 轮廓检测与标记contours, _ = cv.findContours(mask2, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)display_img = target_bgr.copy()for cnt in contours:x, y, w, h = cv.boundingRect(cnt)if h * 2 < w < h * 10:cv.rectangle(display_img, (x, y-5), (x + w, y), (255, 0, 0), 2)cv_show('Result', display_img)

以上代码中使用 OpenCV 来完成功能,涉及到的函数功能说明如下:
cv.imread:读取图片cv.inRange:指定的颜色范围从图像中提取目标区域cv.morphologyEx/cv.dilate:形态学操作cv.findContours: 轮廓检测与标记
颜色阈值分割
cv.inRange是 OpenCV 中用于颜色阈值分割的核心函数。其主要作用是根据指定的颜色范围从图像中提取目标区域,生成一个二值掩码(Mask),便于后续的图像处理和分析。
原理,对输入图像的每个像素进行判断:
- 若像素值在
[lowerb, upperb]范围内 → 输出掩码中对应位置设为 255(白色)。 - 若像素值超出范围 → 输出掩码中对应位置设为 0(黑色)
支持多通道处理
- 可处理单通道(灰度图)或多通道图像(如 RGB、HSV)
- 多通道规则:像素需在所有通道上同时满足范围条件才会被保留
cv2.inRange(InputArray src, # 输入图像(单/多通道)InputArray lowerb, # 范围下界(Scalar 或数组)InputArray upperb, # 范围上界(Scalar 或数组)OutputArray dst # 输出二值掩码(单通道二值图 CV_8U 类型)
);
案例:
def test_inRange():# 读取图像img = cv2.imread("./image/img.png")if img is None:print("Error: Image not found.")return# 转换为 HSV 色彩空间hsv_img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)# 定义红色的 HSV 范围lower_red = np.array([0, 100, 100])upper_red = np.array([10, 255, 255])# 创建掩码mask1 = cv2.inRange(hsv_img, lower_red, upper_red)# 定义蓝色的 HSV 范围lower_blue = np.array([110, 50, 50])upper_blue = np.array([130, 255, 255])# 创建掩码mask2 = cv2.inRange(hsv_img, lower_blue, upper_blue)# 定义绿色的 HSV 范围lower_green = np.array([50, 100, 100])upper_green = np.array([70, 255, 255])# 创建掩码mask3 = cv2.inRange(hsv_img, lower_green, upper_green)mask = merge_images_with_white_gap([mask1, mask2, mask3], gap=20, scaling=0.3)# 显示结果cv_show("Mask", mask)

形态学操作
形态学操作是图像处理中一种基于形状的处理技术,主要用于分析和处理图像中的几何结构。它通常作用于二值图像,但也可以应用于灰度图像。
形态学操作的核心思想是使用一个称为"结构元素"(kernel)的模板在图像上滑动,并根据结构元素与图像局部区域的相互作用来改变图像的形状。常见的结构元素形状有矩形、椭圆和十字形。
基本形态学操作包括:
- 腐蚀(Erosion):使图像中的前景物体(通常为白色区域)缩小或"变瘦",通过取局部最小值实现。可以用来消除小噪声点或分离接触的物体
- 膨胀(Dilation):使前景物体扩大或"变胖",通过取局部最大值实现。可以填充小孔洞或连接断裂的部分
- 开运算(Opening):先腐蚀后膨胀的操作组合。可以去除小的噪声点和平滑物体边缘
- 闭运算(Closing):先膨胀后腐蚀的操作组合。可以填充物体内部的小孔洞和连接邻近物体
高级形态学操作包括:
- 形态学梯度(Morphological Gradient):膨胀图减去腐蚀图,得到物体的轮廓
- 顶帽变换(Top Hat):原图减去开运算图,用于突出比结构元素小的亮区域
- 黑帽变换(Black Hat):闭运算图减去原图,用于突出比结构元素小的暗区域
基本操作与原理
| 作用 | 原理 | 函数 | |
|---|---|---|---|
| 腐蚀(Erosion) | 使前景物体(白色区域)“变瘦”,消除小噪声点或分离粘连物体 | 结构元素覆盖区域内,若存在黑色像素(值为0),则中心点置为黑色(取局部最小值) | cv2.erode(img, kernel) |
| 膨胀(Dilation) | 使前景物体“变胖”,填充孔洞或连接断裂部分 | 结构元素覆盖区域内,若存在白色像素(255),则中心点置为白色(取局部最大值) | cv2.dilate(img, kernel) |
| 开运算(Opening) | 消除细小噪声和平滑边界,保留主体形状(去外噪) | 先腐蚀后膨胀 | cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel) |
| 闭运算(Closing) | 填充物体内部小孔洞或裂缝(去内噪) | 先膨胀后腐蚀 | cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) |
| 形态学梯度(Morphological Gradient) | 突出物体轮廓(类似边缘检测) | 膨胀图减腐蚀图(dilation - erosion) | cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel) |
| 顶帽变换(Top Hat) | 提取比结构元素小的亮区域(如背景中的文字) | 原图减开运算图(src - opening) | |
| 黑帽变换(Black Hat) | 提取比结构元素小的暗区域(如显微图像中的细胞核) | 闭运算图减原图(closing - src) |
结构元素(Kernel)的设计
结构元素形状直接影响效果,常见类型:
- 矩形:
cv2.getStructuringElement(cv2.MORPH_RECT, (5,5)) - 椭圆:
cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5,5)) - 十字形:
cv2.getStructuringElement(cv2.MORPH_CROSS, (5,5))
尺寸选择:核越大,操作效果越显著,但可能过度失真。
腐蚀操作原理
形态学操作举例—腐蚀操作
def test_shape():img = cv2.imread("./image/1.png")hsv_img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)# 定义红色的 HSV 范围lower_red = np.array([0, 100, 100])upper_red = np.array([10, 255, 255])# 创建掩码mask1 = cv2.inRange(hsv_img, lower_red, upper_red)kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))mask2 = cv2.erode(mask1, kernel, iterations=1)mask3 = cv2.erode(mask1, kernel, iterations=2)mask = merge_images_with_white_gap([mask1, mask2, mask3], gap=20, scaling=0.4)# 显示结果cv_show("Mask", mask)
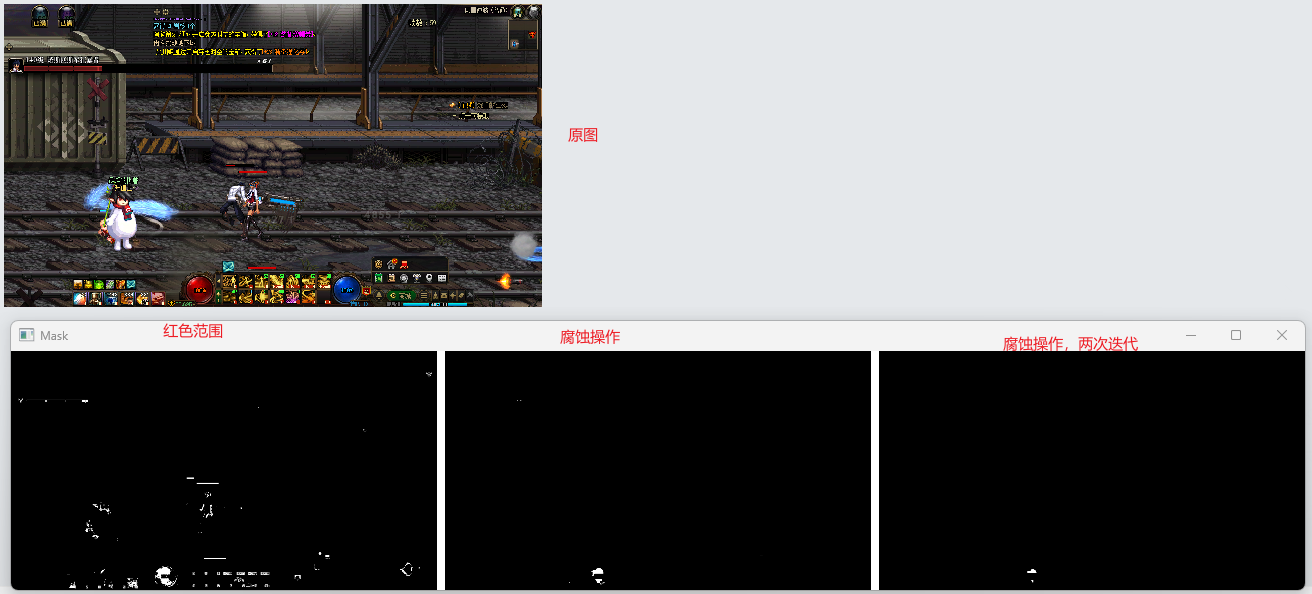
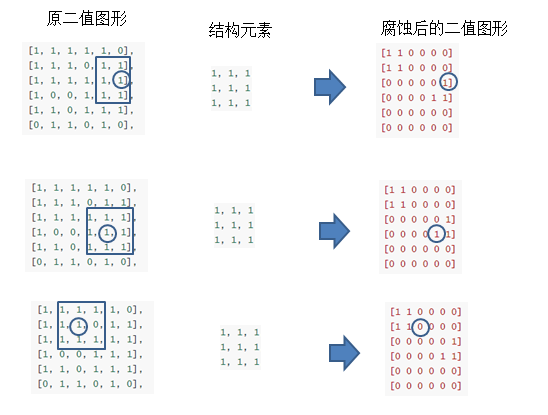
腐蚀操作原理深究,可分为如下四步:
- 定义结构元素(如
kernel = np.ones((3,3), np.uint8))。 - 结构元素中心遍历图像每个像素。
- 检查结构元素覆盖区域是否全为前景:
- 是 → 中心像素保留原值。
- 否 → 中心像素置为背景值(二值图)或邻域最小值(灰度图)
- 重复迭代(iterations 参数控制次数),每次迭代以上次输出为输入
前景(Foreground):在二值图像中,前景通常指目标物体(像素值为1或255,如白色区域);背景则为非目标区域(像素值为0,如黑色区域)
腐蚀的数学表达式为:
A⊖B=x∣Bx⊆A
其中 A 是图像,B 是结构元素。表示结构元素 B 平移至位置 x 时,B 完全包含于 A 内,则 x 属于腐蚀结果
img1 = np.array([[1, 1, 1, 1, 1, 0],[1, 1, 1, 0, 1, 1],[1, 1, 1, 1, 1, 1],[1, 0, 0, 1, 1, 1],[1, 1, 0, 1, 1, 1],[0, 1, 1, 0, 1, 0],],dtype=np.uint8,)kernel1_33 = np.ones((3, 3), np.uint8)a = cv2.erode(img1, kernel1_33, iterations=1)print("a:", a, )
"""
[[1 1 0 0 0 0][1 1 0 0 0 0][0 0 0 0 0 1][0 0 0 0 1 1][0 0 0 0 0 0][0 0 0 0 0 0]]"""
膨胀操作原理
形态学操作举例—膨胀操作
def test_shape2():img = cv2.imread("./image/1.png")hsv_img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)# 定义红色的 HSV 范围lower_red = np.array([0, 100, 100])upper_red = np.array([10, 255, 255])# 创建掩码mask1 = cv2.inRange(hsv_img, lower_red, upper_red)kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))mask2 = cv2.dilate(mask1, kernel, iterations=1)mask3 = cv2.dilate(mask1, kernel, iterations=2)mask = merge_images_with_white_gap([mask1, mask2, mask3], gap=20, scaling=0.4)# 显示结果cv_show("Mask", mask)
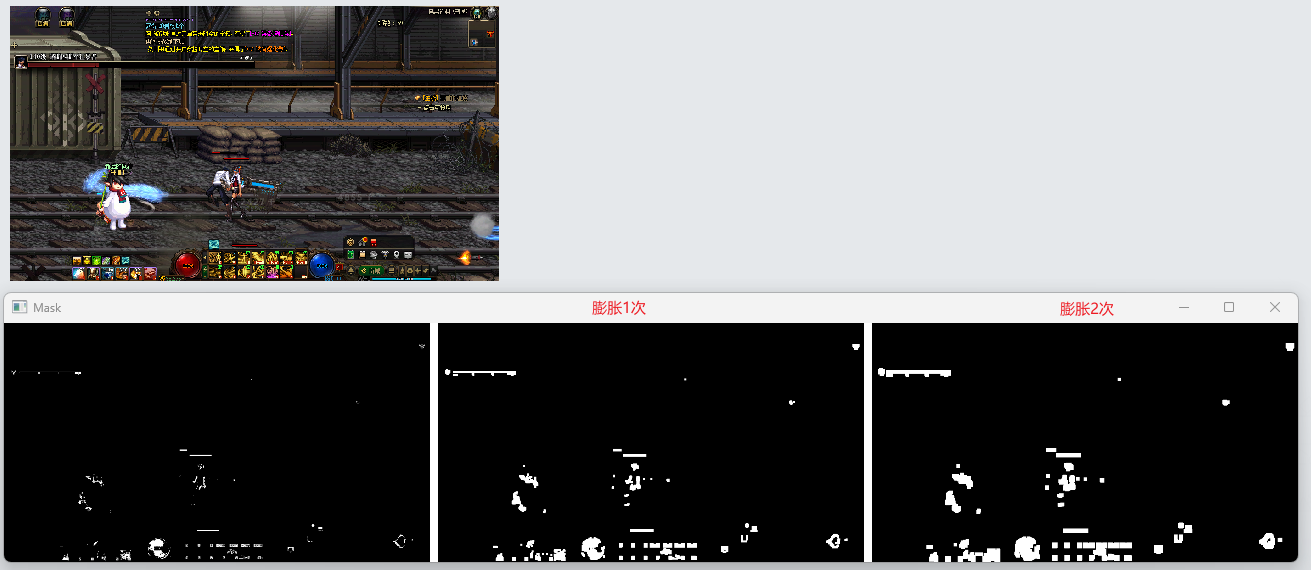
膨胀操作按以下流程执行:
- 定义结构元素:选择形状、尺寸(如3×3矩形核)。
- 遍历图像:结构元素中心从图像左上角开始滑动,覆盖每个像素位置。
- 计算与更新:对每个位置,检查结构元素覆盖区域:
- 二值图像:区域内存在前景像素则中心置1。
- 灰度图像:取区域内最大灰度值赋给中心。
- 重复至完成:遍历全图后输出膨胀图像
基本数学原理
膨胀操作的数学本质是局部最大值滤波:
公式表达:对于图像A和结构元素B,膨胀操作定义为:
(A⊕B)(x,y)=(i,j)∈B|max(A(x−i,y−j))
其中(x,y)是图像坐标,(i,j)是结构元素B的坐标。
操作逻辑:结构元素在图像上滑动,计算其覆盖区域内像素的最大值,并将该值赋给中心像素(锚点),邻域像素值 [70, 100, 130] 的膨胀结果为最大值 130
不同形态学操作对比

轮廓检测
cv.findContours 是 OpenCV 中用于从二值图像中提取物体轮廓的核心函数,常用于目标检测、形状分析和图像分割。
contours, hierarchy = cv.findContours(image, mode, method,[offset]
)
返回值:
contours:轮廓点坐标列表,每个轮廓是一个点集(NumPy数组)。hierarchy:轮廓层级关系,描述轮廓间的嵌套结构(OpenCV 3.x返回;4.x需用_, contours, _ = cv.findContours(...))
参数:
-
image:二值输入图像- 必须是单通道二值图(黑白),前景为白色(255),背景为黑色(0)。
- 需预处理:灰度化 → 二值化(如
cv.threshold)或边缘检测(如cv.Canny)
-
mode:轮廓检索模式模式 作用 cv.RETR_EXTERNAL只检测最外层轮廓(忽略内部孔洞)。 cv.RETR_LIST检测所有轮廓,不建立层级关系( hierarchy无效)。cv.RETR_CCOMP检测所有轮廓,组织为两层(外层+内孔)。 cv.RETR_TREE检测所有轮廓,建立完整的树形层级(嵌套轮廓分析) -
method:轮廓近似方法方法 特点 cv.CHAIN_APPROX_NONE保存轮廓所有连续点(数据量大)。 cv.CHAIN_APPROX_SIMPLE压缩冗余点,仅保留拐点(如矩形→4个顶点)。 cv.CHAIN_APPROX_TC89_L1/KCOS使用Teh-Chin算法近似,平衡精度与效率 -
offset(可选):轮廓点偏移量- 格式:
(x_offset, y_offset),用于ROI区域提取的轮廓映射到原图坐标
- 格式:
轮廓提取流程
典型流程包括:
-
预处理:灰度化、去噪(高斯滤波)。
-
边缘增强:边缘检测(如Canny)或二值化(如Otsu阈值分割)。
-
轮廓提取:通过算法(如findContours)连接边缘点生成轮廓。
-
后处理:轮廓筛选(面积过滤)、多边形近似等
轮廓检索模式效果测试
def test_findContours():img = cv2.imread("./image/circle.jpg")# 复制图像以便绘制轮廓img1 = img.copy()img2 = img.copy()gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV)# 检测所有轮廓,建立完整的树形层级contours1, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)# 只检测最外层轮廓contours2, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)# 绘制轮廓res1 = cv2.drawContours(img1, contours1, -1, (0, 0, 255), 2)res2 = cv2.drawContours(img2, contours2, -1, (0, 0, 255), 2)res = merge_images_with_white_gap([img,binary, res1, res2], gap=20, scaling=0.4, is_gray=False)cv_show("Contours", res)
完整代码:
import cv2 as cv
import numpy as np
from util import cv_show , read_image , nothing,cv_show_await,merge_images_with_white_gapimage_path = "./image/2.png"
def main_findMonster():"""主函数:用于检测图像中的特定目标(如怪物)该函数读取图像,将其从BGR颜色空间转换为HSV颜色空间,然后使用预定义的HSV范围创建阈值掩码,以识别图像中的特定目标。最后,使用形态学处理和轮廓检测来定位目标,并显示结果图像。"""# 读取目标图像,图像为BGR三通道格式target_bgr = read_image(image_path)# 将图像从BGR颜色空间转换为HSV颜色空间target_hsv = cv.cvtColor(target_bgr, cv.COLOR_BGR2HSV)# 创建两个阈值掩码,分别针对HSV颜色空间中的两个不同范围# 这是为了更好地检测图像中的特定颜色(如红色)threshold_mask1 = cv.inRange(target_hsv, (0, 180, 150), (10, 255, 255))threshold_mask2 = cv.inRange(target_hsv, (175, 180, 150), (180, 255, 255))# 将两个阈值掩码合并,以覆盖更广的颜色范围threshold_mask = threshold_mask1 + threshold_mask2# 设置形态学处理的核kernel = setKernel()# 调用findMonster函数,在目标图像中使用阈值掩码和核来检测和定位目标display_img = findMonster(target_bgr, threshold_mask, kernel)# 显示处理后的图像,并等待用户按键cv_show_await("display_img", display_img)def create_trackbar():cv.namedWindow('Adjust HSV Thresholds')# 创建滑动条,初始值为默认的红色范围cv.createTrackbar('Lower H', 'Adjust HSV Thresholds', 0, 180, nothing)cv.createTrackbar('Upper H', 'Adjust HSV Thresholds', 10, 180, nothing)cv.createTrackbar('Lower S', 'Adjust HSV Thresholds', 210, 255, nothing)cv.createTrackbar('Upper S', 'Adjust HSV Thresholds', 255, 255, nothing)cv.createTrackbar('Lower V', 'Adjust HSV Thresholds', 180, 255, nothing)cv.createTrackbar('Upper V', 'Adjust HSV Thresholds', 255, 255, nothing)def get_threshold_mask(hsv_img):lower_h = cv.getTrackbarPos('Lower H', 'Adjust HSV Thresholds')upper_h = cv.getTrackbarPos('Upper H', 'Adjust HSV Thresholds')lower_s = cv.getTrackbarPos('Lower S', 'Adjust HSV Thresholds')upper_s = cv.getTrackbarPos('Upper S', 'Adjust HSV Thresholds')lower_v = cv.getTrackbarPos('Lower V', 'Adjust HSV Thresholds')upper_v = cv.getTrackbarPos('Upper V', 'Adjust HSV Thresholds')lower_red = np.array([lower_h, lower_s, lower_v])upper_red = np.array([upper_h, upper_s, upper_v])return cv.inRange(hsv_img, lower_red, upper_red)def setKernel():kernel_size = (5, 5)return cv.getStructuringElement(cv.MORPH_RECT, kernel_size)# 建立滑动条,动态测试调整HSV Thresholds
def test_findMonster():create_trackbar()target_bgr = read_image(image_path) # 读取为BGR三通道kernel = setKernel()while True:target_hsv = cv.cvtColor(target_bgr, cv.COLOR_BGR2HSV)threshold_mask = get_threshold_mask(target_hsv)findMonster(target_bgr,threshold_mask,kernel)key = cv.waitKey(1) & 0xFFif key == 27: # 按下 ESC 键退出break# 清理资源cv.destroyAllWindows()cv.waitKey(1) # 防止某些系统残留窗口def findMonster(target_bgr,mask, kernel):# 形态学操作mask1 = cv.morphologyEx(mask, cv.MORPH_CLOSE, kernel)mask2 = cv.dilate(mask1, kernel, iterations=2)# 显示拼接图target_gray = cv.cvtColor(target_bgr, cv.COLOR_BGR2GRAY)combined = merge_images_with_white_gap([target_gray, mask, mask1, mask2], gap=10, scaling=0.2)cv_show('Combined Image', combined)# 轮廓检测与标记contours, _ = cv.findContours(mask2, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)display_img = target_bgr.copy()for cnt in contours:x, y, w, h = cv.boundingRect(cnt)if h * 2 < w < h * 10:cv.rectangle(display_img, (x, y-5), (x + w, y), (255, 0, 0), 2)cv_show('Result', display_img)return display_img
import cv2 as cv
import os
import numpy as npdef nothing(x):passdef merge_images_with_white_gap(images, gap=20, scaling=1, is_gray=True):"""合并多张图像为水平排列的单张图像,图像间有白色间隔,支持缩放和灰度转换参数:images (list): 包含多张OpenCV格式图像的列表gap (int): 图像间的白色间隔宽度(像素),默认为20scaling (float): 最终图像的缩放比例,默认为1(不缩放)is_gray (bool): 是否转换为灰度图像,默认为False返回:np.ndarray: 合并后的图像,失败时返回None"""# 1. 输入校验if not images:print("Error: No images to merge.")return Noneif gap < 0:gap = 0if scaling <= 0:scaling = 1# 2. 灰度转换处理if is_gray:# 统一转为单通道灰度图processed_images = [cv.cvtColor(img, cv.COLOR_BGR2GRAY) if len(img.shape) == 3 else imgfor img in images]channel = 1 # 单通道else:# 统一转为三通道彩色图processed_images = []for img in images:if len(img.shape) == 2: # 单通道转三通道processed_images.append(cv.cvtColor(img, cv.COLOR_GRAY2BGR))elif len(img.shape) == 3 and img.shape[2] == 4: # 带透明通道processed_images.append(cv.cvtColor(img, cv.COLOR_BGRA2BGR))else:processed_images.append(img)channel = 3 # 三通道# 3. 计算合并尺寸max_height = max(img.shape[0] for img in processed_images)total_width = sum(img.shape[1] for img in processed_images) + gap * (len(processed_images) - 1)# 4. 创建白色背景画布if channel == 1:merged_image = np.full((max_height, total_width), 255, dtype=np.uint8) # 单通道白底else:merged_image = np.full((max_height, total_width, channel), 255, dtype=np.uint8) # 三通道白底[7](@ref)# 5. 图像拼接current_x = 0for img in processed_images:h, w = img.shape[:2] if channel == 1 else img.shape[:2]# 垂直居中放置y_offset = (max_height - h) // 2merged_image[y_offset : y_offset + h, current_x : current_x + w] = imgcurrent_x += w + gap # 移动位置并添加间隔[4](@ref)# 6. 缩放处理if scaling != 1:new_width = int(total_width * scaling)new_height = int(max_height * scaling)merged_image = cv.resize(merged_image,(new_width, new_height),interpolation=cv.INTER_AREA if scaling < 1 else cv.INTER_CUBIC,)return merged_imagedef read_image(image_path):if not os.path.exists(image_path):print(f"Error: Image file {image_path} does not exist.")returnimage = cv.imread(image_path)if image is None:print(f"Error: Image file {image_path} does not exist.")return Nonereturn imagedef cv_show_await(name, img):cv.imshow(name, img)cv.waitKey(0)cv.destroyAllWindows()def cv_show(winname, img):try:# 尝试获取窗口属性,判断是否已经创建if not hasattr(cv_show, "windows"):cv_show.windows = set()if winname not in cv_show.windows:cv.namedWindow(winname, cv.WINDOW_AUTOSIZE)cv_show.windows.add(winname)cv.imshow(winname, img)except cv.error:# 如果窗口已关闭,则重新创建cv.namedWindow(winname, cv.WINDOW_AUTOSIZE)cv_show.windows.add(winname)cv.imshow(winname, img)